 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DeepVisualInsight: Time-Travelling Visualization for Spatio-Temporal Causality of Deep Classification Training
Dec 31, 2021

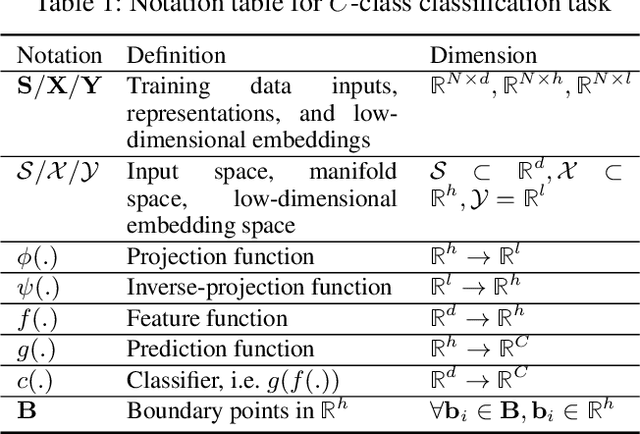
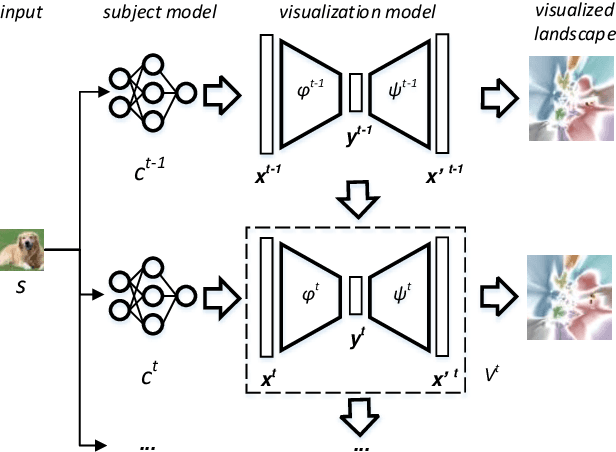
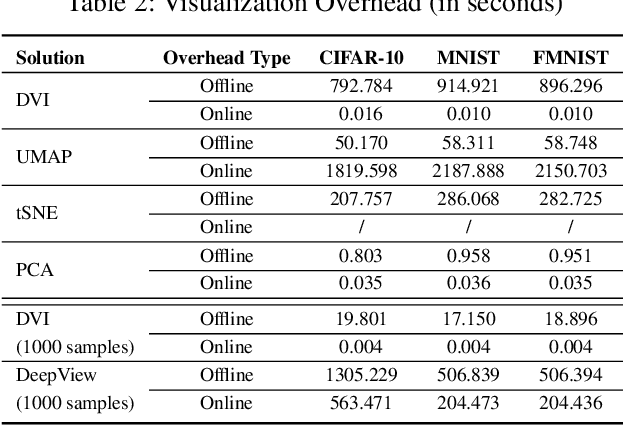
Understanding how the predictions of deep learning models are formed during the training process is crucial to improve model performance and fix model defects, especially when we need to investigate nontrivial training strategies such as active learning, and track the root cause of unexpected training results such as performance degeneration. In this work, we propose a time-travelling visual solution DeepVisualInsight (DVI), aiming to manifest the spatio-temporal causality while training a deep learning image classifier. The spatio-temporal causality demonstrates how the gradient-descent algorithm and various training data sampling techniques can influence and reshape the layout of learnt input representation and the classification boundaries in consecutive epochs. Such causality allows us to observe and analyze the whole learning process in the visible low dimensional space. Technically, we propose four spatial and temporal properties and design our visualization solution to satisfy them. These properties preserve the most important information when inverse-)projecting input samples between the visible low-dimensional and the invisible high-dimensional space, for causal analyses. Our extensive experiments show that, comparing to baseline approaches, we achieve the best visualization performance regarding the spatial/temporal properties and visualization efficiency. Moreover, our case study shows that our visual solution can well reflect the characteristics of various training scenarios, showing good potential of DVI as a debugging tool for analyzing deep learning training processes.
MiNet: A Convolutional Neural Network for Identifying and Categorising Minerals
Nov 22, 2021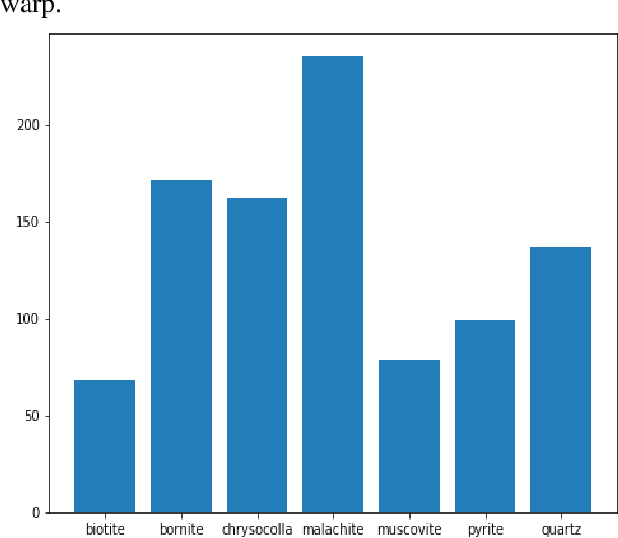
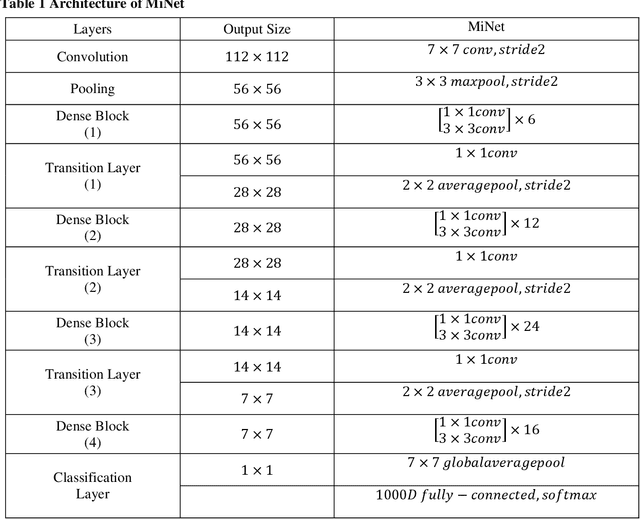
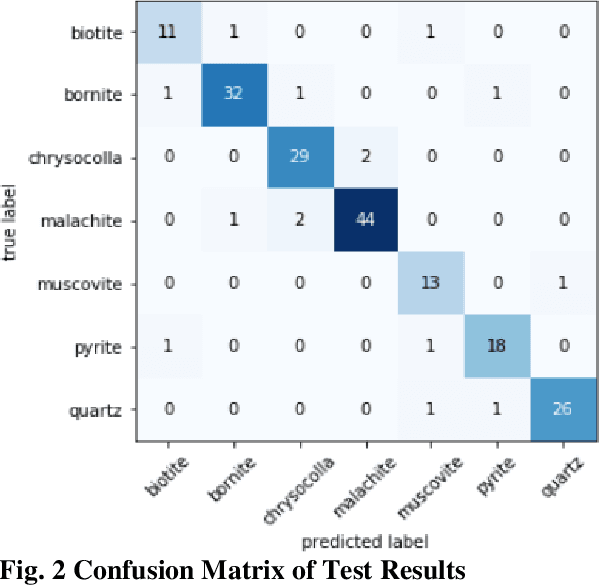
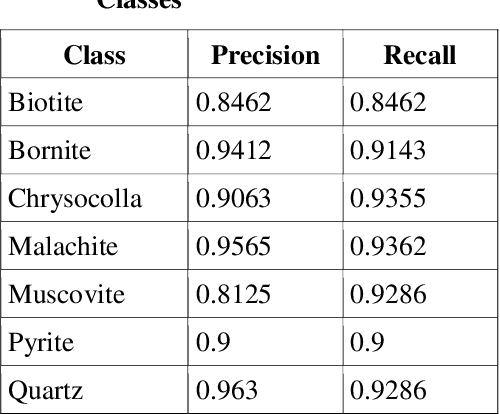
Identification of minerals in the field is a task that is wrought with many challenges. Traditional approaches are prone to errors where there is no enough experience and expertise. Several existing techniques mainly make use of features of the minerals under a microscope and tend to favour a manual feature extraction pipeline. Deep learning methods can help overcome some of these hurdles and provide simple and effective ways to identify minerals. In this paper, we present an algorithm for identifying minerals from hand specimen images. Using a Convolutional Neural Network (CNN), we develop a single-label image classification model to identify and categorise seven classes of minerals. Experiments conducted using real-world datasets show that the model achieves an accuracy of 90.75%.
Kernel-aware Raw Burst Blind Super-Resolution
Dec 14, 2021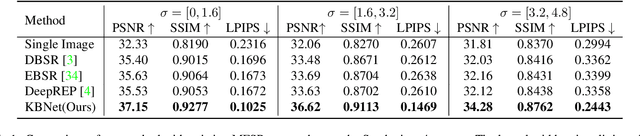
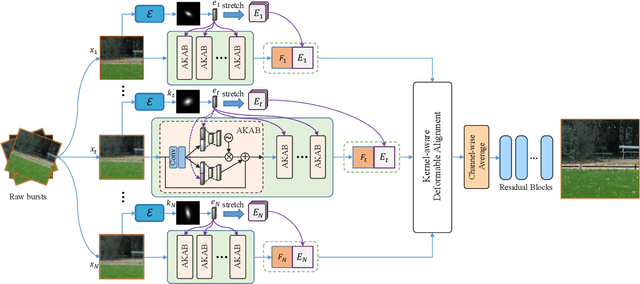
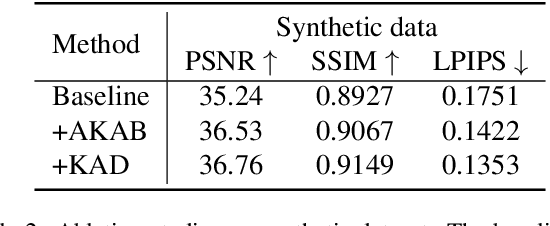
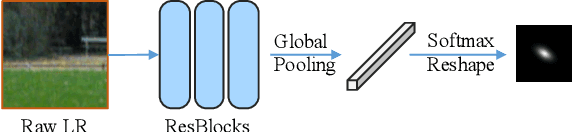
Burst super-resolution (SR) provides a possibility of restoring rich details from low-quality images. However, since low-resolution (LR) images in practical applications have multiple complicated and unknown degradations, existing non-blind (e.g., bicubic) designed networks usually lead to a severe performance drop in recovering high-resolution (HR) images. Moreover, handling multiple misaligned noisy raw inputs is also challenging. In this paper, we address the problem of reconstructing HR images from raw burst sequences acquired from modern handheld devices. The central idea is a kernel-guided strategy which can solve the burst SR with two steps: kernel modeling and HR restoring. The former estimates burst kernels from raw inputs, while the latter predicts the super-resolved image based on the estimated kernels. Furthermore, we introduce a kernel-aware deformable alignment module which can effectively align the raw images with consideration of the blurry priors. Extensive experiments on synthetic and real-world datasets demonstrate that the proposed method can perform favorable state-of-the-art performance in the burst SR problem.
Lung image segmentation by generative adversarial networks
Jul 30, 2019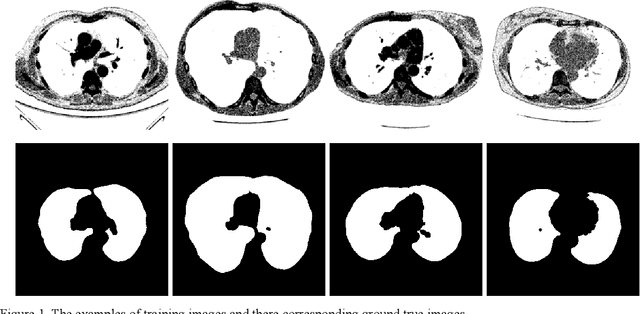
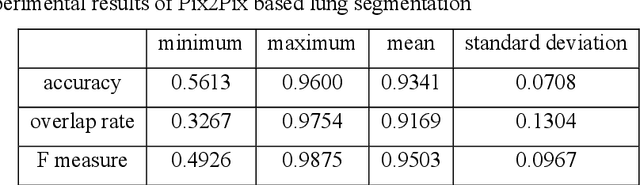
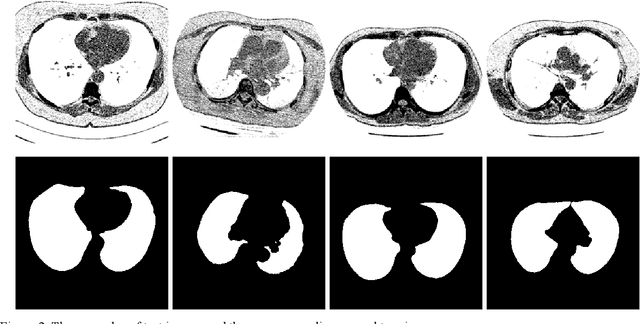

Lung image segmentation plays an important role in computer-aid pulmonary diseases diagnosis and treatment. This paper proposed a lung image segmentation method by generative adversarial networks. We employed a variety of generative adversarial networks and use its capability of image translation to perform image segmentation. The generative adversarial networks was employed to translate the original lung image to the segmented image. The generative adversarial networks based segmentation method was test on real lung image data set. Experimental results shows that the proposed method is effective and outperform state-of-the art method.
Beyond Semantic to Instance Segmentation: Weakly-Supervised Instance Segmentation via Semantic Knowledge Transfer and Self-Refinement
Sep 20, 2021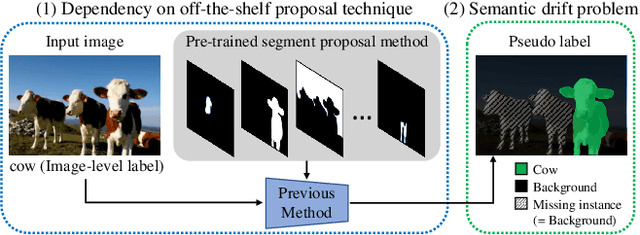
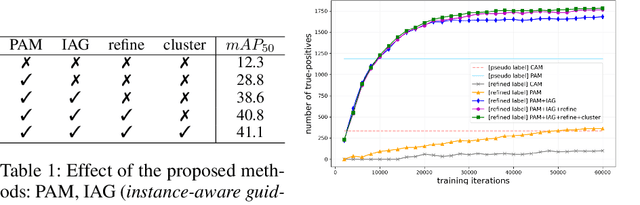
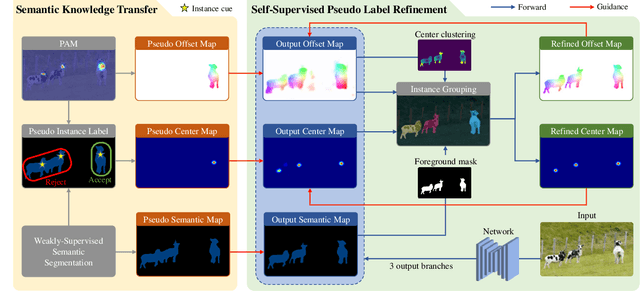
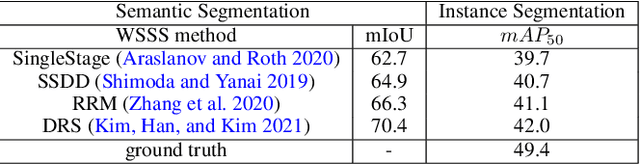
Recent weakly-supervised semantic segmentation (WSSS) has made remarkable progress due to class-wise localization techniques using image-level labels. Meanwhile, weakly-supervised instance segmentation (WSIS) is a more challenging task because instance-wise localization using only image-level labels is quite difficult. Consequently, most WSIS approaches exploit off-the-shelf proposal technique that requires pre-training with high-level labels, deviating a fully image-level supervised setting. Moreover, we focus on semantic drift problem, $i.e.,$ missing instances in pseudo instance labels are categorized as background class, occurring confusion between background and instance in training. To this end, we propose a novel approach that consists of two innovative components. First, we design a semantic knowledge transfer to obtain pseudo instance labels by transferring the knowledge of WSSS to WSIS while eliminating the need for off-the-shelf proposals. Second, we propose a self-refinement method that refines the pseudo instance labels in a self-supervised scheme and employs them to the training in an online manner while resolving the semantic drift problem. The extensive experiments demonstrate the effectiveness of our approach, and we outperform existing works on PASCAL VOC2012 without any off-the-shelf proposal techniques. Furthermore, our approach can be easily applied to the point-supervised setting, boosting the performance with an economical annotation cost. The code will be available soon.
WORD: Revisiting Organs Segmentation in the Whole Abdominal Region
Nov 03, 2021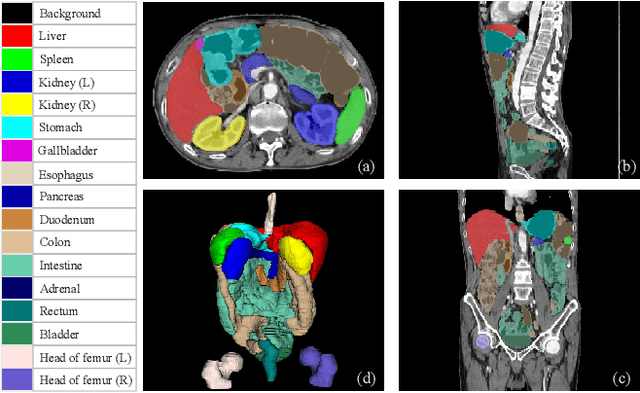
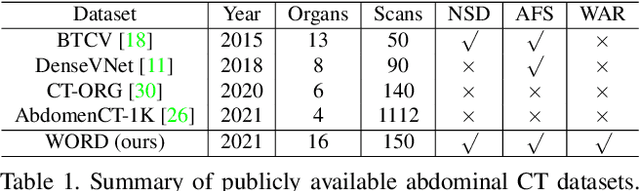
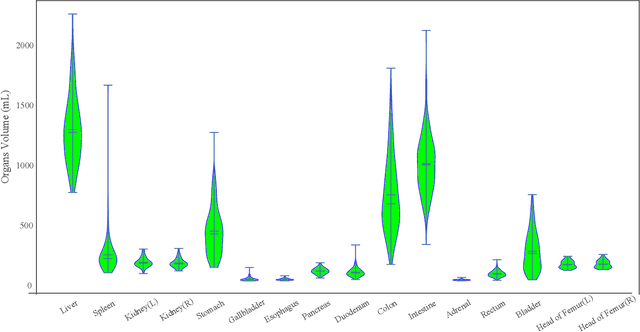

Whole abdominal organs segmentation plays an important role in abdomen lesion diagnosis, radiotherapy planning, and follow-up. However, delineating all abdominal organs by oncologists manually is time-consuming and very expensive. Recently, deep learning-based medical image segmentation has shown the potential to reduce manual delineation efforts, but it still requires a large-scale fine annotated dataset for training. Although many efforts in this task, there are still few large image datasets covering the whole abdomen region with accurate and detailed annotations for the whole abdominal organ segmentation. In this work, we establish a large-scale \textit{W}hole abdominal \textit{OR}gans \textit{D}ataset (\textit{WORD}) for algorithms research and clinical applications development. This dataset contains 150 abdominal CT volumes (30495 slices) and each volume has 16 organs with fine pixel-level annotations and scribble-based sparse annotation, which may be the largest dataset with whole abdominal organs annotation. Several state-of-the-art segmentation methods are evaluated on this dataset. And, we also invited clinical oncologists to revise the model predictions to measure the gap between the deep learning method and real oncologists. We further introduce and evaluate a new scribble-based weakly supervised segmentation on this dataset. The work provided a new benchmark for the abdominal multi-organ segmentation task and these experiments can serve as the baseline for future research and clinical application development. The codebase and dataset will be released at: https://github.com/HiLab-git/WORD
Cross-Modal Object Tracking: Modality-Aware Representations and A Unified Benchmark
Nov 08, 2021In many visual systems, visual tracking often bases on RGB image sequences, in which some targets are invalid in low-light conditions, and tracking performance is thus affected significantly. Introducing other modalities such as depth and infrared data is an effective way to handle imaging limitations of individual sources, but multi-modal imaging platforms usually require elaborate designs and cannot be applied in many real-world applications at present. Near-infrared (NIR) imaging becomes an essential part of many surveillance cameras, whose imaging is switchable between RGB and NIR based on the light intensity. These two modalities are heterogeneous with very different visual properties and thus bring big challenges for visual tracking. However, existing works have not studied this challenging problem. In this work, we address the cross-modal object tracking problem and contribute a new video dataset, including 654 cross-modal image sequences with over 481K frames in total, and the average video length is more than 735 frames. To promote the research and development of cross-modal object tracking, we propose a new algorithm, which learns the modality-aware target representation to mitigate the appearance gap between RGB and NIR modalities in the tracking process. It is plug-and-play and could thus be flexibly embedded into different tracking frameworks. Extensive experiments on the dataset are conducted, and we demonstrate the effectiveness of the proposed algorithm in two representative tracking frameworks against 17 state-of-the-art tracking methods. We will release the dataset for free academic usage, dataset download link and code will be released soon.
Weakly Supervised High-Fidelity Clothing Model Generation
Dec 14, 2021
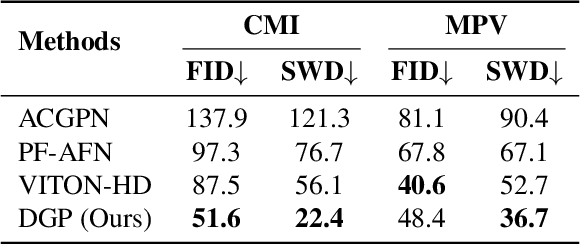
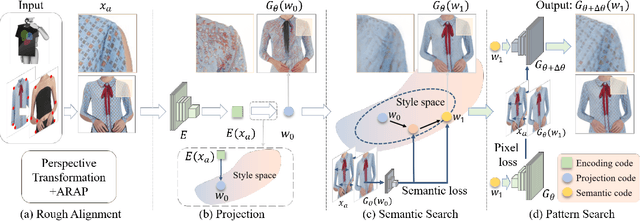

The development of online economics arouses the demand of generating images of models on product clothes, to display new clothes and promote sales. However, the expensive proprietary model images challenge the existing image virtual try-on methods in this scenario, as most of them need to be trained on considerable amounts of model images accompanied with paired clothes images. In this paper, we propose a cheap yet scalable weakly-supervised method called Deep Generative Projection (DGP) to address this specific scenario. Lying in the heart of the proposed method is to imitate the process of human predicting the wearing effect, which is an unsupervised imagination based on life experience rather than computation rules learned from supervisions. Here a pretrained StyleGAN is used to capture the practical experience of wearing. Experiments show that projecting the rough alignment of clothing and body onto the StyleGAN space can yield photo-realistic wearing results. Experiments on real scene proprietary model images demonstrate the superiority of DGP over several state-of-the-art supervised methods when generating clothing model images.
Learning Spatial Pyramid Attentive Pooling in Image Synthesis and Image-to-Image Translation
Jan 18, 2019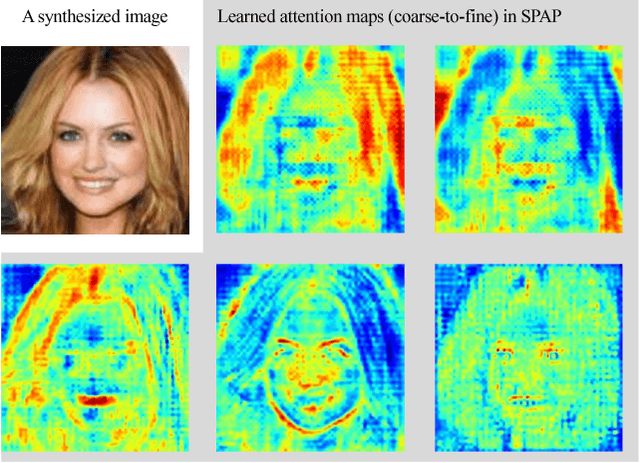
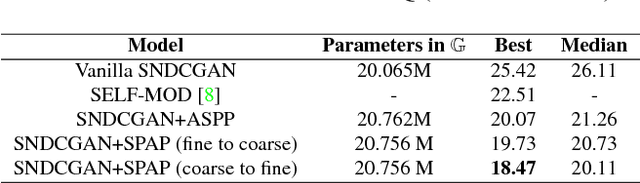
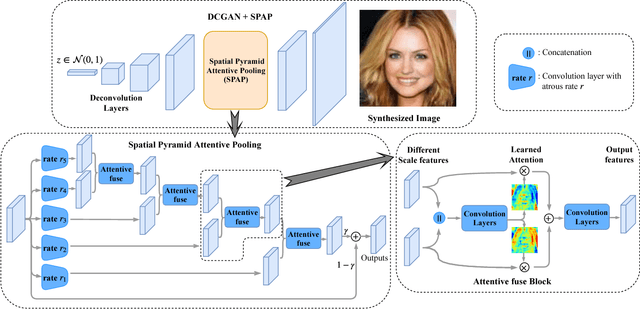
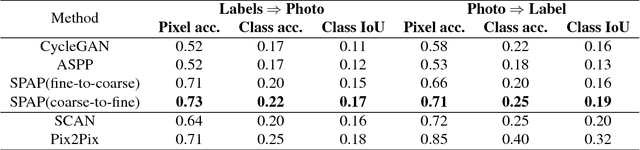
Image synthesis and image-to-image translation are two important generative learning tasks. Remarkable progress has been made by learning Generative Adversarial Networks (GANs)~\cite{goodfellow2014generative} and cycle-consistent GANs (CycleGANs)~\cite{zhu2017unpaired} respectively. This paper presents a method of learning Spatial Pyramid Attentive Pooling (SPAP) which is a novel architectural unit and can be easily integrated into both generators and discriminators in GANs and CycleGANs. The proposed SPAP integrates Atrous spatial pyramid~\cite{chen2018deeplab}, a proposed cascade attention mechanism and residual connections~\cite{he2016deep}. It leverages the advantages of the three components to facilitate effective end-to-end generative learning: (i) the capability of fusing multi-scale information by ASPP; (ii) the capability of capturing relative importance between both spatial locations (especially multi-scale context) or feature channels by attention; (iii) the capability of preserving information and enhancing optimization feasibility by residual connections. Coarse-to-fine and fine-to-coarse SPAP are studied and intriguing attention maps are observed in both tasks. In experiments, the proposed SPAP is tested in GANs on the Celeba-HQ-128 dataset~\cite{karras2017progressive}, and tested in CycleGANs on the Image-to-Image translation datasets including the Cityscape dataset~\cite{cordts2016cityscapes}, Facade and Aerial Maps dataset~\cite{zhu2017unpaired}, both obtaining better performance.
PaMIR: Parametric Model-Conditioned Implicit Representation for Image-based Human Reconstruction
Jul 08, 2020
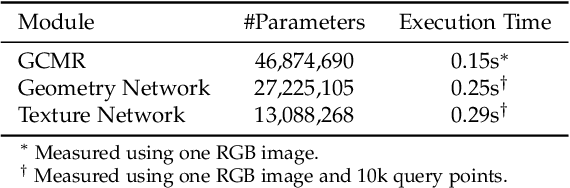
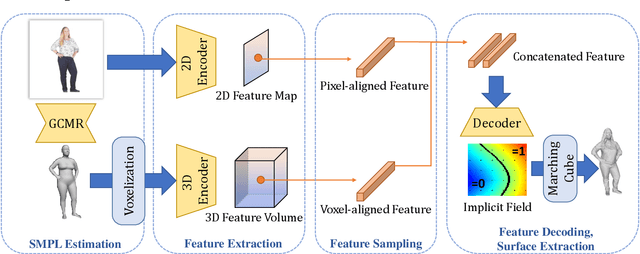
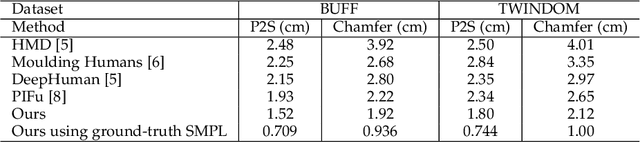
Modeling 3D humans accurately and robustly from a single image is very challenging, and the key for such an ill-posed problem is the 3D representation of the human models. To overcome the limitations of regular 3D representations, we propose Parametric Model-Conditioned Implicit Representation (PaMIR), which combines the parametric body model with the free-form deep implicit function. In our PaMIR-based reconstruction framework, a novel deep neural network is proposed to regularize the free-form deep implicit function using the semantic features of the parametric model, which improves the generalization ability under the scenarios of challenging poses and various clothing topologies. Moreover, a novel depth-ambiguity-aware training loss is further integrated to resolve depth ambiguities and enable successful surface detail reconstruction with imperfect body reference. Finally, we propose a body reference optimization method to improve the parametric model estimation accuracy and to enhance the consistency between the parametric model and the implicit function. With the PaMIR representation, our framework can be easily extended to multi-image input scenarios without the need of multi-camera calibration and pose synchronization. Experimental results demonstrate that our method achieves state-of-the-art performance for image-based 3D human reconstruction in the cases of challenging poses and clothing types.