 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Random Network Distillation as a Diversity Metric for Both Image and Text Generation
Oct 13, 2020
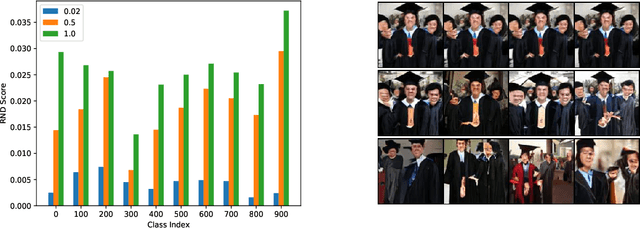
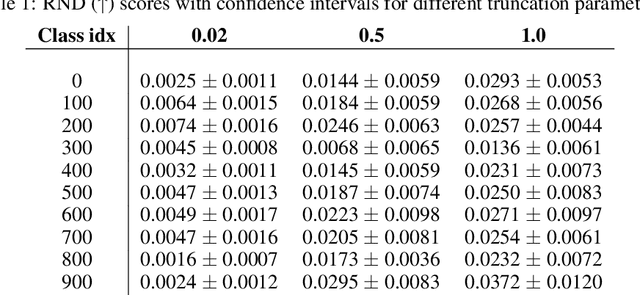
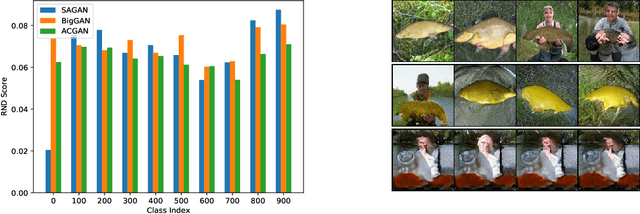
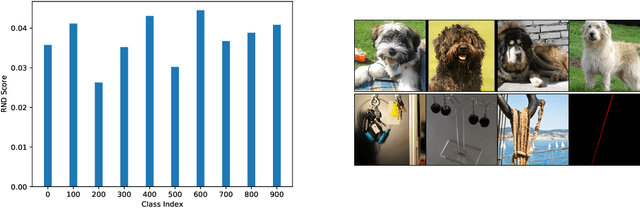
Generative models are increasingly able to produce remarkably high quality images and text. The community has developed numerous evaluation metrics for comparing generative models. However, these metrics do not effectively quantify data diversity. We develop a new diversity metric that can readily be applied to data, both synthetic and natural, of any type. Our method employs random network distillation, a technique introduced in reinforcement learning. We validate and deploy this metric on both images and text. We further explore diversity in few-shot image generation, a setting which was previously difficult to evaluate.
4D Semantic Cardiac Magnetic Resonance Image Synthesis on XCAT Anatomical Model
Feb 17, 2020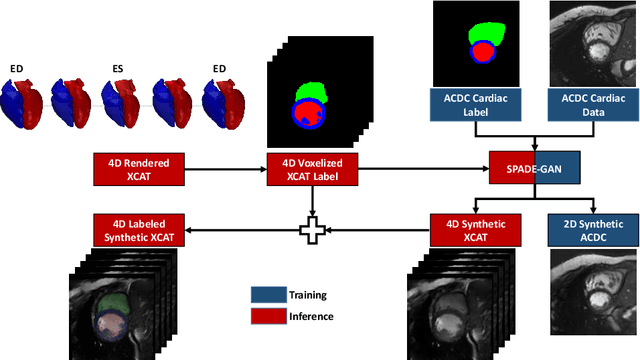
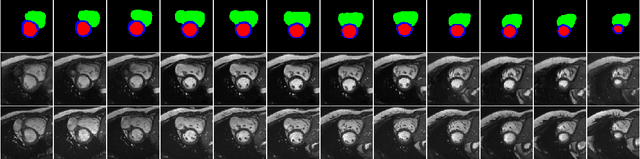

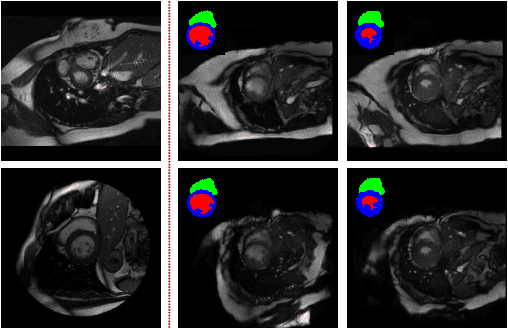
We propose a hybrid controllable image generation method to synthesize anatomically meaningful 3D+t labeled Cardiac Magnetic Resonance (CMR) images. Our hybrid method takes the mechanistic 4D eXtended CArdiac Torso (XCAT) heart model as the anatomical ground truth and synthesizes CMR images via a data-driven Generative Adversarial Network (GAN). We employ the state-of-the-art SPatially Adaptive De-normalization (SPADE) technique for conditional image synthesis to preserve the semantic spatial information of ground truth anatomy. Using the parameterized motion model of the XCAT heart, we generate labels for 25 time frames of the heart for one cardiac cycle at 18 locations for the short axis view. Subsequently, realistic images are generated from these labels, with modality-specific features that are learned from real CMR image data. We demonstrate that style transfer from another cardiac image can be accomplished by using a style encoder network. Due to the flexibility of XCAT in creating new heart models, this approach can result in a realistic virtual population to address different challenges the medical image analysis research community is facing such as expensive data collection. Our proposed method has a great potential to synthesize 4D controllable CMR images with annotations and adaptable styles to be used in various supervised multi-site, multi-vendor applications in medical image analysis.
Efficient Blind-Spot Neural Network Architecture for Image Denoising
Aug 25, 2020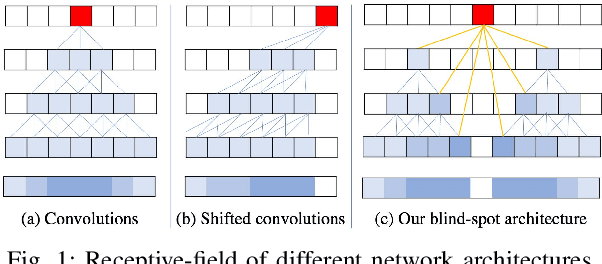
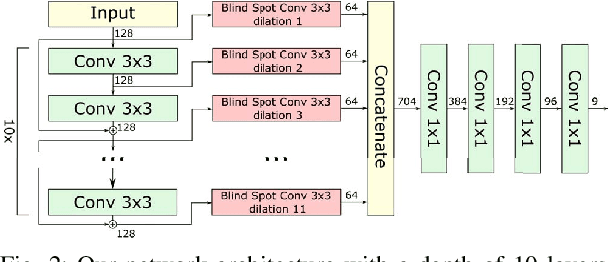
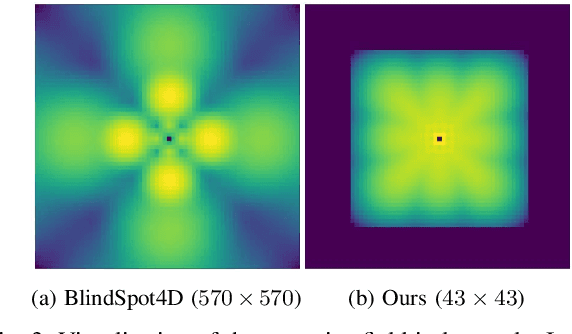
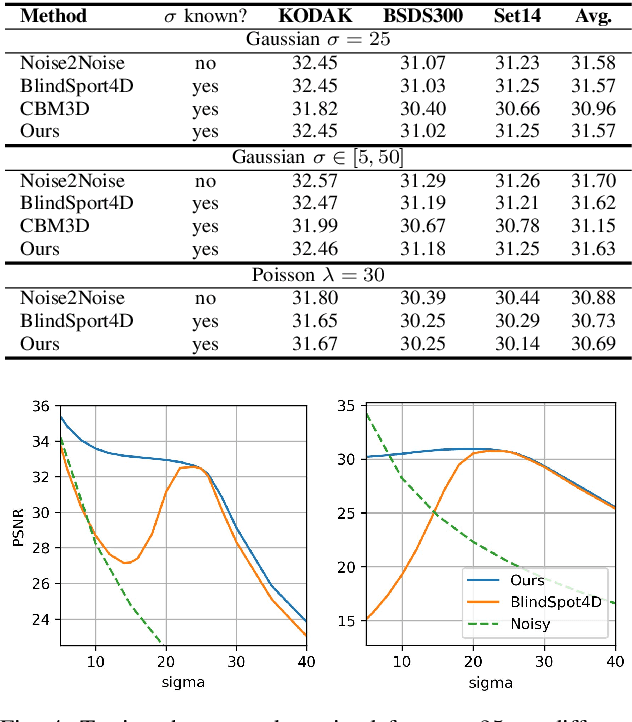
Image denoising is an essential tool in computational photography. Standard denoising techniques, which use deep neural networks at their core, require pairs of clean and noisy images for its training. If we do not possess the clean samples, we can use blind-spot neural network architectures, which estimate the pixel value based on the neighbouring pixels only. These networks thus allow training on noisy images directly, as they by-design avoid trivial solutions. Nowadays, the blind-spot is mostly achieved using shifted convolutions or serialization. We propose a novel fully convolutional network architecture that uses dilations to achieve the blind-spot property. Our network improves the performance over the prior work and achieves state-of-the-art results on established datasets.
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
Aug 16, 2021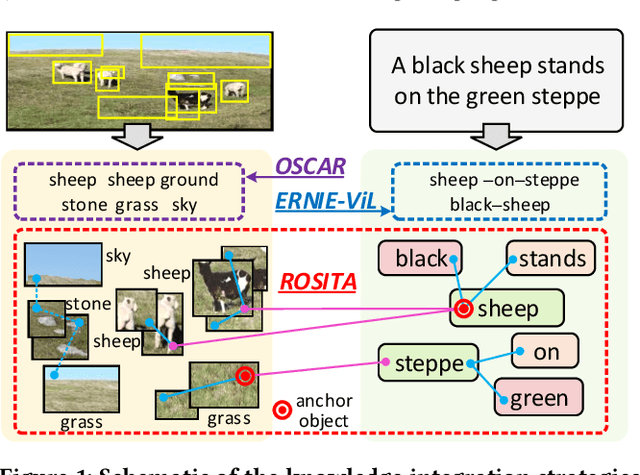
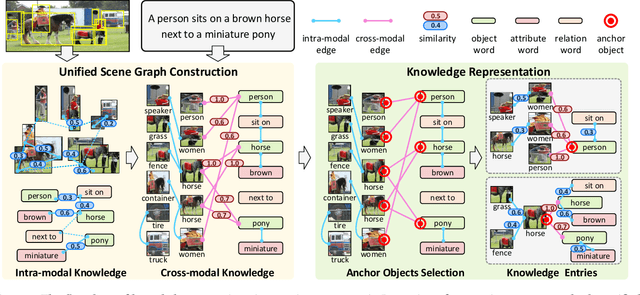
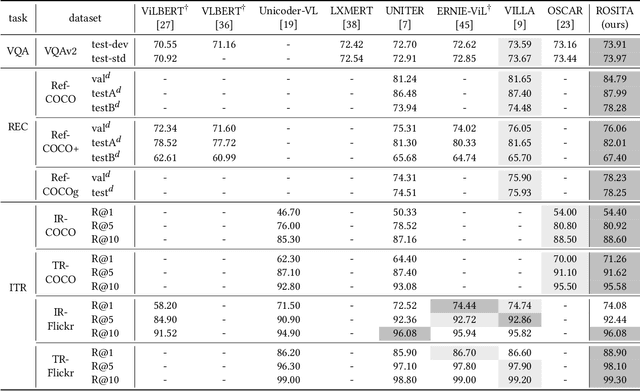
Vision-and-language pretraining (VLP) aims to learn generic multimodal representations from massive image-text pairs. While various successful attempts have been proposed, learning fine-grained semantic alignments between image-text pairs plays a key role in their approaches. Nevertheless, most existing VLP approaches have not fully utilized the intrinsic knowledge within the image-text pairs, which limits the effectiveness of the learned alignments and further restricts the performance of their models. To this end, we introduce a new VLP method called ROSITA, which integrates the cross- and intra-modal knowledge in a unified scene graph to enhance the semantic alignments. Specifically, we introduce a novel structural knowledge masking (SKM) strategy to use the scene graph structure as a priori to perform masked language (region) modeling, which enhances the semantic alignments by eliminating the interference information within and across modalities. Extensive ablation studies and comprehensive analysis verifies the effectiveness of ROSITA in semantic alignments. Pretrained with both in-domain and out-of-domain datasets, ROSITA significantly outperforms existing state-of-the-art VLP methods on three typical vision-and-language tasks over six benchmark datasets.
UIBert: Learning Generic Multimodal Representations for UI Understanding
Aug 10, 2021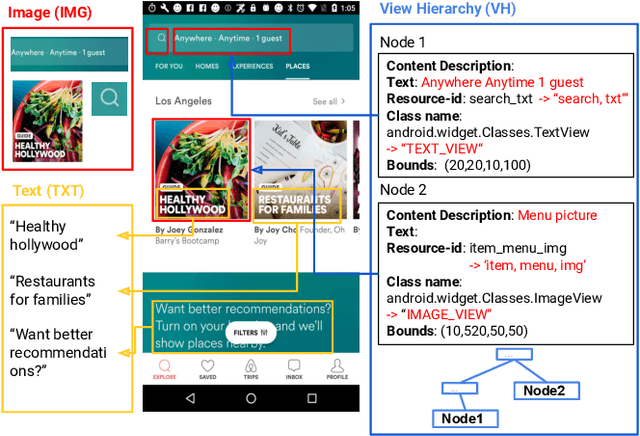
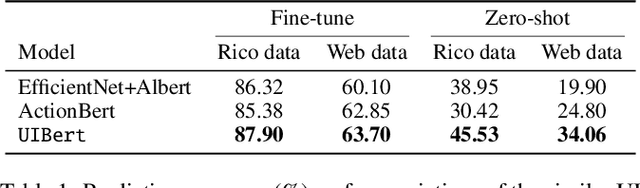
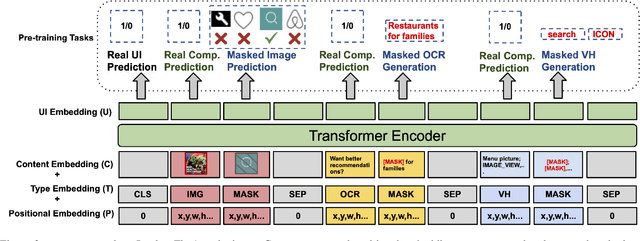
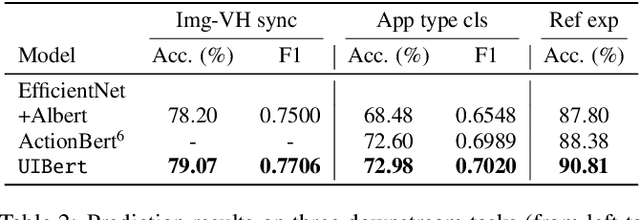
To improve the accessibility of smart devices and to simplify their usage, building models which understand user interfaces (UIs) and assist users to complete their tasks is critical. However, unique challenges are proposed by UI-specific characteristics, such as how to effectively leverage multimodal UI features that involve image, text, and structural metadata and how to achieve good performance when high-quality labeled data is unavailable. To address such challenges we introduce UIBert, a transformer-based joint image-text model trained through novel pre-training tasks on large-scale unlabeled UI data to learn generic feature representations for a UI and its components. Our key intuition is that the heterogeneous features in a UI are self-aligned, i.e., the image and text features of UI components, are predictive of each other. We propose five pretraining tasks utilizing this self-alignment among different features of a UI component and across various components in the same UI. We evaluate our method on nine real-world downstream UI tasks where UIBert outperforms strong multimodal baselines by up to 9.26% accuracy.
Optimal Image Smoothing and Its Applications in Anomaly Detection in Remote Sensing
Mar 17, 2020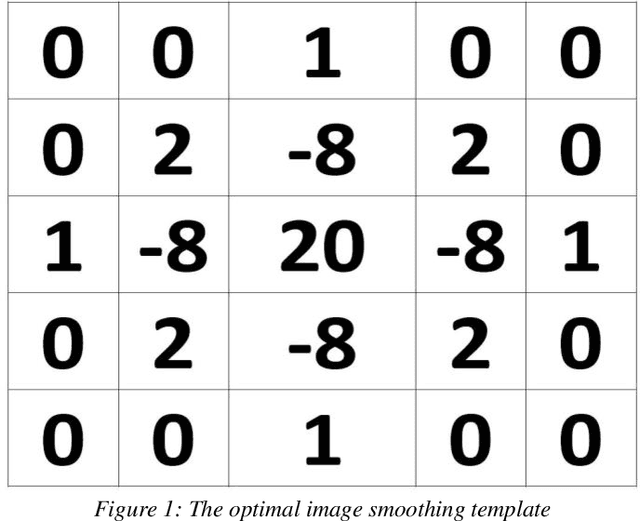



This paper is focused on deriving an optimal image smoother. The optimization is done through the minimization of the norm of the Laplace operator in the image coordinate system. Discretizing the Laplace operator and using the method of Euler-Lagrange result in a weighted average scheme for the optimal smoother. Satellite imagery can be smoothed by this optimal smoother. It is also very fast and can be used for detecting the anomalies in the image. A real anomaly detecting problem is considered for the Qom region in Iran. Satellite image in different bands are smoothed. Comparing the smoothed and original images in different bands, the maps of anomalies are presented. Comparison between the derived method and the existing methods reveals that it is more efficient in detecting anomalies in the region.
AdaStereo: An Efficient Domain-Adaptive Stereo Matching Approach
Dec 09, 2021
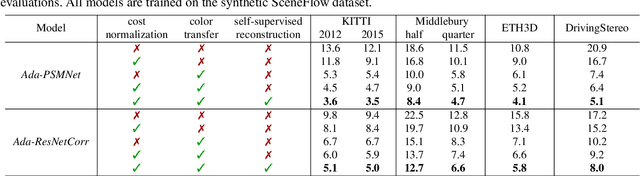
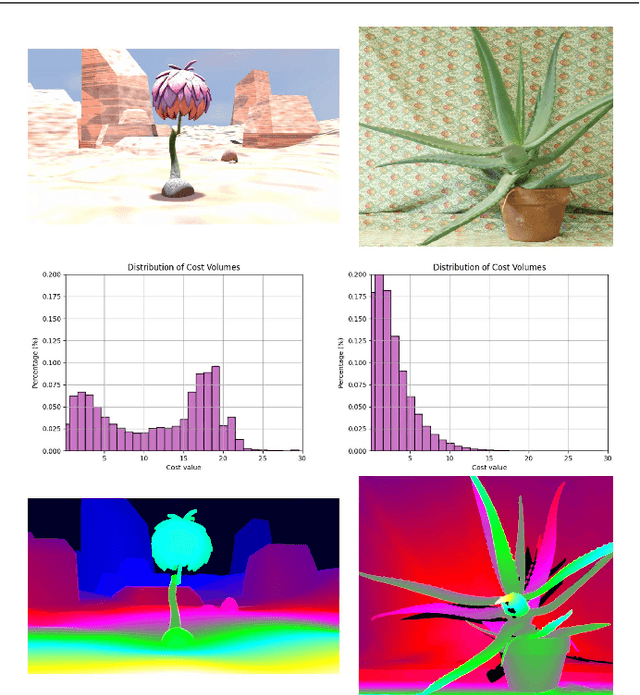
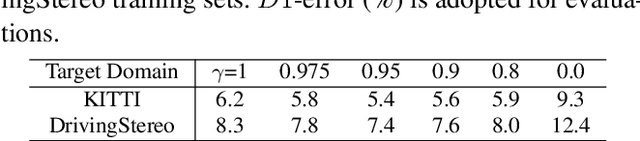
Recently, records on stereo matching benchmarks are constantly broken by end-to-end disparity networks. However, the domain adaptation ability of these deep models is quite limited. Addressing such problem, we present a novel domain-adaptive approach called AdaStereo that aims to align multi-level representations for deep stereo matching networks. Compared to previous methods, our AdaStereo realizes a more standard, complete and effective domain adaptation pipeline. Firstly, we propose a non-adversarial progressive color transfer algorithm for input image-level alignment. Secondly, we design an efficient parameter-free cost normalization layer for internal feature-level alignment. Lastly, a highly related auxiliary task, self-supervised occlusion-aware reconstruction is presented to narrow the gaps in output space. We perform intensive ablation studies and break-down comparisons to validate the effectiveness of each proposed module. With no extra inference overhead and only a slight increase in training complexity, our AdaStereo models achieve state-of-the-art cross-domain performance on multiple benchmarks, including KITTI, Middlebury, ETH3D and DrivingStereo, even outperforming some state-of-the-art disparity networks finetuned with target-domain ground-truths. Moreover, based on two additional evaluation metrics, the superiority of our domain-adaptive stereo matching pipeline is further uncovered from more perspectives. Finally, we demonstrate that our method is robust to various domain adaptation settings, and can be easily integrated into quick adaptation application scenarios and real-world deployments.
An Auto-Encoder Strategy for Adaptive Image Segmentation
Apr 29, 2020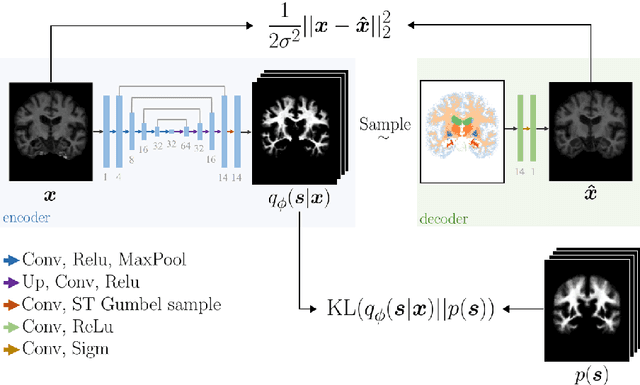
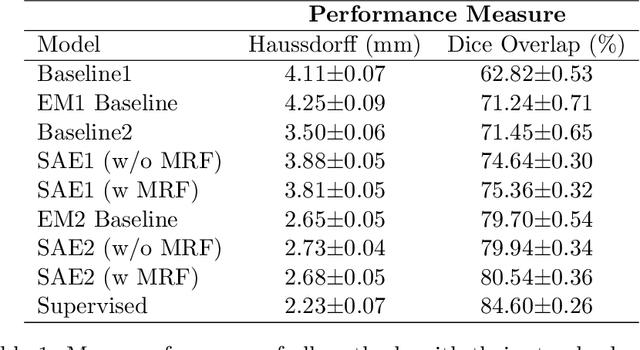
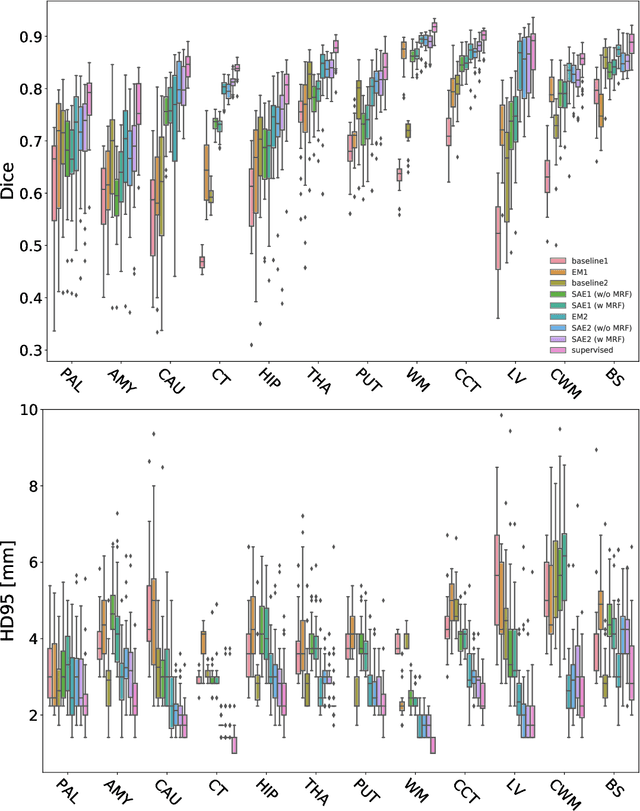
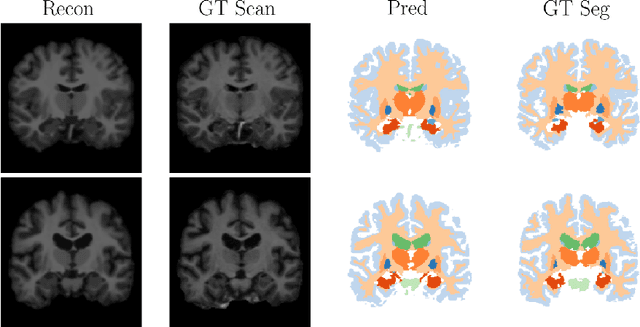
Deep neural networks are powerful tools for biomedical image segmentation. These models are often trained with heavy supervision, relying on pairs of images and corresponding voxel-level labels. However, obtaining segmentations of anatomical regions on a large number of cases can be prohibitively expensive. Thus there is a strong need for deep learning-based segmentation tools that do not require heavy supervision and can continuously adapt. In this paper, we propose a novel perspective of segmentation as a discrete representation learning problem, and present a variational autoencoder segmentation strategy that is flexible and adaptive. Our method, called Segmentation Auto-Encoder (SAE), leverages all available unlabeled scans and merely requires a segmentation prior, which can be a single unpaired segmentation image. In experiments, we apply SAE to brain MRI scans. Our results show that SAE can produce good quality segmentations, particularly when the prior is good. We demonstrate that a Markov Random Field prior can yield significantly better results than a spatially independent prior. Our code is freely available at https://github.com/evanmy/sae.
MARMOT: A Deep Learning Framework for Constructing Multimodal Representations for Vision-and-Language Tasks
Sep 23, 2021
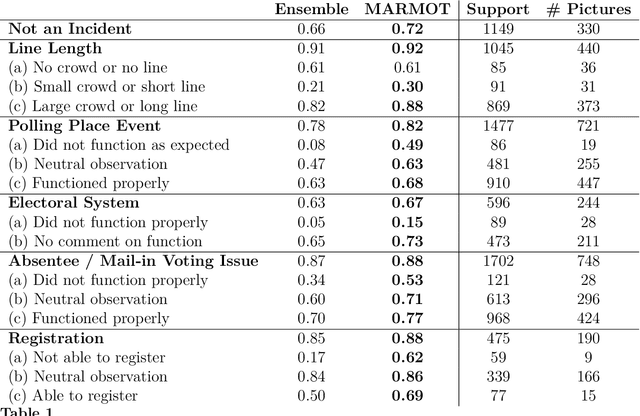
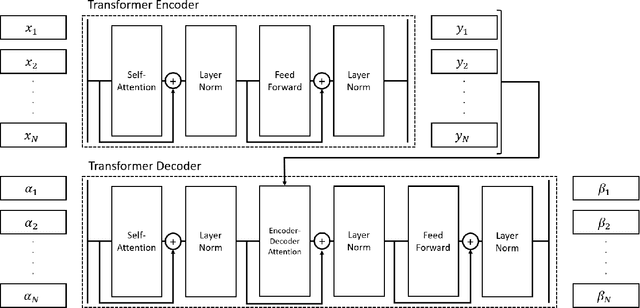
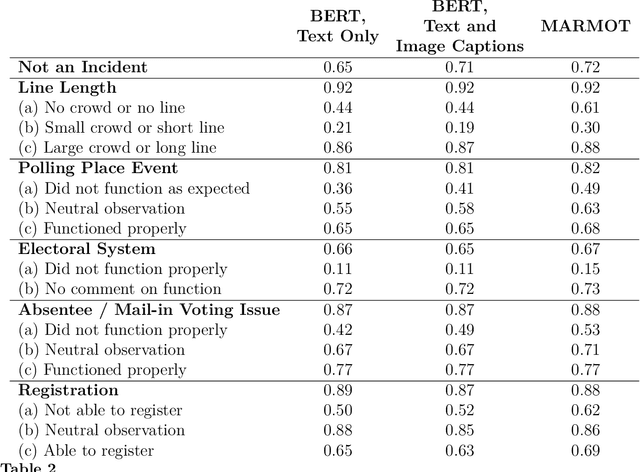
Political activity on social media presents a data-rich window into political behavior, but the vast amount of data means that almost all content analyses of social media require a data labeling step. However, most automated machine classification methods ignore the multimodality of posted content, focusing either on text or images. State-of-the-art vision-and-language models are unusable for most political science research: they require all observations to have both image and text and require computationally expensive pretraining. This paper proposes a novel vision-and-language framework called multimodal representations using modality translation (MARMOT). MARMOT presents two methodological contributions: it can construct representations for observations missing image or text, and it replaces the computationally expensive pretraining with modality translation. MARMOT outperforms an ensemble text-only classifier in 19 of 20 categories in multilabel classifications of tweets reporting election incidents during the 2016 U.S. general election. Moreover, MARMOT shows significant improvements over the results of benchmark multimodal models on the Hateful Memes dataset, improving the best result set by VisualBERT in terms of accuracy from 0.6473 to 0.6760 and area under the receiver operating characteristic curve (AUC) from 0.7141 to 0.7530.
Learning Diagnosis of COVID-19 from a Single Radiological Image
Jun 06, 2020
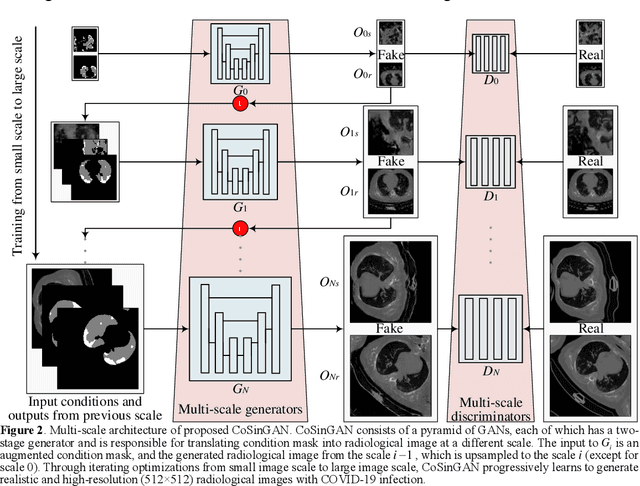
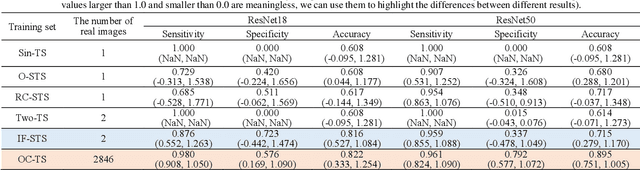
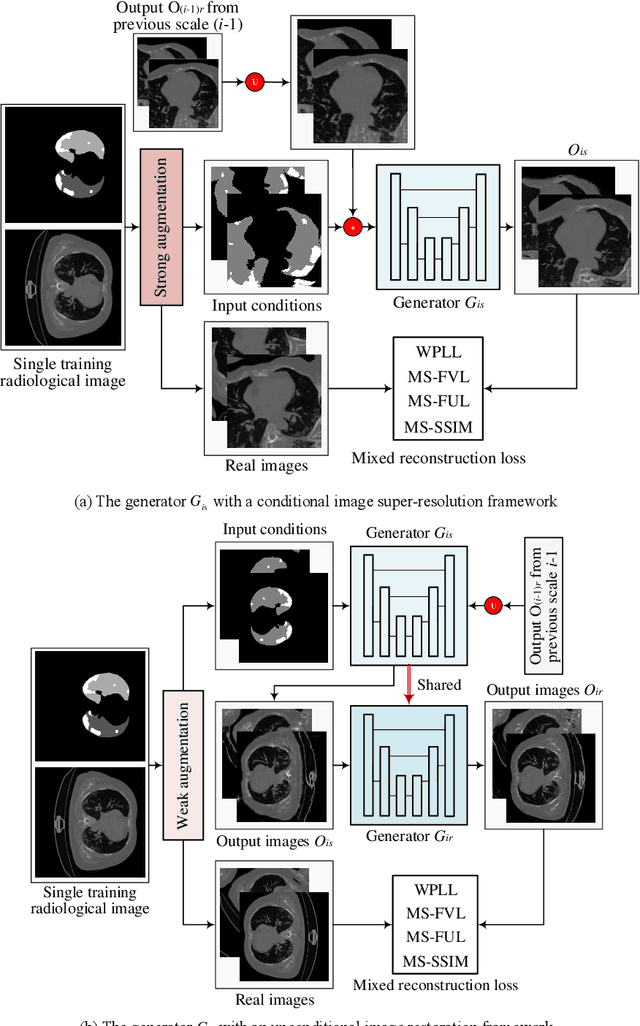
Radiological image is currently adopted as the visual evidence for COVID-19 diagnosis in clinical. Using deep models to realize automated infection measurement and COVID-19 diagnosis is important for faster examination based on radiological imaging. Unfortunately, collecting large training data systematically in the early stage is difficult. To address this problem, we explore the feasibility of learning deep models for COVID-19 diagnosis from a single radiological image by resorting to synthesizing diverse radiological images. Specifically, we propose a novel conditional generative model, called CoSinGAN, which can be learned from a single radiological image with a given condition, i.e., the annotations of the lung and COVID-19 infection. Our CoSinGAN is able to capture the conditional distribution of visual finds of COVID-19 infection, and further synthesize diverse and high-resolution radiological images that match the input conditions precisely. Both deep classification and segmentation networks trained on synthesized samples from CoSinGAN achieve notable detection accuracy of COVID-19 infection. Such results are significantly better than the counterparts trained on the same extremely small number of real samples (1 or 2 real samples) by using strong data augmentation, and approximate to the counterparts trained on large dataset (2846 real images). It confirms our method can significantly reduce the performance gap between deep models trained on extremely small dataset and on large dataset, and thus has the potential to realize learning COVID-19 diagnosis from few radiological images in the early stage of COVID-19 pandemic. Our codes are made publicly available at https://github.com/PengyiZhang/CoSinGAN.