 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Simple and Efficient Registration of 3D Point Cloud and Image Data for Indoor Mobile Mapping System
Oct 27, 2020
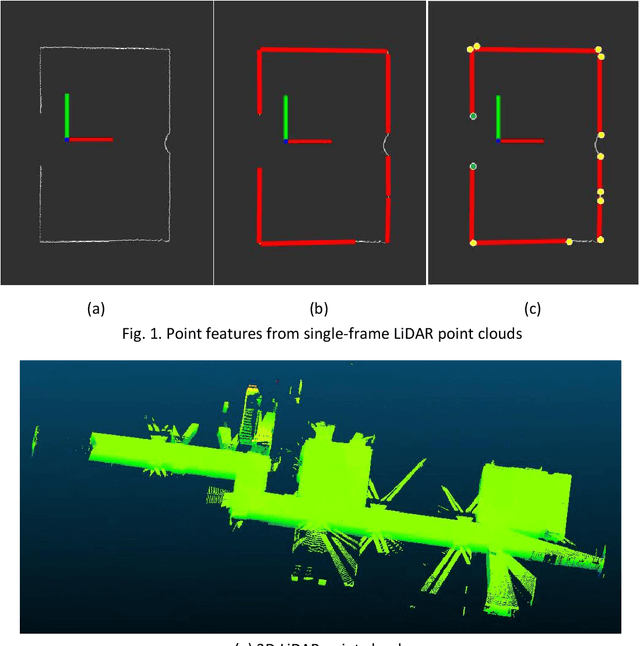


Registration of 3D LiDAR point clouds with optical images is critical in the combination of multi-source data. Geometric misalignment originally exists in the pose data between LiDAR point clouds and optical images. To improve the accuracy of the initial pose and the applicability of the integration of 3D points and image data, we develop a simple but efficient registration method. We firstly extract point features from LiDAR point clouds and images: point features is extracted from single-frame LiDAR and point features from images using classical Canny method. Cost map is subsequently built based on Canny image edge detection. The optimization direction is guided by the cost map where low cost represents the the desired direction, and loss function is also considered to improve the robustness of the the purposed method. Experiments show pleasant results.
LCTR: On Awakening the Local Continuity of Transformer for Weakly Supervised Object Localization
Dec 10, 2021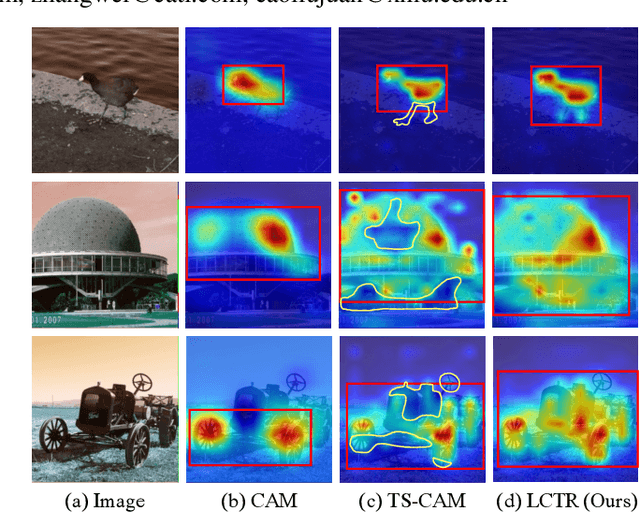
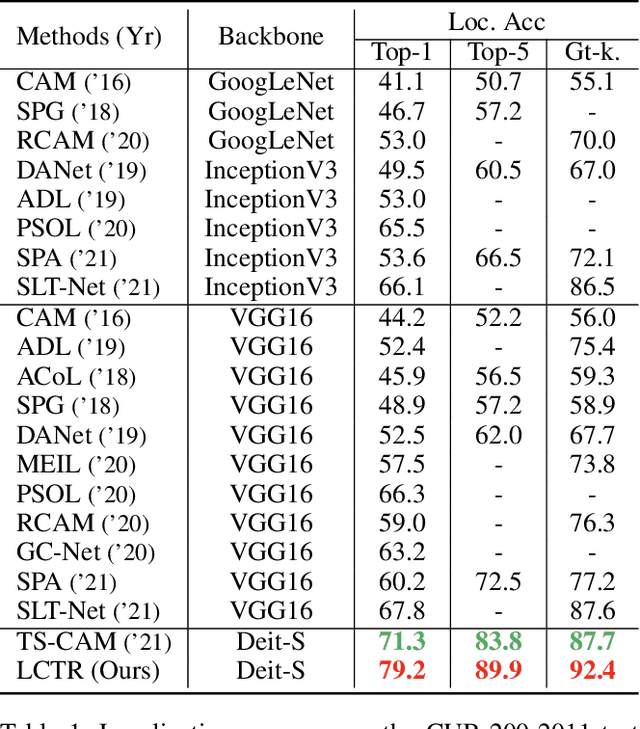
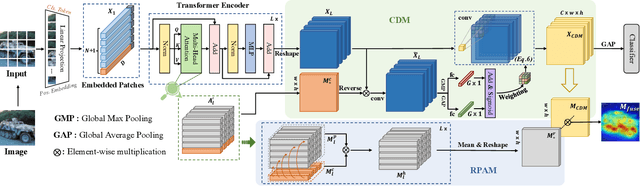
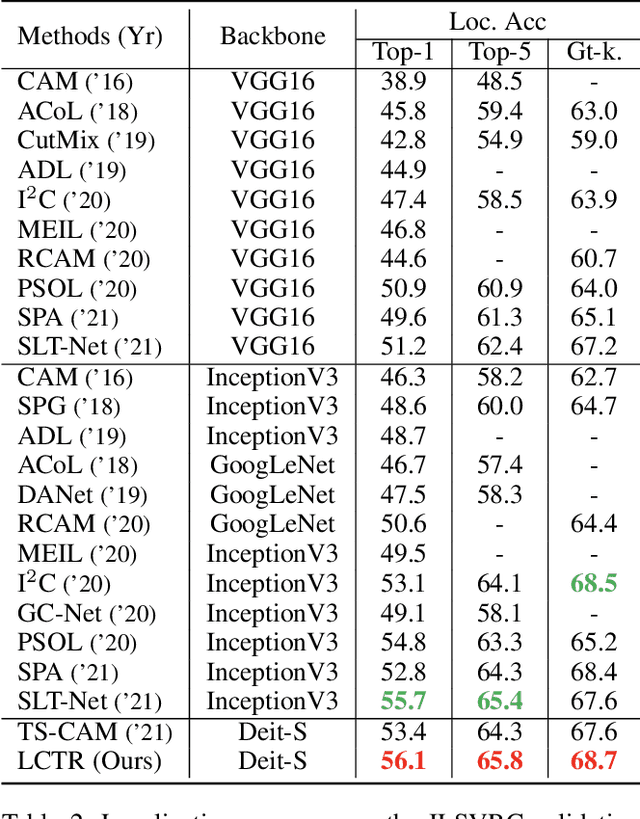
Weakly supervised object localization (WSOL) aims to learn object localizer solely by using image-level labels. The convolution neural network (CNN) based techniques often result in highlighting the most discriminative part of objects while ignoring the entire object extent. Recently, the transformer architecture has been deployed to WSOL to capture the long-range feature dependencies with self-attention mechanism and multilayer perceptron structure. Nevertheless, transformers lack the locality inductive bias inherent to CNNs and therefore may deteriorate local feature details in WSOL. In this paper, we propose a novel framework built upon the transformer, termed LCTR (Local Continuity TRansformer), which targets at enhancing the local perception capability of global features among long-range feature dependencies. To this end, we propose a relational patch-attention module (RPAM), which considers cross-patch information on a global basis. We further design a cue digging module (CDM), which utilizes local features to guide the learning trend of the model for highlighting the weak local responses. Finally, comprehensive experiments are carried out on two widely used datasets, ie, CUB-200-2011 and ILSVRC, to verify the effectiveness of our method.
Comparing to Learn: Surpassing ImageNet Pretraining on Radiographs By Comparing Image Representations
Jul 22, 2020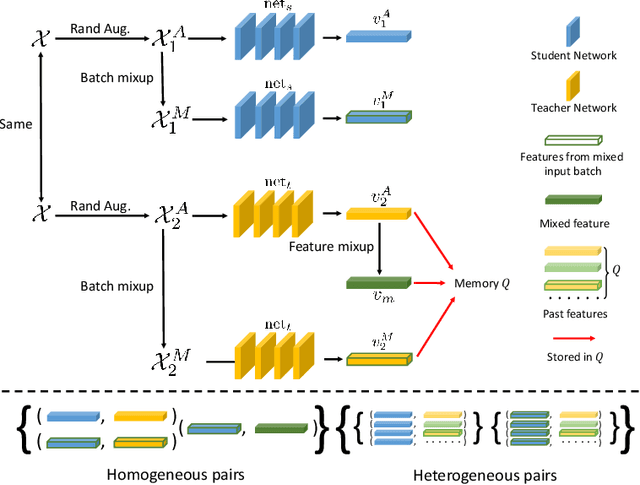
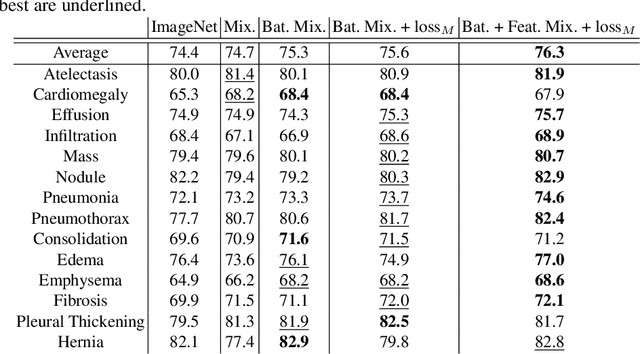

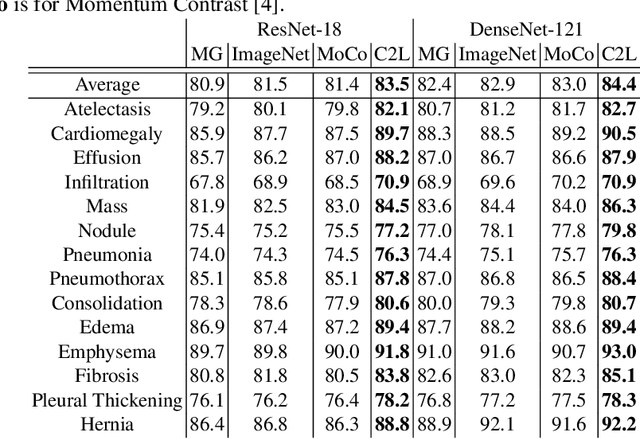
In deep learning era, pretrained models play an important role in medical image analysis, in which ImageNet pretraining has been widely adopted as the best way. However, it is undeniable that there exists an obvious domain gap between natural images and medical images. To bridge this gap, we propose a new pretraining method which learns from 700k radiographs given no manual annotations. We call our method as Comparing to Learn (C2L) because it learns robust features by comparing different image representations. To verify the effectiveness of C2L, we conduct comprehensive ablation studies and evaluate it on different tasks and datasets. The experimental results on radiographs show that C2L can outperform ImageNet pretraining and previous state-of-the-art approaches significantly. Code and models are available.
Barlow Graph Auto-Encoder for Unsupervised Network Embedding
Nov 23, 2021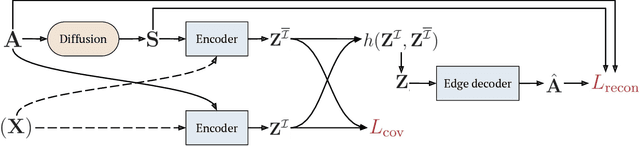
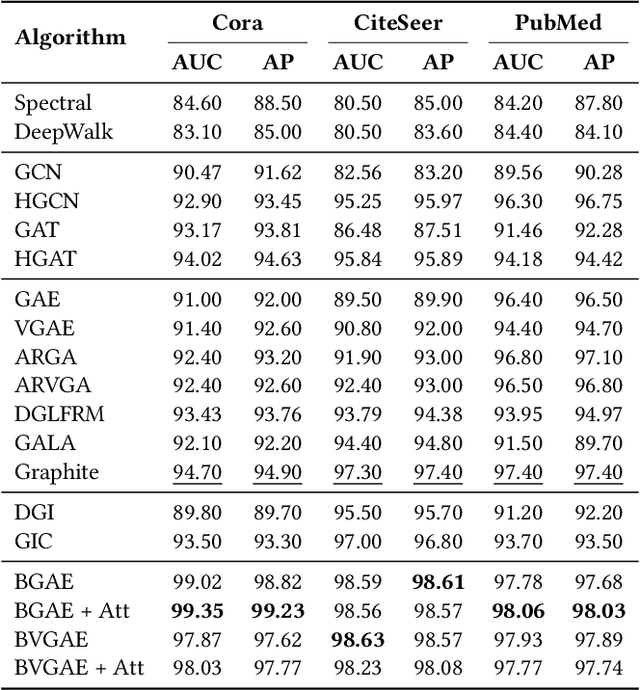
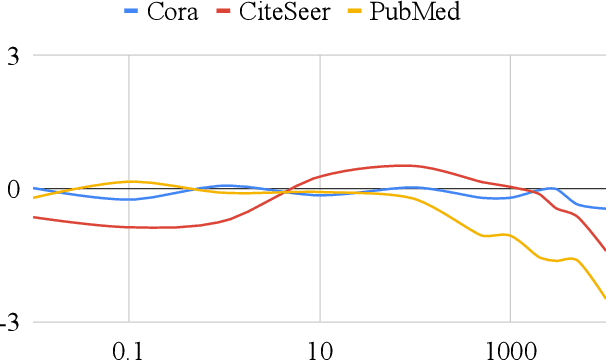
Network embedding has emerged as a promising research field for network analysis. Recently, an approach, named Barlow Twins, has been proposed for self-supervised learning in computer vision by applying the redundancy-reduction principle to the embedding vectors corresponding to two distorted versions of the image samples. Motivated by this, we propose Barlow Graph Auto-Encoder, a simple yet effective architecture for learning network embedding. It aims to maximize the similarity between the embedding vectors of immediate and larger neighborhoods of a node, while minimizing the redundancy between the components of these projections. In addition, we also present the variation counterpart named as Barlow Variational Graph Auto-Encoder. Our approach yields promising results for inductive link prediction and is also on par with state of the art for clustering and downstream node classification, as demonstrated by extensive comparisons with several well-known techniques on three benchmark citation datasets.
An End-To-End-Trainable Iterative Network Architecture for Accelerated Radial Multi-Coil 2D Cine MR Image Reconstruction
Feb 01, 2021
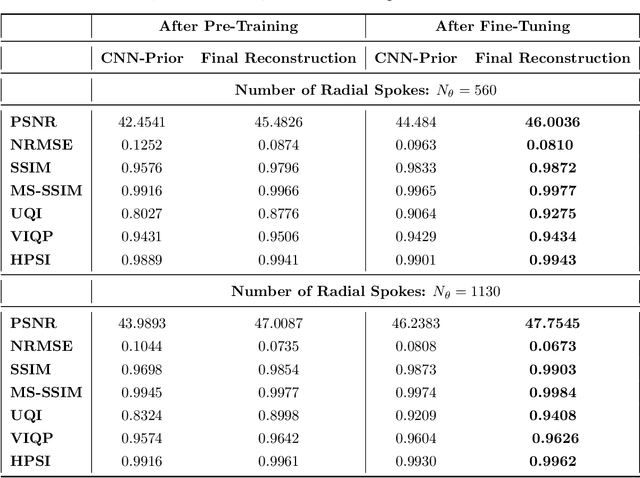
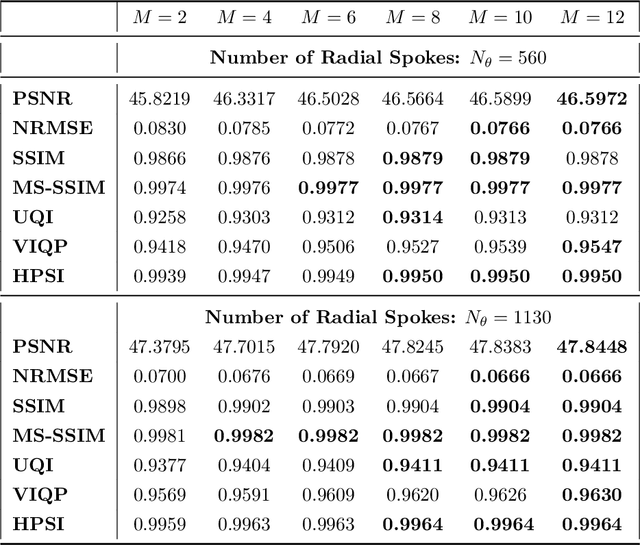
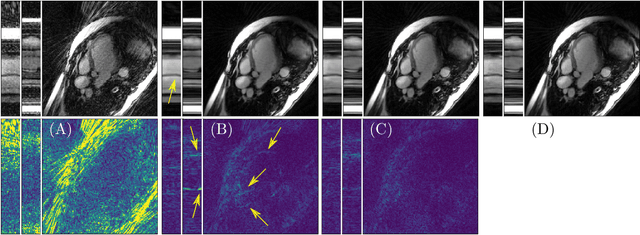
Purpose: Iterative Convolutional Neural Networks (CNNs) which resemble unrolled learned iterative schemes have shown to consistently deliver state-of-the-art results for image reconstruction problems across different imaging modalities. However, because these methodes include the forward model in the architecture, their applicability is often restricted to either relatively small reconstruction problems or to problems with operators which are computationally cheap to compute. As a consequence, they have so far not been applied to dynamic non-Cartesian multi-coil reconstruction problems. Methods: In this work, we propose a CNN-architecture for image reconstruction of accelerated 2D radial cine MRI with multiple receiver coils. The network is based on a computationally light CNN-component and a subsequent conjugate gradient (CG) method which can be jointly trained end-to-end using an efficient training strategy. We investigate the proposed training-strategy and compare our method to other well-known reconstruction techniques with learned and non-learned regularization methods. Results: Our proposed method outperforms all other methods based on non-learned regularization. Further, it performs similar or better than a CNN-based method employing a 3D U-Net and a method using adaptive dictionary learning. In addition, we empirically demonstrate that even by training the network with only iteration, it is possible to increase the length of the network at test time and further improve the results. Conclusions: End-to-end training allows to highly reduce the number of trainable parameters of and stabilize the reconstruction network. Further, because it is possible to change the length of the network at test time, the need to find a compromise between the complexity of the CNN-block and the number of iterations in each CG-block becomes irrelevant.
Image Embedded Segmentation: Combining Supervised and Unsupervised Objectives through Generative Adversarial Networks
Jan 30, 2020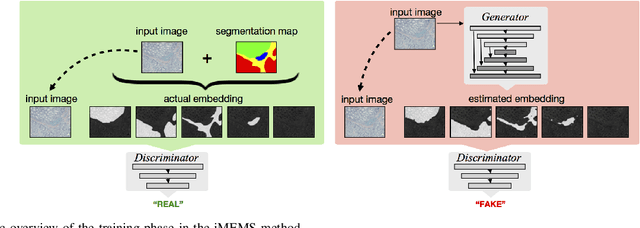
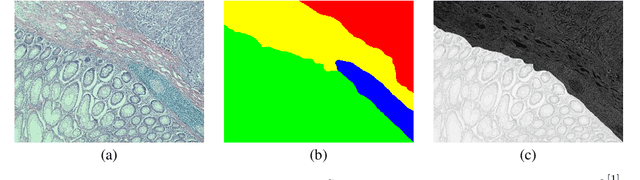

This paper presents a new regularization method to train a fully convolutional network for semantic tissue segmentation in histopathological images. This method relies on benefiting unsupervised learning, in the form of image reconstruction, for the network training. To this end, it puts forward an idea of defining a new embedding that allows uniting the main supervised task of semantic segmentation and an auxiliary unsupervised task of image reconstruction into a single task and proposes to learn this united task by a single generative model. This embedding generates a multi-channel output image by superimposing an original input image on its segmentation map. Then, the method learns to translate the input image to this embedded output image using a conditional generative adversarial network, which is known to be quite effective for image-to-image translations. This proposal is different than the existing approach that uses image reconstruction for the same regularization purpose. The existing approach considers segmentation and image reconstruction as two separate tasks in a multi-task network, defines their losses independently, and then combines these losses in a joint loss function. However, the definition of such a function requires externally determining the right contribution amounts of the supervised and unsupervised losses that yield balanced learning between the segmentation and image reconstruction tasks. The proposed approach eliminates this difficulty by uniting these two tasks into a single one, which intrinsically combines their losses. Using histopathological image segmentation as a showcase application, our experiments demonstrate that this proposed approach leads to better segmentation results.
Salient Object Detection by LTP Texture Characterization on Opposing Color Pairs under SLICO Superpixel Constraint
Jan 03, 2022
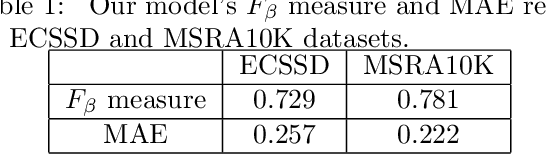
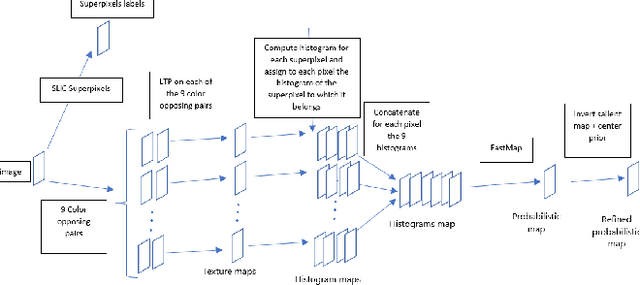

The effortless detection of salient objects by humans has been the subject of research in several fields, including computer vision as it has many applications. However, salient object detection remains a challenge for many computer models dealing with color and textured images. Herein, we propose a novel and efficient strategy, through a simple model, almost without internal parameters, which generates a robust saliency map for a natural image. This strategy consists of integrating color information into local textural patterns to characterize a color micro-texture. Most models in the literature that use the color and texture features treat them separately. In our case, it is the simple, yet powerful LTP (Local Ternary Patterns) texture descriptor applied to opposing color pairs of a color space that allows us to achieve this end. Each color micro-texture is represented by vector whose components are from a superpixel obtained by SLICO (Simple Linear Iterative Clustering with zero parameter) algorithm which is simple, fast and exhibits state-of-the-art boundary adherence. The degree of dissimilarity between each pair of color micro-texture is computed by the FastMap method, a fast version of MDS (Multi-dimensional Scaling), that considers the color micro-textures non-linearity while preserving their distances. These degrees of dissimilarity give us an intermediate saliency map for each RGB, HSL, LUV and CMY color spaces. The final saliency map is their combination to take advantage of the strength of each of them. The MAE (Mean Absolute Error) and F$_{\beta}$ measures of our saliency maps, on the complex ECSSD dataset show that our model is both simple and efficient, outperforming several state-of-the-art models.
Transfer learning using deep neural networks for Ear Presentation Attack Detection: New Database for PAD
Dec 09, 2021
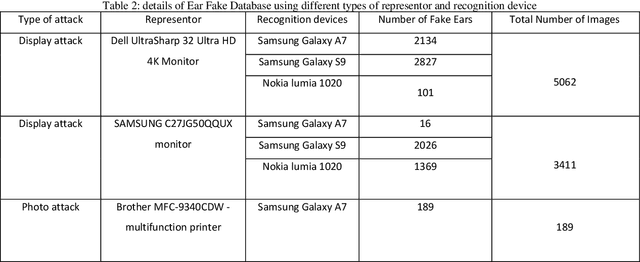
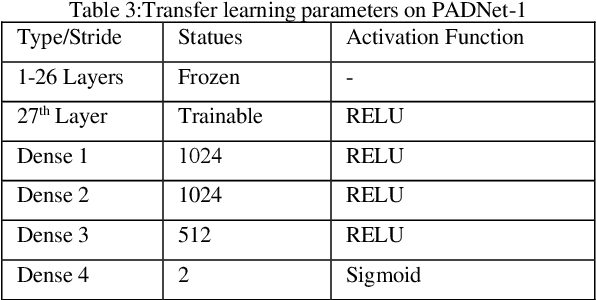
Ear recognition system has been widely studied whereas there are just a few ear presentation attack detection methods for ear recognition systems, consequently, there is no publicly available ear presentation attack detection (PAD) database. In this paper, we propose a PAD method using a pre-trained deep neural network and release a new dataset called Warsaw University of Technology Ear Dataset for Presentation Attack Detection (WUT-Ear V1.0). There is no ear database that is captured using mobile devices. Hence, we have captured more than 8500 genuine ear images from 134 subjects and more than 8500 fake ear images using. We made replay-attack and photo print attacks with 3 different mobile devices. Our approach achieves 99.83% and 0.08% for the half total error rate (HTER) and attack presentation classification error rate (APCER), respectively, on the replay-attack database. The captured data is analyzed and visualized statistically to find out its importance and make it a benchmark for further research. The experiments have been found out a secure PAD method for ear recognition system, publicly available ear image, and ear PAD dataset. The codes and evaluation results are publicly available at https://github.com/Jalilnkh/KartalOl-EAR-PAD.
Face Reconstruction with Variational Autoencoder and Face Masks
Dec 03, 2021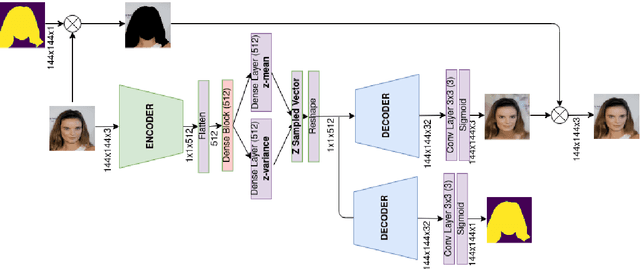

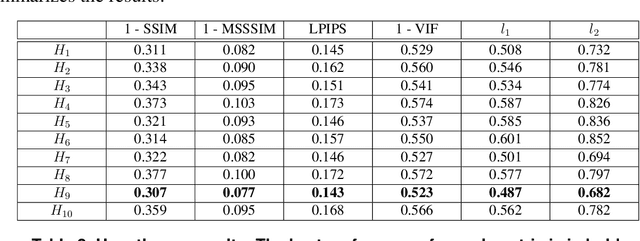
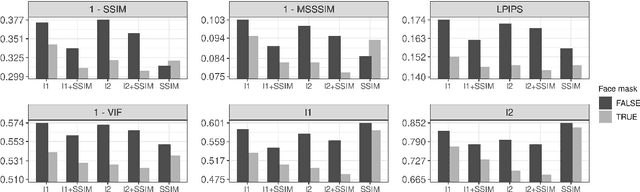
Variational AutoEncoders (VAE) employ deep learning models to learn a continuous latent z-space that is subjacent to a high-dimensional observed dataset. With that, many tasks are made possible, including face reconstruction and face synthesis. In this work, we investigated how face masks can help the training of VAEs for face reconstruction, by restricting the learning to the pixels selected by the face mask. An evaluation of the proposal using the celebA dataset shows that the reconstructed images are enhanced with the face masks, especially when SSIM loss is used either with l1 or l2 loss functions. We noticed that the inclusion of a decoder for face mask prediction in the architecture affected the performance for l1 or l2 loss functions, while this was not the case for the SSIM loss. Besides, SSIM perceptual loss yielded the crispest samples between all hypotheses tested, although it shifts the original color of the image, making the usage of the l1 or l2 losses together with SSIM helpful to solve this issue.
Microscopy Image Restoration using Deep Learning on W2S
Apr 22, 2020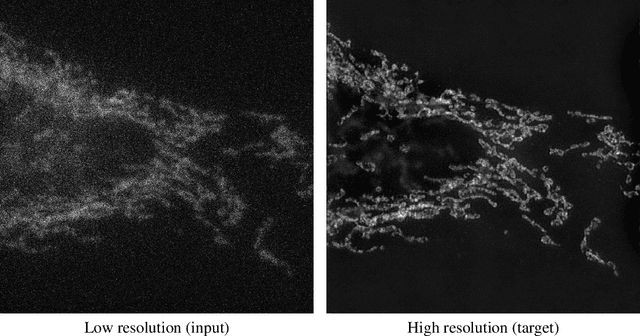

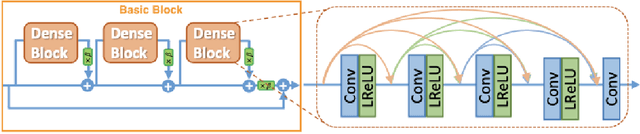
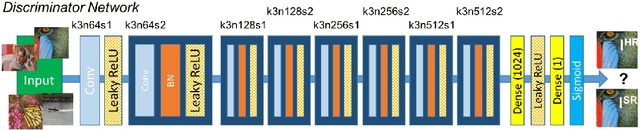
We leverage deep learning techniques to jointly denoise and super-resolve biomedical images acquired with fluorescence microscopy. We develop a deep learning algorithm based on the networks and method described in the recent W2S paper to solve a joint denoising and super-resolution problem. Specifically, we address the restoration of SIM images from widefield images. Our TensorFlow model is trained on the W2S dataset of cell images and is made accessible online in this repository: https://github.com/mchatton/w2s-tensorflow. On test images, the model shows a visually-convincing denoising and increases the resolution by a factor of two compared to the input image. For a 512 $\times$ 512 image, the inference takes less than 1 second on a Titan X GPU and about 15 seconds on a common CPU. We further present the results of different variations of losses used in training.