 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DVHN: A Deep Hashing Framework for Large-scale Vehicle Re-identification
Dec 09, 2021
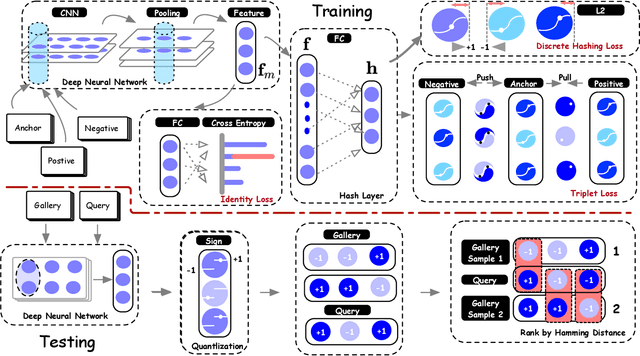
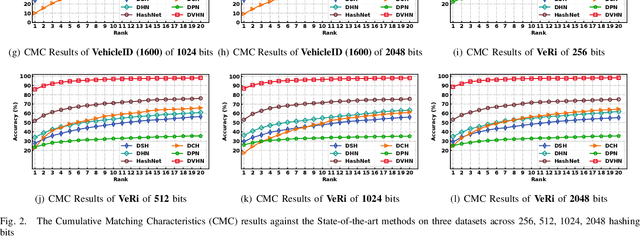
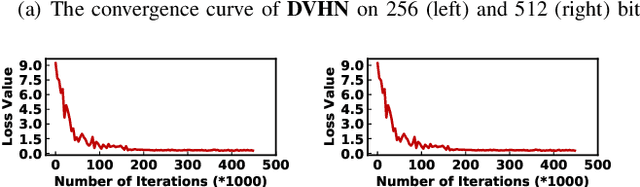
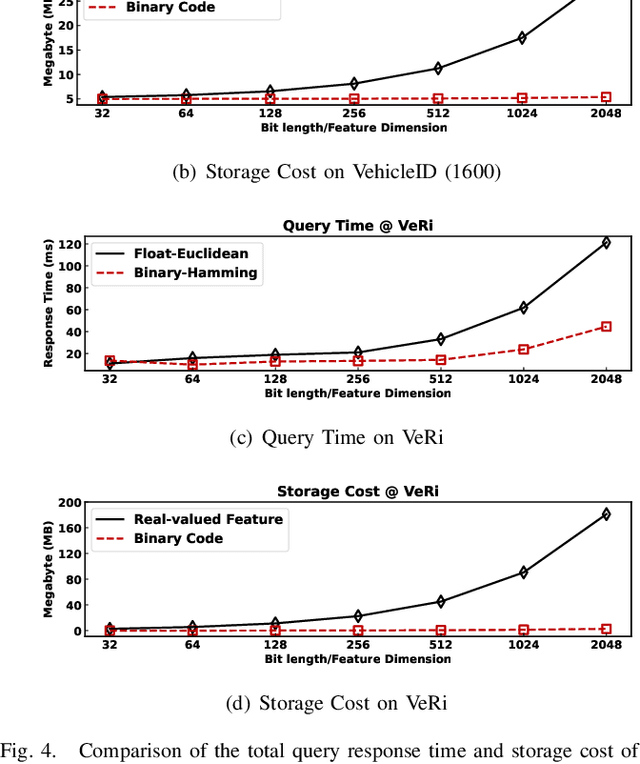
In this paper, we make the very first attempt to investigate the integration of deep hash learning with vehicle re-identification. We propose a deep hash-based vehicle re-identification framework, dubbed DVHN, which substantially reduces memory usage and promotes retrieval efficiency while reserving nearest neighbor search accuracy. Concretely,~DVHN directly learns discrete compact binary hash codes for each image by jointly optimizing the feature learning network and the hash code generating module. Specifically, we directly constrain the output from the convolutional neural network to be discrete binary codes and ensure the learned binary codes are optimal for classification. To optimize the deep discrete hashing framework, we further propose an alternating minimization method for learning binary similarity-preserved hashing codes. Extensive experiments on two widely-studied vehicle re-identification datasets- \textbf{VehicleID} and \textbf{VeRi}-~have demonstrated the superiority of our method against the state-of-the-art deep hash methods. \textbf{DVHN} of $2048$ bits can achieve 13.94\% and 10.21\% accuracy improvement in terms of \textbf{mAP} and \textbf{Rank@1} for \textbf{VehicleID (800)} dataset. For \textbf{VeRi}, we achieve 35.45\% and 32.72\% performance gains for \textbf{Rank@1} and \textbf{mAP}, respectively.
IGAN: Inferent and Generative Adversarial Networks
Sep 27, 2021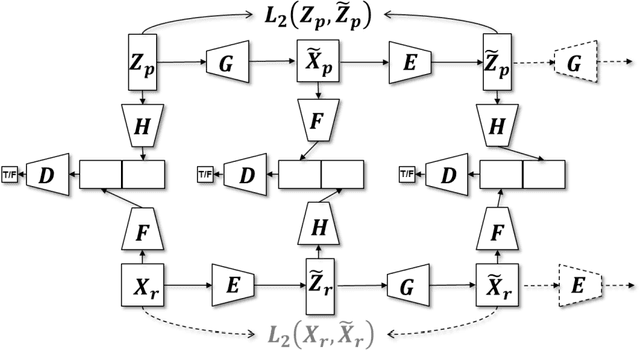


I present IGAN (Inferent Generative Adversarial Networks), a neural architecture that learns both a generative and an inference model on a complex high dimensional data distribution, i.e. a bidirectional mapping between data samples and a simpler low-dimensional latent space. It extends the traditional GAN framework with inference by rewriting the adversarial strategy in both the image and the latent space with an entangled game between data-latent encoded posteriors and priors. It brings a measurable stability and convergence to the classical GAN scheme, while keeping its generative quality and remaining simple and frugal in order to run on a lab PC. IGAN fosters the encoded latents to span the full prior space: this enables the exploitation of an enlarged and self-organised latent space in an unsupervised manner. An analysis of previously published articles sets the theoretical ground for the proposed algorithm. A qualitative demonstration of potential applications like self-supervision or multi-modal data translation is given on common image datasets including SAR and optical imagery.
Salient Object Detection by LTP Texture Characterization on Opposing Color Pairs under SLICO Superpixel Constraint
Jan 03, 2022
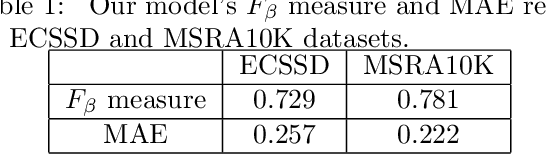
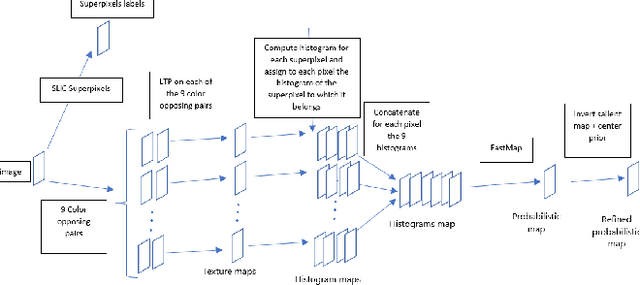

The effortless detection of salient objects by humans has been the subject of research in several fields, including computer vision as it has many applications. However, salient object detection remains a challenge for many computer models dealing with color and textured images. Herein, we propose a novel and efficient strategy, through a simple model, almost without internal parameters, which generates a robust saliency map for a natural image. This strategy consists of integrating color information into local textural patterns to characterize a color micro-texture. Most models in the literature that use the color and texture features treat them separately. In our case, it is the simple, yet powerful LTP (Local Ternary Patterns) texture descriptor applied to opposing color pairs of a color space that allows us to achieve this end. Each color micro-texture is represented by vector whose components are from a superpixel obtained by SLICO (Simple Linear Iterative Clustering with zero parameter) algorithm which is simple, fast and exhibits state-of-the-art boundary adherence. The degree of dissimilarity between each pair of color micro-texture is computed by the FastMap method, a fast version of MDS (Multi-dimensional Scaling), that considers the color micro-textures non-linearity while preserving their distances. These degrees of dissimilarity give us an intermediate saliency map for each RGB, HSL, LUV and CMY color spaces. The final saliency map is their combination to take advantage of the strength of each of them. The MAE (Mean Absolute Error) and F$_{\beta}$ measures of our saliency maps, on the complex ECSSD dataset show that our model is both simple and efficient, outperforming several state-of-the-art models.
1st Place Solutions for UG2+ Challenge 2021 -- (Semi-)supervised Face detection in the low light condition
Jul 02, 2021

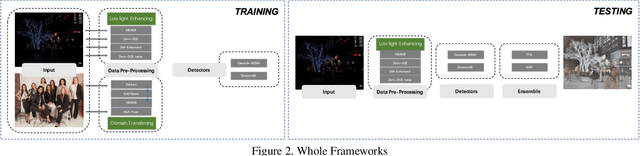

In this technical report, we briefly introduce the solution of our team "TAL-ai" for (Semi-) supervised Face detection in the low light condition in UG2+ Challenge in CVPR 2021. By conducting several experiments with popular image enhancement methods and image transfer methods, we pulled the low light image and the normal image to a more closer domain. And it is observed that using these data to training can achieve better performance. We also adapt several popular object detection frameworks, e.g., DetectoRS, Cascade-RCNN, and large backbone like Swin-transformer. Finally, we ensemble several models which achieved mAP 74.89 on the testing set, ranking 1st on the final leaderboard.
UFPMP-Det: Toward Accurate and Efficient Object Detection on Drone Imagery
Dec 20, 2021
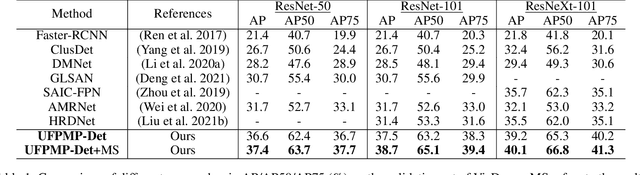
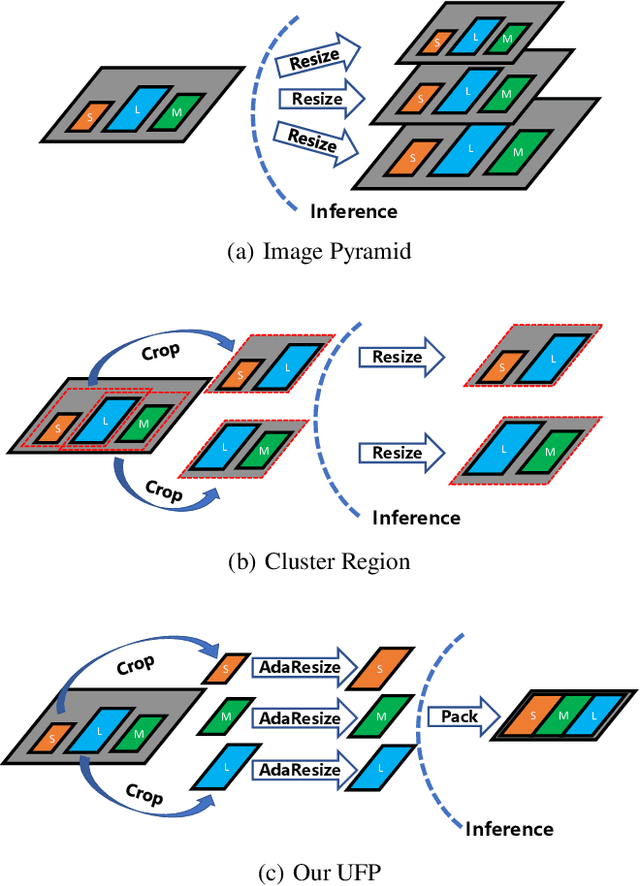
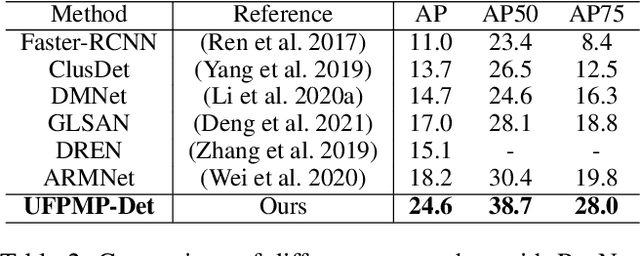
This paper proposes a novel approach to object detection on drone imagery, namely Multi-Proxy Detection Network with Unified Foreground Packing (UFPMP-Det). To deal with the numerous instances of very small scales, different from the common solution that divides the high-resolution input image into quite a number of chips with low foreground ratios to perform detection on them each, the Unified Foreground Packing (UFP) module is designed, where the sub-regions given by a coarse detector are initially merged through clustering to suppress background and the resulting ones are subsequently packed into a mosaic for a single inference, thus significantly reducing overall time cost. Furthermore, to address the more serious confusion between inter-class similarities and intra-class variations of instances, which deteriorates detection performance but is rarely discussed, the Multi-Proxy Detection Network (MP-Det) is presented to model object distributions in a fine-grained manner by employing multiple proxy learning, and the proxies are enforced to be diverse by minimizing a Bag-of-Instance-Words (BoIW) guided optimal transport loss. By such means, UFPMP-Det largely promotes both the detection accuracy and efficiency. Extensive experiments are carried out on the widely used VisDrone and UAVDT datasets, and UFPMP-Det reports new state-of-the-art scores at a much higher speed, highlighting its advantages.
Sensing Anomalies as Potential Hazards: Datasets and Benchmarks
Oct 27, 2021

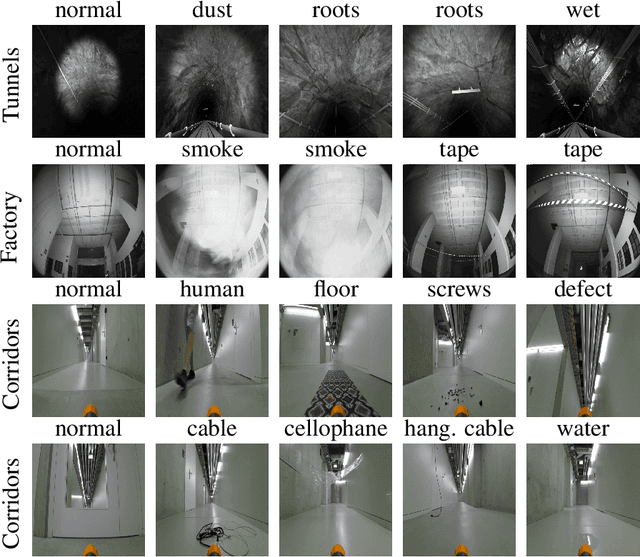
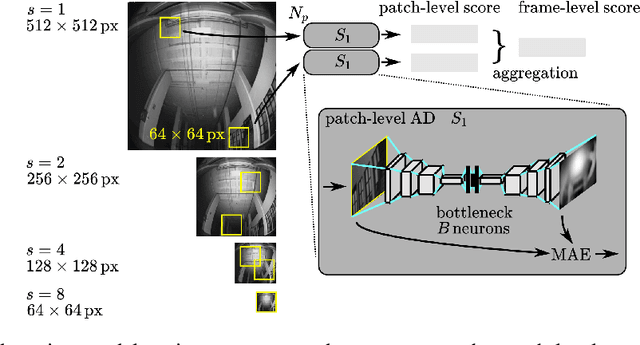
We consider the problem of detecting, in the visual sensing data stream of an autonomous mobile robot, semantic patterns that are unusual (i.e., anomalous) with respect to the robot's previous experience in similar environments. These anomalies might indicate unforeseen hazards and, in scenarios where failure is costly, can be used to trigger an avoidance behavior. We contribute three novel image-based datasets acquired in robot exploration scenarios, comprising a total of more than 200k labeled frames, spanning various types of anomalies. On these datasets, we study the performance of an anomaly detection approach based on autoencoders operating at different scales.
LipSound2: Self-Supervised Pre-Training for Lip-to-Speech Reconstruction and Lip Reading
Dec 09, 2021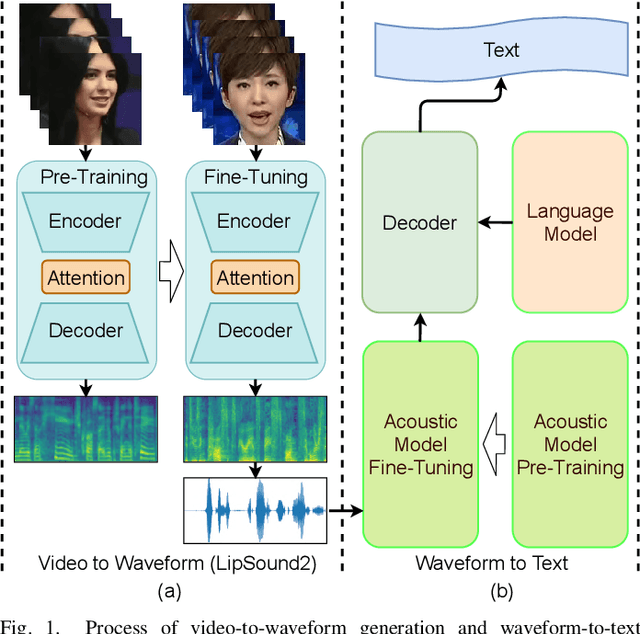
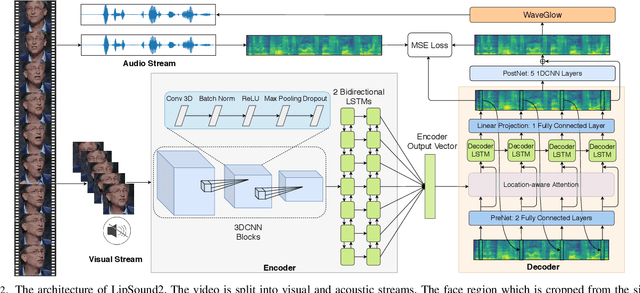
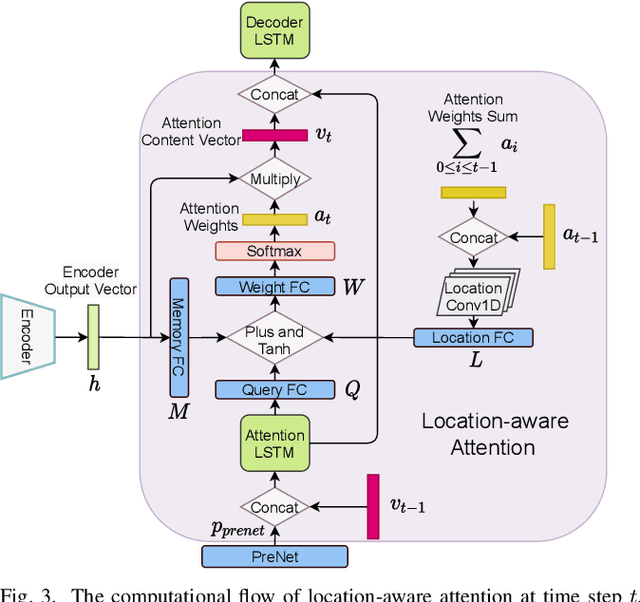

The aim of this work is to investigate the impact of crossmodal self-supervised pre-training for speech reconstruction (video-to-audio) by leveraging the natural co-occurrence of audio and visual streams in videos. We propose LipSound2 which consists of an encoder-decoder architecture and location-aware attention mechanism to map face image sequences to mel-scale spectrograms directly without requiring any human annotations. The proposed LipSound2 model is firstly pre-trained on $\sim$2400h multi-lingual (e.g. English and German) audio-visual data (VoxCeleb2). To verify the generalizability of the proposed method, we then fine-tune the pre-trained model on domain-specific datasets (GRID, TCD-TIMIT) for English speech reconstruction and achieve a significant improvement on speech quality and intelligibility compared to previous approaches in speaker-dependent and -independent settings. In addition to English, we conduct Chinese speech reconstruction on the CMLR dataset to verify the impact on transferability. Lastly, we train the cascaded lip reading (video-to-text) system by fine-tuning the generated audios on a pre-trained speech recognition system and achieve state-of-the-art performance on both English and Chinese benchmark datasets.
Improved Model based Deep Learning using Monotone Operator Learning (MOL)
Nov 22, 2021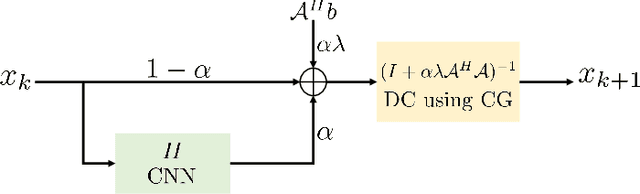
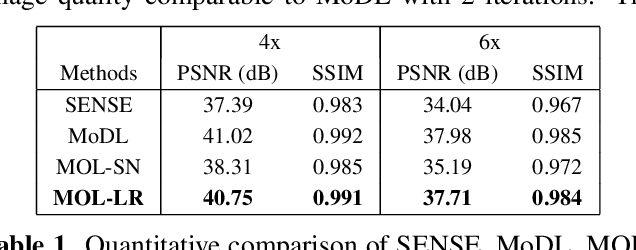
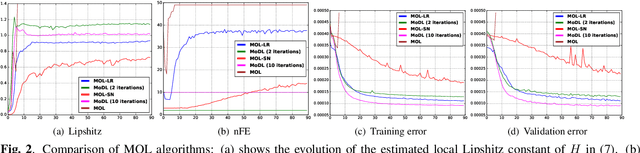
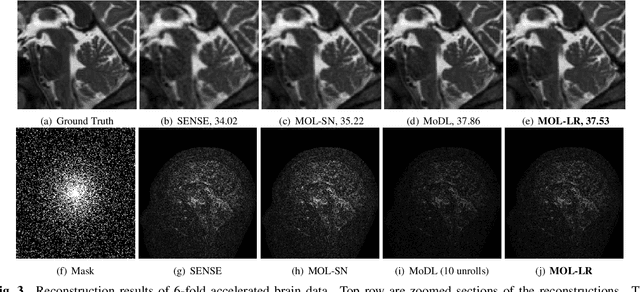
Model-based deep learning (MoDL) algorithms that rely on unrolling are emerging as powerful tools for image recovery. In this work, we introduce a novel monotone operator learning framework to overcome some of the challenges associated with current unrolled frameworks, including high memory cost, lack of guarantees on robustness to perturbations, and low interpretability. Unlike current unrolled architectures that use finite number of iterations, we use the deep equilibrium (DEQ) framework to iterate the algorithm to convergence and to evaluate the gradient of the convolutional neural network blocks using Jacobian iterations. This approach significantly reduces the memory demand, facilitating the extension of MoDL algorithms to high dimensional problems. We constrain the CNN to be a monotone operator, which allows us to introduce algorithms with guaranteed convergence properties and robustness guarantees. We demonstrate the utility of the proposed scheme in the context of parallel MRI.
Data Invariants to Understand Unsupervised Out-of-Distribution Detection
Nov 26, 2021

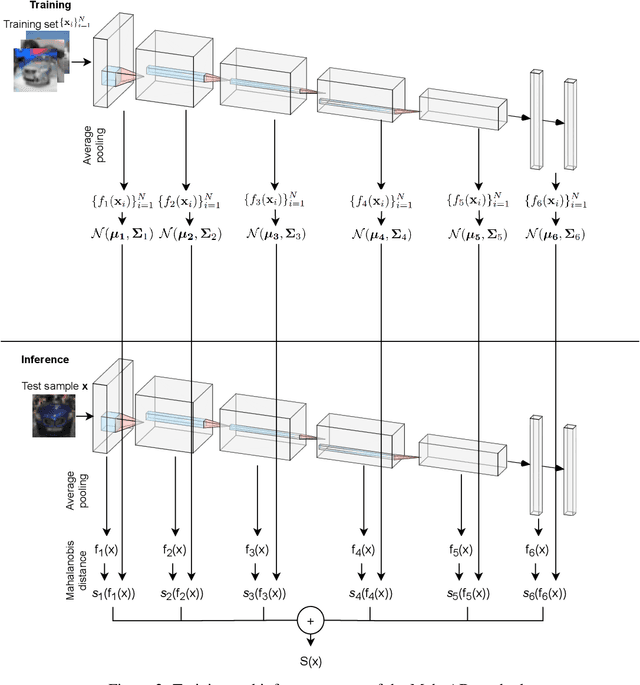
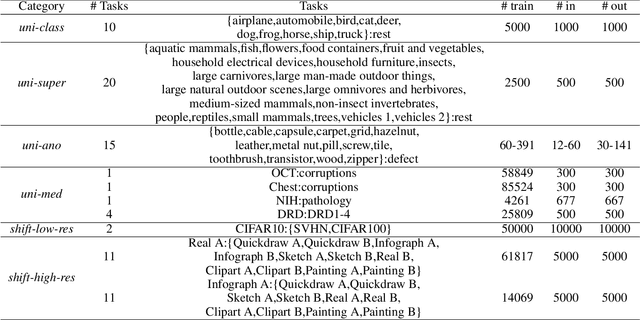
Unsupervised out-of-distribution (U-OOD) detection has recently attracted much attention due its importance in mission-critical systems and broader applicability over its supervised counterpart. Despite this increase in attention, U-OOD methods suffer from important shortcomings. By performing a large-scale evaluation on different benchmarks and image modalities, we show in this work that most popular state-of-the-art methods are unable to consistently outperform a simple and relatively unknown anomaly detector based on the Mahalanobis distance (MahaAD). A key reason for the inconsistencies of these methods is the lack of a formal description of U-OOD. Motivated by a simple thought experiment, we propose a characterization of U-OOD based on the invariants of the training dataset. We show how this characterization is unknowingly embodied in the top-scoring MahaAD method, thereby explaining its quality. Furthermore, our approach can be used to interpret predictions of U-OOD detectors and provides insights into good practices for evaluating future U-OOD methods.
Enabling Image Recognition on Constrained Devices Using Neural Network Pruning and a CycleGAN
Sep 11, 2020


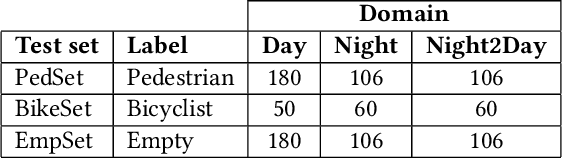
Smart cameras are increasingly used in surveillance solutions in public spaces. Contemporary computer vision applications can be used to recognize events that require intervention by emergency services. Smart cameras can be mounted in locations where citizens feel particularly unsafe, e.g., pathways and underpasses with a history of incidents. One promising approach for smart cameras is edge AI, i.e., deploying AI technology on IoT devices. However, implementing resource-demanding technology such as image recognition using deep neural networks (DNN) on constrained devices is a substantial challenge. In this paper, we explore two approaches to reduce the need for compute in contemporary image recognition in an underpass. First, we showcase successful neural network pruning, i.e., we retain comparable classification accuracy with only 1.1\% of the neurons remaining from the state-of-the-art DNN architecture. Second, we demonstrate how a CycleGAN can be used to transform out-of-distribution images to the operational design domain. We posit that both pruning and CycleGANs are promising enablers for efficient edge AI in smart cameras.