 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Co-training Transformer with Videos and Images Improves Action Recognition
Dec 14, 2021
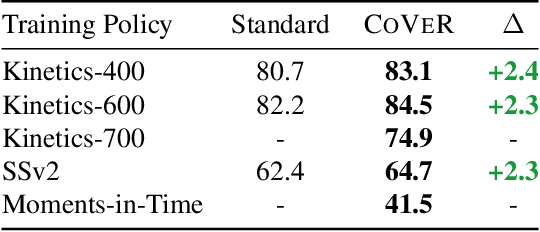
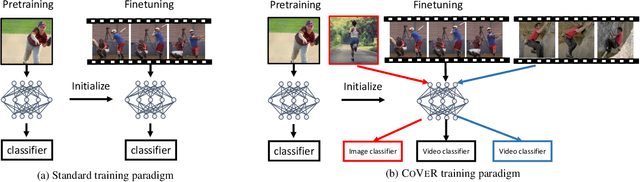

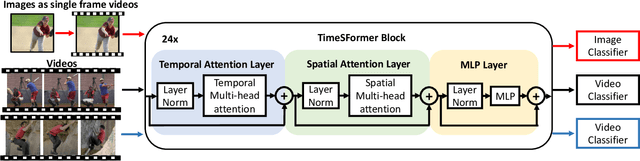
In learning action recognition, models are typically pre-trained on object recognition with images, such as ImageNet, and later fine-tuned on target action recognition with videos. This approach has achieved good empirical performance especially with recent transformer-based video architectures. While recently many works aim to design more advanced transformer architectures for action recognition, less effort has been made on how to train video transformers. In this work, we explore several training paradigms and present two findings. First, video transformers benefit from joint training on diverse video datasets and label spaces (e.g., Kinetics is appearance-focused while SomethingSomething is motion-focused). Second, by further co-training with images (as single-frame videos), the video transformers learn even better video representations. We term this approach as Co-training Videos and Images for Action Recognition (CoVeR). In particular, when pretrained on ImageNet-21K based on the TimeSFormer architecture, CoVeR improves Kinetics-400 Top-1 Accuracy by 2.4%, Kinetics-600 by 2.3%, and SomethingSomething-v2 by 2.3%. When pretrained on larger-scale image datasets following previous state-of-the-art, CoVeR achieves best results on Kinetics-400 (87.2%), Kinetics-600 (87.9%), Kinetics-700 (79.8%), SomethingSomething-v2 (70.9%), and Moments-in-Time (46.1%), with a simple spatio-temporal video transformer.
Multiple Sclerosis Lesions Segmentation using Attention-Based CNNs in FLAIR Images
Jan 05, 2022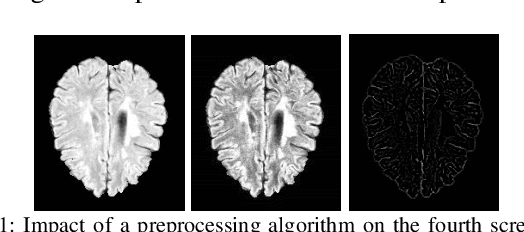
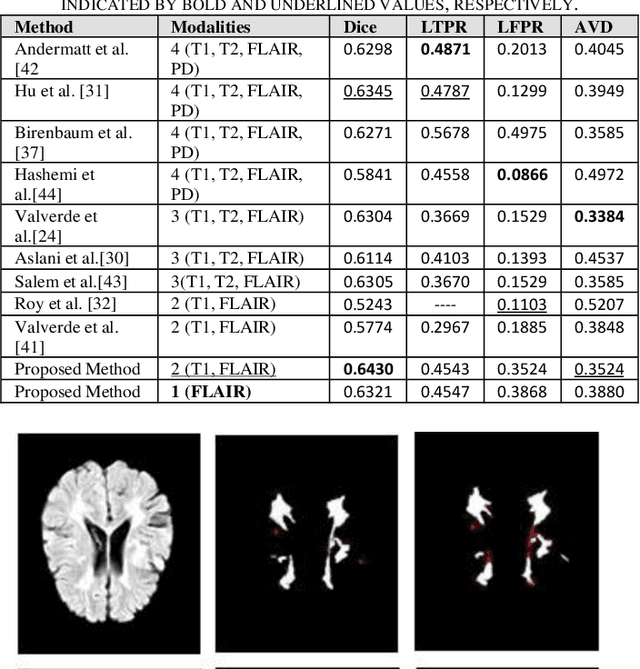
Objective: Multiple Sclerosis (MS) is an autoimmune, and demyelinating disease that leads to lesions in the central nervous system. This disease can be tracked and diagnosed using Magnetic Resonance Imaging (MRI). Up to now a multitude of multimodality automatic biomedical approaches is used to segment lesions which are not beneficial for patients in terms of cost, time, and usability. The authors of the present paper propose a method employing just one modality (FLAIR image) to segment MS lesions accurately. Methods: A patch-based Convolutional Neural Network (CNN) is designed, inspired by 3D-ResNet and spatial-channel attention module, to segment MS lesions. The proposed method consists of three stages: (1) the contrast-limited adaptive histogram equalization (CLAHE) is applied to the original images and concatenated to the extracted edges in order to create 4D images; (2) the patches of size 80 * 80 * 80 * 2 are randomly selected from the 4D images; and (3) the extracted patches are passed into an attention-based CNN which is used to segment the lesions. Finally, the proposed method was compared to previous studies of the same dataset. Results: The current study evaluates the model, with a test set of ISIB challenge data. Experimental results illustrate that the proposed approach significantly surpasses existing methods in terms of Dice similarity and Absolute Volume Difference while the proposed method use just one modality (FLAIR) to segment the lesions. Conclusions: The authors have introduced an automated approach to segment the lesions which is based on, at most, two modalities as an input. The proposed architecture is composed of convolution, deconvolution, and an SCA-VoxRes module as an attention module. The results show, the proposed method outperforms well compare to other methods.
Deep Reinforcement Learning in Computer Vision: A Comprehensive Survey
Aug 25, 2021

Deep reinforcement learning augments the reinforcement learning framework and utilizes the powerful representation of deep neural networks. Recent works have demonstrated the remarkable successes of deep reinforcement learning in various domains including finance, medicine, healthcare, video games, robotics, and computer vision. In this work, we provide a detailed review of recent and state-of-the-art research advances of deep reinforcement learning in computer vision. We start with comprehending the theories of deep learning, reinforcement learning, and deep reinforcement learning. We then propose a categorization of deep reinforcement learning methodologies and discuss their advantages and limitations. In particular, we divide deep reinforcement learning into seven main categories according to their applications in computer vision, i.e. (i)landmark localization (ii) object detection; (iii) object tracking; (iv) registration on both 2D image and 3D image volumetric data (v) image segmentation; (vi) videos analysis; and (vii) other applications. Each of these categories is further analyzed with reinforcement learning techniques, network design, and performance. Moreover, we provide a comprehensive analysis of the existing publicly available datasets and examine source code availability. Finally, we present some open issues and discuss future research directions on deep reinforcement learning in computer vision
How useful is Active Learning for Image-based Plant Phenotyping?
Jun 07, 2020

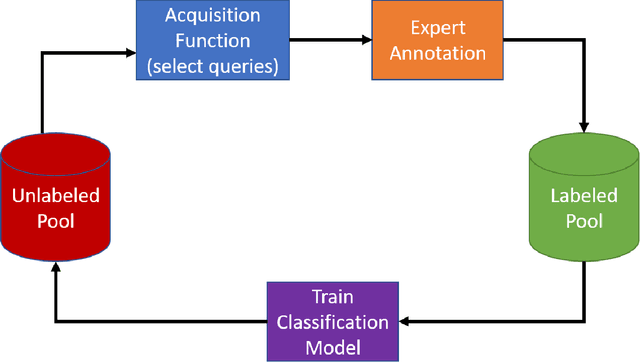
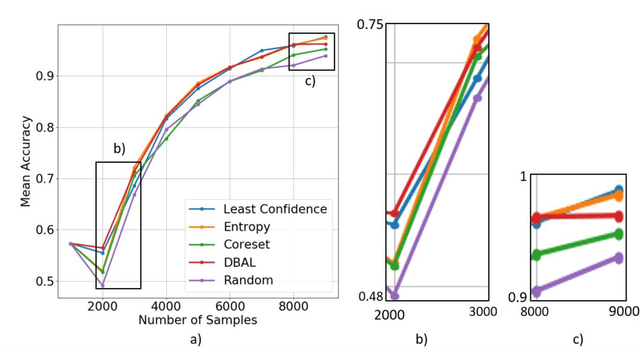
Deep learning models have been successfully deployed for a diverse array of image-based plant phenotyping applications including disease detection and classification. However, successful deployment of supervised deep learning models requires large amount of labeled data, which is a significant challenge in plant science (and most biological) domains due to the inherent complexity. Specifically, data annotation is costly, laborious, time consuming and needs domain expertise for phenotyping tasks, especially for diseases. To overcome this challenge, active learning algorithms have been proposed that reduce the amount of labeling needed by deep learning models to achieve good predictive performance. Active learning methods adaptively select samples to annotate using an acquisition function to achieve maximum (classification) performance under a fixed labeling budget. We reports the performance of four different active learning methods, (1) Deep Bayesian Active Learning (DBAL), (2) Entropy, (3) Least Confidence, and (4) Coreset, with conventional random sampling-based annotation for two different image-based classification datasets. The first image dataset consists of soybean [Glycine max L. (Merr.)] leaves belonging to eight different soybean stresses and a healthy class, and the second consists of nine different weed species from the field. For a fixed labeling budget, we observed that the classification performance of deep learning models with active learning-based acquisition strategies is better than random sampling-based acquisition for both datasets. The integration of active learning strategies for data annotation can help mitigate labelling challenges in the plant sciences applications particularly where deep domain knowledge is required.
Dynamic imaging using motion-compensated smoothness regularization on manifolds (MoCo-SToRM)
Nov 21, 2021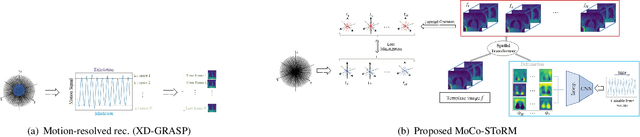
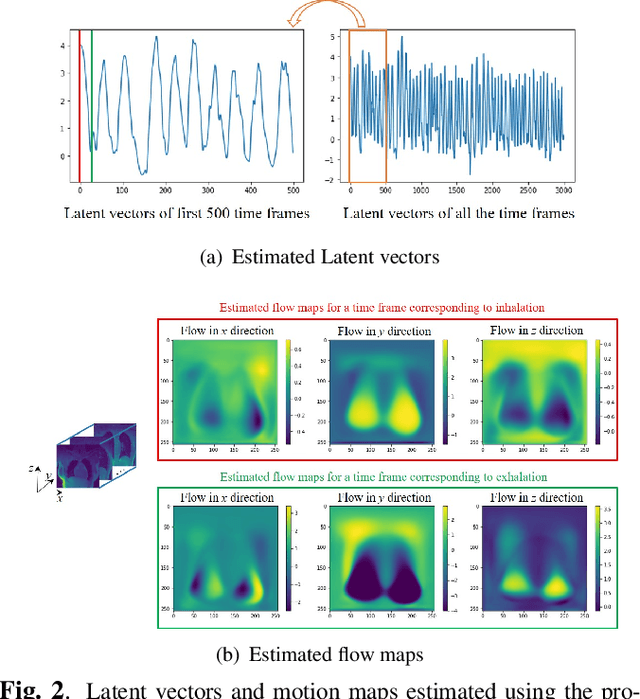
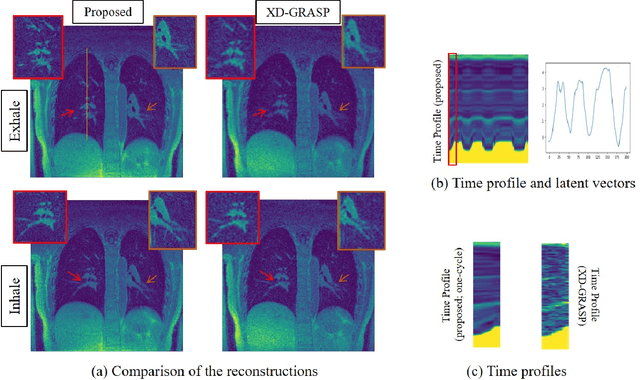
We introduce an unsupervised deep manifold learning algorithm for motion-compensated dynamic MRI. We assume that the motion fields in a free-breathing lung MRI dataset live on a manifold. The motion field at each time instant is modeled as the output of a deep generative model, driven by low-dimensional time-varying latent vectors that capture the temporal variability. The images at each time instant are modeled as the deformed version of an image template using the above motion fields. The template, the parameters of the deep generator, and the latent vectors are learned from the k-t space data in an unsupervised fashion. The manifold motion model serves as a regularizer, making the joint estimation of the motion fields and images from few radial spokes/frame well-posed. The utility of the algorithm is demonstrated in the context of motion-compensated high-resolution lung MRI.
Transform Network Architectures for Deep Learning based End-to-End Image/Video Coding in Subsampled Color Spaces
Feb 27, 2021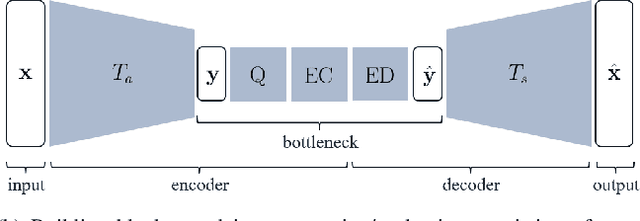
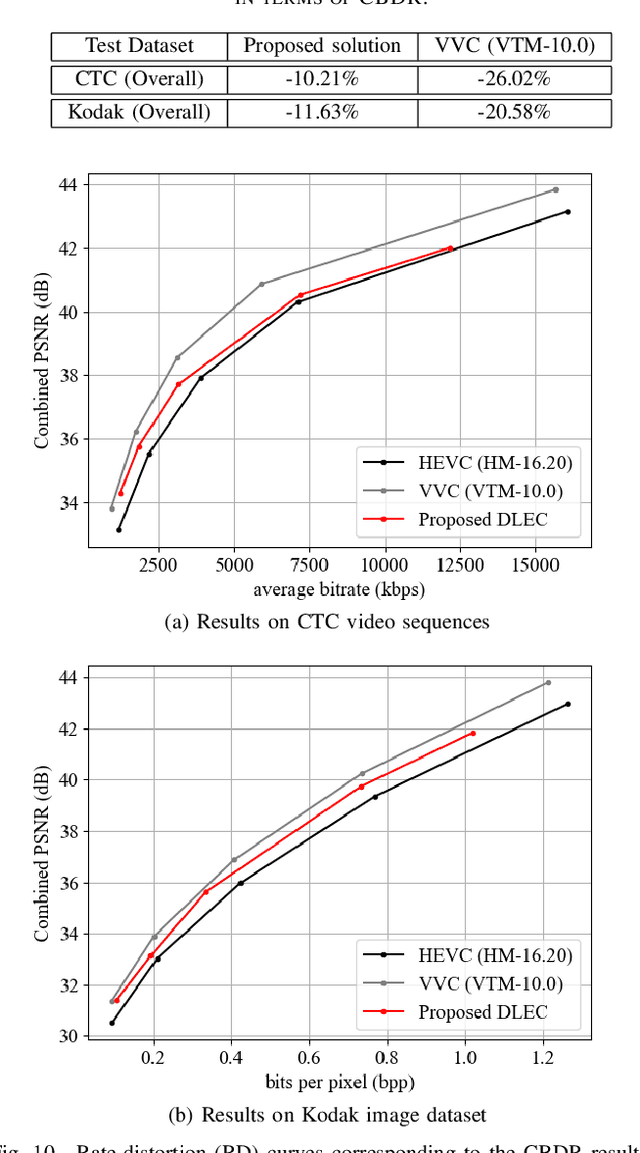
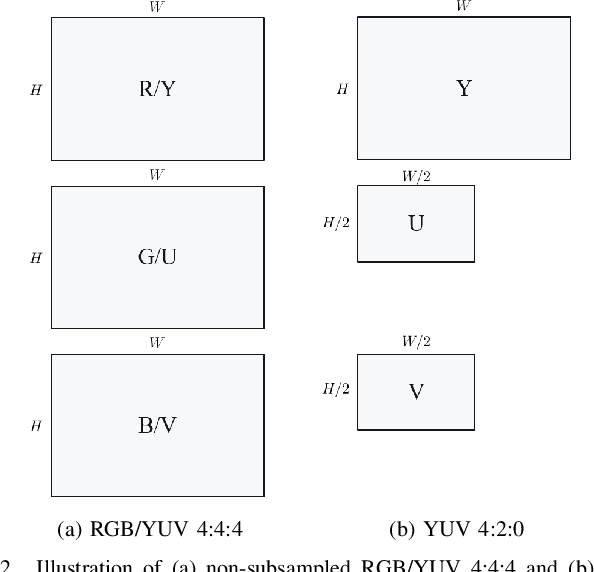

Most of the existing deep learning based end-to-end image/video coding (DLEC) architectures are designed for non-subsampled RGB color format. However, in order to achieve a superior coding performance, many state-of-the-art block-based compression standards such as High Efficiency Video Coding (HEVC/H.265) and Versatile Video Coding (VVC/H.266) are designed primarily for YUV 4:2:0 format, where U and V components are subsampled by considering the human visual system. This paper investigates various DLEC designs to support YUV 4:2:0 format by comparing their performance against the main profiles of HEVC and VVC standards under a common evaluation framework. Moreover, a new transform network architecture is proposed to improve the efficiency of coding YUV 4:2:0 data. The experimental results on YUV 4:2:0 datasets show that the proposed architecture significantly outperforms naive extensions of existing architectures designed for RGB format and achieves about 10% average BD-rate improvement over the intra-frame coding in HEVC.
Self-Distilled Self-Supervised Representation Learning
Nov 25, 2021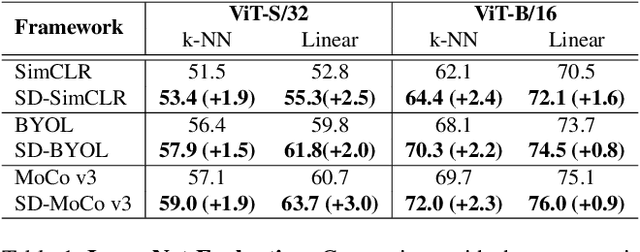
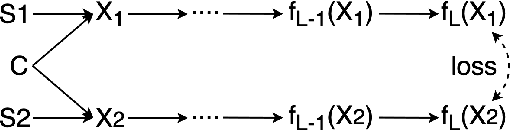
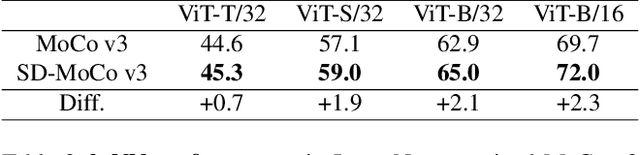
State-of-the-art frameworks in self-supervised learning have recently shown that fully utilizing transformer-based models can lead to performance boost compared to conventional CNN models. Thriving to maximize the mutual information of two views of an image, existing works apply a contrastive loss to the final representations. In our work, we further exploit this by allowing the intermediate representations to learn from the final layers via the contrastive loss, which is maximizing the upper bound of the original goal and the mutual information between two layers. Our method, Self-Distilled Self-Supervised Learning (SDSSL), outperforms competitive baselines (SimCLR, BYOL and MoCo v3) using ViT on various tasks and datasets. In the linear evaluation and k-NN protocol, SDSSL not only leads to superior performance in the final layers, but also in most of the lower layers. Furthermore, positive and negative alignments are used to explain how representations are formed more effectively. Code will be available.
Low Rank Quaternion Matrix Recovery via Logarithmic Approximation
Jul 03, 2021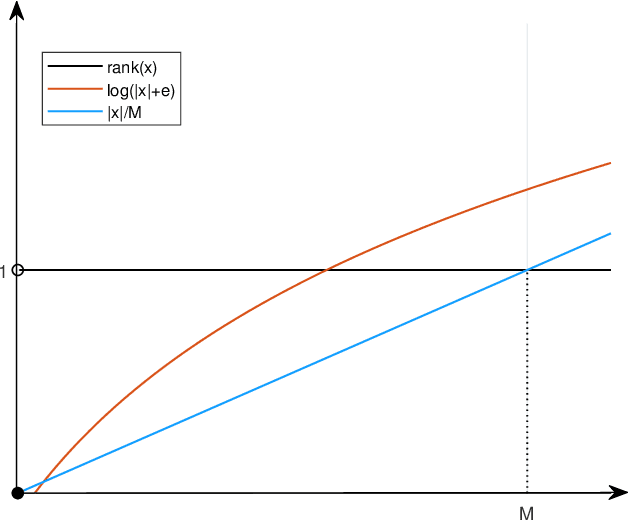
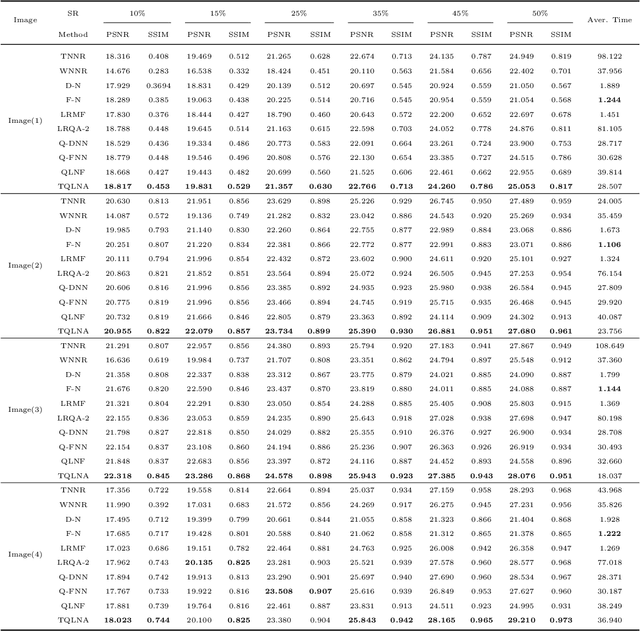

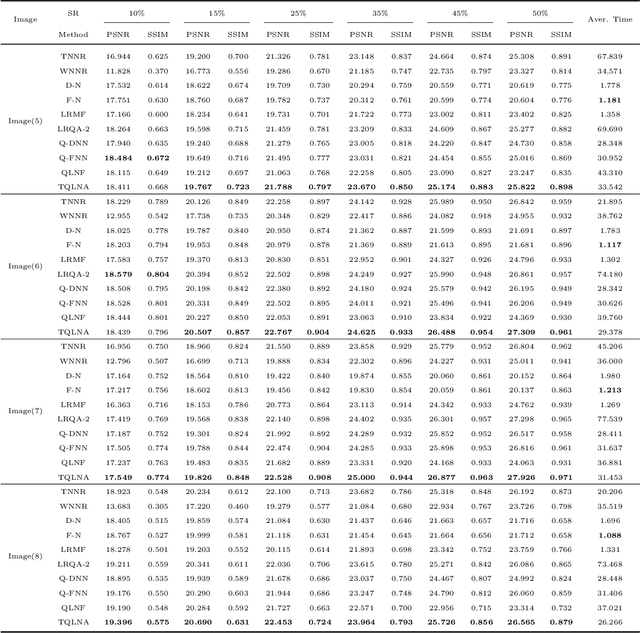
In color image processing, image completion aims to restore missing entries from the incomplete observation image. Recently, great progress has been made in achieving completion by approximately solving the rank minimization problem. In this paper, we utilize a novel quaternion matrix logarithmic norm to approximate rank under the quaternion matrix framework. From one side, unlike the traditional matrix completion method that handles RGB channels separately, the quaternion-based method is able to avoid destroying the structure of images via putting the color image in a pure quaternion matrix. From the other side, the logarithmic norm induces a more accurate rank surrogate. Based on the logarithmic norm, we take advantage of not only truncated technique but also factorization strategy to achieve image restoration. Both strategies are optimized based on the alternating minimization framework. The experimental results demonstrate that the use of logarithmic surrogates in the quaternion domain is more superior in solving the problem of color images completion.
Meta-Learning Initializations for Image Segmentation
Dec 13, 2019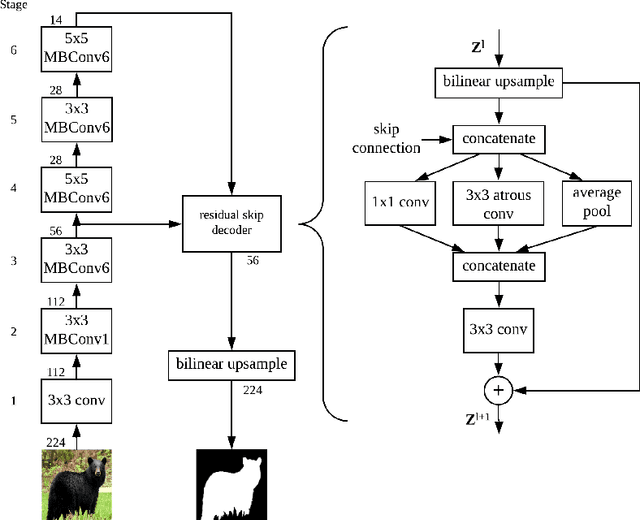


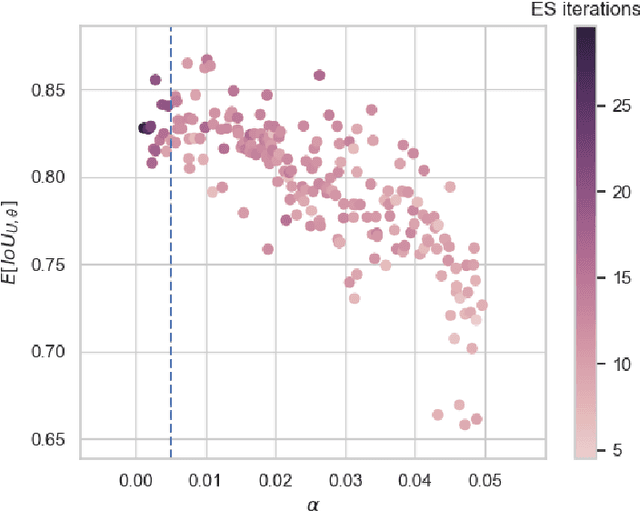
While meta-learning approaches that utilize neural network representations have made progress in few-shot image classification, reinforcement learning, and, more recently, image semantic segmentation, the training algorithms and model architectures have become increasingly specialized to the few-shot domain. A natural question that arises is how to develop learning systems that scale from few-shot to many-shot settings while yielding competitive performance in both. One scalable potential approach that does not require ensembling many models nor the computational costs of relation networks, is to meta-learn an initialization. In this work, we study first-order meta-learning of initializations for deep neural networks that must produce dense, structured predictions given an arbitrary amount of training data for a new task. Our primary contributions include (1), an extension and experimental analysis of first-order model agnostic meta-learning algorithms (including FOMAML and Reptile) to image segmentation, (2) a novel neural network architecture built for parameter efficiency and fast learning which we call EfficientLab, (3) a formalization of the generalization error of meta-learning algorithms, which we leverage to decrease error on unseen tasks, and (4) a small benchmark dataset, FP-k, for the empirical study of how meta-learning systems perform in both few- and many-shot settings. We show that meta-learned initializations for image segmentation provide value for both canonical few-shot learning problems and larger datasets, outperforming ImageNet-trained initializations for up to 400 densely labeled examples. We find that our network, with an empirically estimated optimal update procedure, yields state of the art results on the FSS-1000 dataset while only requiring one forward pass through a single model at evaluation time.
Single-shot wide-field optical section imaging
Nov 05, 2021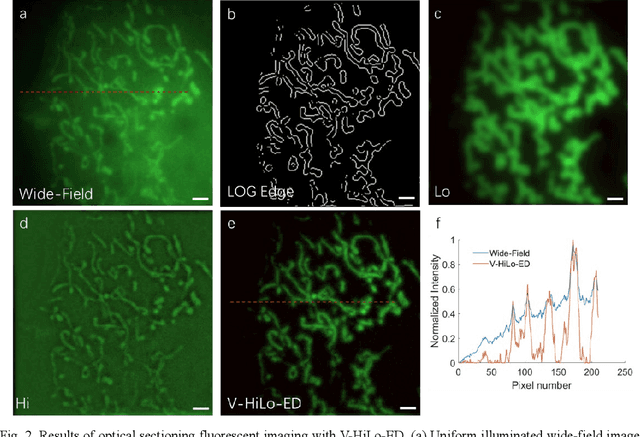
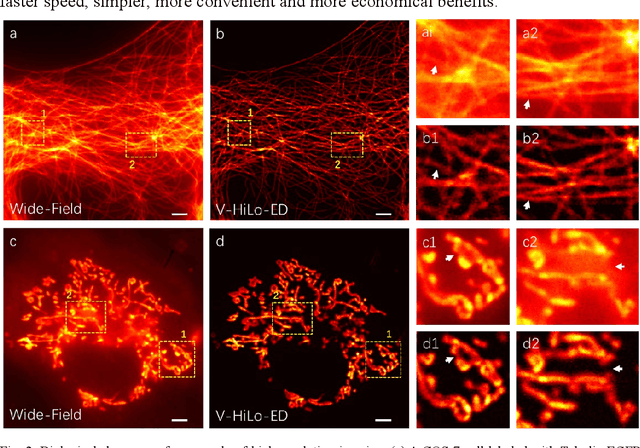
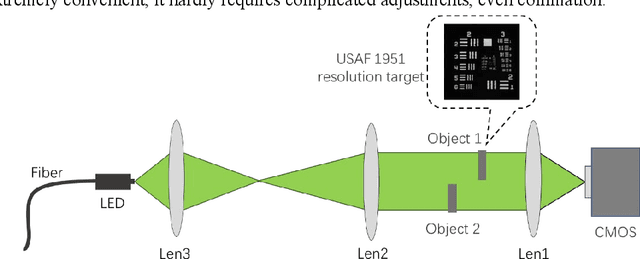
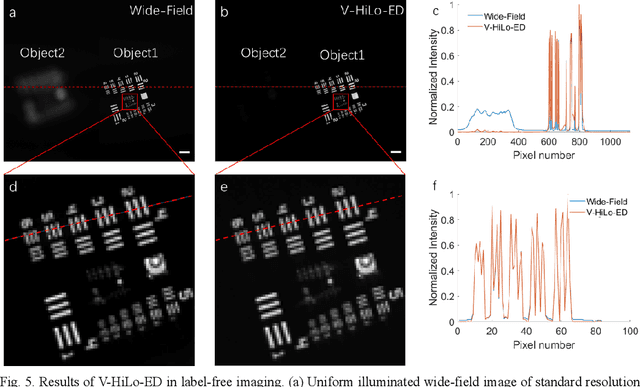
Optical sectioning technology has been widely used in various fluorescence microscopes owing to its background removing capability. Here, a virtual HiLo based on edge detection (V-HiLo-ED) is proposed to achieve wide-field optical sectioning, which requires only single wide-field image. Compared with conventional optical sectioning technologies, its imaging speed can be increased by at least twice, meanwhile maintaining nice optical sectioning performance, low cost, and excellent artifact suppression capabilities. Furthermore, the new V-HiLo-ED can also be extended to other non-fluorescence imaging fields. This simple, cost-effective and easy-to-extend method will benefit many research and application fields that needs to remove out-of-focus blurred images.