 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RSV: Robotic Sonography for Thyroid Volumetry
Dec 13, 2021
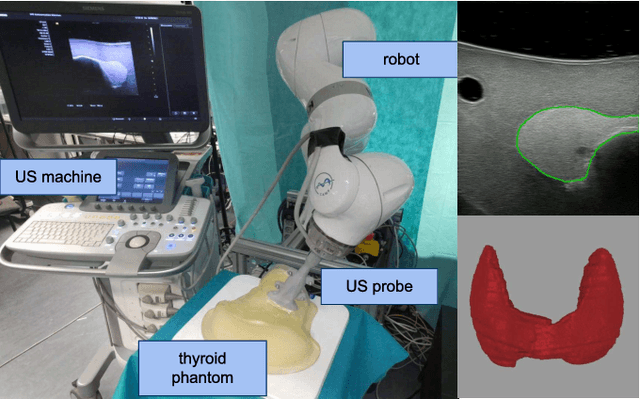
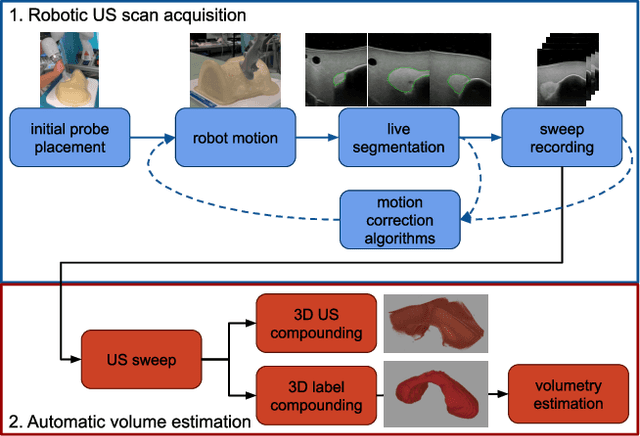
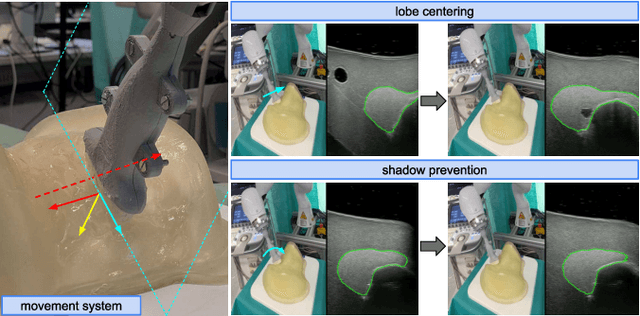
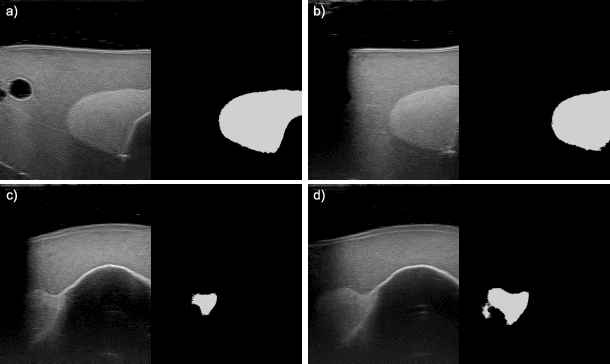
In nuclear medicine, radioiodine therapy is prescribed to treat diseases like hyperthyroidism. The calculation of the prescribed dose depends, amongst other factors, on the thyroid volume. This is currently estimated using conventional 2D ultrasound imaging. However, this modality is inherently user-dependant, resulting in high variability in volume estimations. To increase reproducibility and consistency, we uniquely combine a neural network-based segmentation with an automatic robotic ultrasound scanning for thyroid volumetry. The robotic acquisition is achieved by using a 6 DOF robotic arm with an attached ultrasound probe. Its movement is based on an online segmentation of each thyroid lobe and the appearance of the US image. During post-processing, the US images are segmented to obtain a volume estimation. In an ablation study, we demonstrated the superiority of the motion guidance algorithms for the robot arm movement compared to a naive linear motion, executed by the robot in terms of volumetric accuracy. In a user study on a phantom, we compared conventional 2D ultrasound measurements with our robotic system. The mean volume measurement error of ultrasound expert users could be significantly decreased from 20.85+/-16.10% to only 8.23+/-3.10% compared to the ground truth. This tendency was observed even more in non-expert users where the mean error improvement with the robotic system was measured to be as high as $85\%$ which clearly shows the advantages of the robotic support.
Residual-Guided Learning Representation for Self-Supervised Monocular Depth Estimation
Nov 08, 2021Photometric consistency loss is one of the representative objective functions commonly used for self-supervised monocular depth estimation. However, this loss often causes unstable depth predictions in textureless or occluded regions due to incorrect guidance. Recent self-supervised learning approaches tackle this issue by utilizing feature representations explicitly learned from auto-encoders, expecting better discriminability than the input image. Despite the use of auto-encoded features, we observe that the method does not embed features as discriminative as auto-encoded features. In this paper, we propose residual guidance loss that enables the depth estimation network to embed the discriminative feature by transferring the discriminability of auto-encoded features. We conducted experiments on the KITTI benchmark and verified our method's superiority and orthogonality on other state-of-the-art methods.
Anomaly Detection using Capsule Networks for High-dimensional Datasets
Dec 27, 2021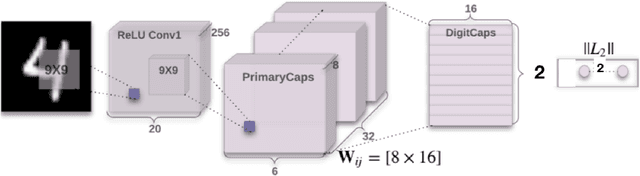
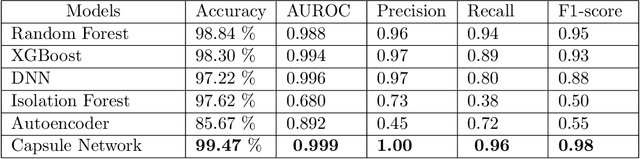
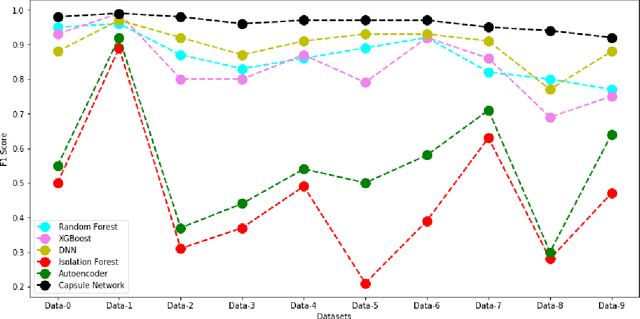
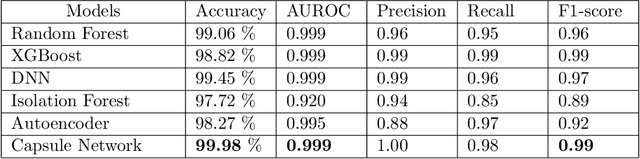
Anomaly detection is an essential problem in machine learning. Application areas include network security, health care, fraud detection, etc., involving high-dimensional datasets. A typical anomaly detection system always faces the class-imbalance problem in the form of a vast difference in the sample sizes of different classes. They usually have class overlap problems. This study used a capsule network for the anomaly detection task. To the best of our knowledge, this is the first instance where a capsule network is analyzed for the anomaly detection task in a high-dimensional non-image complex data setting. We also handle the related novelty and outlier detection problems. The architecture of the capsule network was suitably modified for a binary classification task. Capsule networks offer a good option for detecting anomalies due to the effect of viewpoint invariance captured in its predictions and viewpoint equivariance captured in internal capsule architecture. We used six-layered under-complete autoencoder architecture with second and third layers containing capsules. The capsules were trained using the dynamic routing algorithm. We created $10$-imbalanced datasets from the original MNIST dataset and compared the performance of the capsule network with $5$ baseline models. Our leading test set measures are F1-score for minority class and area under the ROC curve. We found that the capsule network outperformed every other baseline model on the anomaly detection task by using only ten epochs for training and without using any other data level and algorithm level approach. Thus, we conclude that capsule networks are excellent in modeling complex high-dimensional imbalanced datasets for the anomaly detection task.
Improving Model Generalization by Agreement of Learned Representations from Data Augmentation
Oct 20, 2021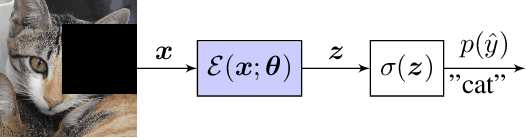
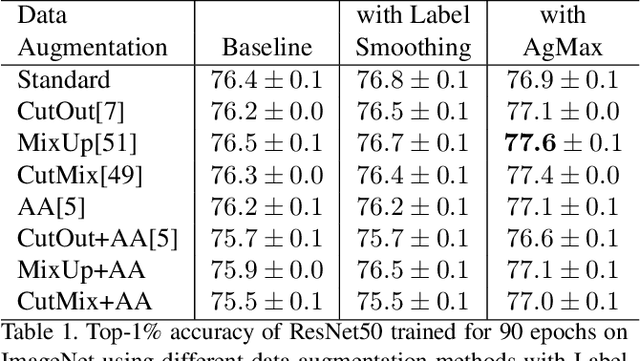
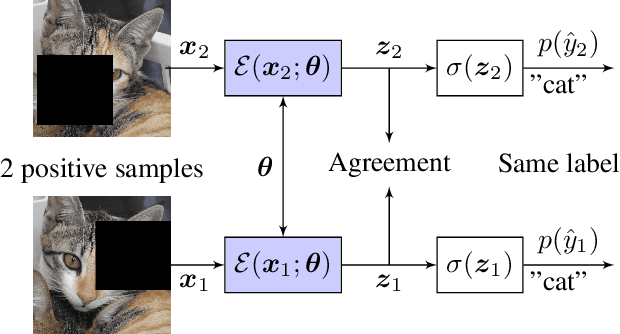
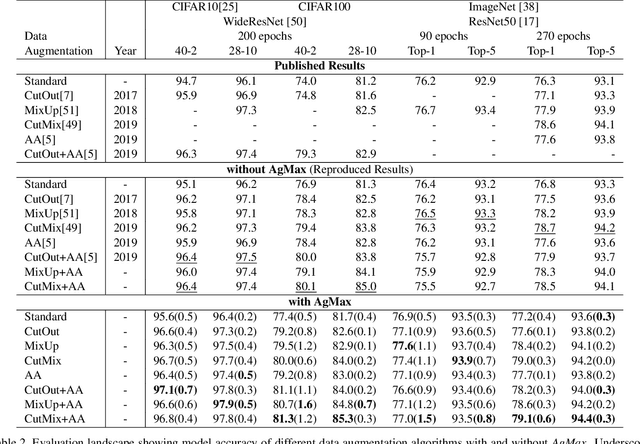
Data augmentation reduces the generalization error by forcing a model to learn invariant representations given different transformations of the input image. In computer vision, on top of the standard image processing functions, data augmentation techniques based on regional dropout such as CutOut, MixUp, and CutMix and policy-based selection such as AutoAugment demonstrated state-of-the-art (SOTA) results. With an increasing number of data augmentation algorithms being proposed, the focus is always on optimizing the input-output mapping while not realizing that there might be an untapped value in the transformed images with the same label. We hypothesize that by forcing the representations of two transformations to agree, we can further reduce the model generalization error. We call our proposed method Agreement Maximization or simply AgMax. With this simple constraint applied during training, empirical results show that data augmentation algorithms can further improve the classification accuracy of ResNet50 on ImageNet by up to 1.5%, WideResNet40-2 on CIFAR10 by up to 0.7%, WideResNet40-2 on CIFAR100 by up to 1.6%, and LeNet5 on Speech Commands Dataset by up to 1.4%. Experimental results further show that unlike other regularization terms such as label smoothing, AgMax can take advantage of the data augmentation to consistently improve model generalization by a significant margin. On downstream tasks such as object detection and segmentation on PascalVOC and COCO, AgMax pre-trained models outperforms other data augmentation methods by as much as 1.0mAP (box) and 0.5mAP (mask). Code is available at https://github.com/roatienza/agmax.
Morphology Decoder: A Machine Learning Guided 3D Vision Quantifying Heterogenous Rock Permeability for Planetary Surveillance and Robotic Functions
Nov 26, 2021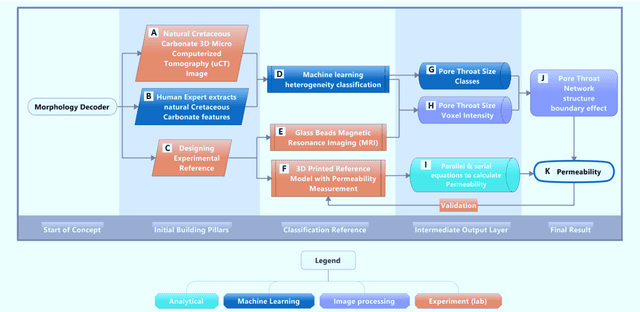

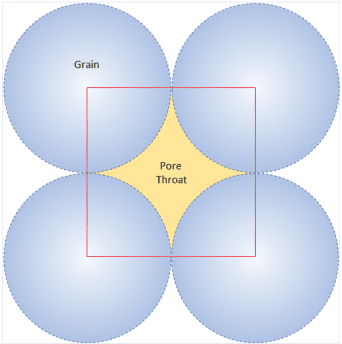

Permeability has a dominant influence on the flow properties of a natural fluid. Lattice Boltzmann simulator determines permeability from the nano and micropore network. The simulator holds millions of flow dynamics calculations with its accumulated errors and high consumption of computing power. To efficiently and consistently predict permeability, we propose a morphology decoder, a parallel and serial flow reconstruction of machine learning segmented heterogeneous Cretaceous texture from 3D micro computerized tomography and nuclear magnetic resonance images. For 3D vision, we introduce controllable-measurable-volume as new supervised segmentation, in which a unique set of voxel intensity corresponds to grain and pore throat sizes. The morphology decoder demarks and aggregates the morphologies boundaries in a novel way to produce permeability. Morphology decoder method consists of five novel processes, which describes in this paper, these novel processes are: (1) Geometrical 3D Permeability, (2) Machine Learning guided 3D Properties Recognition of Rock Morphology, (3) 3D Image Properties Integration Model for Permeability, (4) MRI Permeability Imager, and (5) Morphology Decoder (the process that integrates the other four novel processes).
One-Shot Image-to-Image Translation via Part-Global Learning with a Multi-adversarial Framework
May 12, 2019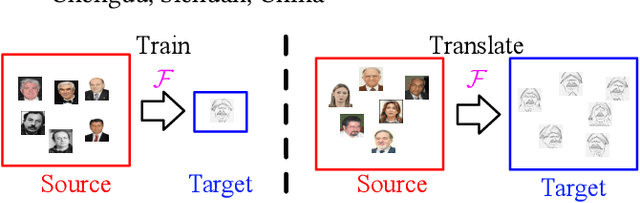
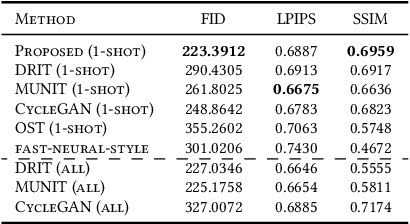
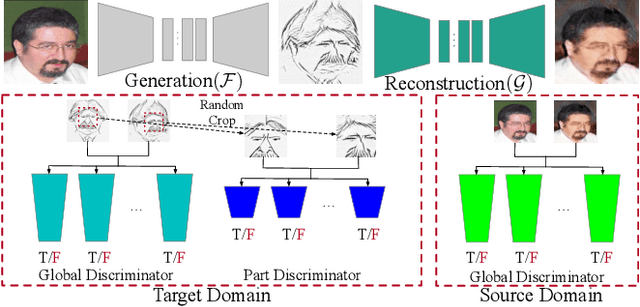
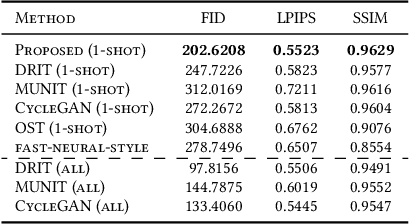
It is well known that humans can learn and recognize objects effectively from several limited image samples. However, learning from just a few images is still a tremendous challenge for existing main-stream deep neural networks. Inspired by analogical reasoning in the human mind, a feasible strategy is to translate the abundant images of a rich source domain to enrich the relevant yet different target domain with insufficient image data. To achieve this goal, we propose a novel, effective multi-adversarial framework (MA) based on part-global learning, which accomplishes one-shot cross-domain image-to-image translation. In specific, we first devise a part-global adversarial training scheme to provide an efficient way for feature extraction and prevent discriminators being over-fitted. Then, a multi-adversarial mechanism is employed to enhance the image-to-image translation ability to unearth the high-level semantic representation. Moreover, a balanced adversarial loss function is presented, which aims to balance the training data and stabilize the training process. Extensive experiments demonstrate that the proposed approach can obtain impressive results on various datasets between two extremely imbalanced image domains and outperform state-of-the-art methods on one-shot image-to-image translation.
Towards Explainable End-to-End Prostate Cancer Relapse Prediction from H&E Images Combining Self-Attention Multiple Instance Learning with a Recurrent Neural Network
Nov 26, 2021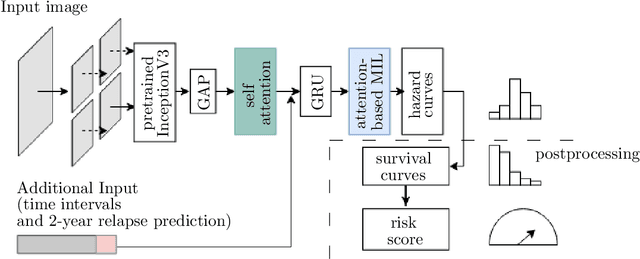
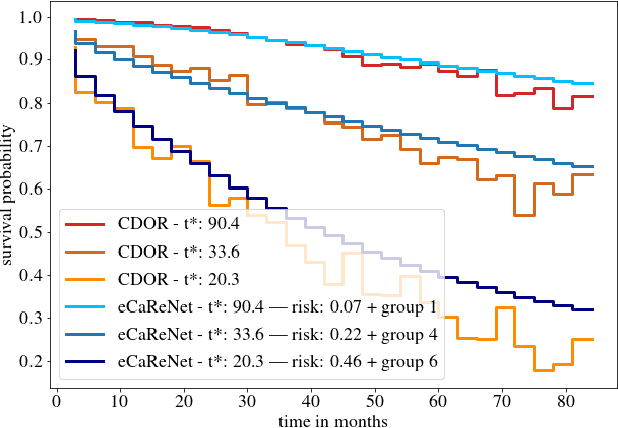
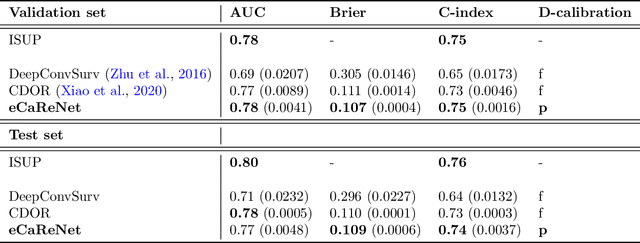
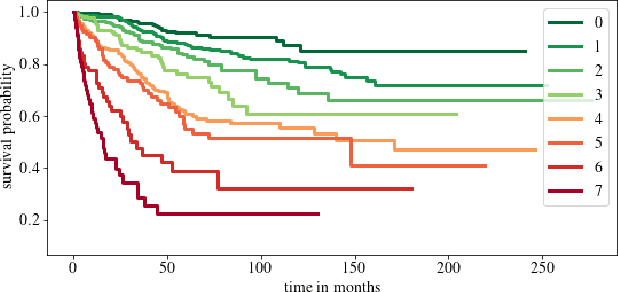
Clinical decision support for histopathology image data mainly focuses on strongly supervised annotations, which offers intuitive interpretability, but is bound by expert performance. Here, we propose an explainable cancer relapse prediction network (eCaReNet) and show that end-to-end learning without strong annotations offers state-of-the-art performance while interpretability can be included through an attention mechanism. On the use case of prostate cancer survival prediction, using 14,479 images and only relapse times as annotations, we reach a cumulative dynamic AUC of 0.78 on a validation set, being on par with an expert pathologist (and an AUC of 0.77 on a separate test set). Our model is well-calibrated and outputs survival curves as well as a risk score and group per patient. Making use of the attention weights of a multiple instance learning layer, we show that malignant patches have a higher influence on the prediction than benign patches, thus offering an intuitive interpretation of the prediction. Our code is available at www.github.com/imsb-uke/ecarenet.
Adversarial Machine Learning in Image Classification: A Survey Towards the Defender's Perspective
Sep 08, 2020
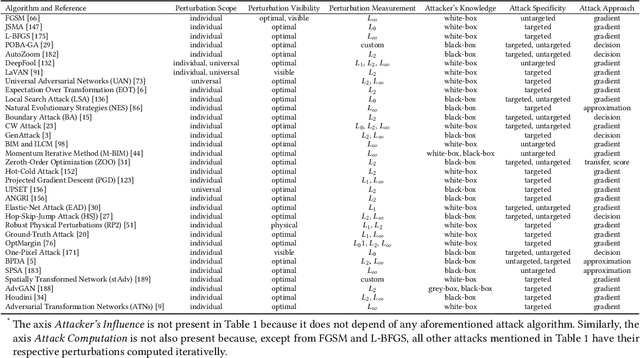
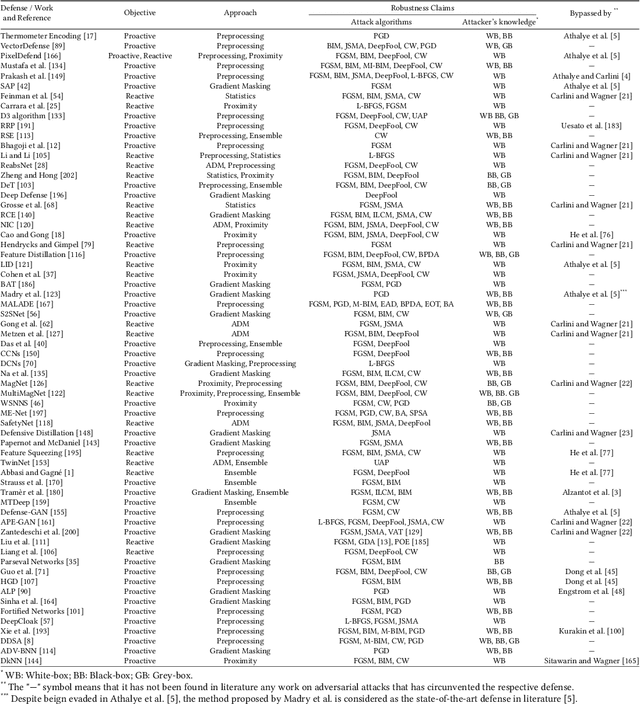
Deep Learning algorithms have achieved the state-of-the-art performance for Image Classification and have been used even in security-critical applications, such as biometric recognition systems and self-driving cars. However, recent works have shown those algorithms, which can even surpass the human capabilities, are vulnerable to adversarial examples. In Computer Vision, adversarial examples are images containing subtle perturbations generated by malicious optimization algorithms in order to fool classifiers. As an attempt to mitigate these vulnerabilities, numerous countermeasures have been constantly proposed in literature. Nevertheless, devising an efficient defense mechanism has proven to be a difficult task, since many approaches have already shown to be ineffective to adaptive attackers. Thus, this self-containing paper aims to provide all readerships with a review of the latest research progress on Adversarial Machine Learning in Image Classification, however with a defender's perspective. Here, novel taxonomies for categorizing adversarial attacks and defenses are introduced and discussions about the existence of adversarial examples are provided. Further, in contrast to exisiting surveys, it is also given relevant guidance that should be taken into consideration by researchers when devising and evaluating defenses. Finally, based on the reviewed literature, it is discussed some promising paths for future research.
Meta Adversarial Perturbations
Nov 19, 2021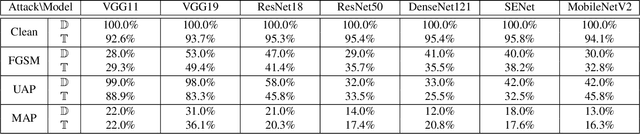
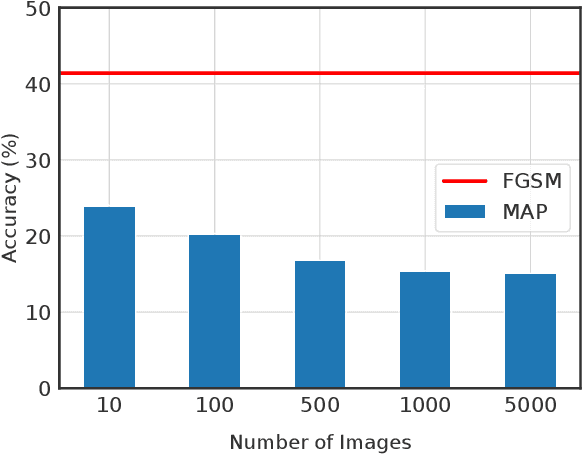
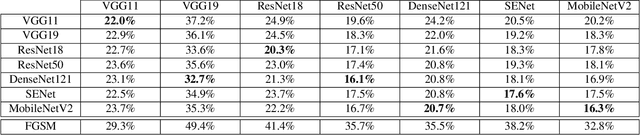
A plethora of attack methods have been proposed to generate adversarial examples, among which the iterative methods have been demonstrated the ability to find a strong attack. However, the computation of an adversarial perturbation for a new data point requires solving a time-consuming optimization problem from scratch. To generate a stronger attack, it normally requires updating a data point with more iterations. In this paper, we show the existence of a meta adversarial perturbation (MAP), a better initialization that causes natural images to be misclassified with high probability after being updated through only a one-step gradient ascent update, and propose an algorithm for computing such perturbations. We conduct extensive experiments, and the empirical results demonstrate that state-of-the-art deep neural networks are vulnerable to meta perturbations. We further show that these perturbations are not only image-agnostic, but also model-agnostic, as a single perturbation generalizes well across unseen data points and different neural network architectures.
Image Generation Via Minimizing Fréchet Distance in Discriminator Feature Space
Mar 30, 2020
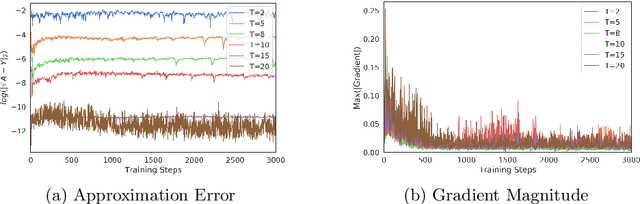
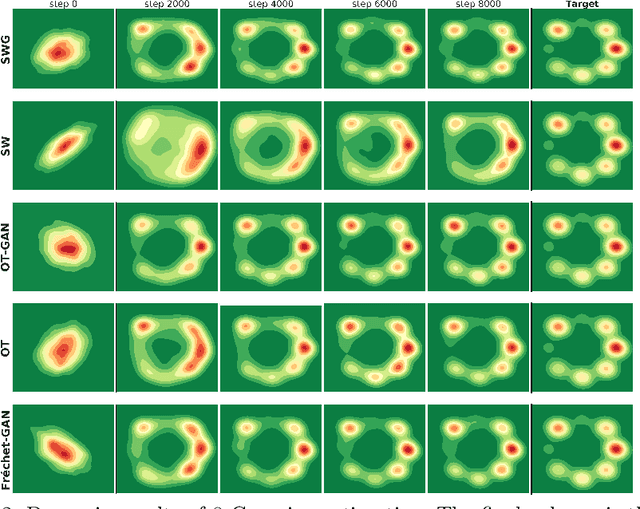
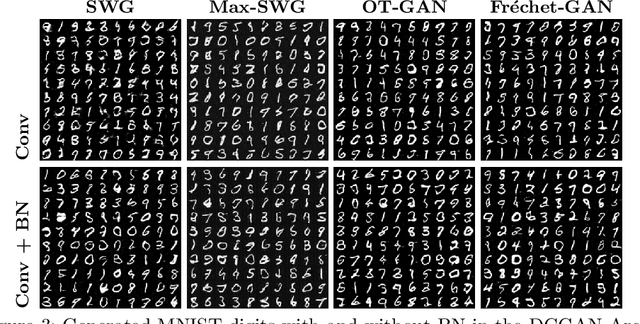
For a given image generation problem, the intrinsic image manifold is often low dimensional. We use the intuition that it is much better to train the GAN generator by minimizing the distributional distance between real and generated images in a small dimensional feature space representing such a manifold than on the original pixel-space. We use the feature space of the GAN discriminator for such a representation. For distributional distance, we employ one of two choices: the Fr\'{e}chet distance or direct optimal transport (OT); these respectively lead us to two new GAN methods: Fr\'{e}chet-GAN and OT-GAN. The idea of employing Fr\'{e}chet distance comes from the success of Fr\'{e}chet Inception Distance as a solid evaluation metric in image generation. Fr\'{e}chet-GAN is attractive in several ways. We propose an efficient, numerically stable approach to calculate the Fr\'{e}chet distance and its gradient. The Fr\'{e}chet distance estimation requires a significantly less computation time than OT; this allows Fr\'{e}chet-GAN to use much larger mini-batch size in training than OT. More importantly, we conduct experiments on a number of benchmark datasets and show that Fr\'{e}chet-GAN (in particular) and OT-GAN have significantly better image generation capabilities than the existing representative primal and dual GAN approaches based on the Wasserstein distance.