 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Competing Ratio Loss for Discriminative Multi-class Image Classification
Dec 25, 2019
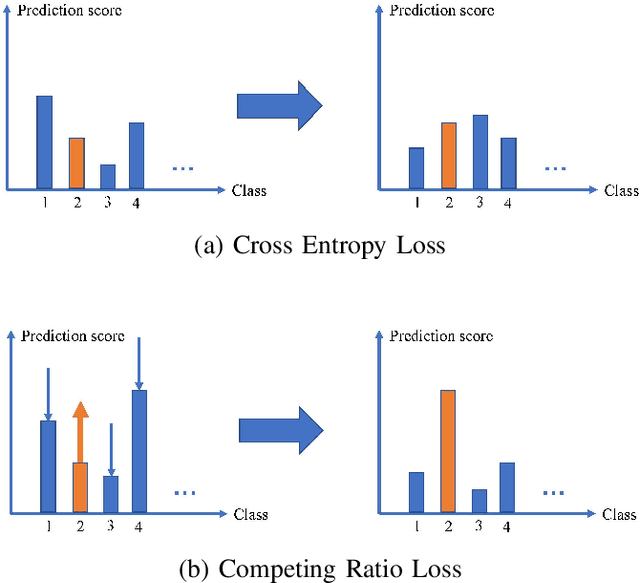
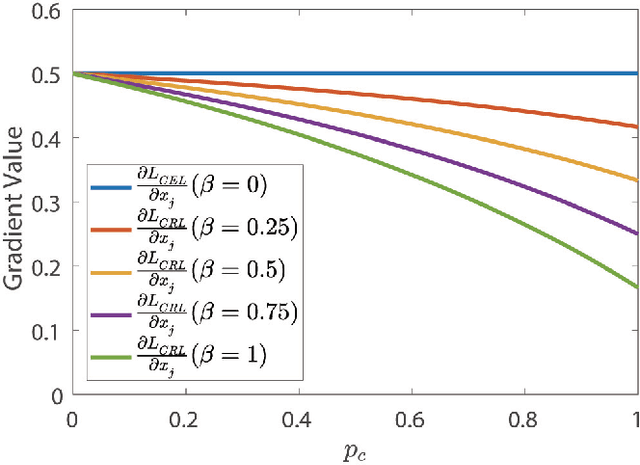
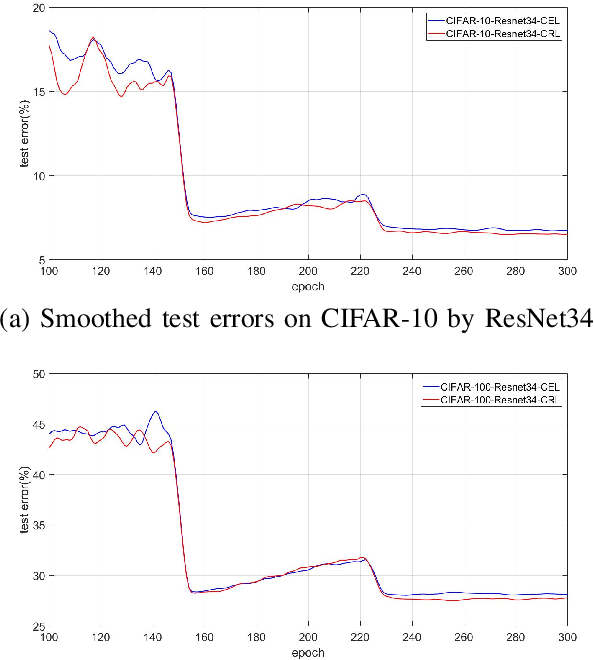

The development of deep convolutional neural network architecture is critical to the improvement of image classification task performance. Many image classification studies use deep convolutional neural network and focus on modifying the network structure to improve image classification performance. Conversely, our study focuses on loss function design. Cross-entropy Loss (CEL) has been widely used for training deep convolutional neural network for the task of multi-class classification. Although CEL has been successfully implemented in several image classification tasks, it only focuses on the posterior probability of the correct class. For this reason, a negative log likelihood ratio loss (NLLR) was proposed to better differentiate between the correct class and the competing incorrect ones. However, during the training of the deep convolutional neural network, the value of NLLR is not always positive or negative, which severely affects the convergence of NLLR. Our proposed competing ratio loss (CRL) calculates the posterior probability ratio between the correct class and the competing incorrect classes to further enlarge the probability difference between the correct and incorrect classes. We added hyperparameters to CRL, thereby ensuring its value to be positive and that the update size of backpropagation is suitable for the CRL's fast convergence. To demonstrate the performance of CRL, we conducted experiments on general image classification tasks (CIFAR10/100, SVHN, ImageNet), the fine-grained image classification tasks (CUB200-2011 and Stanford Car), and the challenging face age estimation task (using Adience). Experimental results show the effectiveness and robustness of the proposed loss function on different deep convolutional neural network architectures and different image classification tasks.
Image Outpainting and Harmonization using Generative Adversarial Networks
Dec 23, 2019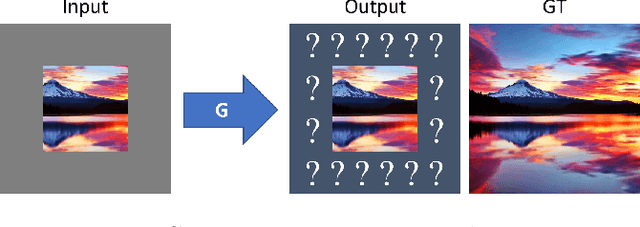



Although the inherently ambiguous task of predicting what resides beyond all four edges of an image has rarely been explored before, we demonstrate that GANs hold powerful potential in producing reasonable extrapolations. Two outpainting methods are proposed that aim to instigate this line of research: the first approach uses a context encoder inspired by common inpainting architectures and paradigms, while the second approach adds an extra post-processing step using a single-image generative model. This way, the hallucinated details are integrated with the style of the original image, in an attempt to further boost the quality of the result and possibly allow for arbitrary output resolutions to be supported.
SGM3D: Stereo Guided Monocular 3D Object Detection
Dec 03, 2021
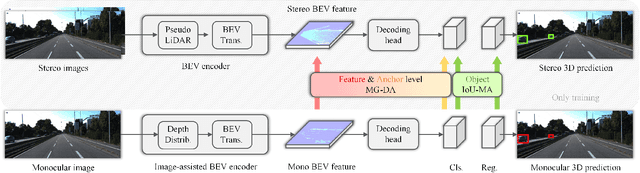
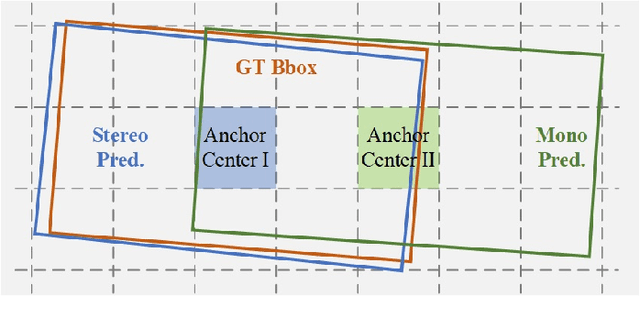

Monocular 3D object detection is a critical yet challenging task for autonomous driving, due to the lack of accurate depth information captured by LiDAR sensors. In this paper, we propose a stereo-guided monocular 3D object detection network, termed SGM3D, which leverages robust 3D features extracted from stereo images to enhance the features learned from the monocular image. We innovatively investigate a multi-granularity domain adaptation module (MG-DA) to exploit the network's ability so as to generate stereo-mimic features only based on the monocular cues. The coarse BEV feature-level, as well as the fine anchor-level domain adaptation, are leveraged to guide the monocular branch. We present an IoU matching-based alignment module (IoU-MA) for object-level domain adaptation between the stereo and monocular predictions to alleviate the mismatches in previous stages. We conduct extensive experiments on the most challenging KITTI and Lyft datasets and achieve new state-of-the-art performance. Furthermore, our method can be integrated into many other monocular approaches to boost performance without introducing any extra computational cost.
Mask Transfiner for High-Quality Instance Segmentation
Nov 26, 2021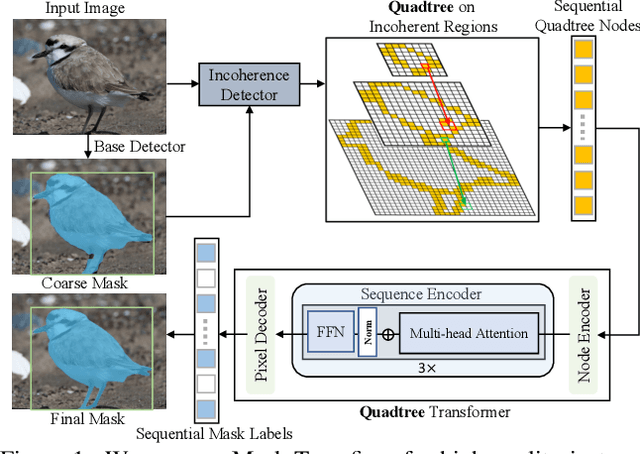


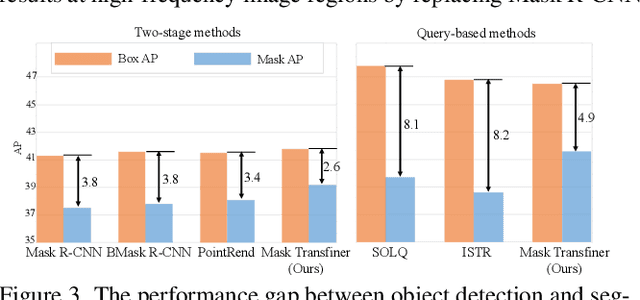
Two-stage and query-based instance segmentation methods have achieved remarkable results. However, their segmented masks are still very coarse. In this paper, we present Mask Transfiner for high-quality and efficient instance segmentation. Instead of operating on regular dense tensors, our Mask Transfiner decomposes and represents the image regions as a quadtree. Our transformer-based approach only processes detected error-prone tree nodes and self-corrects their errors in parallel. While these sparse pixels only constitute a small proportion of the total number, they are critical to the final mask quality. This allows Mask Transfiner to predict highly accurate instance masks, at a low computational cost. Extensive experiments demonstrate that Mask Transfiner outperforms current instance segmentation methods on three popular benchmarks, significantly improving both two-stage and query-based frameworks by a large margin of +3.0 mask AP on COCO and BDD100K, and +6.6 boundary AP on Cityscapes. Our code and trained models will be available at http://vis.xyz/pub/transfiner.
Latent Space Smoothing for Individually Fair Representations
Nov 26, 2021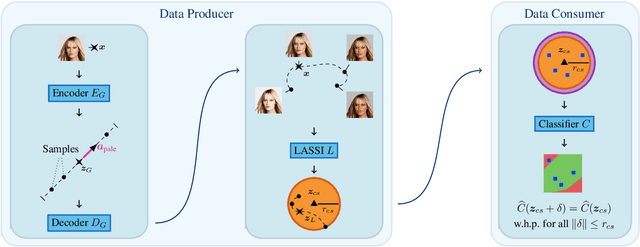
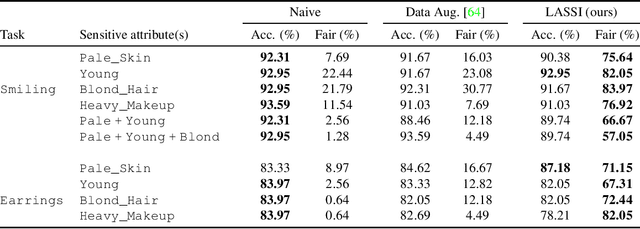
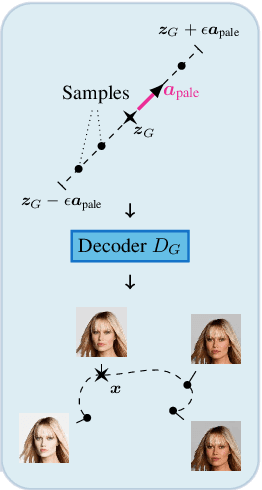
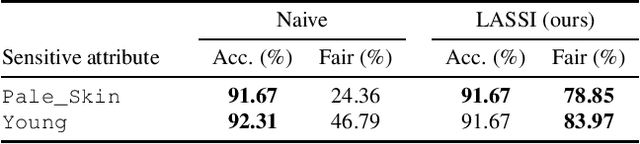
Fair representation learning encodes user data to ensure fairness and utility, regardless of the downstream application. However, learning individually fair representations, i.e., guaranteeing that similar individuals are treated similarly, remains challenging in high-dimensional settings such as computer vision. In this work, we introduce LASSI, the first representation learning method for certifying individual fairness of high-dimensional data. Our key insight is to leverage recent advances in generative modeling to capture the set of similar individuals in the generative latent space. This allows learning individually fair representations where similar individuals are mapped close together, by using adversarial training to minimize the distance between their representations. Finally, we employ randomized smoothing to provably map similar individuals close together, in turn ensuring that local robustness verification of the downstream application results in end-to-end fairness certification. Our experimental evaluation on challenging real-world image data demonstrates that our method increases certified individual fairness by up to 60%, without significantly affecting task utility.
The Geometry of Adversarial Training in Binary Classification
Nov 26, 2021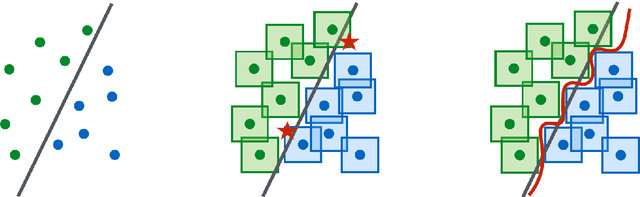
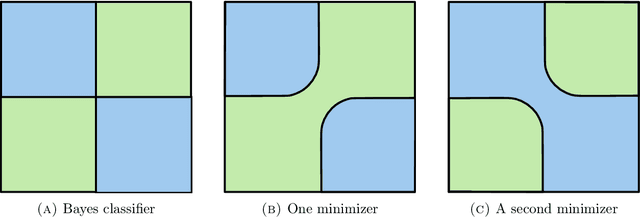
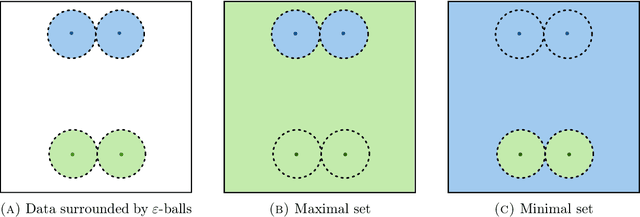
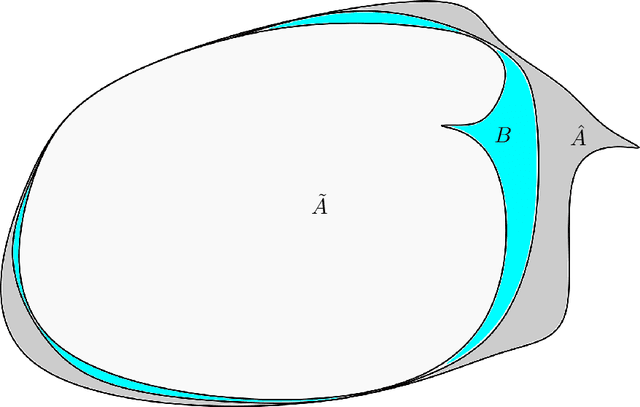
We establish an equivalence between a family of adversarial training problems for non-parametric binary classification and a family of regularized risk minimization problems where the regularizer is a nonlocal perimeter functional. The resulting regularized risk minimization problems admit exact convex relaxations of the type $L^1+$ (nonlocal) $\operatorname{TV}$, a form frequently studied in image analysis and graph-based learning. A rich geometric structure is revealed by this reformulation which in turn allows us to establish a series of properties of optimal solutions of the original problem, including the existence of minimal and maximal solutions (interpreted in a suitable sense), and the existence of regular solutions (also interpreted in a suitable sense). In addition, we highlight how the connection between adversarial training and perimeter minimization problems provides a novel, directly interpretable, statistical motivation for a family of regularized risk minimization problems involving perimeter/total variation. The majority of our theoretical results are independent of the distance used to define adversarial attacks.
Semi-supervised music emotion recognition using noisy student training and harmonic pitch class profiles
Dec 09, 2021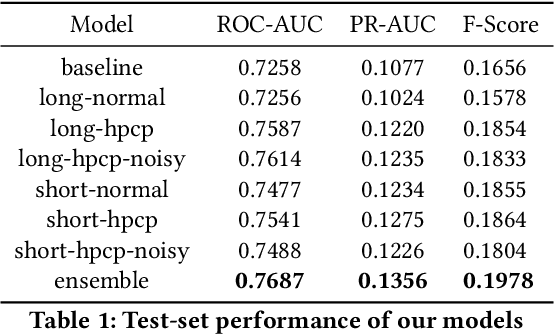
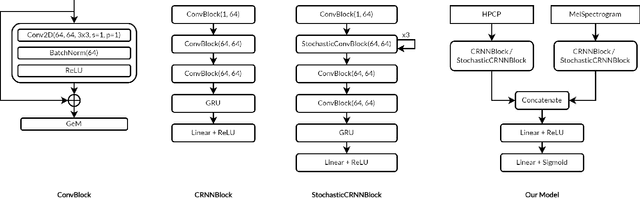
We present Mirable's submission to the 2021 Emotions and Themes in Music challenge. In this work, we intend to address the question: can we leverage semi-supervised learning techniques on music emotion recognition? With that, we experiment with noisy student training, which has improved model performance in the image classification domain. As the noisy student method requires a strong teacher model, we further delve into the factors including (i) input training length and (ii) complementary music representations to further boost the performance of the teacher model. For (i), we find that models trained with short input length perform better in PR-AUC, whereas those trained with long input length perform better in ROC-AUC. For (ii), we find that using harmonic pitch class profiles (HPCP) consistently improve tagging performance, which suggests that harmonic representation is useful for music emotion tagging. Finally, we find that noisy student method only improves tagging results for the case of long training length. Additionally, we find that ensembling representations trained with different training lengths can improve tagging results significantly, which suggest a possible direction to explore incorporating multiple temporal resolutions in the network architecture for future work.
WenLan 2.0: Make AI Imagine via a Multimodal Foundation Model
Oct 27, 2021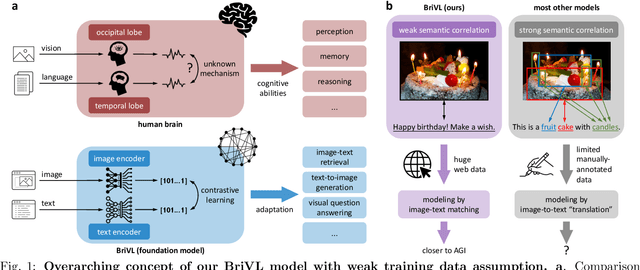


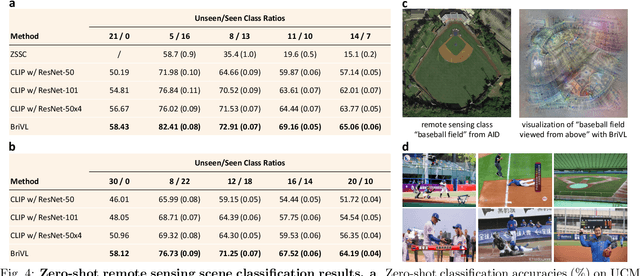
The fundamental goal of artificial intelligence (AI) is to mimic the core cognitive activities of human including perception, memory, and reasoning. Although tremendous success has been achieved in various AI research fields (e.g., computer vision and natural language processing), the majority of existing works only focus on acquiring single cognitive ability (e.g., image classification, reading comprehension, or visual commonsense reasoning). To overcome this limitation and take a solid step to artificial general intelligence (AGI), we develop a novel foundation model pre-trained with huge multimodal (visual and textual) data, which is able to be quickly adapted for a broad class of downstream cognitive tasks. Such a model is fundamentally different from the multimodal foundation models recently proposed in the literature that typically make strong semantic correlation assumption and expect exact alignment between image and text modalities in their pre-training data, which is often hard to satisfy in practice thus limiting their generalization abilities. To resolve this issue, we propose to pre-train our foundation model by self-supervised learning with weak semantic correlation data crawled from the Internet and show that state-of-the-art results can be obtained on a wide range of downstream tasks (both single-modal and cross-modal). Particularly, with novel model-interpretability tools developed in this work, we demonstrate that strong imagination ability (even with hints of commonsense) is now possessed by our foundation model. We believe our work makes a transformative stride towards AGI and will have broad impact on various AI+ fields (e.g., neuroscience and healthcare).
DVHN: A Deep Hashing Framework for Large-scale Vehicle Re-identification
Dec 09, 2021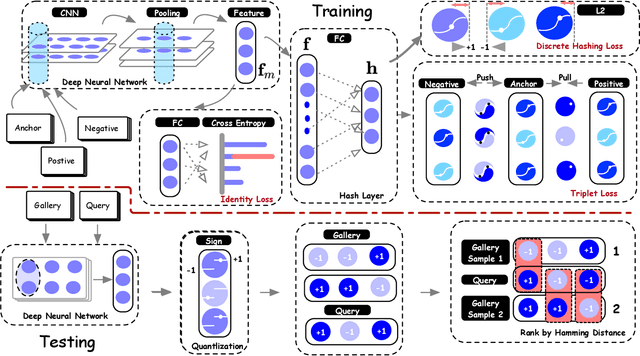
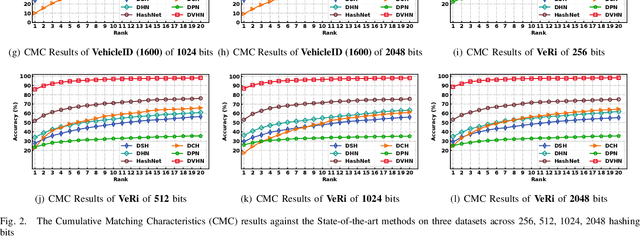
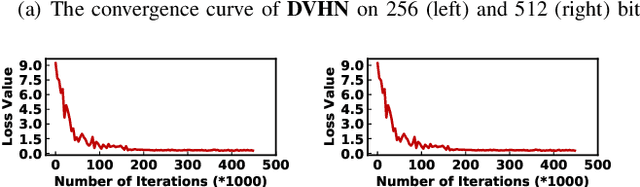
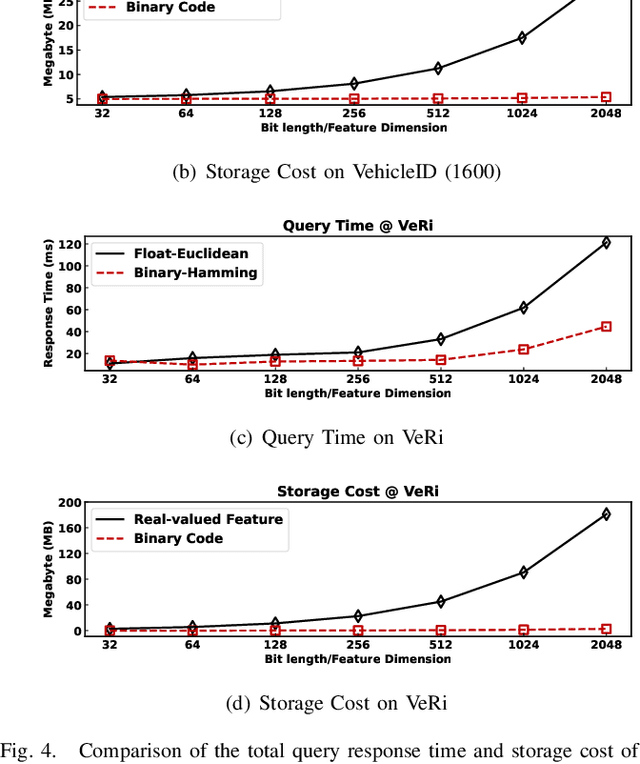
In this paper, we make the very first attempt to investigate the integration of deep hash learning with vehicle re-identification. We propose a deep hash-based vehicle re-identification framework, dubbed DVHN, which substantially reduces memory usage and promotes retrieval efficiency while reserving nearest neighbor search accuracy. Concretely,~DVHN directly learns discrete compact binary hash codes for each image by jointly optimizing the feature learning network and the hash code generating module. Specifically, we directly constrain the output from the convolutional neural network to be discrete binary codes and ensure the learned binary codes are optimal for classification. To optimize the deep discrete hashing framework, we further propose an alternating minimization method for learning binary similarity-preserved hashing codes. Extensive experiments on two widely-studied vehicle re-identification datasets- \textbf{VehicleID} and \textbf{VeRi}-~have demonstrated the superiority of our method against the state-of-the-art deep hash methods. \textbf{DVHN} of $2048$ bits can achieve 13.94\% and 10.21\% accuracy improvement in terms of \textbf{mAP} and \textbf{Rank@1} for \textbf{VehicleID (800)} dataset. For \textbf{VeRi}, we achieve 35.45\% and 32.72\% performance gains for \textbf{Rank@1} and \textbf{mAP}, respectively.
Salient Object Detection by LTP Texture Characterization on Opposing Color Pairs under SLICO Superpixel Constraint
Jan 03, 2022
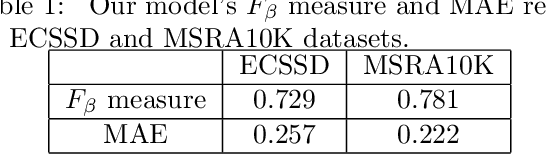
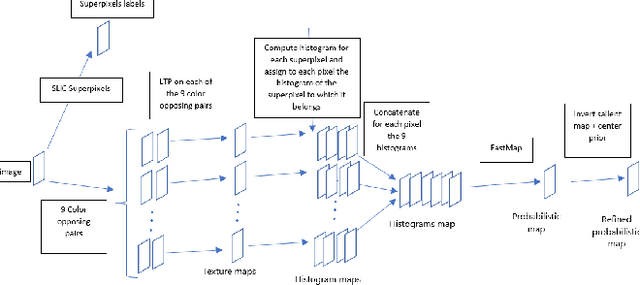

The effortless detection of salient objects by humans has been the subject of research in several fields, including computer vision as it has many applications. However, salient object detection remains a challenge for many computer models dealing with color and textured images. Herein, we propose a novel and efficient strategy, through a simple model, almost without internal parameters, which generates a robust saliency map for a natural image. This strategy consists of integrating color information into local textural patterns to characterize a color micro-texture. Most models in the literature that use the color and texture features treat them separately. In our case, it is the simple, yet powerful LTP (Local Ternary Patterns) texture descriptor applied to opposing color pairs of a color space that allows us to achieve this end. Each color micro-texture is represented by vector whose components are from a superpixel obtained by SLICO (Simple Linear Iterative Clustering with zero parameter) algorithm which is simple, fast and exhibits state-of-the-art boundary adherence. The degree of dissimilarity between each pair of color micro-texture is computed by the FastMap method, a fast version of MDS (Multi-dimensional Scaling), that considers the color micro-textures non-linearity while preserving their distances. These degrees of dissimilarity give us an intermediate saliency map for each RGB, HSL, LUV and CMY color spaces. The final saliency map is their combination to take advantage of the strength of each of them. The MAE (Mean Absolute Error) and F$_{\beta}$ measures of our saliency maps, on the complex ECSSD dataset show that our model is both simple and efficient, outperforming several state-of-the-art models.