 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MultiPath++: Efficient Information Fusion and Trajectory Aggregation for Behavior Prediction
Dec 22, 2021
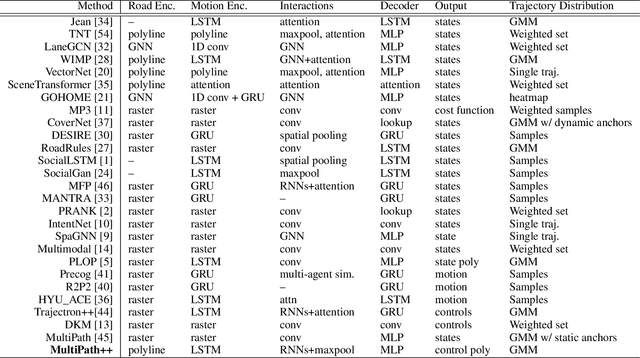
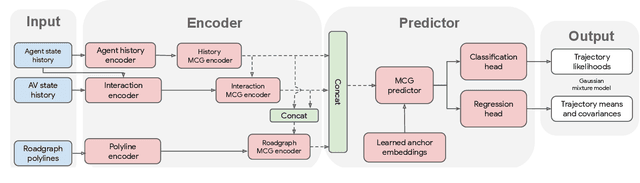
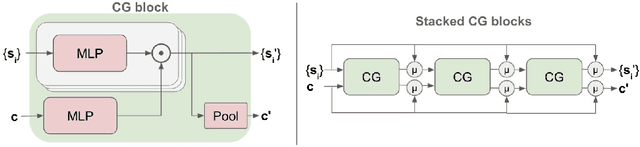
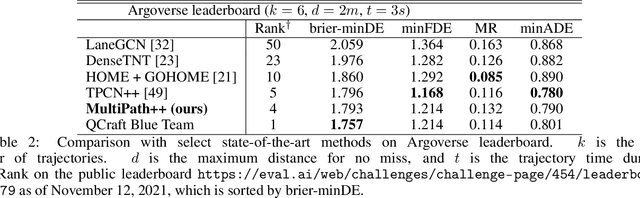
Predicting the future behavior of road users is one of the most challenging and important problems in autonomous driving. Applying deep learning to this problem requires fusing heterogeneous world state in the form of rich perception signals and map information, and inferring highly multi-modal distributions over possible futures. In this paper, we present MultiPath++, a future prediction model that achieves state-of-the-art performance on popular benchmarks. MultiPath++ improves the MultiPath architecture by revisiting many design choices. The first key design difference is a departure from dense image-based encoding of the input world state in favor of a sparse encoding of heterogeneous scene elements: MultiPath++ consumes compact and efficient polylines to describe road features, and raw agent state information directly (e.g., position, velocity, acceleration). We propose a context-aware fusion of these elements and develop a reusable multi-context gating fusion component. Second, we reconsider the choice of pre-defined, static anchors, and develop a way to learn latent anchor embeddings end-to-end in the model. Lastly, we explore ensembling and output aggregation techniques -- common in other ML domains -- and find effective variants for our probabilistic multimodal output representation. We perform an extensive ablation on these design choices, and show that our proposed model achieves state-of-the-art performance on the Argoverse Motion Forecasting Competition and the Waymo Open Dataset Motion Prediction Challenge.
Bringing Your Own View: Graph Contrastive Learning without Prefabricated Data Augmentations
Jan 04, 2022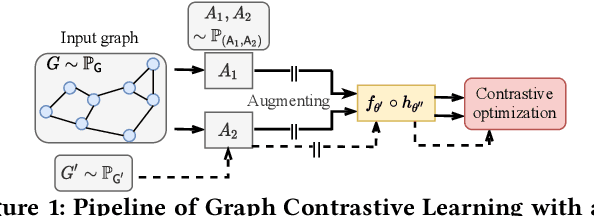

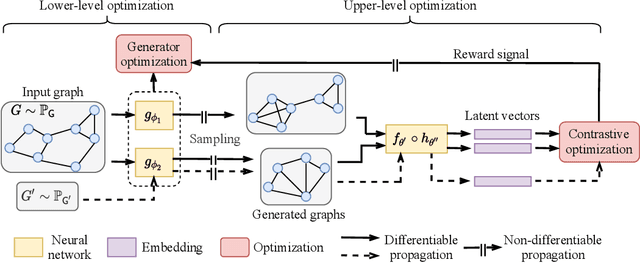
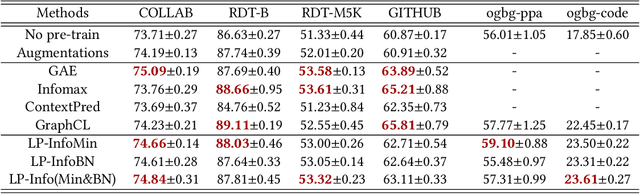
Self-supervision is recently surging at its new frontier of graph learning. It facilitates graph representations beneficial to downstream tasks; but its success could hinge on domain knowledge for handcraft or the often expensive trials and errors. Even its state-of-the-art representative, graph contrastive learning (GraphCL), is not completely free of those needs as GraphCL uses a prefabricated prior reflected by the ad-hoc manual selection of graph data augmentations. Our work aims at advancing GraphCL by answering the following questions: How to represent the space of graph augmented views? What principle can be relied upon to learn a prior in that space? And what framework can be constructed to learn the prior in tandem with contrastive learning? Accordingly, we have extended the prefabricated discrete prior in the augmentation set, to a learnable continuous prior in the parameter space of graph generators, assuming that graph priors per se, similar to the concept of image manifolds, can be learned by data generation. Furthermore, to form contrastive views without collapsing to trivial solutions due to the prior learnability, we have leveraged both principles of information minimization (InfoMin) and information bottleneck (InfoBN) to regularize the learned priors. Eventually, contrastive learning, InfoMin, and InfoBN are incorporated organically into one framework of bi-level optimization. Our principled and automated approach has proven to be competitive against the state-of-the-art graph self-supervision methods, including GraphCL, on benchmarks of small graphs; and shown even better generalizability on large-scale graphs, without resorting to human expertise or downstream validation. Our code is publicly released at https://github.com/Shen-Lab/GraphCL_Automated.
Universal Captioner: Long-Tail Vision-and-Language Model Training through Content-Style Separation
Nov 24, 2021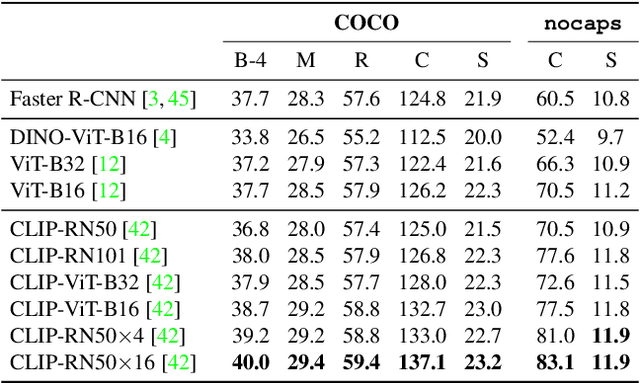

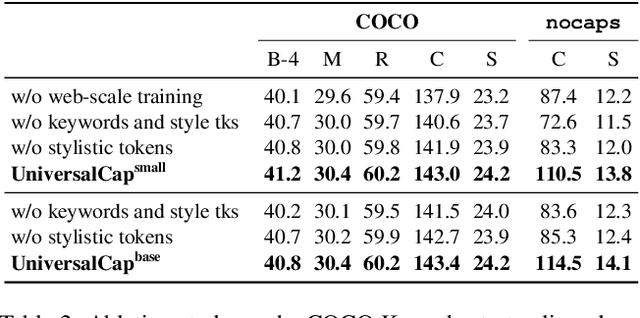
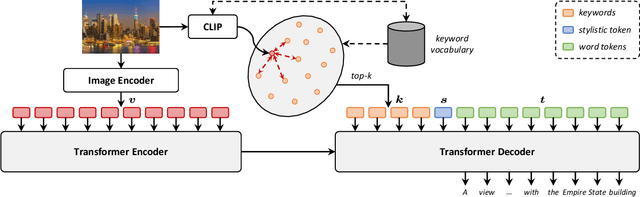
While captioning models have obtained compelling results in describing natural images, they still do not cover the entire long-tail distribution of real-world concepts. In this paper, we address the task of generating human-like descriptions with in-the-wild concepts by training on web-scale automatically collected datasets. To this end, we propose a model which can exploit noisy image-caption pairs while maintaining the descriptive style of traditional human-annotated datasets like COCO. Our model separates content from style through the usage of keywords and stylistic tokens, employing a single objective of prompt language modeling and being simpler than other recent proposals. Experimentally, our model consistently outperforms existing methods in terms of caption quality and capability of describing long-tail concepts, also in zero-shot settings. According to the CIDEr metric, we obtain a new state of the art on both COCO and nocaps when using external data.
Visual Persuasion in COVID-19 Social Media Content: A Multi-Modal Characterization
Dec 05, 2021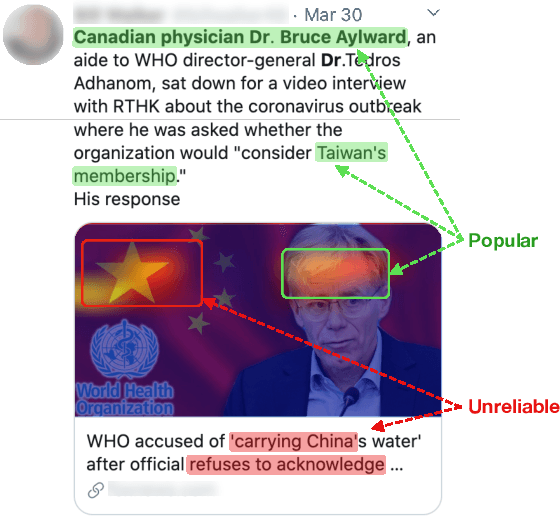
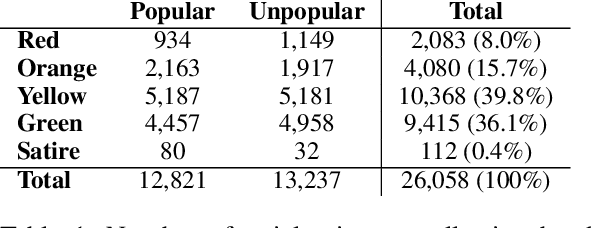

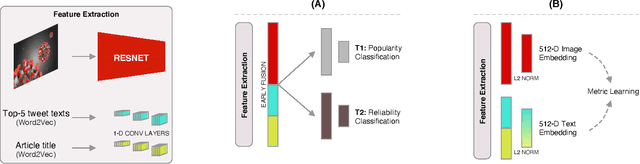
Social media content routinely incorporates multi-modal design to covey information and shape meanings, and sway interpretations toward desirable implications, but the choices and outcomes of using both texts and visual images have not been sufficiently studied. This work proposes a computational approach to analyze the outcome of persuasive information in multi-modal content, focusing on two aspects, popularity and reliability, in COVID-19-related news articles shared on Twitter. The two aspects are intertwined in the spread of misinformation: for example, an unreliable article that aims to misinform has to attain some popularity. This work has several contributions. First, we propose a multi-modal (image and text) approach to effectively identify popularity and reliability of information sources simultaneously. Second, we identify textual and visual elements that are predictive to information popularity and reliability. Third, by modeling cross-modal relations and similarity, we are able to uncover how unreliable articles construct multi-modal meaning in a distorted, biased fashion. Our work demonstrates how to use multi-modal analysis for understanding influential content and has implications to social media literacy and engagement.
Cross-Media Keyphrase Prediction: A Unified Framework with Multi-Modality Multi-Head Attention and Image Wordings
Nov 03, 2020
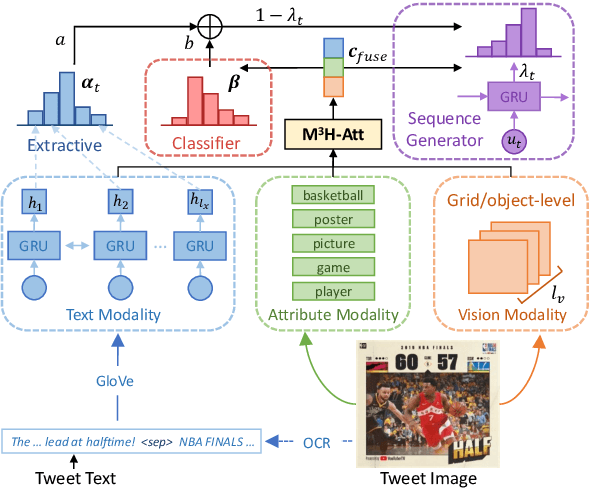
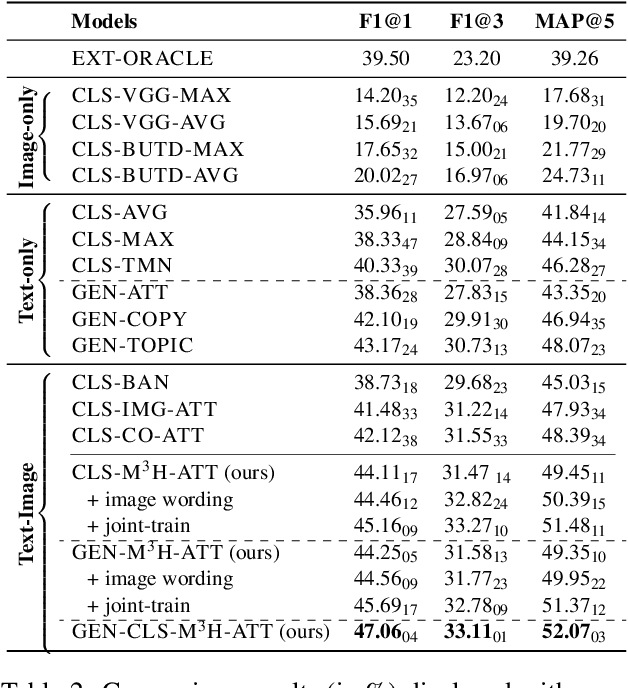
Social media produces large amounts of contents every day. To help users quickly capture what they need, keyphrase prediction is receiving a growing attention. Nevertheless, most prior efforts focus on text modeling, largely ignoring the rich features embedded in the matching images. In this work, we explore the joint effects of texts and images in predicting the keyphrases for a multimedia post. To better align social media style texts and images, we propose: (1) a novel Multi-Modality Multi-Head Attention (M3H-Att) to capture the intricate cross-media interactions; (2) image wordings, in forms of optical characters and image attributes, to bridge the two modalities. Moreover, we design a unified framework to leverage the outputs of keyphrase classification and generation and couple their advantages. Extensive experiments on a large-scale dataset newly collected from Twitter show that our model significantly outperforms the previous state of the art based on traditional attention networks. Further analyses show that our multi-head attention is able to attend information from various aspects and boost classification or generation in diverse scenarios.
Sparse Coding with Multi-Layer Decoders using Variance Regularization
Dec 16, 2021
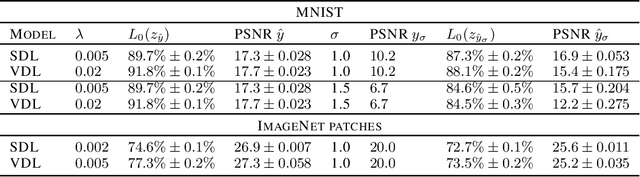


Sparse coding with an $l_1$ penalty and a learned linear dictionary requires regularization of the dictionary to prevent a collapse in the $l_1$ norms of the codes. Typically, this regularization entails bounding the Euclidean norms of the dictionary's elements. In this work, we propose a novel sparse coding protocol which prevents a collapse in the codes without the need to regularize the decoder. Our method regularizes the codes directly so that each latent code component has variance greater than a fixed threshold over a set of sparse representations for a given set of inputs. Furthermore, we explore ways to effectively train sparse coding systems with multi-layer decoders since they can model more complex relationships than linear dictionaries. In our experiments with MNIST and natural image patches, we show that decoders learned with our approach have interpretable features both in the linear and multi-layer case. Moreover, we show that sparse autoencoders with multi-layer decoders trained using our variance regularization method produce higher quality reconstructions with sparser representations when compared to autoencoders with linear dictionaries. Additionally, sparse representations obtained with our variance regularization approach are useful in the downstream tasks of denoising and classification in the low-data regime.
Weak Novel Categories without Tears: A Survey on Weak-Shot Learning
Oct 06, 2021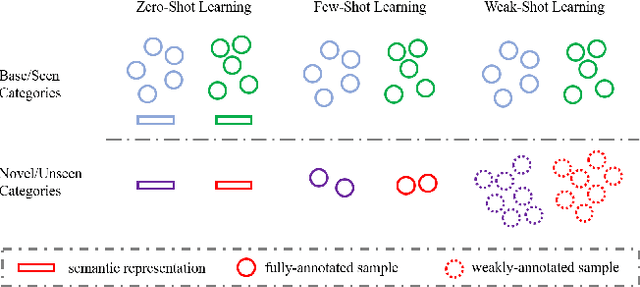
Deep learning is a data-hungry approach, which requires massive training data. However, it is time-consuming and labor-intensive to collect abundant fully-annotated training data for all categories. Assuming the existence of base categories with adequate fully-annotated training samples, different paradigms requiring fewer training samples or weaker annotations for novel categories have attracted growing research interest. Among them, zero-shot (resp., few-shot) learning explores using zero (resp., a few) training samples for novel categories, which lowers the quantity requirement for novel categories. Instead, weak-shot learning lowers the quality requirement for novel categories. Specifically, sufficient training samples are collected for novel categories but they only have weak annotations. In different tasks, weak annotations are presented in different forms (e.g., noisy labels for image classification, image labels for object detection, bounding boxes for segmentation), similar to the definitions in weakly supervised learning. Therefore, weak-shot learning can also be treated as weakly supervised learning with auxiliary fully supervised categories. In this paper, we discuss the existing weak-shot learning methodologies in different tasks and summarize the codes at https://github.com/bcmi/Awesome-Weak-Shot-Learning.
Adherent Mist and Raindrop Removal from a Single Image Using Attentive Convolutional Network
Sep 03, 2020

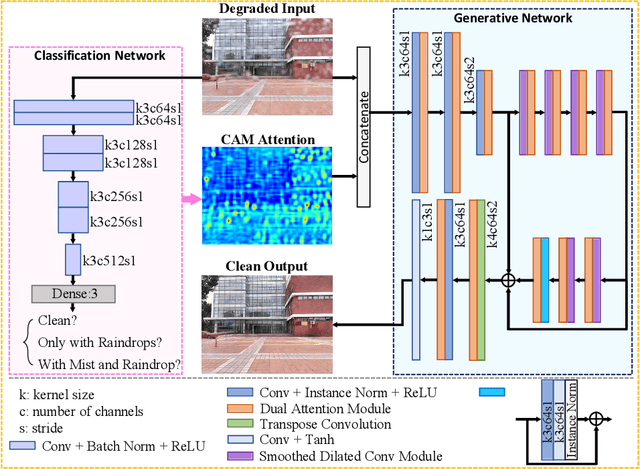

Temperature difference-induced mist adhered to the windshield, camera lens, etc. are often inhomogeneous and obscure, which can easily obstruct the vision and degrade the image severely. Together with adherent raindrops, they bring considerable challenges to various vision systems but without enough attention. Recent methods for similar problems typically use hand-crafted priors to generate spatial attention maps. In this work, we propose to visually remove the adherent mist and raindrop jointly from a single image using attentive convolutional neural networks. We apply classification activation map attention to our model to strengthen the spatial attention without hand-crafted priors. In addition, the smoothed dilated convolution is adopted to obtain a large receptive field without spatial information loss, and the dual attention module is utilized for efficiently selecting channels and spatial features. Our experiments show our method achieves state-of-the-art performance, and demonstrate that this underrated practical problem is critical to high-level vision scenes.
RLCorrector: Reinforced Proofreading for Connectomics Image Segmentation
Jun 10, 2021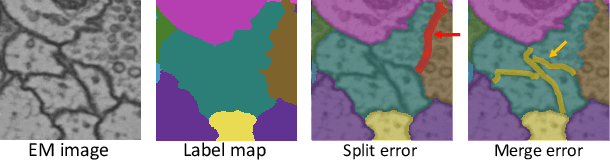
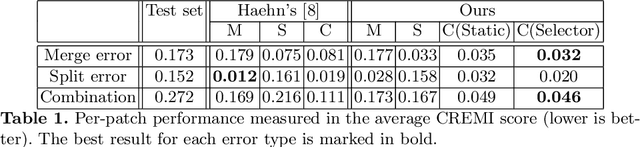
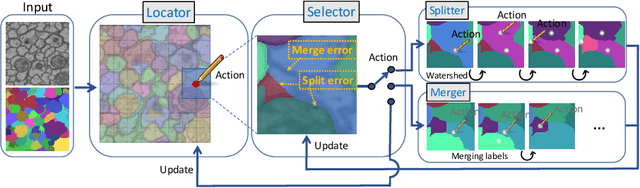

The segmentation of nanoscale electron microscopy (EM) images is crucial but challenging in connectomics. Recent advances in deep learning have demonstrated the significant potential of automatic segmentation for tera-scale EM images. However, none of the existing segmentation methods are error-free, and they require proofreading, which is typically implemented as an interactive, semi-automatic process via manual intervention. Herein, we propose a fully automatic proofreading method based on reinforcement learning. The main idea is to model the human decision process in proofreading using a reinforcement agent to achieve fully automatic proofreading. We systematically design the proposed system by combining multiple reinforcement learning agents in a hierarchical manner, where each agent focuses only on a specific task while preserving dependency between agents. Furthermore, we also demonstrate that the episodic task setting of reinforcement learning can efficiently manage a combination of merge and split errors concurrently presented in the input. We demonstrate the efficacy of the proposed system by comparing it with state-of-the-art proofreading methods using various testing examples.
Asymmetric Modality Translation For Face Presentation Attack Detection
Oct 18, 2021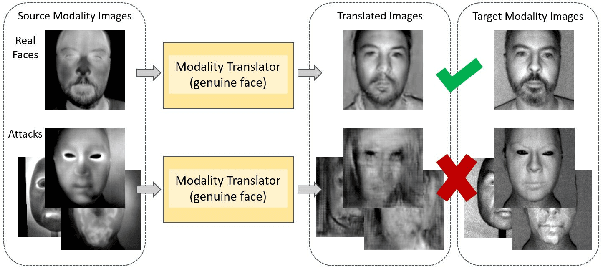
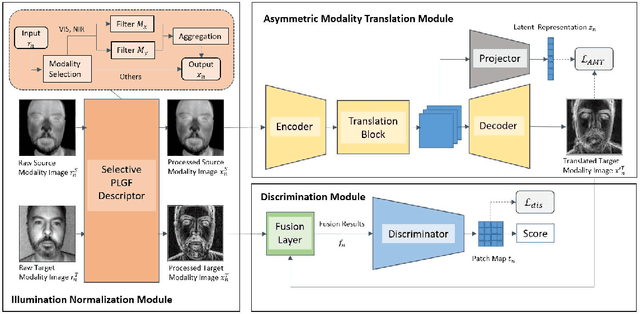
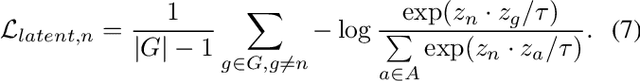
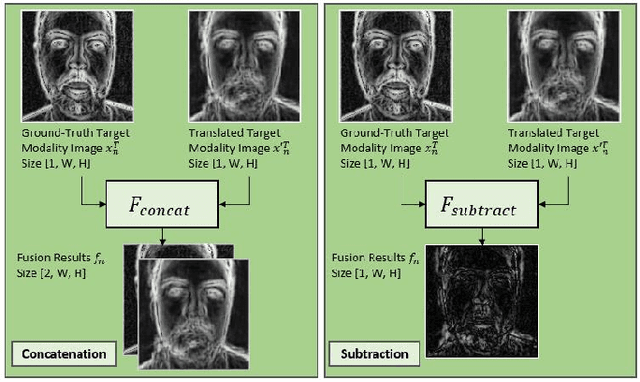
Face presentation attack detection (PAD) is an essential measure to protect face recognition systems from being spoofed by malicious users and has attracted great attention from both academia and industry. Although most of the existing methods can achieve desired performance to some extent, the generalization issue of face presentation attack detection under cross-domain settings (e.g., the setting of unseen attacks and varying illumination) remains to be solved. In this paper, we propose a novel framework based on asymmetric modality translation for face presentation attack detection in bi-modality scenarios. Under the framework, we establish connections between two modality images of genuine faces. Specifically, a novel modality fusion scheme is presented that the image of one modality is translated to the other one through an asymmetric modality translator, then fused with its corresponding paired image. The fusion result is fed as the input to a discriminator for inference. The training of the translator is supervised by an asymmetric modality translation loss. Besides, an illumination normalization module based on Pattern of Local Gravitational Force (PLGF) representation is used to reduce the impact of illumination variation. We conduct extensive experiments on three public datasets, which validate that our method is effective in detecting various types of attacks and achieves state-of-the-art performance under different evaluation protocols.