 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DRIT++: Diverse Image-to-Image Translation via Disentangled Representations
May 02, 2019

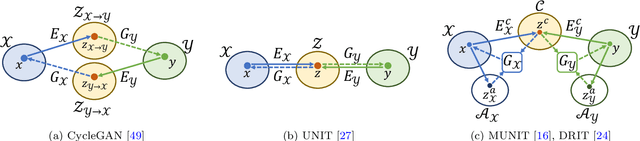
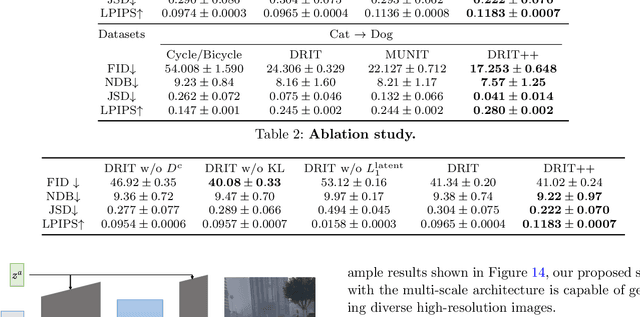
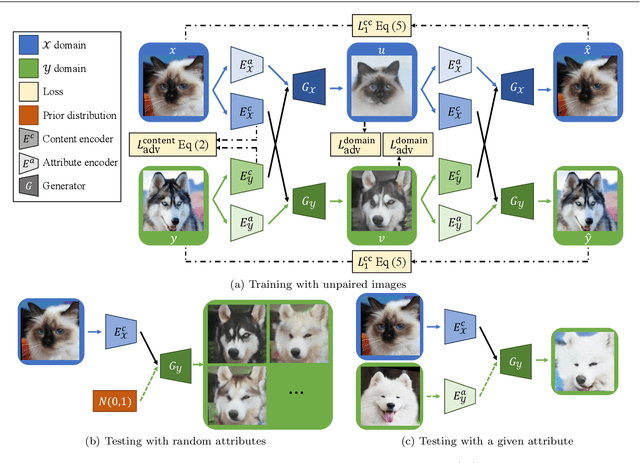
Image-to-image translation aims to learn the mapping between two visual domains. There are two main challenges for this task: 1) lack of aligned training pairs and 2) multiple possible outputs from a single input image. In this work, we present an approach based on disentangled representation for generating diverse outputs without paired training images. To synthesize diverse outputs, we propose to embed images onto two spaces: a domain-invariant content space capturing shared information across domains and a domain-specific attribute space. Our model takes the encoded content features extracted from a given input and attribute vectors sampled from the attribute space to synthesize diverse outputs at test time. To handle unpaired training data, we introduce a cross-cycle consistency loss based on disentangled representations. Qualitative results show that our model can generate diverse and realistic images on a wide range of tasks without paired training data. For quantitative evaluations, we measure realism with user study and Fr\'{e}chet inception distance, and measure diversity with the perceptual distance metric, Jensen-Shannon divergence, and number of statistically-different bins.
An Auto-Encoder Strategy for Adaptive Image Segmentation
Apr 29, 2020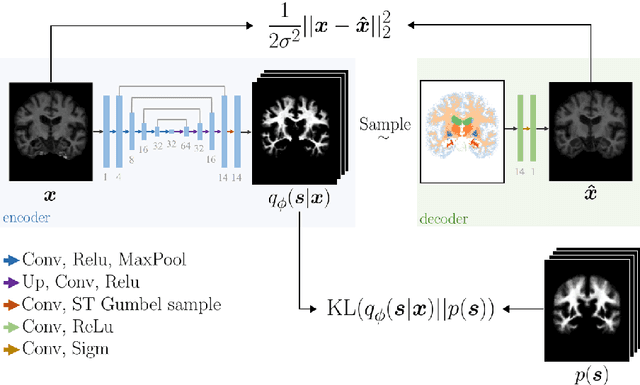
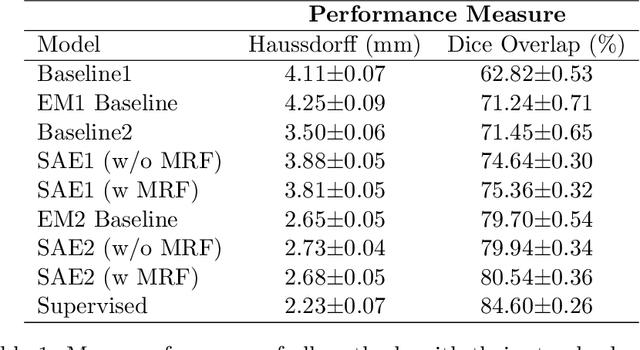
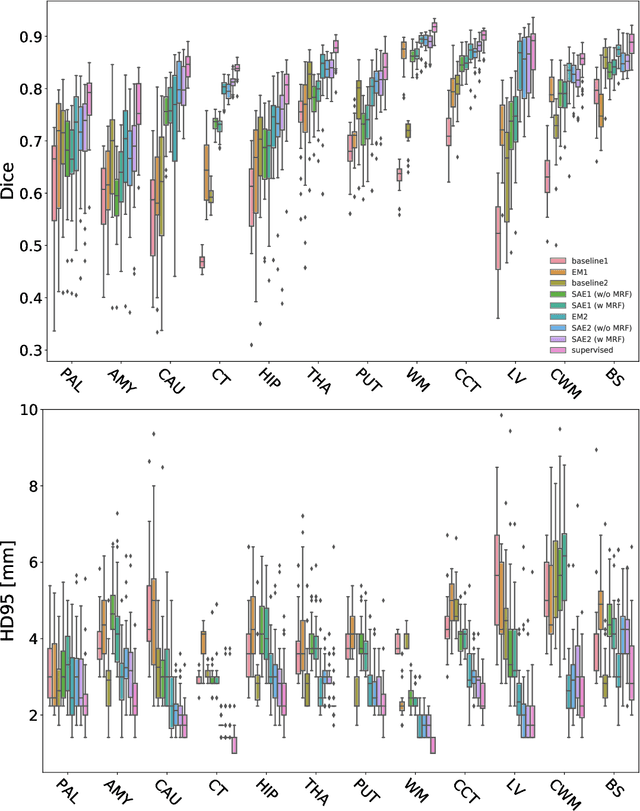
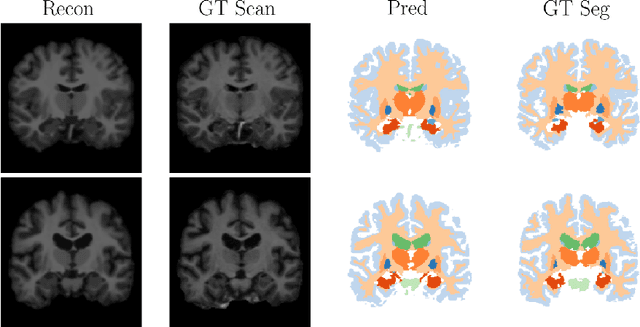
Deep neural networks are powerful tools for biomedical image segmentation. These models are often trained with heavy supervision, relying on pairs of images and corresponding voxel-level labels. However, obtaining segmentations of anatomical regions on a large number of cases can be prohibitively expensive. Thus there is a strong need for deep learning-based segmentation tools that do not require heavy supervision and can continuously adapt. In this paper, we propose a novel perspective of segmentation as a discrete representation learning problem, and present a variational autoencoder segmentation strategy that is flexible and adaptive. Our method, called Segmentation Auto-Encoder (SAE), leverages all available unlabeled scans and merely requires a segmentation prior, which can be a single unpaired segmentation image. In experiments, we apply SAE to brain MRI scans. Our results show that SAE can produce good quality segmentations, particularly when the prior is good. We demonstrate that a Markov Random Field prior can yield significantly better results than a spatially independent prior. Our code is freely available at https://github.com/evanmy/sae.
Efficient Blind-Spot Neural Network Architecture for Image Denoising
Aug 25, 2020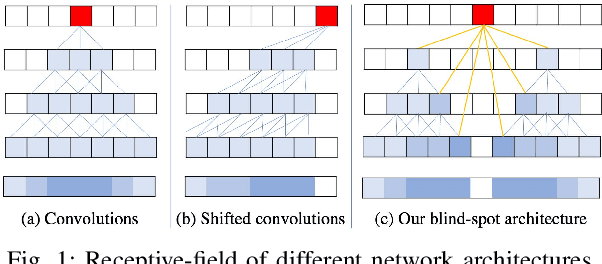
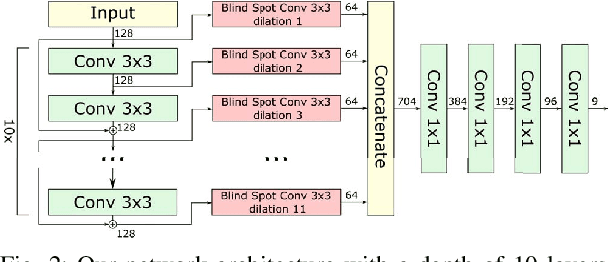
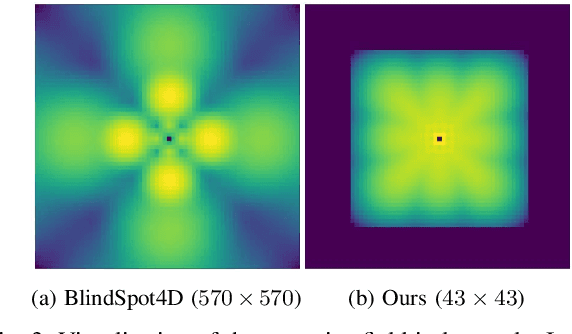
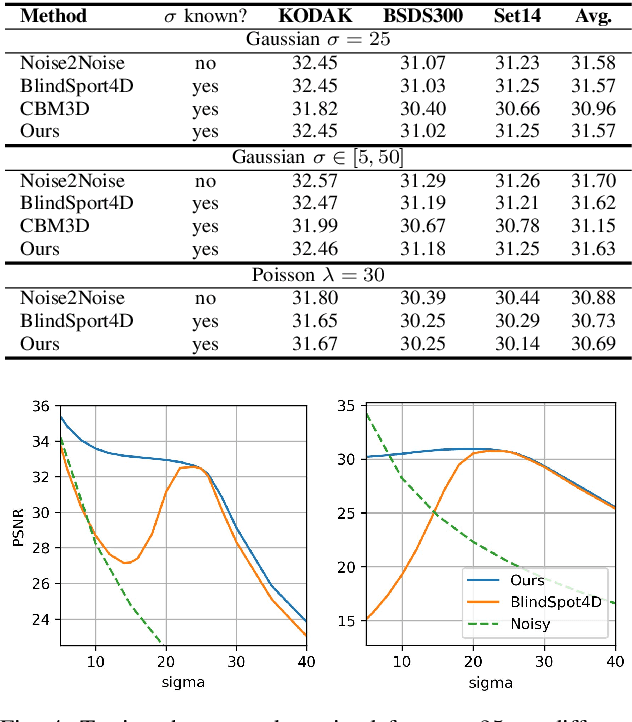
Image denoising is an essential tool in computational photography. Standard denoising techniques, which use deep neural networks at their core, require pairs of clean and noisy images for its training. If we do not possess the clean samples, we can use blind-spot neural network architectures, which estimate the pixel value based on the neighbouring pixels only. These networks thus allow training on noisy images directly, as they by-design avoid trivial solutions. Nowadays, the blind-spot is mostly achieved using shifted convolutions or serialization. We propose a novel fully convolutional network architecture that uses dilations to achieve the blind-spot property. Our network improves the performance over the prior work and achieves state-of-the-art results on established datasets.
Rethinking Image Mixture for Unsupervised Visual Representation Learning
Mar 11, 2020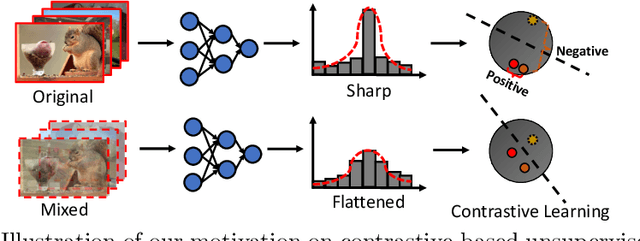


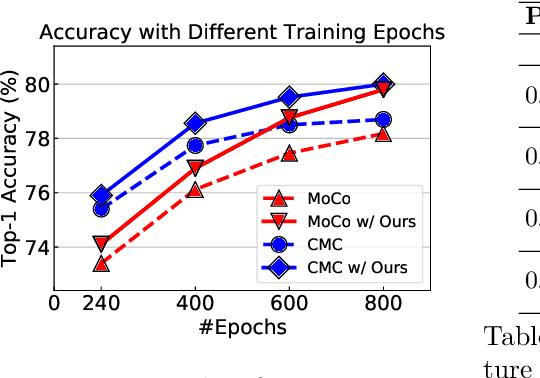
In supervised learning, smoothing label/prediction distribution in neural network training has been proven useful in preventing the model from being over-confident, and is crucial for learning more robust visual representations. This observation motivates us to explore the way to make predictions flattened in unsupervised learning. Considering that human annotated labels are not adopted in unsupervised learning, we introduce a straightforward approach to perturb input image space in order to soften the output prediction space indirectly. Despite its conceptual simplicity, we show empirically that with the simple solution -- image mixture, we can learn more robust visual representations from the transformed input, and the benefits of representations learned from this space can be inherited by the linear classification and downstream tasks.
Crossing the Format Boundary of Text and Boxes: Towards Unified Vision-Language Modeling
Nov 23, 2021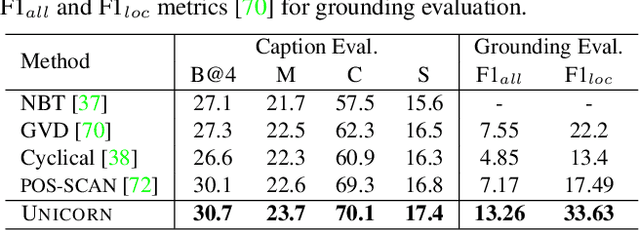
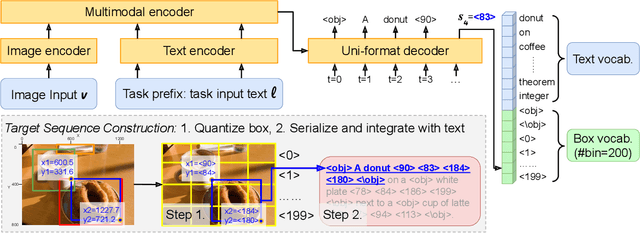
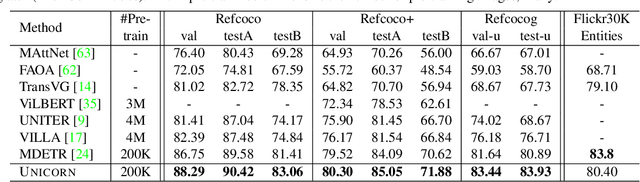
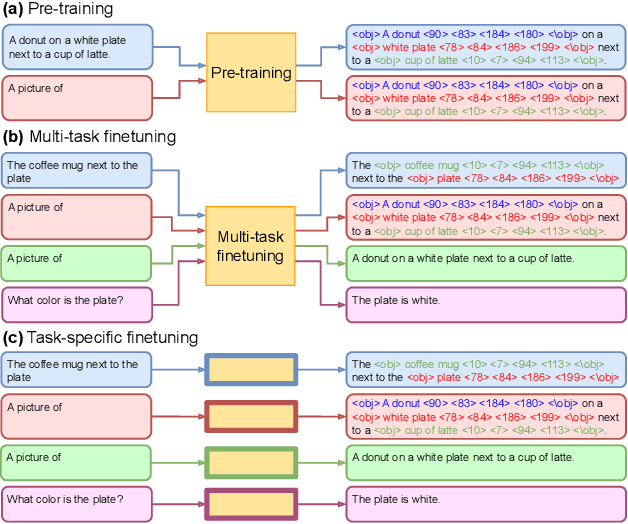
In this paper, we propose UNICORN, a vision-language (VL) model that unifies text generation and bounding box prediction into a single architecture. Specifically, we quantize each box into four discrete box tokens and serialize them as a sequence, which can be integrated with text tokens. We formulate all VL problems as a generation task, where the target sequence consists of the integrated text and box tokens. We then train a transformer encoder-decoder to predict the target in an auto-regressive manner. With such a unified framework and input-output format, UNICORN achieves comparable performance to task-specific state of the art on 7 VL benchmarks, covering the visual grounding, grounded captioning, visual question answering, and image captioning tasks. When trained with multi-task finetuning, UNICORN can approach different VL tasks with a single set of parameters, thus crossing downstream task boundary. We show that having a single model not only saves parameters, but also further boosts the model performance on certain tasks. Finally, UNICORN shows the capability of generalizing to new tasks such as ImageNet object localization.
Random Network Distillation as a Diversity Metric for Both Image and Text Generation
Oct 13, 2020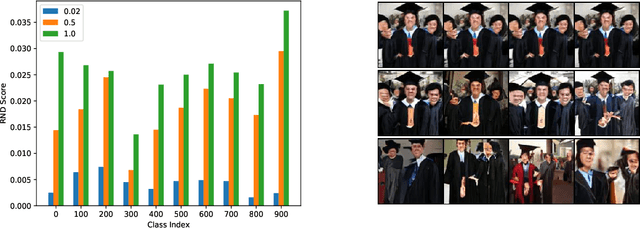
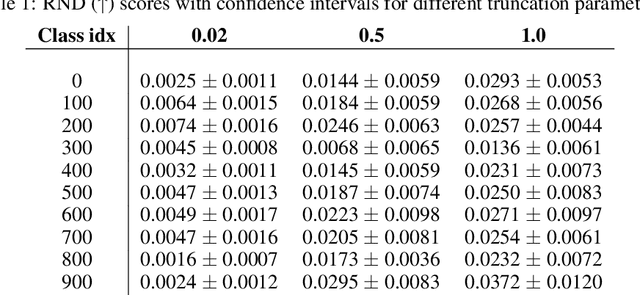
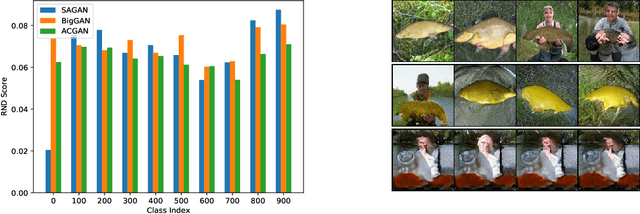
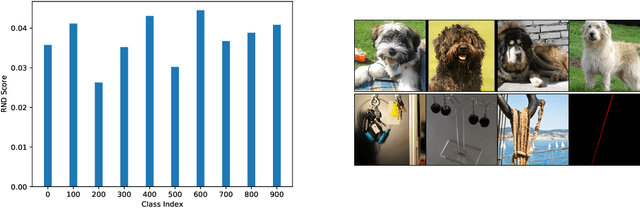
Generative models are increasingly able to produce remarkably high quality images and text. The community has developed numerous evaluation metrics for comparing generative models. However, these metrics do not effectively quantify data diversity. We develop a new diversity metric that can readily be applied to data, both synthetic and natural, of any type. Our method employs random network distillation, a technique introduced in reinforcement learning. We validate and deploy this metric on both images and text. We further explore diversity in few-shot image generation, a setting which was previously difficult to evaluate.
Statistical Dependency Guided Contrastive Learning for Multiple Labeling in Prenatal Ultrasound
Aug 11, 2021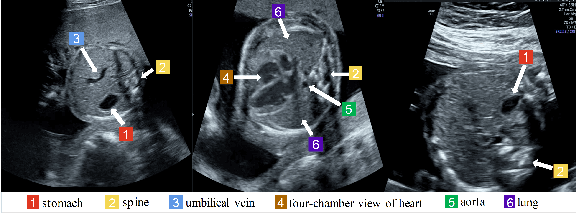
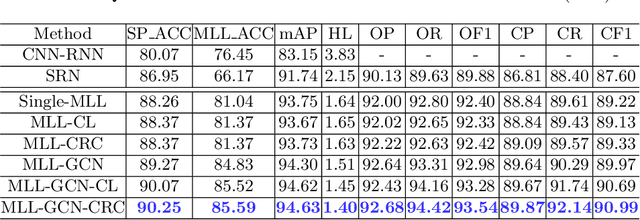
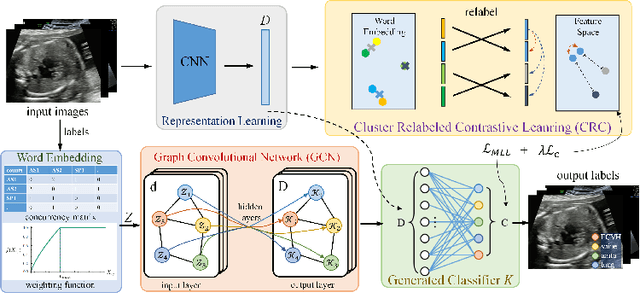
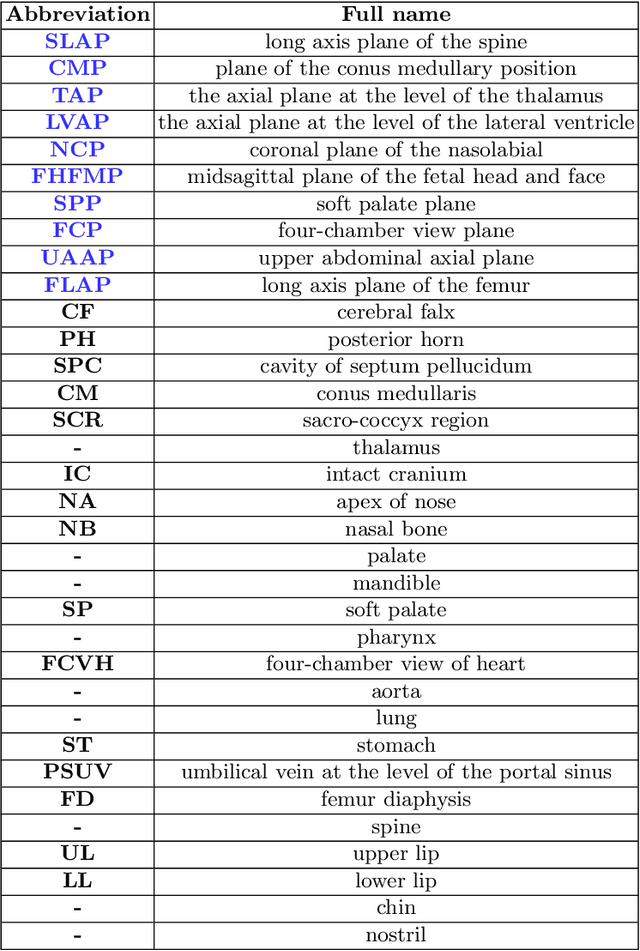
Standard plane recognition plays an important role in prenatal ultrasound (US) screening. Automatically recognizing the standard plane along with the corresponding anatomical structures in US image can not only facilitate US image interpretation but also improve diagnostic efficiency. In this study, we build a novel multi-label learning (MLL) scheme to identify multiple standard planes and corresponding anatomical structures of fetus simultaneously. Our contribution is three-fold. First, we represent the class correlation by word embeddings to capture the fine-grained semantic and latent statistical concurrency. Second, we equip the MLL with a graph convolutional network to explore the inner and outer relationship among categories. Third, we propose a novel cluster relabel-based contrastive learning algorithm to encourage the divergence among ambiguous classes. Extensive validation was performed on our large in-house dataset. Our approach reports the highest accuracy as 90.25% for standard planes labeling, 85.59% for planes and structures labeling and mAP as 94.63%. The proposed MLL scheme provides a novel perspective for standard plane recognition and can be easily extended to other medical image classification tasks.
Learning Diagnosis of COVID-19 from a Single Radiological Image
Jun 06, 2020
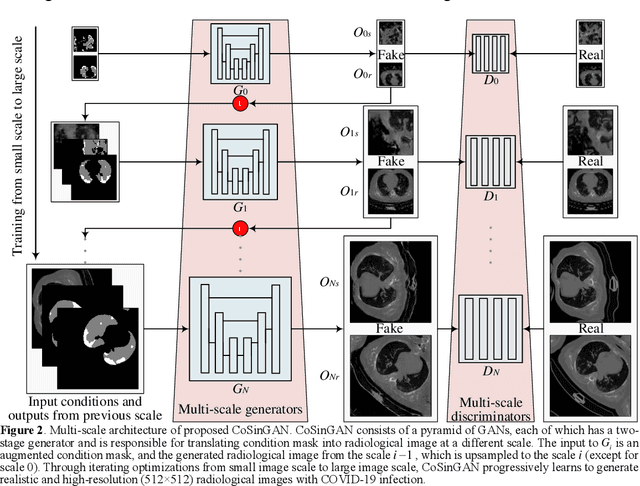
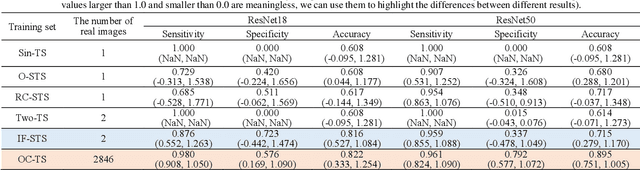
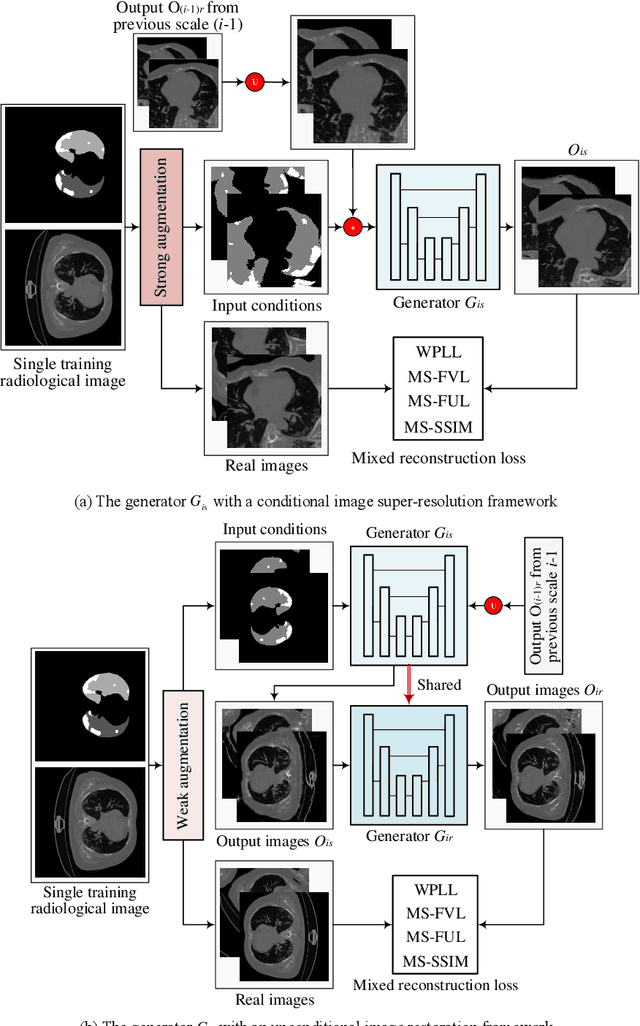
Radiological image is currently adopted as the visual evidence for COVID-19 diagnosis in clinical. Using deep models to realize automated infection measurement and COVID-19 diagnosis is important for faster examination based on radiological imaging. Unfortunately, collecting large training data systematically in the early stage is difficult. To address this problem, we explore the feasibility of learning deep models for COVID-19 diagnosis from a single radiological image by resorting to synthesizing diverse radiological images. Specifically, we propose a novel conditional generative model, called CoSinGAN, which can be learned from a single radiological image with a given condition, i.e., the annotations of the lung and COVID-19 infection. Our CoSinGAN is able to capture the conditional distribution of visual finds of COVID-19 infection, and further synthesize diverse and high-resolution radiological images that match the input conditions precisely. Both deep classification and segmentation networks trained on synthesized samples from CoSinGAN achieve notable detection accuracy of COVID-19 infection. Such results are significantly better than the counterparts trained on the same extremely small number of real samples (1 or 2 real samples) by using strong data augmentation, and approximate to the counterparts trained on large dataset (2846 real images). It confirms our method can significantly reduce the performance gap between deep models trained on extremely small dataset and on large dataset, and thus has the potential to realize learning COVID-19 diagnosis from few radiological images in the early stage of COVID-19 pandemic. Our codes are made publicly available at https://github.com/PengyiZhang/CoSinGAN.
Deep Learning on Image Denoising: An overview
Dec 31, 2019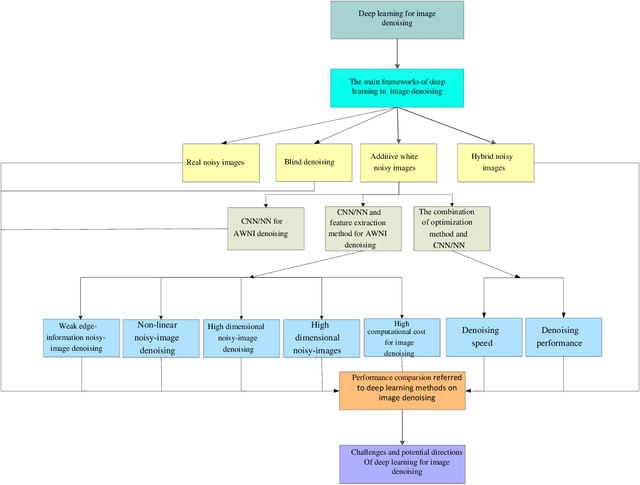
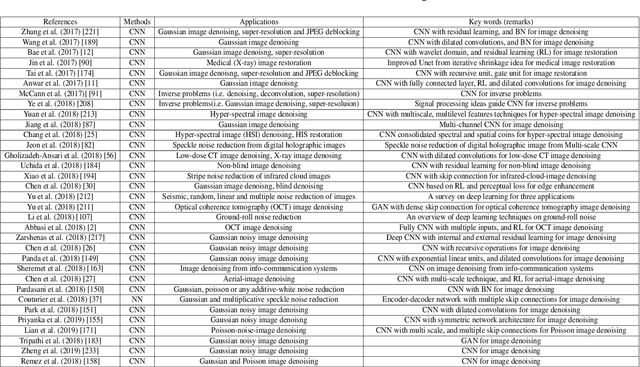
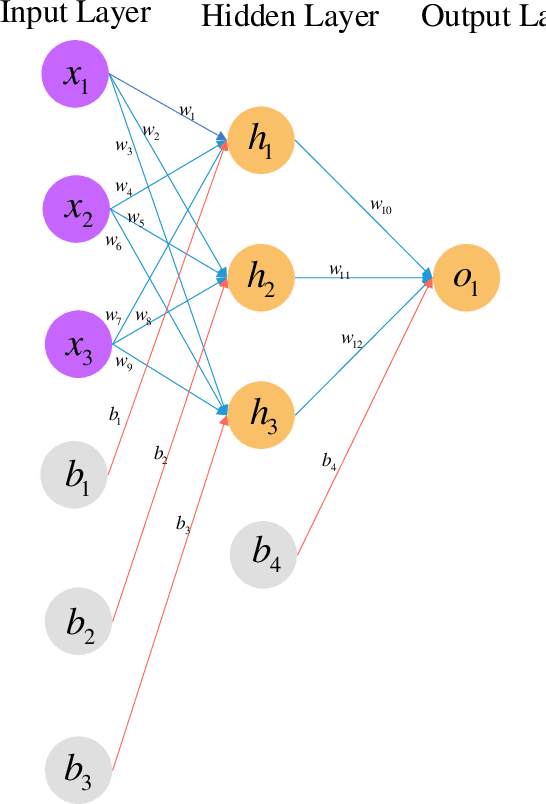
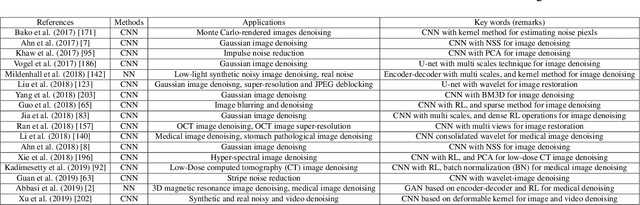
Deep learning techniques have obtained much attention in image denoising. However, deep learning methods of different types deal with the noise have enormous differences. Specifically, discriminative learning based on deep learning can well address the Gaussian noise. Optimization model methods based on deep learning have good effect on estimating of the real noise. So far, there are little related researches to summarize different deep learning techniques for image denoising. In this paper, we make such a comparative study of different deep techniques in image denoising. We first classify the (1) deep convolutional neural networks (CNNs) for additive white noisy images, (2) deep CNNs for real noisy images, (3) deep CNNs for blind denoising and (4) deep CNNs for hybrid noisy images, which is the combination of noisy, blurred and low-resolution images. Then, we analyze the motivations and principles of deep learning methods of different types. Next, we compare and verify the state-of-the-art methods on public denoising datasets in terms of quantitative and qualitative analysis. Finally, we point out some potential challenges and directions of future research.
Don't Generate Me: Training Differentially Private Generative Models with Sinkhorn Divergence
Nov 29, 2021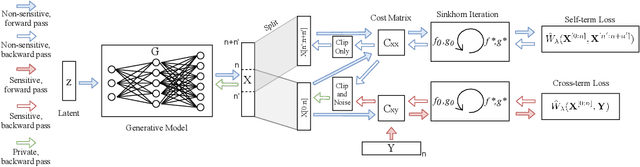
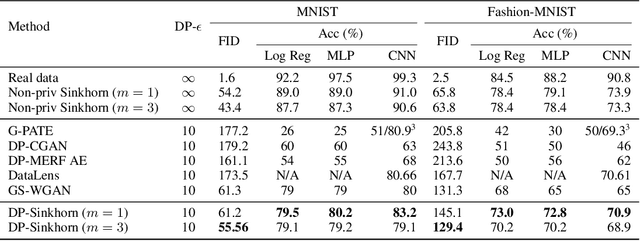

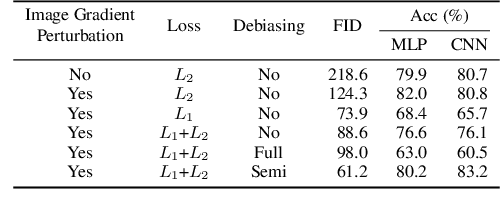
Although machine learning models trained on massive data have led to break-throughs in several areas, their deployment in privacy-sensitive domains remains limited due to restricted access to data. Generative models trained with privacy constraints on private data can sidestep this challenge, providing indirect access to private data instead. We propose DP-Sinkhorn, a novel optimal transport-based generative method for learning data distributions from private data with differential privacy. DP-Sinkhorn minimizes the Sinkhorn divergence, a computationally efficient approximation to the exact optimal transport distance, between the model and data in a differentially private manner and uses a novel technique for control-ling the bias-variance trade-off of gradient estimates. Unlike existing approaches for training differentially private generative models, which are mostly based on generative adversarial networks, we do not rely on adversarial objectives, which are notoriously difficult to optimize, especially in the presence of noise imposed by privacy constraints. Hence, DP-Sinkhorn is easy to train and deploy. Experimentally, we improve upon the state-of-the-art on multiple image modeling benchmarks and show differentially private synthesis of informative RGB images. Project page:https://nv-tlabs.github.io/DP-Sinkhorn.