 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Printing and Scanning Attack for Image Counter Forensics
Apr 27, 2020



Examining the authenticity of images has become increasingly important as manipulation tools become more accessible and advanced. Recent work has shown that while CNN-based image manipulation detectors can successfully identify manipulations, they are also vulnerable to adversarial attacks, ranging from simple double JPEG compression to advanced pixel-based perturbation. Rephrase(hailey): In this paper we explore another method of highly plausible attack: printing and scanning. We demonstrate the vulnerability of two state-of-the-art models to this type of attack. We also propose a new machine learning model that performs comparably to these state-of-the-art models when trained and validated on printed and scanned images. Of the three models, our proposed model performs the best when trained and validated on images from a single printer. To facilitate this exploration, we create a dataset of over 6,000 printed and scanned image blocks. Further analysis suggests that variation between images produced from different printers is significant, large enough that good validation accuracy on images from one printer does not imply similar validation accuracy on images from a different printer.
KNAS: Green Neural Architecture Search
Nov 26, 2021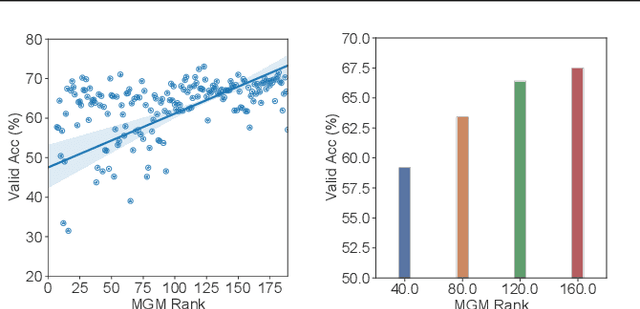
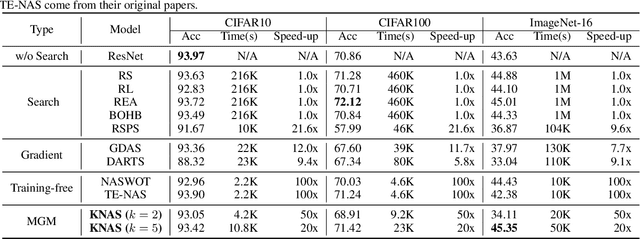

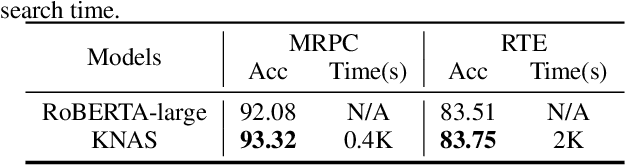
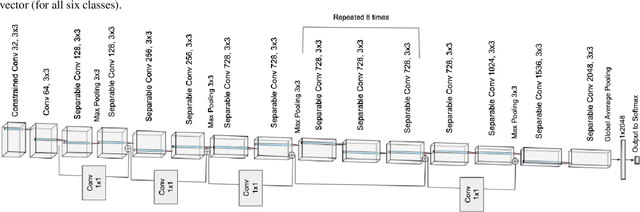
Many existing neural architecture search (NAS) solutions rely on downstream training for architecture evaluation, which takes enormous computations. Considering that these computations bring a large carbon footprint, this paper aims to explore a green (namely environmental-friendly) NAS solution that evaluates architectures without training. Intuitively, gradients, induced by the architecture itself, directly decide the convergence and generalization results. It motivates us to propose the gradient kernel hypothesis: Gradients can be used as a coarse-grained proxy of downstream training to evaluate random-initialized networks. To support the hypothesis, we conduct a theoretical analysis and find a practical gradient kernel that has good correlations with training loss and validation performance. According to this hypothesis, we propose a new kernel based architecture search approach KNAS. Experiments show that KNAS achieves competitive results with orders of magnitude faster than "train-then-test" paradigms on image classification tasks. Furthermore, the extremely low search cost enables its wide applications. The searched network also outperforms strong baseline RoBERTA-large on two text classification tasks. Codes are available at \url{https://github.com/Jingjing-NLP/KNAS} .
Scale-Aware Dynamic Network for Continuous-Scale Super-Resolution
Oct 29, 2021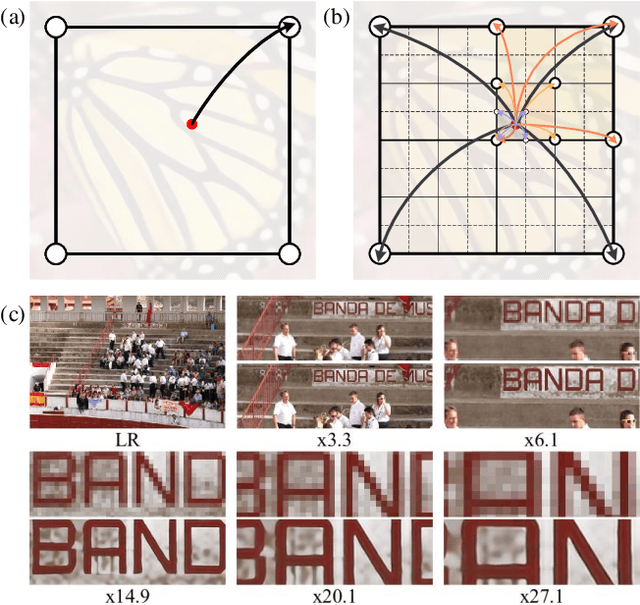
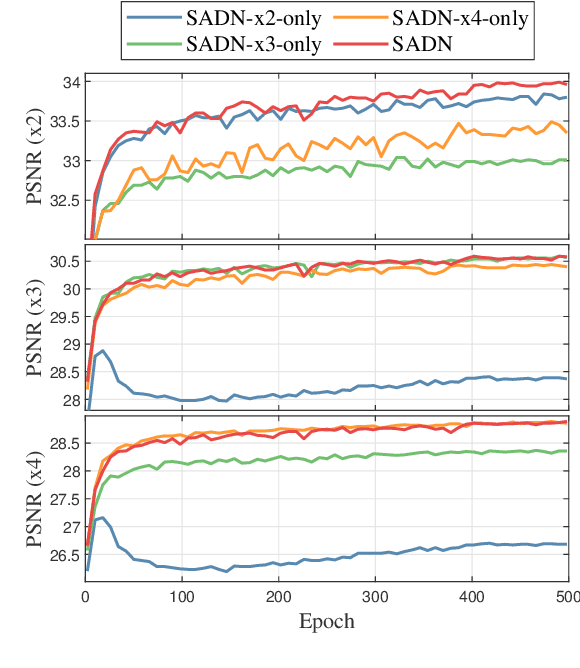

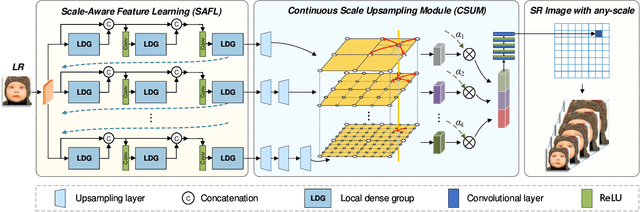
Single-image super-resolution (SR) with fixed and discrete scale factors has achieved great progress due to the development of deep learning technology. However, the continuous-scale SR, which aims to use a single model to process arbitrary (integer or non-integer) scale factors, is still a challenging task. The existing SR models generally adopt static convolution to extract features, and thus unable to effectively perceive the change of scale factor, resulting in limited generalization performance on multi-scale SR tasks. Moreover, the existing continuous-scale upsampling modules do not make full use of multi-scale features and face problems such as checkerboard artifacts in the SR results and high computational complexity. To address the above problems, we propose a scale-aware dynamic network (SADN) for continuous-scale SR. First, we propose a scale-aware dynamic convolutional (SAD-Conv) layer for the feature learning of multiple SR tasks with various scales. The SAD-Conv layer can adaptively adjust the attention weights of multiple convolution kernels based on the scale factor, which enhances the expressive power of the model with a negligible extra computational cost. Second, we devise a continuous-scale upsampling module (CSUM) with the multi-bilinear local implicit function (MBLIF) for any-scale upsampling. The CSUM constructs multiple feature spaces with gradually increasing scales to approximate the continuous feature representation of an image, and then the MBLIF makes full use of multi-scale features to map arbitrary coordinates to RGB values in high-resolution space. We evaluate our SADN using various benchmarks. The experimental results show that the CSUM can replace the previous fixed-scale upsampling layers and obtain a continuous-scale SR network while maintaining performance. Our SADN uses much fewer parameters and outperforms the state-of-the-art SR methods.
LegoDNN: Block-grained Scaling of Deep Neural Networks for Mobile Vision
Dec 18, 2021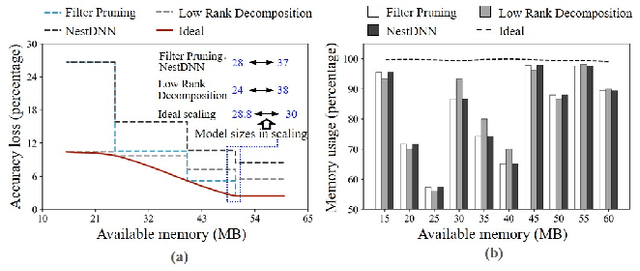
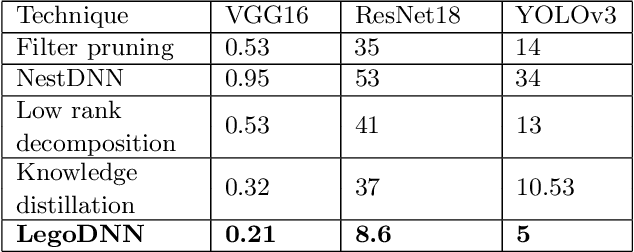
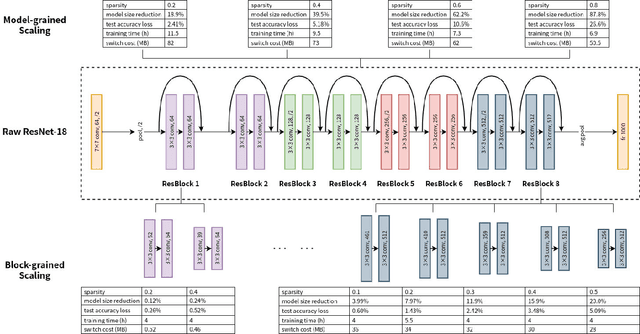
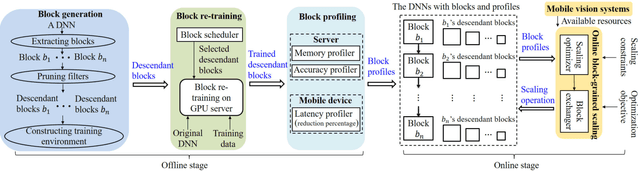
Deep neural networks (DNNs) have become ubiquitous techniques in mobile and embedded systems for applications such as image/object recognition and classification. The trend of executing multiple DNNs simultaneously exacerbate the existing limitations of meeting stringent latency/accuracy requirements on resource constrained mobile devices. The prior art sheds light on exploring the accuracy-resource tradeoff by scaling the model sizes in accordance to resource dynamics. However, such model scaling approaches face to imminent challenges: (i) large space exploration of model sizes, and (ii) prohibitively long training time for different model combinations. In this paper, we present LegoDNN, a lightweight, block-grained scaling solution for running multi-DNN workloads in mobile vision systems. LegoDNN guarantees short model training times by only extracting and training a small number of common blocks (e.g. 5 in VGG and 8 in ResNet) in a DNN. At run-time, LegoDNN optimally combines the descendant models of these blocks to maximize accuracy under specific resources and latency constraints, while reducing switching overhead via smart block-level scaling of the DNN. We implement LegoDNN in TensorFlow Lite and extensively evaluate it against state-of-the-art techniques (FLOP scaling, knowledge distillation and model compression) using a set of 12 popular DNN models. Evaluation results show that LegoDNN provides 1,296x to 279,936x more options in model sizes without increasing training time, thus achieving as much as 31.74% improvement in inference accuracy and 71.07% reduction in scaling energy consumptions.
* 13 pages, 15 figures
Big Data in Astroinformatics -- Compression of Scanned Astronomical Photographic Plates
Aug 20, 2021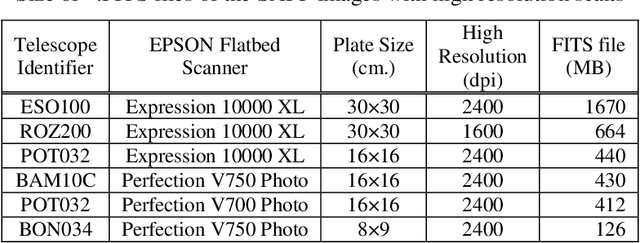
Construction of Scanned Astronomical Photographic Plates(SAPPs) databases and SVD image compression algorithm are considered. Some examples of compression with different plates are shown.
Crosslink-Net: Double-branch Encoder Segmentation Network via Fusing Vertical and Horizontal Convolutions
Jul 24, 2021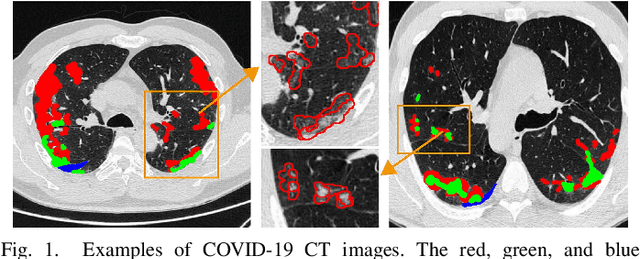

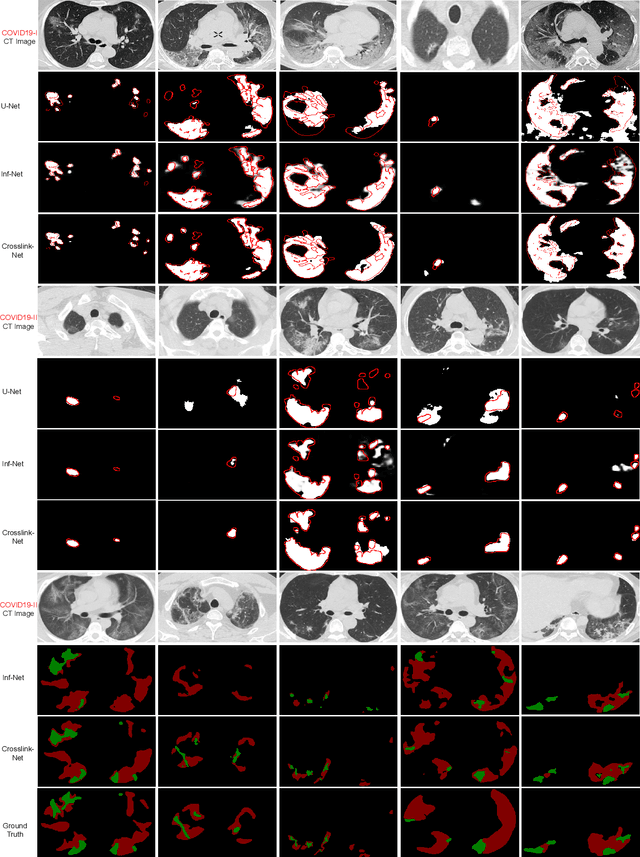
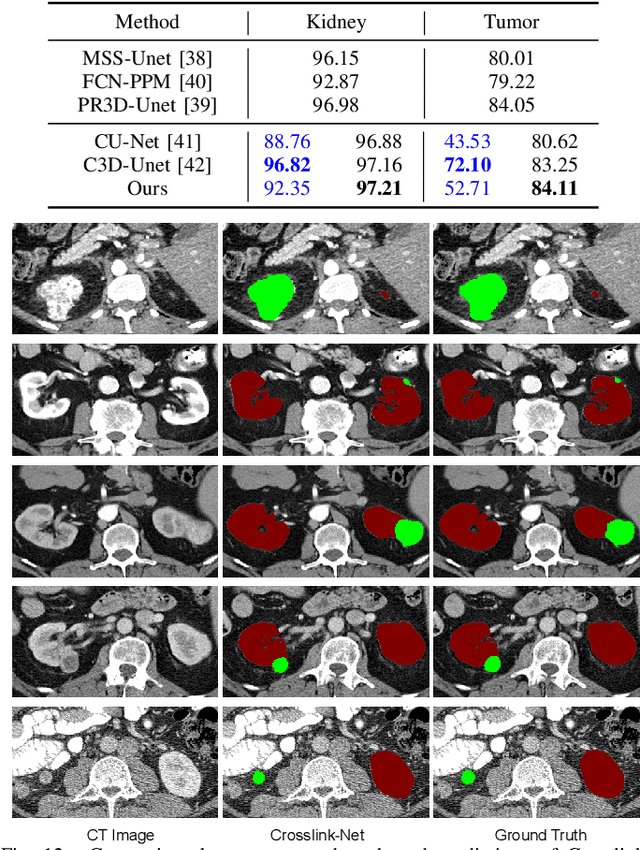
Accurate image segmentation plays a crucial role in medical image analysis, yet it faces great challenges of various shapes, diverse sizes, and blurry boundaries. To address these difficulties, square kernel-based encoder-decoder architecture has been proposed and widely used, but its performance remains still unsatisfactory. To further cope with these challenges, we present a novel double-branch encoder architecture. Our architecture is inspired by two observations: 1) Since the discrimination of features learned via square convolutional kernels needs to be further improved, we propose to utilize non-square vertical and horizontal convolutional kernels in the double-branch encoder, so features learned by the two branches can be expected to complement each other. 2) Considering that spatial attention can help models to better focus on the target region in a large-sized image, we develop an attention loss to further emphasize the segmentation on small-sized targets. Together, the above two schemes give rise to a novel double-branch encoder segmentation framework for medical image segmentation, namely Crosslink-Net. The experiments validate the effectiveness of our model on four datasets. The code is released at https://github.com/Qianyu1226/Crosslink-Net.
Latent Filter Scaling for Multimodal Unsupervised Image-to-Image Translation
Dec 24, 2018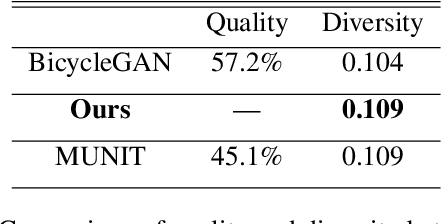
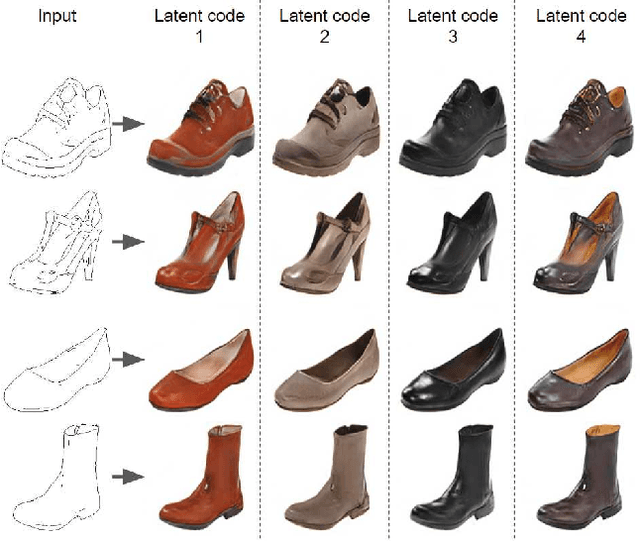


In multimodal unsupervised image-to-image translation tasks, the goal is to translate an image from the source domain to many images in the target domain. We present a simple method that produces higher quality images than current state-of-the-art while maintaining the same amount of multimodal diversity. Previous methods follow the unconditional approach of trying to map the latent code directly to a full-size image. This leads to complicated network architectures with several introduced hyperparameters to tune. By treating the latent code as a modifier of the convolutional filters, we produce multimodal output while maintaining the traditional Generative Adversarial Network (GAN) loss and without additional hyperparameters. The only tuning required by our method controls the tradeoff between variability and quality of generated images. Furthermore, we achieve disentanglement between source domain content and target domain style for free as a by-product of our formulation. We perform qualitative and quantitative experiments showing the advantages of our method compared with the state-of-the art on multiple benchmark image-to-image translation datasets.
Guided interactive image segmentation using machine learning and color based data set clustering
May 15, 2020We present a novel approach that combines machine learning based interactive image segmentation with a two-stage clustering method for identification of similarly colored images enabling efficient batch image segmentation through guided reuse of interactively trained classifiers. The segmentation task is formulated as a supervised machine learning problem working on supervoxels. These visually homogeneous groups of voxels are characterized using local color, edge and texture features. Classifiers are interactively trained from sparse annotations in a iterative process of annotation refinement. Resulting models can be used for batch processing of previously unseen images. However, due to systemic discrepancies of image colorization classifier reusability is typically limited. By clustering a set of images into subsets of similar colorization, considering characteristic dominant color vectors obtained from the individual images it is possible to identify a minimal set of prototype images eligible for interactive segmentation. We demonstrate that limiting the reuse of pre-trained classifiers to images in the same color-cluster significantly improves the average segmentation performance of batch processing. The described methods are implemented in our free image processing and quantification software TiQuant released alongside this publication.
VLBInet: Radio Interferometry Data Classification for EHT with Neural Networks
Oct 14, 2021

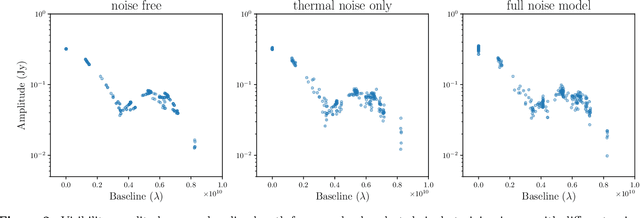
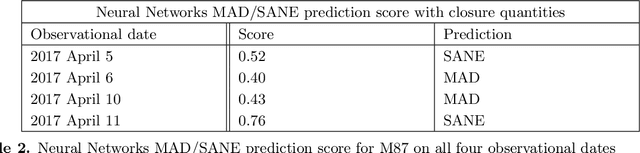
The Event Horizon Telescope (EHT) recently released the first horizon-scale images of the black hole in M87. Combined with other astronomical data, these images constrain the mass and spin of the hole as well as the accretion rate and magnetic flux trapped on the hole. An important question for the EHT is how well key parameters, such as trapped magnetic flux and the associated disk models, can be extracted from present and future EHT VLBI data products. The process of modeling visibilities and analyzing them is complicated by the fact that the data are sparsely sampled in the Fourier domain while most of the theory/simulation is constructed in the image domain. Here we propose a data-driven approach to analyze complex visibilities and closure quantities for radio interferometric data with neural networks. Using mock interferometric data, we show that our neural networks are able to infer the accretion state as either high magnetic flux (MAD) or low magnetic flux (SANE), suggesting that it is possible to perform parameter extraction directly in the visibility domain without image reconstruction. We have applied VLBInet to real M87 EHT data taken on four different days in 2017 (April 5, 6, 10, 11), and our neural networks give a score prediction 0.52, 0.4, 0.43, 0.76 for each day, with an average score 0.53, which shows no significant indication for the data to lean toward either the MAD or SANE state.
LiteDenseNet: A Lightweight Network for Hyperspectral Image Classification
Apr 26, 2020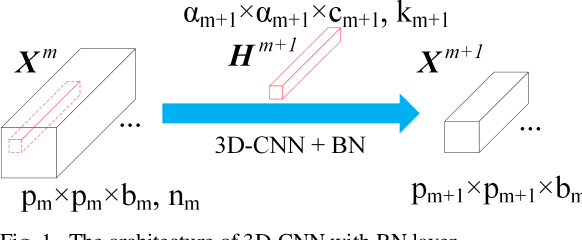
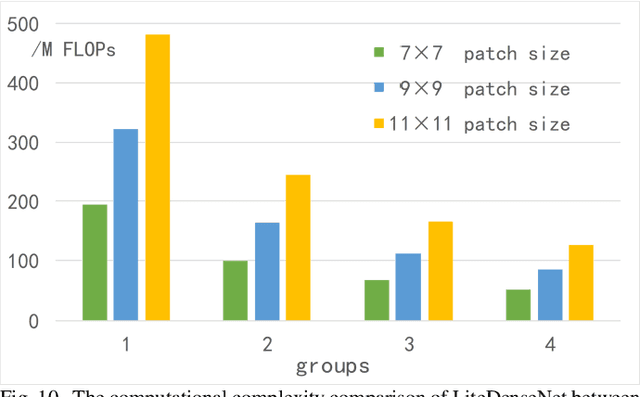
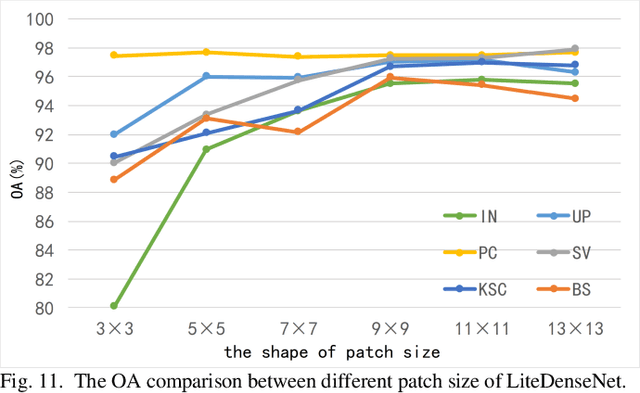
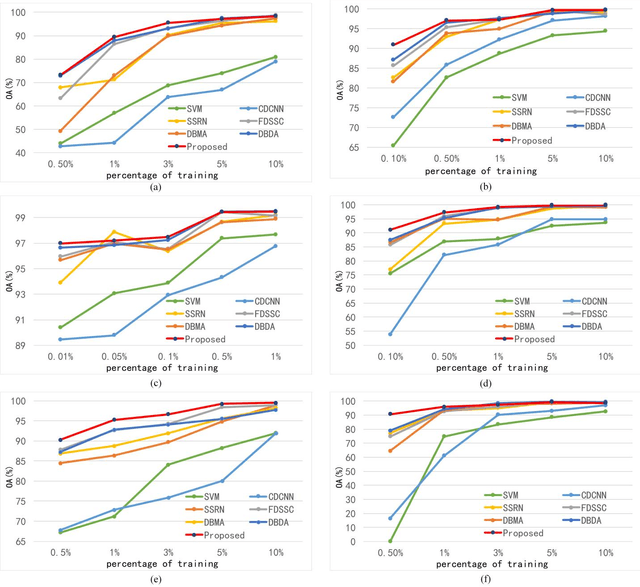
Hyperspectral Image (HSI) classification based on deep learning has been an attractive area in recent years. However, as a kind of data-driven algorithm, deep learning method usually requires numerous computational resources and high-quality labelled dataset, while the cost of high-performance computing and data annotation is expensive. In this paper, to reduce dependence on massive calculation and labelled samples, we propose a lightweight network architecture (LiteDenseNet) based on DenseNet for Hyperspectral Image Classification. Inspired by GoogLeNet and PeleeNet, we design a 3D two-way dense layer to capture the local and global features of the input. As convolution is a computationally intensive operation, we introduce group convolution to decrease calculation cost and parameter size further. Thus, the number of parameters and the consumptions of calculation are observably less than contrapositive deep learning methods, which means LiteDenseNet owns simpler architecture and higher efficiency. A series of quantitative experiences on 6 widely used hyperspectral datasets show that the proposed LiteDenseNet obtains the state-of-the-art performance, even though when the absence of labelled samples is severe.