 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Research on facial expression recognition based on Multimodal data fusion and neural network
Sep 26, 2021

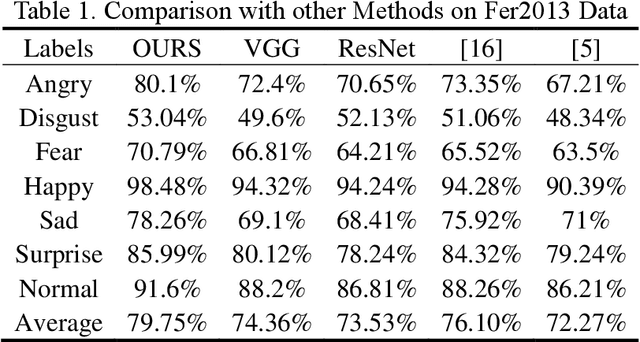
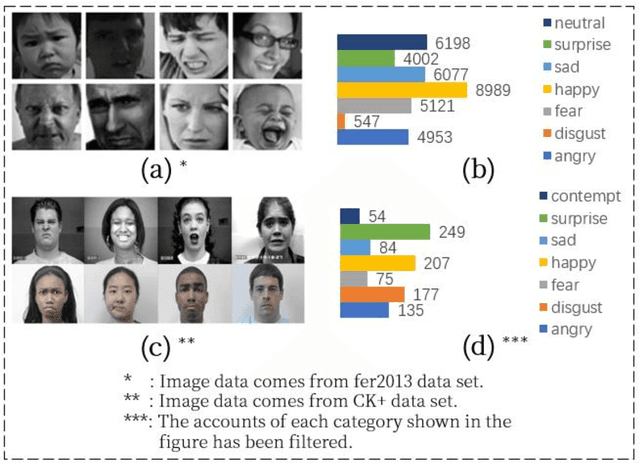
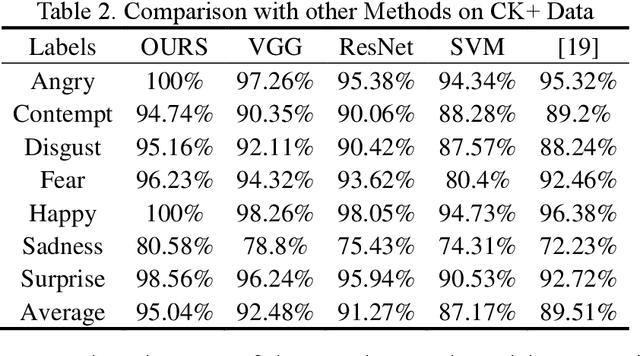
Facial expression recognition is a challenging task when neural network is applied to pattern recognition. Most of the current recognition research is based on single source facial data, which generally has the disadvantages of low accuracy and low robustness. In this paper, a neural network algorithm of facial expression recognition based on multimodal data fusion is proposed. The algorithm is based on the multimodal data, and it takes the facial image, the histogram of oriented gradient of the image and the facial landmarks as the input, and establishes CNN, LNN and HNN three sub neural networks to extract data features, using multimodal data feature fusion mechanism to improve the accuracy of facial expression recognition. Experimental results show that, benefiting by the complementarity of multimodal data, the algorithm has a great improvement in accuracy, robustness and detection speed compared with the traditional facial expression recognition algorithm. Especially in the case of partial occlusion, illumination and head posture transformation, the algorithm also shows a high confidence.
Approaches Toward Physical and General Video Anomaly Detection
Dec 14, 2021

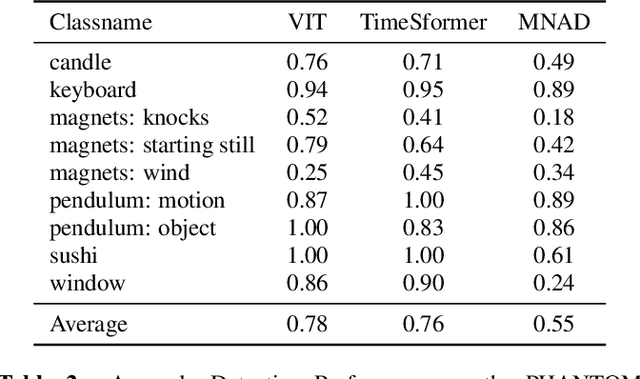

In recent years, many works have addressed the problem of finding never-seen-before anomalies in videos. Yet, most work has been focused on detecting anomalous frames in surveillance videos taken from security cameras. Meanwhile, the task of anomaly detection (AD) in videos exhibiting anomalous mechanical behavior, has been mostly overlooked. Anomaly detection in such videos is both of academic and practical interest, as they may enable automatic detection of malfunctions in many manufacturing, maintenance, and real-life settings. To assess the potential of the different approaches to detect such anomalies, we evaluate two simple baseline approaches: (i) Temporal-pooled image AD techniques. (ii) Density estimation of videos represented with features pretrained for video-classification. Development of such methods calls for new benchmarks to allow evaluation of different possible approaches. We introduce the Physical Anomalous Trajectory or Motion (PHANTOM) dataset, which contains six different video classes. Each class consists of normal and anomalous videos. The classes differ in the presented phenomena, the normal class variability, and the kind of anomalies in the videos. We also suggest an even harder benchmark where anomalous activities should be spotted on highly variable scenes.
Revisiting PGD Attacks for Stability Analysis of Large-Scale Nonlinear Systems and Perception-Based Control
Jan 03, 2022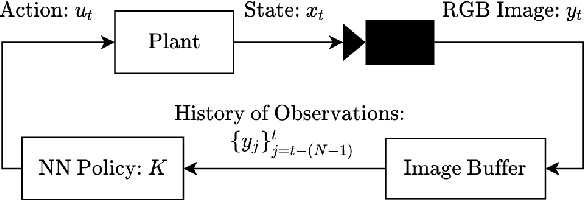
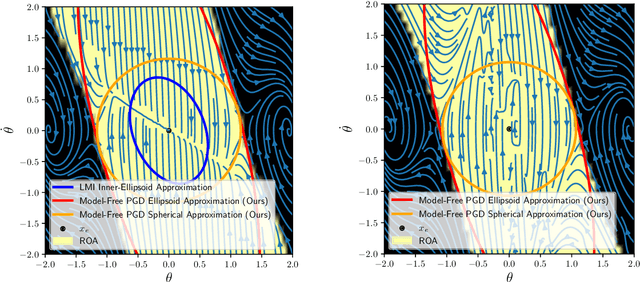
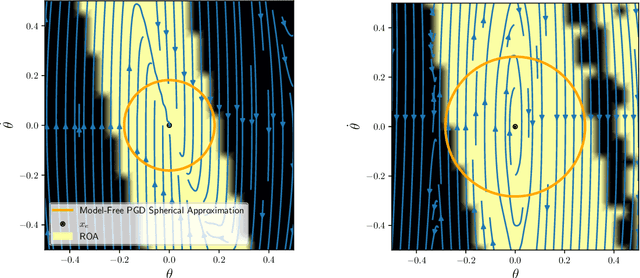
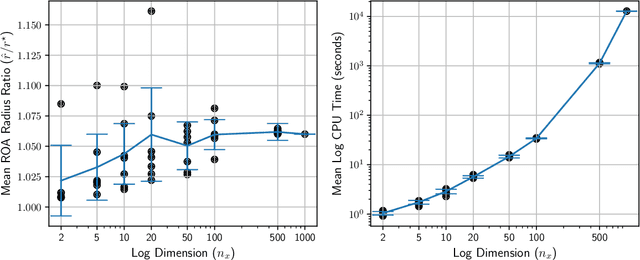
Many existing region-of-attraction (ROA) analysis tools find difficulty in addressing feedback systems with large-scale neural network (NN) policies and/or high-dimensional sensing modalities such as cameras. In this paper, we tailor the projected gradient descent (PGD) attack method developed in the adversarial learning community as a general-purpose ROA analysis tool for large-scale nonlinear systems and end-to-end perception-based control. We show that the ROA analysis can be approximated as a constrained maximization problem whose goal is to find the worst-case initial condition which shifts the terminal state the most. Then we present two PGD-based iterative methods which can be used to solve the resultant constrained maximization problem. Our analysis is not based on Lyapunov theory, and hence requires minimum information of the problem structures. In the model-based setting, we show that the PGD updates can be efficiently performed using back-propagation. In the model-free setting (which is more relevant to ROA analysis of perception-based control), we propose a finite-difference PGD estimate which is general and only requires a black-box simulator for generating the trajectories of the closed-loop system given any initial state. We demonstrate the scalability and generality of our analysis tool on several numerical examples with large-scale NN policies and high-dimensional image observations. We believe that our proposed analysis serves as a meaningful initial step toward further understanding of closed-loop stability of large-scale nonlinear systems and perception-based control.
Octree Transformer: Autoregressive 3D Shape Generation on Hierarchically Structured Sequences
Nov 24, 2021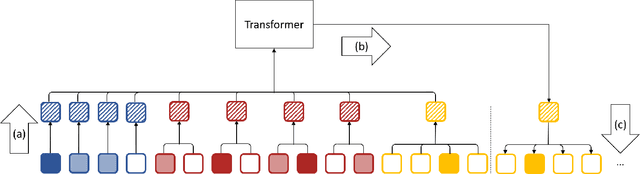
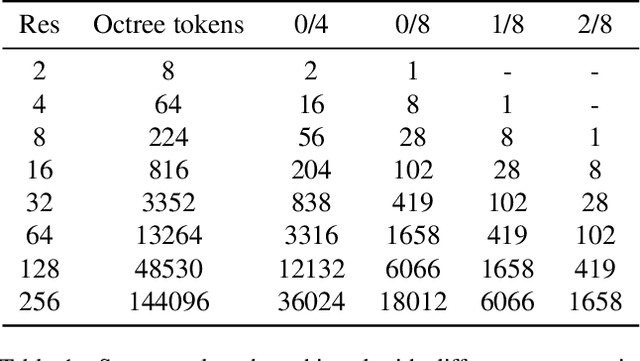
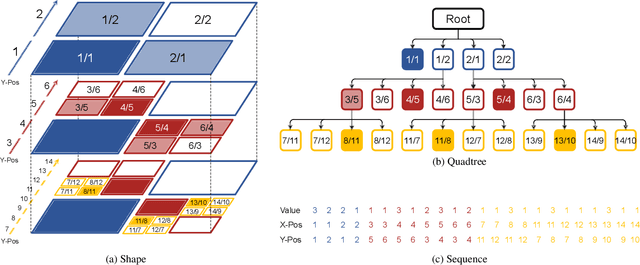
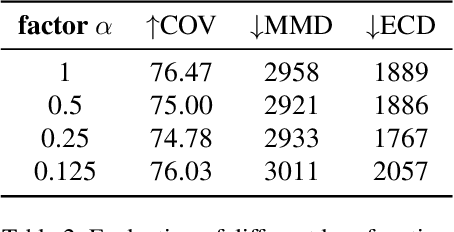
Autoregressive models have proven to be very powerful in NLP text generation tasks and lately have gained popularity for image generation as well. However, they have seen limited use for the synthesis of 3D shapes so far. This is mainly due to the lack of a straightforward way to linearize 3D data as well as to scaling problems with the length of the resulting sequences when describing complex shapes. In this work we address both of these problems. We use octrees as a compact hierarchical shape representation that can be sequentialized by traversal ordering. Moreover, we introduce an adaptive compression scheme, that significantly reduces sequence lengths and thus enables their effective generation with a transformer, while still allowing fully autoregressive sampling and parallel training. We demonstrate the performance of our model by comparing against the state-of-the-art in shape generation.
Multi-Modal Temporal Attention Models for Crop Mapping from Satellite Time Series
Dec 14, 2021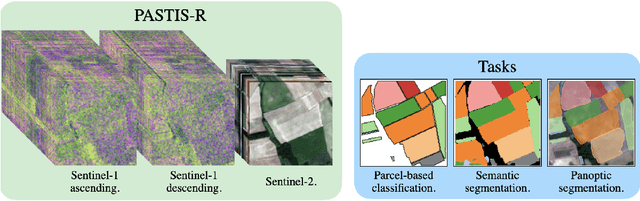
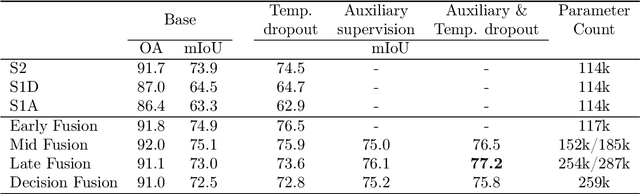
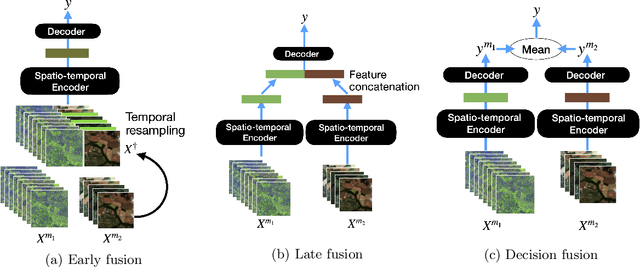
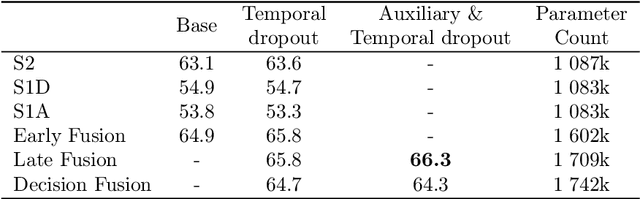
Optical and radar satellite time series are synergetic: optical images contain rich spectral information, while C-band radar captures useful geometrical information and is immune to cloud cover. Motivated by the recent success of temporal attention-based methods across multiple crop mapping tasks, we propose to investigate how these models can be adapted to operate on several modalities. We implement and evaluate multiple fusion schemes, including a novel approach and simple adjustments to the training procedure, significantly improving performance and efficiency with little added complexity. We show that most fusion schemes have advantages and drawbacks, making them relevant for specific settings. We then evaluate the benefit of multimodality across several tasks: parcel classification, pixel-based segmentation, and panoptic parcel segmentation. We show that by leveraging both optical and radar time series, multimodal temporal attention-based models can outmatch single-modality models in terms of performance and resilience to cloud cover. To conduct these experiments, we augment the PASTIS dataset with spatially aligned radar image time series. The resulting dataset, PASTIS-R, constitutes the first large-scale, multimodal, and open-access satellite time series dataset with semantic and instance annotations.
Semi-supervised Impedance Inversion by Bayesian Neural Network Based on 2-d CNN Pre-training
Nov 20, 2021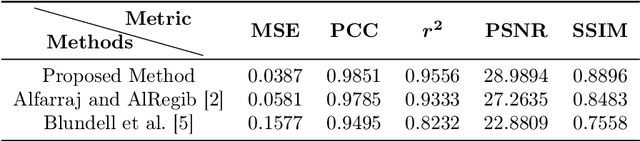
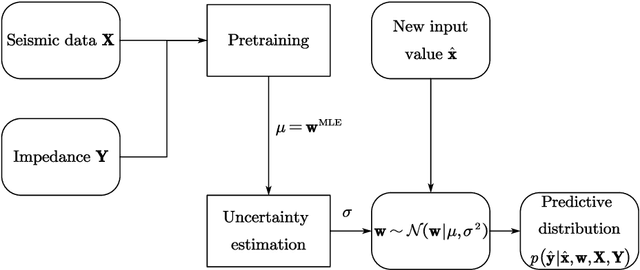

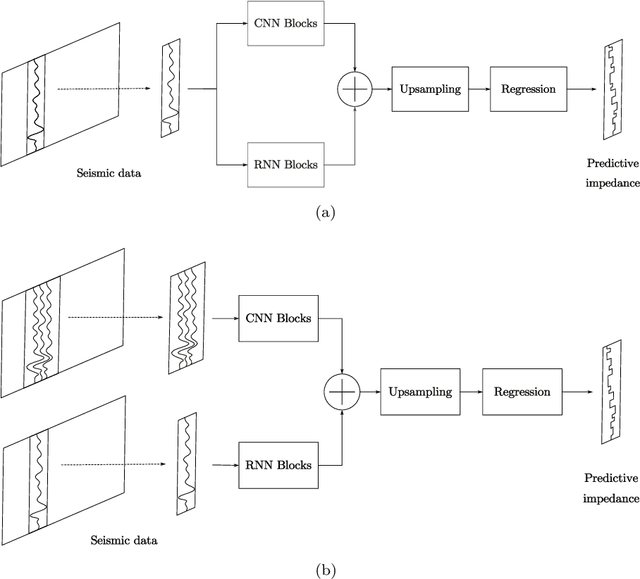
Seismic impedance inversion can be performed with a semi-supervised learning algorithm, which only needs a few logs as labels and is less likely to get overfitted. However, classical semi-supervised learning algorithm usually leads to artifacts on the predicted impedance image. In this artical, we improve the semi-supervised learning from two aspects. First, by replacing 1-d convolutional neural network (CNN) layers in deep learning structure with 2-d CNN layers and 2-d maxpooling layers, the prediction accuracy is improved. Second, prediction uncertainty can also be estimated by embedding the network into a Bayesian inference framework. Local reparameterization trick is used during forward propagation of the network to reduce sampling cost. Tests with Marmousi2 model and SEAM model validate the feasibility of the proposed strategy.
Text Classification Models for Form Entity Linking
Dec 14, 2021


Forms are a widespread type of template-based document used in a great variety of fields including, among others, administration, medicine, finance, or insurance. The automatic extraction of the information included in these documents is greatly demanded due to the increasing volume of forms that are generated in a daily basis. However, this is not a straightforward task when working with scanned forms because of the great diversity of templates with different location of form entities, and the quality of the scanned documents. In this context, there is a feature that is shared by all forms: they contain a collection of interlinked entities built as key-value (or label-value) pairs, together with other entities such as headers or images. In this work, we have tacked the problem of entity linking in forms by combining image processing techniques and a text classification model based on the BERT architecture. This approach achieves state-of-the-art results with a F1-score of 0.80 on the FUNSD dataset, a 5% improvement regarding the best previous method. The code of this project is available at https://github.com/mavillot/FUNSD-Entity-Linking.
Space-Partitioning RANSAC
Nov 24, 2021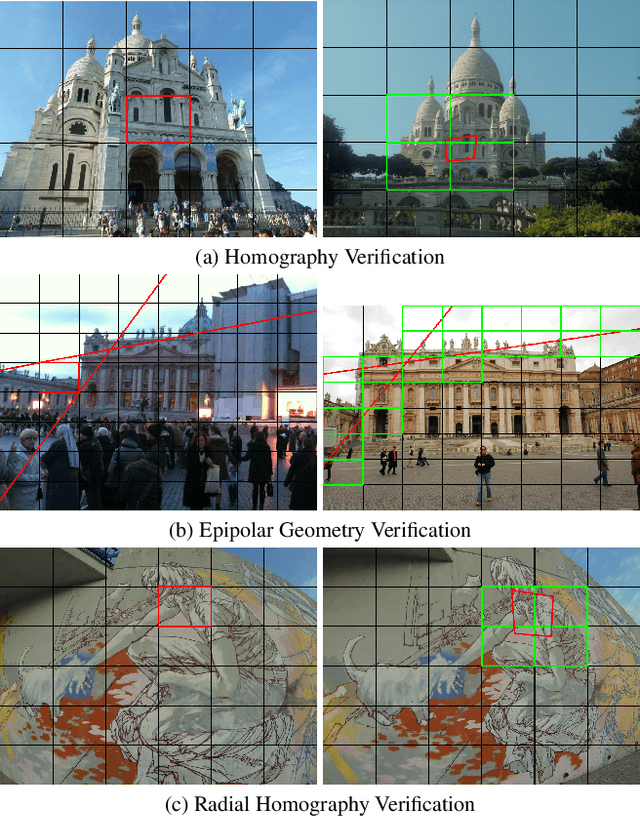
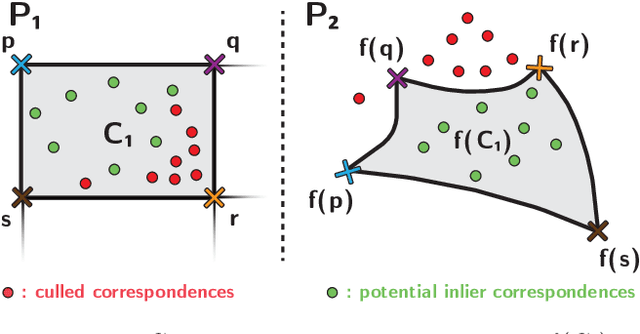

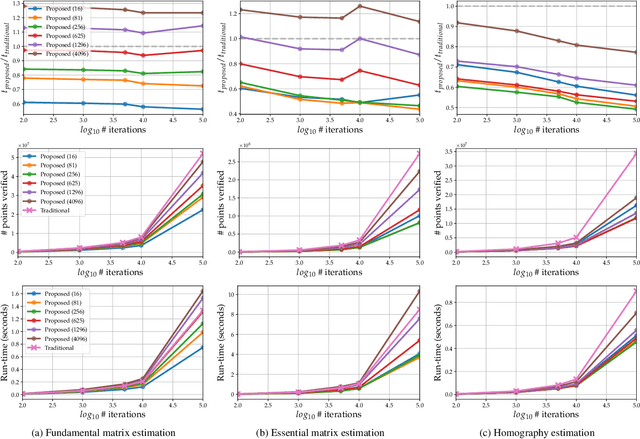
A new algorithm is proposed to accelerate RANSAC model quality calculations. The method is based on partitioning the joint correspondence space, e.g., 2D-2D point correspondences, into a pair of regular grids. The grid cells are mapped by minimal sample models, estimated within RANSAC, to reject correspondences that are inconsistent with the model parameters early. The proposed technique is general. It works with arbitrary transformations even if a point is mapped to a point set, e.g., as a fundamental matrix maps to epipolar lines. The method is tested on thousands of image pairs from publicly available datasets on fundamental and essential matrix, homography and radially distorted homography estimation. On average, it reduces the RANSAC run-time by 41% with provably no deterioration in the accuracy. It can be straightforwardly plugged into state-of-the-art RANSAC frameworks, e.g. VSAC.
Image Embedded Segmentation: Combining Supervised and Unsupervised Objectives through Generative Adversarial Networks
Jan 30, 2020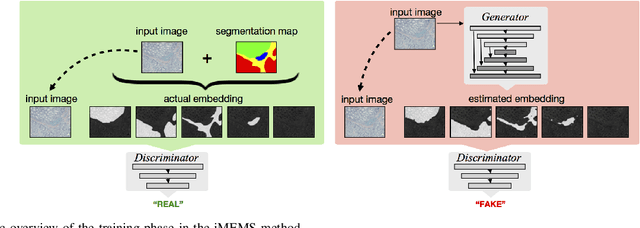
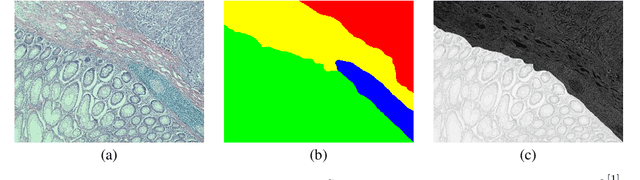

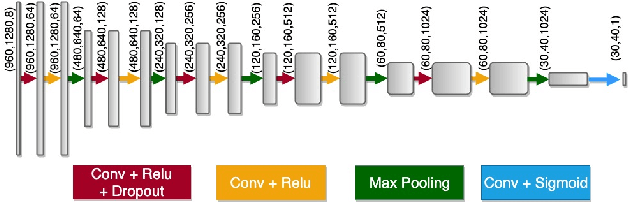
This paper presents a new regularization method to train a fully convolutional network for semantic tissue segmentation in histopathological images. This method relies on benefiting unsupervised learning, in the form of image reconstruction, for the network training. To this end, it puts forward an idea of defining a new embedding that allows uniting the main supervised task of semantic segmentation and an auxiliary unsupervised task of image reconstruction into a single task and proposes to learn this united task by a single generative model. This embedding generates a multi-channel output image by superimposing an original input image on its segmentation map. Then, the method learns to translate the input image to this embedded output image using a conditional generative adversarial network, which is known to be quite effective for image-to-image translations. This proposal is different than the existing approach that uses image reconstruction for the same regularization purpose. The existing approach considers segmentation and image reconstruction as two separate tasks in a multi-task network, defines their losses independently, and then combines these losses in a joint loss function. However, the definition of such a function requires externally determining the right contribution amounts of the supervised and unsupervised losses that yield balanced learning between the segmentation and image reconstruction tasks. The proposed approach eliminates this difficulty by uniting these two tasks into a single one, which intrinsically combines their losses. Using histopathological image segmentation as a showcase application, our experiments demonstrate that this proposed approach leads to better segmentation results.
Adversarial Parametric Pose Prior
Dec 08, 2021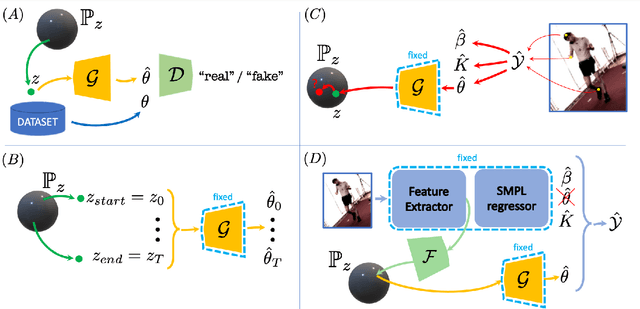
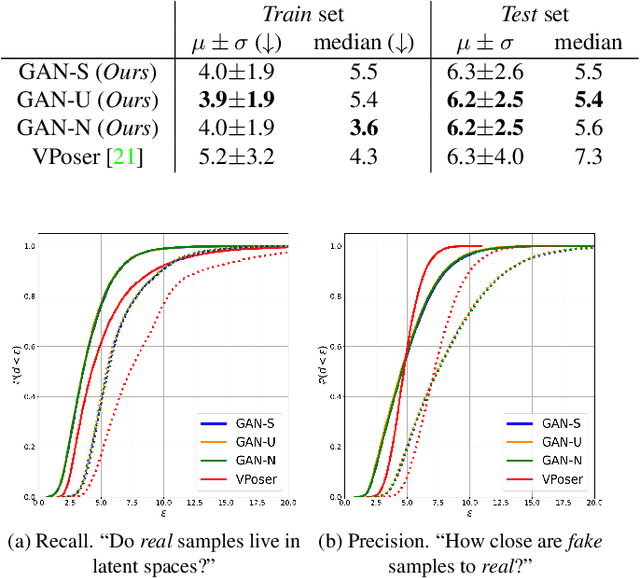
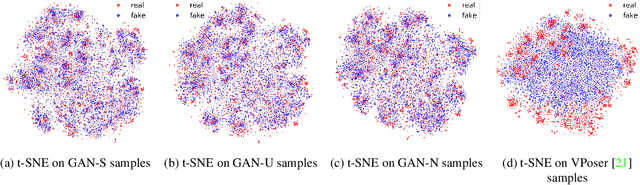
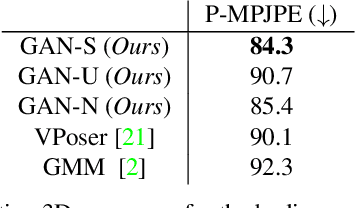
The Skinned Multi-Person Linear (SMPL) model can represent a human body by mapping pose and shape parameters to body meshes. This has been shown to facilitate inferring 3D human pose and shape from images via different learning models. However, not all pose and shape parameter values yield physically-plausible or even realistic body meshes. In other words, SMPL is under-constrained and may thus lead to invalid results when used to reconstruct humans from images, either by directly optimizing its parameters, or by learning a mapping from the image to these parameters. In this paper, we therefore learn a prior that restricts the SMPL parameters to values that produce realistic poses via adversarial training. We show that our learned prior covers the diversity of the real-data distribution, facilitates optimization for 3D reconstruction from 2D keypoints, and yields better pose estimates when used for regression from images. We found that the prior based on spherical distribution gets the best results. Furthermore, in all these tasks, it outperforms the state-of-the-art VAE-based approach to constraining the SMPL parameters.