 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Single-Image Super-Resolution via CNNs and TV-TV Minimization
Apr 02, 2020
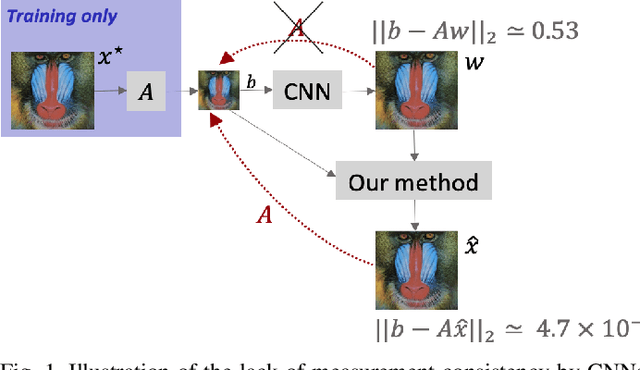
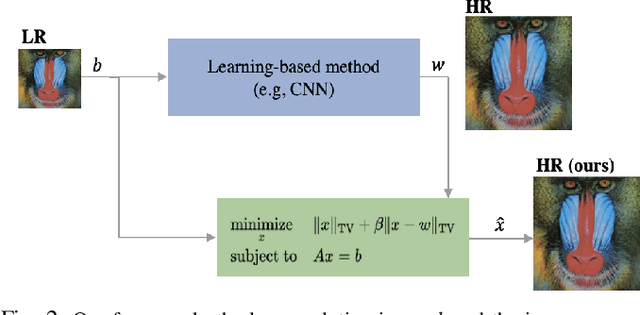


Single-image super-resolution is the process of increasing the resolution of an image, obtaining a high-resolution (HR) image from a low-resolution (LR) one. By leveraging large training datasets, convolutional neural networks (CNNs) currently achieve the state-of-the-art performance in this task. Yet, during testing/deployment, they fail to enforce consistency between the HR and LR images: if we downsample the output HR image, it never matches its LR input. Based on this observation, we propose to post-process the CNN outputs with an optimization problem that we call TV-TV minimization, which enforces consistency. As our extensive experiments show, such post-processing not only improves the quality of the images, in terms of PSNR and SSIM, but also makes the super-resolution task robust to operator mismatch, i.e., when the true downsampling operator is different from the one used to create the training dataset.
Diverse Image Captioning with Context-Object Split Latent Spaces
Nov 02, 2020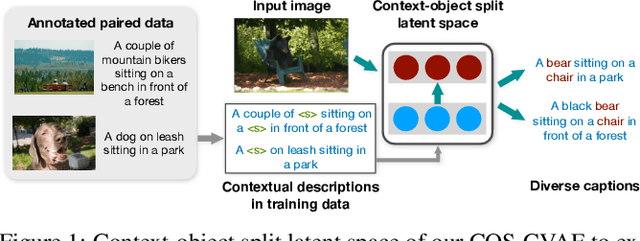

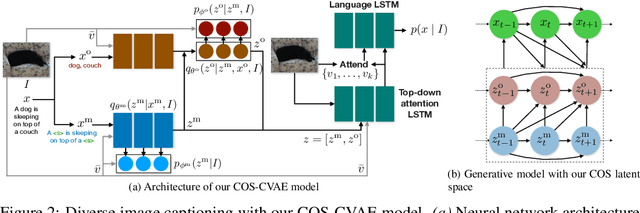
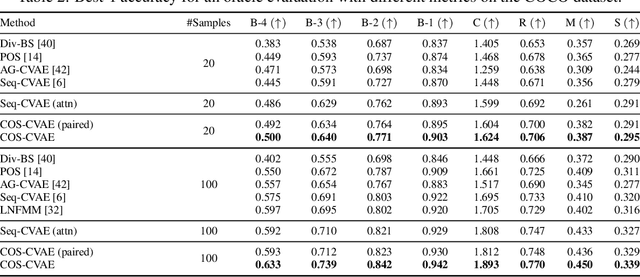
Diverse image captioning models aim to learn one-to-many mappings that are innate to cross-domain datasets, such as of images and texts. Current methods for this task are based on generative latent variable models, e.g. VAEs with structured latent spaces. Yet, the amount of multimodality captured by prior work is limited to that of the paired training data -- the true diversity of the underlying generative process is not fully captured. To address this limitation, we leverage the contextual descriptions in the dataset that explain similar contexts in different visual scenes. To this end, we introduce a novel factorization of the latent space, termed context-object split, to model diversity in contextual descriptions across images and texts within the dataset. Our framework not only enables diverse captioning through context-based pseudo supervision, but extends this to images with novel objects and without paired captions in the training data. We evaluate our COS-CVAE approach on the standard COCO dataset and on the held-out COCO dataset consisting of images with novel objects, showing significant gains in accuracy and diversity.
A Complex Constrained Total Variation Image Denoising Algorithm with Application to Phase Retrieval
Sep 12, 2021
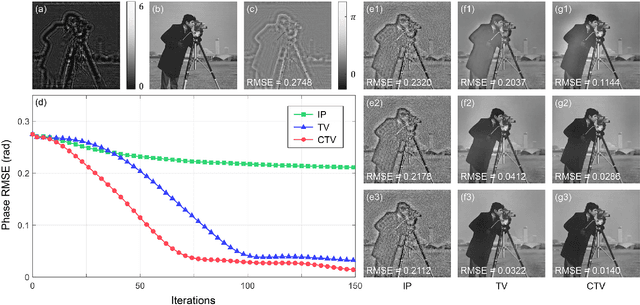
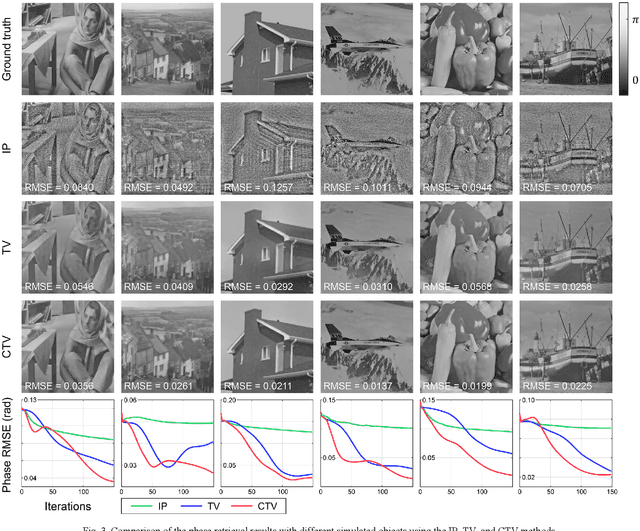
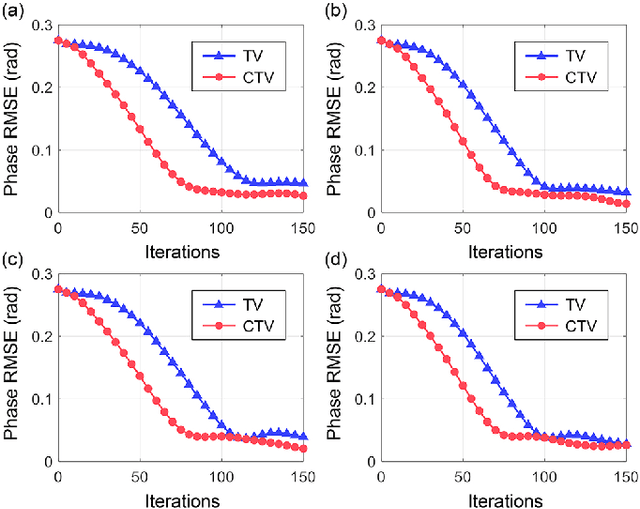
This paper considers the constrained total variation (TV) denoising problem for complex-valued images. We extend the definition of TV seminorms for real-valued images to dealing with complex-valued ones. In particular, we introduce two types of complex TV in both isotropic and anisotropic forms. To solve the constrained denoising problem, we adopt a dual approach and derive an accelerated gradient projection algorithm. We further generalize the proposed denoising algorithm as a key building block of the proximal gradient scheme to solve a vast class of complex constrained optimization problems with TV regularizers. As an example, we apply the proposed algorithmic framework to phase retrieval. We combine the complex TV regularizer with the conventional projection-based method within the constraint complex TV model. Initial results from both simulated and optical experiments demonstrate the validity of the constrained TV model in extracting sparsity priors within complex-valued images, while also utilizing physically tractable constraints that help speed up convergence.
A Shared Representation for Photorealistic Driving Simulators
Dec 09, 2021
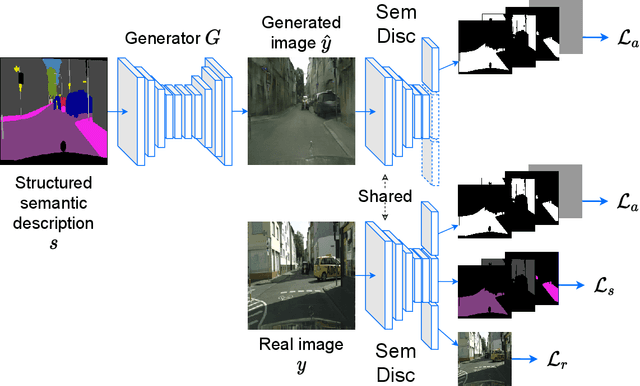


A powerful simulator highly decreases the need for real-world tests when training and evaluating autonomous vehicles. Data-driven simulators flourished with the recent advancement of conditional Generative Adversarial Networks (cGANs), providing high-fidelity images. The main challenge is synthesizing photorealistic images while following given constraints. In this work, we propose to improve the quality of generated images by rethinking the discriminator architecture. The focus is on the class of problems where images are generated given semantic inputs, such as scene segmentation maps or human body poses. We build on successful cGAN models to propose a new semantically-aware discriminator that better guides the generator. We aim to learn a shared latent representation that encodes enough information to jointly do semantic segmentation, content reconstruction, along with a coarse-to-fine grained adversarial reasoning. The achieved improvements are generic and simple enough to be applied to any architecture of conditional image synthesis. We demonstrate the strength of our method on the scene, building, and human synthesis tasks across three different datasets. The code is available at https://github.com/vita-epfl/SemDisc.
Non-Autoregressive Image Captioning with Counterfactuals-Critical Multi-Agent Learning
May 10, 2020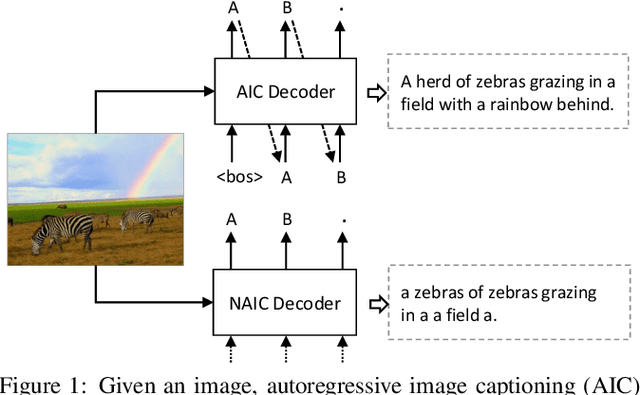
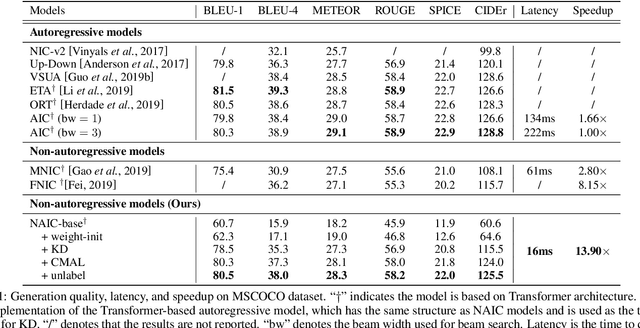
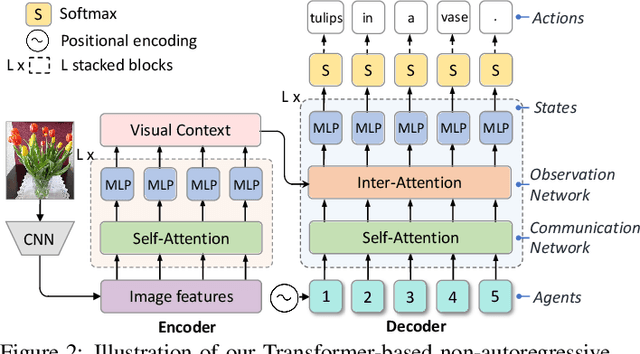

Most image captioning models are autoregressive, i.e. they generate each word by conditioning on previously generated words, which leads to heavy latency during inference. Recently, non-autoregressive decoding has been proposed in machine translation to speed up the inference time by generating all words in parallel. Typically, these models use the word-level cross-entropy loss to optimize each word independently. However, such a learning process fails to consider the sentence-level consistency, thus resulting in inferior generation quality of these non-autoregressive models. In this paper, we propose a Non-Autoregressive Image Captioning (NAIC) model with a novel training paradigm: Counterfactuals-critical Multi-Agent Learning (CMAL). CMAL formulates NAIC as a multi-agent reinforcement learning system where positions in the target sequence are viewed as agents that learn to cooperatively maximize a sentence-level reward. Besides, we propose to utilize massive unlabeled images to boost captioning performance. Extensive experiments on MSCOCO image captioning benchmark show that our NAIC model achieves a performance comparable to state-of-the-art autoregressive models, while brings 13.9x decoding speedup.
GraphFPN: Graph Feature Pyramid Network for Object Detection
Aug 02, 2021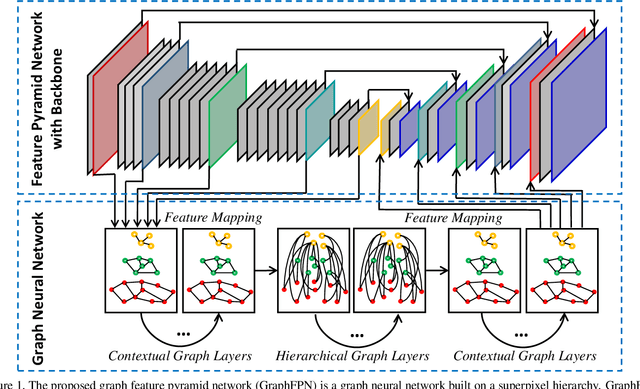
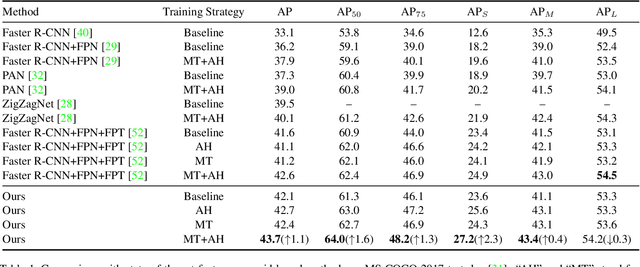
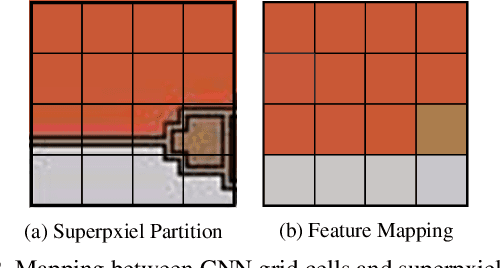

Feature pyramids have been proven powerful in image understanding tasks that require multi-scale features. State-of-the-art methods for multi-scale feature learning focus on performing feature interactions across space and scales using neural networks with a fixed topology. In this paper, we propose graph feature pyramid networks that are capable of adapting their topological structures to varying intrinsic image structures and supporting simultaneous feature interactions across all scales. We first define an image-specific superpixel hierarchy for each input image to represent its intrinsic image structures. The graph feature pyramid network inherits its structure from this superpixel hierarchy. Contextual and hierarchical layers are designed to achieve feature interactions within the same scale and across different scales. To make these layers more powerful, we introduce two types of local channel attention for graph neural networks by generalizing global channel attention for convolutional neural networks. The proposed graph feature pyramid network can enhance the multiscale features from a convolutional feature pyramid network. We evaluate our graph feature pyramid network in the object detection task by integrating it into the Faster R-CNN algorithm. The modified algorithm outperforms not only previous state-of-the-art feature pyramid-based methods with a clear margin but also other popular detection methods on both MS-COCO 2017 validation and test datasets.
A Bayesian Treatment of Real-to-Sim for Deformable Object Manipulation
Dec 09, 2021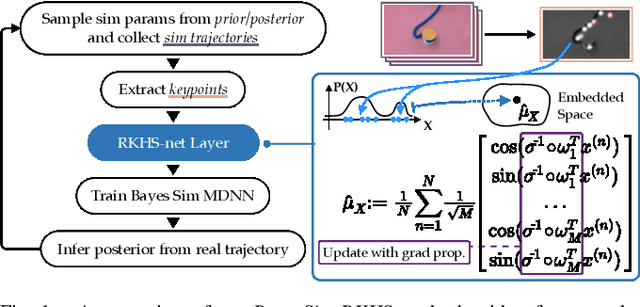


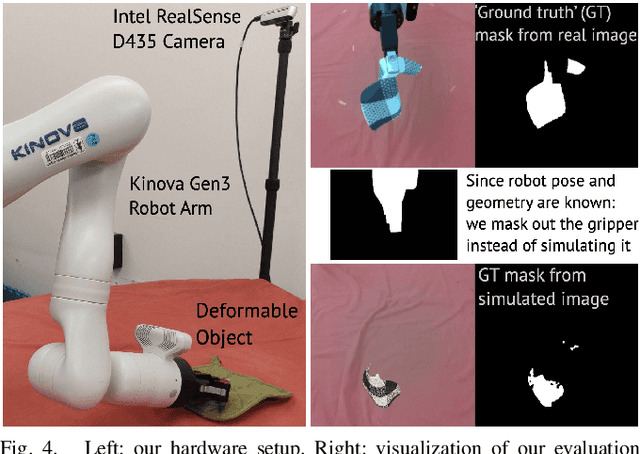
Deformable object manipulation remains a challenging task in robotics research. Conventional techniques for parameter inference and state estimation typically rely on a precise definition of the state space and its dynamics. While this is appropriate for rigid objects and robot states, it is challenging to define the state space of a deformable object and how it evolves in time. In this work, we pose the problem of inferring physical parameters of deformable objects as a probabilistic inference task defined with a simulator. We propose a novel methodology for extracting state information from image sequences via a technique to represent the state of a deformable object as a distribution embedding. This allows to incorporate noisy state observations directly into modern Bayesian simulation-based inference tools in a principled manner. Our experiments confirm that we can estimate posterior distributions of physical properties, such as elasticity, friction and scale of highly deformable objects, such as cloth and ropes. Overall, our method addresses the real-to-sim problem probabilistically and helps to better represent the evolution of the state of deformable objects.
BuildFormer: Automatic building extraction with vision transformer
Nov 29, 2021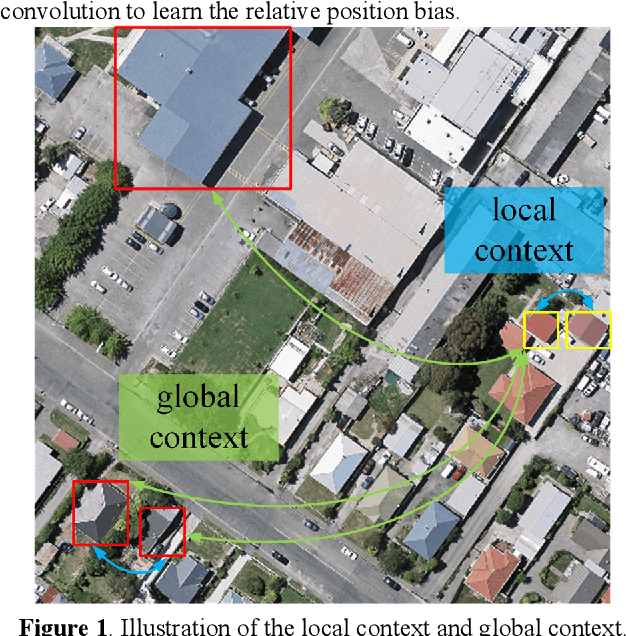
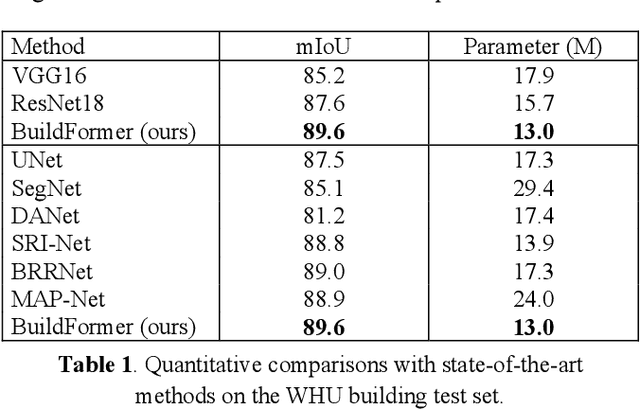
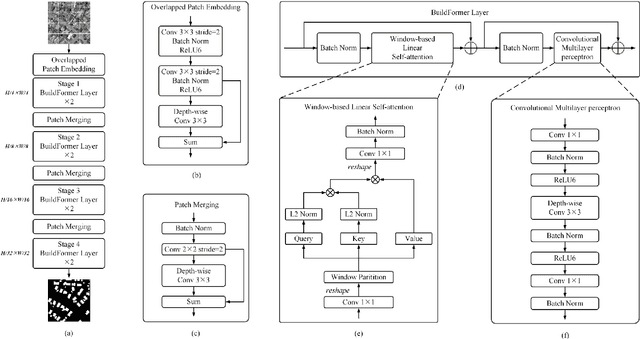
Building extraction from fine-resolution remote sensing images plays a vital role in numerous geospatial applications, such as urban planning, population statistic, economic assessment and disaster management. With the advancement of deep learning technology, deep convolutional neural networks (DCNNs) have dominated the automatic building extraction task for many years. However, the local property of DCNNs limits the extraction of global information, weakening the ability of the network for recognizing the building instance. Recently, the Transformer comprises a hot topic in the computer vision domain and achieves state-of-the-art performance in fundamental vision tasks, such as image classification, semantic segmentation and object detection. Inspired by this, in this paper, we propose a novel transformer-based network for extracting buildings from fine-resolution remote sensing images, namely BuildFormer. In Comparision with the ResNet, the proposed method achieves an improvement of 2% in mIoU on the WHU building dataset.
Identification of splicing edges in tampered image based on Dichromatic Reflection Model
Apr 09, 2020Imaging is a sophisticated process combining a plenty of photovoltaic conversions, which lead to some spectral signatures beyond visual perception in the final images. Any manipulation against an original image will destroy these signatures and inevitably leave some traces in the final forgery. Therefore we present a novel optic-physical method to discriminate splicing edges from natural edges in a tampered image. First, we transform the forensic image from RGB into color space of S and o1o2. Then on the assumption of Dichromatic Reflection Model, edges in the image are discovered by composite gradient and classified into different types based on their different photometric properties. Finally, splicing edges are reserved against natural ones by a simple logical algorithm. Experiment results show the efficacy of the proposed method.
Seeking an Optimal Approach for Computer-Aided Pulmonary Embolism Detection
Sep 15, 2021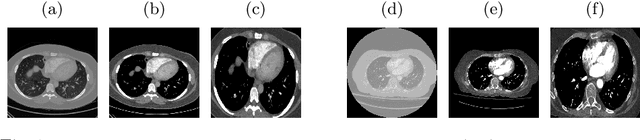
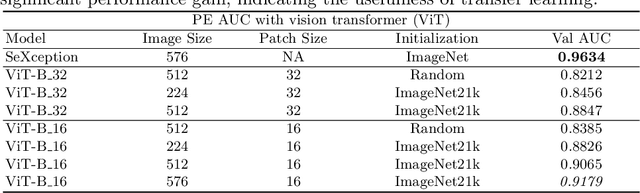
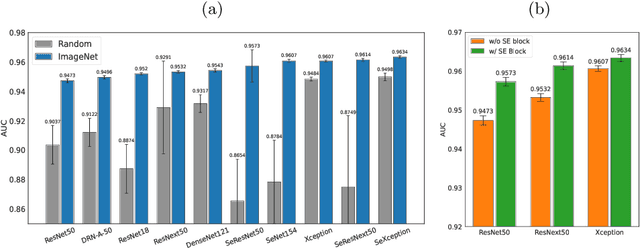
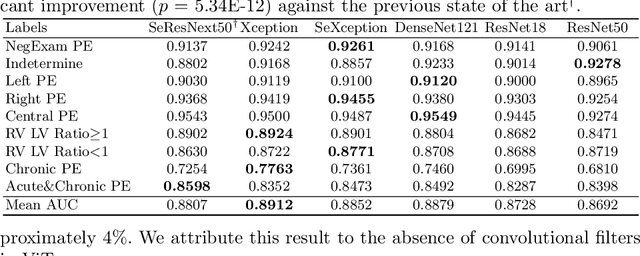
Pulmonary embolism (PE) represents a thrombus ("blood clot"), usually originating from a lower extremity vein, that travels to the blood vessels in the lung, causing vascular obstruction and in some patients, death. This disorder is commonly diagnosed using CT pulmonary angiography (CTPA). Deep learning holds great promise for the computer-aided CTPA diagnosis (CAD) of PE. However, numerous competing methods for a given task in the deep learning literature exist, causing great confusion regarding the development of a CAD PE system. To address this confusion, we present a comprehensive analysis of competing deep learning methods applicable to PE diagnosis using CTPA at the both image and exam levels. At the image level, we compare convolutional neural networks (CNNs) with vision transformers, and contrast self-supervised learning (SSL) with supervised learning, followed by an evaluation of transfer learning compared with training from scratch. At the exam level, we focus on comparing conventional classification (CC) with multiple instance learning (MIL). Our extensive experiments consistently show: (1) transfer learning consistently boosts performance despite differences between natural images and CT scans, (2) transfer learning with SSL surpasses its supervised counterparts; (3) CNNs outperform vision transformers, which otherwise show satisfactory performance; and (4) CC is, surprisingly, superior to MIL. Compared with the state of the art, our optimal approach provides an AUC gain of 0.2\% and 1.05\% for image-level and exam-level, respectively.