 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SPTS: Single-Point Text Spotting
Dec 15, 2021

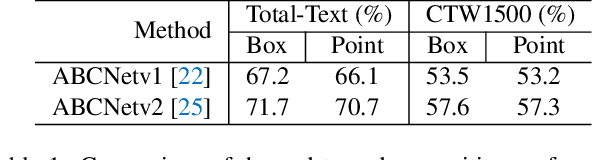

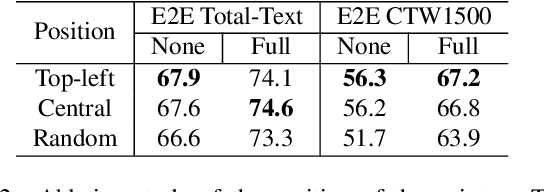
Almost all scene text spotting (detection and recognition) methods rely on costly box annotation (e.g., text-line box, word-level box, and character-level box). For the first time, we demonstrate that training scene text spotting models can be achieved with an extremely low-cost annotation of a single-point for each instance. We propose an end-to-end scene text spotting method that tackles scene text spotting as a sequence prediction task, like language modeling. Given an image as input, we formulate the desired detection and recognition results as a sequence of discrete tokens and use an auto-regressive transformer to predict the sequence. We achieve promising results on several horizontal, multi-oriented, and arbitrarily shaped scene text benchmarks. Most significantly, we show that the performance is not very sensitive to the positions of the point annotation, meaning that it can be much easier to be annotated and automatically generated than the bounding box that requires precise positions. We believe that such a pioneer attempt indicates a significant opportunity for scene text spotting applications of a much larger scale than previously possible.
Efficient Image Gallery Representations at Scale Through Multi-Task Learning
May 18, 2020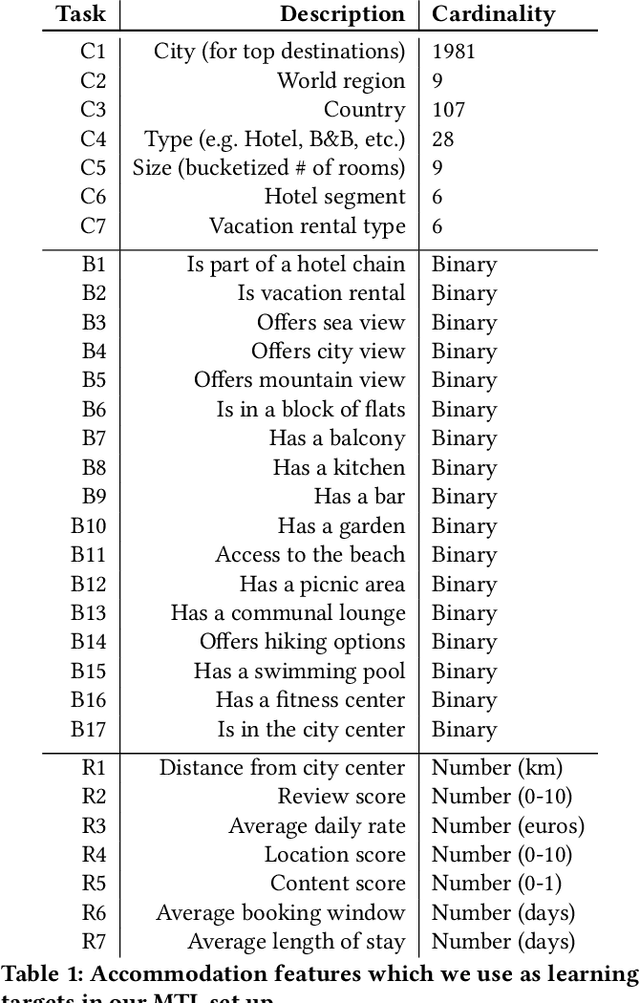

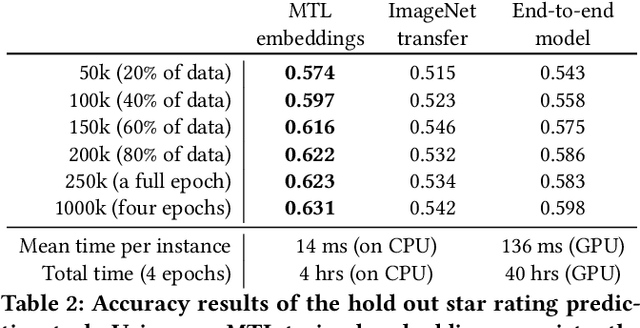
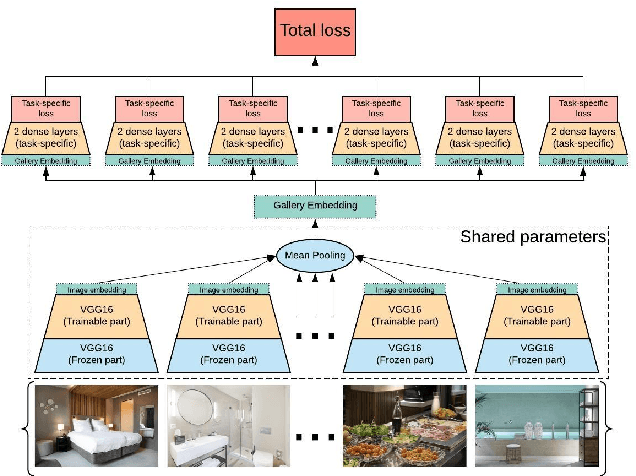
Image galleries provide a rich source of diverse information about a product which can be leveraged across many recommendation and retrieval applications. We study the problem of building a universal image gallery encoder through multi-task learning (MTL) approach and demonstrate that it is indeed a practical way to achieve generalizability of learned representations to new downstream tasks. Additionally, we analyze the relative predictive performance of MTL-trained solutions against optimal and substantially more expensive solutions, and find signals that MTL can be a useful mechanism to address sparsity in low-resource binary tasks.
Robust Depth Completion with Uncertainty-Driven Loss Functions
Dec 15, 2021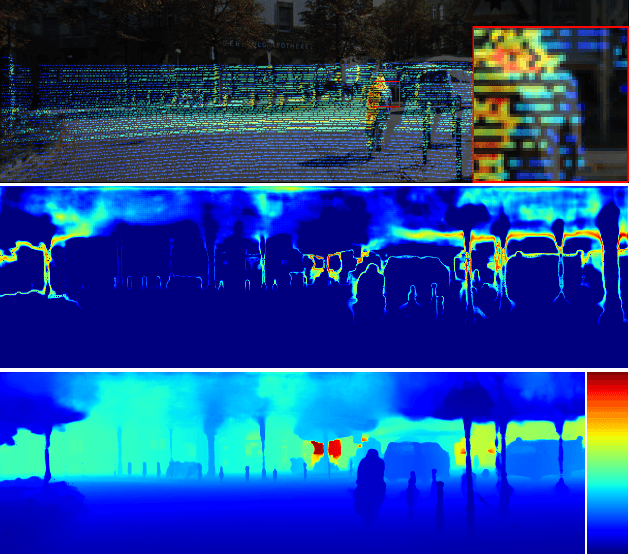
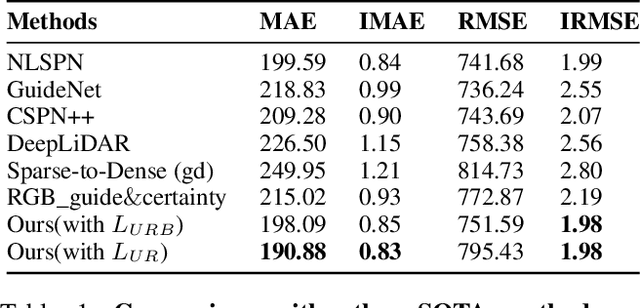
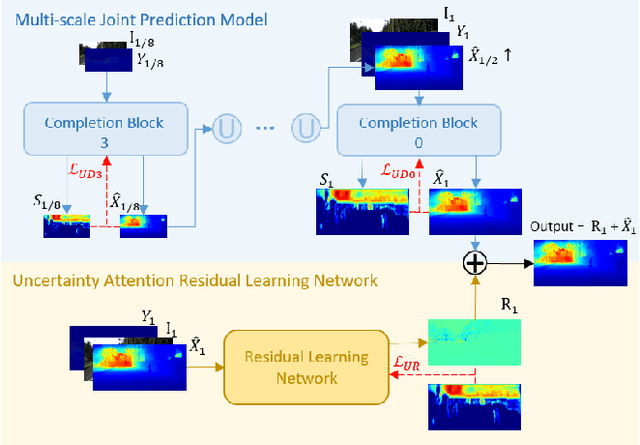
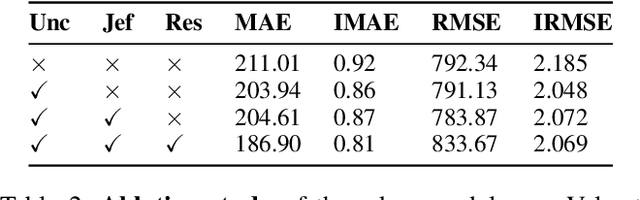
Recovering a dense depth image from sparse LiDAR scans is a challenging task. Despite the popularity of color-guided methods for sparse-to-dense depth completion, they treated pixels equally during optimization, ignoring the uneven distribution characteristics in the sparse depth map and the accumulated outliers in the synthesized ground truth. In this work, we introduce uncertainty-driven loss functions to improve the robustness of depth completion and handle the uncertainty in depth completion. Specifically, we propose an explicit uncertainty formulation for robust depth completion with Jeffrey's prior. A parametric uncertain-driven loss is introduced and translated to new loss functions that are robust to noisy or missing data. Meanwhile, we propose a multiscale joint prediction model that can simultaneously predict depth and uncertainty maps. The estimated uncertainty map is also used to perform adaptive prediction on the pixels with high uncertainty, leading to a residual map for refining the completion results. Our method has been tested on KITTI Depth Completion Benchmark and achieved the state-of-the-art robustness performance in terms of MAE, IMAE, and IRMSE metrics.
Test-Time Adaptable Neural Networks for Robust Medical Image Segmentation
Apr 10, 2020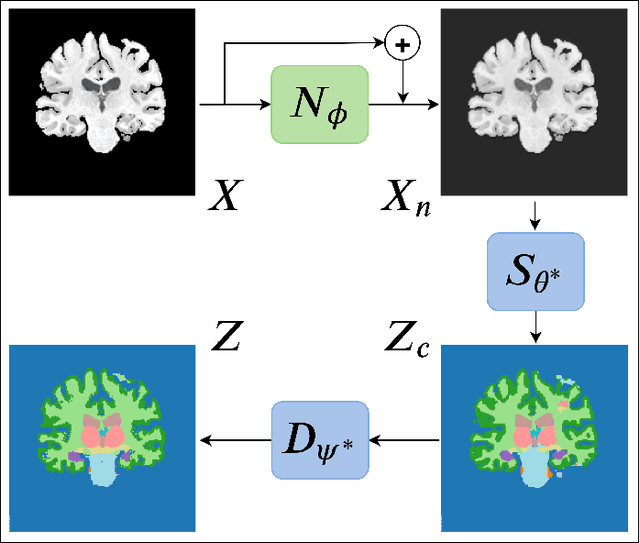
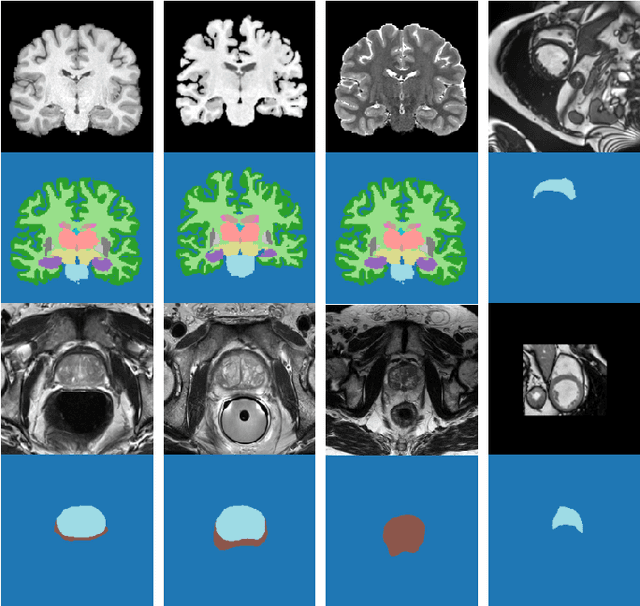
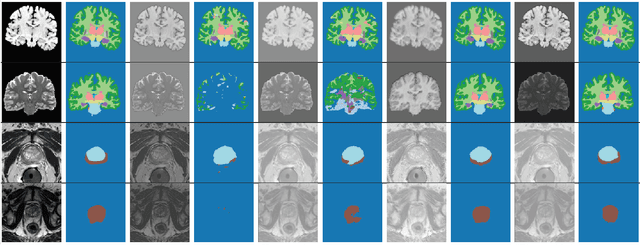
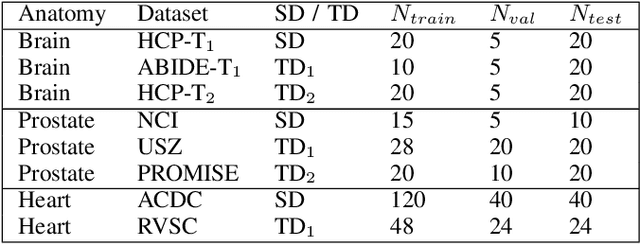
Convolutional Neural Networks (CNNs) work very well for supervised learning problems when the training dataset is representative of the variations expected to be encountered at test time. In medical image segmentation, this premise is violated when there is a mismatch between training and test images in terms of their acquisition details, such as the scanner model or the protocol. Remarkable performance degradation of CNNs in this scenario is well documented in the literature. To address this problem, we design the segmentation CNN as a concatenation of two sub-networks: a relatively shallow image normalization CNN, followed by a deep CNN that segments the normalized image. We train both these sub-networks using a training dataset, consisting of annotated images from a particular scanner and protocol setting. Now, at test time, we adapt the image normalization sub-network for each test image, guided by an implicit prior on the predicted segmentation labels. We employ an independently trained denoising autoencoder (DAE) in order to model such an implicit prior on plausible anatomical segmentation labels. We validate the proposed idea on multi-center Magnetic Resonance imaging datasets of three anatomies: brain, heart and prostate. The proposed test-time adaptation consistently provides performance improvement, demonstrating the promise and generality of the approach. Being agnostic to the architecture of the deep CNN, the second sub-network, the proposed design can be utilized with any segmentation network to increase robustness to variations in imaging scanners and protocols.
Gaze Estimation with Eye Region Segmentation and Self-Supervised Multistream Learning
Dec 15, 2021
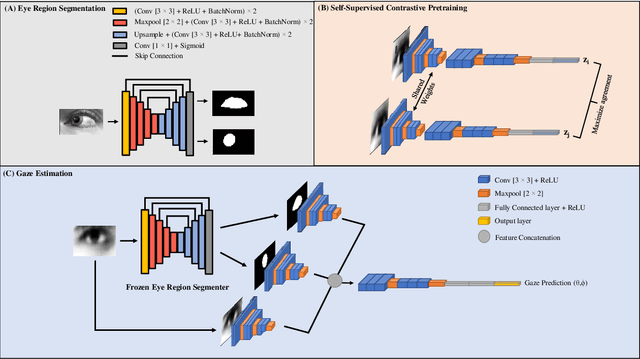


We present a novel multistream network that learns robust eye representations for gaze estimation. We first create a synthetic dataset containing eye region masks detailing the visible eyeball and iris using a simulator. We then perform eye region segmentation with a U-Net type model which we later use to generate eye region masks for real-world eye images. Next, we pretrain an eye image encoder in the real domain with self-supervised contrastive learning to learn generalized eye representations. Finally, this pretrained eye encoder, along with two additional encoders for visible eyeball region and iris, are used in parallel in our multistream framework to extract salient features for gaze estimation from real-world images. We demonstrate the performance of our method on the EYEDIAP dataset in two different evaluation settings and achieve state-of-the-art results, outperforming all the existing benchmarks on this dataset. We also conduct additional experiments to validate the robustness of our self-supervised network with respect to different amounts of labeled data used for training.
Deep Manifold Embedding for Hyperspectral Image Classification
Dec 24, 2019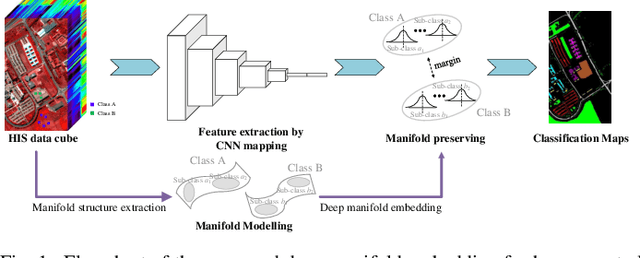

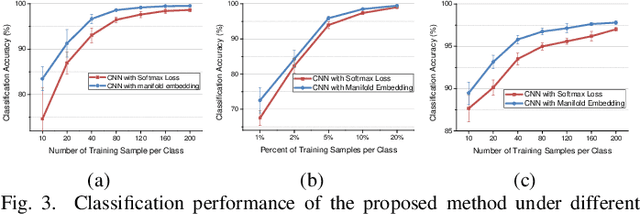
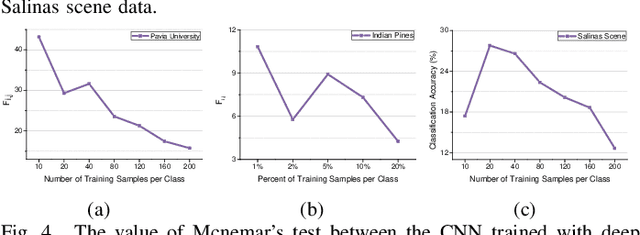
Deep learning methods have played a more and more important role in hyperspectral image classification. However, the general deep learning methods mainly take advantage of the information of sample itself or the pairwise information between samples while ignore the intrinsic data structure within the whole data. To tackle this problem, this work develops a novel deep manifold embedding method(DMEM) for hyperspectral image classification. First, each class in the image is modelled as a specific nonlinear manifold and the geodesic distance is used to measure the correlation between the samples. Then, based on the hierarchical clustering, the manifold structure of the data can be captured and each nonlinear data manifold can be divided into several sub-classes. Finally, considering the distribution of each sub-class and the correlation between different subclasses, the DMEM is constructed to preserve the estimated geodesic distances on the data manifold between the learned low dimensional features of different samples. Experiments over three real-world hyperspectral image datasets have demonstrated the effectiveness of the proposed method.
Lawin Transformer: Improving Semantic Segmentation Transformer with Multi-Scale Representations via Large Window Attention
Jan 05, 2022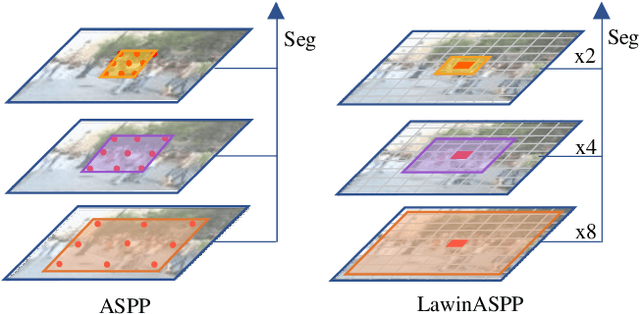
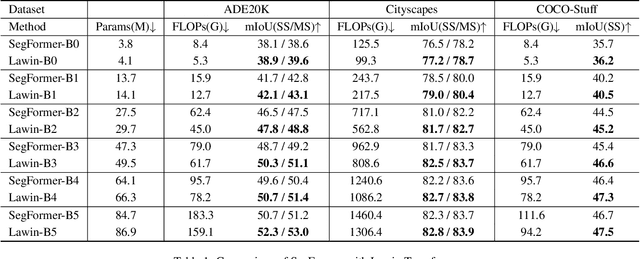
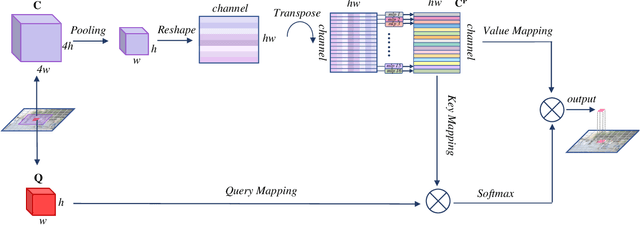
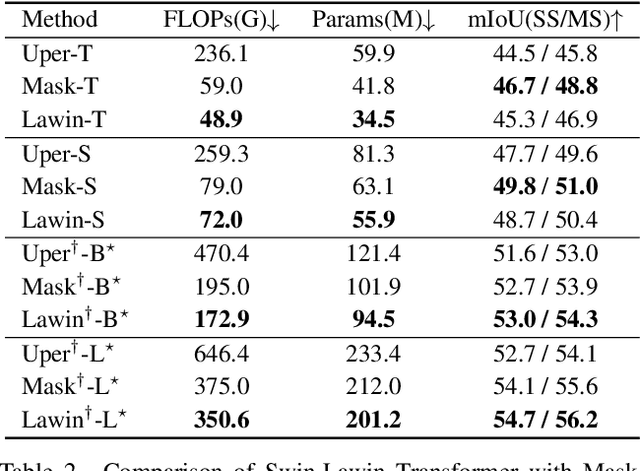
Multi-scale representations are crucial for semantic segmentation. The community has witnessed the flourish of semantic segmentation convolutional neural networks (CNN) exploiting multi-scale contextual information. Motivated by that the vision transformer (ViT) is powerful in image classification, some semantic segmentation ViTs are recently proposed, most of them attaining impressive results but at a cost of computational economy. In this paper, we succeed in introducing multi-scale representations into semantic segmentation ViT via window attention mechanism and further improves the performance and efficiency. To this end, we introduce large window attention which allows the local window to query a larger area of context window at only a little computation overhead. By regulating the ratio of the context area to the query area, we enable the large window attention to capture the contextual information at multiple scales. Moreover, the framework of spatial pyramid pooling is adopted to collaborate with the large window attention, which presents a novel decoder named large window attention spatial pyramid pooling (LawinASPP) for semantic segmentation ViT. Our resulting ViT, Lawin Transformer, is composed of an efficient hierachical vision transformer (HVT) as encoder and a LawinASPP as decoder. The empirical results demonstrate that Lawin Transformer offers an improved efficiency compared to the existing method. Lawin Transformer further sets new state-of-the-art performance on Cityscapes (84.4\% mIoU), ADE20K (56.2\% mIoU) and COCO-Stuff datasets. The code will be released at https://github.com/yan-hao-tian/lawin.
Self-Loop Uncertainty: A Novel Pseudo-Label for Semi-Supervised Medical Image Segmentation
Jul 20, 2020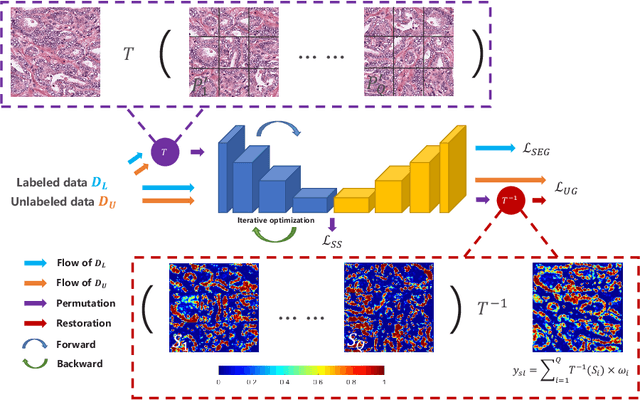

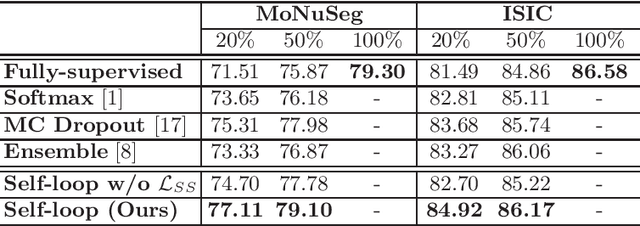
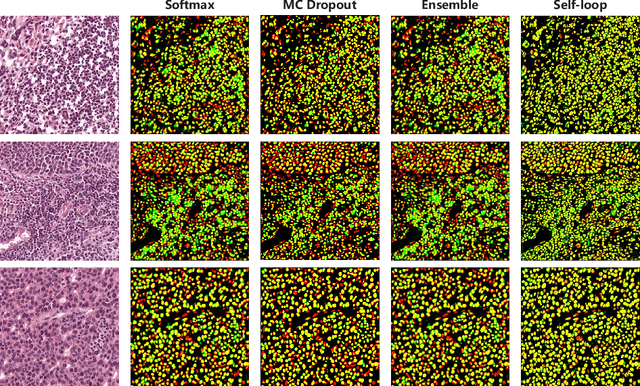
Witnessing the success of deep learning neural networks in natural image processing, an increasing number of studies have been proposed to develop deep-learning-based frameworks for medical image segmentation. However, since the pixel-wise annotation of medical images is laborious and expensive, the amount of annotated data is usually deficient to well-train a neural network. In this paper, we propose a semi-supervised approach to train neural networks with limited labeled data and a large quantity of unlabeled images for medical image segmentation. A novel pseudo-label (namely self-loop uncertainty), generated by recurrently optimizing the neural network with a self-supervised task, is adopted as the ground-truth for the unlabeled images to augment the training set and boost the segmentation accuracy. The proposed self-loop uncertainty can be seen as an approximation of the uncertainty estimation yielded by ensembling multiple models with a significant reduction of inference time. Experimental results on two publicly available datasets demonstrate the effectiveness of our semi-supervied approach.
Projective Skip-Connections for Segmentation Along a Subset of Dimensions in Retinal OCT
Aug 02, 2021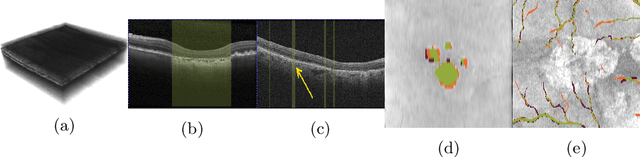
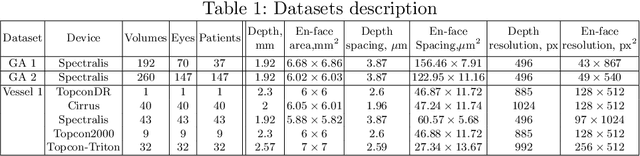
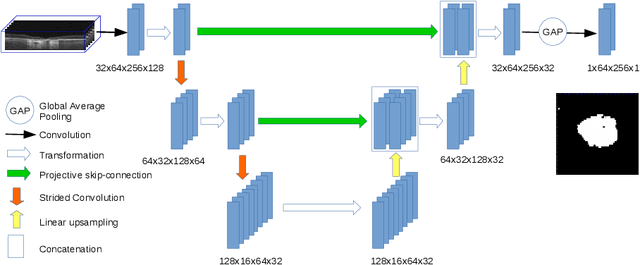
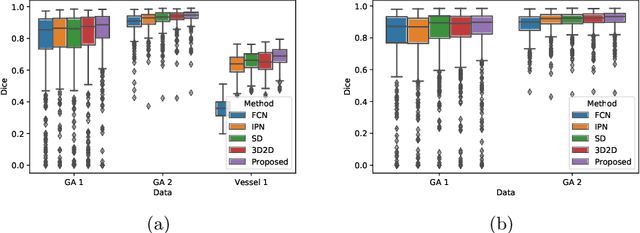
In medical imaging, there are clinically relevant segmentation tasks where the output mask is a projection to a subset of input image dimensions. In this work, we propose a novel convolutional neural network architecture that can effectively learn to produce a lower-dimensional segmentation mask than the input image. The network restores encoded representation only in a subset of input spatial dimensions and keeps the representation unchanged in the others. The newly proposed projective skip-connections allow linking the encoder and decoder in a UNet-like structure. We evaluated the proposed method on two clinically relevant tasks in retinal Optical Coherence Tomography (OCT): geographic atrophy and retinal blood vessel segmentation. The proposed method outperformed the current state-of-the-art approaches on all the OCT datasets used, consisting of 3D volumes and corresponding 2D en-face masks. The proposed architecture fills the methodological gap between image classification and ND image segmentation.
Causal Explanations of Image Misclassifications
Jun 28, 2020

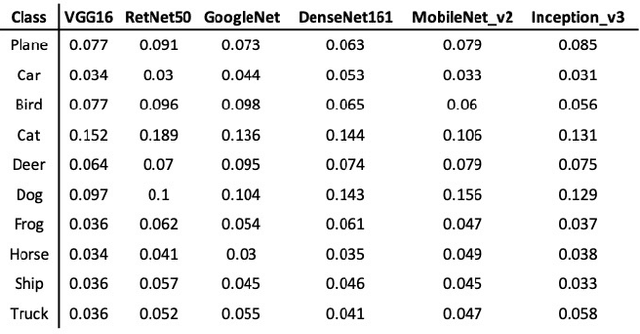
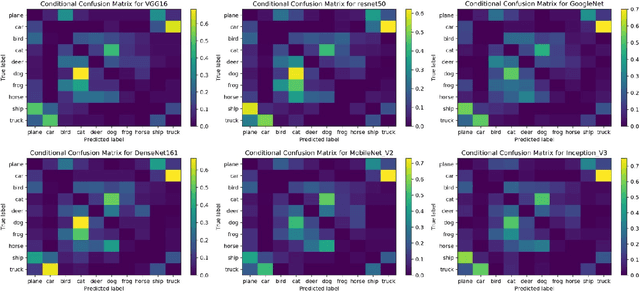
The causal explanation of image misclassifications is an understudied niche, which can potentially provide valuable insights in model interpretability and increase prediction accuracy. This study trains CIFAR-10 on six modern CNN architectures, including VGG16, ResNet50, GoogLeNet, DenseNet161, MobileNet V2, and Inception V3, and explores the misclassification patterns using conditional confusion matrices and misclassification networks. Two causes are identified and qualitatively distinguished: morphological similarity and non-essential information interference. The former cause is not model dependent, whereas the latter is inconsistent across all six models. To reduce the misclassifications caused by non-essential information interference, this study erases the pixels within the bonding boxes anchored at the top 5% pixels of the saliency map. This method first verifies the cause; then by directly modifying the cause it reduces the misclassification. Future studies will focus on quantitatively differentiating the two causes of misclassifications, generalizing the anchor-box based inference modification method to reduce misclassification, exploring the interactions of the two causes in misclassifications.