 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AIM 2019 Challenge on Image Demoireing: Dataset and Study
Nov 06, 2019

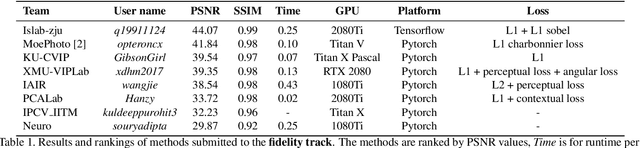

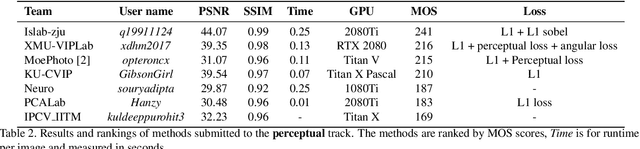
This paper introduces a novel dataset, called LCDMoire, which was created for the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. The dataset comprises 10,200 synthetically generated image pairs (consisting of an image degraded by moire and a clean ground truth image). In addition to describing the dataset and its creation, this paper also reviews the challenge tracks, competition, and results, the latter summarizing the current state-of-the-art on this dataset.
Deep Neuroevolution Squeezes More out of Small Neural Networks and Small Training Sets: Sample Application to MRI Brain Sequence Classification
Dec 24, 2021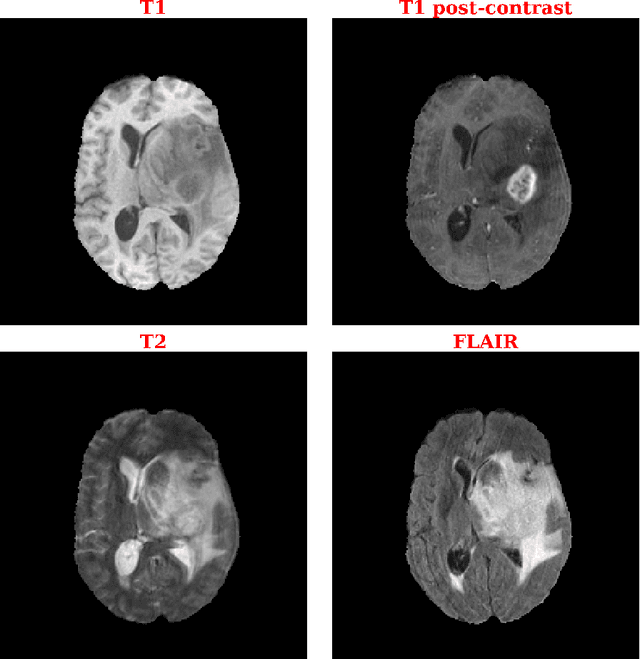

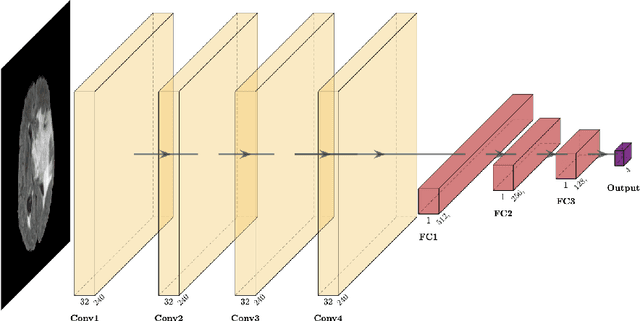
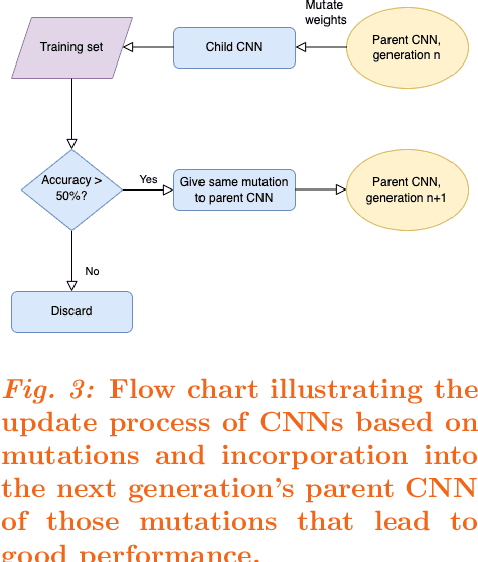
Purpose: Deep Neuroevolution (DNE) holds the promise of providing radiology artificial intelligence (AI) that performs well with small neural networks and small training sets. We seek to realize this potential via a proof-of-principle application to MRI brain sequence classification. Methods: We analyzed a training set of 20 patients, each with four sequences/weightings: T1, T1 post-contrast, T2, and T2-FLAIR. We trained the parameters of a relatively small convolutional neural network (CNN) as follows: First, we randomly mutated the CNN weights. We then measured the CNN training set accuracy, using the latter as the fitness evaluation metric. The fittest child CNNs were identified. We incorporated their mutations into the parent CNN. This selectively mutated parent became the next generation's parent CNN. We repeated this process for approximately 50,000 generations. Results: DNE achieved monotonic convergence to 100% training set accuracy. DNE also converged monotonically to 100% testing set accuracy. Conclusions: DNE can achieve perfect accuracy with small training sets and small CNNs. Particularly when combined with Deep Reinforcement Learning, DNE may provide a path forward in the quest to make radiology AI more human-like in its ability to learn. DNE may very well turn out to be a key component of the much-anticipated meta-learning regime of radiology AI algorithms that can adapt to new tasks and new image types, similar to human radiologists.
Sensor Adversarial Traits: Analyzing Robustness of 3D Object Detection Sensor Fusion Models
Sep 13, 2021
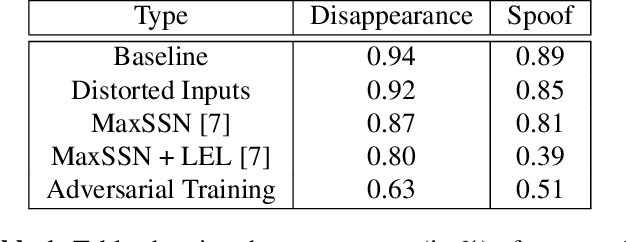

A critical aspect of autonomous vehicles (AVs) is the object detection stage, which is increasingly being performed with sensor fusion models: multimodal 3D object detection models which utilize both 2D RGB image data and 3D data from a LIDAR sensor as inputs. In this work, we perform the first study to analyze the robustness of a high-performance, open source sensor fusion model architecture towards adversarial attacks and challenge the popular belief that the use of additional sensors automatically mitigate the risk of adversarial attacks. We find that despite the use of a LIDAR sensor, the model is vulnerable to our purposefully crafted image-based adversarial attacks including disappearance, universal patch, and spoofing. After identifying the underlying reason, we explore some potential defenses and provide some recommendations for improved sensor fusion models.
Centroid-UNet: Detecting Centroids in Aerial Images
Dec 13, 2021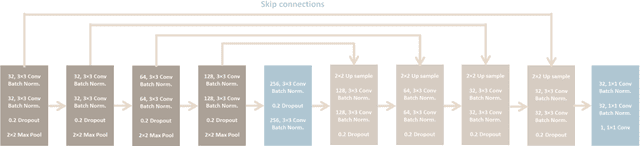
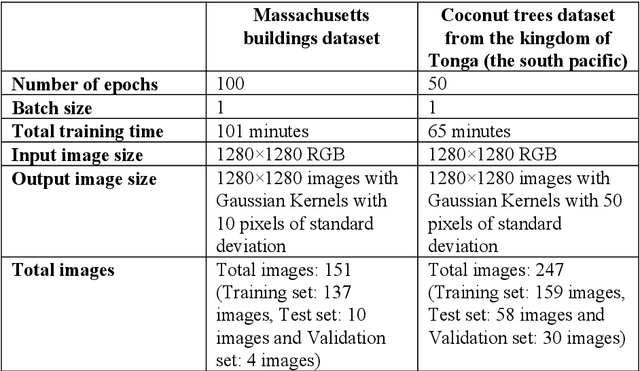

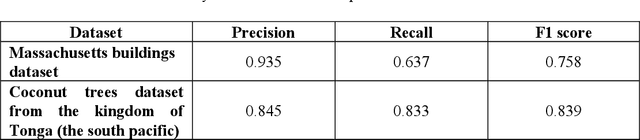
In many applications of aerial/satellite image analysis (remote sensing), the generation of exact shapes of objects is a cumbersome task. In most remote sensing applications such as counting objects requires only location estimation of objects. Hence, locating object centroids in aerial/satellite images is an easy solution for tasks where the object's exact shape is not necessary. Thus, this study focuses on assessing the feasibility of using deep neural networks for locating object centroids in satellite images. Name of our model is Centroid-UNet. The Centroid-UNet model is based on classic U-Net semantic segmentation architecture. We modified and adapted the U-Net semantic segmentation architecture into a centroid detection model preserving the simplicity of the original model. Furthermore, we have tested and evaluated our model with two case studies involving aerial/satellite images. Those two case studies are building centroid detection case study and coconut tree centroid detection case study. Our evaluation results have reached comparably good accuracy compared to other methods, and also offer simplicity. The code and models developed under this study are also available in the Centroid-UNet GitHub repository: https://github.com/gicait/centroid-unet
* Proccedings of the 42nd Asian Conference on Remote Sensing, 2021, Can Tho city, Vietnam
Vision-Language Transformer and Query Generation for Referring Segmentation
Aug 12, 2021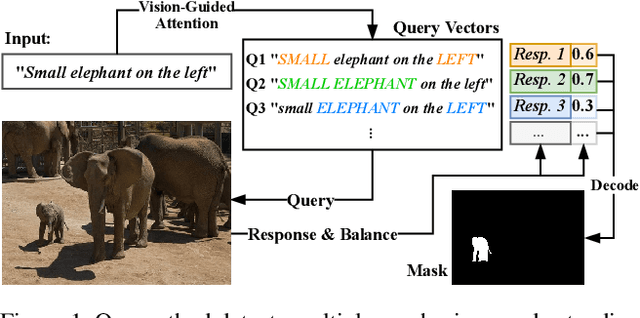
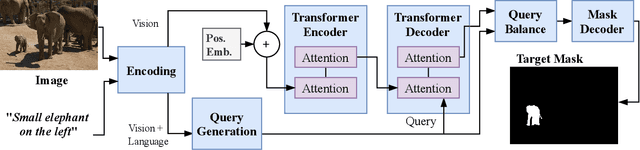
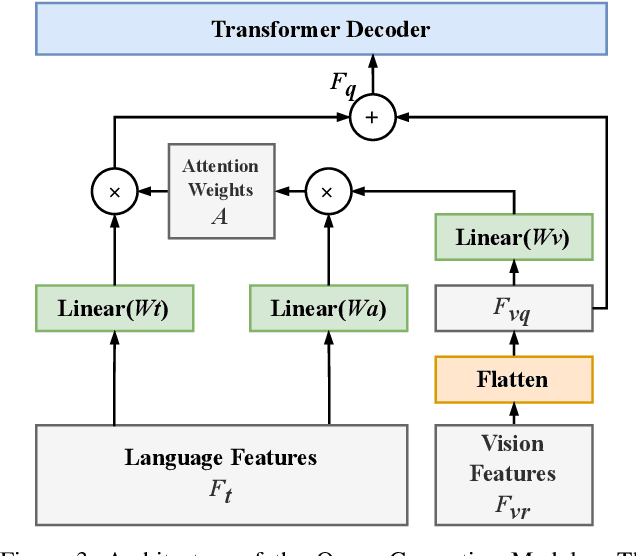
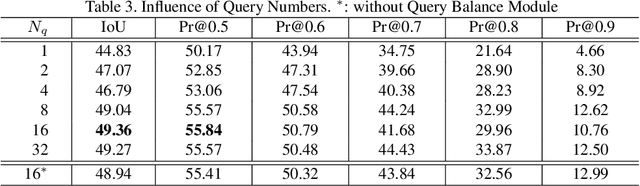
In this work, we address the challenging task of referring segmentation. The query expression in referring segmentation typically indicates the target object by describing its relationship with others. Therefore, to find the target one among all instances in the image, the model must have a holistic understanding of the whole image. To achieve this, we reformulate referring segmentation as a direct attention problem: finding the region in the image where the query language expression is most attended to. We introduce transformer and multi-head attention to build a network with an encoder-decoder attention mechanism architecture that "queries" the given image with the language expression. Furthermore, we propose a Query Generation Module, which produces multiple sets of queries with different attention weights that represent the diversified comprehensions of the language expression from different aspects. At the same time, to find the best way from these diversified comprehensions based on visual clues, we further propose a Query Balance Module to adaptively select the output features of these queries for a better mask generation. Without bells and whistles, our approach is light-weight and achieves new state-of-the-art performance consistently on three referring segmentation datasets, RefCOCO, RefCOCO+, and G-Ref. Our code is available at https://github.com/henghuiding/Vision-Language-Transformer.
Evaluation of Deep Learning Topcoders Method for Neuron Individualization in Histological Macaque Brain Section
Nov 10, 2021
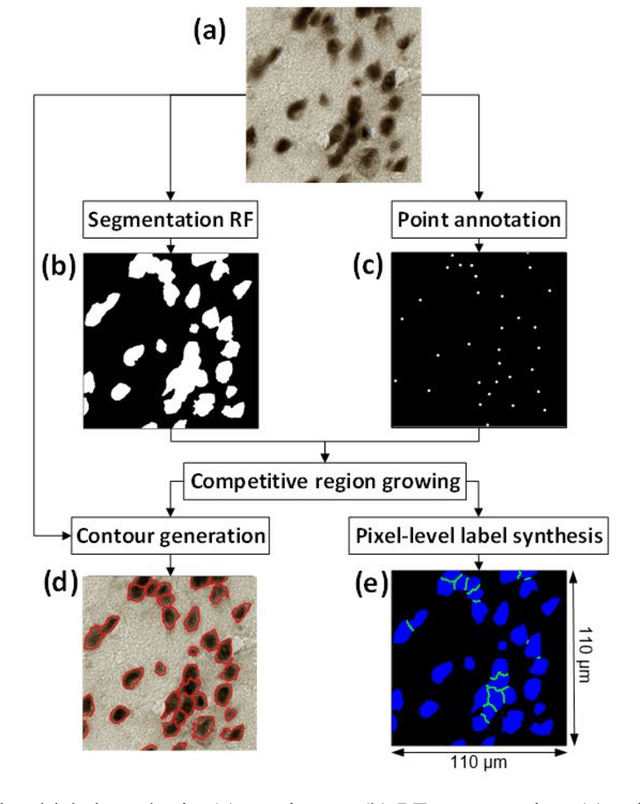

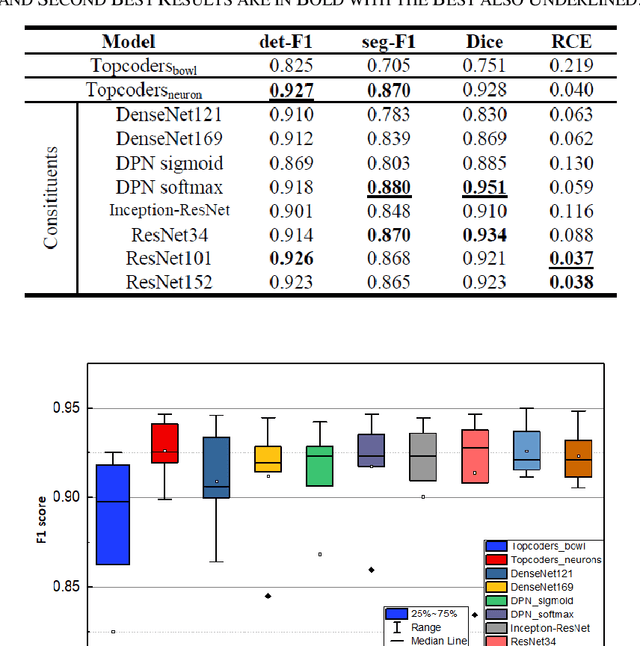
Cell individualization has a vital role in digital pathology image analysis. Deep Learning is considered as an efficient tool for instance segmentation tasks, including cell individualization. However, the precision of the Deep Learning model relies on massive unbiased dataset and manual pixel-level annotations, which is labor intensive. Moreover, most applications of Deep Learning have been developed for processing oncological data. To overcome these challenges, i) we established a pipeline to synthesize pixel-level labels with only point annotations provided; ii) we tested an ensemble Deep Learning algorithm to perform cell individualization on neurological data. Results suggest that the proposed method successfully segments neuronal cells in both object-level and pixel-level, with an average detection accuracy of 0.93.
Handwritten Digit Recognition Using Improved Bounding Box Recognition Technique
Nov 10, 2021
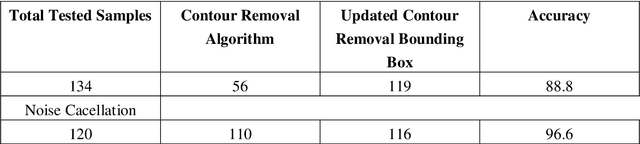
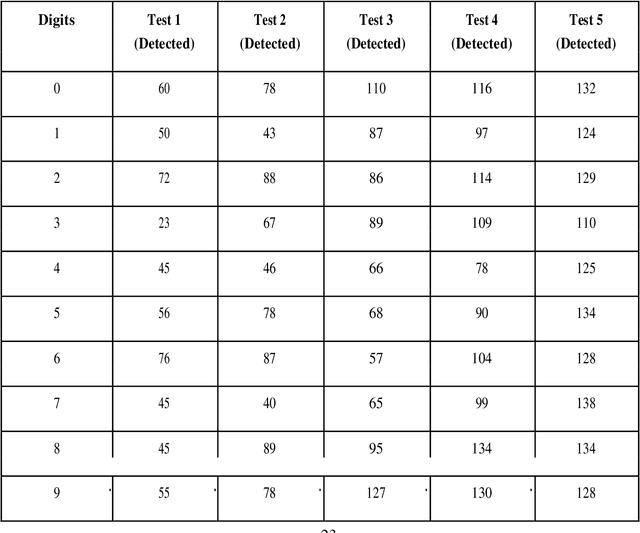
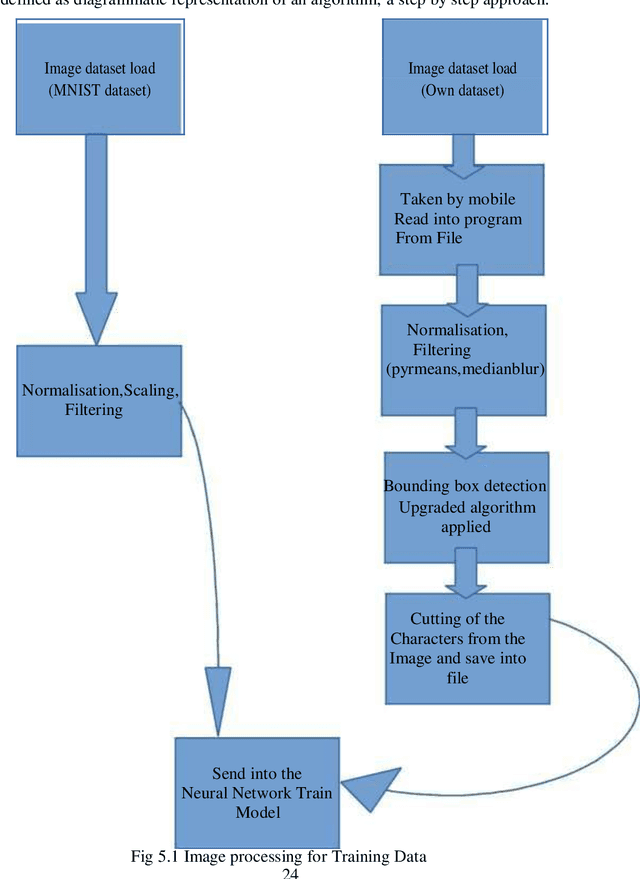
The project comes with the technique of OCR (Optical Character Recognition) which includes various research sides of computer science. The project is to take a picture of a character and process it up to recognize the image of that character like a human brain recognize the various digits. The project contains the deep idea of the Image Processing techniques and the big research area of machine learning and the building block of the machine learning called Neural Network. There are two different parts of the project. Training part comes with the idea of to train a child by giving various sets of similar characters but not the totally same and to say them the output of this is this. Like this idea one has to train the newly built neural network with so many characters. This part contains some new algorithm which is self-created and upgraded as the project need. The testing part contains the testing of a new dataset .This part always comes after the part of the training .At first one has to teach the child how to recognize the character .Then one has to take the test whether he has given right answer or not. If not, one has to train him harder by giving new dataset and new entries. Just like that one has to test the algorithm also. There are many parts of statistical modeling and optimization techniques which come into the project requiring a lot of modeling concept of statistics like optimizer technique and filtering process, that how the mathematics and prediction behind that filtering or the algorithms comes after or which result one actually needs to and ultimately for the prediction of a predictive model creation. Machine learning algorithm is built by concepts of prediction and programming.
FICGAN: Facial Identity Controllable GAN for De-identification
Oct 02, 2021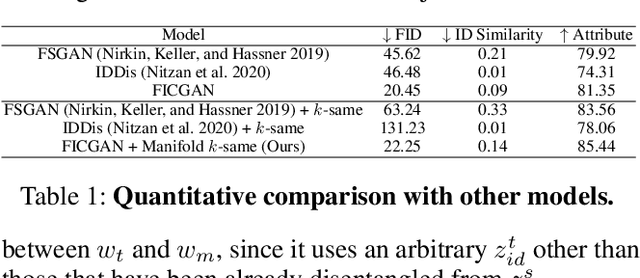
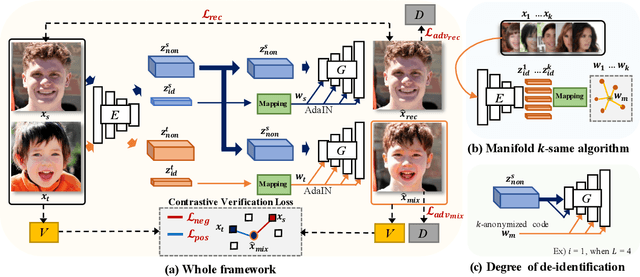


In this work, we present Facial Identity Controllable GAN (FICGAN) for not only generating high-quality de-identified face images with ensured privacy protection, but also detailed controllability on attribute preservation for enhanced data utility. We tackle the less-explored yet desired functionality in face de-identification based on the two factors. First, we focus on the challenging issue to obtain a high level of privacy protection in the de-identification task while uncompromising the image quality. Second, we analyze the facial attributes related to identity and non-identity and explore the trade-off between the degree of face de-identification and preservation of the source attributes for enhanced data utility. Based on the analysis, we develop Facial Identity Controllable GAN (FICGAN), an autoencoder-based conditional generative model that learns to disentangle the identity attributes from non-identity attributes on a face image. By applying the manifold k-same algorithm to satisfy k-anonymity for strengthened security, our method achieves enhanced privacy protection in de-identified face images. Numerous experiments demonstrate that our model outperforms others in various scenarios of face de-identification.
Imbalanced Image Classification with Complement Cross Entropy
Sep 04, 2020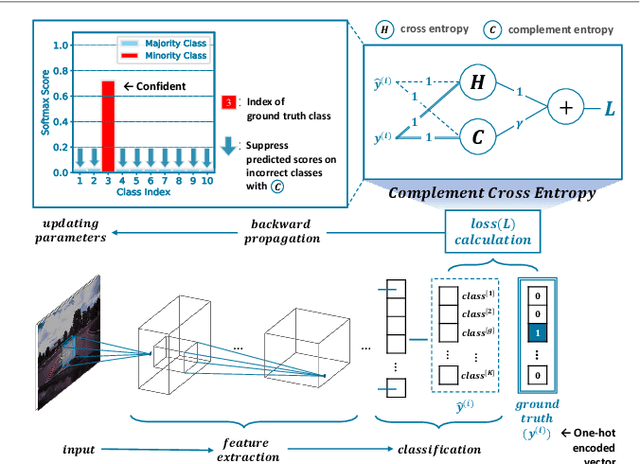

Recently, deep learning models have achieved great success in computer vision applications, relying on large-scale class-balanced datasets. However, imbalanced class distributions still limit the wide applicability of these models due to degradation in performance. To solve this problem, we focus on the study of cross entropy: it mostly ignores output scores on wrong classes. In this work, we discover that neutralizing predicted probabilities on incorrect classes helps improve accuracy of prediction for imbalanced image classification. This paper proposes a simple but effective loss named complement cross entropy (CCE) based on this finding. Our loss makes the ground truth class overwhelm the other classes in terms of softmax probability, by neutralizing probabilities of incorrect classes, without additional training procedures. Along with it, this loss facilitates the models to learn key information especially from samples on minority classes. It ensures more accurate and robust classification results for imbalanced class distributions. Extensive experiments on imbalanced datasets demonstrate the effectiveness of our method compared to other state-of-the-art methods.
Spectral Complexity-scaled Generalization Bound of Complex-valued Neural Networks
Dec 07, 2021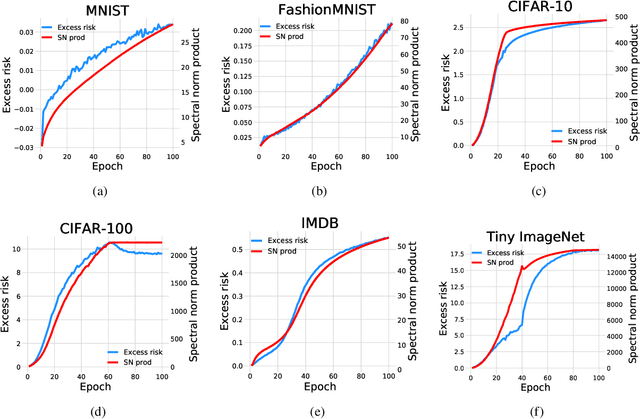
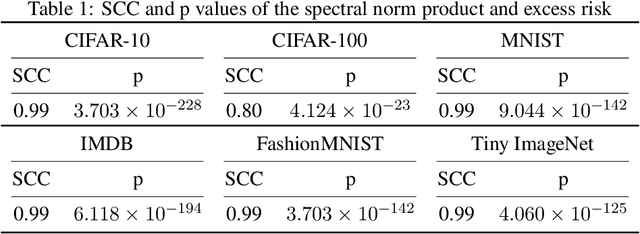
Complex-valued neural networks (CVNNs) have been widely applied to various fields, especially signal processing and image recognition. However, few works focus on the generalization of CVNNs, albeit it is vital to ensure the performance of CVNNs on unseen data. This paper is the first work that proves a generalization bound for the complex-valued neural network. The bound scales with the spectral complexity, the dominant factor of which is the spectral norm product of weight matrices. Further, our work provides a generalization bound for CVNNs when training data is sequential, which is also affected by the spectral complexity. Theoretically, these bounds are derived via Maurey Sparsification Lemma and Dudley Entropy Integral. Empirically, we conduct experiments by training complex-valued convolutional neural networks on different datasets: MNIST, FashionMNIST, CIFAR-10, CIFAR-100, Tiny ImageNet, and IMDB. Spearman's rank-order correlation coefficients and the corresponding p values on these datasets give strong proof that the spectral complexity of the network, measured by the weight matrices spectral norm product, has a statistically significant correlation with the generalization ability.