 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Domain Generalization via Progressive Layer-wise and Channel-wise Dropout
Dec 07, 2021
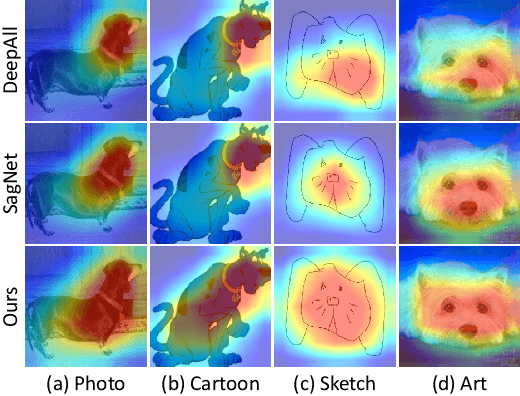
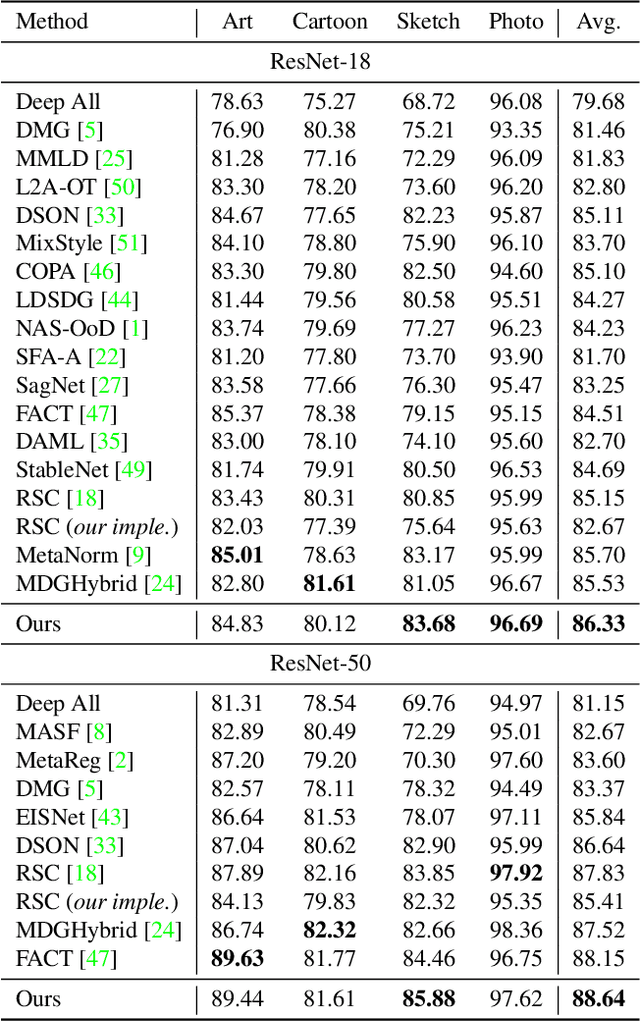
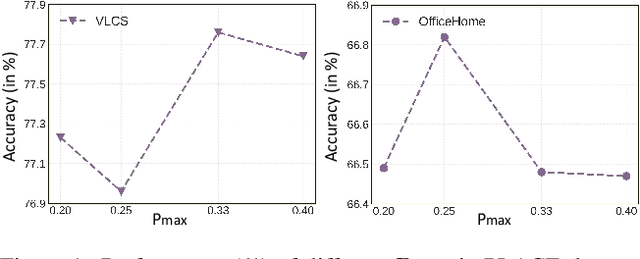
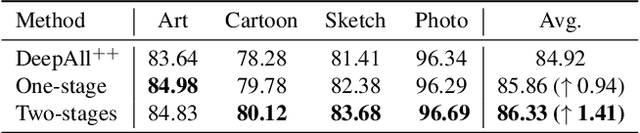
By training a model on multiple observed source domains, domain generalization aims to generalize well to arbitrary unseen target domains without further training. Existing works mainly focus on learning domain-invariant features to improve the generalization ability. However, since target domain is not available during training, previous methods inevitably suffer from overfitting in source domains. To tackle this issue, we develop an effective dropout-based framework to enlarge the region of the model's attention, which can effectively mitigate the overfitting problem. Particularly, different from the typical dropout scheme, which normally conducts the dropout on the fixed layer, first, we randomly select one layer, and then we randomly select its channels to conduct dropout. Besides, we leverage the progressive scheme to add the ratio of the dropout during training, which can gradually boost the difficulty of training model to enhance the robustness of the model. Moreover, to further alleviate the impact of the overfitting issue, we leverage the augmentation schemes on image-level and feature-level to yield a strong baseline model. We conduct extensive experiments on multiple benchmark datasets, which show our method can outperform the state-of-the-art methods.
Learning Generalizable Vision-Tactile Robotic Grasping Strategy for Deformable Objects via Transformer
Dec 13, 2021

Reliable robotic grasping, especially with deformable objects, (e.g. fruit), remains a challenging task due to underactuated contact interactions with a gripper, unknown object dynamics, and variable object geometries. In this study, we propose a Transformer-based robotic grasping framework for rigid grippers that leverage tactile and visual information for safe object grasping. Specifically, the Transformer models learn physical feature embeddings with sensor feedback through performing two pre-defined explorative actions (pinching and sliding) and predict a final grasping outcome through a multilayer perceptron (MLP) with a given grasping strength. Using these predictions, the gripper is commanded with a safe grasping strength for the grasping tasks via inference. Compared with convolutional recurrent networks, the Transformer models can capture the long-term dependencies across the image sequences and process the spatial-temporal features simultaneously. We first benchmark the proposed Transformer models on a public dataset for slip detection. Following that, we show that the Transformer models outperform a CNN+LSTM model in terms of grasping accuracy and computational efficiency. We also collect our own fruit grasping dataset and conduct the online grasping experiments using the proposed framework for both seen and unseen fruits. Our codes and dataset are made public on GitHub.
Evaluating Generic Auto-ML Tools for Computational Pathology
Dec 07, 2021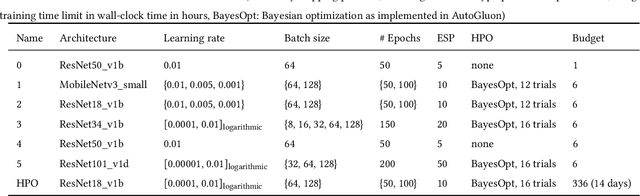
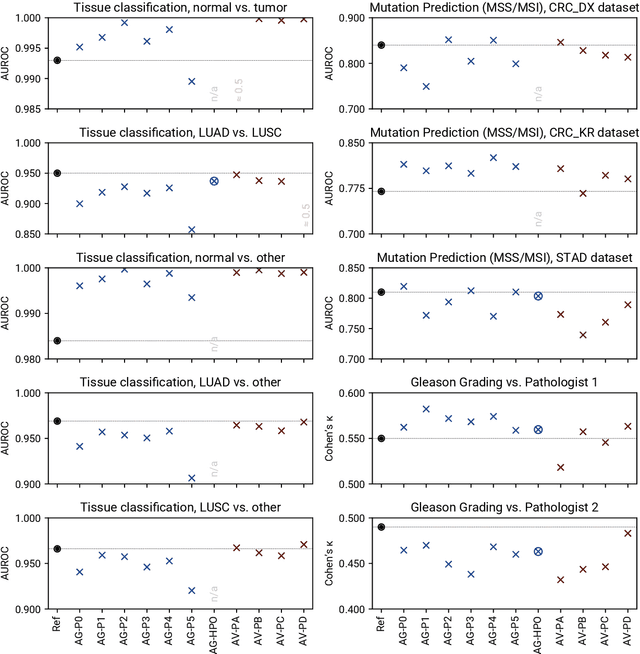

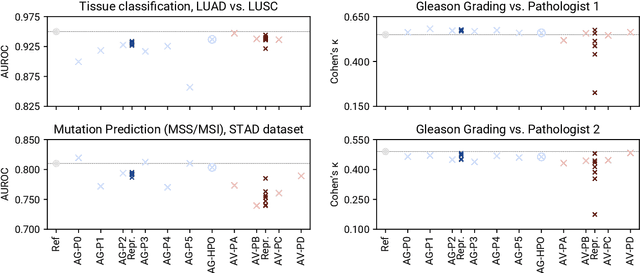
Image analysis tasks in computational pathology are commonly solved using convolutional neural networks (CNNs). The selection of a suitable CNN architecture and hyperparameters is usually done through exploratory iterative optimization, which is computationally expensive and requires substantial manual work. The goal of this article is to evaluate how generic tools for neural network architecture search and hyperparameter optimization perform for common use cases in computational pathology. For this purpose, we evaluated one on-premises and one cloud-based tool for three different classification tasks for histological images: tissue classification, mutation prediction, and grading. We found that the default CNN architectures and parameterizations of the evaluated AutoML tools already yielded classification performance on par with the original publications. Hyperparameter optimization for these tasks did not substantially improve performance, despite the additional computational effort. However, performance varied substantially between classifiers obtained from individual AutoML runs due to non-deterministic effects. Generic CNN architectures and AutoML tools could thus be a viable alternative to manually optimizing CNN architectures and parametrizations. This would allow developers of software solutions for computational pathology to focus efforts on harder-to-automate tasks such as data curation.
As if by magic: self-supervised training of deep despeckling networks with MERLIN
Oct 25, 2021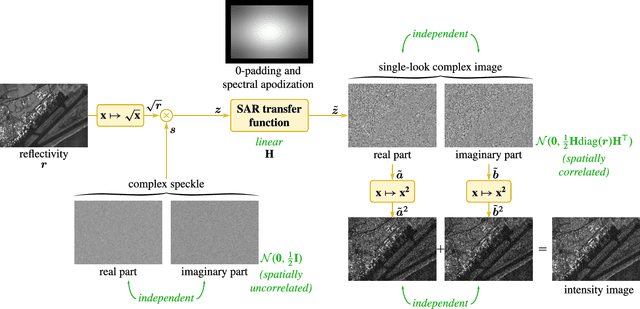
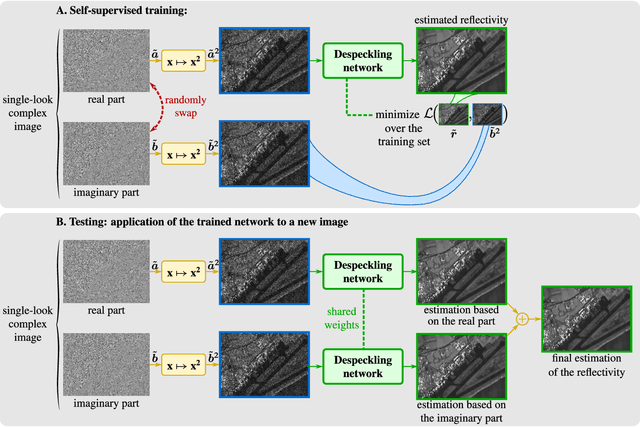


Speckle fluctuations seriously limit the interpretability of synthetic aperture radar (SAR) images. Speckle reduction has thus been the subject of numerous works spanning at least four decades. Techniques based on deep neural networks have recently achieved a new level of performance in terms of SAR image restoration quality. Beyond the design of suitable network architectures or the selection of adequate loss functions, the construction of training sets is of uttermost importance. So far, most approaches have considered a supervised training strategy: the networks are trained to produce outputs as close as possible to speckle-free reference images. Speckle-free images are generally not available, which requires resorting to natural or optical images or the selection of stable areas in long time series to circumvent the lack of ground truth. Self-supervision, on the other hand, avoids the use of speckle-free images. We introduce a self-supervised strategy based on the separation of the real and imaginary parts of single-look complex SAR images, called MERLIN (coMplex sElf-supeRvised despeckLINg), and show that it offers a straightforward way to train all kinds of deep despeckling networks. Networks trained with MERLIN take into account the spatial correlations due to the SAR transfer function specific to a given sensor and imaging mode. By requiring only a single image, and possibly exploiting large archives, MERLIN opens the door to hassle-free as well as large-scale training of despeckling networks. The code of the trained models is made freely available at https://gitlab.telecom-paris.fr/RING/MERLIN.
Multi-task manifold learning for small sample size datasets
Nov 24, 2021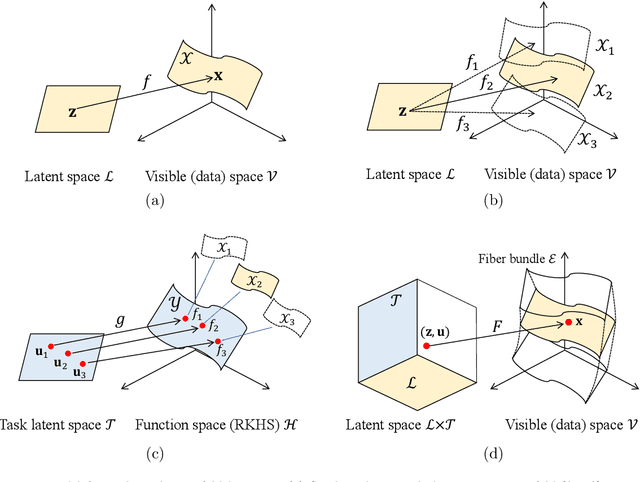
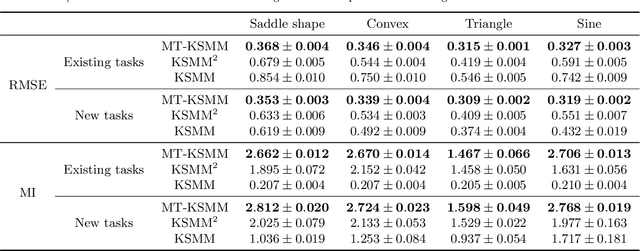
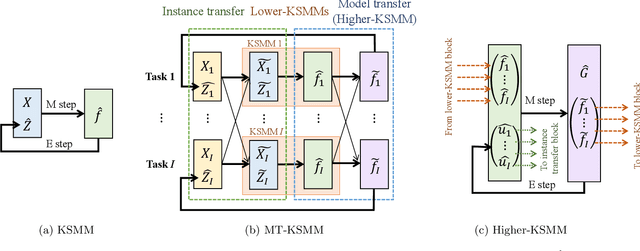

In this study, we develop a method for multi-task manifold learning. The method aims to improve the performance of manifold learning for multiple tasks, particularly when each task has a small number of samples. Furthermore, the method also aims to generate new samples for new tasks, in addition to new samples for existing tasks. In the proposed method, we use two different types of information transfer: instance transfer and model transfer. For instance transfer, datasets are merged among similar tasks, whereas for model transfer, the manifold models are averaged among similar tasks. For this purpose, the proposed method consists of a set of generative manifold models corresponding to the tasks, which are integrated into a general model of a fiber bundle. We applied the proposed method to artificial datasets and face image sets, and the results showed that the method was able to estimate the manifolds, even for a tiny number of samples.
AIM 2019 Challenge on Image Demoireing: Methods and Results
Nov 08, 2019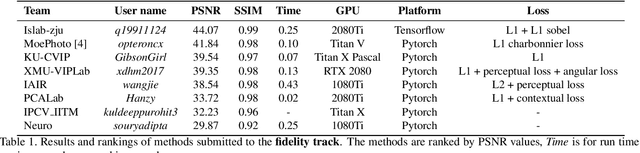
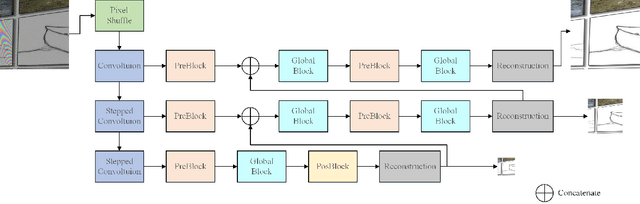
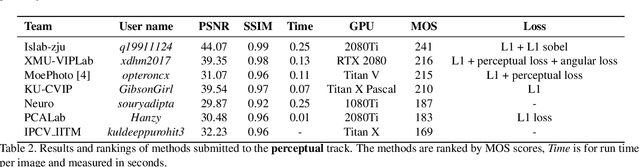
This paper reviews the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. This paper describes the challenge, and focuses on the proposed solutions and their results. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. A new dataset, called LCDMoire was created for this challenge, and consists of 10,200 synthetically generated image pairs (moire and clean ground truth). The challenge was divided into 2 tracks. Track 1 targeted fidelity, measuring the ability of demoire methods to obtain a moire-free image compared with the ground truth, while Track 2 examined the perceptual quality of demoire methods. The tracks had 60 and 39 registered participants, respectively. A total of eight teams competed in the final testing phase. The entries span the current the state-of-the-art in the image demoireing problem.
Regularizing Nighttime Weirdness: Efficient Self-supervised Monocular Depth Estimation in the Dark
Aug 13, 2021
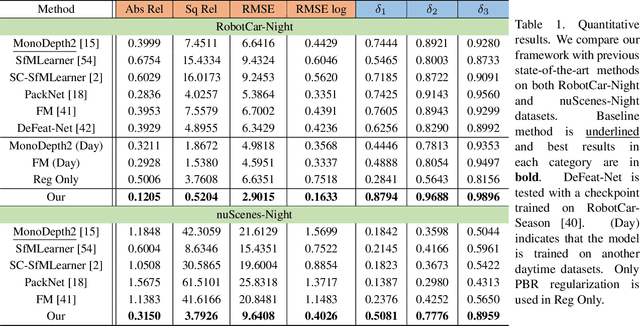
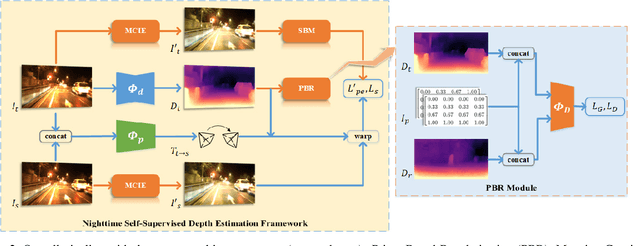
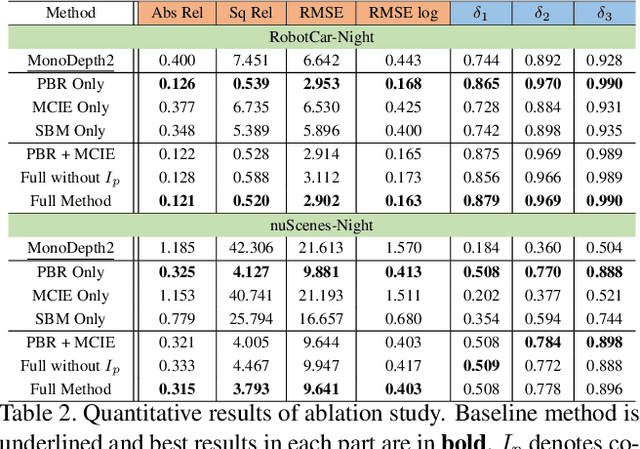
Monocular depth estimation aims at predicting depth from a single image or video. Recently, self-supervised methods draw much attention since they are free of depth annotations and achieve impressive performance on several daytime benchmarks. However, they produce weird outputs in more challenging nighttime scenarios because of low visibility and varying illuminations, which bring weak textures and break brightness-consistency assumption, respectively. To address these problems, in this paper we propose a novel framework with several improvements: (1) we introduce Priors-Based Regularization to learn distribution knowledge from unpaired depth maps and prevent model from being incorrectly trained; (2) we leverage Mapping-Consistent Image Enhancement module to enhance image visibility and contrast while maintaining brightness consistency; and (3) we present Statistics-Based Mask strategy to tune the number of removed pixels within textureless regions, using dynamic statistics. Experimental results demonstrate the effectiveness of each component. Meanwhile, our framework achieves remarkable improvements and state-of-the-art results on two nighttime datasets.
1st Place Solutions for UG2+ Challenge 2021 -- (Semi-)supervised Face detection in the low light condition
Jul 02, 2021

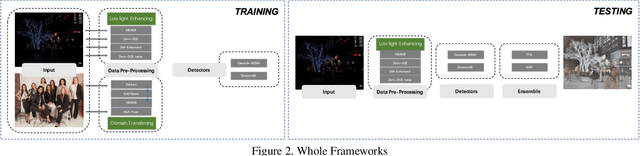

In this technical report, we briefly introduce the solution of our team "TAL-ai" for (Semi-) supervised Face detection in the low light condition in UG2+ Challenge in CVPR 2021. By conducting several experiments with popular image enhancement methods and image transfer methods, we pulled the low light image and the normal image to a more closer domain. And it is observed that using these data to training can achieve better performance. We also adapt several popular object detection frameworks, e.g., DetectoRS, Cascade-RCNN, and large backbone like Swin-transformer. Finally, we ensemble several models which achieved mAP 74.89 on the testing set, ranking 1st on the final leaderboard.
WaveFake: A Data Set to Facilitate Audio Deepfake Detection
Nov 04, 2021

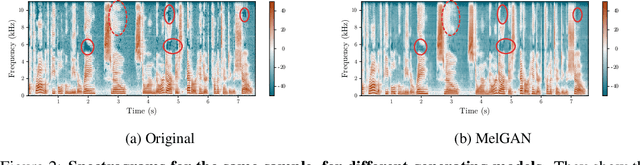
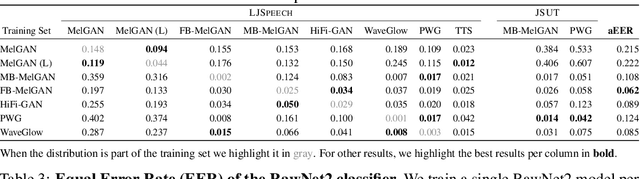
Deep generative modeling has the potential to cause significant harm to society. Recognizing this threat, a magnitude of research into detecting so-called "Deepfakes" has emerged. This research most often focuses on the image domain, while studies exploring generated audio signals have, so-far, been neglected. In this paper we make three key contributions to narrow this gap. First, we provide researchers with an introduction to common signal processing techniques used for analyzing audio signals. Second, we present a novel data set, for which we collected nine sample sets from five different network architectures, spanning two languages. Finally, we supply practitioners with two baseline models, adopted from the signal processing community, to facilitate further research in this area.
Continuous Convolutional Neural Networks: Coupled Neural PDE and ODE
Oct 30, 2021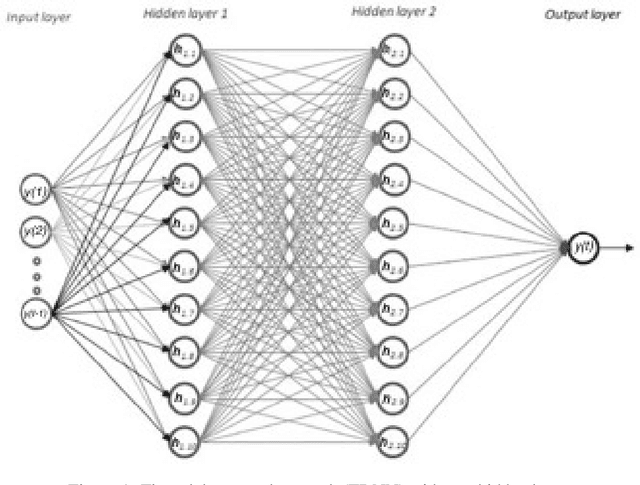
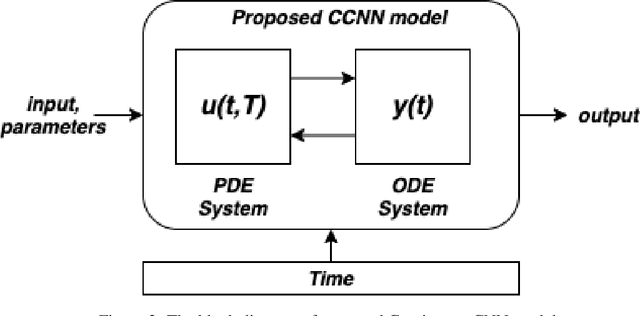
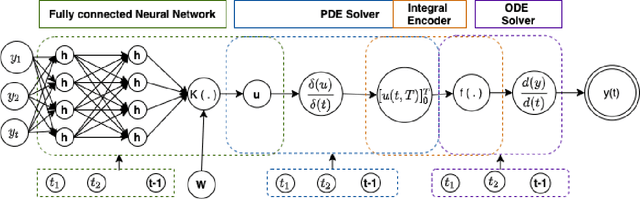
Recent work in deep learning focuses on solving physical systems in the Ordinary Differential Equation or Partial Differential Equation. This current work proposed a variant of Convolutional Neural Networks (CNNs) that can learn the hidden dynamics of a physical system using ordinary differential equation (ODEs) systems (ODEs) and Partial Differential Equation systems (PDEs). Instead of considering the physical system such as image, time -series as a system of multiple layers, this new technique can model a system in the form of Differential Equation (DEs). The proposed method has been assessed by solving several steady-state PDEs on irregular domains, including heat equations, Navier-Stokes equations.