 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Recyclable Waste Identification Using CNN Image Recognition and Gaussian Clustering
Nov 02, 2020

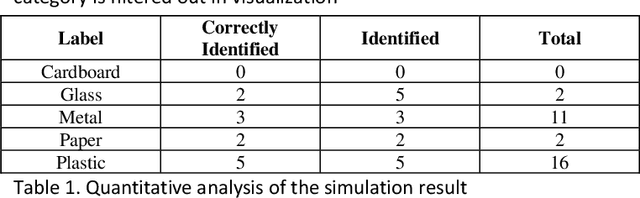

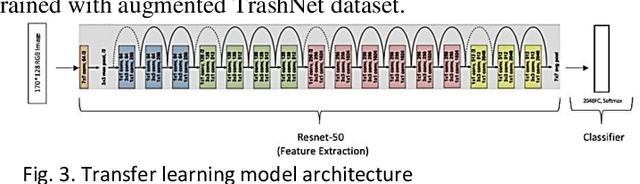
Waste recycling is an important way of saving energy and materials in the production process. In general cases recyclable objects are mixed with unrecyclable objects, which raises a need for identification and classification. This paper proposes a convolutional neural network (CNN) model to complete both tasks. The model uses transfer learning from a pretrained Resnet-50 CNN to complete feature extraction. A subsequent fully connected layer for classification was trained on the augmented TrashNet dataset [1]. In the application, sliding-window is used for image segmentation in the pre-classification stage. In the post-classification stage, the labelled sample points are integrated with Gaussian Clustering to locate the object. The resulting model has achieved an overall detection rate of 48.4% in simulation and final classification accuracy of 92.4%.
KD-VLP: Improving End-to-End Vision-and-Language Pretraining with Object Knowledge Distillation
Sep 22, 2021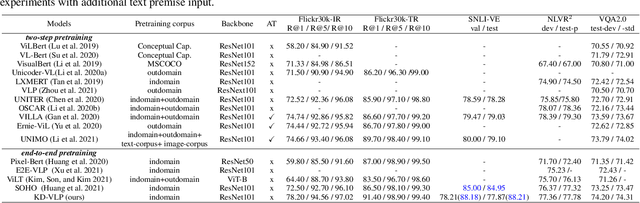
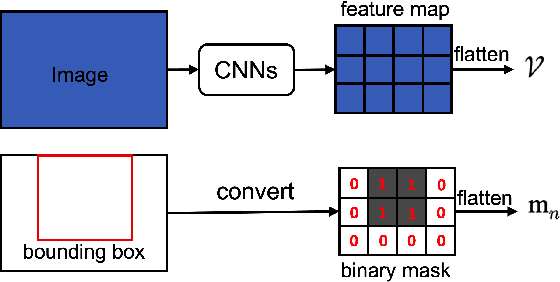
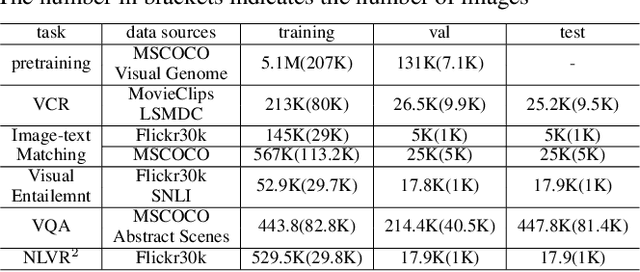
Self-supervised vision-and-language pretraining (VLP) aims to learn transferable multi-modal representations from large-scale image-text data and to achieve strong performances on a broad scope of vision-language tasks after finetuning. Previous mainstream VLP approaches typically adopt a two-step strategy relying on external object detectors to encode images in a multi-modal Transformer framework, which suffer from restrictive object concept space, limited image context and inefficient computation. In this paper, we propose an object-aware end-to-end VLP framework, which directly feeds image grid features from CNNs into the Transformer and learns the multi-modal representations jointly. More importantly, we propose to perform object knowledge distillation to facilitate learning cross-modal alignment at different semantic levels. To achieve that, we design two novel pretext tasks by taking object features and their semantic labels from external detectors as supervision: 1.) Object-guided masked vision modeling task focuses on enforcing object-aware representation learning in the multi-modal Transformer; 2.) Phrase-region alignment task aims to improve cross-modal alignment by utilizing the similarities between noun phrases and object labels in the linguistic space. Extensive experiments on a wide range of vision-language tasks demonstrate the efficacy of our proposed framework, and we achieve competitive or superior performances over the existing pretraining strategies. The code is available in supplementary materials.
UFPMP-Det: Toward Accurate and Efficient Object Detection on Drone Imagery
Jan 01, 2022
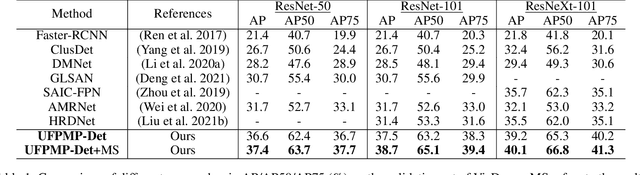
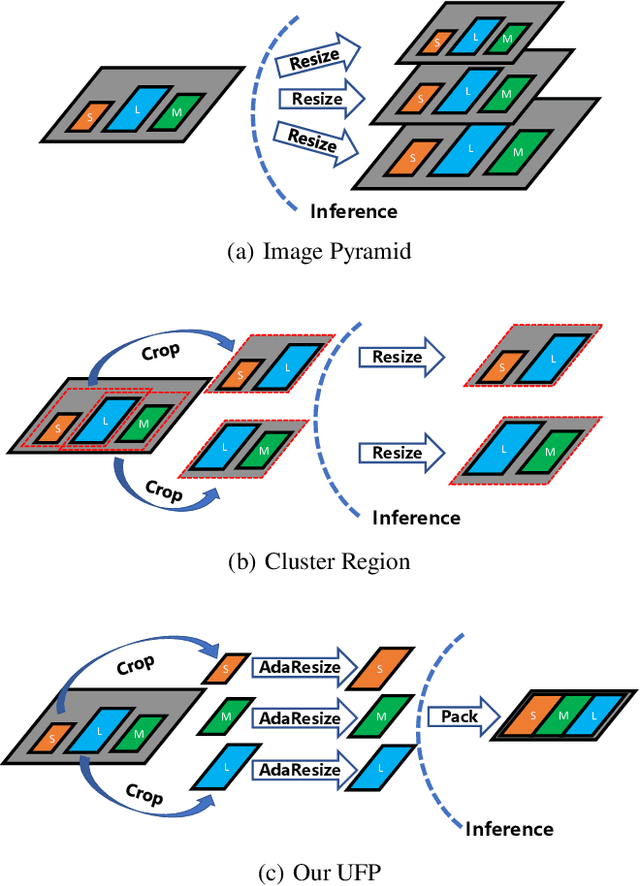
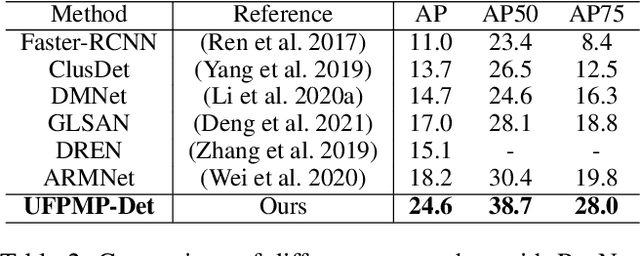
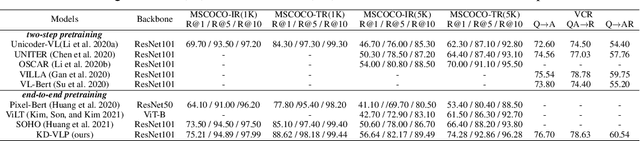
This paper proposes a novel approach to object detection on drone imagery, namely Multi-Proxy Detection Network with Unified Foreground Packing (UFPMP-Det). To deal with the numerous instances of very small scales, different from the common solution that divides the high-resolution input image into quite a number of chips with low foreground ratios to perform detection on them each, the Unified Foreground Packing (UFP) module is designed, where the sub-regions given by a coarse detector are initially merged through clustering to suppress background and the resulting ones are subsequently packed into a mosaic for a single inference, thus significantly reducing overall time cost. Furthermore, to address the more serious confusion between inter-class similarities and intra-class variations of instances, which deteriorates detection performance but is rarely discussed, the Multi-Proxy Detection Network (MP-Det) is presented to model object distributions in a fine-grained manner by employing multiple proxy learning, and the proxies are enforced to be diverse by minimizing a Bag-of-Instance-Words (BoIW) guided optimal transport loss. By such means, UFPMP-Det largely promotes both the detection accuracy and efficiency. Extensive experiments are carried out on the widely used VisDrone and UAVDT datasets, and UFPMP-Det reports new state-of-the-art scores at a much higher speed, highlighting its advantages.
Weighted Encoding Based Image Interpolation With Nonlocal Linear Regression Model
Mar 04, 2020



Image interpolation is a special case of image super-resolution, where the low-resolution image is directly down-sampled from its high-resolution counterpart without blurring and noise. Therefore, assumptions adopted in super-resolution models are not valid for image interpolation. To address this problem, we propose a novel image interpolation model based on sparse representation. Two widely used priors including sparsity and nonlocal self-similarity are used as the regularization terms to enhance the stability of interpolation model. Meanwhile, we incorporate the nonlocal linear regression into this model since nonlocal similar patches could provide a better approximation to a given patch. Moreover, we propose a new approach to learn adaptive sub-dictionary online instead of clustering. For each patch, similar patches are grouped to learn adaptive sub-dictionary, generating a more sparse and accurate representation. Finally, the weighted encoding is introduced to suppress tailing of fitting residuals in data fidelity. Abundant experimental results demonstrate that our proposed method outperforms several state-of-the-art methods in terms of quantitative measures and visual quality.
Recommendation Unlearning
Jan 18, 2022
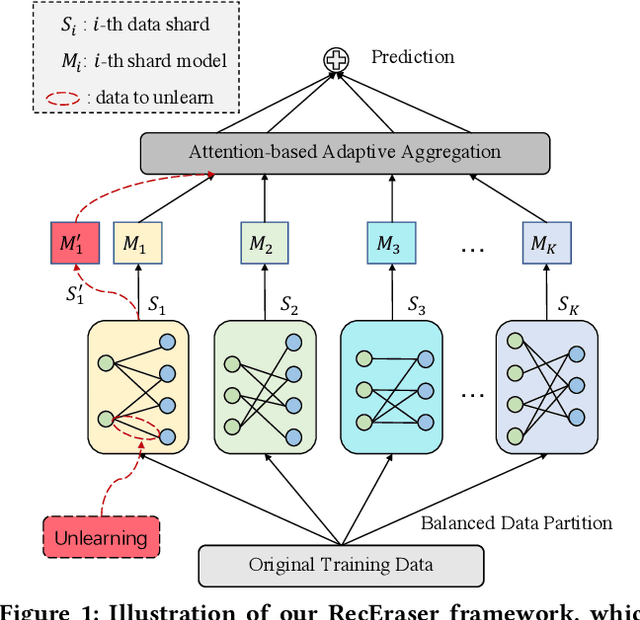
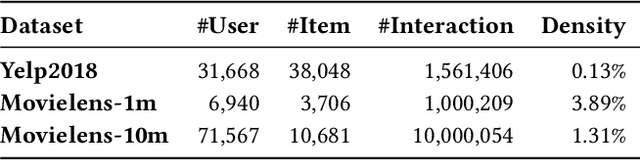
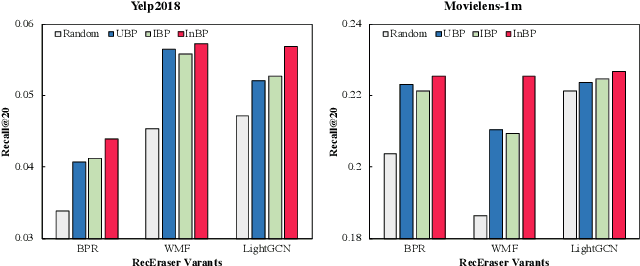
Recommender systems provide essential web services by learning users' personal preferences from collected data. However, in many cases, systems also need to forget some training data. From the perspective of privacy, several privacy regulations have recently been proposed, requiring systems to eliminate any impact of the data whose owner requests to forget. From the perspective of utility, if a system's utility is damaged by some bad data, the system needs to forget these data to regain utility. From the perspective of usability, users can delete noise and incorrect entries so that a system can provide more useful recommendations. While unlearning is very important, it has not been well-considered in existing recommender systems. Although there are some researches have studied the problem of machine unlearning in the domains of image and text data, existing methods can not been directly applied to recommendation as they are unable to consider the collaborative information. In this paper, we propose RecEraser, a general and efficient machine unlearning framework tailored to recommendation task. The main idea of RecEraser is to partition the training set into multiple shards and train a constituent model for each shard. Specifically, to keep the collaborative information of the data, we first design three novel data partition algorithms to divide training data into balanced groups based on their similarity. Then, considering that different shard models do not uniformly contribute to the final prediction, we further propose an adaptive aggregation method to improve the global model utility. Experimental results on three public benchmarks show that RecEraser can not only achieve efficient unlearning, but also outperform the state-of-the-art unlearning methods in terms of model utility. The source code can be found at https://github.com/chenchongthu/Recommendation-Unlearning
Margin-Aware Intra-Class Novelty Identification for Medical Images
Jul 31, 2021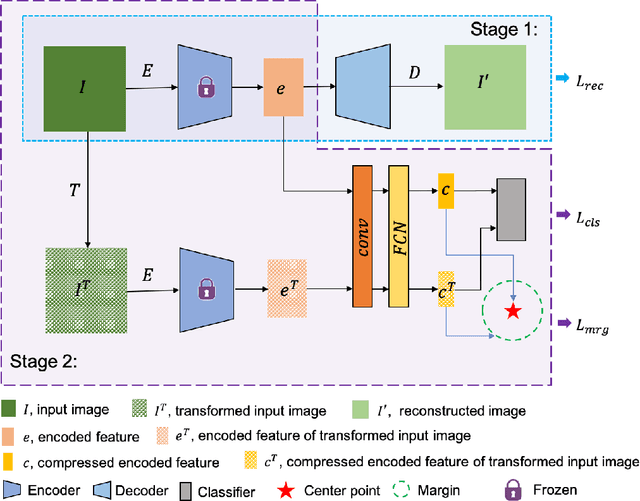

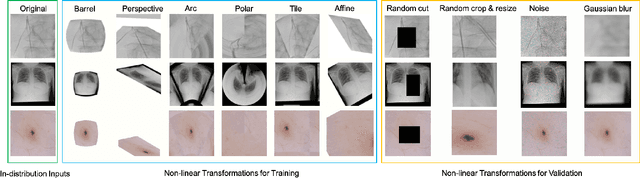

Traditional anomaly detection methods focus on detecting inter-class variations while medical image novelty identification is inherently an intra-class detection problem. For example, a machine learning model trained with normal chest X-ray and common lung abnormalities, is expected to discover and flag idiopathic pulmonary fibrosis which a rare lung disease and unseen by the model during training. The nuances from intra-class variations and lack of relevant training data in medical image analysis pose great challenges for existing anomaly detection methods. To tackle the challenges, we propose a hybrid model - Transformation-based Embedding learning for Novelty Detection (TEND) which without any out-of-distribution training data, performs novelty identification by combining both autoencoder-based and classifier-based method. With a pre-trained autoencoder as image feature extractor, TEND learns to discriminate the feature embeddings of in-distribution data from the transformed counterparts as fake out-of-distribution inputs. To enhance the separation, a distance objective is optimized to enforce a margin between the two classes. Extensive experimental results on both natural image datasets and medical image datasets are presented and our method out-performs state-of-the-art approaches.
DDet: Dual-path Dynamic Enhancement Network for Real-World Image Super-Resolution
Feb 25, 2020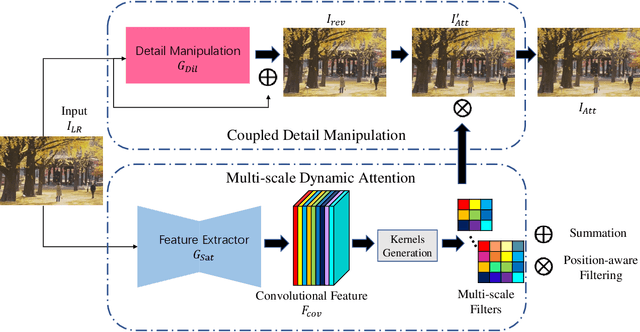
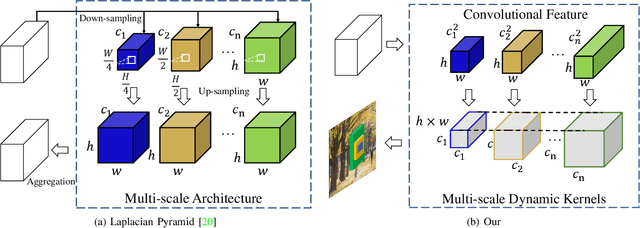

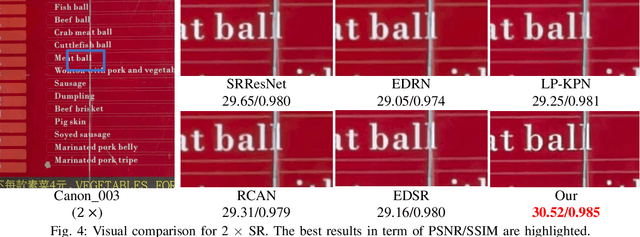
Different from traditional image super-resolution task, real image super-resolution(Real-SR) focus on the relationship between real-world high-resolution(HR) and low-resolution(LR) image. Most of the traditional image SR obtains the LR sample by applying a fixed down-sampling operator. Real-SR obtains the LR and HR image pair by incorporating different quality optical sensors. Generally, Real-SR has more challenges as well as broader application scenarios. Previous image SR methods fail to exhibit similar performance on Real-SR as the image data is not aligned inherently. In this article, we propose a Dual-path Dynamic Enhancement Network(DDet) for Real-SR, which addresses the cross-camera image mapping by realizing a dual-way dynamic sub-pixel weighted aggregation and refinement. Unlike conventional methods which stack up massive convolutional blocks for feature representation, we introduce a content-aware framework to study non-inherently aligned image pair in image SR issue. First, we use a content-adaptive component to exhibit the Multi-scale Dynamic Attention(MDA). Second, we incorporate a long-term skip connection with a Coupled Detail Manipulation(CDM) to perform collaborative compensation and manipulation. The above dual-path model is joint into a unified model and works collaboratively. Extensive experiments on the challenging benchmarks demonstrate the superiority of our model.
HYPPO: A Surrogate-Based Multi-Level Parallelism Tool for Hyperparameter Optimization
Oct 04, 2021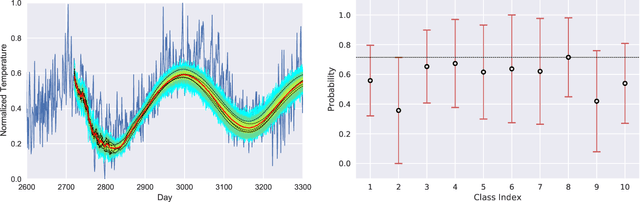
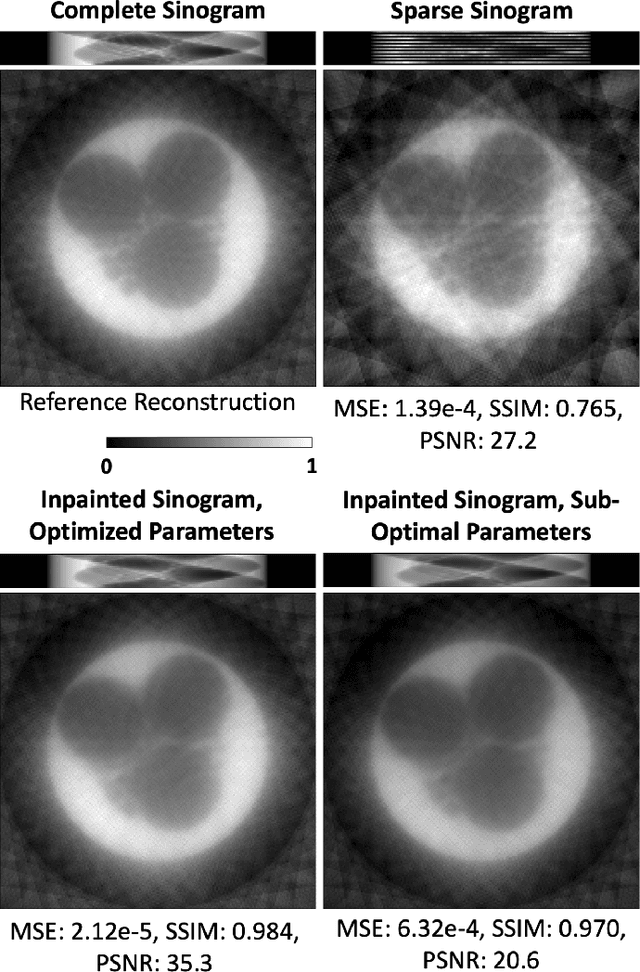
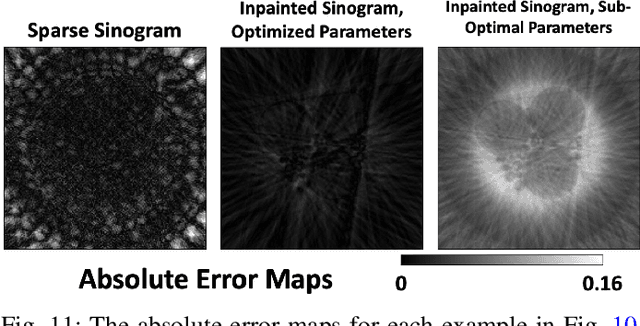
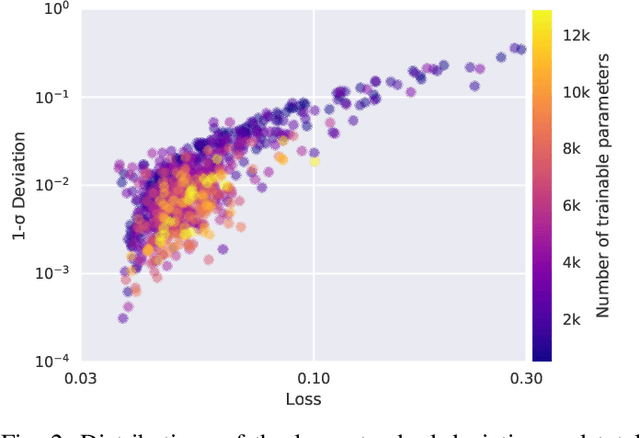
We present a new software, HYPPO, that enables the automatic tuning of hyperparameters of various deep learning (DL) models. Unlike other hyperparameter optimization (HPO) methods, HYPPO uses adaptive surrogate models and directly accounts for uncertainty in model predictions to find accurate and reliable models that make robust predictions. Using asynchronous nested parallelism, we are able to significantly alleviate the computational burden of training complex architectures and quantifying the uncertainty. HYPPO is implemented in Python and can be used with both TensorFlow and PyTorch libraries. We demonstrate various software features on time-series prediction and image classification problems as well as a scientific application in computed tomography image reconstruction. Finally, we show that (1) we can reduce by an order of magnitude the number of evaluations necessary to find the most optimal region in the hyperparameter space and (2) we can reduce by two orders of magnitude the throughput for such HPO process to complete.
Update in Unit Gradient
Oct 01, 2021
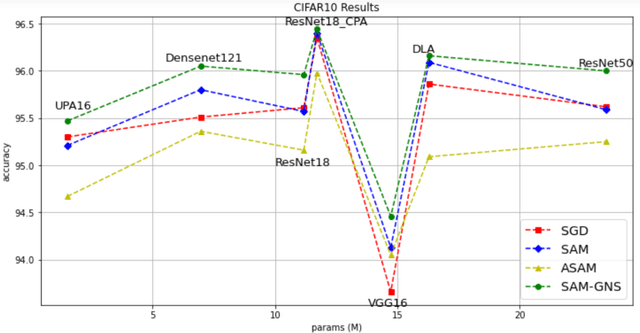
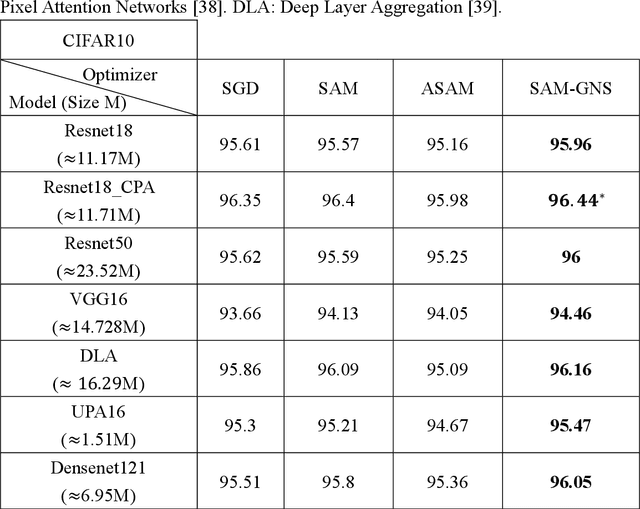
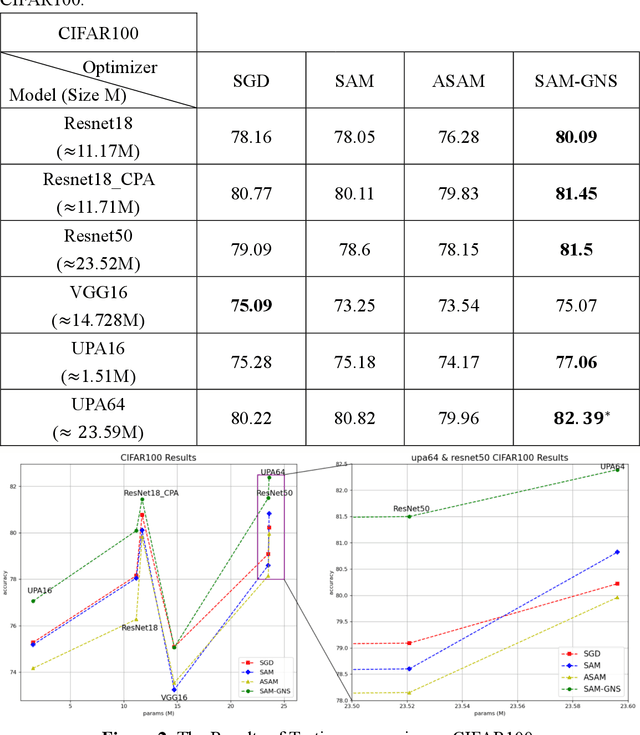
In Machine Learning, optimization mostly has been done by using a gradient descent method to find the minimum value of the loss. However, especially in deep learning, finding a global minimum from a nonconvex loss function across a high dimensional space is an extraordinarily difficult task. Recently, a generalization learning algorithm, Sharpness-Aware Minimization (SAM), has made a great success in image classification task. Despite the great performance in creating convex space, proper direction leading by SAM is still remained unclear. We, thereby, propose a creating a Unit Vector space in SAM, which not only consisted of the mathematical instinct in linear algebra but also kept the advantages of adaptive gradient algorithm. Moreover, applying SAM in unit gradient brings models competitive performances in image classification datasets, such as CIFAR - {10, 100}. The experiment showed that it performed even better and more robust than SAM.
Dynamically Stable Poincaré Embeddings for Neural Manifolds
Dec 21, 2021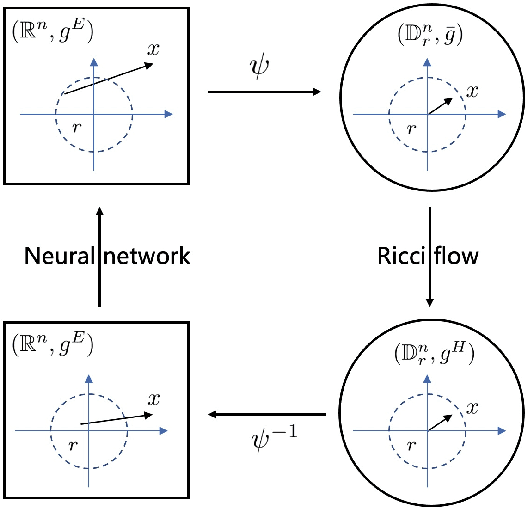
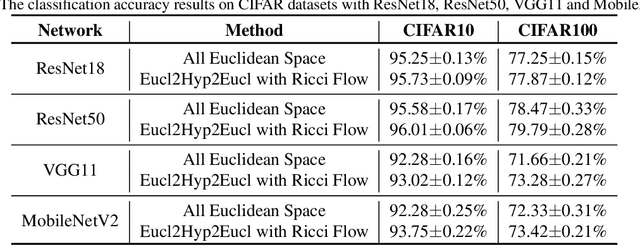
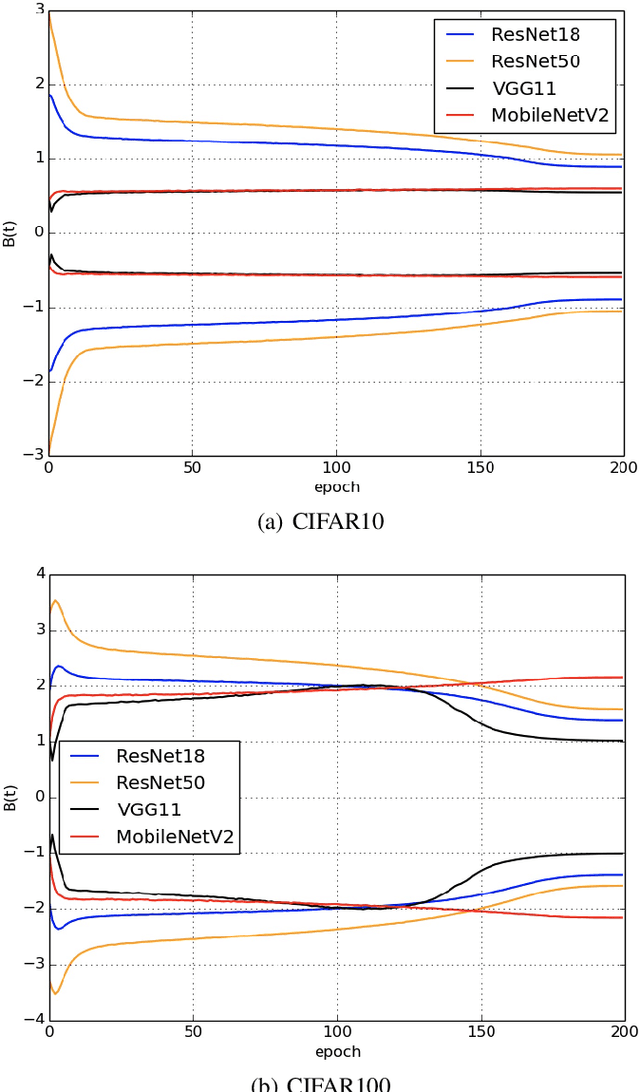
In a Riemannian manifold, the Ricci flow is a partial differential equation for evolving the metric to become more regular. We hope that topological structures from such metrics may be used to assist in the tasks of machine learning. However, this part of the work is still missing. In this paper, we bridge this gap between the Ricci flow and deep neural networks by dynamically stable Poincar\'e embeddings for neural manifolds. As a result, we prove that, if initial metrics have an $L^2$-norm perturbation which deviates from the Hyperbolic metric on the Poincar\'e ball, the scaled Ricci-DeTurck flow of such metrics smoothly and exponentially converges to the Hyperbolic metric. Specifically, the role of the Ricci flow is to serve as naturally evolving to the stable Poincar\'e ball that will then be mapped back to the Euclidean space. For such dynamically stable neural manifolds under the Ricci flow, the convergence of neural networks embedded with such manifolds is not susceptible to perturbations. And we show that such Ricci flow assisted neural networks outperform with their all Euclidean versions on image classification tasks (CIFAR datasets).