 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Meta Adversarial Perturbations
Nov 19, 2021
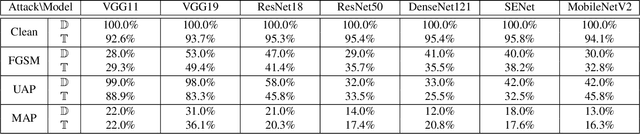
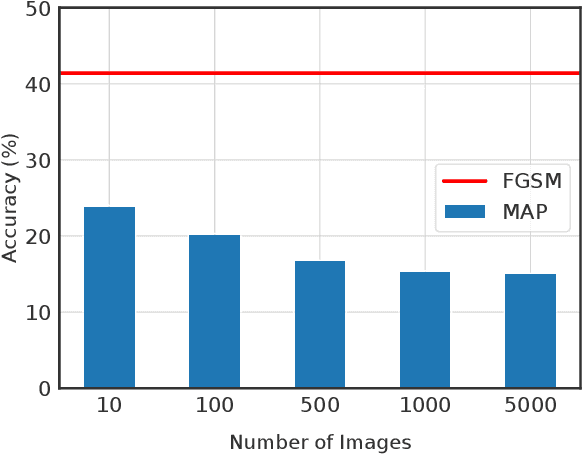
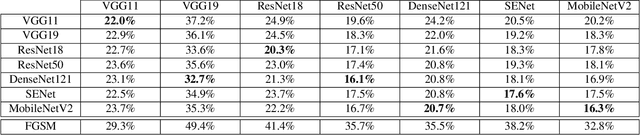
A plethora of attack methods have been proposed to generate adversarial examples, among which the iterative methods have been demonstrated the ability to find a strong attack. However, the computation of an adversarial perturbation for a new data point requires solving a time-consuming optimization problem from scratch. To generate a stronger attack, it normally requires updating a data point with more iterations. In this paper, we show the existence of a meta adversarial perturbation (MAP), a better initialization that causes natural images to be misclassified with high probability after being updated through only a one-step gradient ascent update, and propose an algorithm for computing such perturbations. We conduct extensive experiments, and the empirical results demonstrate that state-of-the-art deep neural networks are vulnerable to meta perturbations. We further show that these perturbations are not only image-agnostic, but also model-agnostic, as a single perturbation generalizes well across unseen data points and different neural network architectures.
DU-GAN: Generative Adversarial Networks with Dual-Domain U-Net Based Discriminators for Low-Dose CT Denoising
Aug 24, 2021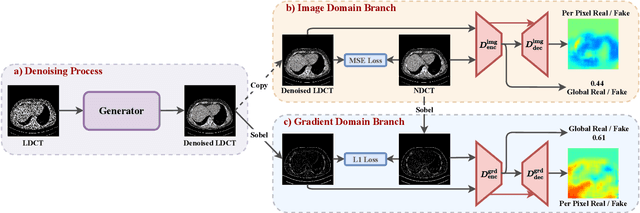
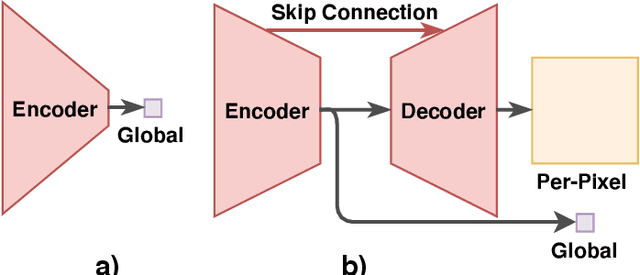
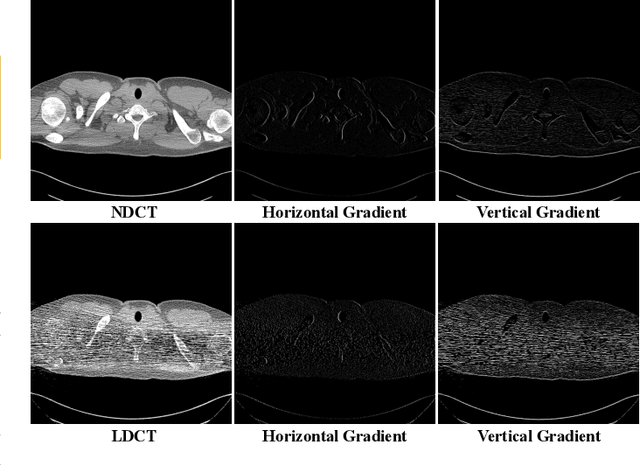
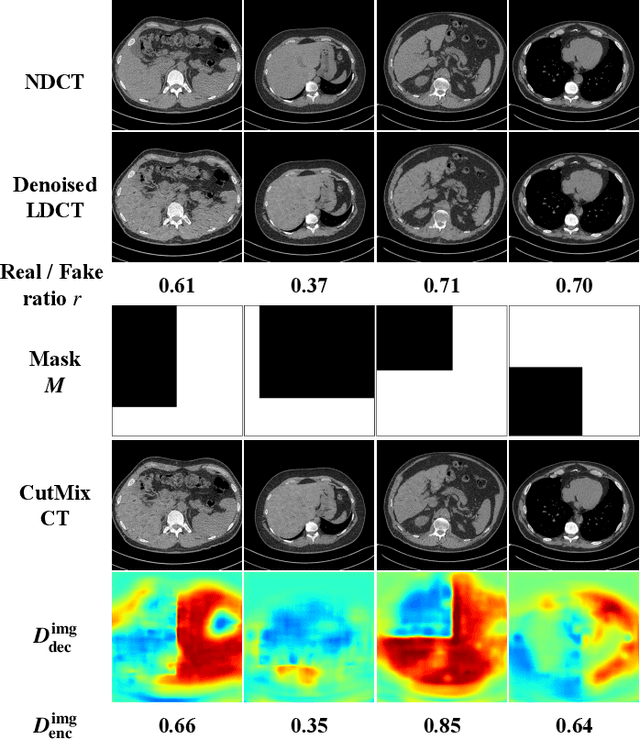
LDCT has drawn major attention in the medical imaging field due to the potential health risks of CT-associated X-ray radiation to patients. Reducing the radiation dose, however, decreases the quality of the reconstructed images, which consequently compromises the diagnostic performance. Various deep learning techniques have been introduced to improve the image quality of LDCT images through denoising. GANs-based denoising methods usually leverage an additional classification network, i.e. discriminator, to learn the most discriminate difference between the denoised and normal-dose images and, hence, regularize the denoising model accordingly; it often focuses either on the global structure or local details. To better regularize the LDCT denoising model, this paper proposes a novel method, termed DU-GAN, which leverages U-Net based discriminators in the GANs framework to learn both global and local difference between the denoised and normal-dose images in both image and gradient domains. The merit of such a U-Net based discriminator is that it can not only provide the per-pixel feedback to the denoising network through the outputs of the U-Net but also focus on the global structure in a semantic level through the middle layer of the U-Net. In addition to the adversarial training in the image domain, we also apply another U-Net based discriminator in the image gradient domain to alleviate the artifacts caused by photon starvation and enhance the edge of the denoised CT images. Furthermore, the CutMix technique enables the per-pixel outputs of the U-Net based discriminator to provide radiologists with a confidence map to visualize the uncertainty of the denoised results, facilitating the LDCT-based screening and diagnosis. Extensive experiments on the simulated and real-world datasets demonstrate superior performance over recently published methods both qualitatively and quantitatively.
LegoDNN: Block-grained Scaling of Deep Neural Networks for Mobile Vision
Dec 18, 2021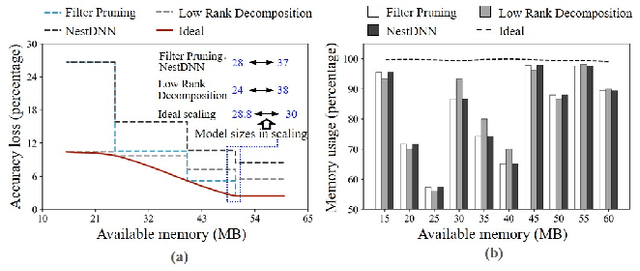
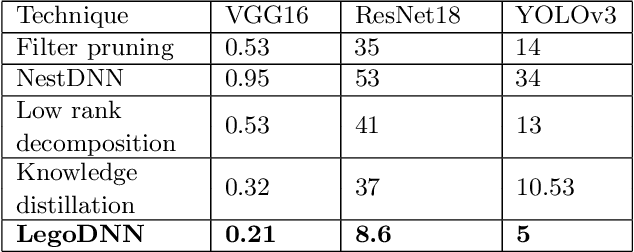
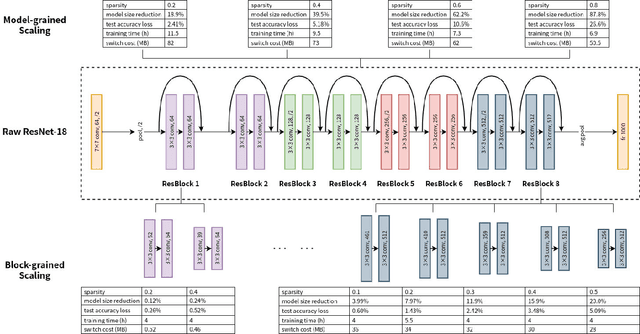
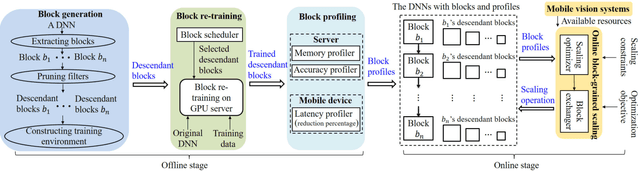
Deep neural networks (DNNs) have become ubiquitous techniques in mobile and embedded systems for applications such as image/object recognition and classification. The trend of executing multiple DNNs simultaneously exacerbate the existing limitations of meeting stringent latency/accuracy requirements on resource constrained mobile devices. The prior art sheds light on exploring the accuracy-resource tradeoff by scaling the model sizes in accordance to resource dynamics. However, such model scaling approaches face to imminent challenges: (i) large space exploration of model sizes, and (ii) prohibitively long training time for different model combinations. In this paper, we present LegoDNN, a lightweight, block-grained scaling solution for running multi-DNN workloads in mobile vision systems. LegoDNN guarantees short model training times by only extracting and training a small number of common blocks (e.g. 5 in VGG and 8 in ResNet) in a DNN. At run-time, LegoDNN optimally combines the descendant models of these blocks to maximize accuracy under specific resources and latency constraints, while reducing switching overhead via smart block-level scaling of the DNN. We implement LegoDNN in TensorFlow Lite and extensively evaluate it against state-of-the-art techniques (FLOP scaling, knowledge distillation and model compression) using a set of 12 popular DNN models. Evaluation results show that LegoDNN provides 1,296x to 279,936x more options in model sizes without increasing training time, thus achieving as much as 31.74% improvement in inference accuracy and 71.07% reduction in scaling energy consumptions.
* 13 pages, 15 figures
Measures of Complexity for Large Scale Image Datasets
Aug 10, 2020


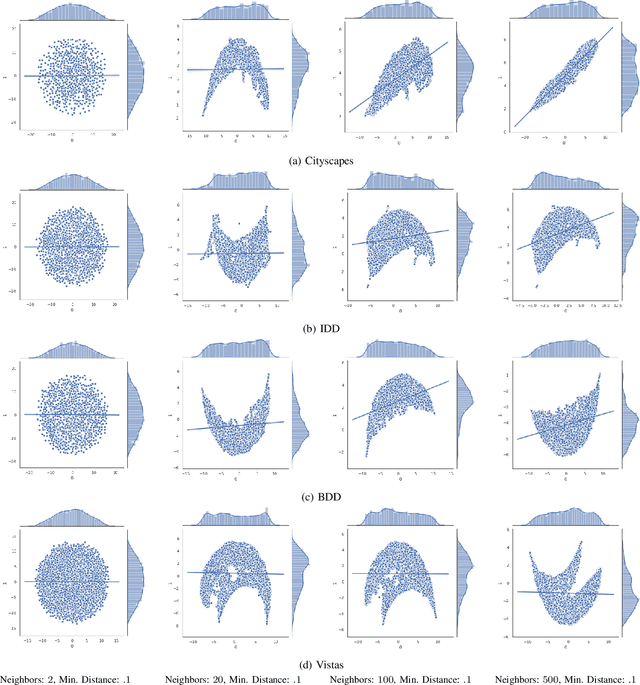
Large scale image datasets are a growing trend in the field of machine learning. However, it is hard to quantitatively understand or specify how various datasets compare to each other - i.e., if one dataset is more complex or harder to ``learn'' with respect to a deep-learning based network. In this work, we build a series of relatively computationally simple methods to measure the complexity of a dataset. Furthermore, we present an approach to demonstrate visualizations of high dimensional data, in order to assist with visual comparison of datasets. We present our analysis using four datasets from the autonomous driving research community - Cityscapes, IDD, BDD and Vistas. Using entropy based metrics, we present a rank-order complexity of these datasets, which we compare with an established rank-order with respect to deep learning.
One-Shot Image-to-Image Translation via Part-Global Learning with a Multi-adversarial Framework
May 12, 2019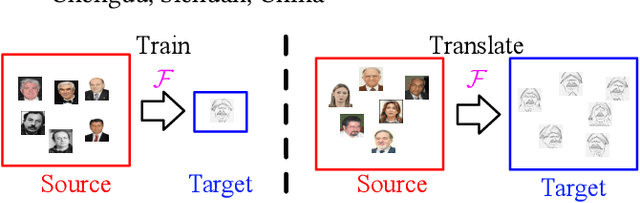
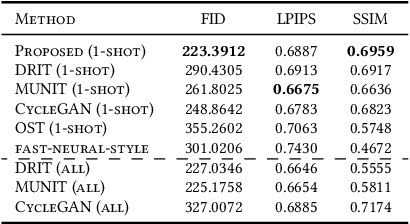
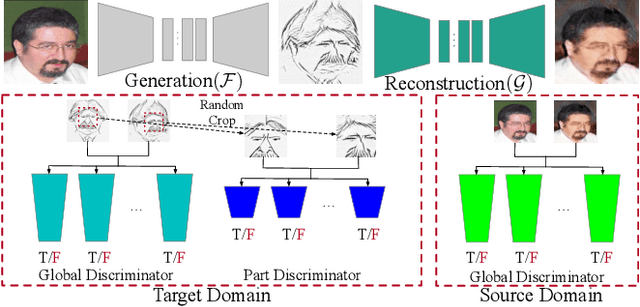
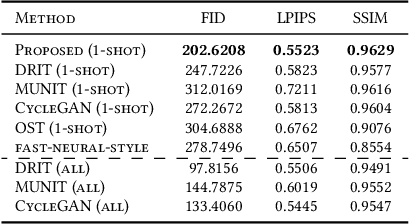
It is well known that humans can learn and recognize objects effectively from several limited image samples. However, learning from just a few images is still a tremendous challenge for existing main-stream deep neural networks. Inspired by analogical reasoning in the human mind, a feasible strategy is to translate the abundant images of a rich source domain to enrich the relevant yet different target domain with insufficient image data. To achieve this goal, we propose a novel, effective multi-adversarial framework (MA) based on part-global learning, which accomplishes one-shot cross-domain image-to-image translation. In specific, we first devise a part-global adversarial training scheme to provide an efficient way for feature extraction and prevent discriminators being over-fitted. Then, a multi-adversarial mechanism is employed to enhance the image-to-image translation ability to unearth the high-level semantic representation. Moreover, a balanced adversarial loss function is presented, which aims to balance the training data and stabilize the training process. Extensive experiments demonstrate that the proposed approach can obtain impressive results on various datasets between two extremely imbalanced image domains and outperform state-of-the-art methods on one-shot image-to-image translation.
Bio-inspired Polarization Event Camera
Dec 02, 2021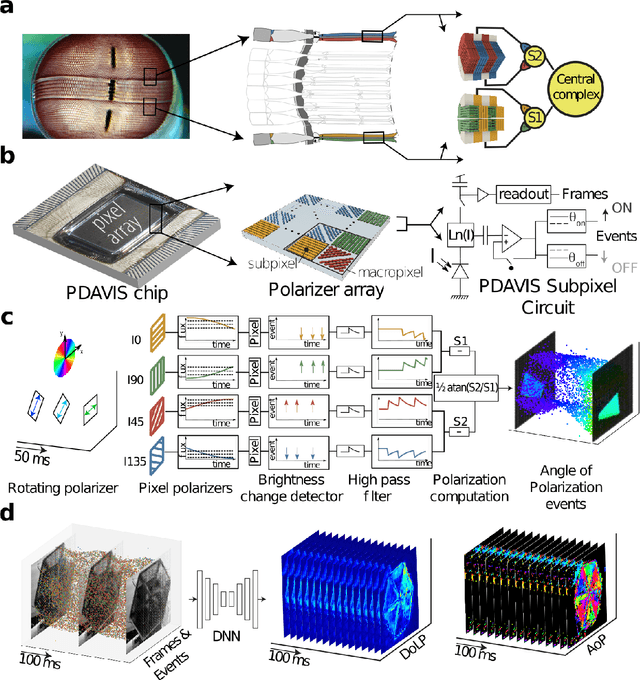
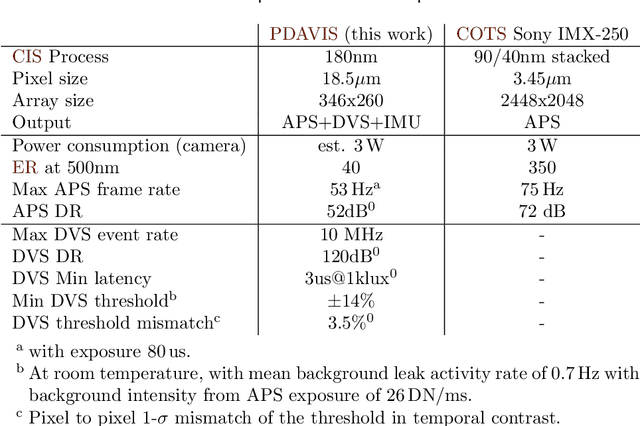
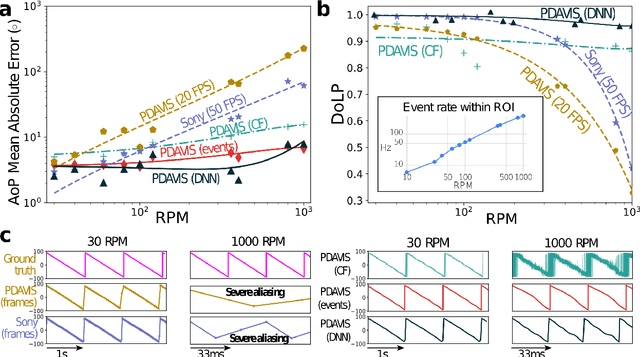

The stomatopod (mantis shrimp) visual system has recently provided a blueprint for the design of paradigm-shifting polarization and multispectral imaging sensors, enabling solutions to challenging medical and remote sensing problems. However, these bioinspired sensors lack the high dynamic range (HDR) and asynchronous polarization vision capabilities of the stomatopod visual system, limiting temporal resolution to \~12 ms and dynamic range to \~ 72 dB. Here we present a novel stomatopod-inspired polarization camera which mimics the sustained and transient biological visual pathways to save power and sample data beyond the maximum Nyquist frame rate. This bio-inspired sensor simultaneously captures both synchronous intensity frames and asynchronous polarization brightness change information with sub-millisecond latencies over a million-fold range of illumination. Our PDAVIS camera is comprised of 346x260 pixels, organized in 2-by-2 macropixels, which filter the incoming light with four linear polarization filters offset by 45 degrees. Polarization information is reconstructed using both low cost and latency event-based algorithms and more accurate but slower deep neural networks. Our sensor is used to image HDR polarization scenes which vary at high speeds and to observe dynamical properties of single collagen fibers in bovine tendon under rapid cyclical loads
Unsupervised Portrait Shadow Removal via Generative Priors
Aug 07, 2021



Portrait images often suffer from undesirable shadows cast by casual objects or even the face itself. While existing methods for portrait shadow removal require training on a large-scale synthetic dataset, we propose the first unsupervised method for portrait shadow removal without any training data. Our key idea is to leverage the generative facial priors embedded in the off-the-shelf pretrained StyleGAN2. To achieve this, we formulate the shadow removal task as a layer decomposition problem: a shadowed portrait image is constructed by the blending of a shadow image and a shadow-free image. We propose an effective progressive optimization algorithm to learn the decomposition process. Our approach can also be extended to portrait tattoo removal and watermark removal. Qualitative and quantitative experiments on a real-world portrait shadow dataset demonstrate that our approach achieves comparable performance with supervised shadow removal methods. Our source code is available at https://github.com/YingqingHe/Shadow-Removal-via-Generative-Priors.
Symmetric Skip Connection Wasserstein GAN for High-Resolution Facial Image Inpainting
Jan 11, 2020
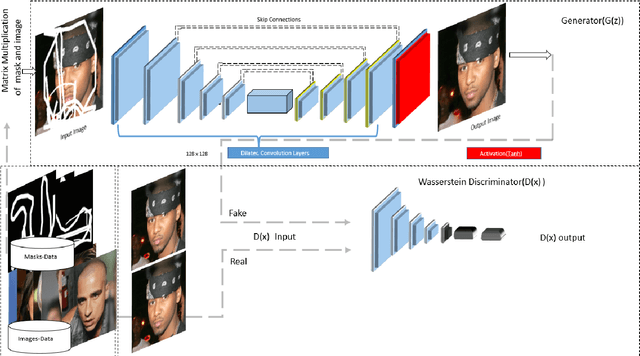

We propose a Symmetric Skip Connection Wasserstein Generative Adversarial Network (S-WGAN) for high-resolution facial image inpainting. The architecture is an encoder-decoder with convolutional blocks, linked by skip connections. The encoder is a feature extractor that captures data abstractions of an input image to learn an end-to-end mapping from an input (binary masked image) to the ground-truth. The decoder uses the learned abstractions to reconstruct the image. With skip connections, S-WGAN transfers image details to the decoder. Also, we propose a Wasserstein-Perceptual loss function to preserve colour and maintain realism on a reconstructed image. We evaluate our method and the state-of-the-art methods on CelebA-HQ dataset. Our results show S-WGAN produces sharper and more realistic images when visually compared with other methods. The quantitative measures show our proposed S-WGAN achieves the best Structure Similarity Index Measure of 0.94.
SUB-Depth: Self-distillation and Uncertainty Boosting Self-supervised Monocular Depth Estimation
Nov 19, 2021
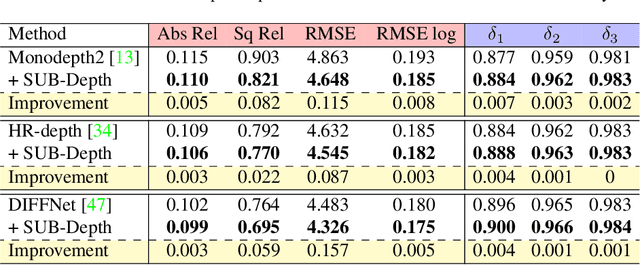
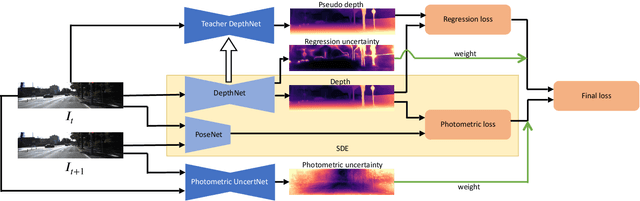
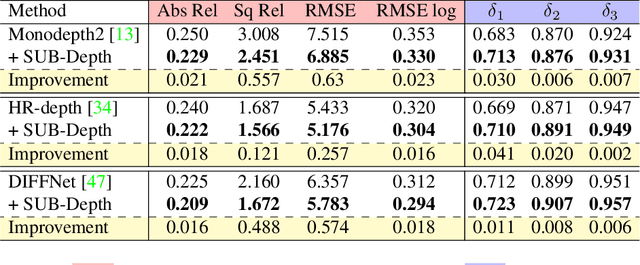
We propose SUB-Depth, a universal multi-task training framework for self-supervised monocular depth estimation (SDE). Depth models trained with SUB-Depth outperform the same models trained in a standard single-task SDE framework. By introducing an additional self-distillation task into a standard SDE training framework, SUB-Depth trains a depth network, not only to predict the depth map for an image reconstruction task, but also to distill knowledge from a trained teacher network with unlabelled data. To take advantage of this multi-task setting, we propose homoscedastic uncertainty formulations for each task to penalize areas likely to be affected by teacher network noise, or violate SDE assumptions. We present extensive evaluations on KITTI to demonstrate the improvements achieved by training a range of existing networks using the proposed framework, and we achieve state-of-the-art performance on this task. Additionally, SUB-Depth enables models to estimate uncertainty on depth output.
Fine-Grained Image Captioning with Global-Local Discriminative Objective
Jul 21, 2020

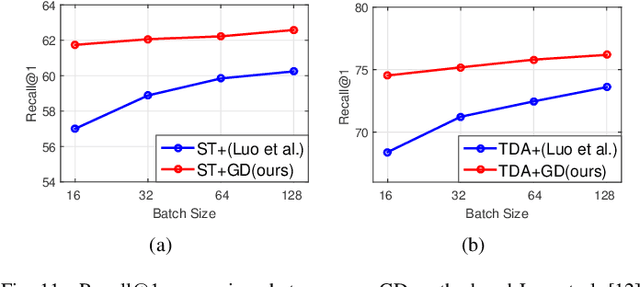
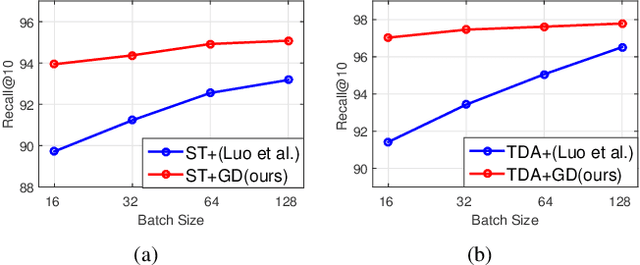
Significant progress has been made in recent years in image captioning, an active topic in the fields of vision and language. However, existing methods tend to yield overly general captions and consist of some of the most frequent words/phrases, resulting in inaccurate and indistinguishable descriptions (see Figure 1). This is primarily due to (i) the conservative characteristic of traditional training objectives that drives the model to generate correct but hardly discriminative captions for similar images and (ii) the uneven word distribution of the ground-truth captions, which encourages generating highly frequent words/phrases while suppressing the less frequent but more concrete ones. In this work, we propose a novel global-local discriminative objective that is formulated on top of a reference model to facilitate generating fine-grained descriptive captions. Specifically, from a global perspective, we design a novel global discriminative constraint that pulls the generated sentence to better discern the corresponding image from all others in the entire dataset. From the local perspective, a local discriminative constraint is proposed to increase attention such that it emphasizes the less frequent but more concrete words/phrases, thus facilitating the generation of captions that better describe the visual details of the given images. We evaluate the proposed method on the widely used MS-COCO dataset, where it outperforms the baseline methods by a sizable margin and achieves competitive performance over existing leading approaches. We also conduct self-retrieval experiments to demonstrate the discriminability of the proposed method.