 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Experimental-based Review of Image Enhancement and Image Restoration Methods for Underwater Imaging
Jul 07, 2019
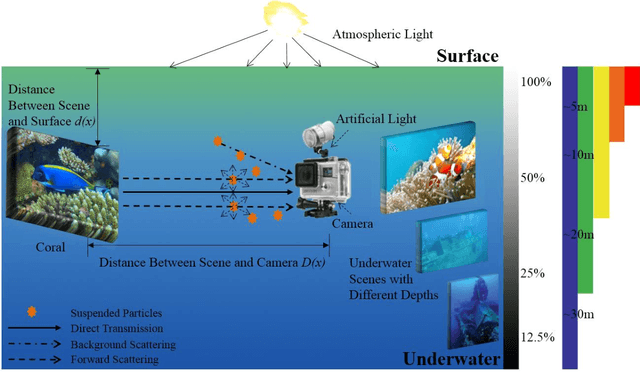

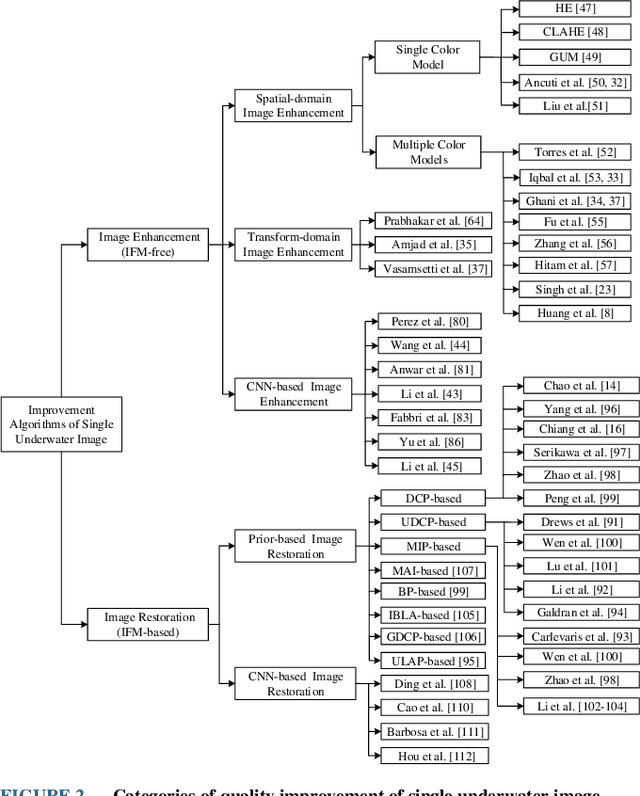
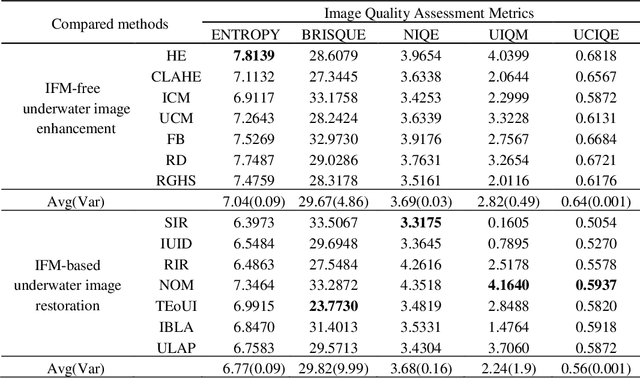
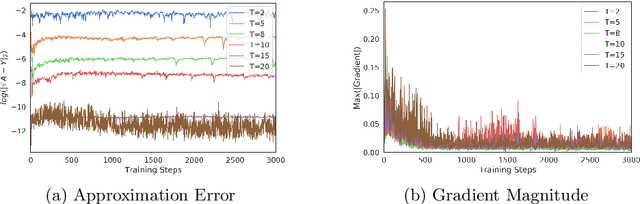
Underwater images play a key role in ocean exploration, but often suffer from severe quality degradation due to light absorption and scattering in water medium. Although major breakthroughs have been made recently in the general area of image enhancement and restoration, the applicability of new methods for improving the quality of underwater images has not specifically been captured. In this paper, we review the image enhancement and restoration methods that tackle typical underwater image impairments, including some extreme degradations and distortions. Firstly, we introduce the key causes of quality reduction in underwater images, in terms of the underwater image formation model (IFM). Then, we review underwater restoration methods, considering both the IFM-free and the IFM-based approaches. Next, we present an experimental-based comparative evaluation of state-of-the-art IFM-free and IFM-based methods, considering also the prior-based parameter estimation algorithms of the IFM-based methods, using both subjective and objective analysis (the used code is freely available at https://github.com/wangyanckxx/Single-Underwater-Image-Enhancement-and-Color-Restoration). Starting from this study, we pinpoint the key shortcomings of existing methods, drawing recommendations for future research in this area. Our review of underwater image enhancement and restoration provides researchers with the necessary background to appreciate challenges and opportunities in this important field.
Image Generation Via Minimizing Fréchet Distance in Discriminator Feature Space
Mar 30, 2020
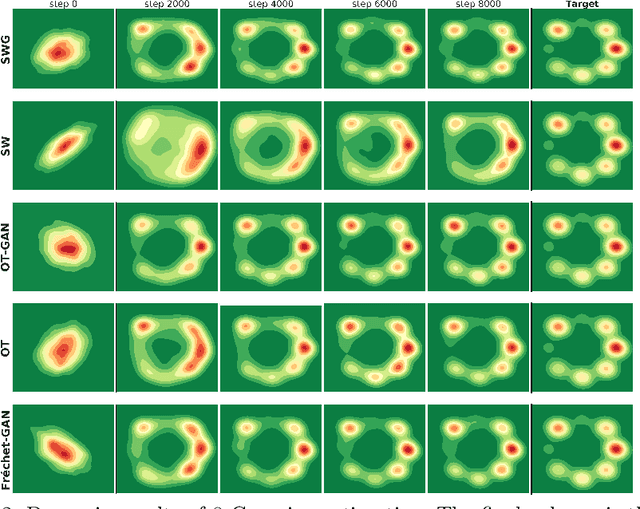
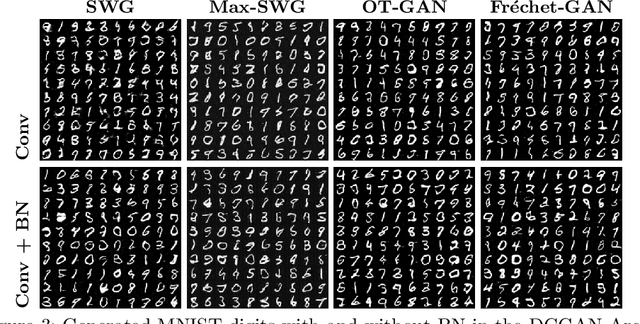
For a given image generation problem, the intrinsic image manifold is often low dimensional. We use the intuition that it is much better to train the GAN generator by minimizing the distributional distance between real and generated images in a small dimensional feature space representing such a manifold than on the original pixel-space. We use the feature space of the GAN discriminator for such a representation. For distributional distance, we employ one of two choices: the Fr\'{e}chet distance or direct optimal transport (OT); these respectively lead us to two new GAN methods: Fr\'{e}chet-GAN and OT-GAN. The idea of employing Fr\'{e}chet distance comes from the success of Fr\'{e}chet Inception Distance as a solid evaluation metric in image generation. Fr\'{e}chet-GAN is attractive in several ways. We propose an efficient, numerically stable approach to calculate the Fr\'{e}chet distance and its gradient. The Fr\'{e}chet distance estimation requires a significantly less computation time than OT; this allows Fr\'{e}chet-GAN to use much larger mini-batch size in training than OT. More importantly, we conduct experiments on a number of benchmark datasets and show that Fr\'{e}chet-GAN (in particular) and OT-GAN have significantly better image generation capabilities than the existing representative primal and dual GAN approaches based on the Wasserstein distance.
Trivial or impossible -- dichotomous data difficulty masks model differences (on ImageNet and beyond)
Oct 12, 2021

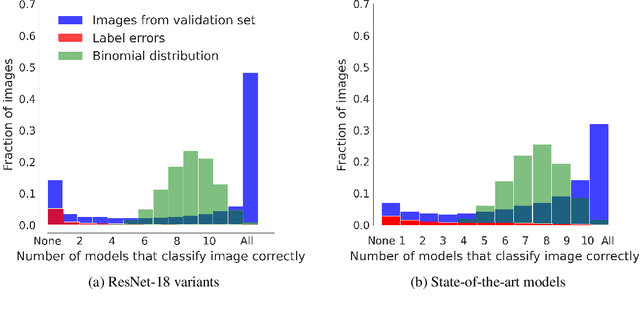
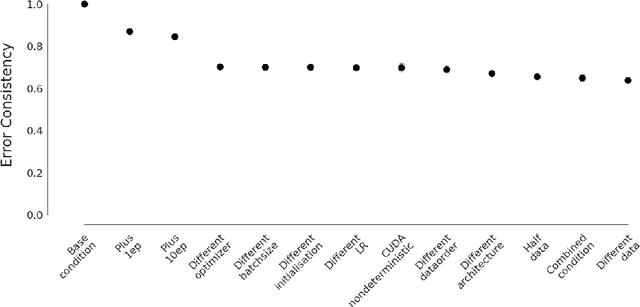
"The power of a generalization system follows directly from its biases" (Mitchell 1980). Today, CNNs are incredibly powerful generalisation systems -- but to what degree have we understood how their inductive bias influences model decisions? We here attempt to disentangle the various aspects that determine how a model decides. In particular, we ask: what makes one model decide differently from another? In a meticulously controlled setting, we find that (1.) irrespective of the network architecture or objective (e.g. self-supervised, semi-supervised, vision transformers, recurrent models) all models end up with a similar decision boundary. (2.) To understand these findings, we analysed model decisions on the ImageNet validation set from epoch to epoch and image by image. We find that the ImageNet validation set, among others, suffers from dichotomous data difficulty (DDD): For the range of investigated models and their accuracies, it is dominated by 46.0% "trivial" and 11.5% "impossible" images (beyond label errors). Only 42.5% of the images could possibly be responsible for the differences between two models' decision boundaries. (3.) Only removing the "impossible" and "trivial" images allows us to see pronounced differences between models. (4.) Humans are highly accurate at predicting which images are "trivial" and "impossible" for CNNs (81.4%). This implies that in future comparisons of brains, machines and behaviour, much may be gained from investigating the decisive role of images and the distribution of their difficulties.
CC-Loss: Channel Correlation Loss For Image Classification
Oct 12, 2020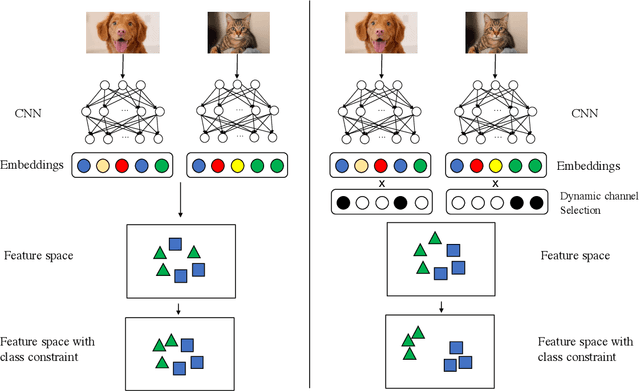

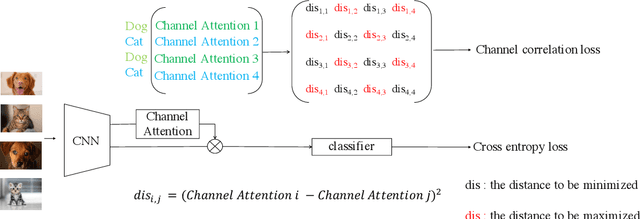
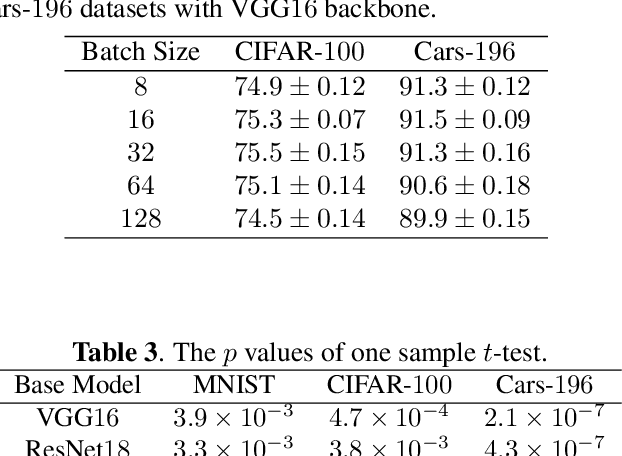
The loss function is a key component in deep learning models. A commonly used loss function for classification is the cross entropy loss, which is a simple yet effective application of information theory for classification problems. Based on this loss, many other loss functions have been proposed,~\emph{e.g.}, by adding intra-class and inter-class constraints to enhance the discriminative ability of the learned features. However, these loss functions fail to consider the connections between the feature distribution and the model structure. Aiming at addressing this problem, we propose a channel correlation loss (CC-Loss) that is able to constrain the specific relations between classes and channels as well as maintain the intra-class and the inter-class separability. CC-Loss uses a channel attention module to generate channel attention of features for each sample in the training stage. Next, an Euclidean distance matrix is calculated to make the channel attention vectors associated with the same class become identical and to increase the difference between different classes. Finally, we obtain a feature embedding with good intra-class compactness and inter-class separability.Experimental results show that two different backbone models trained with the proposed CC-Loss outperform the state-of-the-art loss functions on three image classification datasets.
Upgrading the Newsroom: An Automated Image Selection System for News Articles
Apr 23, 2020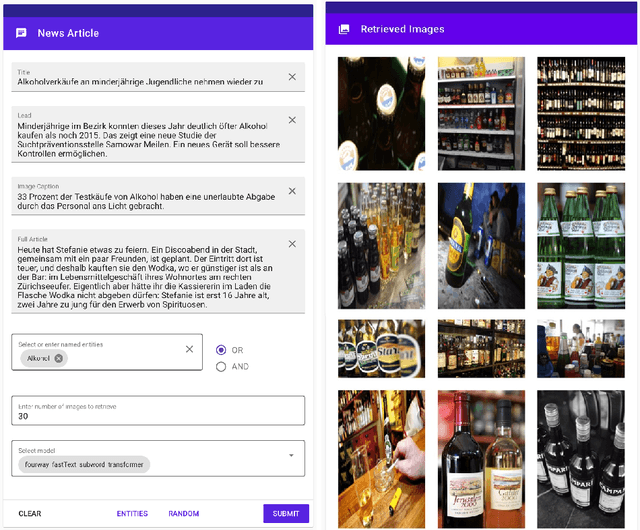
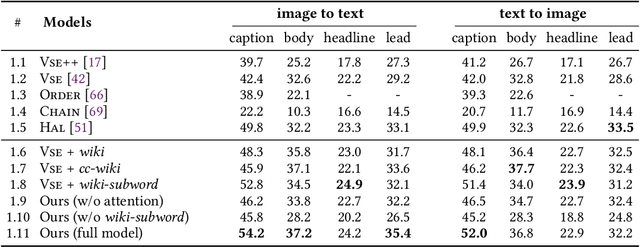
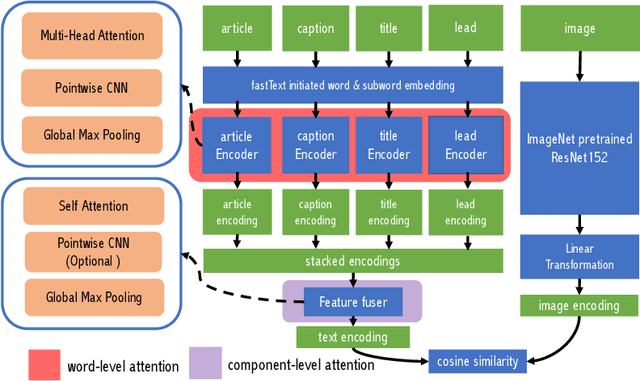
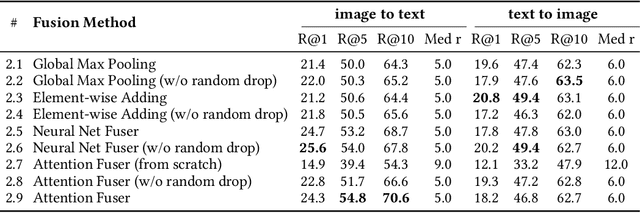
We propose an automated image selection system to assist photo editors in selecting suitable images for news articles. The system fuses multiple textual sources extracted from news articles and accepts multilingual inputs. It is equipped with char-level word embeddings to help both modeling morphologically rich languages, e.g. German, and transferring knowledge across nearby languages. The text encoder adopts a hierarchical self-attention mechanism to attend more to both keywords within a piece of text and informative components of a news article. We extensively experiment with our system on a large-scale text-image database containing multimodal multilingual news articles collected from Swiss local news media websites. The system is compared with multiple baselines with ablation studies and is shown to beat existing text-image retrieval methods in a weakly-supervised learning setting. Besides, we also offer insights on the advantage of using multiple textual sources and multilingual data.
A Cross-Modal Image Fusion Theory Guided by Human Visual Characteristics
Dec 23, 2019
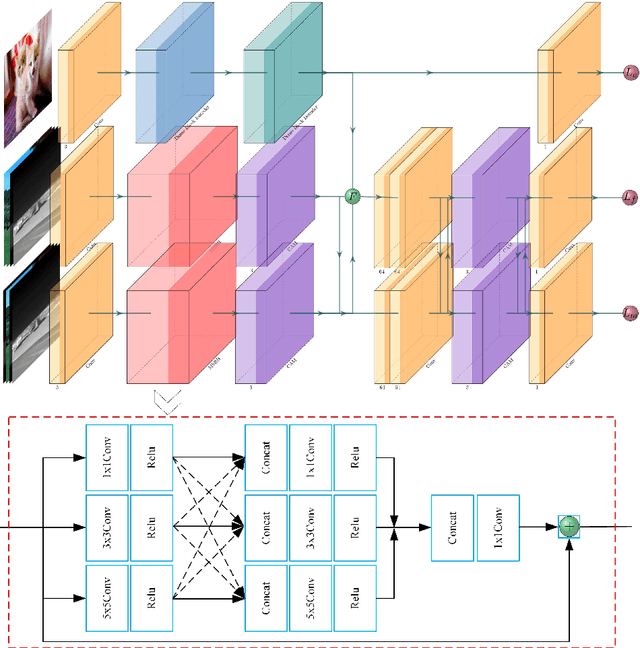
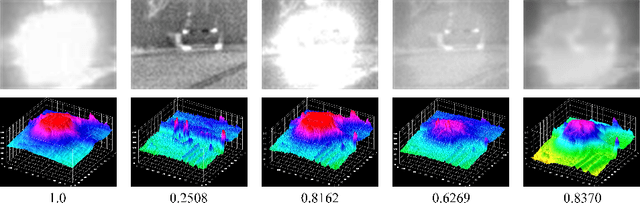

The characteristics of feature selection, nonlinear combination and multi-task auxiliary learning mechanism of the human visual perception system play an important role in real-world scenarios, but the research of image fusion theory based on the characteristics of human visual perception is less. Inspired by the characteristics of human visual perception, we propose a robust multi-task auxiliary learning optimization image fusion theory. Firstly, we combine channel attention model with nonlinear convolutional neural network to select features and fuse nonlinear features. Then, we analyze the impact of the existing image fusion loss on the image fusion quality, and establish the multi-loss function model of unsupervised learning network. Secondly, aiming at the multi-task auxiliary learning mechanism of human visual perception system, we study the influence of multi-task auxiliary learning mechanism on image fusion task on the basis of single task multi-loss network model. By simulating the three characteristics of human visual perception system, the fused image is more consistent with the mechanism of human brain image fusion. Finally, in order to verify the superiority of our algorithm, we carried out experiments on the combined vision system image data set, and extended our algorithm to the infrared and visible image and the multi-focus image public data set for experimental verification. The experimental results demonstrate the superiority of our fusion theory over state-of-arts in generality and robustness.
360-DFPE: Leveraging Monocular 360-Layouts for Direct Floor Plan Estimation
Dec 21, 2021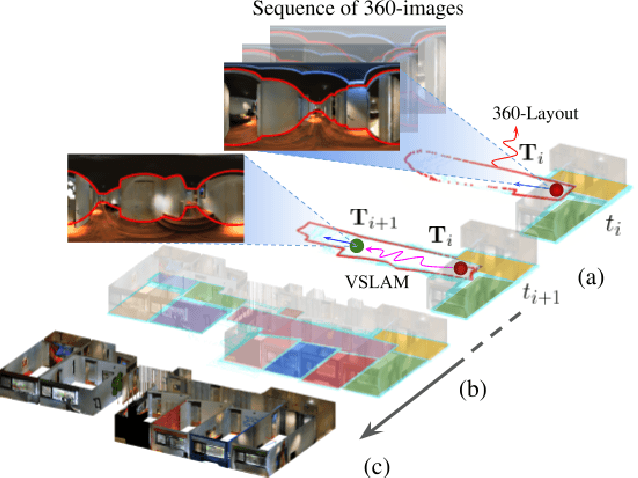
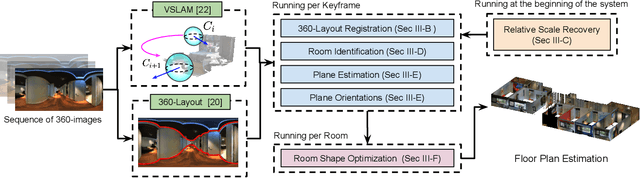
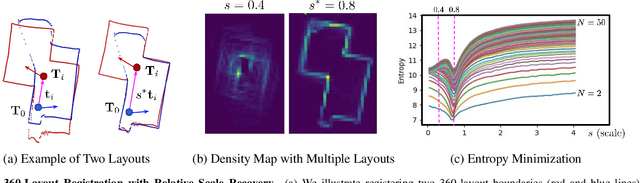
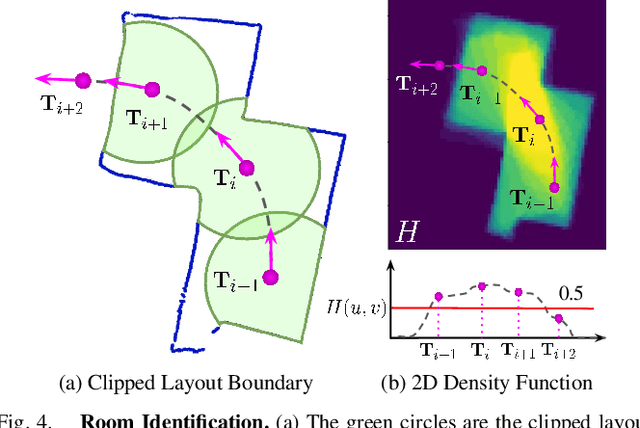
We present 360-DFPE, a sequential floor plan estimation method that directly takes 360-images as input without relying on active sensors or 3D information. Our approach leverages a loosely coupled integration between a monocular visual SLAM solution and a monocular 360-room layout approach, which estimate camera poses and layout geometries, respectively. Since our task is to sequentially capture the floor plan using monocular images, the entire scene structure, room instances, and room shapes are unknown. To tackle these challenges, we first handle the scale difference between visual odometry and layout geometry via formulating an entropy minimization process, which enables us to directly align 360-layouts without knowing the entire scene in advance. Second, to sequentially identify individual rooms, we propose a novel room identification algorithm that tracks every room along the camera exploration using geometry information. Lastly, to estimate the final shape of the room, we propose a shortest path algorithm with an iterative coarse-to-fine strategy, which improves prior formulations with higher accuracy and faster run-time. Moreover, we collect a new floor plan dataset with challenging large-scale scenes, providing both point clouds and sequential 360-image information. Experimental results show that our monocular solution achieves favorable performance against the current state-of-the-art algorithms that rely on active sensors and require the entire scene reconstruction data in advance. Our code and dataset will be released soon.
BioLCNet: Reward-modulated Locally Connected Spiking Neural Networks
Sep 12, 2021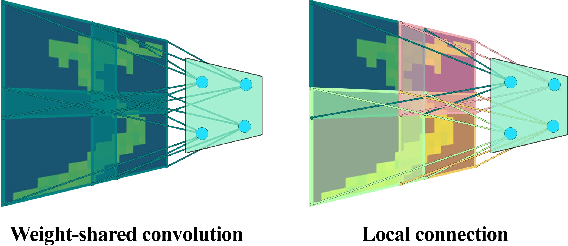
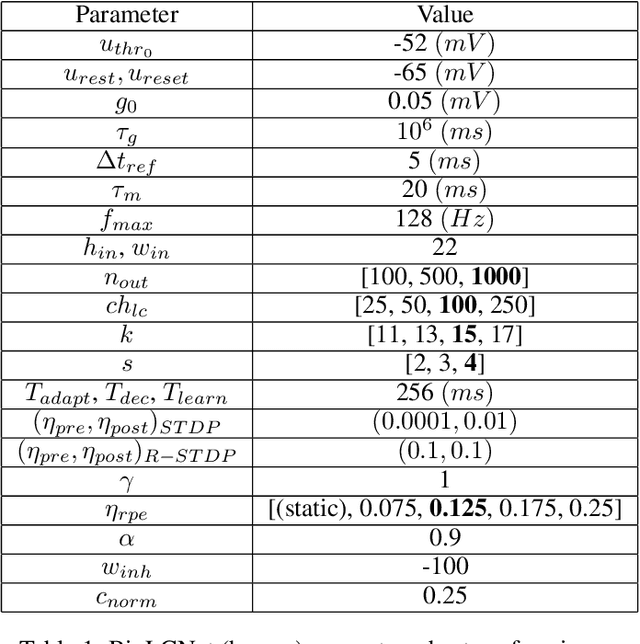
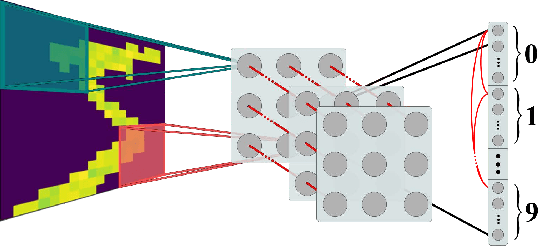

Recent studies have shown that convolutional neural networks (CNNs) are not the only feasible solution for image classification. Furthermore, weight sharing and backpropagation used in CNNs do not correspond to the mechanisms present in the primate visual system. To propose a more biologically plausible solution, we designed a locally connected spiking neural network (SNN) trained using spike-timing-dependent plasticity (STDP) and its reward-modulated variant (R-STDP) learning rules. The use of spiking neurons and local connections along with reinforcement learning (RL) led us to the nomenclature BioLCNet for our proposed architecture. Our network consists of a rate-coded input layer followed by a locally connected hidden layer and a decoding output layer. A spike population-based voting scheme is adopted for decoding in the output layer. We used the MNIST dataset to obtain image classification accuracy and to assess the robustness of our rewarding system to varying target responses.
Adversarial Attacks in Cooperative AI
Nov 29, 2021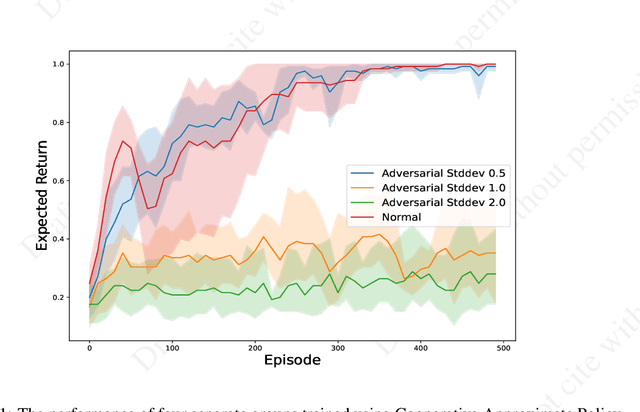
Single-agent reinforcement learning algorithms in a multi-agent environment are inadequate for fostering cooperation. If intelligent agents are to interact and work together to solve complex problems, methods that counter non-cooperative behavior are needed to facilitate the training of multiple agents. This is the goal of cooperative AI. Recent work in adversarial machine learning, however, shows that models (e.g., image classifiers) can be easily deceived into making incorrect decisions. In addition, some past research in cooperative AI has relied on new notions of representations, like public beliefs, to accelerate the learning of optimally cooperative behavior. Hence, cooperative AI might introduce new weaknesses not investigated in previous machine learning research. In this paper, our contributions include: (1) arguing that three algorithms inspired by human-like social intelligence introduce new vulnerabilities, unique to cooperative AI, that adversaries can exploit, and (2) an experiment showing that simple, adversarial perturbations on the agents' beliefs can negatively impact performance. This evidence points to the possibility that formal representations of social behavior are vulnerable to adversarial attacks.
P$^2$-GAN: Efficient Style Transfer Using Single Style Image
Jan 21, 2020
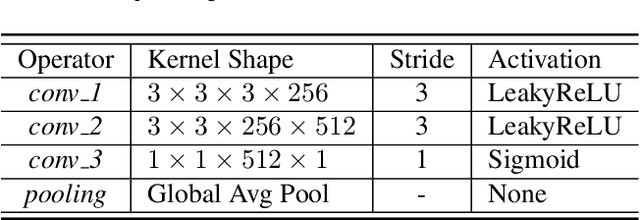
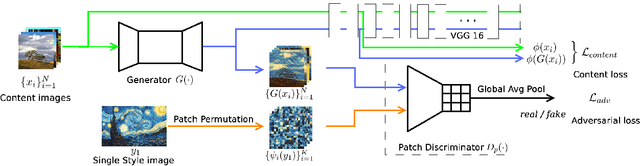
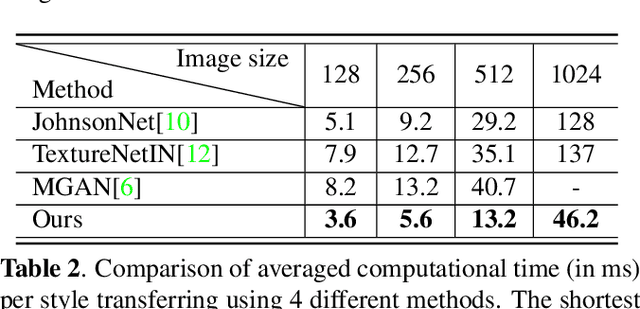
Style transfer is a useful image synthesis technique that can re-render given image into another artistic style while preserving its content information. Generative Adversarial Network (GAN) is a widely adopted framework toward this task for its better representation ability on local style patterns than the traditional Gram-matrix based methods. However, most previous methods rely on sufficient amount of pre-collected style images to train the model. In this paper, a novel Patch Permutation GAN (P$^2$-GAN) network that can efficiently learn the stroke style from a single style image is proposed. We use patch permutation to generate multiple training samples from the given style image. A patch discriminator that can simultaneously process patch-wise images and natural images seamlessly is designed. We also propose a local texture descriptor based criterion to quantitatively evaluate the style transfer quality. Experimental results showed that our method can produce finer quality re-renderings from single style image with improved computational efficiency compared with many state-of-the-arts methods.