 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Symmetric Skip Connection Wasserstein GAN for High-Resolution Facial Image Inpainting
Jan 11, 2020

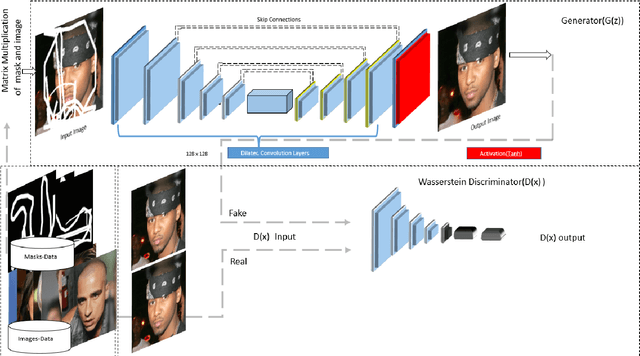
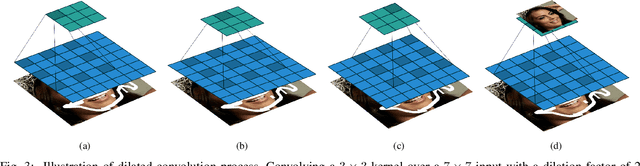

We propose a Symmetric Skip Connection Wasserstein Generative Adversarial Network (S-WGAN) for high-resolution facial image inpainting. The architecture is an encoder-decoder with convolutional blocks, linked by skip connections. The encoder is a feature extractor that captures data abstractions of an input image to learn an end-to-end mapping from an input (binary masked image) to the ground-truth. The decoder uses the learned abstractions to reconstruct the image. With skip connections, S-WGAN transfers image details to the decoder. Also, we propose a Wasserstein-Perceptual loss function to preserve colour and maintain realism on a reconstructed image. We evaluate our method and the state-of-the-art methods on CelebA-HQ dataset. Our results show S-WGAN produces sharper and more realistic images when visually compared with other methods. The quantitative measures show our proposed S-WGAN achieves the best Structure Similarity Index Measure of 0.94.
RadFusion: Benchmarking Performance and Fairness for Multimodal Pulmonary Embolism Detection from CT and EHR
Nov 27, 2021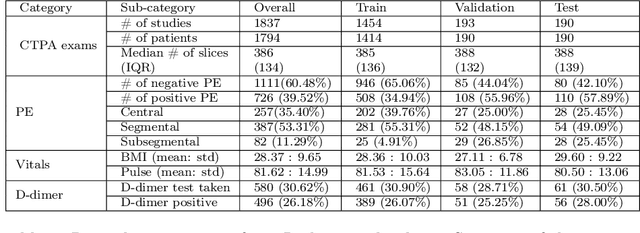
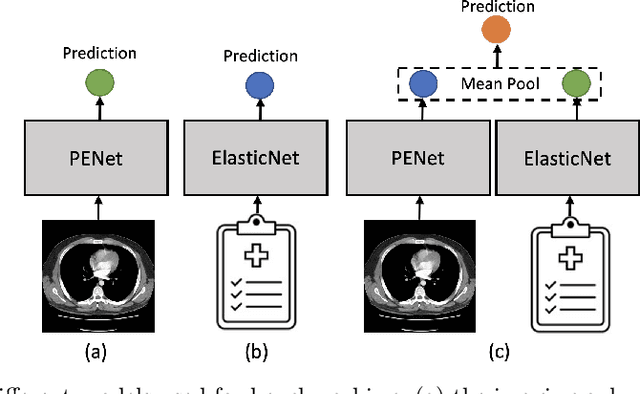
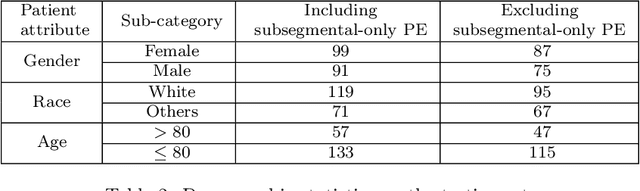
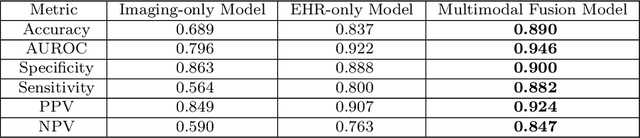
Despite the routine use of electronic health record (EHR) data by radiologists to contextualize clinical history and inform image interpretation, the majority of deep learning architectures for medical imaging are unimodal, i.e., they only learn features from pixel-level information. Recent research revealing how race can be recovered from pixel data alone highlights the potential for serious biases in models which fail to account for demographics and other key patient attributes. Yet the lack of imaging datasets which capture clinical context, inclusive of demographics and longitudinal medical history, has left multimodal medical imaging underexplored. To better assess these challenges, we present RadFusion, a multimodal, benchmark dataset of 1794 patients with corresponding EHR data and high-resolution computed tomography (CT) scans labeled for pulmonary embolism. We evaluate several representative multimodal fusion models and benchmark their fairness properties across protected subgroups, e.g., gender, race/ethnicity, age. Our results suggest that integrating imaging and EHR data can improve classification performance and robustness without introducing large disparities in the true positive rate between population groups.
Binarized P-Network: Deep Reinforcement Learning of Robot Control from Raw Images on FPGA
Sep 10, 2021This paper explores a Deep Reinforcement Learning (DRL) approach for designing image-based control for edge robots to be implemented on Field Programmable Gate Arrays (FPGAs). Although FPGAs are more power-efficient than CPUs and GPUs, a typical (DRL) method cannot be applied since they are composed of many Logic Blocks (LBs) for high-speed logical operations but low-speed real-number operations. To cope with this problem, we propose a novel DRL algorithm called Binarized P-Network (BPN), which learns image-input control policies using Binarized Convolutional Neural Networks (BCNNs). To alleviate the instability of reinforcement learning caused by a BCNN with low function approximation accuracy, our BPN adopts a robust value update scheme called Conservative Value Iteration, which is tolerant of function approximation errors. We confirmed the BPN's effectiveness through applications to a visual tracking task in simulation and real-robot experiments with FPGA.
Image Generation Via Minimizing Fréchet Distance in Discriminator Feature Space
Mar 30, 2020
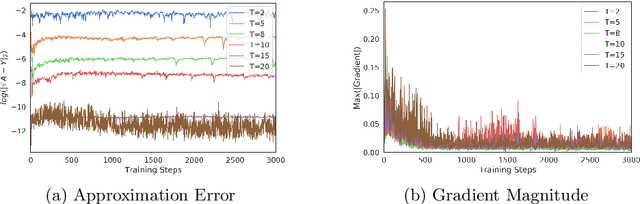
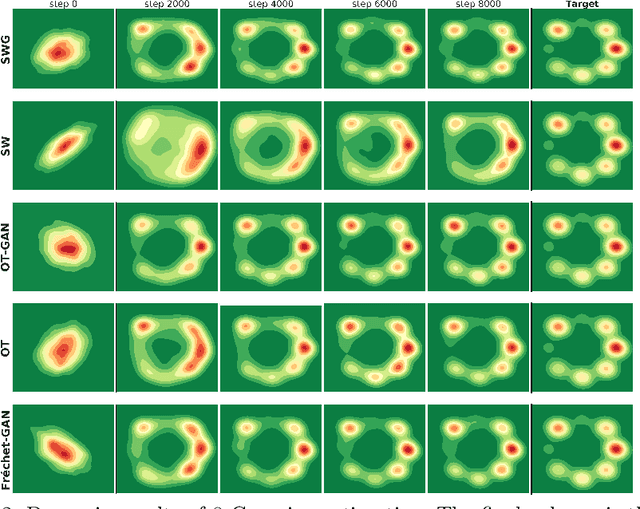
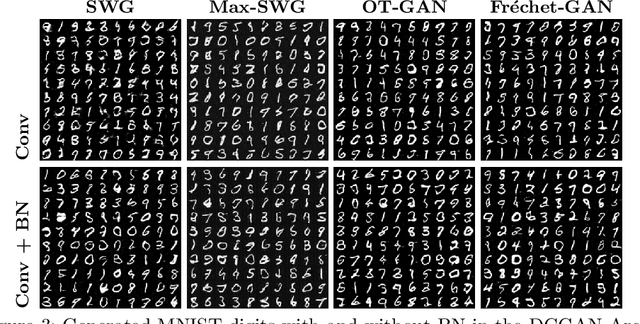
For a given image generation problem, the intrinsic image manifold is often low dimensional. We use the intuition that it is much better to train the GAN generator by minimizing the distributional distance between real and generated images in a small dimensional feature space representing such a manifold than on the original pixel-space. We use the feature space of the GAN discriminator for such a representation. For distributional distance, we employ one of two choices: the Fr\'{e}chet distance or direct optimal transport (OT); these respectively lead us to two new GAN methods: Fr\'{e}chet-GAN and OT-GAN. The idea of employing Fr\'{e}chet distance comes from the success of Fr\'{e}chet Inception Distance as a solid evaluation metric in image generation. Fr\'{e}chet-GAN is attractive in several ways. We propose an efficient, numerically stable approach to calculate the Fr\'{e}chet distance and its gradient. The Fr\'{e}chet distance estimation requires a significantly less computation time than OT; this allows Fr\'{e}chet-GAN to use much larger mini-batch size in training than OT. More importantly, we conduct experiments on a number of benchmark datasets and show that Fr\'{e}chet-GAN (in particular) and OT-GAN have significantly better image generation capabilities than the existing representative primal and dual GAN approaches based on the Wasserstein distance.
Upgrading the Newsroom: An Automated Image Selection System for News Articles
Apr 23, 2020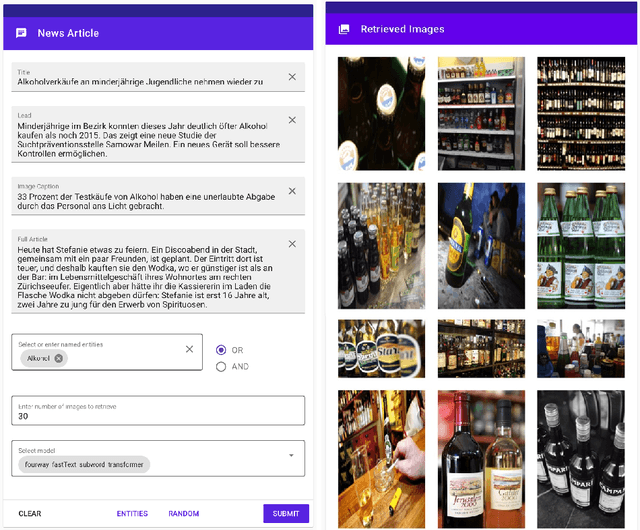
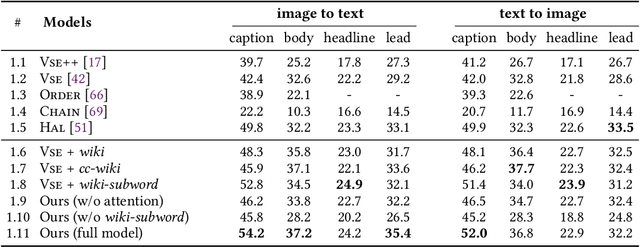
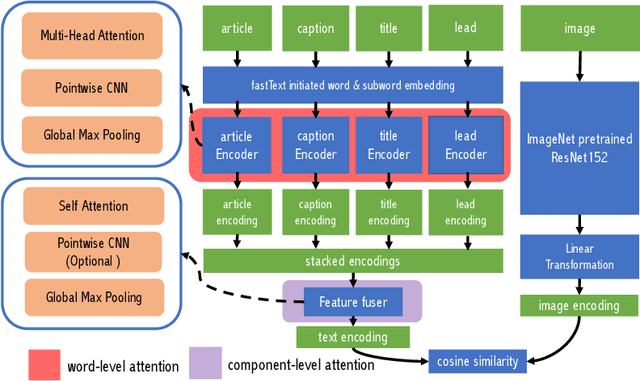
We propose an automated image selection system to assist photo editors in selecting suitable images for news articles. The system fuses multiple textual sources extracted from news articles and accepts multilingual inputs. It is equipped with char-level word embeddings to help both modeling morphologically rich languages, e.g. German, and transferring knowledge across nearby languages. The text encoder adopts a hierarchical self-attention mechanism to attend more to both keywords within a piece of text and informative components of a news article. We extensively experiment with our system on a large-scale text-image database containing multimodal multilingual news articles collected from Swiss local news media websites. The system is compared with multiple baselines with ablation studies and is shown to beat existing text-image retrieval methods in a weakly-supervised learning setting. Besides, we also offer insights on the advantage of using multiple textual sources and multilingual data.
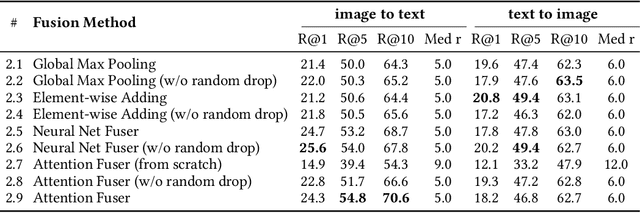
Aligning Visual Regions and Textual Concepts: Learning Fine-Grained Image Representations for Image Captioning
May 15, 2019
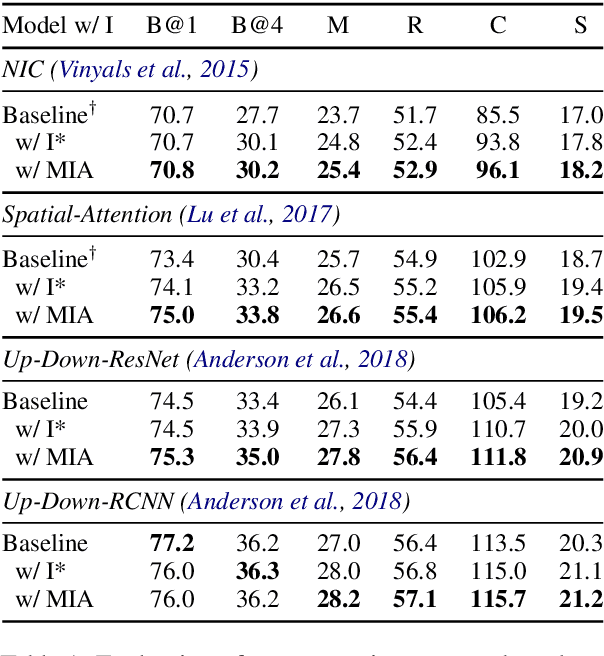
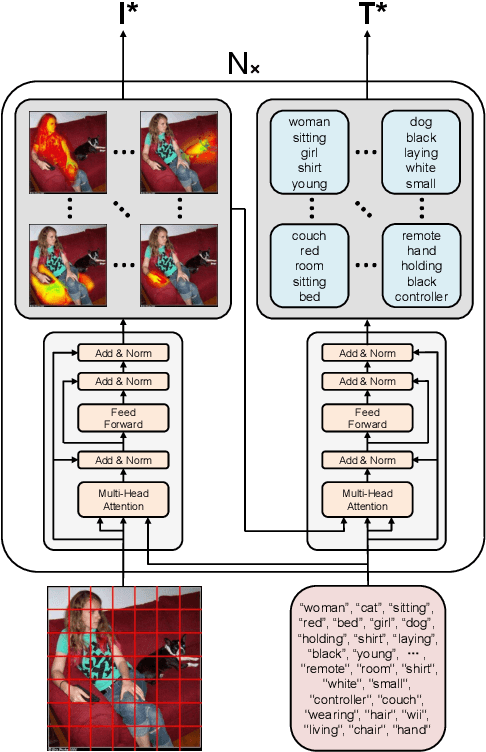
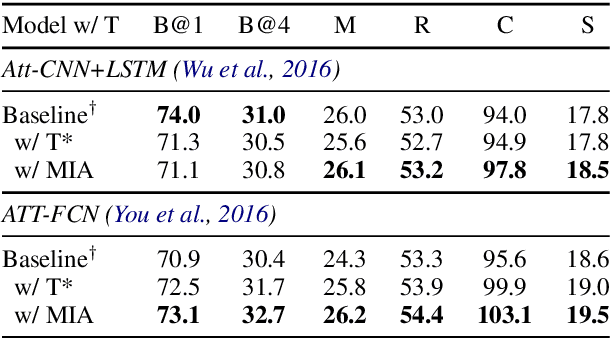
In image-grounded text generation, fine-grained representations of the image are considered to be of paramount importance. Most of the current systems incorporate visual features and textual concepts as a sketch of an image. However, plainly inferred representations are usually undesirable in that they are composed of separate components, the relations of which are elusive. In this work, we aim at representing an image with a set of integrated visual regions and corresponding textual concepts. To this end, we build the Mutual Iterative Attention (MIA) module, which integrates correlated visual features and textual concepts, respectively, by aligning the two modalities. We evaluate the proposed approach on the COCO dataset for image captioning. Extensive experiments show that the refined image representations boost the baseline models by up to 12% in terms of CIDEr, demonstrating that our method is effective and generalizes well to a wide range of models.
Adversarial Machine Learning in Image Classification: A Survey Towards the Defender's Perspective
Sep 08, 2020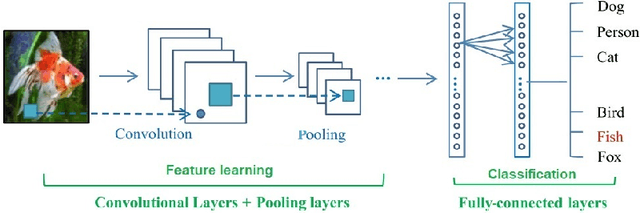
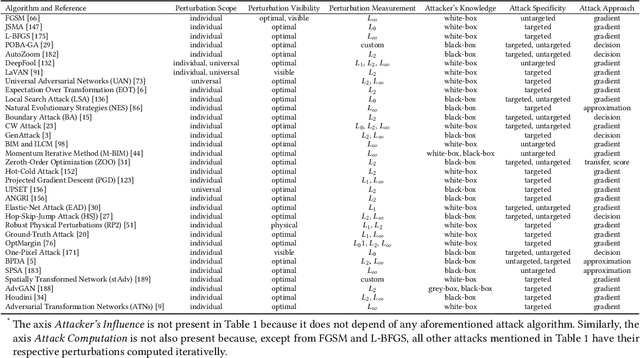
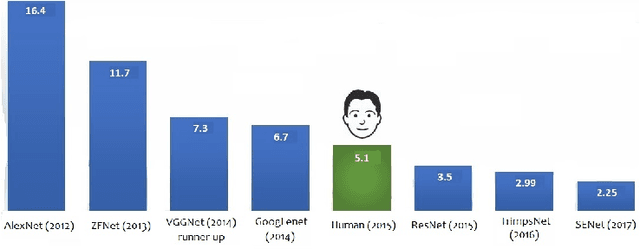
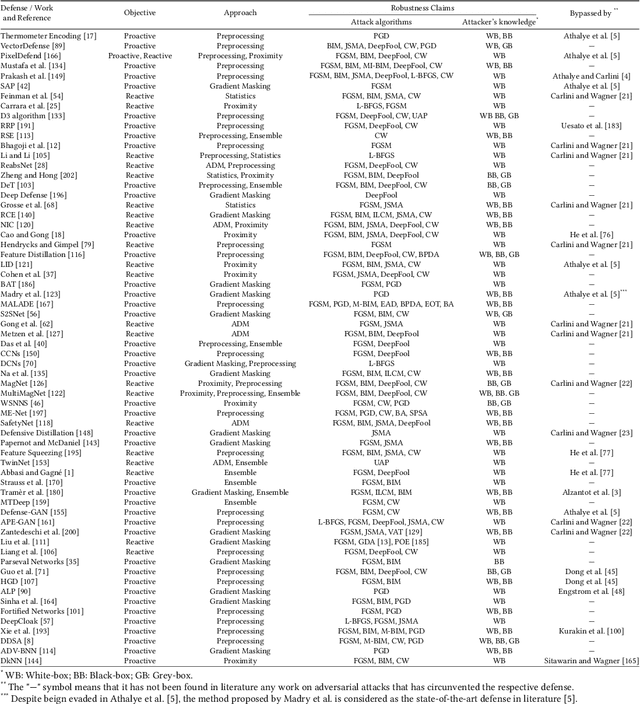
Deep Learning algorithms have achieved the state-of-the-art performance for Image Classification and have been used even in security-critical applications, such as biometric recognition systems and self-driving cars. However, recent works have shown those algorithms, which can even surpass the human capabilities, are vulnerable to adversarial examples. In Computer Vision, adversarial examples are images containing subtle perturbations generated by malicious optimization algorithms in order to fool classifiers. As an attempt to mitigate these vulnerabilities, numerous countermeasures have been constantly proposed in literature. Nevertheless, devising an efficient defense mechanism has proven to be a difficult task, since many approaches have already shown to be ineffective to adaptive attackers. Thus, this self-containing paper aims to provide all readerships with a review of the latest research progress on Adversarial Machine Learning in Image Classification, however with a defender's perspective. Here, novel taxonomies for categorizing adversarial attacks and defenses are introduced and discussions about the existence of adversarial examples are provided. Further, in contrast to exisiting surveys, it is also given relevant guidance that should be taken into consideration by researchers when devising and evaluating defenses. Finally, based on the reviewed literature, it is discussed some promising paths for future research.
Learning Structural Representations for Recipe Generation and Food Retrieval
Oct 04, 2021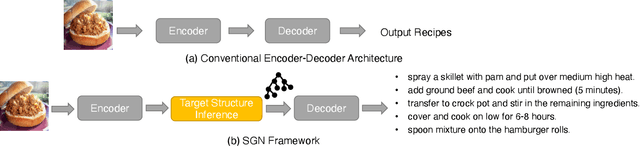
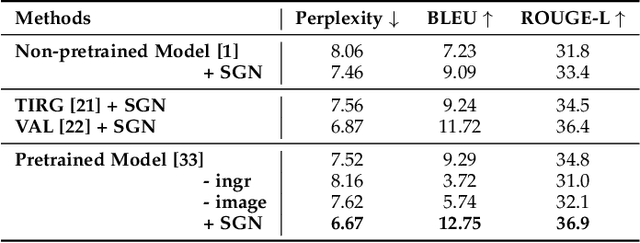
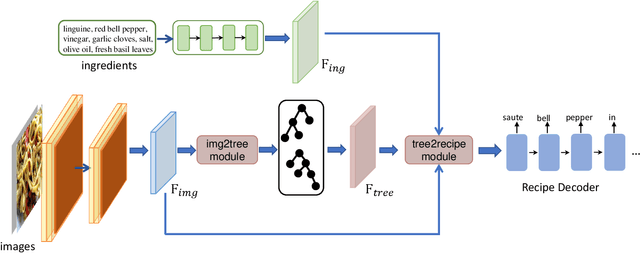
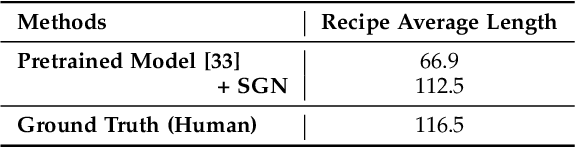
Food is significant to human daily life. In this paper, we are interested in learning structural representations for lengthy recipes, that can benefit the recipe generation and food retrieval tasks. We mainly investigate an open research task of generating cooking instructions based on food images and ingredients, which is similar to the image captioning task. However, compared with image captioning datasets, the target recipes are lengthy paragraphs and do not have annotations on structure information. To address the above limitations, we propose a novel framework of Structure-aware Generation Network (SGN) to tackle the food recipe generation task. Our approach brings together several novel ideas in a systematic framework: (1) exploiting an unsupervised learning approach to obtain the sentence-level tree structure labels before training; (2) generating trees of target recipes from images with the supervision of tree structure labels learned from (1); and (3) integrating the inferred tree structures into the recipe generation procedure. Our proposed model can produce high-quality and coherent recipes, and achieve the state-of-the-art performance on the benchmark Recipe1M dataset. We also validate the usefulness of our learned tree structures in the food cross-modal retrieval task, where the proposed model with tree representations can outperform state-of-the-art benchmark results.
Pediatric Otoscopy Video Screening with Shift Contrastive Anomaly Detection
Oct 25, 2021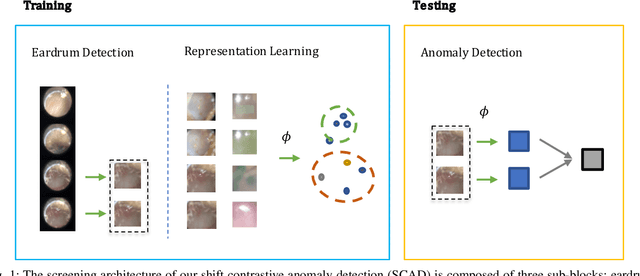
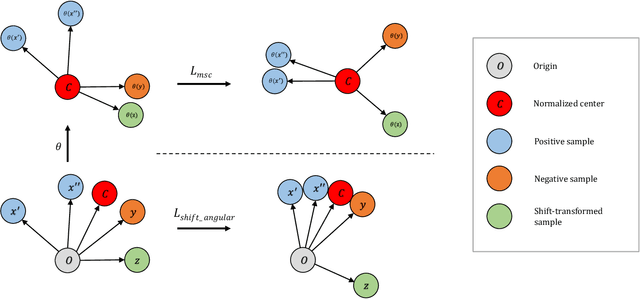

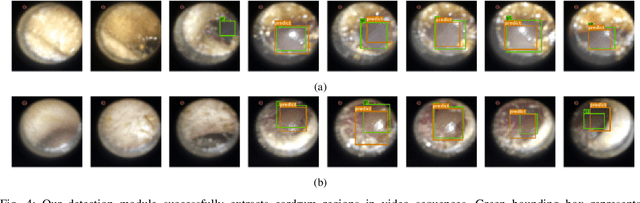
Ear related concerns and symptoms represents the leading indication for seeking pediatric healthcare attention. Despite the high incidence of such encounters, the diagnostic process of commonly encountered disease of the middle and external presents significant challenge. Much of this challenge stems from the lack of cost effective diagnostic testing, which necessitating the presence or absence of ear pathology to be determined clinically. Research has however demonstrated considerable variation among clinicians in their ability to accurately diagnose and consequently manage ear pathology. With recent advances in computer vision and machine learning, there is an increasing interest in helping clinicians to accurately diagnose middle and external ear pathology with computer-aided systems. It has been shown that AI has the capacity to analyse a single clinical image captured during examination of the ear canal and eardrum from which it can determine the likelihood of a pathognomonic pattern for a specific diagnosis being present. The capture of such an image can however be challenging especially to inexperienced clinicians. To help mitigate this technical challenge we have developed and tested a method using video sequences. We present a two stage method that first, identifies valid frames by detecting and extracting ear drum patches from the video sequence, and second, performs the proposed shift contrastive anomaly detection to flag the otoscopy video sequences as normal or abnormal. Our method achieves an AUROC of 88.0% on the patient-level and also outperforms the average of a group of 25 clinicians in a comparative study, which is the largest of such published to date. We conclude that the presented method achieves a promising first step towards automated analysis of otoscopy video.
Unsupervised Portrait Shadow Removal via Generative Priors
Aug 07, 2021



Portrait images often suffer from undesirable shadows cast by casual objects or even the face itself. While existing methods for portrait shadow removal require training on a large-scale synthetic dataset, we propose the first unsupervised method for portrait shadow removal without any training data. Our key idea is to leverage the generative facial priors embedded in the off-the-shelf pretrained StyleGAN2. To achieve this, we formulate the shadow removal task as a layer decomposition problem: a shadowed portrait image is constructed by the blending of a shadow image and a shadow-free image. We propose an effective progressive optimization algorithm to learn the decomposition process. Our approach can also be extended to portrait tattoo removal and watermark removal. Qualitative and quantitative experiments on a real-world portrait shadow dataset demonstrate that our approach achieves comparable performance with supervised shadow removal methods. Our source code is available at https://github.com/YingqingHe/Shadow-Removal-via-Generative-Priors.