 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Fixed Points in Generative Adversarial Networks: From Image-to-Image Translation to Disease Detection and Localization
Aug 29, 2019
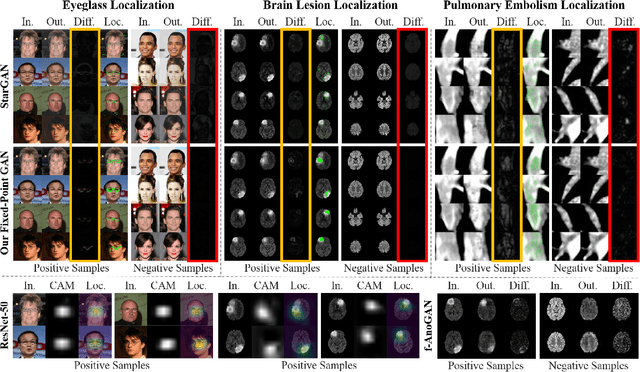

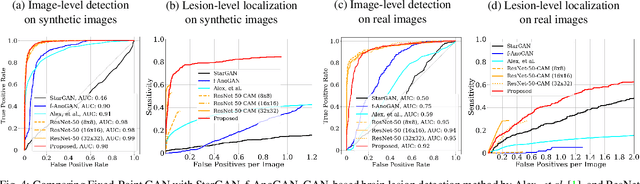
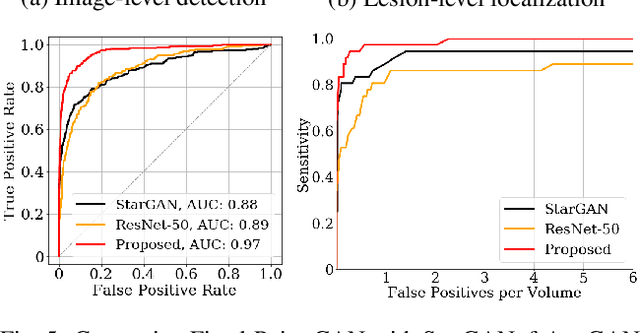
Generative adversarial networks (GANs) have ushered in a revolution in image-to-image translation. The development and proliferation of GANs raises an interesting question: can we train a GAN to remove an object, if present, from an image while otherwise preserving the image? Specifically, can a GAN "virtually heal" anyone by turning his medical image, with an unknown health status (diseased or healthy), into a healthy one, so that diseased regions could be revealed by subtracting those two images? Such a task requires a GAN to identify a minimal subset of target pixels for domain translation, an ability that we call fixed-point translation, which no GAN is equipped with yet. Therefore, we propose a new GAN, called Fixed-Point GAN, trained by (1) supervising same-domain translation through a conditional identity loss, and (2) regularizing cross-domain translation through revised adversarial, domain classification, and cycle consistency loss. Based on fixed-point translation, we further derive a novel framework for disease detection and localization using only image-level annotation. Qualitative and quantitative evaluations demonstrate that the proposed method outperforms the state of the art in multi-domain image-to-image translation and that it surpasses predominant weakly-supervised localization methods in both disease detection and localization. Implementation is available at https://github.com/jlianglab/Fixed-Point-GAN.
Robust data analysis and imaging with computational ghost imaging
Nov 06, 2021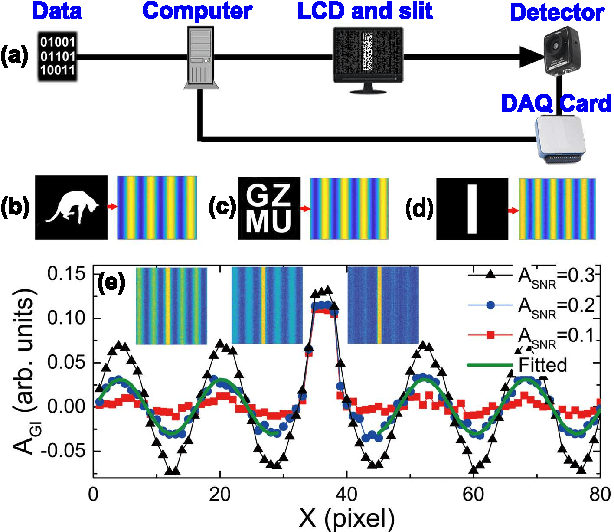
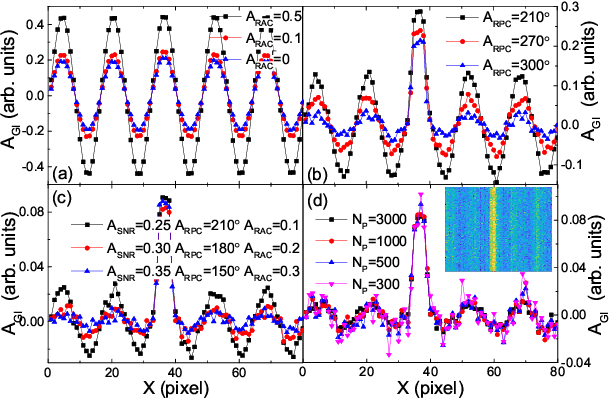
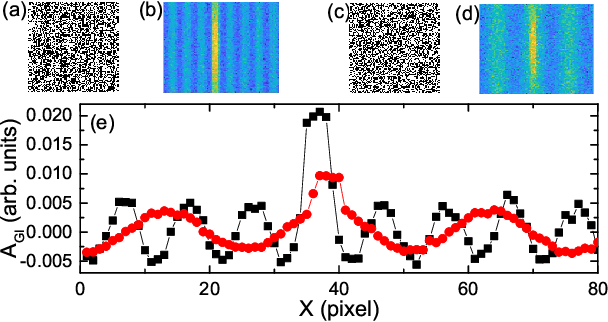
Nowadays the world has entered into the digital age, in which the data analysis and visualization have become more and more important. In analogy to imaging the real object, we demonstrate that the computational ghost imaging can image the digital data to show their characteristics, such as periodicity. Furthermore, our experimental results show that the use of optical imaging methods to analyse data exhibits unique advantages, especially in anti-interference. The data analysis with computational ghost imaging can be well performed against strong noise, random amplitude and phase changes in the binarized signals. Such robust data data analysis and imaging has an important application prospect in big data analysis, meteorology, astronomy, economics and many other fields.
Learning from Temporal Gradient for Semi-supervised Action Recognition
Nov 25, 2021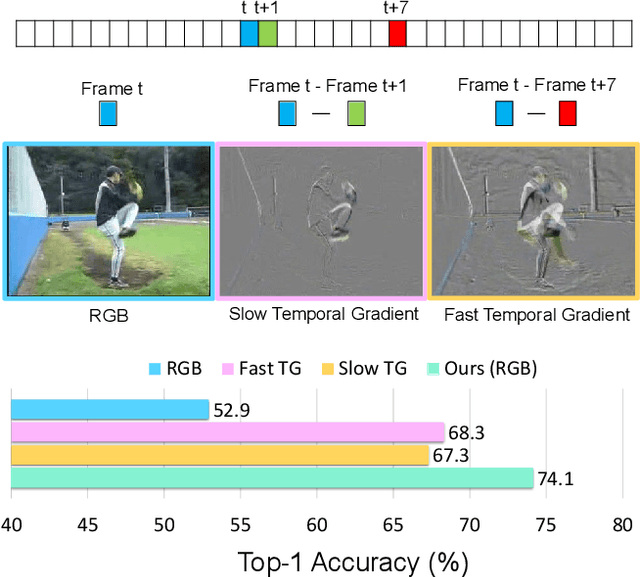
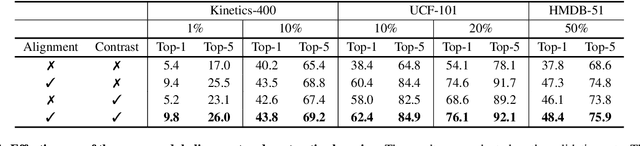
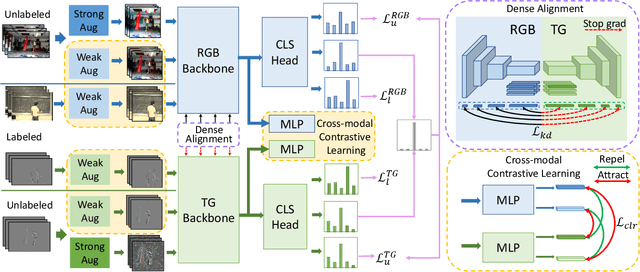
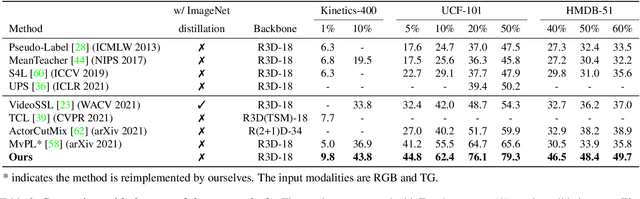
Semi-supervised video action recognition tends to enable deep neural networks to achieve remarkable performance even with very limited labeled data. However, existing methods are mainly transferred from current image-based methods (e.g., FixMatch). Without specifically utilizing the temporal dynamics and inherent multimodal attributes, their results could be suboptimal. To better leverage the encoded temporal information in videos, we introduce temporal gradient as an additional modality for more attentive feature extraction in this paper. To be specific, our method explicitly distills the fine-grained motion representations from temporal gradient (TG) and imposes consistency across different modalities (i.e., RGB and TG). The performance of semi-supervised action recognition is significantly improved without additional computation or parameters during inference. Our method achieves the state-of-the-art performance on three video action recognition benchmarks (i.e., Kinetics-400, UCF-101, and HMDB-51) under several typical semi-supervised settings (i.e., different ratios of labeled data).
Co-training Transformer with Videos and Images Improves Action Recognition
Dec 14, 2021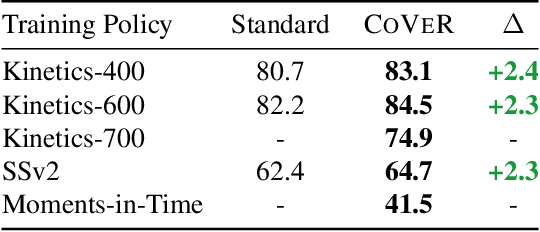
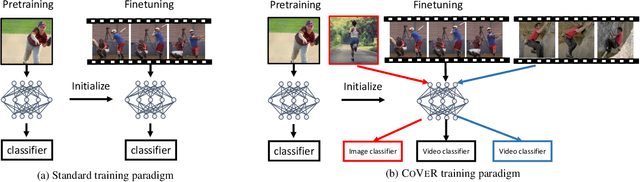

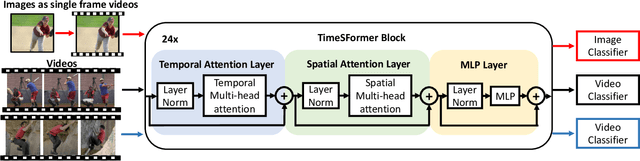
In learning action recognition, models are typically pre-trained on object recognition with images, such as ImageNet, and later fine-tuned on target action recognition with videos. This approach has achieved good empirical performance especially with recent transformer-based video architectures. While recently many works aim to design more advanced transformer architectures for action recognition, less effort has been made on how to train video transformers. In this work, we explore several training paradigms and present two findings. First, video transformers benefit from joint training on diverse video datasets and label spaces (e.g., Kinetics is appearance-focused while SomethingSomething is motion-focused). Second, by further co-training with images (as single-frame videos), the video transformers learn even better video representations. We term this approach as Co-training Videos and Images for Action Recognition (CoVeR). In particular, when pretrained on ImageNet-21K based on the TimeSFormer architecture, CoVeR improves Kinetics-400 Top-1 Accuracy by 2.4%, Kinetics-600 by 2.3%, and SomethingSomething-v2 by 2.3%. When pretrained on larger-scale image datasets following previous state-of-the-art, CoVeR achieves best results on Kinetics-400 (87.2%), Kinetics-600 (87.9%), Kinetics-700 (79.8%), SomethingSomething-v2 (70.9%), and Moments-in-Time (46.1%), with a simple spatio-temporal video transformer.
Restore from Restored: Single Image Denoising with Pseudo Clean Image
Mar 09, 2020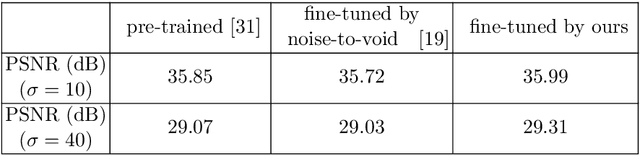

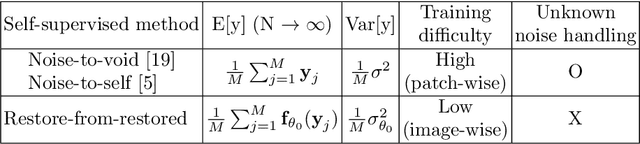
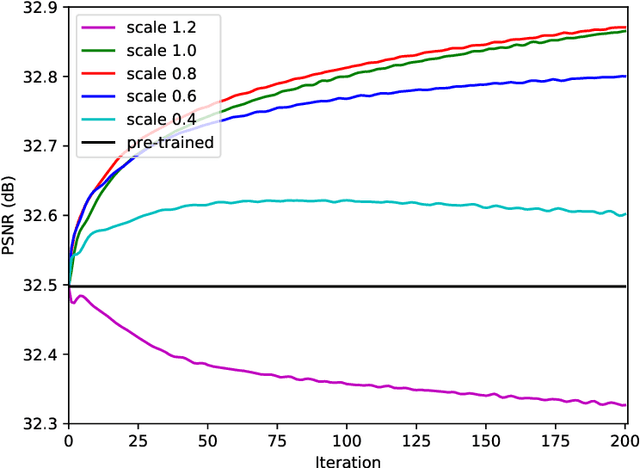
Under certain statistical assumptions of noise (e.g., zero-mean noise), recent self-supervised approaches for denoising have been introduced to learn network parameters without ground-truth clean images, and these methods can restore an image by exploiting information available from the given input (i.e., internal statistics) at test time. However, self-supervised methods are not yet properly combined with conventional supervised denoising methods which train the denoising networks with a large number of external training images. Thus, we propose a new denoising approach that can greatly outperform the state-of-the-art supervised denoising methods by adapting (fine-tuning) their network parameters to the given specific input through self-supervision without changing the fully original network architectures. We demonstrate that the proposed method can be easily employed with state-of-the-art denoising networks without additional parameters, and achieve state-of-the-art performance on numerous denoising benchmark datasets.
"Double-DIP": Unsupervised Image Decomposition via Coupled Deep-Image-Priors
Dec 05, 2018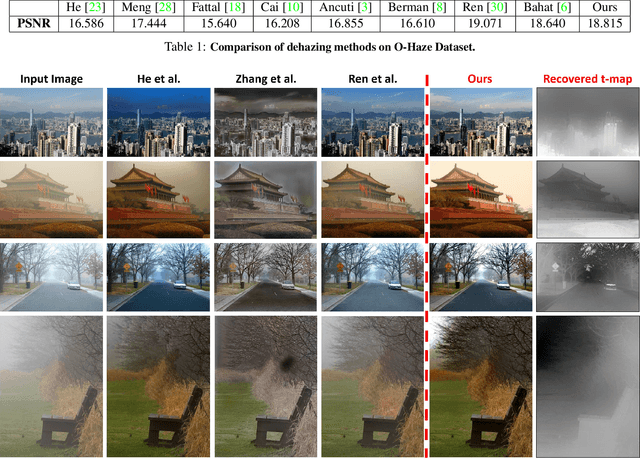
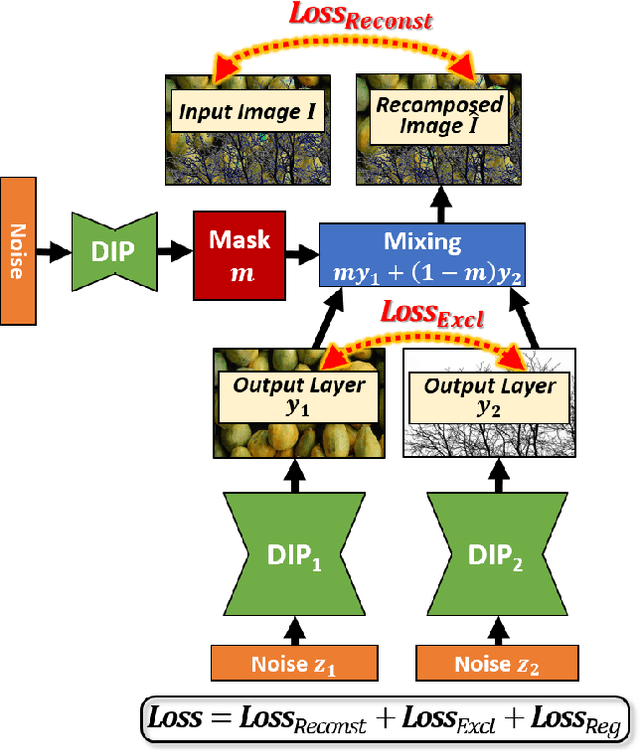
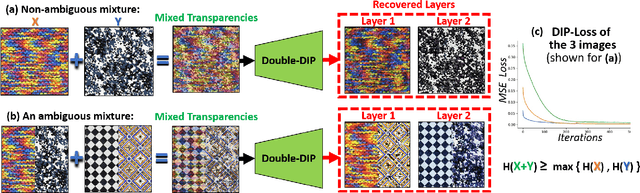

Many seemingly unrelated computer vision tasks can be viewed as a special case of image decomposition into separate layers. For example, image segmentation (separation into foreground and background layers); transparent layer separation (into reflection and transmission layers); Image dehazing (separation into a clear image and a haze map), and more. In this paper we propose a unified framework for unsupervised layer decomposition of a single image, based on coupled "Deep-image-Prior" (DIP) networks. It was shown [Ulyanov et al] that the structure of a single DIP generator network is sufficient to capture the low-level statistics of a single image. We show that coupling multiple such DIPs provides a powerful tool for decomposing images into their basic components, for a wide variety of applications. This capability stems from the fact that the internal statistics of a mixture of layers is more complex than the statistics of each of its individual components. We show the power of this approach for Image-Dehazing, Fg/Bg Segmentation, Watermark-Removal, Transparency Separation in images and video, and more. These capabilities are achieved in a totally unsupervised way, with no training examples other than the input image/video itself.
Augmenting Depth Estimation with Geospatial Context
Sep 20, 2021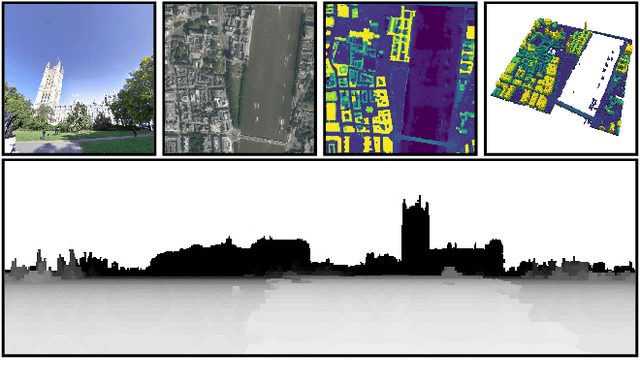
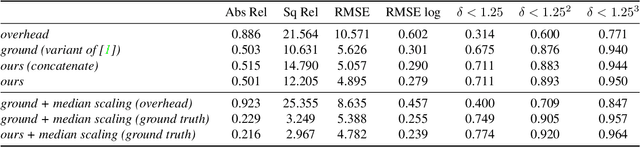

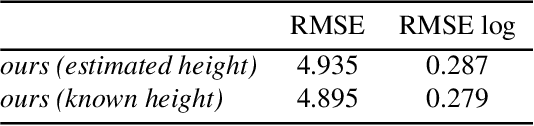
Modern cameras are equipped with a wide array of sensors that enable recording the geospatial context of an image. Taking advantage of this, we explore depth estimation under the assumption that the camera is geocalibrated, a problem we refer to as geo-enabled depth estimation. Our key insight is that if capture location is known, the corresponding overhead viewpoint offers a valuable resource for understanding the scale of the scene. We propose an end-to-end architecture for depth estimation that uses geospatial context to infer a synthetic ground-level depth map from a co-located overhead image, then fuses it inside of an encoder/decoder style segmentation network. To support evaluation of our methods, we extend a recently released dataset with overhead imagery and corresponding height maps. Results demonstrate that integrating geospatial context significantly reduces error compared to baselines, both at close ranges and when evaluating at much larger distances than existing benchmarks consider.
Global Self-Attention Networks for Image Recognition
Oct 14, 2020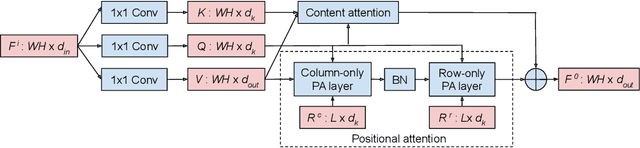
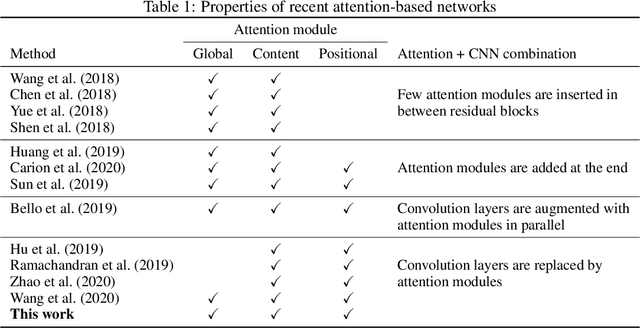
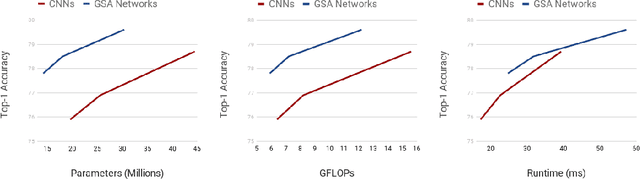

Recently, a series of works in computer vision have shown promising results on various image and video understanding tasks using self-attention. However, due to the quadratic computational and memory complexities of self-attention, these works either apply attention only to low-resolution feature maps in later stages of a deep network or restrict the receptive field of attention in each layer to a small local region. To overcome these limitations, this work introduces a new global self-attention module, referred to as the GSA module, which is efficient enough to serve as the backbone component of a deep network. This module consists of two parallel layers: a content attention layer that attends to pixels based only on their content and a positional attention layer that attends to pixels based on their spatial locations. The output of this module is the sum of the outputs of the two layers. Based on the proposed GSA module, we introduce new standalone global attention-based deep networks that use GSA modules instead of convolutions to model pixel interactions. Due to the global extent of the proposed GSA module, a GSA network has the ability to model long-range pixel interactions throughout the network. Our experimental results show that GSA networks outperform the corresponding convolution-based networks significantly on the CIFAR-100 and ImageNet datasets while using less parameters and computations. The proposed GSA networks also outperform various existing attention-based networks on the ImageNet dataset.
IGAN: Inferent and Generative Adversarial Networks
Sep 27, 2021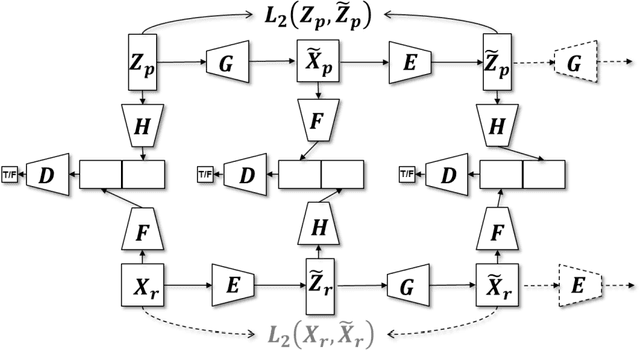


I present IGAN (Inferent Generative Adversarial Networks), a neural architecture that learns both a generative and an inference model on a complex high dimensional data distribution, i.e. a bidirectional mapping between data samples and a simpler low-dimensional latent space. It extends the traditional GAN framework with inference by rewriting the adversarial strategy in both the image and the latent space with an entangled game between data-latent encoded posteriors and priors. It brings a measurable stability and convergence to the classical GAN scheme, while keeping its generative quality and remaining simple and frugal in order to run on a lab PC. IGAN fosters the encoded latents to span the full prior space: this enables the exploitation of an enlarged and self-organised latent space in an unsupervised manner. An analysis of previously published articles sets the theoretical ground for the proposed algorithm. A qualitative demonstration of potential applications like self-supervision or multi-modal data translation is given on common image datasets including SAR and optical imagery.
Lifelong Topological Visual Navigation
Oct 16, 2021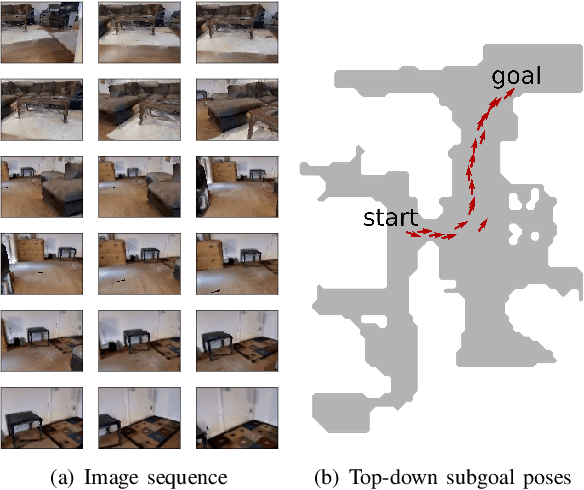
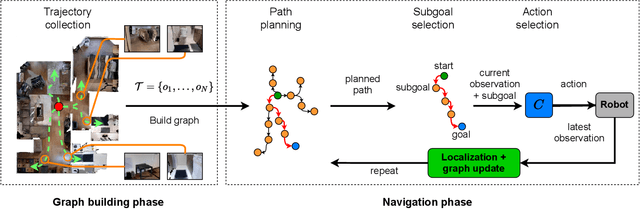
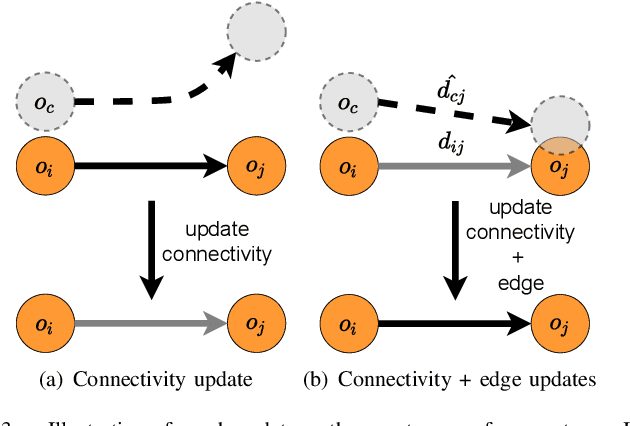
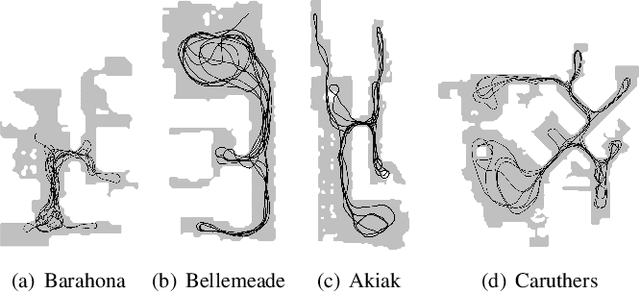
The ability for a robot to navigate with only the use of vision is appealing due to its simplicity. Traditional vision-based navigation approaches required a prior map-building step that was arduous and prone to failure, or could only exactly follow previously executed trajectories. Newer learning-based visual navigation techniques reduce the reliance on a map and instead directly learn policies from image inputs for navigation. There are currently two prevalent paradigms: end-to-end approaches forego the explicit map representation entirely, and topological approaches which still preserve some loose connectivity of the space. However, while end-to-end methods tend to struggle in long-distance navigation tasks, topological map-based solutions are prone to failure due to spurious edges in the graph. In this work, we propose a learning-based topological visual navigation method with graph update strategies that improve lifelong navigation performance over time. We take inspiration from sampling-based planning algorithms to build image-based topological graphs, resulting in sparser graphs yet with higher navigation performance compared to baseline methods. Also, unlike controllers that learn from fixed training environments, we show that our model can be finetuned using a relatively small dataset from the real-world environment where the robot is deployed. We further assess performance of our system in real-world deployments.