 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-Modal Hierarchical Modelling for Fine-Grained Sketch Based Image Retrieval
Aug 11, 2020
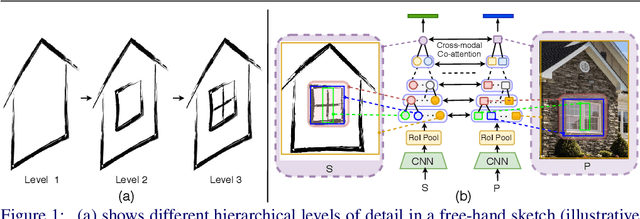
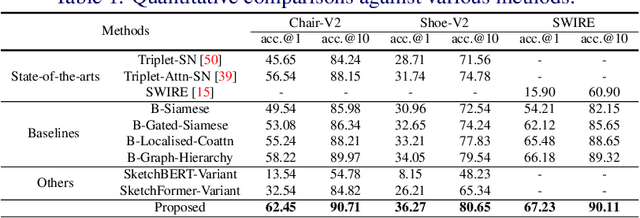
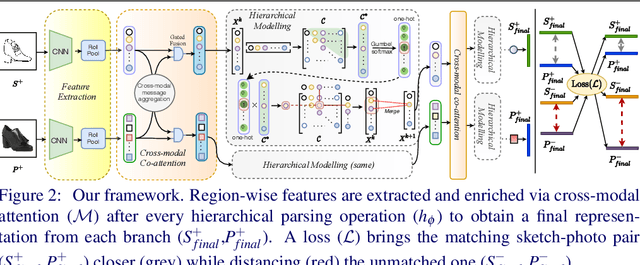
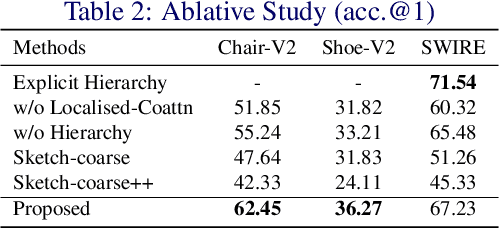
Sketch as an image search query is an ideal alternative to text in capturing the fine-grained visual details. Prior successes on fine-grained sketch-based image retrieval (FG-SBIR) have demonstrated the importance of tackling the unique traits of sketches as opposed to photos, e.g., temporal vs. static, strokes vs. pixels, and abstract vs. pixel-perfect. In this paper, we study a further trait of sketches that has been overlooked to date, that is, they are hierarchical in terms of the levels of detail -- a person typically sketches up to various extents of detail to depict an object. This hierarchical structure is often visually distinct. In this paper, we design a novel network that is capable of cultivating sketch-specific hierarchies and exploiting them to match sketch with photo at corresponding hierarchical levels. In particular, features from a sketch and a photo are enriched using cross-modal co-attention, coupled with hierarchical node fusion at every level to form a better embedding space to conduct retrieval. Experiments on common benchmarks show our method to outperform state-of-the-arts by a significant margin.
Deep Network Interpolation for Accelerated Parallel MR Image Reconstruction
Jul 12, 2020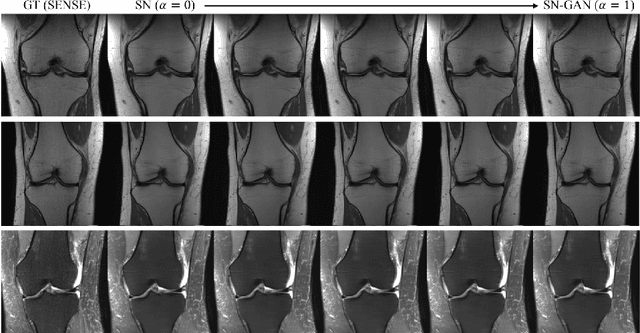
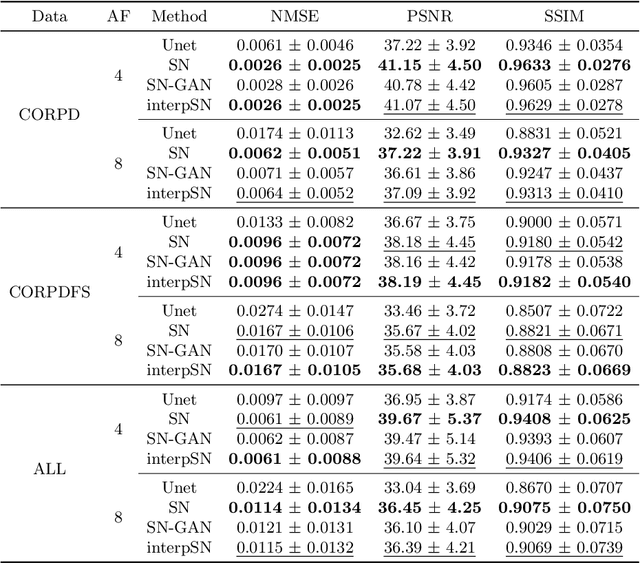
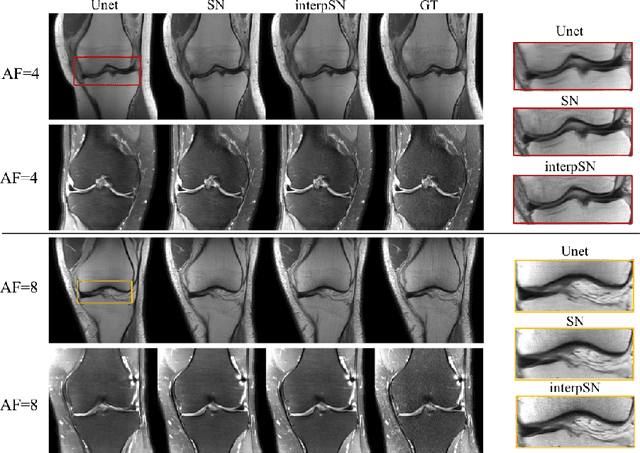
We present a deep network interpolation strategy for accelerated parallel MR image reconstruction. In particular, we examine the network interpolation in parameter space between a source model that is formulated in an unrolled scheme with L1 and SSIM losses and its counterpart that is trained with an adversarial loss. We show that by interpolating between the two different models of the same network structure, the new interpolated network can model a trade-off between perceptual quality and fidelity.
Big Data in Astroinformatics -- Compression of Scanned Astronomical Photographic Plates
Aug 24, 2021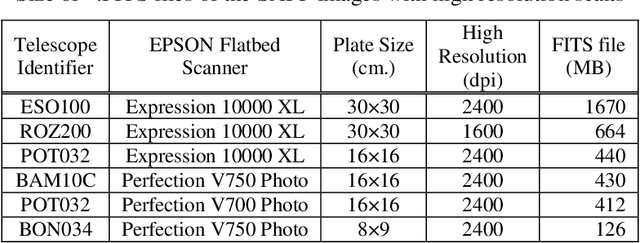
Construction of Scanned Astronomical Photographic Plates(SAPPs) databases and SVD image compression algorithm are considered. Some examples of compression with different plates are shown.
On the Importance of Firth Bias Reduction in Few-Shot Classification
Oct 06, 2021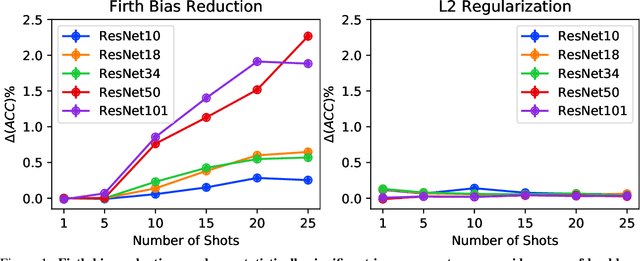
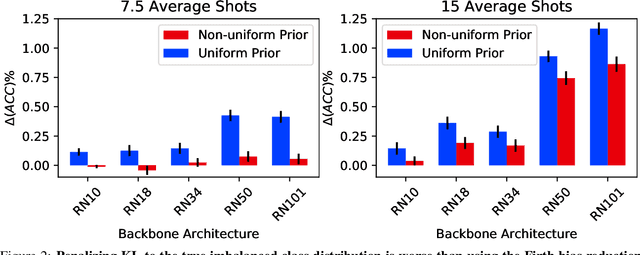
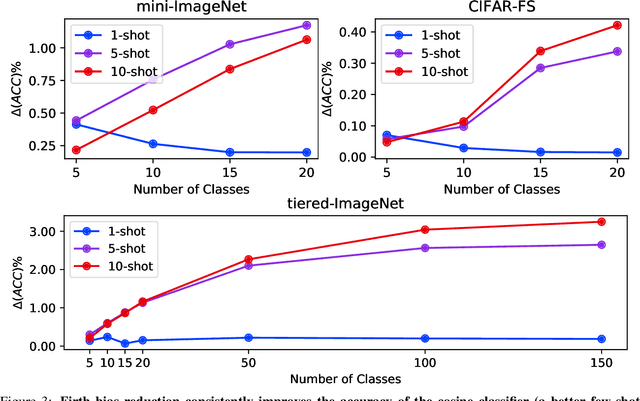
Learning accurate classifiers for novel categories from very few examples, known as few-shot image classification, is a challenging task in statistical machine learning and computer vision. The performance in few-shot classification suffers from the bias in the estimation of classifier parameters; however, an effective underlying bias reduction technique that could alleviate this issue in training few-shot classifiers has been overlooked. In this work, we demonstrate the effectiveness of Firth bias reduction in few-shot classification. Theoretically, Firth bias reduction removes the first order term $O(N^{-1})$ from the small-sample bias of the Maximum Likelihood Estimator. Here we show that the general Firth bias reduction technique simplifies to encouraging uniform class assignment probabilities for multinomial logistic classification, and almost has the same effect in cosine classifiers. We derive the optimization objective for Firth penalized multinomial logistic and cosine classifiers, and empirically evaluate that it is consistently effective across the board for few-shot image classification, regardless of (1) the feature representations from different backbones, (2) the number of samples per class, and (3) the number of classes. Finally, we show the robustness of Firth bias reduction, in the case of imbalanced data distribution. Our implementation is available at https://github.com/ehsansaleh/firth_bias_reduction
Dual Generator Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Jan 14, 2019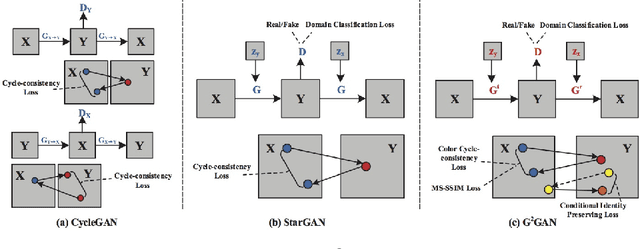
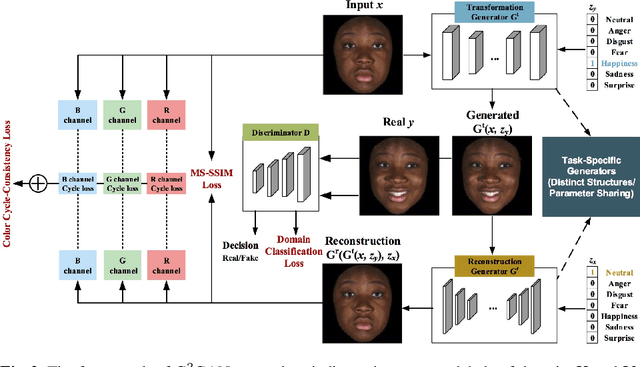

State-of-the-art methods for image-to-image translation with Generative Adversarial Networks (GANs) can learn a mapping from one domain to another domain using unpaired image data. However, these methods require the training of one specific model for every pair of image domains, which limits the scalability in dealing with more than two image domains. In addition, the training stage of these methods has the common problem of model collapse that degrades the quality of the generated images. To tackle these issues, we propose a Dual Generator Generative Adversarial Network (G$^2$GAN), which is a robust and scalable approach allowing to perform unpaired image-to-image translation for multiple domains using only dual generators within a single model. Moreover, we explore different optimization losses for better training of G$^2$GAN, and thus make unpaired image-to-image translation with higher consistency and better stability. Extensive experiments on six publicly available datasets with different scenarios, i.e., architectural buildings, seasons, landscape and human faces, demonstrate that the proposed G$^2$GAN achieves superior model capacity and better generation performance comparing with existing image-to-image translation GAN models.
Aligning Visual Regions and Textual Concepts: Learning Fine-Grained Image Representations for Image Captioning
May 26, 2019
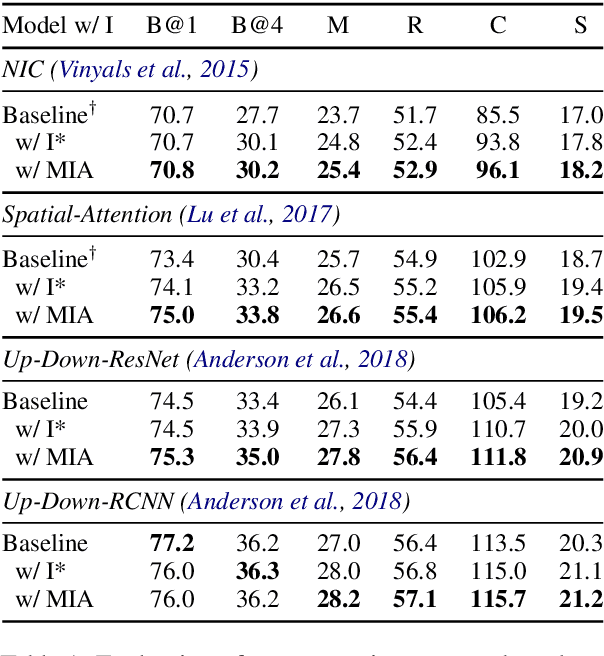
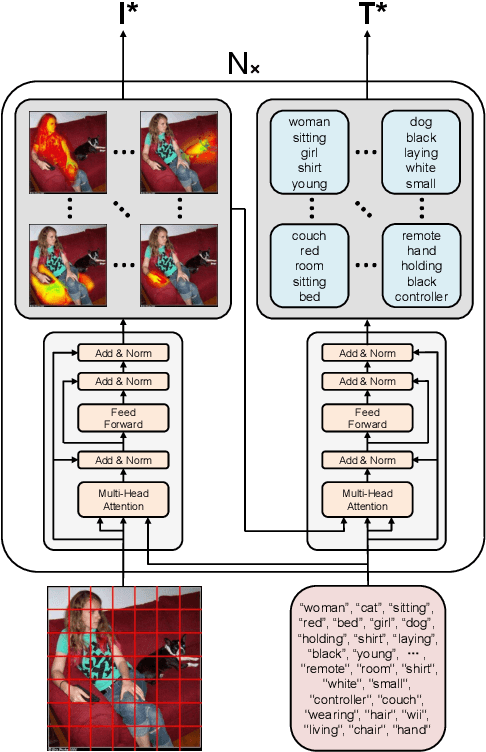
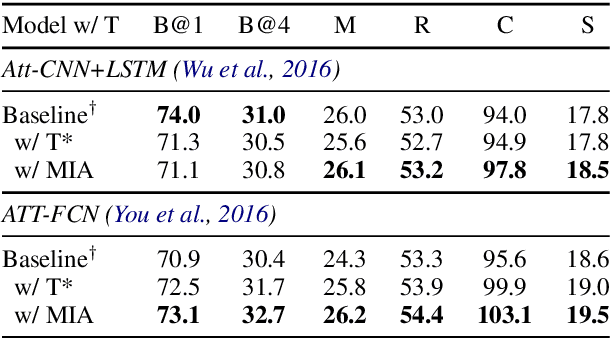
In image-grounded text generation, fine-grained representations of the image are considered to be of paramount importance. Most of the current systems incorporate visual features and textual concepts as a sketch of an image. However, plainly inferred representations are usually undesirable in that they are composed of separate components, the relations of which are elusive. In this work, we aim at representing an image with a set of integrated visual regions and corresponding textual concepts. To this end, we build the Mutual Iterative Attention (MIA) module, which integrates correlated visual features and textual concepts, respectively, by aligning the two modalities. We evaluate the proposed approach on the COCO dataset for image captioning. Extensive experiments show that the refined image representations boost the baseline models by up to 12% in terms of CIDEr, demonstrating that our method is effective and generalizes well to a wide range of models.
A Spatiotemporal Volumetric Interpolation Network for 4D Dynamic Medical Image
Feb 28, 2020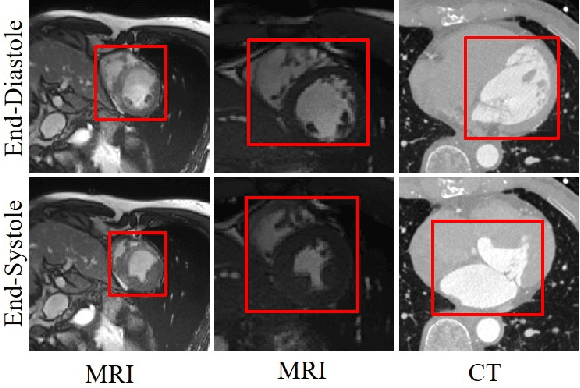

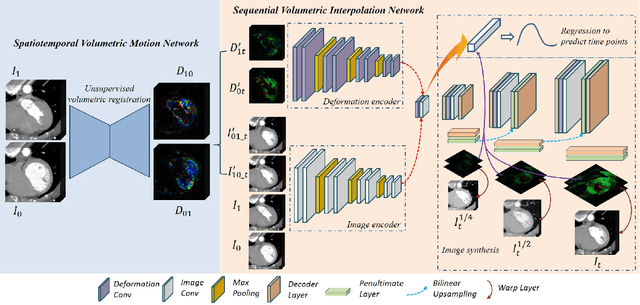

Dynamic medical imaging is usually limited in application due to the large radiation doses and longer image scanning and reconstruction times. Existing methods attempt to reduce the dynamic sequence by interpolating the volumes between the acquired image volumes. However, these methods are limited to either 2D images and/or are unable to support large variations in the motion between the image volume sequences. In this paper, we present a spatiotemporal volumetric interpolation network (SVIN) designed for 4D dynamic medical images. SVIN introduces dual networks: first is the spatiotemporal motion network that leverages the 3D convolutional neural network (CNN) for unsupervised parametric volumetric registration to derive spatiotemporal motion field from two-image volumes; the second is the sequential volumetric interpolation network, which uses the derived motion field to interpolate image volumes, together with a new regression-based module to characterize the periodic motion cycles in functional organ structures. We also introduce an adaptive multi-scale architecture to capture the volumetric large anatomy motions. Experimental results demonstrated that our SVIN outperformed state-of-the-art temporal medical interpolation methods and natural video interpolation methods that have been extended to support volumetric images. Our ablation study further exemplified that our motion network was able to better represent the large functional motion compared with the state-of-the-art unsupervised medical registration methods.
Quick Annotator: an open-source digital pathology based rapid image annotation tool
Jan 06, 2021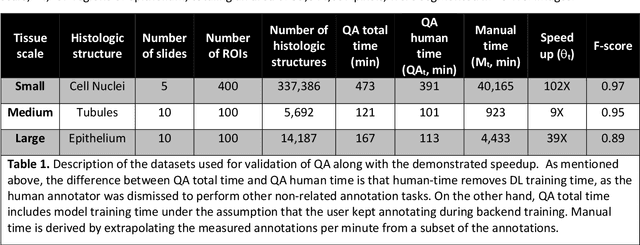
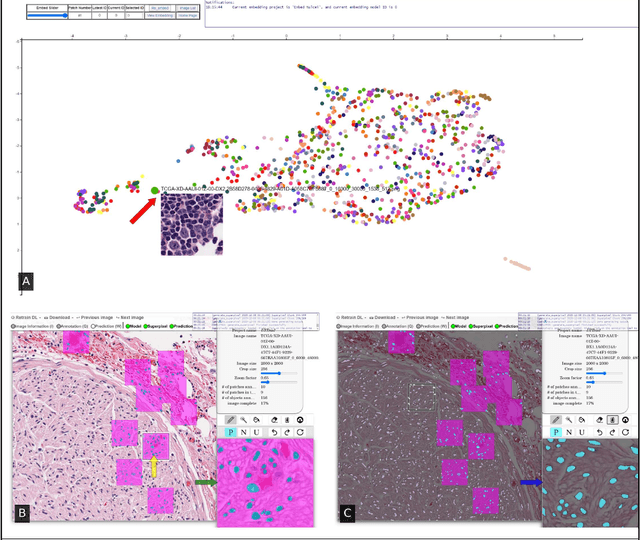
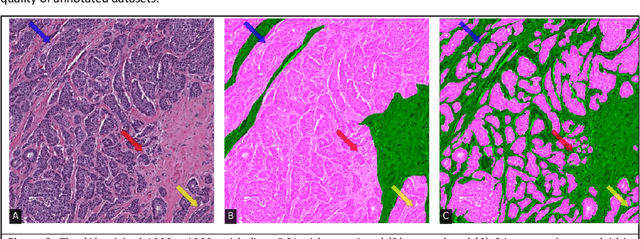
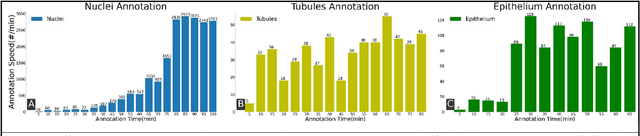
Image based biomarker discovery typically requires an accurate segmentation of histologic structures (e.g., cell nuclei, tubules, epithelial regions) in digital pathology Whole Slide Images (WSI). Unfortunately, annotating each structure of interest is laborious and often intractable even in moderately sized cohorts. Here, we present an open-source tool, Quick Annotator (QA), designed to improve annotation efficiency of histologic structures by orders of magnitude. While the user annotates regions of interest (ROI) via an intuitive web interface, a deep learning (DL) model is concurrently optimized using these annotations and applied to the ROI. The user iteratively reviews DL results to either (a) accept accurately annotated regions, or (b) correct erroneously segmented structures to improve subsequent model suggestions, before transitioning to other ROIs. We demonstrate the effectiveness of QA over comparable manual efforts via three use cases. These include annotating (a) 337,386 nuclei in 5 pancreatic WSIs, (b) 5,692 tubules in 10 colorectal WSIs, and (c) 14,187 regions of epithelium in 10 breast WSIs. Efficiency gains in terms of annotations per second of 102x, 9x, and 39x were respectively witnessed while retaining f-scores >.95, suggesting QA may be a valuable tool for efficiently fully annotating WSIs employed in downstream biomarker studies.
M-FasterSeg: An Efficient Semantic Segmentation Network Based on Neural Architecture Search
Dec 15, 2021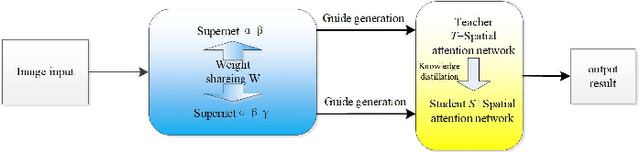
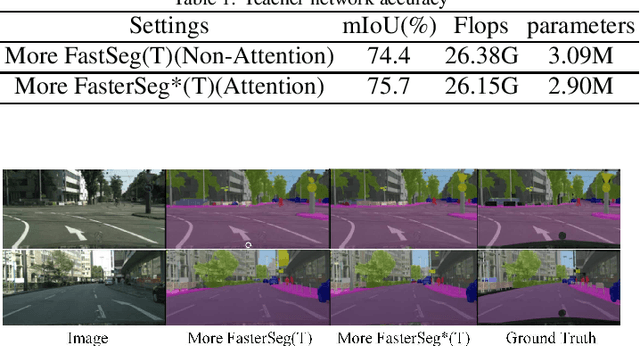
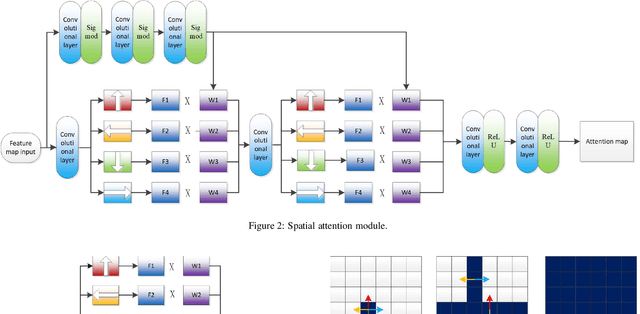
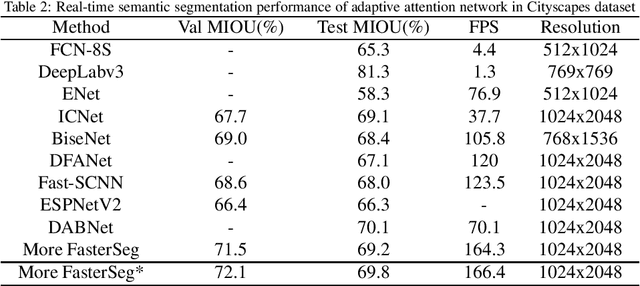
Image semantic segmentation technology is one of the key technologies for intelligent systems to understand natural scenes. As one of the important research directions in the field of visual intelligence, this technology has broad application scenarios in the fields of mobile robots, drones, smart driving, and smart security. However, in the actual application of mobile robots, problems such as inaccurate segmentation semantic label prediction and loss of edge information of segmented objects and background may occur. This paper proposes an improved structure of a semantic segmentation network based on a deep learning network that combines self-attention neural network and neural network architecture search methods. First, a neural network search method NAS (Neural Architecture Search) is used to find a semantic segmentation network with multiple resolution branches. In the search process, combine the self-attention network structure module to adjust the searched neural network structure, and then combine the semantic segmentation network searched by different branches to form a fast semantic segmentation network structure, and input the picture into the network structure to get the final forecast result. The experimental results on the Cityscapes dataset show that the accuracy of the algorithm is 69.8%, and the segmentation speed is 48/s. It achieves a good balance between real-time and accuracy, can optimize edge segmentation, and has a better performance in complex scenes. Good robustness is suitable for practical application.
Super-BPD: Super Boundary-to-Pixel Direction for Fast Image Segmentation
May 30, 2020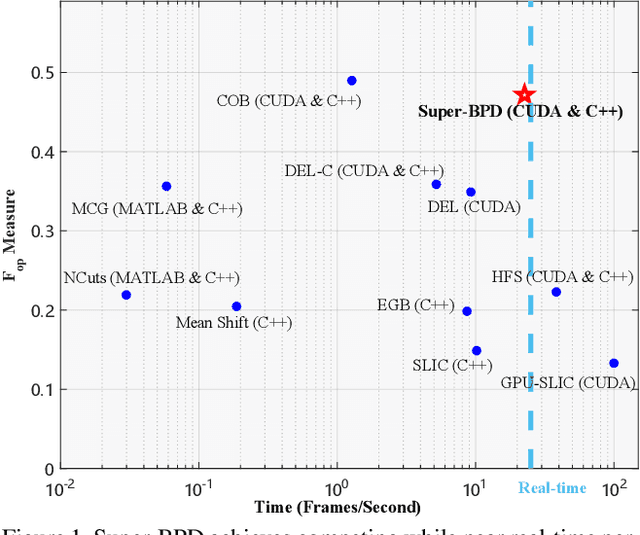
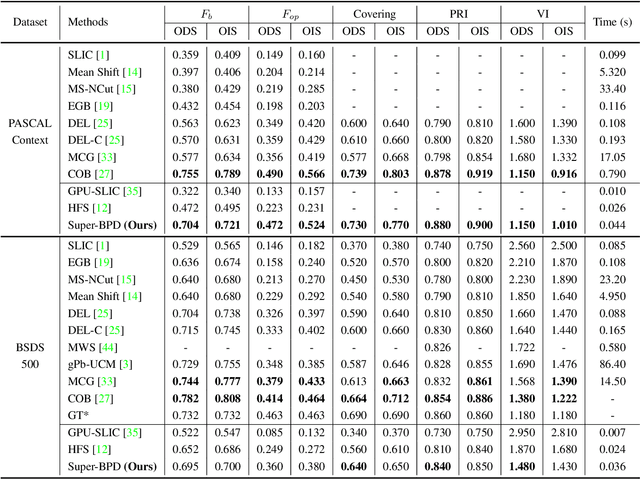

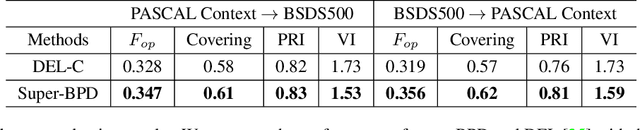
Image segmentation is a fundamental vision task and a crucial step for many applications. In this paper, we propose a fast image segmentation method based on a novel super boundary-to-pixel direction (super-BPD) and a customized segmentation algorithm with super-BPD. Precisely, we define BPD on each pixel as a two-dimensional unit vector pointing from its nearest boundary to the pixel. In the BPD, nearby pixels from different regions have opposite directions departing from each other, and adjacent pixels in the same region have directions pointing to the other or each other (i.e., around medial points). We make use of such property to partition an image into super-BPDs, which are novel informative superpixels with robust direction similarity for fast grouping into segmentation regions. Extensive experimental results on BSDS500 and Pascal Context demonstrate the accuracy and efficency of the proposed super-BPD in segmenting images. In practice, the proposed super-BPD achieves comparable or superior performance with MCG while running at ~25fps vs. 0.07fps. Super-BPD also exhibits a noteworthy transferability to unseen scenes. The code is publicly available at https://github.com/JianqiangWan/Super-BPD.