 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
StyleFusion: A Generative Model for Disentangling Spatial Segments
Jul 15, 2021
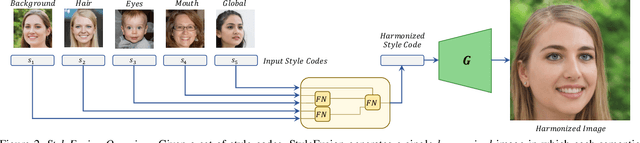


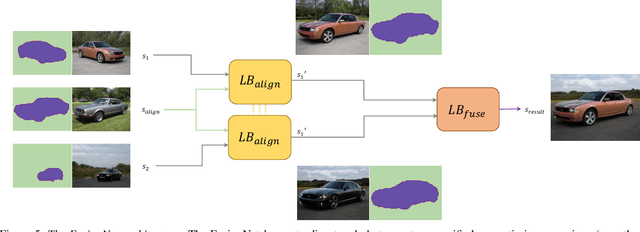
We present StyleFusion, a new mapping architecture for StyleGAN, which takes as input a number of latent codes and fuses them into a single style code. Inserting the resulting style code into a pre-trained StyleGAN generator results in a single harmonized image in which each semantic region is controlled by one of the input latent codes. Effectively, StyleFusion yields a disentangled representation of the image, providing fine-grained control over each region of the generated image. Moreover, to help facilitate global control over the generated image, a special input latent code is incorporated into the fused representation. StyleFusion operates in a hierarchical manner, where each level is tasked with learning to disentangle a pair of image regions (e.g., the car body and wheels). The resulting learned disentanglement allows one to modify both local, fine-grained semantics (e.g., facial features) as well as more global features (e.g., pose and background), providing improved flexibility in the synthesis process. As a natural extension, StyleFusion enables one to perform semantically-aware cross-image mixing of regions that are not necessarily aligned. Finally, we demonstrate how StyleFusion can be paired with existing editing techniques to more faithfully constrain the edit to the user's region of interest.
A single image deep learning approach to restoration of corrupted remote sensing products
Apr 08, 2020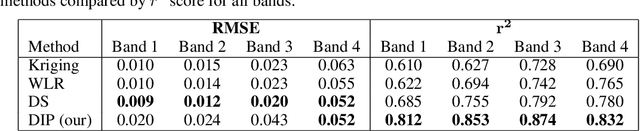
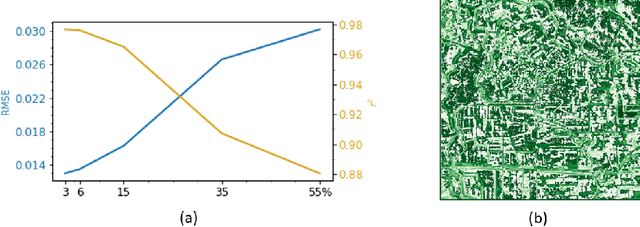
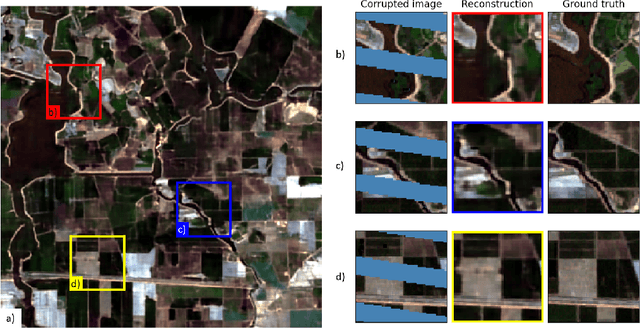
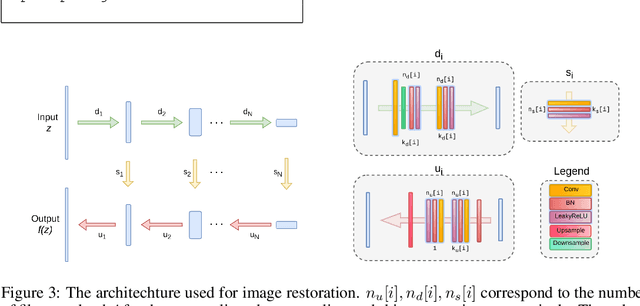
Remote sensing images are used for a variety of analyses, from agricultural monitoring, to disaster relief, to resource planning, among others. The images can be corrupted due to a number of reasons, including instrument errors and natural obstacles such as clouds. We present here a novel approach for reconstruction of missing information in such cases using only the corrupted image as the input. The Deep Image Prior methodology eliminates the need for a pre-trained network or an image database. It is shown that the approach easily beats the performance of traditional single-image methods.
Transfer Learning U-Net Deep Learning for Lung Ultrasound Segmentation
Oct 05, 2021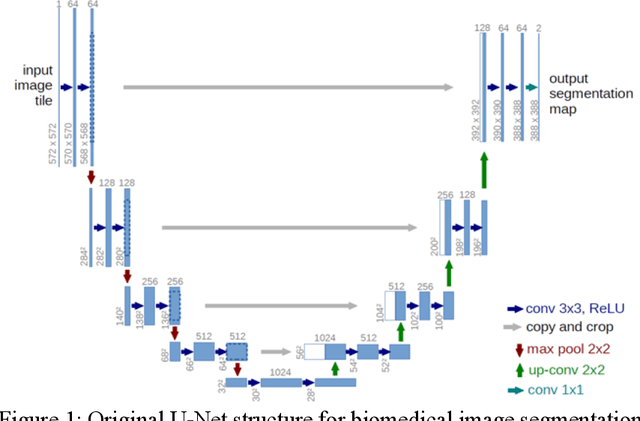
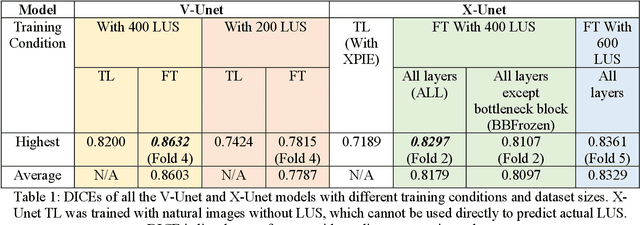
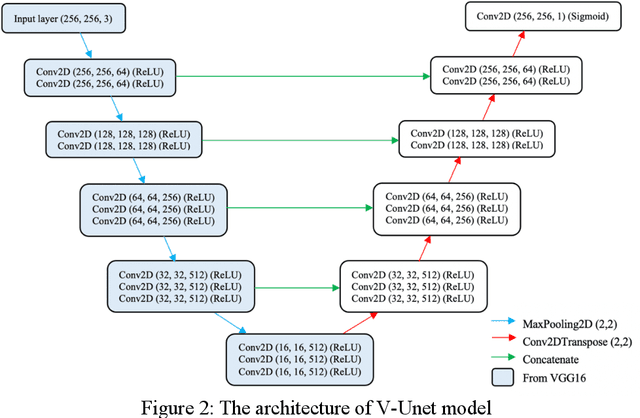
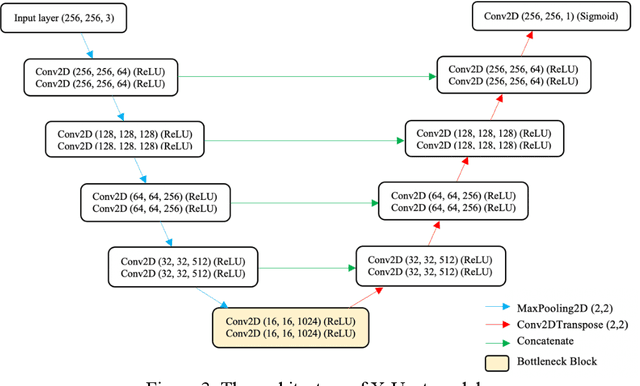
Transfer learning (TL) for medical image segmentation helps deep learning models achieve more accurate performances when there are scarce medical images. This study focuses on completing segmentation of the ribs from lung ultrasound images and finding the best TL technique with U-Net, a convolutional neural network for precise and fast image segmentation. Two approaches of TL were used, using a pre-trained VGG16 model to build the U-Net (V-Unet) and pre-training U-Net network with grayscale natural salient object dataset (X-Unet). Visual results and dice coefficients (DICE) of the models were compared. X-Unet showed more accurate and artifact-free visual performances on the actual mask prediction, despite its lower DICE than V-Unet. A partial-frozen network fine-tuning (FT) technique was also applied to X-Unet to compare results between different FT strategies, which FT all layers slightly outperformed freezing part of the network. The effect of dataset sizes was also evaluated, showing the importance of the combination between TL and data augmentation.
Learning to Prompt for Continual Learning
Dec 16, 2021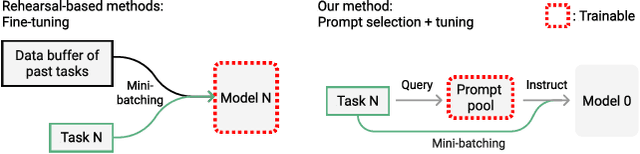
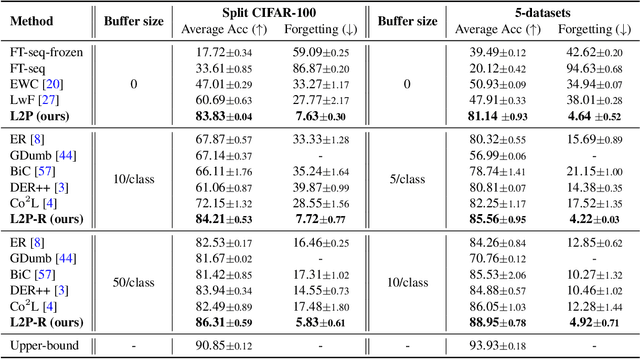
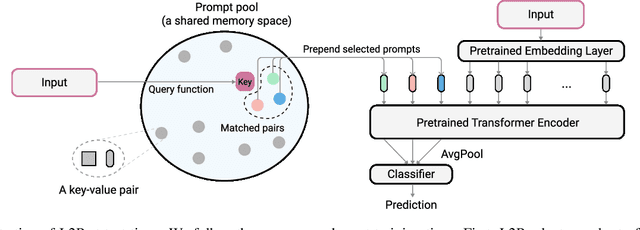
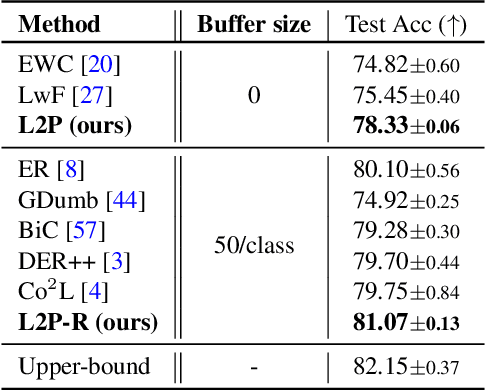
The mainstream paradigm behind continual learning has been to adapt the model parameters to non-stationary data distributions, where catastrophic forgetting is the central challenge. Typical methods rely on a rehearsal buffer or known task identity at test time to retrieve learned knowledge and address forgetting, while this work presents a new paradigm for continual learning that aims to train a more succinct memory system without accessing task identity at test time. Our method learns to dynamically prompt (L2P) a pre-trained model to learn tasks sequentially under different task transitions. In our proposed framework, prompts are small learnable parameters, which are maintained in a memory space. The objective is to optimize prompts to instruct the model prediction and explicitly manage task-invariant and task-specific knowledge while maintaining model plasticity. We conduct comprehensive experiments under popular image classification benchmarks with different challenging continual learning settings, where L2P consistently outperforms prior state-of-the-art methods. Surprisingly, L2P achieves competitive results against rehearsal-based methods even without a rehearsal buffer and is directly applicable to challenging task-agnostic continual learning. Source code is available at https://github.com/google-research/l2p.
Where to Look and How to Describe: Fashion Image Retrieval with an Attentional Heterogeneous Bilinear Network
Oct 26, 2020
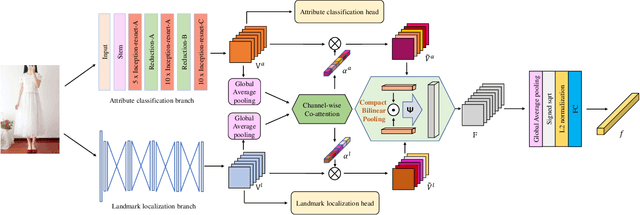
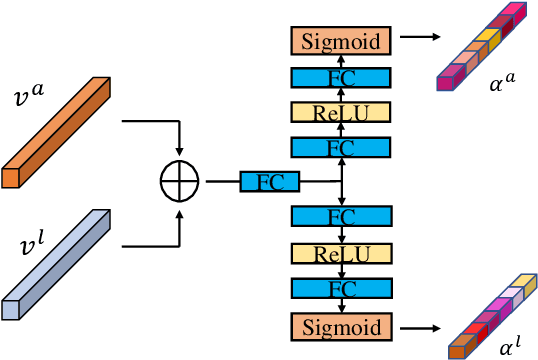
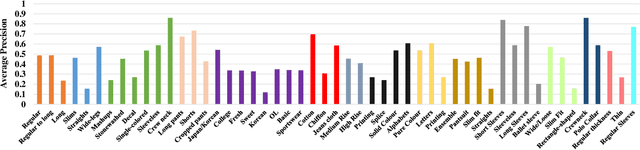
Fashion products typically feature in compositions of a variety of styles at different clothing parts. In order to distinguish images of different fashion products, we need to extract both appearance (i.e., "how to describe") and localization (i.e.,"where to look") information, and their interactions. To this end, we propose a biologically inspired framework for image-based fashion product retrieval, which mimics the hypothesized twostream visual processing system of human brain. The proposed attentional heterogeneous bilinear network (AHBN) consists of two branches: a deep CNN branch to extract fine-grained appearance attributes and a fully convolutional branch to extract landmark localization information. A joint channel-wise attention mechanism is further applied to the extracted heterogeneous features to focus on important channels, followed by a compact bilinear pooling layer to model the interaction of the two streams. Our proposed framework achieves satisfactory performance on three image-based fashion product retrieval benchmarks.
Confidence Measure Guided Single Image De-raining
Sep 10, 2019
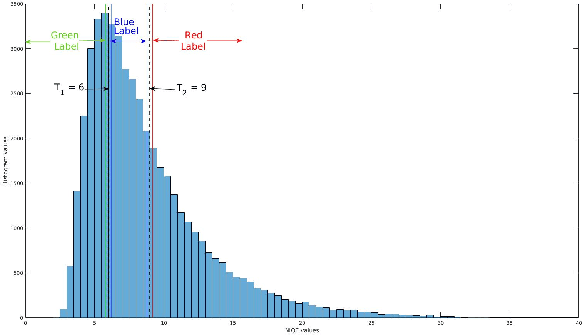


Single image de-raining is an extremely challenging problem since the rainy images contain rain streaks which often vary in size, direction and density. This varying characteristic of rain streaks affect different parts of the image differently. Previous approaches have attempted to address this problem by leveraging some prior information to remove rain streaks from a single image. One of the major limitations of these approaches is that they do not consider the location information of rain drops in the image. The proposed Image Quality-based single image Deraining using Confidence measure (QuDeC), network addresses this issue by learning the quality or distortion level of each patch in the rainy image, and further processes this information to learn the rain content at different scales. In addition, we introduce a technique which guides the network to learn the network weights based on the confidence measure about the estimate of both quality at each location and residual rain streak information (residual map). Extensive experiments on synthetic and real datasets demonstrate that the proposed method achieves significant improvements over the recent state-of-the-art methods.
Offloading Algorithms for Maximizing Inference Accuracy on Edge Device Under a Time Constraint
Dec 21, 2021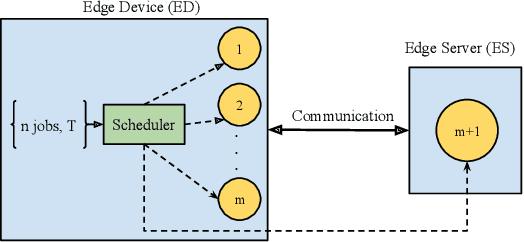
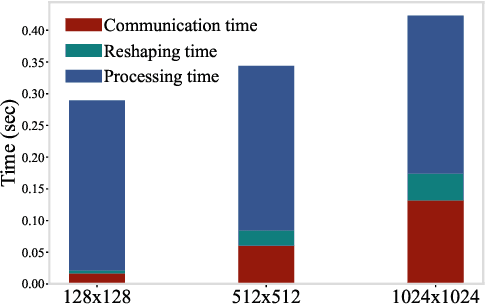
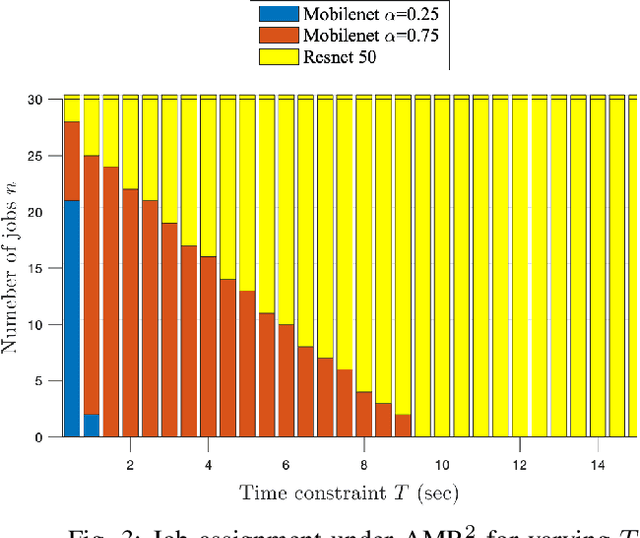
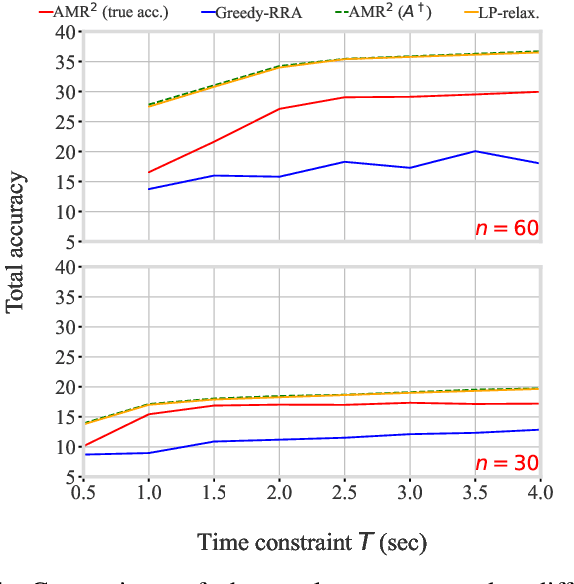
With the emergence of edge computing, the problem of offloading jobs between an Edge Device (ED) and an Edge Server (ES) received significant attention in the past. Motivated by the fact that an increasing number of applications are using Machine Learning (ML) inference, we study the problem of offloading inference jobs by considering the following novel aspects: 1) in contrast to a typical computational job, the processing time of an inference job depends on the size of the ML model, and 2) recently proposed Deep Neural Networks (DNNs) for resource-constrained devices provide the choice of scaling the model size. We formulate an assignment problem with the aim of maximizing the total inference accuracy of n data samples available at the ED, subject to a time constraint T on the makespan. We propose an approximation algorithm AMR2, and prove that it results in a makespan at most 2T, and achieves a total accuracy that is lower by a small constant from optimal total accuracy. As proof of concept, we implemented AMR2 on a Raspberry Pi, equipped with MobileNet, and is connected to a server equipped with ResNet, and studied the total accuracy and makespan performance of AMR2 for image classification application.
Learning Multiple Dense Prediction Tasks from Partially Annotated Data
Nov 29, 2021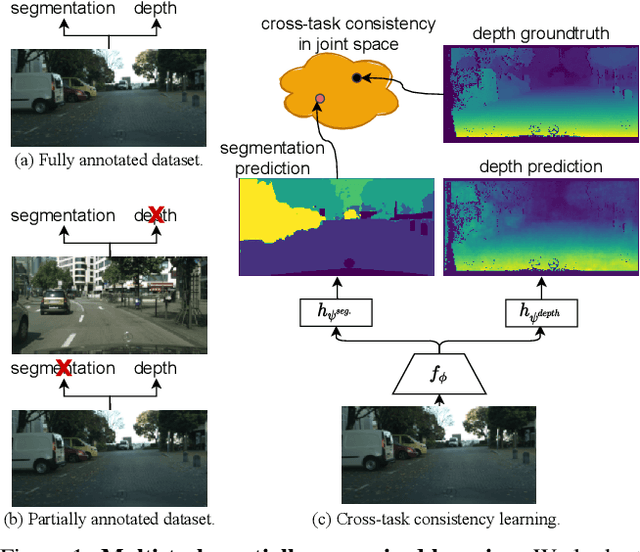
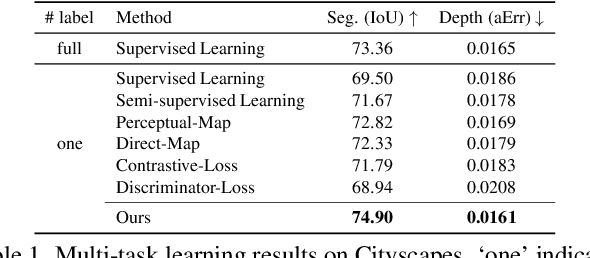
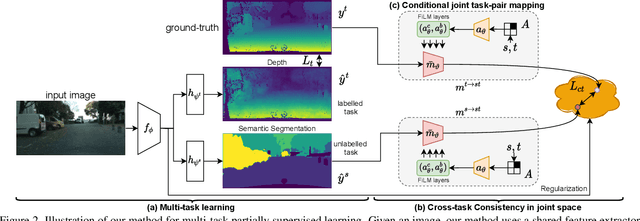
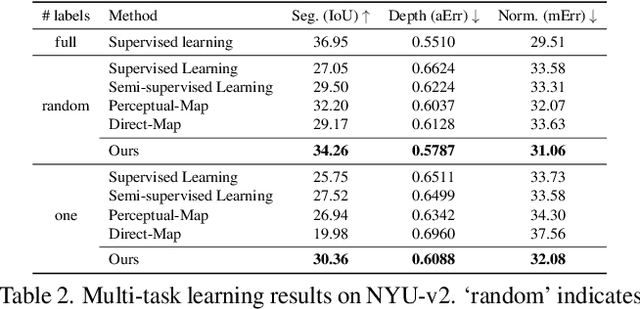
Despite the recent advances in multi-task learning of dense prediction problems, most methods rely on expensive labelled datasets. In this paper, we present a label efficient approach and look at jointly learning of multiple dense prediction tasks on partially annotated data, which we call multi-task partially-supervised learning. We propose a multi-task training procedure that successfully leverages task relations to supervise its multi-task learning when data is partially annotated. In particular, we learn to map each task pair to a joint pairwise task-space which enables sharing information between them in a computationally efficient way through another network conditioned on task pairs, and avoids learning trivial cross-task relations by retaining high-level information about the input image. We rigorously demonstrate that our proposed method effectively exploits the images with unlabelled tasks and outperforms existing semi-supervised learning approaches and related methods on three standard benchmarks.
Online Continual Learning For Visual Food Classification
Aug 15, 2021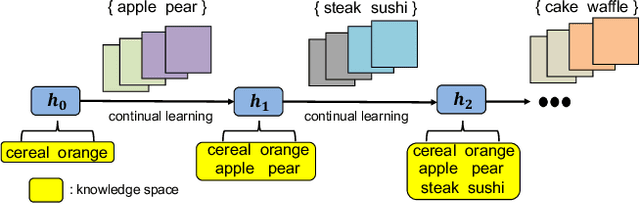
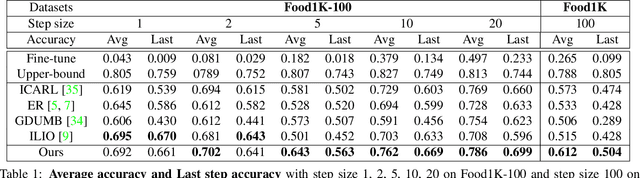
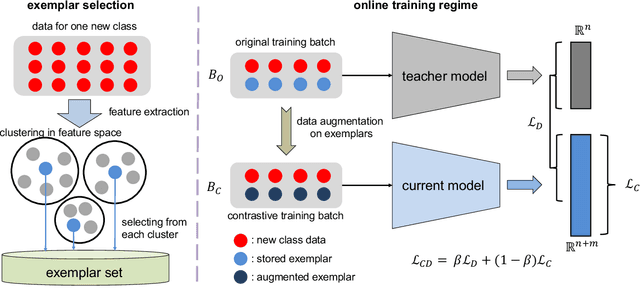
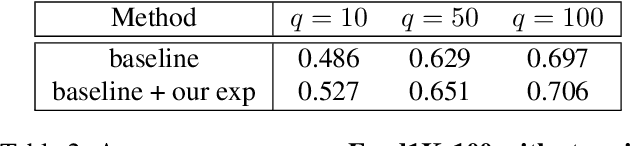
Food image classification is challenging for real-world applications since existing methods require static datasets for training and are not capable of learning from sequentially available new food images. Online continual learning aims to learn new classes from data stream by using each new data only once without forgetting the previously learned knowledge. However, none of the existing works target food image analysis, which is more difficult to learn incrementally due to its high intra-class variation with the unbalanced and unpredictable characteristics of future food class distribution. In this paper, we address these issues by introducing (1) a novel clustering based exemplar selection algorithm to store the most representative data belonging to each learned food for knowledge replay, and (2) an effective online learning regime using balanced training batch along with the knowledge distillation on augmented exemplars to maintain the model performance on all learned classes. Our method is evaluated on a challenging large scale food image database, Food-1K, by varying the number of newly added food classes. Our results show significant improvements compared with existing state-of-the-art online continual learning methods, showing great potential to achieve lifelong learning for food image classification in real world.
What and Where to Translate: Local Mask-based Image-to-Image Translation
Jun 09, 2019
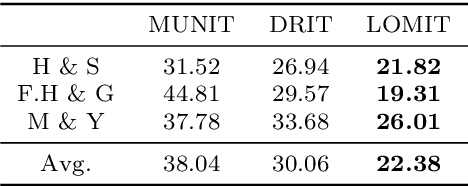

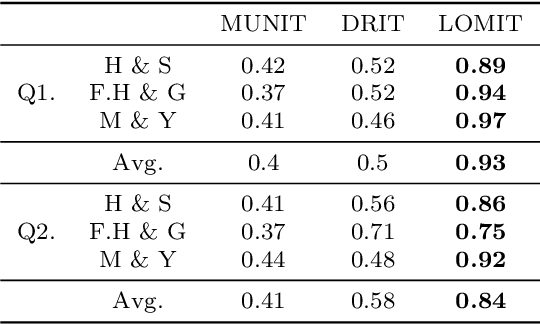
Recently, image-to-image translation has obtained significant attention. Among many, those approaches based on an exemplar image that contains the target style information has been actively studied, due to its capability to handle multimodality as well as its applicability in practical use. However, two intrinsic problems exist in the existing methods: what and where to transfer. First, those methods extract style from an entire exemplar which includes noisy information, which impedes a translation model from properly extracting the intended style of the exemplar. That is, we need to carefully determine what to transfer from the exemplar. Second, the extracted style is applied to the entire input image, which causes unnecessary distortion in irrelevant image regions. In response, we need to decide where to transfer the extracted style. In this paper, we propose a novel approach that extracts out a local mask from the exemplar that determines what style to transfer, and another local mask from the input image that determines where to transfer the extracted style. The main novelty of this paper lies in (1) the highway adaptive instance normalization technique and (2) an end-to-end translation framework which achieves an outstanding performance in reflecting a style of an exemplar. We demonstrate the quantitative and qualitative evaluation results to confirm the advantages of our proposed approach.