 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Evaluating Gradient Inversion Attacks and Defenses in Federated Learning
Nov 30, 2021



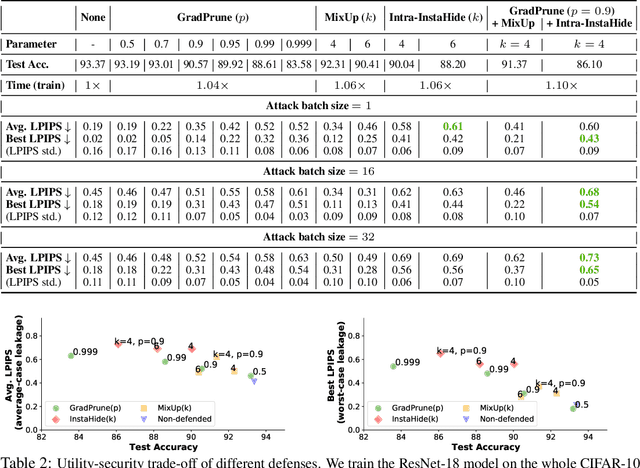
Gradient inversion attack (or input recovery from gradient) is an emerging threat to the security and privacy preservation of Federated learning, whereby malicious eavesdroppers or participants in the protocol can recover (partially) the clients' private data. This paper evaluates existing attacks and defenses. We find that some attacks make strong assumptions about the setup. Relaxing such assumptions can substantially weaken these attacks. We then evaluate the benefits of three proposed defense mechanisms against gradient inversion attacks. We show the trade-offs of privacy leakage and data utility of these defense methods, and find that combining them in an appropriate manner makes the attack less effective, even under the original strong assumptions. We also estimate the computation cost of end-to-end recovery of a single image under each evaluated defense. Our findings suggest that the state-of-the-art attacks can currently be defended against with minor data utility loss, as summarized in a list of potential strategies. Our code is available at: https://github.com/Princeton-SysML/GradAttack.
FastSurferVINN: Building Resolution-Independence into Deep Learning Segmentation Methods -- A Solution for HighRes Brain MRI
Dec 17, 2021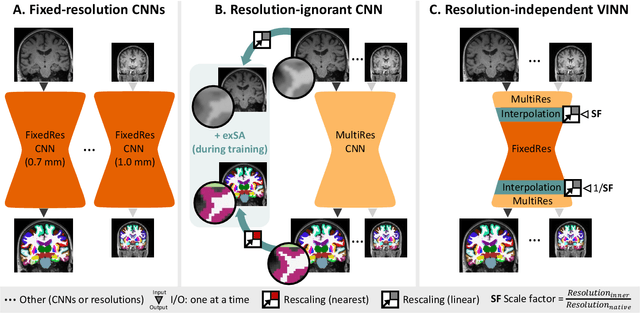

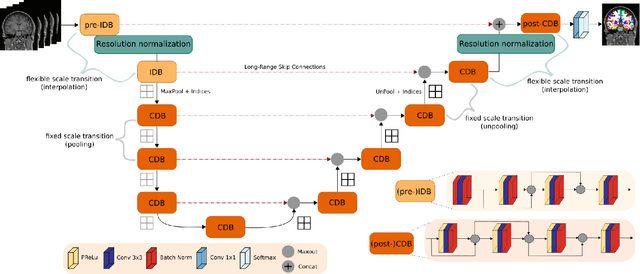
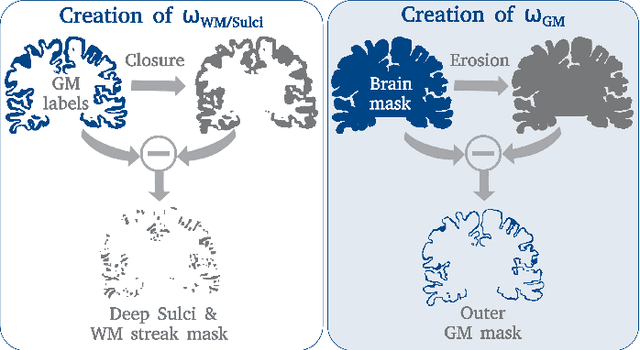
Leading neuroimaging studies have pushed 3T MRI acquisition resolutions below 1.0 mm for improved structure definition and morphometry. Yet, only few, time-intensive automated image analysis pipelines have been validated for high-resolution (HiRes) settings. Efficient deep learning approaches, on the other hand, rarely support more than one fixed resolution (usually 1.0 mm). Furthermore, the lack of a standard submillimeter resolution as well as limited availability of diverse HiRes data with sufficient coverage of scanner, age, diseases, or genetic variance poses additional, unsolved challenges for training HiRes networks. Incorporating resolution-independence into deep learning-based segmentation, i.e., the ability to segment images at their native resolution across a range of different voxel sizes, promises to overcome these challenges, yet no such approach currently exists. We now fill this gap by introducing a Voxelsize Independent Neural Network (VINN) for resolution-independent segmentation tasks and present FastSurferVINN, which (i) establishes and implements resolution-independence for deep learning as the first method simultaneously supporting 0.7-1.0 mm whole brain segmentation, (ii) significantly outperforms state-of-the-art methods across resolutions, and (iii) mitigates the data imbalance problem present in HiRes datasets. Overall, internal resolution-independence mutually benefits both HiRes and 1.0 mm MRI segmentation. With our rigorously validated FastSurferVINN we distribute a rapid tool for morphometric neuroimage analysis. The VINN architecture, furthermore, represents an efficient resolution-independent segmentation method for wider application
Information-theoretic stochastic contrastive conditional GAN: InfoSCC-GAN
Dec 17, 2021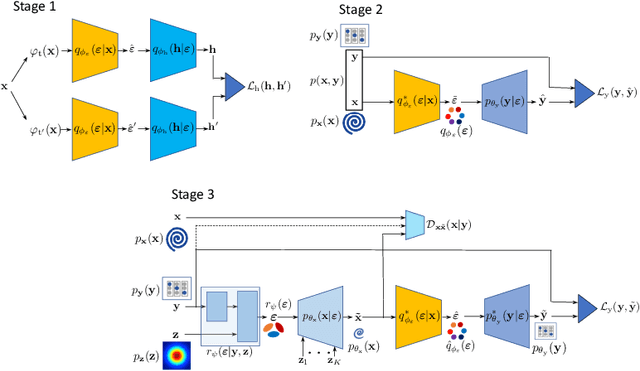
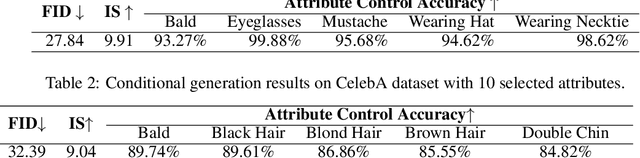
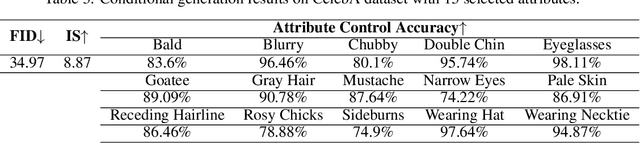
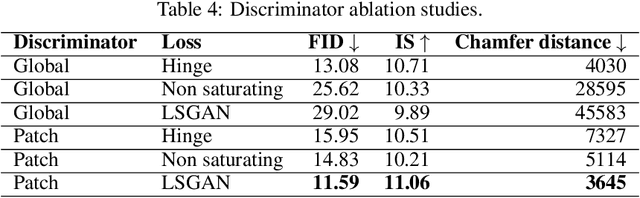
Conditional generation is a subclass of generative problems where the output of the generation is conditioned by the attribute information. In this paper, we present a stochastic contrastive conditional generative adversarial network (InfoSCC-GAN) with an explorable latent space. The InfoSCC-GAN architecture is based on an unsupervised contrastive encoder built on the InfoNCE paradigm, an attribute classifier and an EigenGAN generator. We propose a novel training method, based on generator regularization using external or internal attributes every $n$-th iteration, using a pre-trained contrastive encoder and a pre-trained classifier. The proposed InfoSCC-GAN is derived based on an information-theoretic formulation of mutual information maximization between input data and latent space representation as well as latent space and generated data. Thus, we demonstrate a link between the training objective functions and the above information-theoretic formulation. The experimental results show that InfoSCC-GAN outperforms the "vanilla" EigenGAN in the image generation on AFHQ and CelebA datasets. In addition, we investigate the impact of discriminator architectures and loss functions by performing ablation studies. Finally, we demonstrate that thanks to the EigenGAN generator, the proposed framework enjoys a stochastic generation in contrast to vanilla deterministic GANs yet with the independent training of encoder, classifier, and generator in contrast to existing frameworks. Code, experimental results, and demos are available online at https://github.com/vkinakh/InfoSCC-GAN.
360MonoDepth: High-Resolution 360° Monocular Depth Estimation
Nov 30, 2021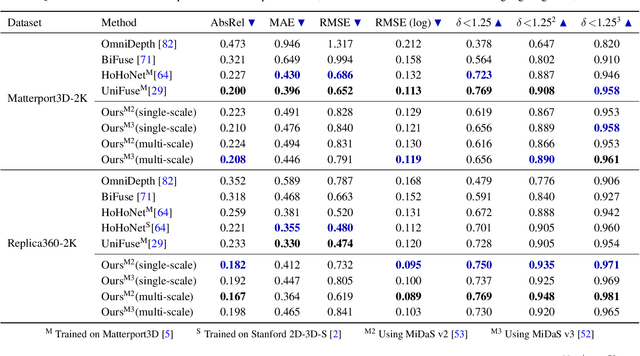

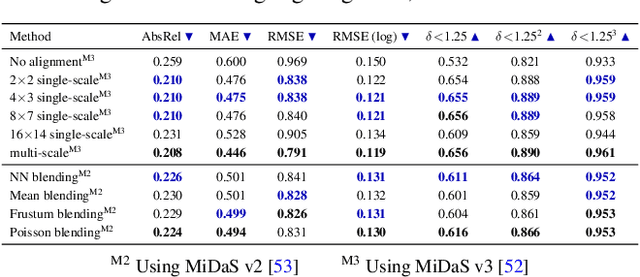
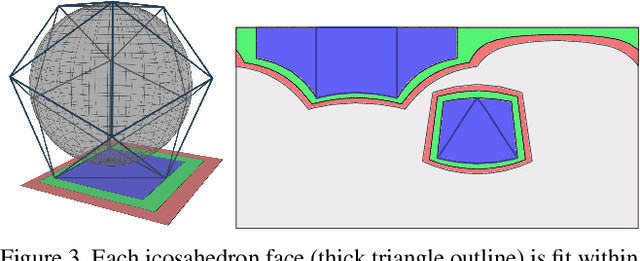
360{\deg} cameras can capture complete environments in a single shot, which makes 360{\deg} imagery alluring in many computer vision tasks. However, monocular depth estimation remains a challenge for 360{\deg} data, particularly for high resolutions like 2K (2048$\times$1024) that are important for novel-view synthesis and virtual reality applications. Current CNN-based methods do not support such high resolutions due to limited GPU memory. In this work, we propose a flexible framework for monocular depth estimation from high-resolution 360{\deg} images using tangent images. We project the 360{\deg} input image onto a set of tangent planes that produce perspective views, which are suitable for the latest, most accurate state-of-the-art perspective monocular depth estimators. We recombine the individual depth estimates using deformable multi-scale alignment followed by gradient-domain blending to improve the consistency of disparity estimates. The result is a dense, high-resolution 360{\deg} depth map with a high level of detail, also for outdoor scenes which are not supported by existing methods.
Predicting Poverty Level from Satellite Imagery using Deep Neural Networks
Nov 30, 2021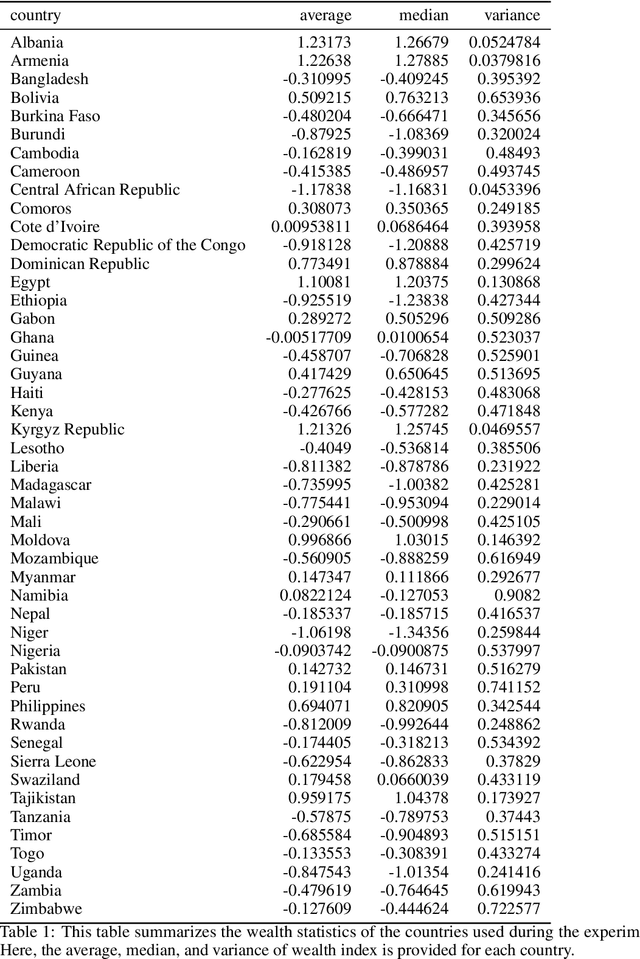
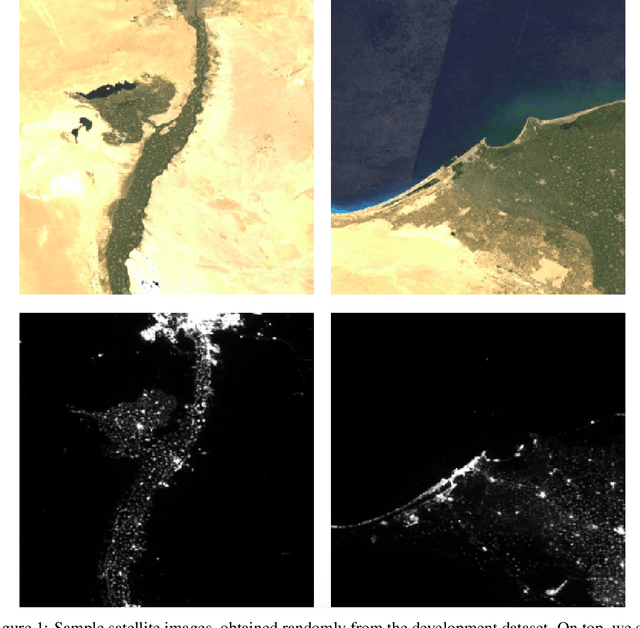
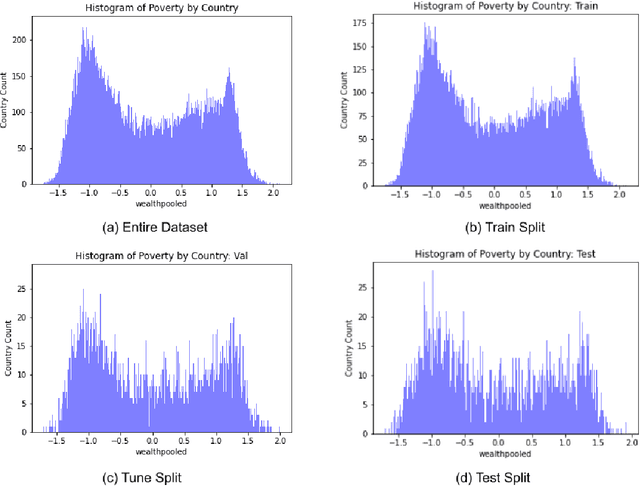
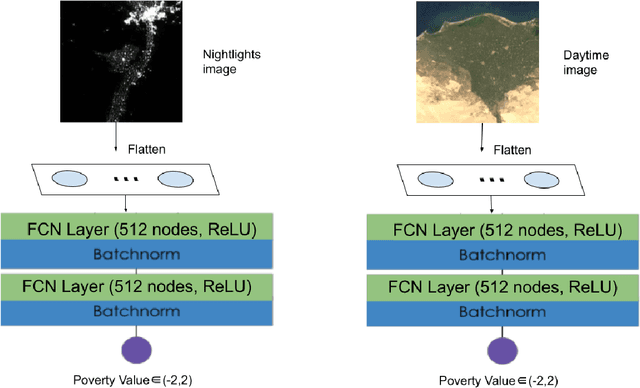
Determining the poverty levels of various regions throughout the world is crucial in identifying interventions for poverty reduction initiatives and directing resources fairly. However, reliable data on global economic livelihoods is hard to come by, especially for areas in the developing world, hampering efforts to both deploy services and monitor/evaluate progress. This is largely due to the fact that this data is obtained from traditional door-to-door surveys, which are time consuming and expensive. Overhead satellite imagery contain characteristics that make it possible to estimate the region's poverty level. In this work, I develop deep learning computer vision methods that can predict a region's poverty level from an overhead satellite image. I experiment with both daytime and nighttime imagery. Furthermore, because data limitations are often the barrier to entry in poverty prediction from satellite imagery, I explore the impact that data quantity and data augmentation have on the representational power and overall accuracy of the networks. Lastly, to evaluate the robustness of the networks, I evaluate them on data from continents that were absent in the development set.
Donut: Document Understanding Transformer without OCR
Nov 30, 2021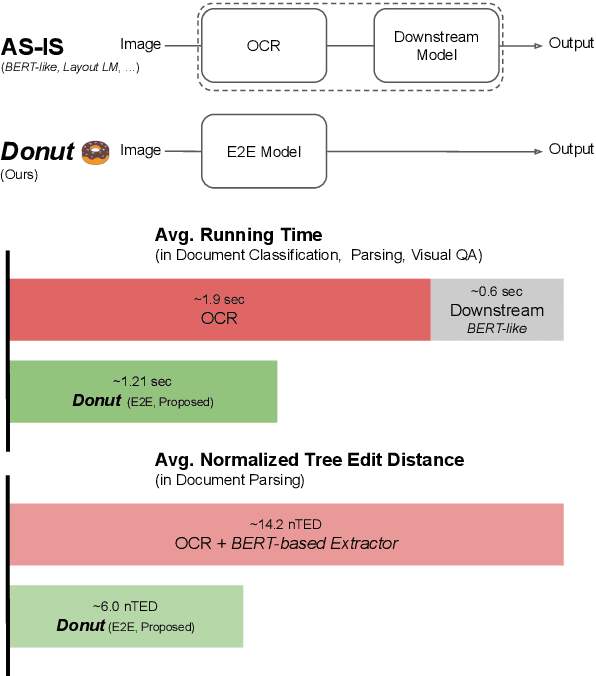
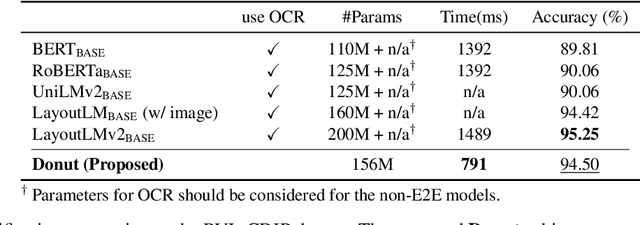
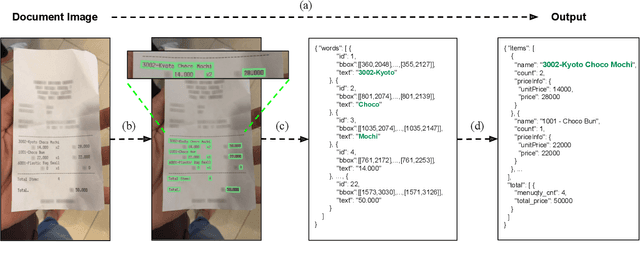

Understanding document images (e.g., invoices) has been an important research topic and has many applications in document processing automation. Through the latest advances in deep learning-based Optical Character Recognition (OCR), current Visual Document Understanding (VDU) systems have come to be designed based on OCR. Although such OCR-based approach promise reasonable performance, they suffer from critical problems induced by the OCR, e.g., (1) expensive computational costs and (2) performance degradation due to the OCR error propagation. In this paper, we propose a novel VDU model that is end-to-end trainable without underpinning OCR framework. To this end, we propose a new task and a synthetic document image generator to pre-train the model to mitigate the dependencies on large-scale real document images. Our approach achieves state-of-the-art performance on various document understanding tasks in public benchmark datasets and private industrial service datasets. Through extensive experiments and analysis, we demonstrate the effectiveness of the proposed model especially with consideration for a real-world application.
Audio Deepfake Perceptions in College Going Populations
Dec 06, 2021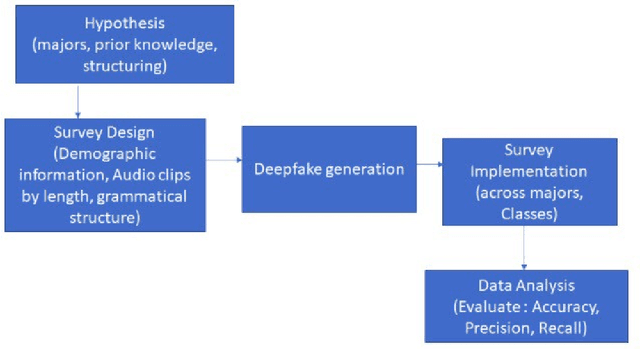
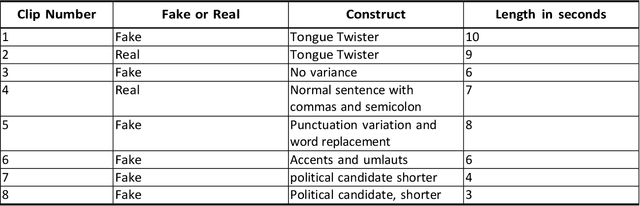

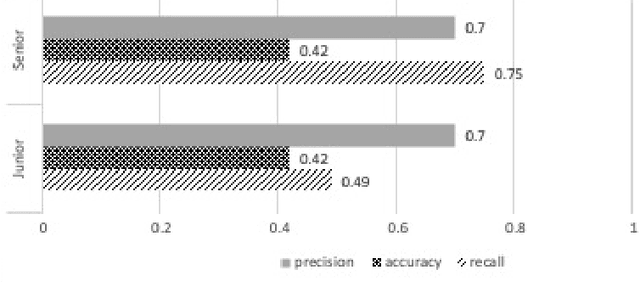
Deepfake is content or material that is generated or manipulated using AI methods, to pass off as real. There are four different deepfake types: audio, video, image and text. In this research we focus on audio deepfakes and how people perceive it. There are several audio deepfake generation frameworks, but we chose MelGAN which is a non-autoregressive and fast audio deepfake generating framework, requiring fewer parameters. This study tries to assess audio deepfake perceptions among college students from different majors. This study also answers the question of how their background and major can affect their perception towards AI generated deepfakes. We also analyzed the results based on different aspects of: grade level, complexity of the grammar used in the audio clips, length of the audio clips, those who knew the term deepfakes and those who did not, as well as the political angle. It is interesting that the results show when an audio clip has a political connotation, it can affect what people think about whether it is real or fake, even if the content is fairly similar. This study also explores the question of how background and major can affect perception towards deepfakes.
Measuring Complexity of Learning Schemes Using Hessian-Schatten Total-Variation
Dec 12, 2021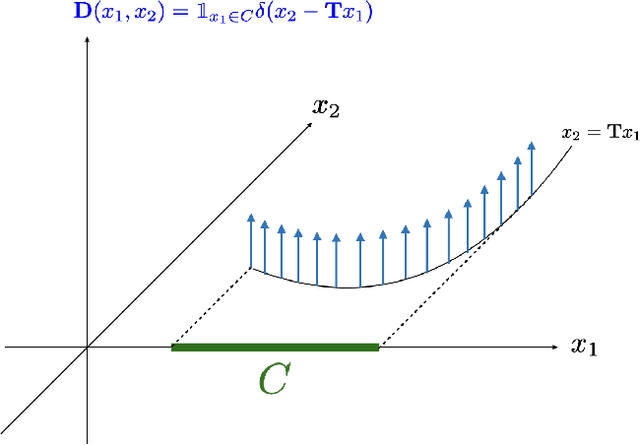
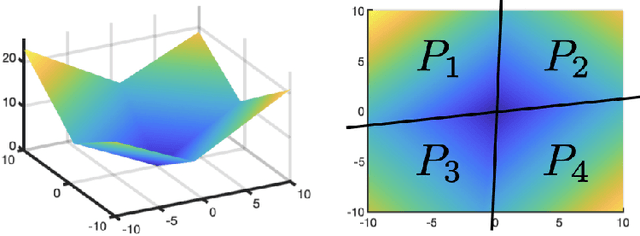
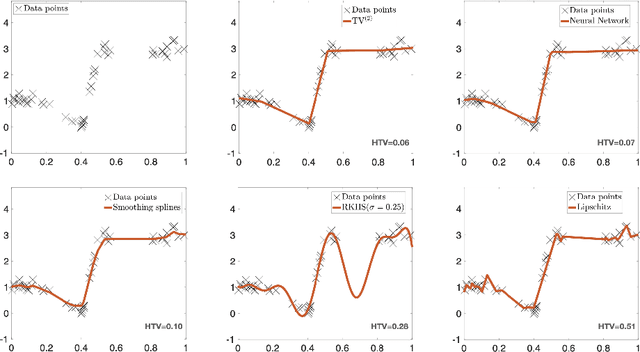

In this paper, we introduce the Hessian-Schatten total-variation (HTV) -- a novel seminorm that quantifies the total "rugosity" of multivariate functions. Our motivation for defining HTV is to assess the complexity of supervised learning schemes. We start by specifying the adequate matrix-valued Banach spaces that are equipped with suitable classes of mixed-norms. We then show that HTV is invariant to rotations, scalings, and translations. Additionally, its minimum value is achieved for linear mappings, supporting the common intuition that linear regression is the least complex learning model. Next, we present closed-form expressions for computing the HTV of two general classes of functions. The first one is the class of Sobolev functions with a certain degree of regularity, for which we show that HTV coincides with the Hessian-Schatten seminorm that is sometimes used as a regularizer for image reconstruction. The second one is the class of continuous and piecewise linear (CPWL) functions. In this case, we show that the HTV reflects the total change in slopes between linear regions that have a common facet. Hence, it can be viewed as a convex relaxation (l1-type) of the number of linear regions (l0-type) of CPWL mappings. Finally, we illustrate the use of our proposed seminorm with some concrete examples.
AudioCLIP: Extending CLIP to Image, Text and Audio
Jun 24, 2021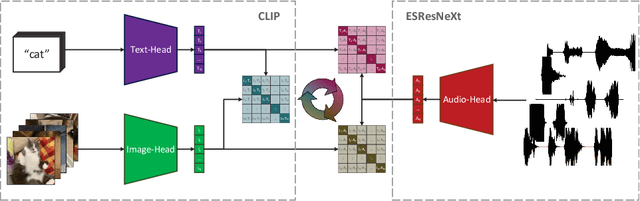

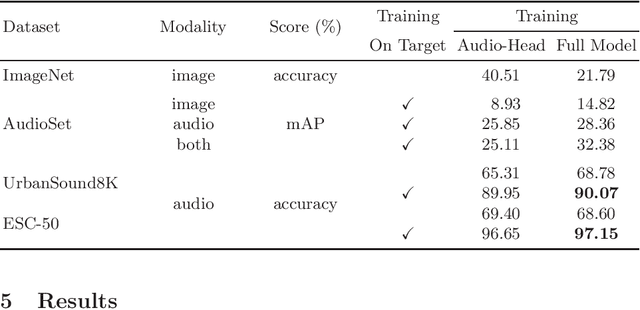
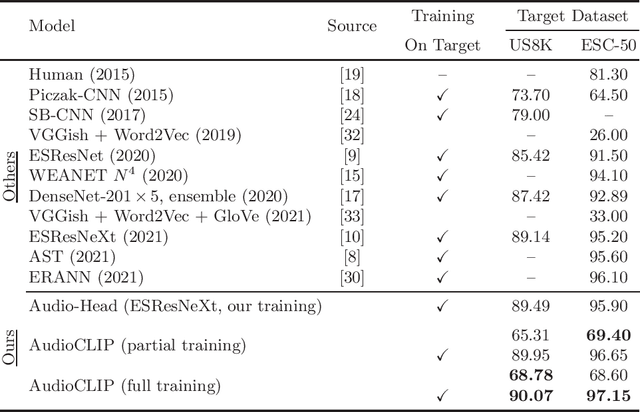
In the past, the rapidly evolving field of sound classification greatly benefited from the application of methods from other domains. Today, we observe the trend to fuse domain-specific tasks and approaches together, which provides the community with new outstanding models. In this work, we present an extension of the CLIP model that handles audio in addition to text and images. Our proposed model incorporates the ESResNeXt audio-model into the CLIP framework using the AudioSet dataset. Such a combination enables the proposed model to perform bimodal and unimodal classification and querying, while keeping CLIP's ability to generalize to unseen datasets in a zero-shot inference fashion. AudioCLIP achieves new state-of-the-art results in the Environmental Sound Classification (ESC) task, out-performing other approaches by reaching accuracies of 90.07% on the UrbanSound8K and 97.15% on the ESC-50 datasets. Further it sets new baselines in the zero-shot ESC-task on the same datasets 68.78% and 69.40%, respectively). Finally, we also assess the cross-modal querying performance of the proposed model as well as the influence of full and partial training on the results. For the sake of reproducibility, our code is published.
Transform Network Architectures for Deep Learning based End-to-End Image/Video Coding in Subsampled Color Spaces
Feb 27, 2021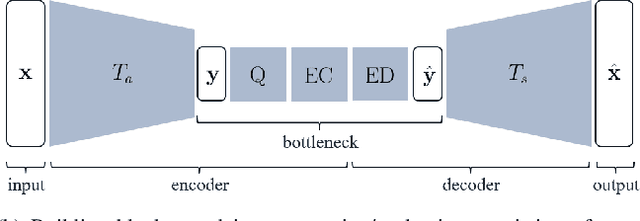
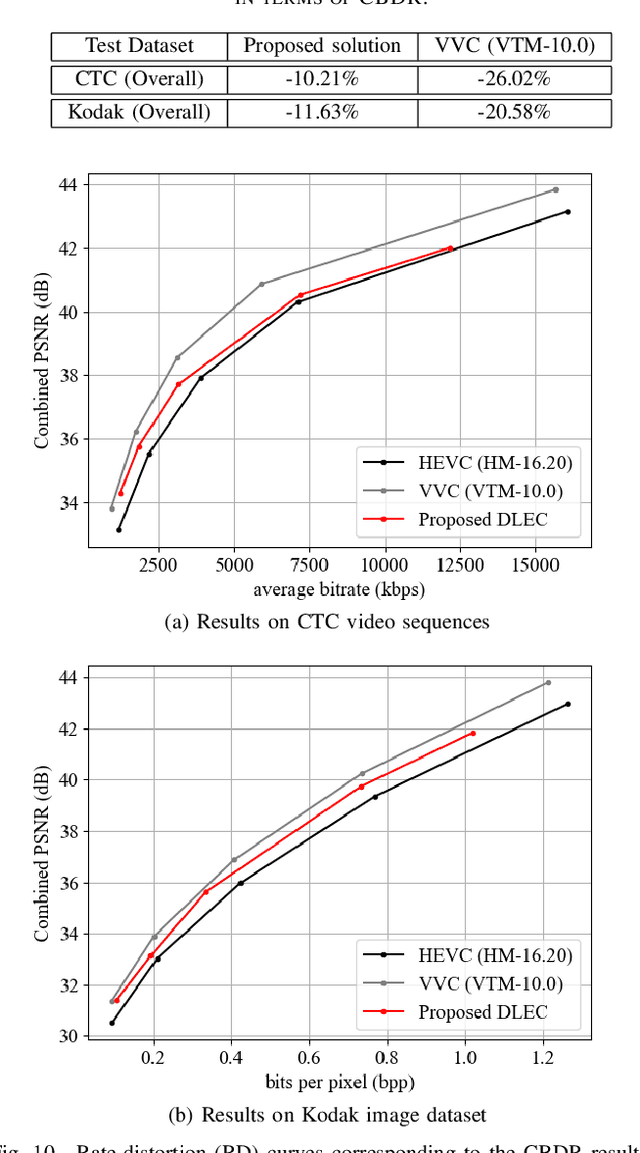
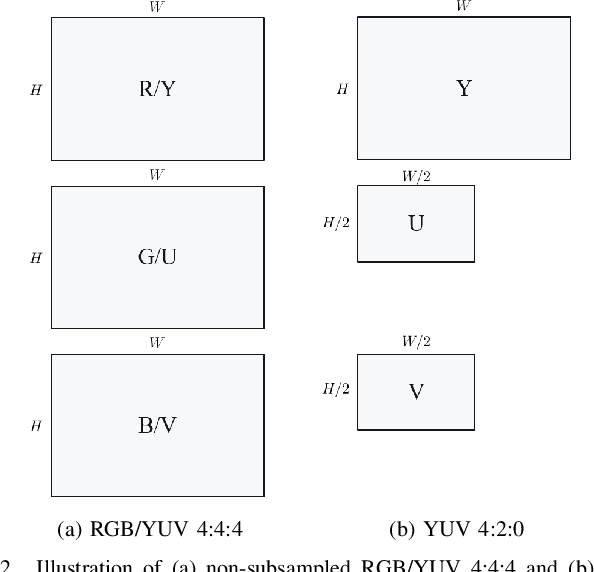

Most of the existing deep learning based end-to-end image/video coding (DLEC) architectures are designed for non-subsampled RGB color format. However, in order to achieve a superior coding performance, many state-of-the-art block-based compression standards such as High Efficiency Video Coding (HEVC/H.265) and Versatile Video Coding (VVC/H.266) are designed primarily for YUV 4:2:0 format, where U and V components are subsampled by considering the human visual system. This paper investigates various DLEC designs to support YUV 4:2:0 format by comparing their performance against the main profiles of HEVC and VVC standards under a common evaluation framework. Moreover, a new transform network architecture is proposed to improve the efficiency of coding YUV 4:2:0 data. The experimental results on YUV 4:2:0 datasets show that the proposed architecture significantly outperforms naive extensions of existing architectures designed for RGB format and achieves about 10% average BD-rate improvement over the intra-frame coding in HEVC.