 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Test-Time Adaptable Neural Networks for Robust Medical Image Segmentation
Apr 10, 2020
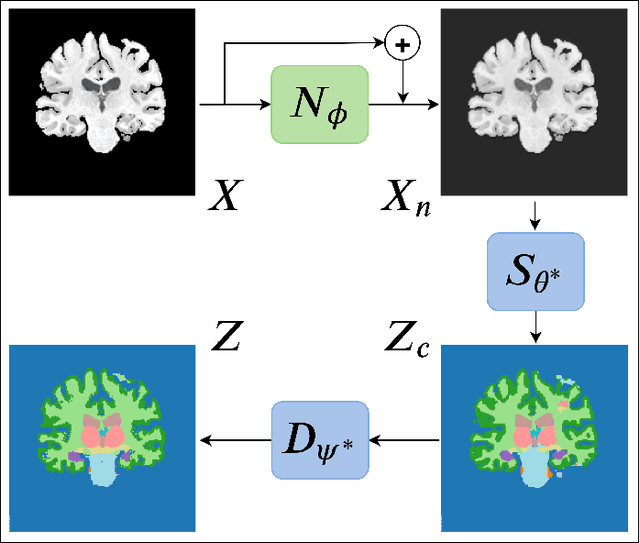
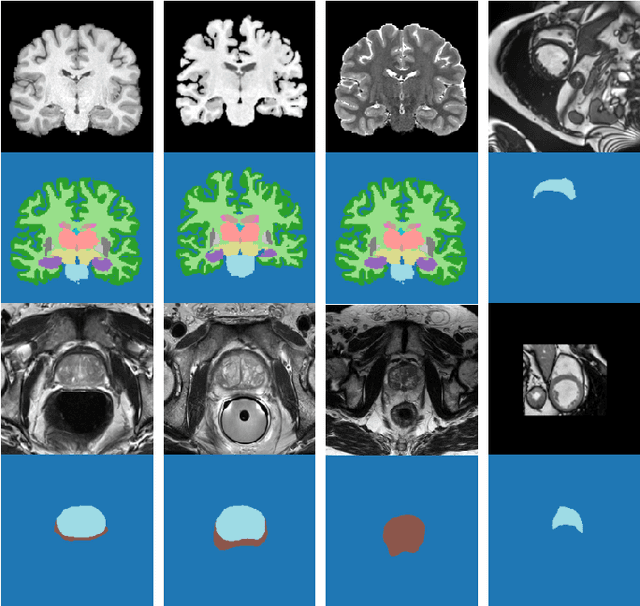
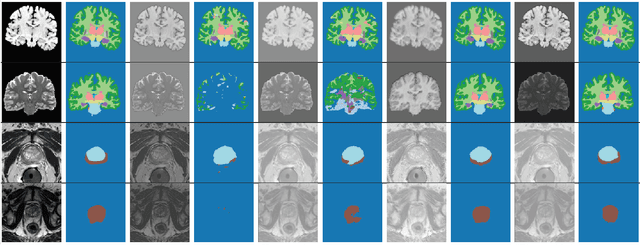
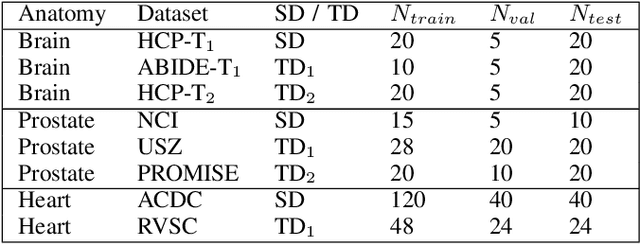
Convolutional Neural Networks (CNNs) work very well for supervised learning problems when the training dataset is representative of the variations expected to be encountered at test time. In medical image segmentation, this premise is violated when there is a mismatch between training and test images in terms of their acquisition details, such as the scanner model or the protocol. Remarkable performance degradation of CNNs in this scenario is well documented in the literature. To address this problem, we design the segmentation CNN as a concatenation of two sub-networks: a relatively shallow image normalization CNN, followed by a deep CNN that segments the normalized image. We train both these sub-networks using a training dataset, consisting of annotated images from a particular scanner and protocol setting. Now, at test time, we adapt the image normalization sub-network for each test image, guided by an implicit prior on the predicted segmentation labels. We employ an independently trained denoising autoencoder (DAE) in order to model such an implicit prior on plausible anatomical segmentation labels. We validate the proposed idea on multi-center Magnetic Resonance imaging datasets of three anatomies: brain, heart and prostate. The proposed test-time adaptation consistently provides performance improvement, demonstrating the promise and generality of the approach. Being agnostic to the architecture of the deep CNN, the second sub-network, the proposed design can be utilized with any segmentation network to increase robustness to variations in imaging scanners and protocols.
Update in Unit Gradient
Oct 01, 2021
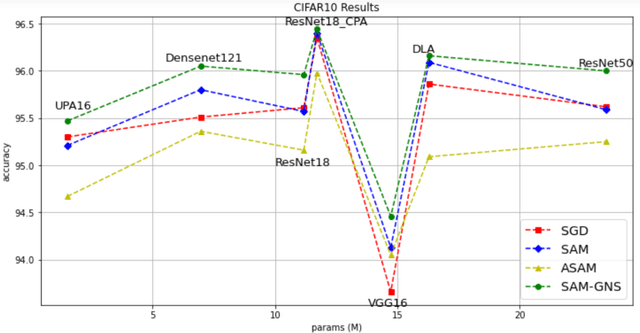
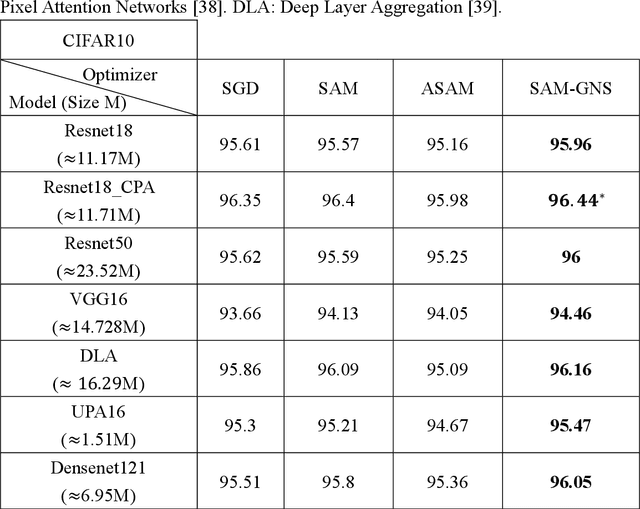
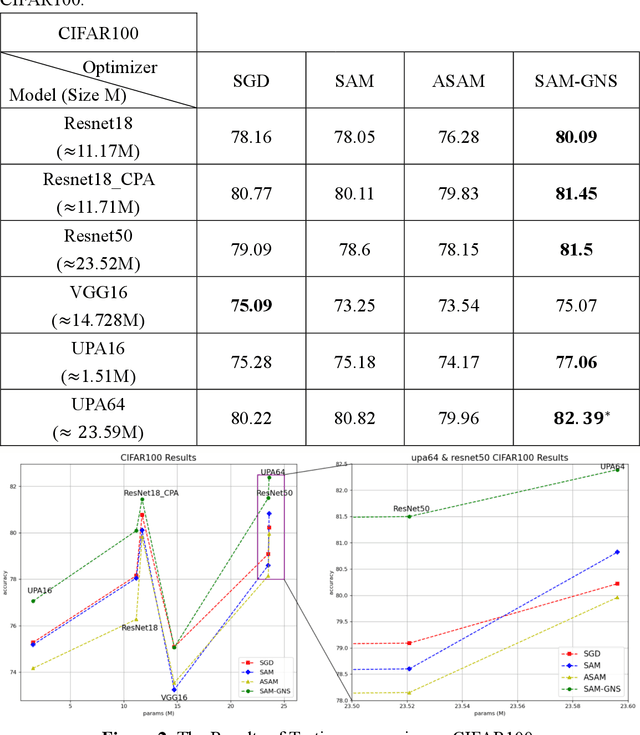
In Machine Learning, optimization mostly has been done by using a gradient descent method to find the minimum value of the loss. However, especially in deep learning, finding a global minimum from a nonconvex loss function across a high dimensional space is an extraordinarily difficult task. Recently, a generalization learning algorithm, Sharpness-Aware Minimization (SAM), has made a great success in image classification task. Despite the great performance in creating convex space, proper direction leading by SAM is still remained unclear. We, thereby, propose a creating a Unit Vector space in SAM, which not only consisted of the mathematical instinct in linear algebra but also kept the advantages of adaptive gradient algorithm. Moreover, applying SAM in unit gradient brings models competitive performances in image classification datasets, such as CIFAR - {10, 100}. The experiment showed that it performed even better and more robust than SAM.
Deep Manifold Embedding for Hyperspectral Image Classification
Dec 24, 2019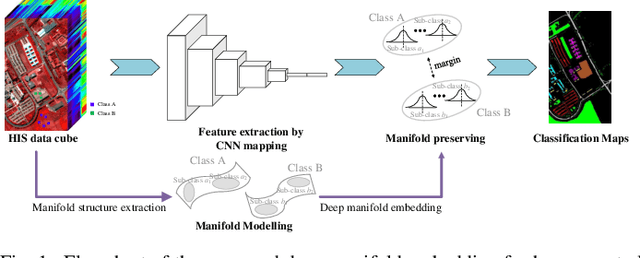

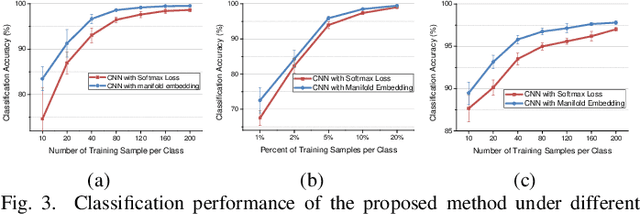
Deep learning methods have played a more and more important role in hyperspectral image classification. However, the general deep learning methods mainly take advantage of the information of sample itself or the pairwise information between samples while ignore the intrinsic data structure within the whole data. To tackle this problem, this work develops a novel deep manifold embedding method(DMEM) for hyperspectral image classification. First, each class in the image is modelled as a specific nonlinear manifold and the geodesic distance is used to measure the correlation between the samples. Then, based on the hierarchical clustering, the manifold structure of the data can be captured and each nonlinear data manifold can be divided into several sub-classes. Finally, considering the distribution of each sub-class and the correlation between different subclasses, the DMEM is constructed to preserve the estimated geodesic distances on the data manifold between the learned low dimensional features of different samples. Experiments over three real-world hyperspectral image datasets have demonstrated the effectiveness of the proposed method.
Dynamically Stable Poincaré Embeddings for Neural Manifolds
Dec 21, 2021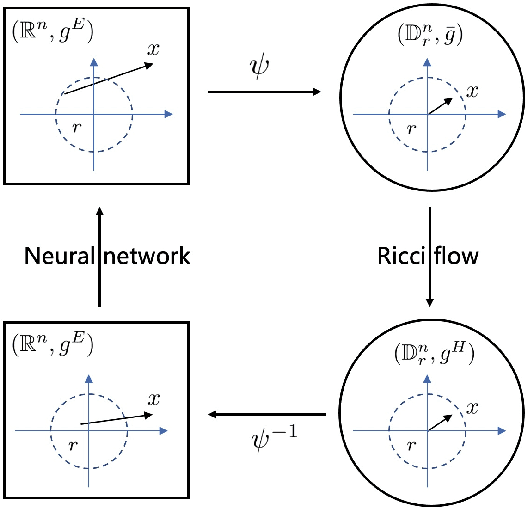
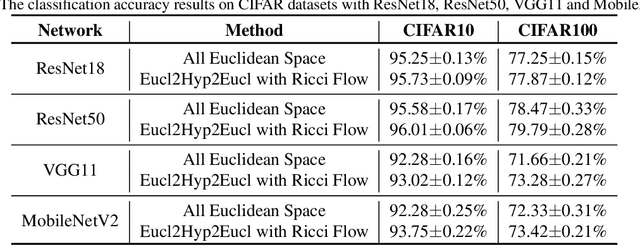
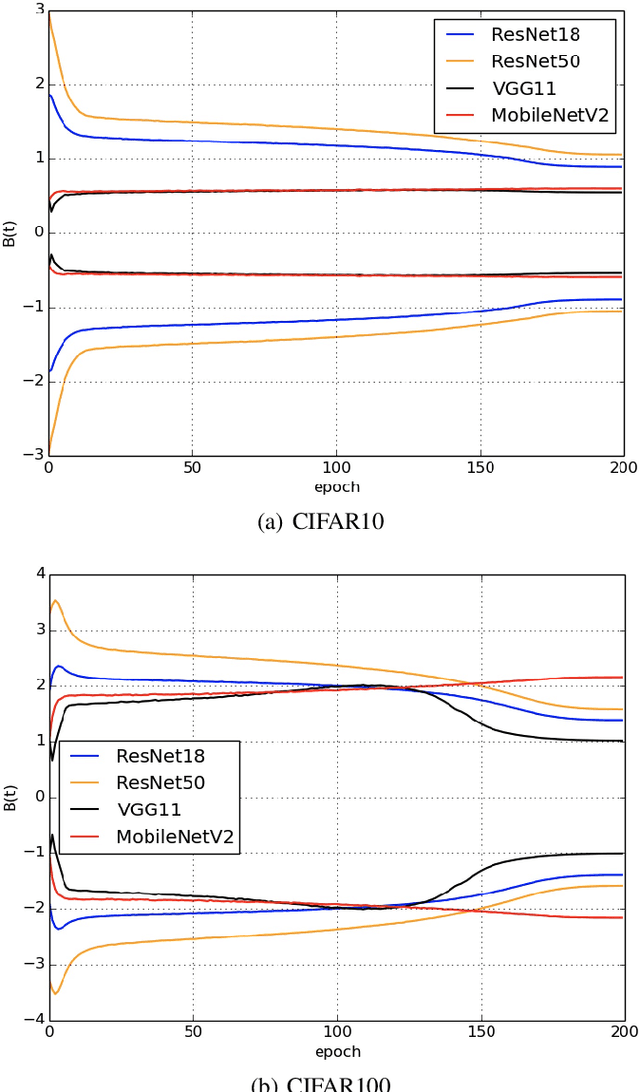
In a Riemannian manifold, the Ricci flow is a partial differential equation for evolving the metric to become more regular. We hope that topological structures from such metrics may be used to assist in the tasks of machine learning. However, this part of the work is still missing. In this paper, we bridge this gap between the Ricci flow and deep neural networks by dynamically stable Poincar\'e embeddings for neural manifolds. As a result, we prove that, if initial metrics have an $L^2$-norm perturbation which deviates from the Hyperbolic metric on the Poincar\'e ball, the scaled Ricci-DeTurck flow of such metrics smoothly and exponentially converges to the Hyperbolic metric. Specifically, the role of the Ricci flow is to serve as naturally evolving to the stable Poincar\'e ball that will then be mapped back to the Euclidean space. For such dynamically stable neural manifolds under the Ricci flow, the convergence of neural networks embedded with such manifolds is not susceptible to perturbations. And we show that such Ricci flow assisted neural networks outperform with their all Euclidean versions on image classification tasks (CIFAR datasets).
Physics Assisted Deep Learning for Indoor Imaging using Phaseless Wi-Fi Measurements
Nov 04, 2021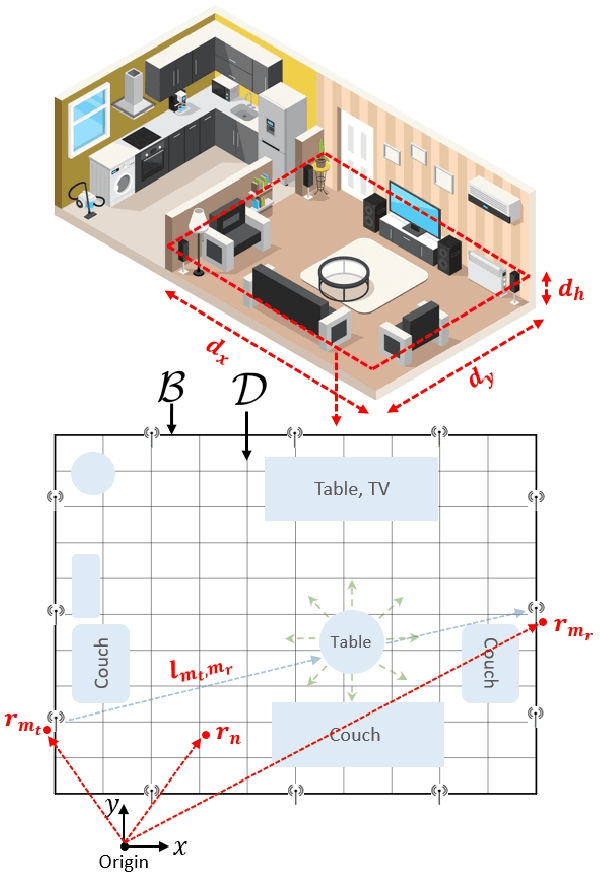

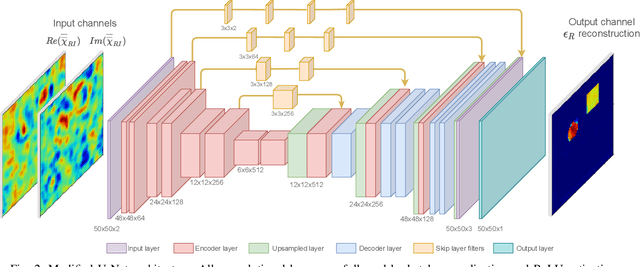
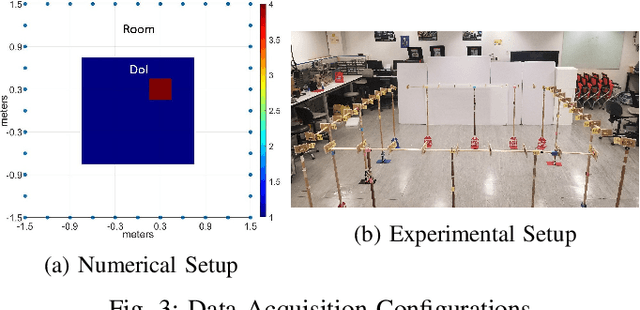
A physics assisted deep learning framework to perform accurate indoor imaging using phaseless Wi-Fi measurements is proposed. It is able to image objects that are large (compared to wavelength) and have high permittivity values, that existing radio frequency (RF) inverse scattering techniques find very challenging, making it suitable for indoor RF imaging. The technique utilizes a Rytov based inverse scattering model with a deep learning framework. The inverse scattering model is based on an extended Rytov approximation (xRA) that pre-reconstructs the RF measurements. Under strong scattering conditions, this pre-reconstruction is related to the actual permittivity profile by a non-linear function, which is learned by a modified U-Net model to obtain the permittivity profile of the object. Thus, our proposed approach not only reconstructs the shape of objects, but also estimates their permittivity values accurately. We demonstrate its imaging performance using simulations as well as experimental results in an actual indoor environment using 2.4 GHz Wi-Fi phaseless measurements. For incident wavelength $\lambda_0$, the proposed framework can reconstruct objects with relative permittivity as high as 77 and electrical size as large as $40 \lambda$, where $\lambda =\lambda_0/\sqrt{77}$. This is in contrast to existing phaseless imaging techniques which cannot reconstruct permittivity values beyond 3 or 4. Thus, our proposed method is the first inverse scattering-based deep learning framework which can image large scatterers with high permittivity and achieve accurate indoor RF imaging using phaseless Wi-Fi measurements.
Del-Net: A Single-Stage Network for Mobile Camera ISP
Aug 03, 2021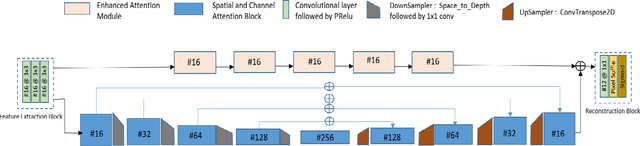
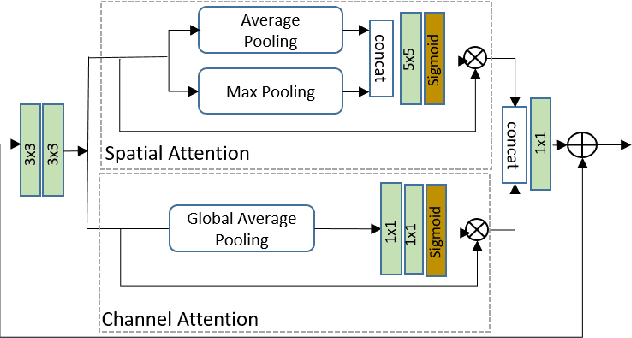
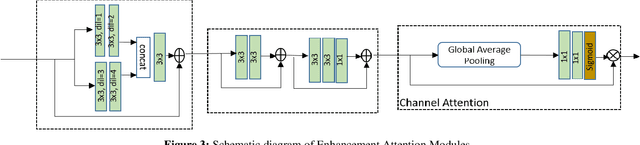
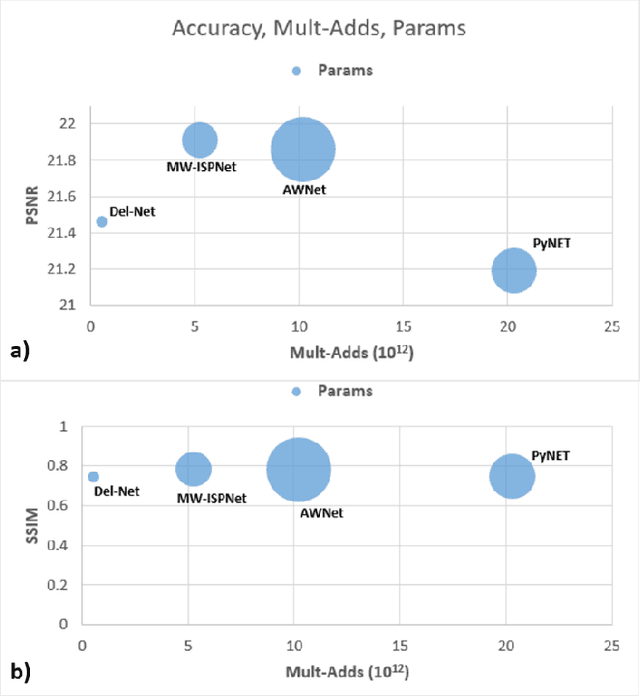
The quality of images captured by smartphones is an important specification since smartphones are becoming ubiquitous as primary capturing devices. The traditional image signal processing (ISP) pipeline in a smartphone camera consists of several image processing steps performed sequentially to reconstruct a high quality sRGB image from the raw sensor data. These steps consist of demosaicing, denoising, white balancing, gamma correction, colour enhancement, etc. Since each of them are performed sequentially using hand-crafted algorithms, the residual error from each processing module accumulates in the final reconstructed signal. Thus, the traditional ISP pipeline has limited reconstruction quality in terms of generalizability across different lighting conditions and associated noise levels while capturing the image. Deep learning methods using convolutional neural networks (CNN) have become popular in solving many image-related tasks such as image denoising, contrast enhancement, super resolution, deblurring, etc. Furthermore, recent approaches for the RAW to sRGB conversion using deep learning methods have also been published, however, their immense complexity in terms of their memory requirement and number of Mult-Adds make them unsuitable for mobile camera ISP. In this paper we propose DelNet - a single end-to-end deep learning model - to learn the entire ISP pipeline within reasonable complexity for smartphone deployment. Del-Net is a multi-scale architecture that uses spatial and channel attention to capture global features like colour, as well as a series of lightweight modified residual attention blocks to help with denoising. For validation, we provide results to show the proposed Del-Net achieves compelling reconstruction quality.
Swin Transformer V2: Scaling Up Capacity and Resolution
Nov 18, 2021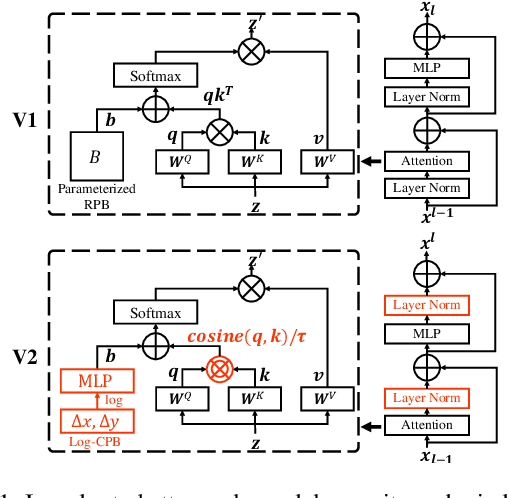
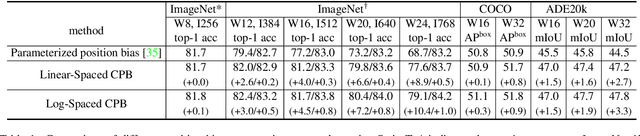
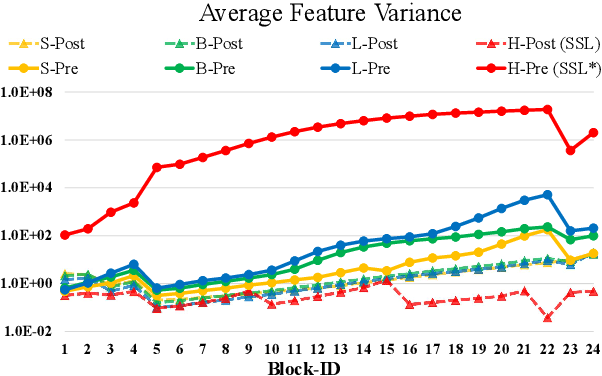
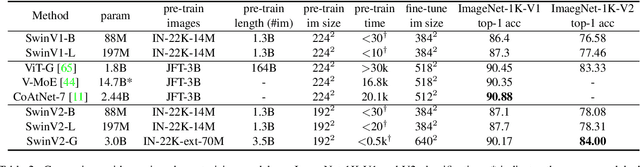
We present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536$\times$1,536 resolution. By scaling up capacity and resolution, Swin Transformer sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1/54.4 box/mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification. Our techniques are generally applicable for scaling up vision models, which has not been widely explored as that of NLP language models, partly due to the following difficulties in training and applications: 1) vision models often face instability issues at scale and 2) many downstream vision tasks require high resolution images or windows and it is not clear how to effectively transfer models pre-trained at low resolutions to higher resolution ones. The GPU memory consumption is also a problem when the image resolution is high. To address these issues, we present several techniques, which are illustrated by using Swin Transformer as a case study: 1) a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models; 2) a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts. In addition, we share our crucial implementation details that lead to significant savings of GPU memory consumption and thus make it feasible to train large vision models with regular GPUs. Using these techniques and self-supervised pre-training, we successfully train a strong 3B Swin Transformer model and effectively transfer it to various vision tasks involving high-resolution images or windows, achieving the state-of-the-art accuracy on a variety of benchmarks.
Dense Semantic Contrast for Self-Supervised Visual Representation Learning
Sep 16, 2021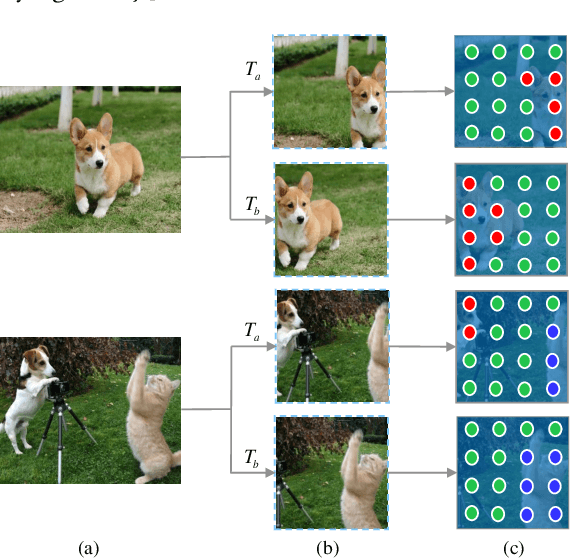
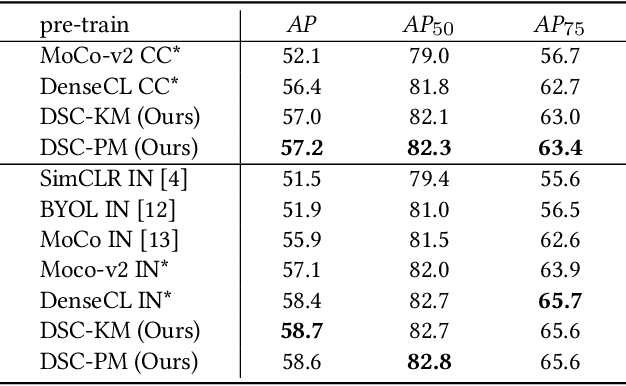
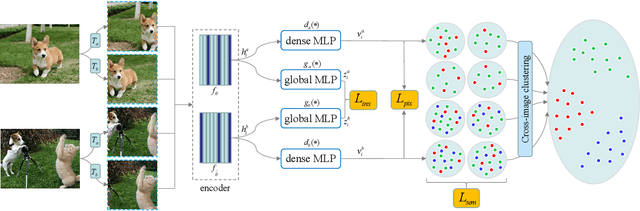
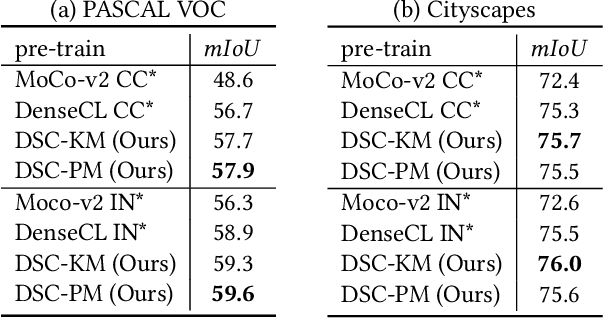
Self-supervised representation learning for visual pre-training has achieved remarkable success with sample (instance or pixel) discrimination and semantics discovery of instance, whereas there still exists a non-negligible gap between pre-trained model and downstream dense prediction tasks. Concretely, these downstream tasks require more accurate representation, in other words, the pixels from the same object must belong to a shared semantic category, which is lacking in the previous methods. In this work, we present Dense Semantic Contrast (DSC) for modeling semantic category decision boundaries at a dense level to meet the requirement of these tasks. Furthermore, we propose a dense cross-image semantic contrastive learning framework for multi-granularity representation learning. Specially, we explicitly explore the semantic structure of the dataset by mining relations among pixels from different perspectives. For intra-image relation modeling, we discover pixel neighbors from multiple views. And for inter-image relations, we enforce pixel representation from the same semantic class to be more similar than the representation from different classes in one mini-batch. Experimental results show that our DSC model outperforms state-of-the-art methods when transferring to downstream dense prediction tasks, including object detection, semantic segmentation, and instance segmentation. Code will be made available.
Supervised learning of analysis-sparsity priors with automatic differentiation
Dec 15, 2021
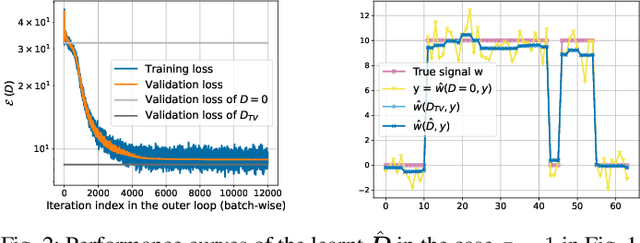
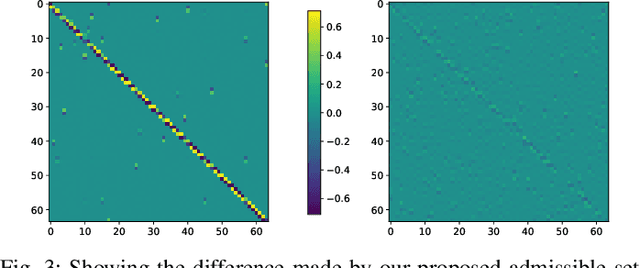
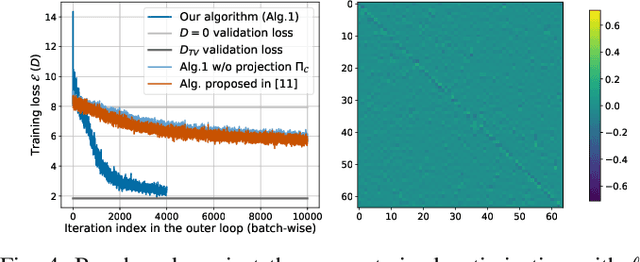
Sparsity priors are commonly used in denoising and image reconstruction. For analysis-type priors, a dictionary defines a representation of signals that is likely to be sparse. In most situations, this dictionary is not known, and is to be recovered from pairs of ground-truth signals and measurements, by minimizing the reconstruction error. This defines a hierarchical optimization problem, which can be cast as a bi-level optimization. Yet, this problem is unsolvable, as reconstructions and their derivative wrt the dictionary have no closed-form expression. However, reconstructions can be iteratively computed using the Forward-Backward splitting (FB) algorithm. In this paper, we approximate reconstructions by the output of the aforementioned FB algorithm. Then, we leverage automatic differentiation to evaluate the gradient of this output wrt the dictionary, which we learn with projected gradient descent. Experiments show that our algorithm successfully learns the 1D Total Variation (TV) dictionary from piecewise constant signals. For the same case study, we propose to constrain our search to dictionaries of 0-centered columns, which removes undesired local minima and improves numerical stability.
Does Melania Trump have a body double from the perspective of automatic face recognition?
Sep 06, 2021
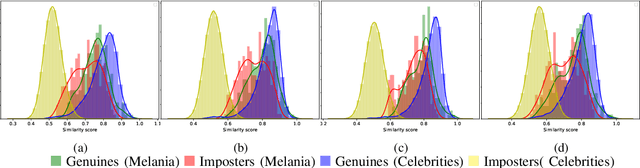
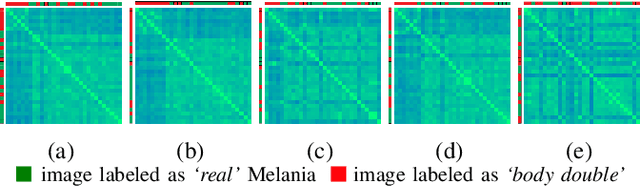
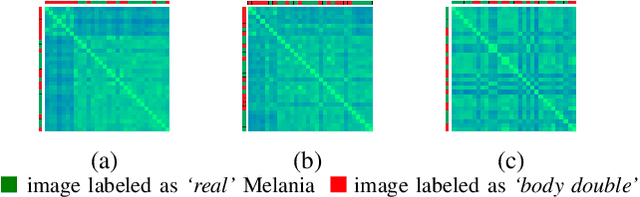
In this paper, we explore whether automatic face recognition can help in verifying widespread misinformation on social media, particularly conspiracy theories that are based on the existence of body doubles. The conspiracy theory addressed in this paper is the case of the Melania Trump body double. We employed four different state-of-the-art descriptors for face recognition to verify the integrity of the claim of the studied conspiracy theory. In addition, we assessed the impact of different image quality metrics on the variation of face recognition results. Two sets of image quality metrics were considered: acquisition-related metrics and subject-related metrics.