 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Universal Captioner: Long-Tail Vision-and-Language Model Training through Content-Style Separation
Nov 24, 2021
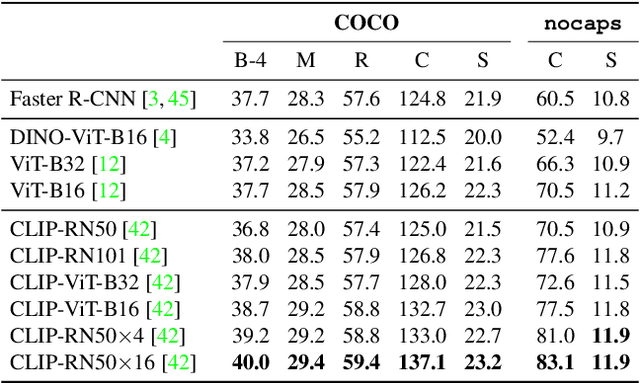

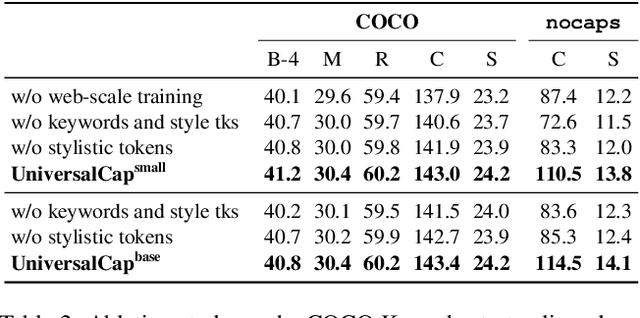
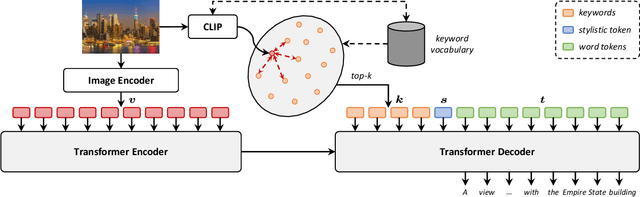
While captioning models have obtained compelling results in describing natural images, they still do not cover the entire long-tail distribution of real-world concepts. In this paper, we address the task of generating human-like descriptions with in-the-wild concepts by training on web-scale automatically collected datasets. To this end, we propose a model which can exploit noisy image-caption pairs while maintaining the descriptive style of traditional human-annotated datasets like COCO. Our model separates content from style through the usage of keywords and stylistic tokens, employing a single objective of prompt language modeling and being simpler than other recent proposals. Experimentally, our model consistently outperforms existing methods in terms of caption quality and capability of describing long-tail concepts, also in zero-shot settings. According to the CIDEr metric, we obtain a new state of the art on both COCO and nocaps when using external data.
Osteoporosis Prescreening using Panoramic Radiographs through a Deep Convolutional Neural Network with Attention Mechanism
Oct 19, 2021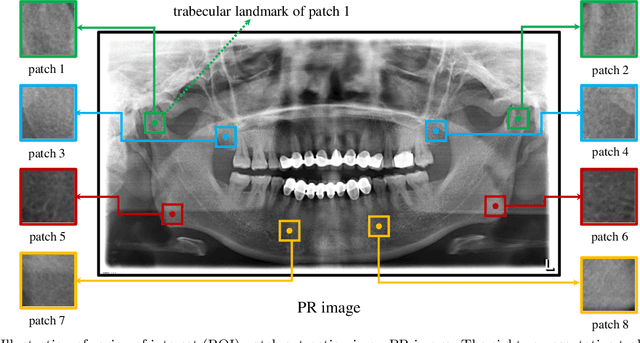
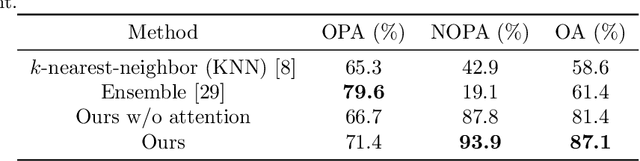
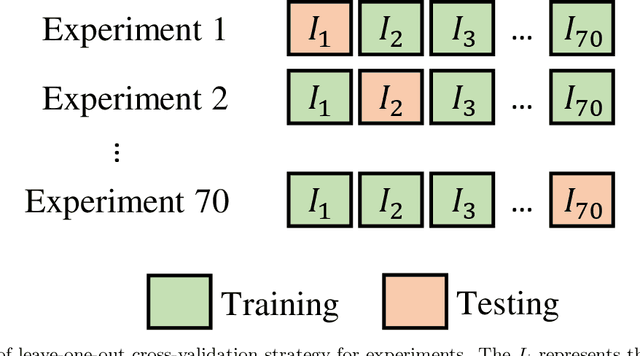
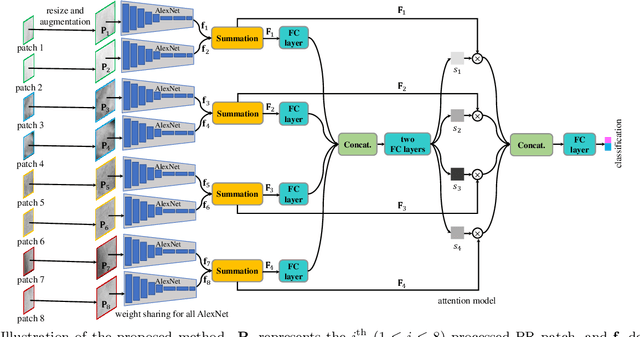
Objectives. The aim of this study was to investigate whether a deep convolutional neural network (CNN) with an attention module can detect osteoporosis on panoramic radiographs. Study Design. A dataset of 70 panoramic radiographs (PRs) from 70 different subjects of age between 49 to 60 was used, including 49 subjects with osteoporosis and 21 normal subjects. We utilized the leave-one-out cross-validation approach to generate 70 training and test splits. Specifically, for each split, one image was used for testing and the remaining 69 images were used for training. A deep convolutional neural network (CNN) using the Siamese architecture was implemented through a fine-tuning process to classify an PR image using patches extracted from eight representative trabecula bone areas (Figure 1). In order to automatically learn the importance of different PR patches, an attention module was integrated into the deep CNN. Three metrics, including osteoporosis accuracy (OPA), non-osteoporosis accuracy (NOPA) and overall accuracy (OA), were utilized for performance evaluation. Results. The proposed baseline CNN approach achieved the OPA, NOPA and OA scores of 0.667, 0.878 and 0.814, respectively. With the help of the attention module, the OPA, NOPA and OA scores were further improved to 0.714, 0.939 and 0.871, respectively. Conclusions. The proposed method obtained promising results using deep CNN with an attention module, which might be applied to osteoporosis prescreening.
Image Embedded Segmentation: Combining Supervised and Unsupervised Objectives through Generative Adversarial Networks
Jan 30, 2020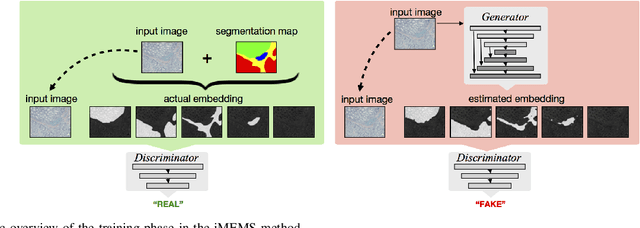
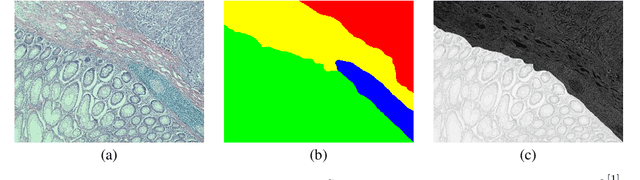

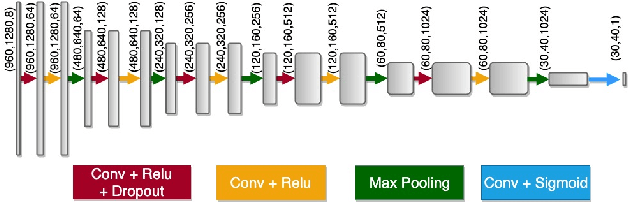
This paper presents a new regularization method to train a fully convolutional network for semantic tissue segmentation in histopathological images. This method relies on benefiting unsupervised learning, in the form of image reconstruction, for the network training. To this end, it puts forward an idea of defining a new embedding that allows uniting the main supervised task of semantic segmentation and an auxiliary unsupervised task of image reconstruction into a single task and proposes to learn this united task by a single generative model. This embedding generates a multi-channel output image by superimposing an original input image on its segmentation map. Then, the method learns to translate the input image to this embedded output image using a conditional generative adversarial network, which is known to be quite effective for image-to-image translations. This proposal is different than the existing approach that uses image reconstruction for the same regularization purpose. The existing approach considers segmentation and image reconstruction as two separate tasks in a multi-task network, defines their losses independently, and then combines these losses in a joint loss function. However, the definition of such a function requires externally determining the right contribution amounts of the supervised and unsupervised losses that yield balanced learning between the segmentation and image reconstruction tasks. The proposed approach eliminates this difficulty by uniting these two tasks into a single one, which intrinsically combines their losses. Using histopathological image segmentation as a showcase application, our experiments demonstrate that this proposed approach leads to better segmentation results.
A Dynamic Keypoints Selection Network for 6DoF Pose Estimation
Oct 24, 2021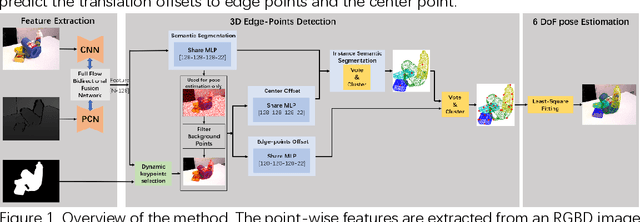
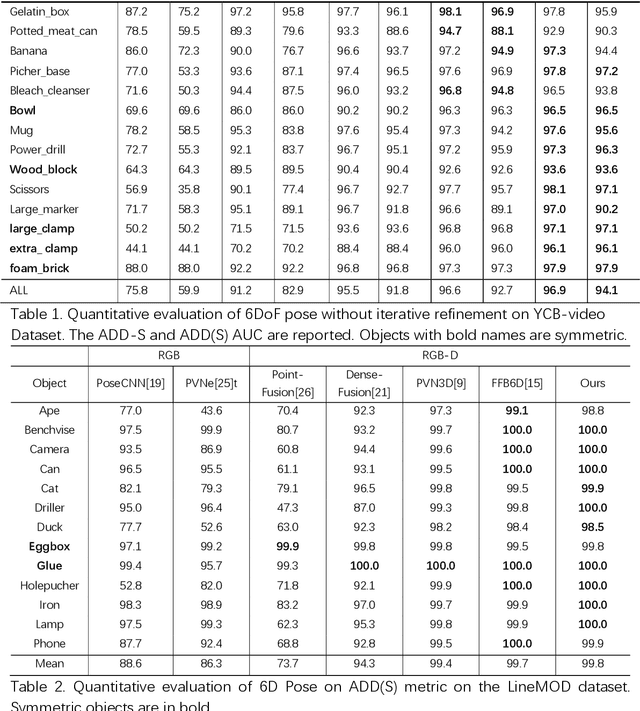


6 DoF poses estimation problem aims to estimate the rotation and translation parameters between two coordinates, such as object world coordinate and camera world coordinate. Although some advances are made with the help of deep learning, how to full use scene information is still a problem. Prior works tackle the problem by pixel-wise feature fusion but need to randomly selecte numerous points from images, which can not satisfy the demands of fast inference simultaneously and accurate pose estimation. In this work, we present a novel deep neural network based on dynamic keypoints selection designed for 6DoF pose estimation from a single RGBD image. Our network includes three parts, instance semantic segmentation, edge points detection and 6DoF pose estimation. Given an RGBD image, our network is trained to predict pixel category and the translation to edge points and center points. Then, a least-square fitting manner is applied to estimate the 6DoF pose parameters. Specifically, we propose a dynamic keypoints selection algorithm to choose keypoints from the foreground feature map. It allows us to leverage geometric and appearance information. During 6DoF pose estimation, we utilize the instance semantic segmentation result to filter out background points and only use foreground points to finish edge points detection and 6DoF pose estimation. Experiments on two commonly used 6DoF estimation benchmark datasets, YCB-Video and LineMoD, demonstrate that our method outperforms the state-of-the-art methods and achieves significant improvements over other same category methods time efficiency.
ADJUST: A Dictionary-Based Joint Reconstruction and Unmixing Method for Spectral Tomography
Dec 21, 2021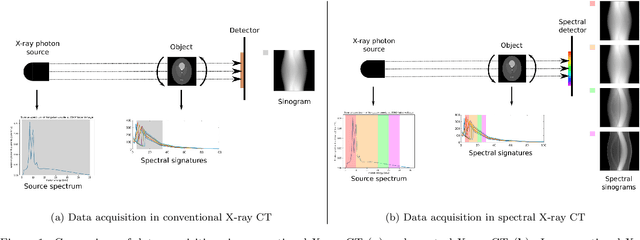
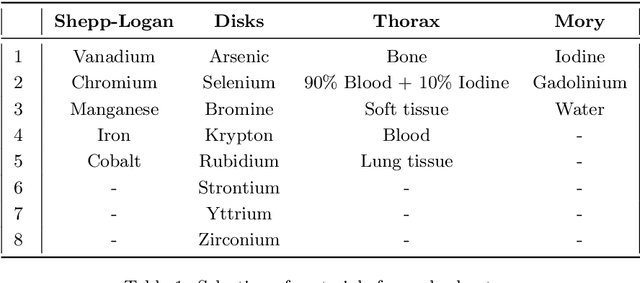
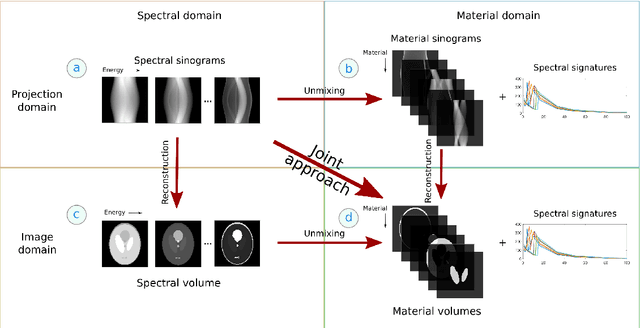
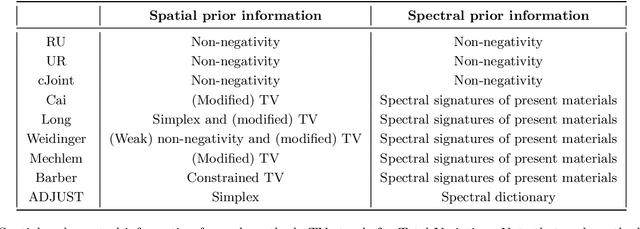
Advances in multi-spectral detectors are causing a paradigm shift in X-ray Computed Tomography (CT). Spectral information acquired from these detectors can be used to extract volumetric material composition maps of the object of interest. If the materials and their spectral responses are known a priori, the image reconstruction step is rather straightforward. If they are not known, however, the maps as well as the responses need to be estimated jointly. A conventional workflow in spectral CT involves performing volume reconstruction followed by material decomposition, or vice versa. However, these methods inherently suffer from the ill-posedness of the joint reconstruction problem. To resolve this issue, we propose `A Dictionary-based Joint reconstruction and Unmixing method for Spectral Tomography' (ADJUST). Our formulation relies on forming a dictionary of spectral signatures of materials common in CT and prior knowledge of the number of materials present in an object. In particular, we decompose the spectral volume linearly in terms of spatial material maps, a spectral dictionary, and the indicator of materials for the dictionary elements. We propose a memory-efficient accelerated alternating proximal gradient method to find an approximate solution to the resulting bi-convex problem. From numerical demonstrations on several synthetic phantoms, we observe that ADJUST performs exceedingly well when compared to other state-of-the-art methods. Additionally, we address the robustness of ADJUST against limited measurement patterns.
StarGAN v2: Diverse Image Synthesis for Multiple Domains
Dec 04, 2019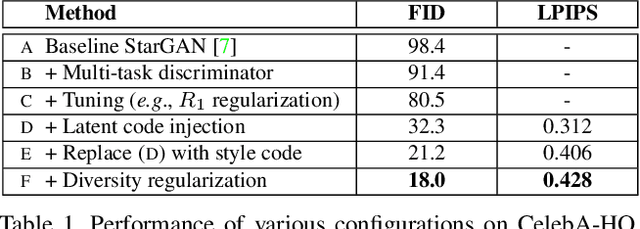
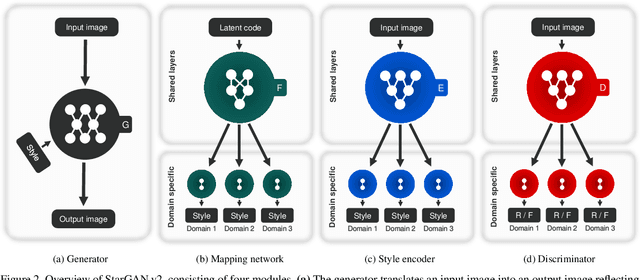
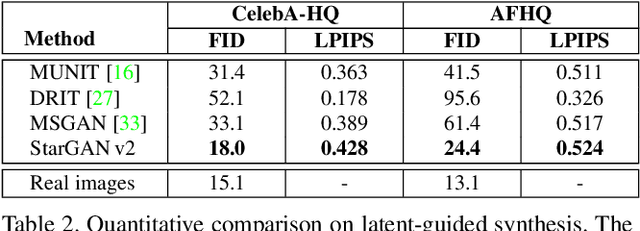
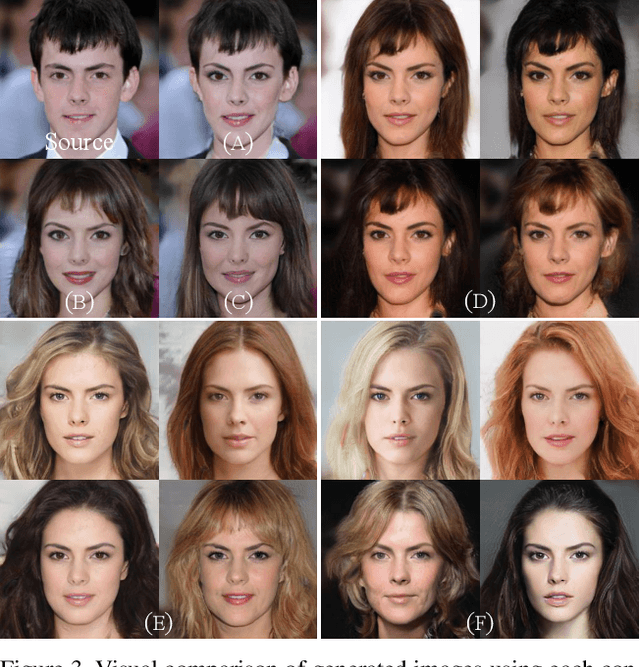
A good image-to-image translation model should learn a mapping between different visual domains while satisfying the following properties: 1) diversity of generated images and 2) scalability over multiple domains. Existing methods address either of the issues, having limited diversity or multiple models for all domains. We propose StarGAN v2, a single framework that tackles both and shows significantly improved results over the baselines. Experiments on CelebA-HQ and a new animal faces dataset (AFHQ) validate our superiority in terms of visual quality, diversity, and scalability. To better assess image-to-image translation models, we release AFHQ, high-quality animal faces with large inter- and intra-domain differences. The code, pretrained models, and dataset can be found at https://github.com/clovaai/stargan-v2.
Radial Intersection Count Image: a Clutter Resistant 3D Shape Descriptor
Jul 05, 2020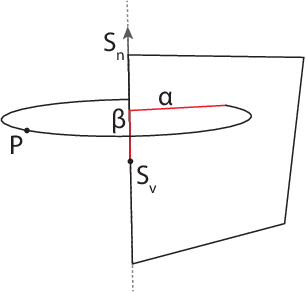

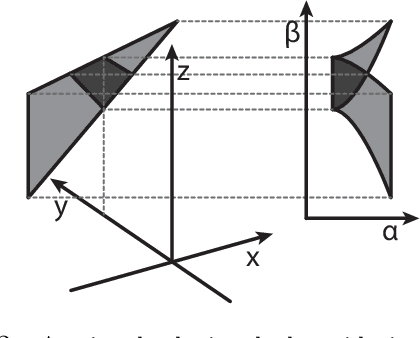
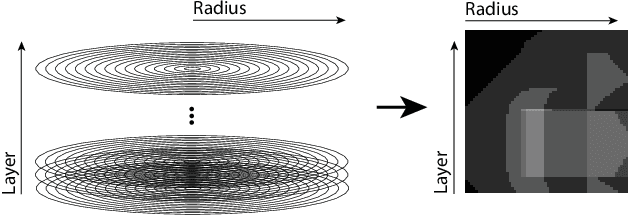
A novel shape descriptor for cluttered scenes is presented, the Radial Intersection Count Image (RICI), and is shown to significantly outperform the classic Spin Image (SI) and 3D Shape Context (3DSC) in both uncluttered and, more significantly, cluttered scenes. It is also faster to compute and compare. The clutter resistance of the RICI is mainly due to the design of a novel distance function, capable of disregarding clutter to a great extent. As opposed to the SI and 3DSC, which both count point samples, the RICI uses intersection counts with the mesh surface, and is therefore noise-free. For efficient RICI construction, novel algorithms of general interest were developed. These include an efficient circle-triangle intersection algorithm and an algorithm for projecting a point into SI-like ($\alpha$, $\beta$) coordinates. The 'clutterbox experiment' is also introduced as a better way of evaluating descriptors' response to clutter. The SI, 3DSC, and RICI are evaluated in this framework and the advantage of the RICI is clearly demonstrated.
MixNMatch: Multifactor Disentanglement and Encodingfor Conditional Image Generation
Nov 26, 2019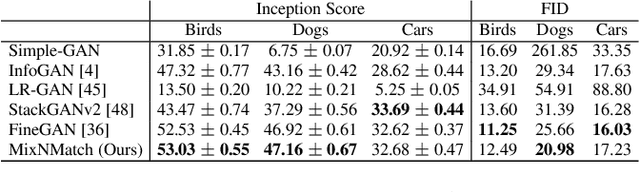

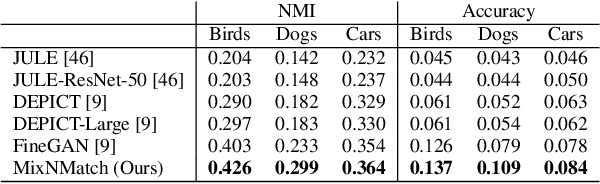

We present MixNMatch, a conditional generative model that learns to disentangle and encode background, object pose, shape, and texture from real images with minimal supervision, for mix-and-match image generation. We build upon FineGAN, an unconditional generative model, to learn the desired disentanglement and image generator, and leverage adversarial joint image-code distribution matching to learn the latent factor encoders. MixNMatch requires bounding boxes during training to model background, but requires no other supervision. Through extensive experiments, we demonstrate MixNMatch's ability to accurately disentangle, encode, and combine multiple factors for mix-and-match image generation, including sketch2color, cartoon2img, and img2gif applications. Our code/models/demo can be found at https://github.com/Yuheng-Li/MixNMatch
Controlled Caption Generation for Images Through Adversarial Attacks
Jul 07, 2021

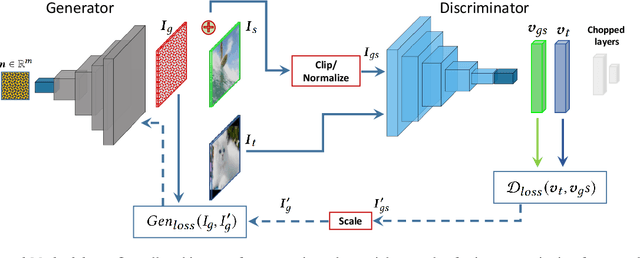
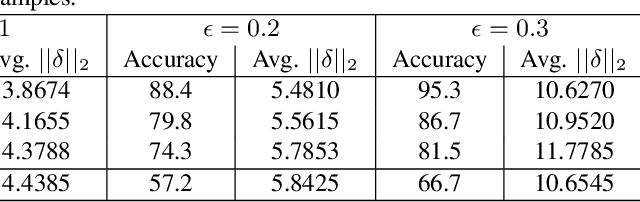
Deep learning is found to be vulnerable to adversarial examples. However, its adversarial susceptibility in image caption generation is under-explored. We study adversarial examples for vision and language models, which typically adopt an encoder-decoder framework consisting of two major components: a Convolutional Neural Network (i.e., CNN) for image feature extraction and a Recurrent Neural Network (RNN) for caption generation. In particular, we investigate attacks on the visual encoder's hidden layer that is fed to the subsequent recurrent network. The existing methods either attack the classification layer of the visual encoder or they back-propagate the gradients from the language model. In contrast, we propose a GAN-based algorithm for crafting adversarial examples for neural image captioning that mimics the internal representation of the CNN such that the resulting deep features of the input image enable a controlled incorrect caption generation through the recurrent network. Our contribution provides new insights for understanding adversarial attacks on vision systems with language component. The proposed method employs two strategies for a comprehensive evaluation. The first examines if a neural image captioning system can be misled to output targeted image captions. The second analyzes the possibility of keywords into the predicted captions. Experiments show that our algorithm can craft effective adversarial images based on the CNN hidden layers to fool captioning framework. Moreover, we discover the proposed attack to be highly transferable. Our work leads to new robustness implications for neural image captioning.
A Novel Home-Built Metrology to Analyze Oral Fluid Droplets and Quantify the Efficacy of Masks
Jan 03, 2022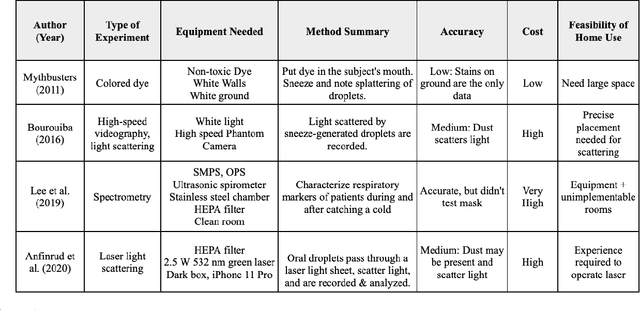
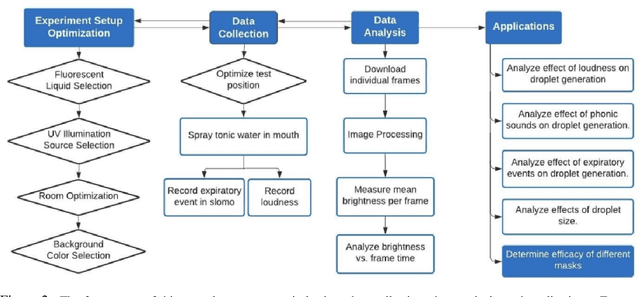


Wearing masks is crucial to preventing the spread of potentially pathogen-containing droplets, especially amidst the COVID-19 pandemic. However, not all face coverings are equally effective and most experiments evaluating mask efficacy are very expensive and complex to operate. In this work, a novel, home-built, low-cost, and accurate metrology to visualize orally-generated fluid droplets has been developed. The project includes setup optimization, data collection, data analysis, and applications. The final materials chosen were quinine-containing tonic water, 397-402 nm wavelength UV tube lights, an iPhone and tripod, string, and a spray bottle. The experiment took place in a dark closet with a dark background. During data collection, the test subject first wets their mouth with an ingestible fluorescent liquid (tonic water) and speaks, sneezes, or coughs under UV darklight. The fluorescence from the tonic water droplets generated can be visualized, recorded by an iPhone 8+ camera in slo-mo (240 fps), and analyzed. The software VLC is used for frame separation and Fiji/ImageJ is used for image processing and analysis. The dependencies of oral fluid droplet generation and propagation on different phonics, the loudness of speech, and the type of expiratory event were studied in detail and established using the metrology developed. The efficacy of different types of masks was evaluated and correlated with fabric microstructures. All masks blocked droplets to varying extent. Masks with smaller-sized pores and thicker material were found to block the most droplets. This low-cost technique can be easily constructed at home using materials that total to a cost of less than $50. Despite the minimal cost, the method is very accurate and the data is quantifiable.