 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the Impact of Lossy Image and Video Compression on the Performance of Deep Convolutional Neural Network Architectures
Jul 28, 2020




Recent advances in generalized image understanding have seen a surge in the use of deep convolutional neural networks (CNN) across a broad range of image-based detection, classification and prediction tasks. Whilst the reported performance of these approaches is impressive, this study investigates the hitherto unapproached question of the impact of commonplace image and video compression techniques on the performance of such deep learning architectures. Focusing on the JPEG and H.264 (MPEG-4 AVC) as a representative proxy for contemporary lossy image/video compression techniques that are in common use within network-connected image/video devices and infrastructure, we examine the impact on performance across five discrete tasks: human pose estimation, semantic segmentation, object detection, action recognition, and monocular depth estimation. As such, within this study we include a variety of network architectures and domains spanning end-to-end convolution, encoder-decoder, region-based CNN (R-CNN), dual-stream, and generative adversarial networks (GAN). Our results show a non-linear and non-uniform relationship between network performance and the level of lossy compression applied. Notably, performance decreases significantly below a JPEG quality (quantization) level of 15% and a H.264 Constant Rate Factor (CRF) of 40. However, retraining said architectures on pre-compressed imagery conversely recovers network performance by up to 78.4% in some cases. Furthermore, there is a correlation between architectures employing an encoder-decoder pipeline and those that demonstrate resilience to lossy image compression. The characteristics of the relationship between input compression to output task performance can be used to inform design decisions within future image/video devices and infrastructure.
Fully Adaptive Bayesian Algorithm for Data Analysis, FABADA
Jan 13, 2022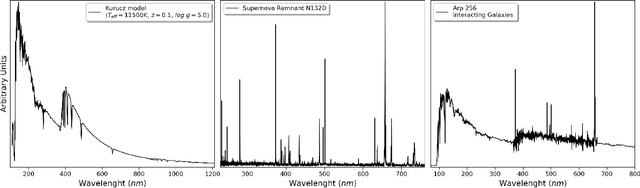

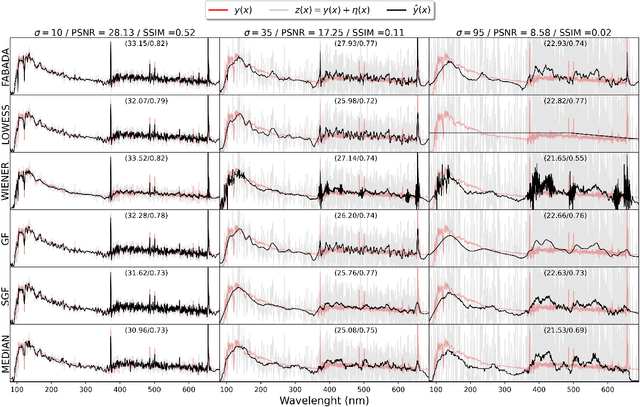
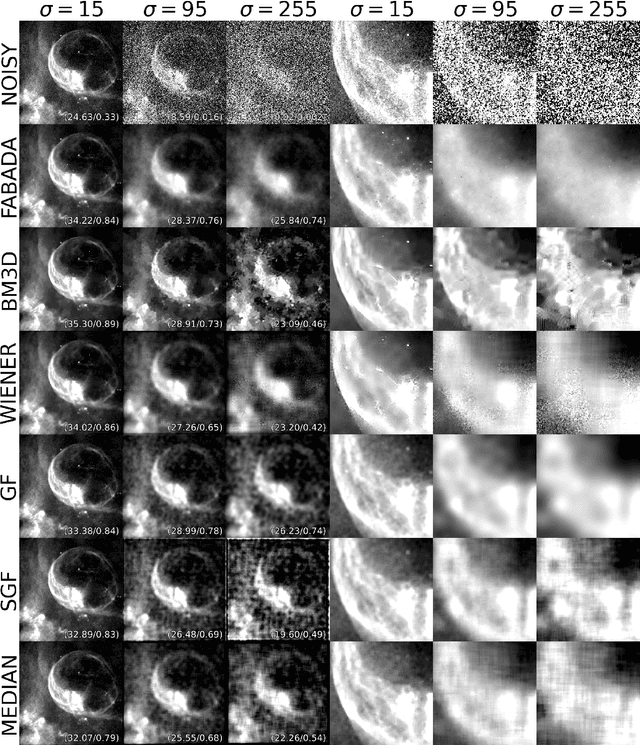
The aim of this paper is to describe a novel non-parametric noise reduction technique from the point of view of Bayesian inference that may automatically improve the signal-to-noise ratio of one- and two-dimensional data, such as e.g. astronomical images and spectra. The algorithm iteratively evaluates possible smoothed versions of the data, the smooth models, obtaining an estimation of the underlying signal that is statistically compatible with the noisy measurements. Iterations stop based on the evidence and the $\chi^2$ statistic of the last smooth model, and we compute the expected value of the signal as a weighted average of the whole set of smooth models. In this paper, we explain the mathematical formalism and numerical implementation of the algorithm, and we evaluate its performance in terms of the peak signal to noise ratio, the structural similarity index, and the time payload, using a battery of real astronomical observations. Our Fully Adaptive Bayesian Algorithm for Data Analysis (FABADA) yields results that, without any parameter tuning, are comparable to standard image processing algorithms whose parameters have been optimized based on the true signal to be recovered, something that is impossible in a real application. State-of-the-art non-parametric methods, such as BM3D, offer slightly better performance at high signal-to-noise ratio, while our algorithm is significantly more accurate for extremely noisy data (higher than $20-40\%$ relative errors, a situation of particular interest in the field of astronomy). In this range, the standard deviation of the residuals obtained by our reconstruction may become more than an order of magnitude lower than that of the original measurements. The source code needed to reproduce all the results presented in this report, including the implementation of the method, is publicly available at https://github.com/PabloMSanAla/fabada
On Asymptotic Linear Convergence of Projected Gradient Descent for Constrained Least Squares
Dec 22, 2021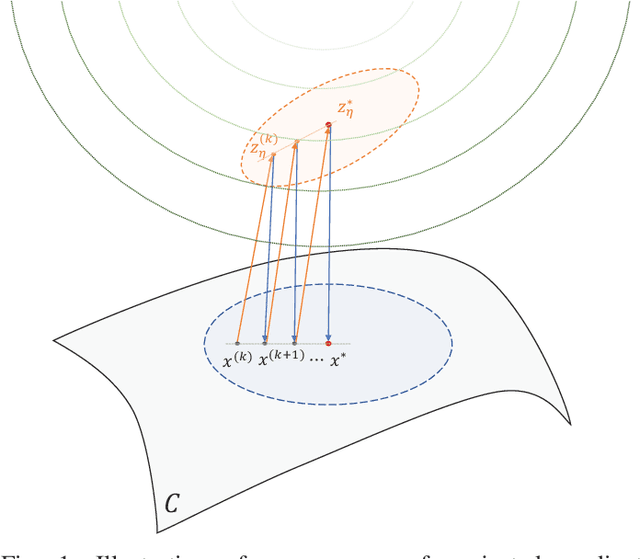
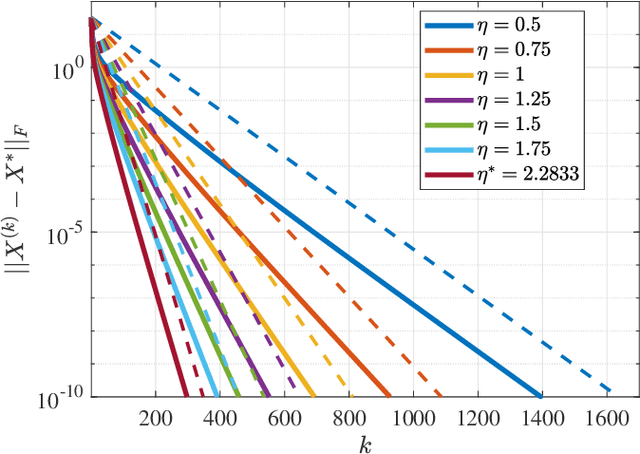


Many recent problems in signal processing and machine learning such as compressed sensing, image restoration, matrix/tensor recovery, and non-negative matrix factorization can be cast as constrained optimization. Projected gradient descent is a simple yet efficient method for solving such constrained optimization problems. Local convergence analysis furthers our understanding of its asymptotic behavior near the solution, offering sharper bounds on the convergence rate compared to global convergence analysis. However, local guarantees often appear scattered in problem-specific areas of machine learning and signal processing. This manuscript presents a unified framework for the local convergence analysis of projected gradient descent in the context of constrained least squares. The proposed analysis offers insights into pivotal local convergence properties such as the condition of linear convergence, the region of convergence, the exact asymptotic rate of convergence, and the bound on the number of iterations needed to reach a certain level of accuracy. To demonstrate the applicability of the proposed approach, we present a recipe for the convergence analysis of PGD and demonstrate it via a beginning-to-end application of the recipe on four fundamental problems, namely, linearly constrained least squares, sparse recovery, least squares with the unit norm constraint, and matrix completion.
SPIN Road Mapper: Extracting Roads from Aerial Images via Spatial and Interaction Space Graph Reasoning for Autonomous Driving
Sep 16, 2021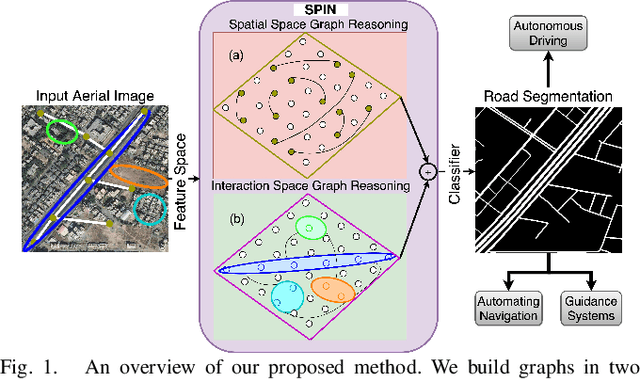
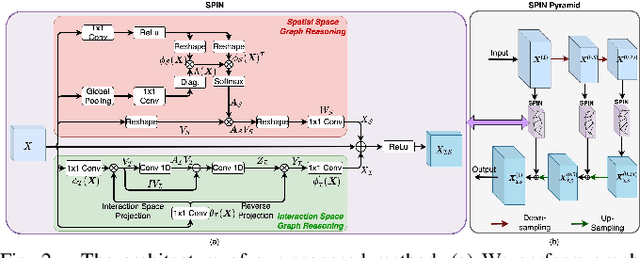
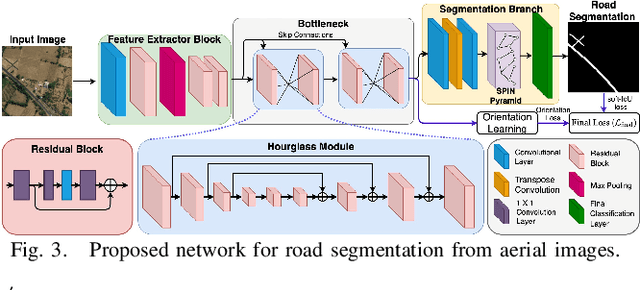

Road extraction is an essential step in building autonomous navigation systems. Detecting road segments is challenging as they are of varying widths, bifurcated throughout the image, and are often occluded by terrain, cloud, or other weather conditions. Using just convolution neural networks (ConvNets) for this problem is not effective as it is inefficient at capturing distant dependencies between road segments in the image which is essential to extract road connectivity. To this end, we propose a Spatial and Interaction Space Graph Reasoning (SPIN) module which when plugged into a ConvNet performs reasoning over graphs constructed on spatial and interaction spaces projected from the feature maps. Reasoning over spatial space extracts dependencies between different spatial regions and other contextual information. Reasoning over a projected interaction space helps in appropriate delineation of roads from other topographies present in the image. Thus, SPIN extracts long-range dependencies between road segments and effectively delineates roads from other semantics. We also introduce a SPIN pyramid which performs SPIN graph reasoning across multiple scales to extract multi-scale features. We propose a network based on stacked hourglass modules and SPIN pyramid for road segmentation which achieves better performance compared to existing methods. Moreover, our method is computationally efficient and significantly boosts the convergence speed during training, making it feasible for applying on large-scale high-resolution aerial images. Code available at: https://github.com/wgcban/SPIN_RoadMapper.git.
* Code available at: https://github.com/wgcban/SPIN_RoadMapper.git
Confidence Measure Guided Single Image De-raining
Sep 10, 2019


Single image de-raining is an extremely challenging problem since the rainy images contain rain streaks which often vary in size, direction and density. This varying characteristic of rain streaks affect different parts of the image differently. Previous approaches have attempted to address this problem by leveraging some prior information to remove rain streaks from a single image. One of the major limitations of these approaches is that they do not consider the location information of rain drops in the image. The proposed Image Quality-based single image Deraining using Confidence measure (QuDeC), network addresses this issue by learning the quality or distortion level of each patch in the rainy image, and further processes this information to learn the rain content at different scales. In addition, we introduce a technique which guides the network to learn the network weights based on the confidence measure about the estimate of both quality at each location and residual rain streak information (residual map). Extensive experiments on synthetic and real datasets demonstrate that the proposed method achieves significant improvements over the recent state-of-the-art methods.
Who calls the shots? Rethinking Few-Shot Learning for Audio
Oct 18, 2021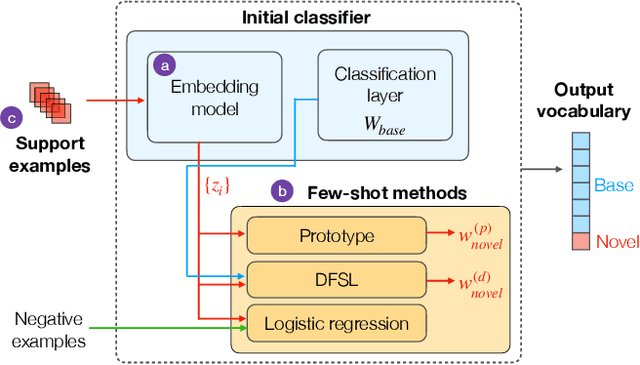
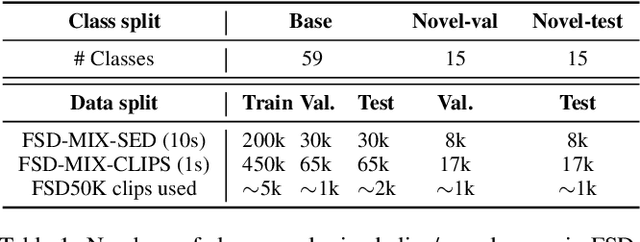
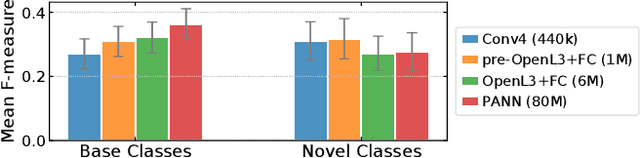
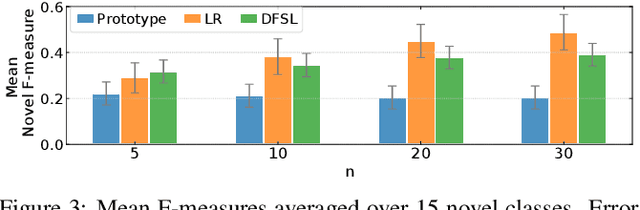
Few-shot learning aims to train models that can recognize novel classes given just a handful of labeled examples, known as the support set. While the field has seen notable advances in recent years, they have often focused on multi-class image classification. Audio, in contrast, is often multi-label due to overlapping sounds, resulting in unique properties such as polyphony and signal-to-noise ratios (SNR). This leads to unanswered questions concerning the impact such audio properties may have on few-shot learning system design, performance, and human-computer interaction, as it is typically up to the user to collect and provide inference-time support set examples. We address these questions through a series of experiments designed to elucidate the answers to these questions. We introduce two novel datasets, FSD-MIX-CLIPS and FSD-MIX-SED, whose programmatic generation allows us to explore these questions systematically. Our experiments lead to audio-specific insights on few-shot learning, some of which are at odds with recent findings in the image domain: there is no best one-size-fits-all model, method, and support set selection criterion. Rather, it depends on the expected application scenario. Our code and data are available at https://github.com/wangyu/rethink-audio-fsl.
$μ$NCA: Texture Generation with Ultra-Compact Neural Cellular Automata
Nov 26, 2021

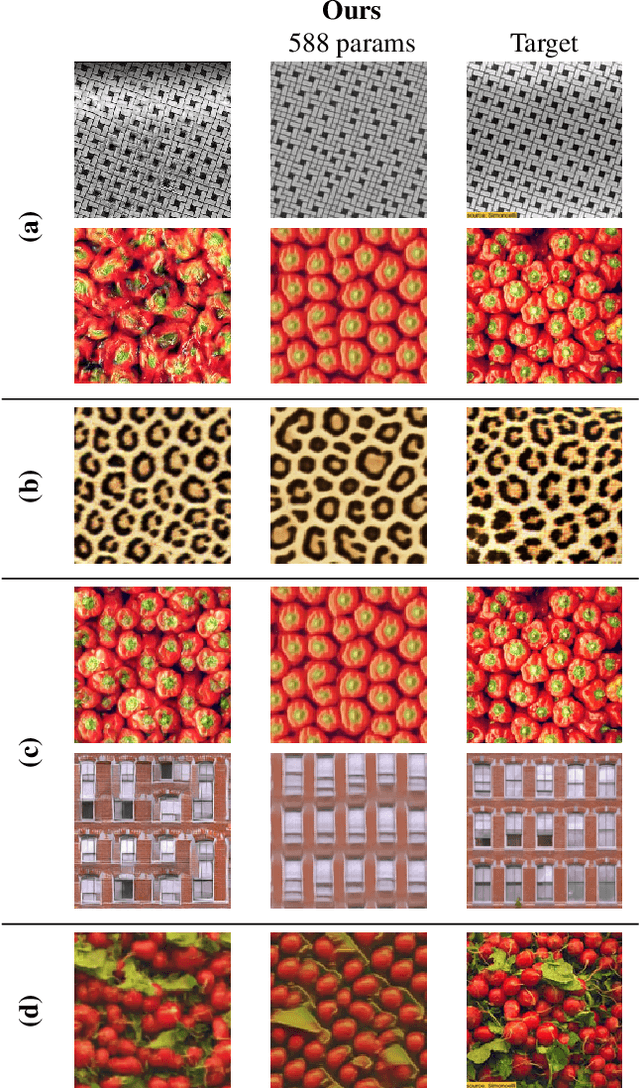
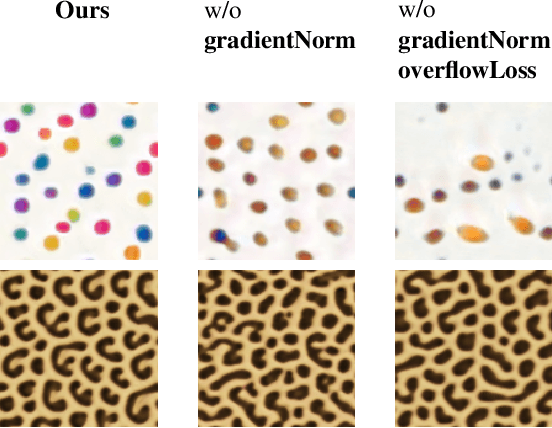
We study the problem of example-based procedural texture synthesis using highly compact models. Given a sample image, we use differentiable programming to train a generative process, parameterised by a recurrent Neural Cellular Automata (NCA) rule. Contrary to the common belief that neural networks should be significantly over-parameterised, we demonstrate that our model architecture and training procedure allows for representing complex texture patterns using just a few hundred learned parameters, making their expressivity comparable to hand-engineered procedural texture generating programs. The smallest models from the proposed $\mu$NCA family scale down to 68 parameters. When using quantisation to one byte per parameter, proposed models can be shrunk to a size range between 588 and 68 bytes. Implementation of a texture generator that uses these parameters to produce images is possible with just a few lines of GLSL or C code.
TraVeLGAN: Image-to-image Translation by Transformation Vector Learning
Feb 25, 2019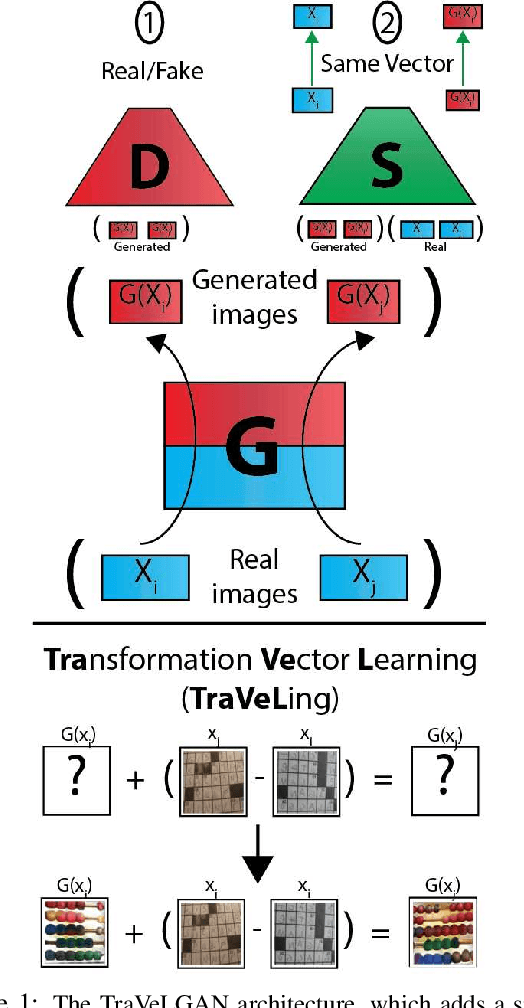
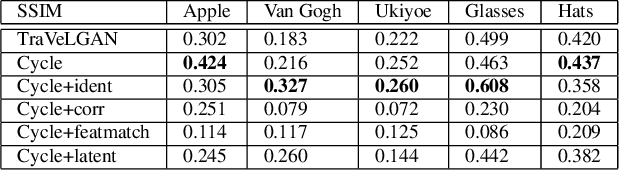

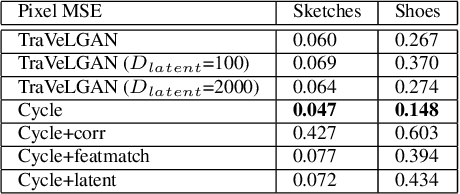
Interest in image-to-image translation has grown substantially in recent years with the success of unsupervised models based on the cycle-consistency assumption. The achievements of these models have been limited to a particular subset of domains where this assumption yields good results, namely homogeneous domains that are characterized by style or texture differences. We tackle the challenging problem of image-to-image translation where the domains are defined by high-level shapes and contexts, as well as including significant clutter and heterogeneity. For this purpose, we introduce a novel GAN based on preserving intra-domain vector transformations in a latent space learned by a siamese network. The traditional GAN system introduced a discriminator network to guide the generator into generating images in the target domain. To this two-network system we add a third: a siamese network that guides the generator so that each original image shares semantics with its generated version. With this new three-network system, we no longer need to constrain the generators with the ubiquitous cycle-consistency restraint. As a result, the generators can learn mappings between more complex domains that differ from each other by large differences - not just style or texture.
What and Where to Translate: Local Mask-based Image-to-Image Translation
Jun 09, 2019
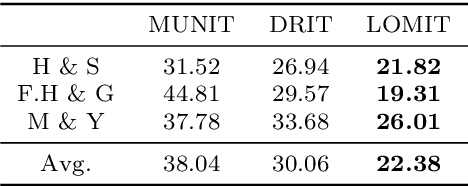

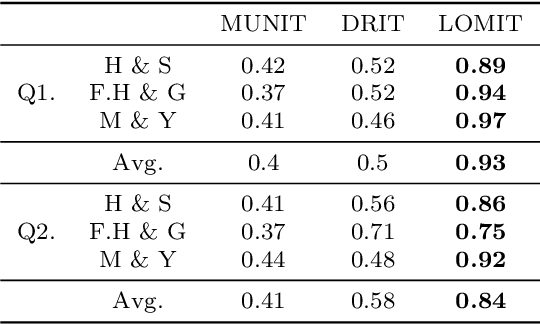
Recently, image-to-image translation has obtained significant attention. Among many, those approaches based on an exemplar image that contains the target style information has been actively studied, due to its capability to handle multimodality as well as its applicability in practical use. However, two intrinsic problems exist in the existing methods: what and where to transfer. First, those methods extract style from an entire exemplar which includes noisy information, which impedes a translation model from properly extracting the intended style of the exemplar. That is, we need to carefully determine what to transfer from the exemplar. Second, the extracted style is applied to the entire input image, which causes unnecessary distortion in irrelevant image regions. In response, we need to decide where to transfer the extracted style. In this paper, we propose a novel approach that extracts out a local mask from the exemplar that determines what style to transfer, and another local mask from the input image that determines where to transfer the extracted style. The main novelty of this paper lies in (1) the highway adaptive instance normalization technique and (2) an end-to-end translation framework which achieves an outstanding performance in reflecting a style of an exemplar. We demonstrate the quantitative and qualitative evaluation results to confirm the advantages of our proposed approach.
Classification of diffraction patterns using a convolutional neural network in single particle imaging experiments performed at X-ray free-electron lasers
Dec 16, 2021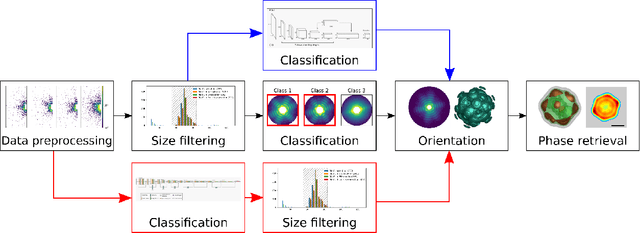
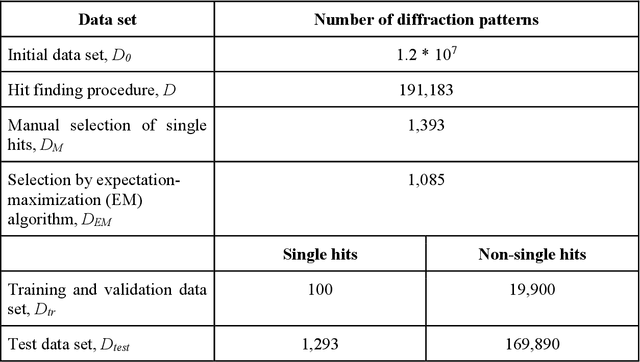
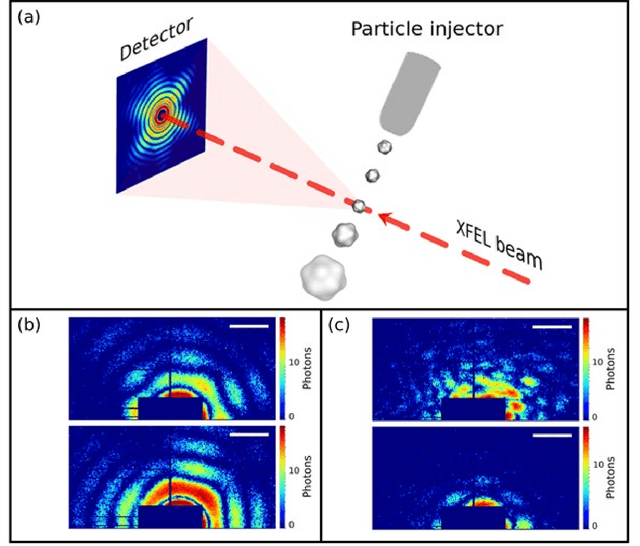
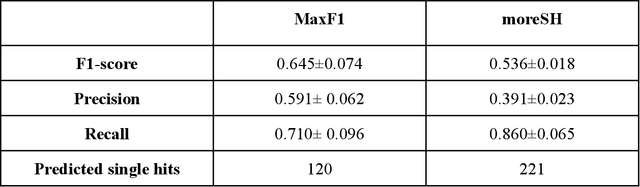
Single particle imaging (SPI) at X-ray free electron lasers (XFELs) is particularly well suited to determine the 3D structure of particles in their native environment. For a successful reconstruction, diffraction patterns originating from a single hit must be isolated from a large number of acquired patterns. We propose to formulate this task as an image classification problem and solve it using convolutional neural network (CNN) architectures. Two CNN configurations are developed: one that maximises the F1-score and one that emphasises high recall. We also combine the CNNs with expectation maximization (EM) selection as well as size filtering. We observed that our CNN selections have lower contrast in power spectral density functions relative to the EM selection, used in our previous work. However, the reconstruction of our CNN-based selections gives similar results. Introducing CNNs into SPI experiments allows streamlining the reconstruction pipeline, enables researchers to classify patterns on the fly, and, as a consequence, enables them to tightly control the duration of their experiments. We think that bringing non-standard artificial intelligence (AI) based solutions in a well-described SPI analysis workflow may be beneficial for the future development of the SPI experiments.