 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Comparing to Learn: Surpassing ImageNet Pretraining on Radiographs By Comparing Image Representations
Jul 22, 2020
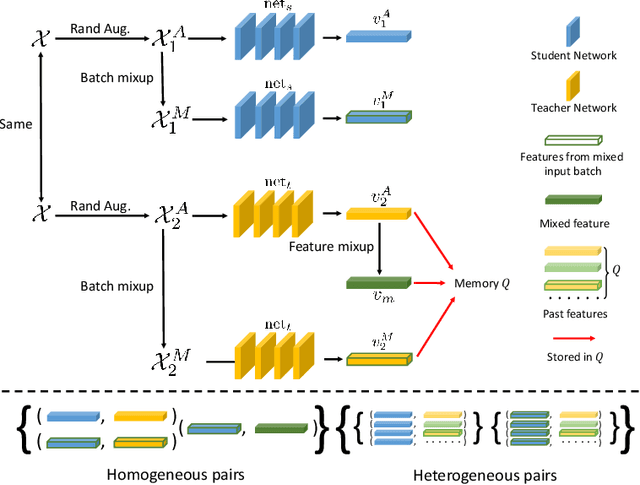
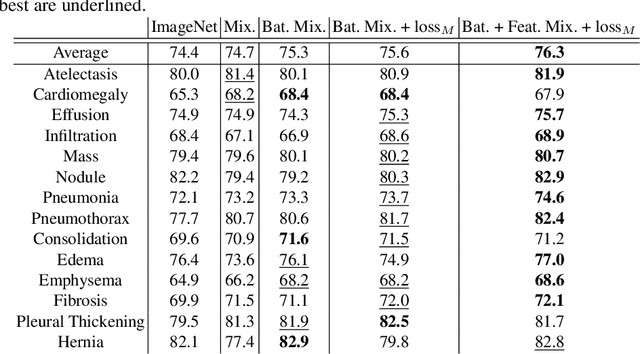

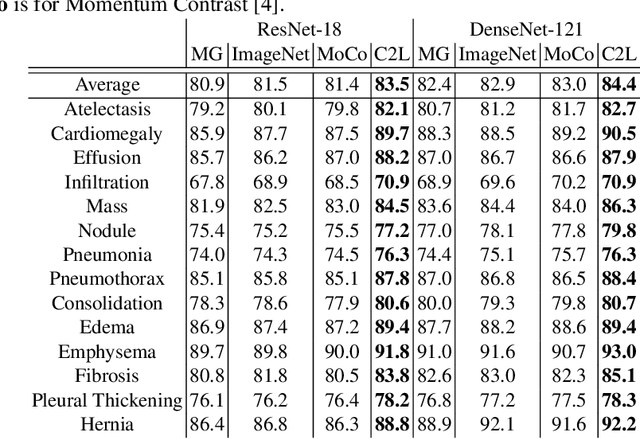
In deep learning era, pretrained models play an important role in medical image analysis, in which ImageNet pretraining has been widely adopted as the best way. However, it is undeniable that there exists an obvious domain gap between natural images and medical images. To bridge this gap, we propose a new pretraining method which learns from 700k radiographs given no manual annotations. We call our method as Comparing to Learn (C2L) because it learns robust features by comparing different image representations. To verify the effectiveness of C2L, we conduct comprehensive ablation studies and evaluate it on different tasks and datasets. The experimental results on radiographs show that C2L can outperform ImageNet pretraining and previous state-of-the-art approaches significantly. Code and models are available.
A Simple and Efficient Registration of 3D Point Cloud and Image Data for Indoor Mobile Mapping System
Oct 27, 2020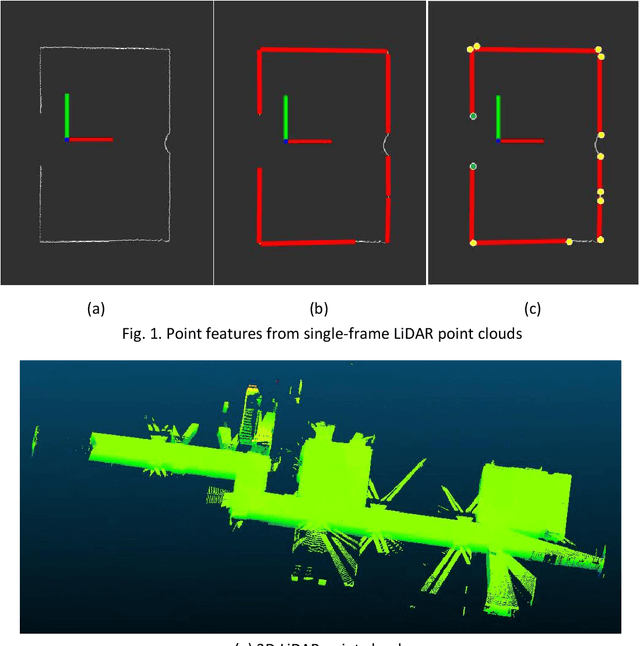


Registration of 3D LiDAR point clouds with optical images is critical in the combination of multi-source data. Geometric misalignment originally exists in the pose data between LiDAR point clouds and optical images. To improve the accuracy of the initial pose and the applicability of the integration of 3D points and image data, we develop a simple but efficient registration method. We firstly extract point features from LiDAR point clouds and images: point features is extracted from single-frame LiDAR and point features from images using classical Canny method. Cost map is subsequently built based on Canny image edge detection. The optimization direction is guided by the cost map where low cost represents the the desired direction, and loss function is also considered to improve the robustness of the the purposed method. Experiments show pleasant results.
SPAA: Stealthy Projector-based Adversarial Attacks on Deep Image Classifiers
Dec 10, 2020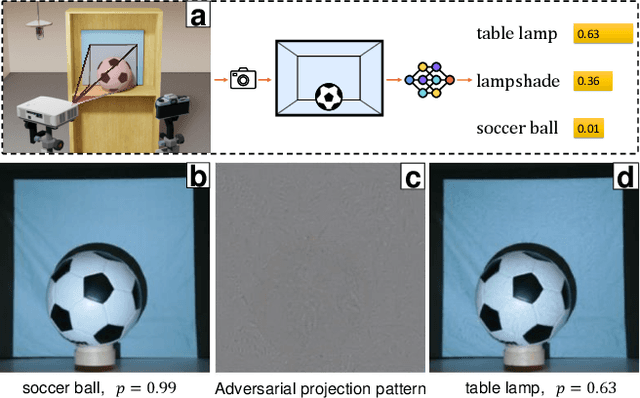
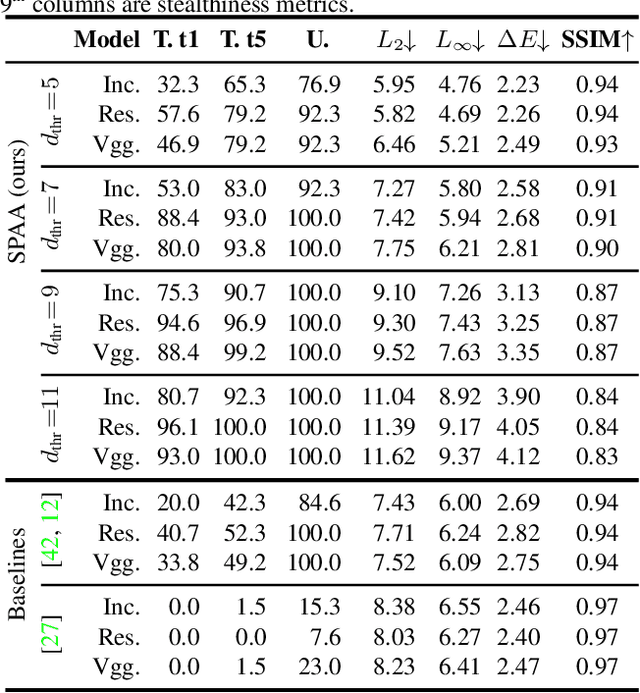

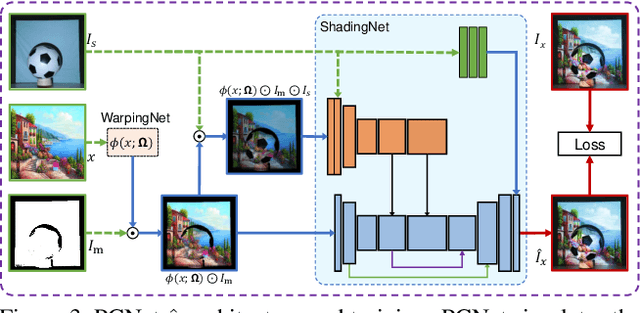
Light-based adversarial attacks aim to fool deep learning-based image classifiers by altering the physical light condition using a controllable light source, e.g., a projector. Compared with physical attacks that place carefully designed stickers or printed adversarial objects, projector-based ones obviate modifying the physical entities. Moreover, projector-based attacks can be performed transiently and dynamically by altering the projection pattern. However, existing approaches focus on projecting adversarial patterns that result in clearly perceptible camera-captured perturbations, while the more interesting yet challenging goal, stealthy projector-based attack, remains an open problem. In this paper, for the first time, we formulate this problem as an end-to-end differentiable process and propose Stealthy Projector-based Adversarial Attack (SPAA). In SPAA, we approximate the real project-and-capture operation using a deep neural network named PCNet, then we include PCNet in the optimization of projector-based attacks such that the generated adversarial projection is physically plausible. Finally, to generate robust and stealthy adversarial projections, we propose an optimization algorithm that uses minimum perturbation and adversarial confidence thresholds to alternate between the adversarial loss and stealthiness loss optimization. Our experimental evaluations show that the proposed SPAA clearly outperforms other methods by achieving higher attack success rates and meanwhile being stealthier.
Graph-based Generative Face Anonymisation with Pose Preservation
Dec 10, 2021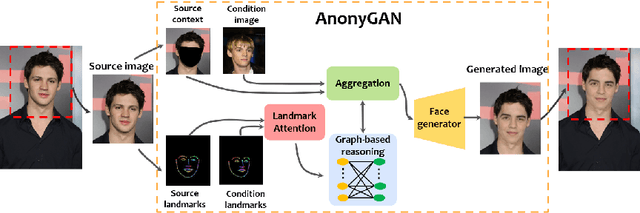
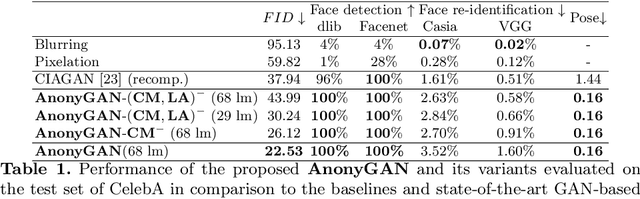
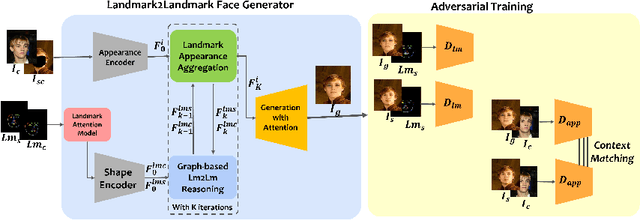
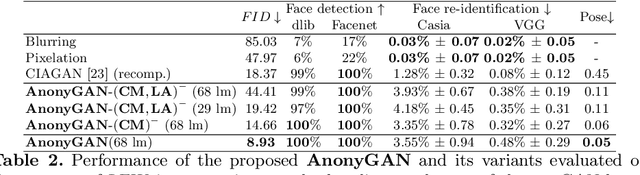
We propose AnonyGAN, a GAN-based solution for face anonymisation which replaces the visual information corresponding to a source identity with a condition identity provided as any single image. With the goal to maintain the geometric attributes of the source face, i.e., the facial pose and expression, and to promote more natural face generation, we propose to exploit a Bipartite Graph to explicitly model the relations between the facial landmarks of the source identity and the ones of the condition identity through a deep model. We further propose a landmark attention model to relax the manual selection of facial landmarks, allowing the network to weight the landmarks for the best visual naturalness and pose preservation. Finally, to facilitate the appearance learning, we propose a hybrid training strategy to address the challenge caused by the lack of direct pixel-level supervision. We evaluate our method and its variants on two public datasets, CelebA and LFW, in terms of visual naturalness, facial pose preservation and of its impacts on face detection and re-identification. We prove that AnonyGAN significantly outperforms the state-of-the-art methods in terms of visual naturalness, face detection and pose preservation.
Optimized 2D CA-CFAR for Drone-Mounted Radar Signal Processing Using Integral Image Algorithm
Dec 21, 2020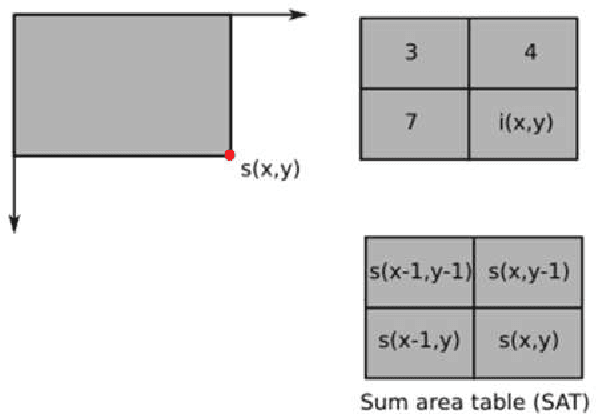
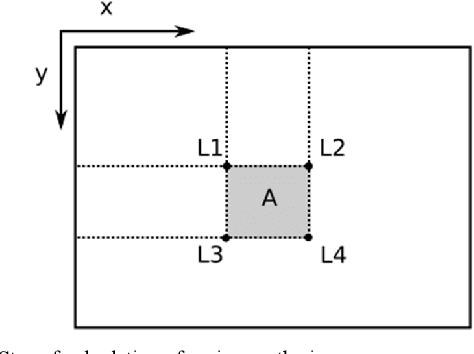
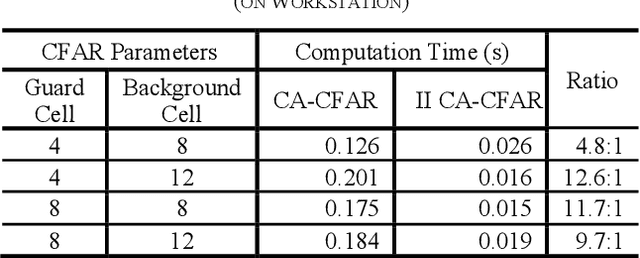

Buried survivor detection in the post-disaster environment by employing radar as sensor is an appealing approach. However, the implementation in the real field is challenging especially for large observation missions. Mounting the radar on the flying drone is the most promising solution. In this case, since the limitations of drones such as low computer specification and limited power resources, an efficient radar data processing is crucially required. Hence, this paper study about the implementation of the integral image technique to optimize the computation of the signal processing step of ultra-wideband impulse radar signatures. The evaluation was held on the single board computer mounted on the developed multisensory drone. The results confirm that the developed method can relatively reduce the data processing time.
Force-in-domain GAN inversion
Jul 14, 2021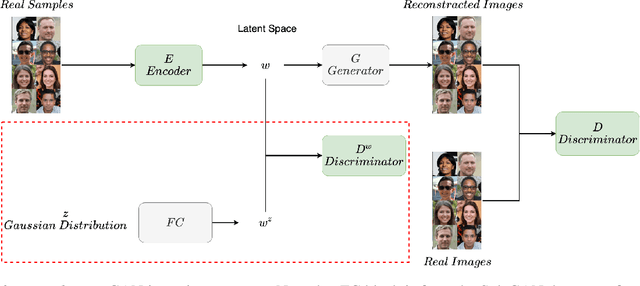
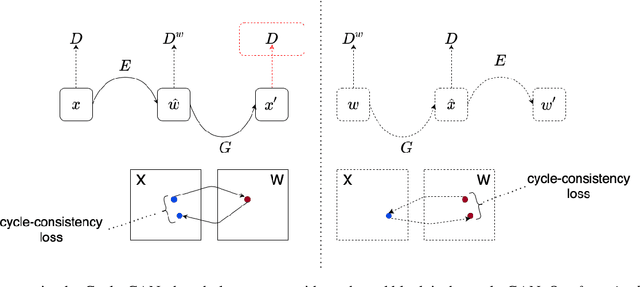

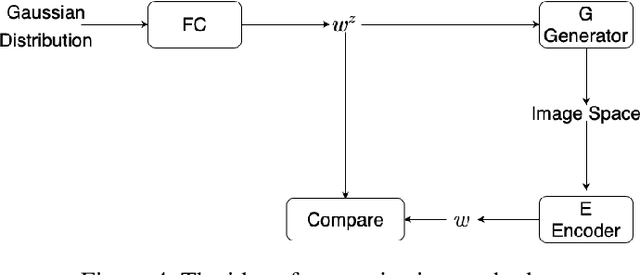
Empirical works suggest that various semantics emerge in the latent space of Generative Adversarial Networks (GANs) when being trained to generate images. To perform real image editing, it requires an accurate mapping from the real image to the latent space to leveraging these learned semantics, which is important yet difficult. An in-domain GAN inversion approach is recently proposed to constraint the inverted code within the latent space by forcing the reconstructed image obtained from the inverted code within the real image space. Empirically, we find that the inverted code by the in-domain GAN can deviate from the latent space significantly. To solve this problem, we propose a force-in-domain GAN based on the in-domain GAN, which utilizes a discriminator to force the inverted code within the latent space. The force-in-domain GAN can also be interpreted by a cycle-GAN with slight modification. Extensive experiments show that our force-in-domain GAN not only reconstructs the target image at the pixel level, but also align the inverted code with the latent space well for semantic editing.
Microscopy Image Restoration using Deep Learning on W2S
Apr 22, 2020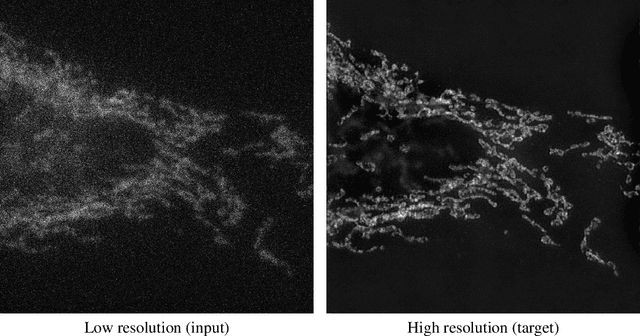

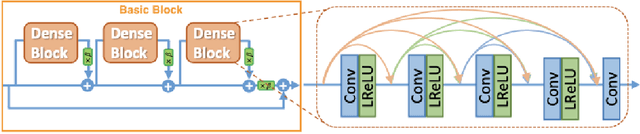
We leverage deep learning techniques to jointly denoise and super-resolve biomedical images acquired with fluorescence microscopy. We develop a deep learning algorithm based on the networks and method described in the recent W2S paper to solve a joint denoising and super-resolution problem. Specifically, we address the restoration of SIM images from widefield images. Our TensorFlow model is trained on the W2S dataset of cell images and is made accessible online in this repository: https://github.com/mchatton/w2s-tensorflow. On test images, the model shows a visually-convincing denoising and increases the resolution by a factor of two compared to the input image. For a 512 $\times$ 512 image, the inference takes less than 1 second on a Titan X GPU and about 15 seconds on a common CPU. We further present the results of different variations of losses used in training.
StarGAN v2: Diverse Image Synthesis for Multiple Domains
Dec 04, 2019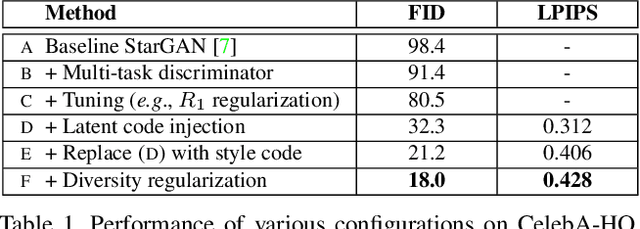
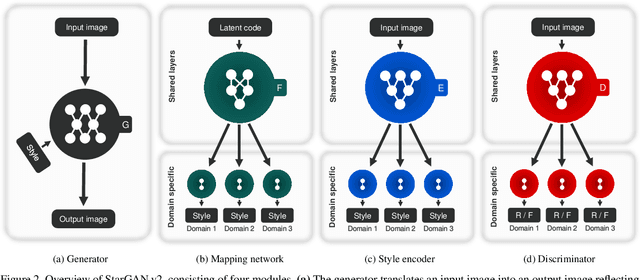
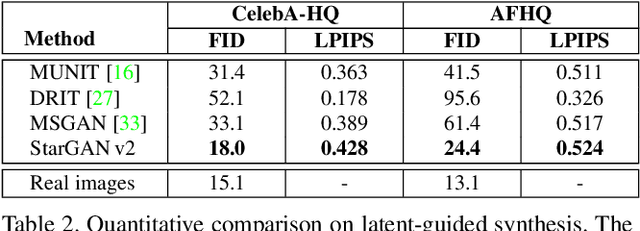
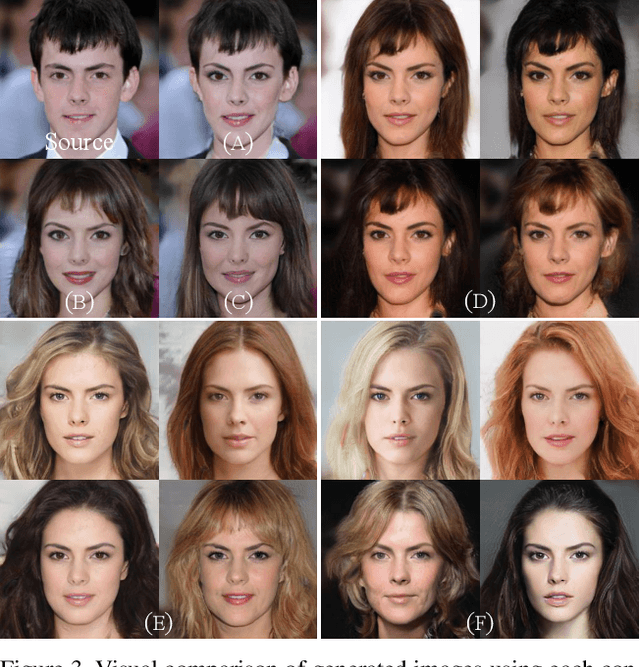
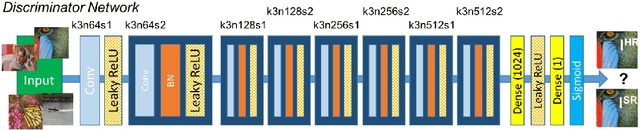
A good image-to-image translation model should learn a mapping between different visual domains while satisfying the following properties: 1) diversity of generated images and 2) scalability over multiple domains. Existing methods address either of the issues, having limited diversity or multiple models for all domains. We propose StarGAN v2, a single framework that tackles both and shows significantly improved results over the baselines. Experiments on CelebA-HQ and a new animal faces dataset (AFHQ) validate our superiority in terms of visual quality, diversity, and scalability. To better assess image-to-image translation models, we release AFHQ, high-quality animal faces with large inter- and intra-domain differences. The code, pretrained models, and dataset can be found at https://github.com/clovaai/stargan-v2.
Discriminator Synthesis: On reusing the other half of Generative Adversarial Networks
Nov 03, 2021



Generative Adversarial Networks have long since revolutionized the world of computer vision and, tied to it, the world of art. Arduous efforts have gone into fully utilizing and stabilizing training so that outputs of the Generator network have the highest possible fidelity, but little has gone into using the Discriminator after training is complete. In this work, we propose to use the latter and show a way to use the features it has learned from the training dataset to both alter an image and generate one from scratch. We name this method Discriminator Dreaming, and the full code can be found at https://github.com/PDillis/stylegan3-fun.
Adaptive Offline Quintuplet Loss for Image-Text Matching
Mar 07, 2020
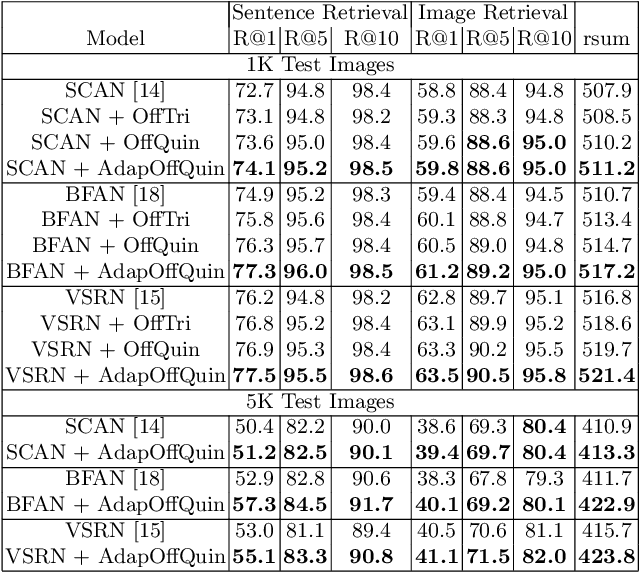
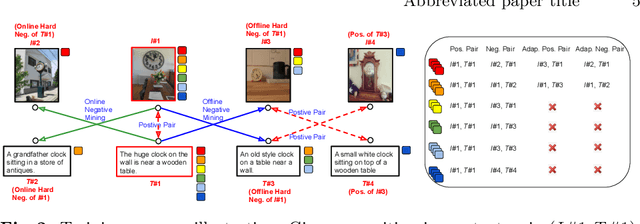
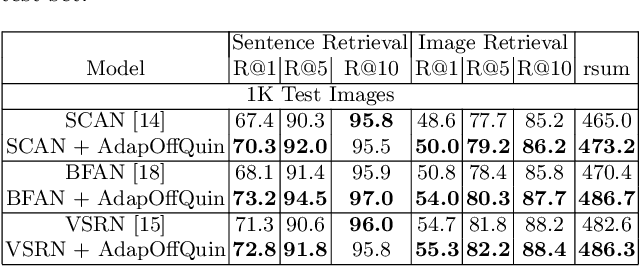
Existing image-text matching approaches typically leverage triplet loss with online hard negatives to train the model. For each image or text anchor in a training mini-batch, the model is trained to distinguish between a positive and the most confusing negative of the anchor mined from the mini-batch (i.e. online hard negative). This strategy improves the model's capacity to discover fine-grained correspondences and non-correspondences between image and text inputs. However, the above training approach has the following drawbacks: (1) the negative selection strategy still provides limited chances for the model to learn from very hard-to-distinguish cases. (2) The trained model has weak generalization capability from the training set to the testing set. (3) The penalty lacks hierarchy and adaptiveness for hard negatives with different ``hardness'' degrees. In this paper, we propose solutions by sampling negatives offline from the whole training set. It provides ``harder'' offline negatives than online hard negatives for the model to distinguish. Based on the offline hard negatives, a quintuplet loss is proposed to improve the model's generalization capability to distinguish positives and negatives. In addition, a novel loss function that combines the knowledge of positives, offline hard negatives and online hard negatives is created. It leverages offline hard negatives as intermediary to adaptively penalize them based on their distance relations to the anchor. We evaluate the proposed training approach on three state-of-the-art image-text models on the MS-COCO and Flickr30K datasets. Significant performance improvements are observed for all the models, demonstrating the effectiveness and generality of the proposed approach.