 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enabling Image Recognition on Constrained Devices Using Neural Network Pruning and a CycleGAN
Sep 11, 2020



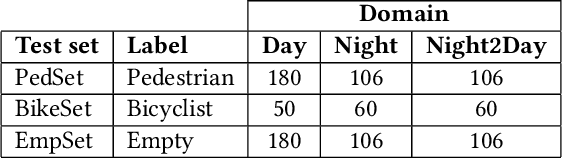
Smart cameras are increasingly used in surveillance solutions in public spaces. Contemporary computer vision applications can be used to recognize events that require intervention by emergency services. Smart cameras can be mounted in locations where citizens feel particularly unsafe, e.g., pathways and underpasses with a history of incidents. One promising approach for smart cameras is edge AI, i.e., deploying AI technology on IoT devices. However, implementing resource-demanding technology such as image recognition using deep neural networks (DNN) on constrained devices is a substantial challenge. In this paper, we explore two approaches to reduce the need for compute in contemporary image recognition in an underpass. First, we showcase successful neural network pruning, i.e., we retain comparable classification accuracy with only 1.1\% of the neurons remaining from the state-of-the-art DNN architecture. Second, we demonstrate how a CycleGAN can be used to transform out-of-distribution images to the operational design domain. We posit that both pruning and CycleGANs are promising enablers for efficient edge AI in smart cameras.
Unifying Relational Sentence Generation and Retrieval for Medical Image Report Composition
Jan 09, 2021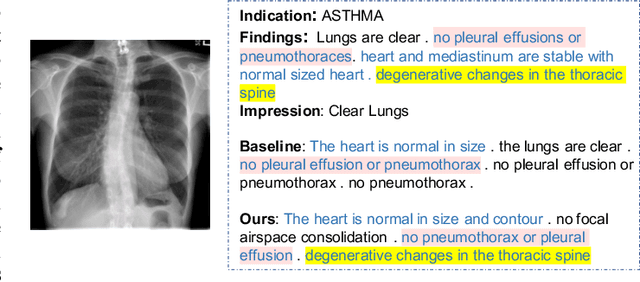
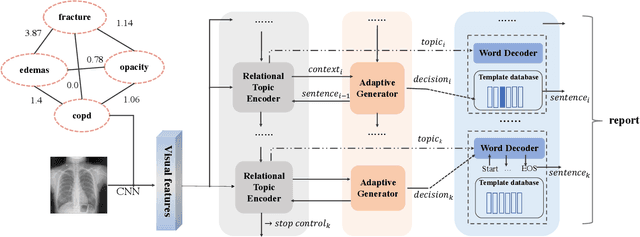
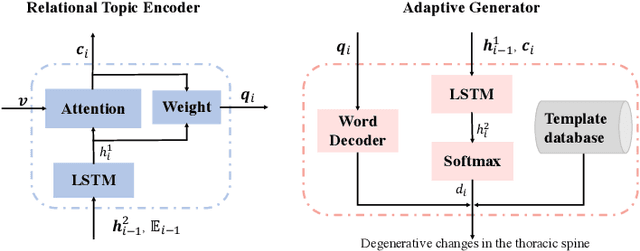
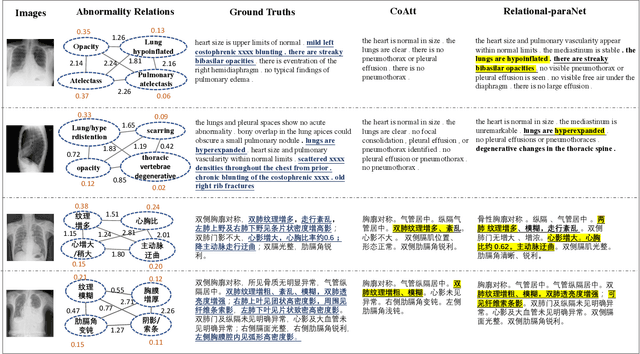
Beyond generating long and topic-coherent paragraphs in traditional captioning tasks, the medical image report composition task poses more task-oriented challenges by requiring both the highly-accurate medical term diagnosis and multiple heterogeneous forms of information including impression and findings. Current methods often generate the most common sentences due to dataset bias for individual case, regardless of whether the sentences properly capture key entities and relationships. Such limitations severely hinder their applicability and generalization capability in medical report composition where the most critical sentences lie in the descriptions of abnormal diseases that are relatively rare. Moreover, some medical terms appearing in one report are often entangled with each other and co-occurred, e.g. symptoms associated with a specific disease. To enforce the semantic consistency of medical terms to be incorporated into the final reports and encourage the sentence generation for rare abnormal descriptions, we propose a novel framework that unifies template retrieval and sentence generation to handle both common and rare abnormality while ensuring the semantic-coherency among the detected medical terms. Specifically, our approach exploits hybrid-knowledge co-reasoning: i) explicit relationships among all abnormal medical terms to induce the visual attention learning and topic representation encoding for better topic-oriented symptoms descriptions; ii) adaptive generation mode that changes between the template retrieval and sentence generation according to a contextual topic encoder. Experimental results on two medical report benchmarks demonstrate the superiority of the proposed framework in terms of both human and metrics evaluation.
Can non-specialists provide high quality gold standard labels in challenging modalities?
Jul 30, 2021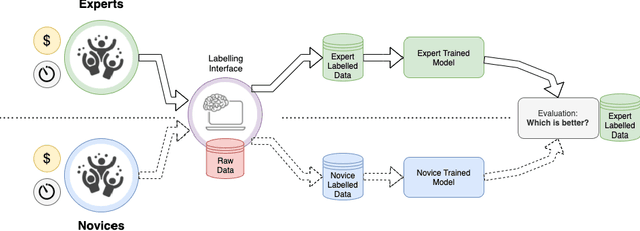
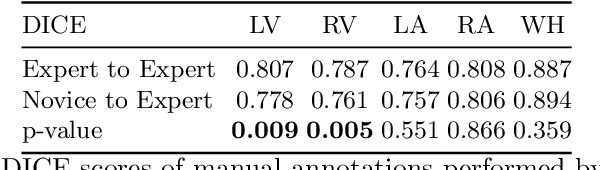
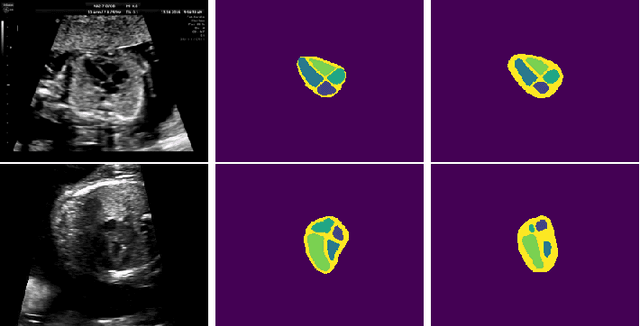
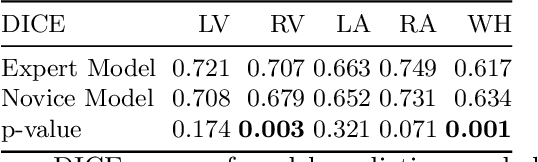
Probably yes. -- Supervised Deep Learning dominates performance scores for many computer vision tasks and defines the state-of-the-art. However, medical image analysis lags behind natural image applications. One of the many reasons is the lack of well annotated medical image data available to researchers. One of the first things researchers are told is that we require significant expertise to reliably and accurately interpret and label such data. We see significant inter- and intra-observer variability between expert annotations of medical images. Still, it is a widely held assumption that novice annotators are unable to provide useful annotations for use by clinical Deep Learning models. In this work we challenge this assumption and examine the implications of using a minimally trained novice labelling workforce to acquire annotations for a complex medical image dataset. We study the time and cost implications of using novice annotators, the raw performance of novice annotators compared to gold-standard expert annotators, and the downstream effects on a trained Deep Learning segmentation model's performance for detecting a specific congenital heart disease (hypoplastic left heart syndrome) in fetal ultrasound imaging.
Deep Learning on Image Denoising: An overview
Jan 16, 2020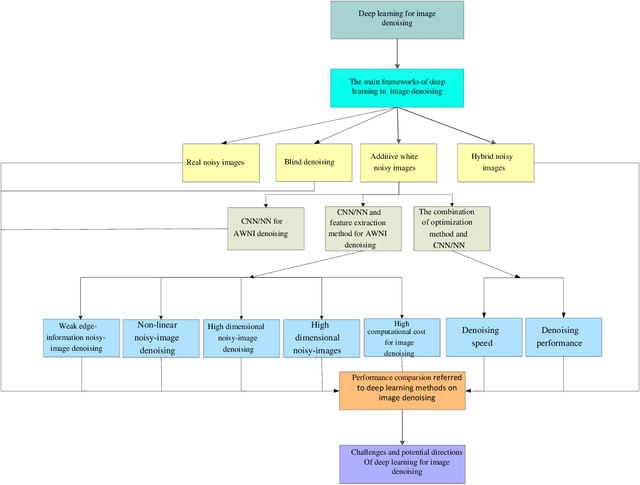
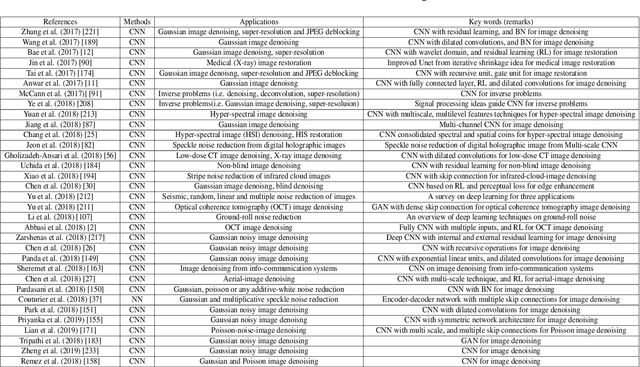
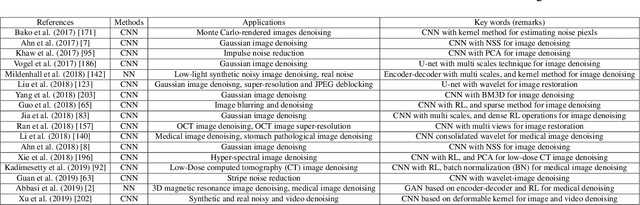
Deep learning techniques have obtained much attention in image denoising. However, deep learning methods of different types deal with the noise have enormous differences. Specifically, discriminative learning based on deep learning can well address the Gaussian noise. Optimization model methods based on deep learning have good effect on estimating of the real noise. So far, there are little related researches to summarize different deep learning techniques for image denoising. In this paper, we make such a comparative study of different deep techniques in image denoising. We first classify the (1) deep convolutional neural networks (CNNs) for additive white noisy images, (2) deep CNNs for real noisy images, (3) deep CNNs for blind denoising and (4) deep CNNs for hybrid noisy images, which is the combination of noisy, blurred and low-resolution images. Then, we analyze the motivations and principles of deep learning methods of different types. Next, we compare and verify the state-of-the-art methods on public denoising datasets in terms of quantitative and qualitative analysis. Finally, we point out some potential challenges and directions of future research.
Deep Network for Scatterer Distribution Estimation for Ultrasound Image Simulation
Jun 17, 2020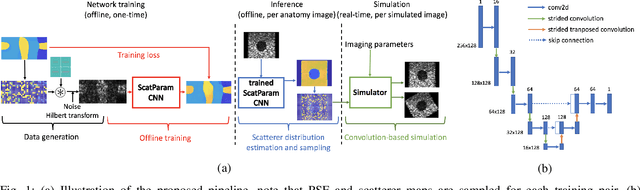

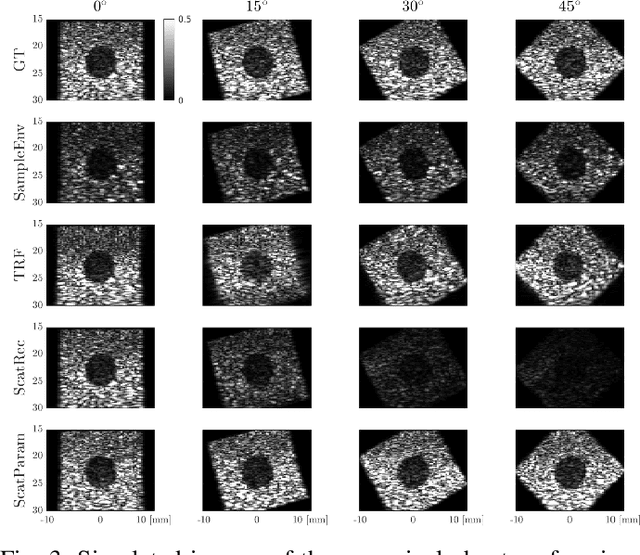
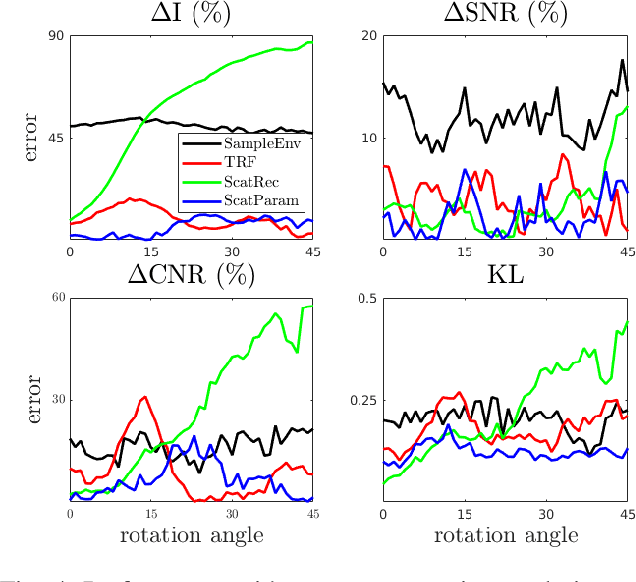
Simulation-based ultrasound training can be an essential educational tool. Realistic ultrasound image appearance with typical speckle texture can be modeled as convolution of a point spread function with point scatterers representing tissue microstructure. Such scatterer distribution, however, is in general not known and its estimation for a given tissue type is fundamentally an ill-posed inverse problem. In this paper, we demonstrate a convolutional neural network approach for probabilistic scatterer estimation from observed ultrasound data. We herein propose to impose a known statistical distribution on scatterers and learn the mapping between ultrasound image and distribution parameter map by training a convolutional neural network on synthetic images. In comparison with several existing approaches, we demonstrate in numerical simulations and with in-vivo images that the synthesized images from scatterer representations estimated with our approach closely match the observations with varying acquisition parameters such as compression and rotation of the imaged domain.
Achieving on-Mobile Real-Time Super-Resolution with Neural Architecture and Pruning Search
Aug 18, 2021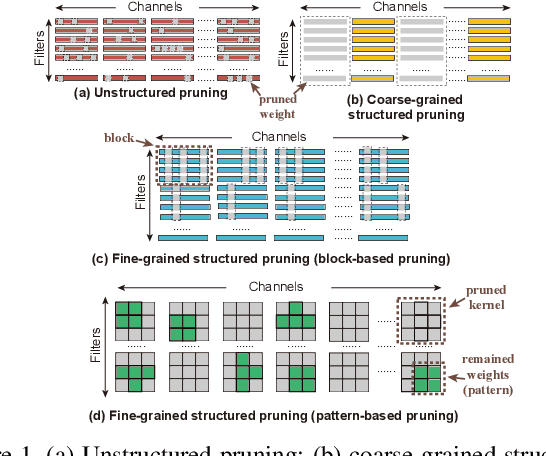
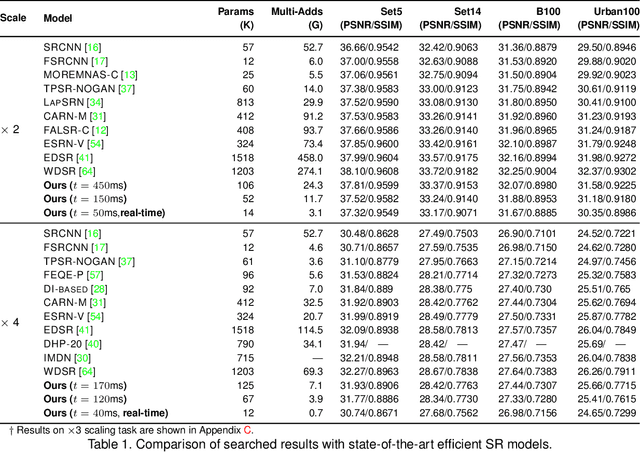
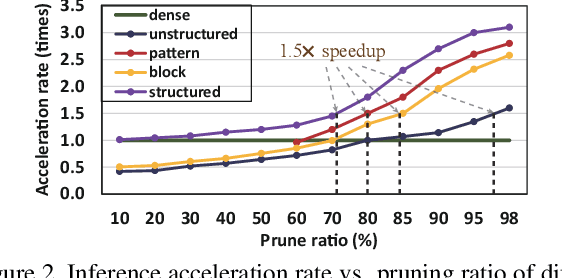
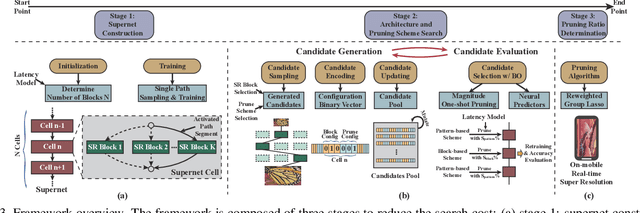
Though recent years have witnessed remarkable progress in single image super-resolution (SISR) tasks with the prosperous development of deep neural networks (DNNs), the deep learning methods are confronted with the computation and memory consumption issues in practice, especially for resource-limited platforms such as mobile devices. To overcome the challenge and facilitate the real-time deployment of SISR tasks on mobile, we combine neural architecture search with pruning search and propose an automatic search framework that derives sparse super-resolution (SR) models with high image quality while satisfying the real-time inference requirement. To decrease the search cost, we leverage the weight sharing strategy by introducing a supernet and decouple the search problem into three stages, including supernet construction, compiler-aware architecture and pruning search, and compiler-aware pruning ratio search. With the proposed framework, we are the first to achieve real-time SR inference (with only tens of milliseconds per frame) for implementing 720p resolution with competitive image quality (in terms of PSNR and SSIM) on mobile platforms (Samsung Galaxy S20).
4D iterative reconstruction of brain fMRI in the moving fetus
Nov 22, 2021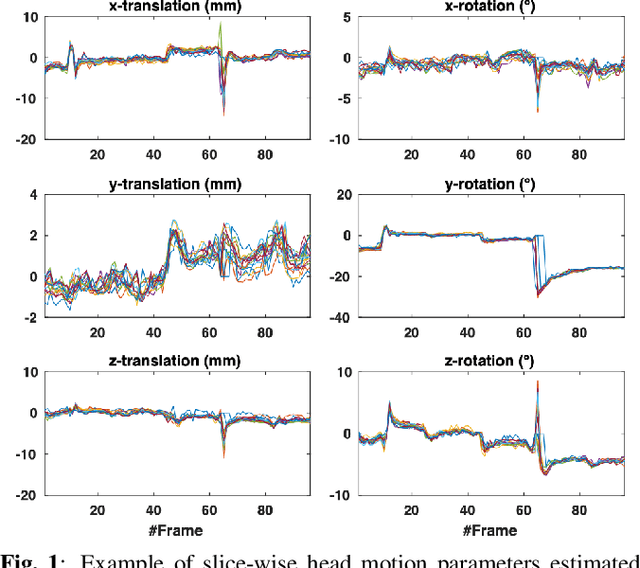
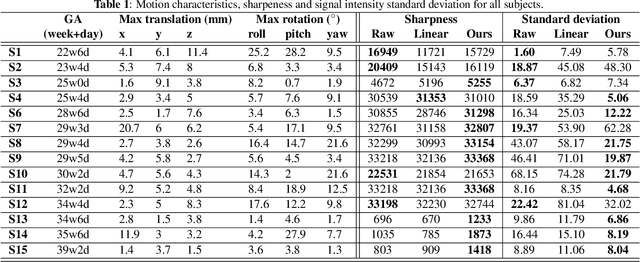
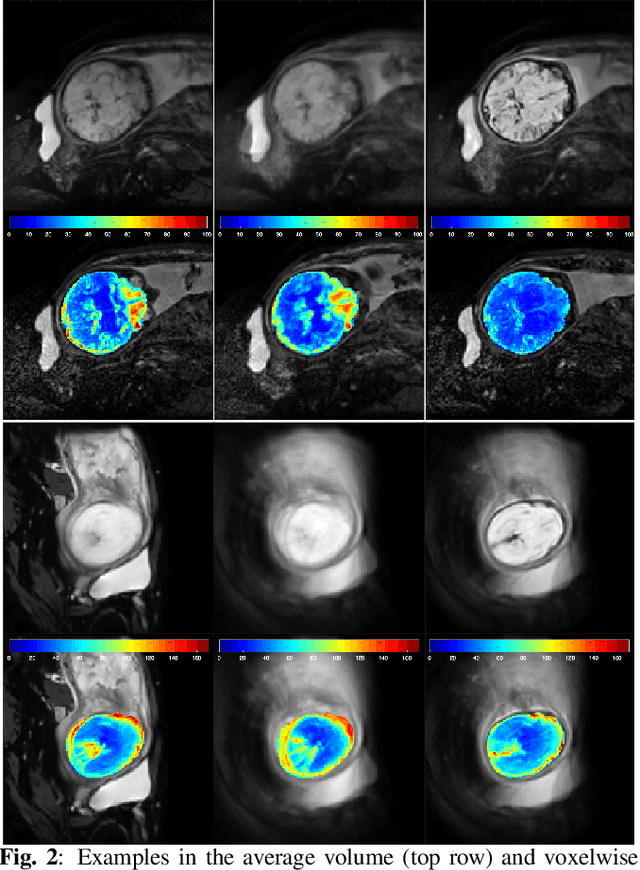
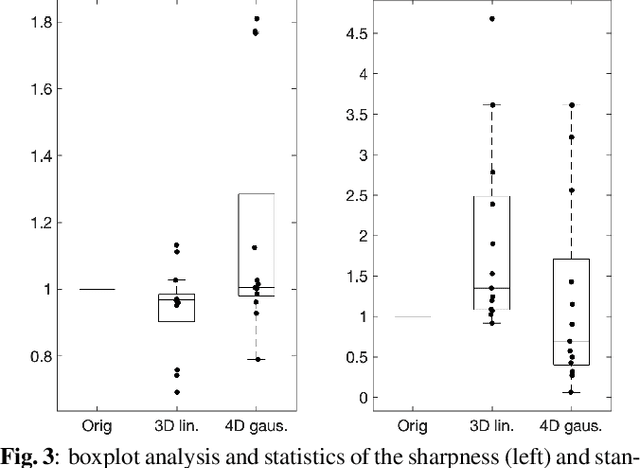
Resting-state functional Magnetic Resonance Imaging (fMRI) is a powerful imaging technique for studying functional development of the brain in utero. However, unpredictable and excessive movement of fetuses has limited clinical application since it causes substantial signal fluctuations which can systematically alter observed patterns of functional connectivity. Previous studies have focused on the accurate estimation of the motion parameters in case of large fetal head movement and used a 3D single step interpolation approach at each timepoint to recover motion-free fMRI images. This does not guarantee that the reconstructed image corresponds to the minimum error representation of fMRI time series given the acquired data. Here, we propose a novel technique based on four dimensional iterative reconstruction of the scattered slices acquired during fetal fMRI. The accuracy of the proposed method was quantitatively evaluated on a group of real clinical fMRI fetuses. The results indicate improvements of reconstruction quality compared to the conventional 3D interpolation approach.
State-of-The-Art Fuzzy Active Contour Models for Image Segmentation
Aug 01, 2020



Image segmentation is the initial step for every image analysis task. A large variety of segmentation algorithm has been proposed in the literature during several decades with some mixed success. Among them, the fuzzy energy based active contour models get attention to the researchers during last decade which results in development of various methods. A good segmentation algorithm should perform well in a large number of images containing noise, blur, low contrast, region in-homogeneity, etc. However, the performances of the most of the existing fuzzy energy based active contour models have been evaluated typically on the limited number of images. In this article, our aim is to review the existing fuzzy active contour models from the theoretical point of view and also evaluate them experimentally on a large set of images under the various conditions. The analysis under a large variety of images provides objective insight into the strengths and weaknesses of various fuzzy active contour models. Finally, we discuss several issues and future research direction on this particular topic.
General Greedy De-bias Learning
Dec 21, 2021
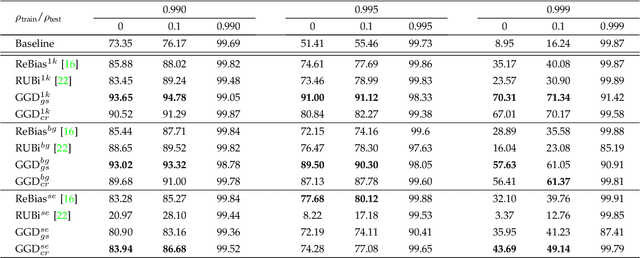
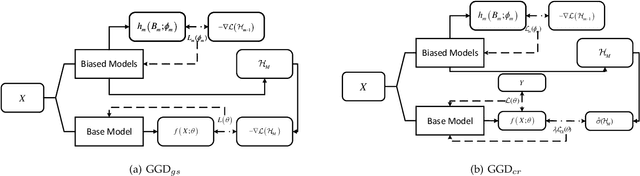
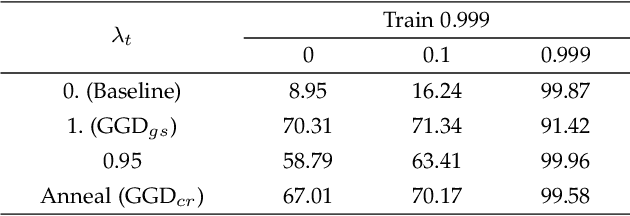
Neural networks often make predictions relying on the spurious correlations from the datasets rather than the intrinsic properties of the task of interest, facing sharp degradation on out-of-distribution (OOD) test data. Existing de-bias learning frameworks try to capture specific dataset bias by bias annotations, they fail to handle complicated OOD scenarios. Others implicitly identify the dataset bias by the special design on the low capability biased model or the loss, but they degrade when the training and testing data are from the same distribution. In this paper, we propose a General Greedy De-bias learning framework (GGD), which greedily trains the biased models and the base model like gradient descent in functional space. It encourages the base model to focus on examples that are hard to solve with biased models, thus remaining robust against spurious correlations in the test stage. GGD largely improves models' OOD generalization ability on various tasks, but sometimes over-estimates the bias level and degrades on the in-distribution test. We further re-analyze the ensemble process of GGD and introduce the Curriculum Regularization into GGD inspired by curriculum learning, which achieves a good trade-off between in-distribution and out-of-distribution performance. Extensive experiments on image classification, adversarial question answering, and visual question answering demonstrate the effectiveness of our method. GGD can learn a more robust base model under the settings of both task-specific biased models with prior knowledge and self-ensemble biased model without prior knowledge.
PyRetri: A PyTorch-based Library for Unsupervised Image Retrieval by Deep Convolutional Neural Networks
May 02, 2020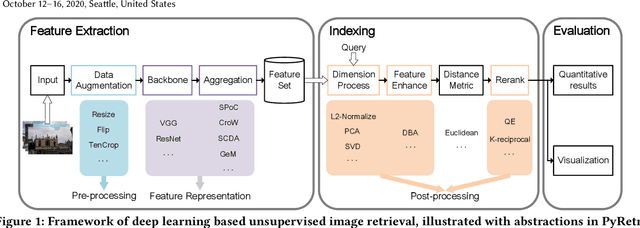
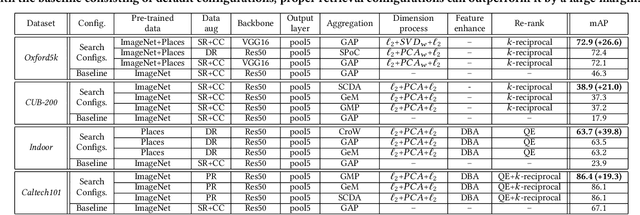

Despite significant progress of applying deep learning methods to the field of content-based image retrieval, there has not been a software library that covers these methods in a unified manner. In order to fill this gap, we introduce PyRetri, an open source library for deep learning based unsupervised image retrieval. The library encapsulates the retrieval process in several stages and provides functionality that covers various prominent methods for each stage. The idea underlying its design is to provide a unified platform for deep learning based image retrieval research, with high usability and extensibility. To the best of our knowledge, this is the first open-source library for unsupervised image retrieval by deep learning.