 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Centroid-UNet: Detecting Centroids in Aerial Images
Dec 13, 2021
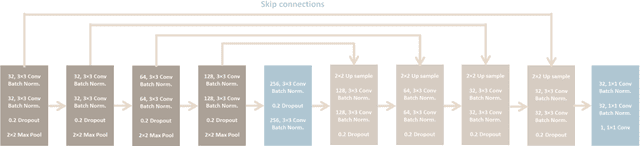
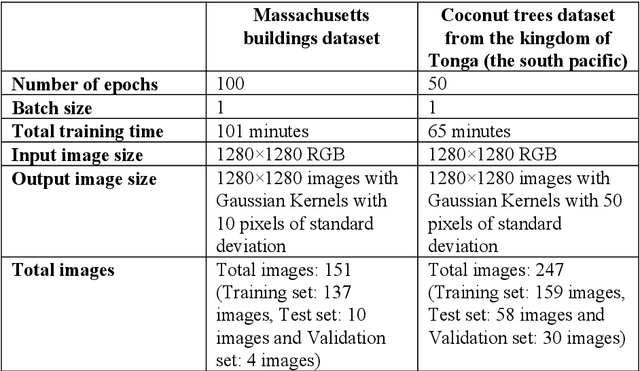

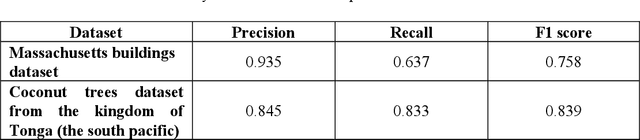
In many applications of aerial/satellite image analysis (remote sensing), the generation of exact shapes of objects is a cumbersome task. In most remote sensing applications such as counting objects requires only location estimation of objects. Hence, locating object centroids in aerial/satellite images is an easy solution for tasks where the object's exact shape is not necessary. Thus, this study focuses on assessing the feasibility of using deep neural networks for locating object centroids in satellite images. Name of our model is Centroid-UNet. The Centroid-UNet model is based on classic U-Net semantic segmentation architecture. We modified and adapted the U-Net semantic segmentation architecture into a centroid detection model preserving the simplicity of the original model. Furthermore, we have tested and evaluated our model with two case studies involving aerial/satellite images. Those two case studies are building centroid detection case study and coconut tree centroid detection case study. Our evaluation results have reached comparably good accuracy compared to other methods, and also offer simplicity. The code and models developed under this study are also available in the Centroid-UNet GitHub repository: https://github.com/gicait/centroid-unet
* Proccedings of the 42nd Asian Conference on Remote Sensing, 2021, Can Tho city, Vietnam
On the Impact of Lossy Image and Video Compression on the Performance of Deep Convolutional Neural Network Architectures
Jul 28, 2020



Recent advances in generalized image understanding have seen a surge in the use of deep convolutional neural networks (CNN) across a broad range of image-based detection, classification and prediction tasks. Whilst the reported performance of these approaches is impressive, this study investigates the hitherto unapproached question of the impact of commonplace image and video compression techniques on the performance of such deep learning architectures. Focusing on the JPEG and H.264 (MPEG-4 AVC) as a representative proxy for contemporary lossy image/video compression techniques that are in common use within network-connected image/video devices and infrastructure, we examine the impact on performance across five discrete tasks: human pose estimation, semantic segmentation, object detection, action recognition, and monocular depth estimation. As such, within this study we include a variety of network architectures and domains spanning end-to-end convolution, encoder-decoder, region-based CNN (R-CNN), dual-stream, and generative adversarial networks (GAN). Our results show a non-linear and non-uniform relationship between network performance and the level of lossy compression applied. Notably, performance decreases significantly below a JPEG quality (quantization) level of 15% and a H.264 Constant Rate Factor (CRF) of 40. However, retraining said architectures on pre-compressed imagery conversely recovers network performance by up to 78.4% in some cases. Furthermore, there is a correlation between architectures employing an encoder-decoder pipeline and those that demonstrate resilience to lossy image compression. The characteristics of the relationship between input compression to output task performance can be used to inform design decisions within future image/video devices and infrastructure.
Multivariate Medians for Image and Shape Analysis
Oct 31, 2019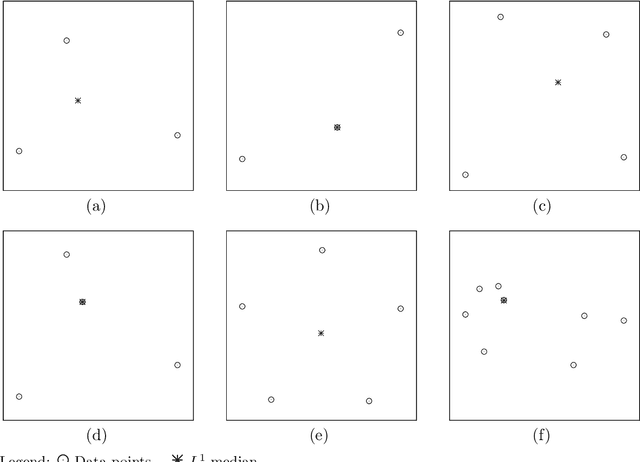
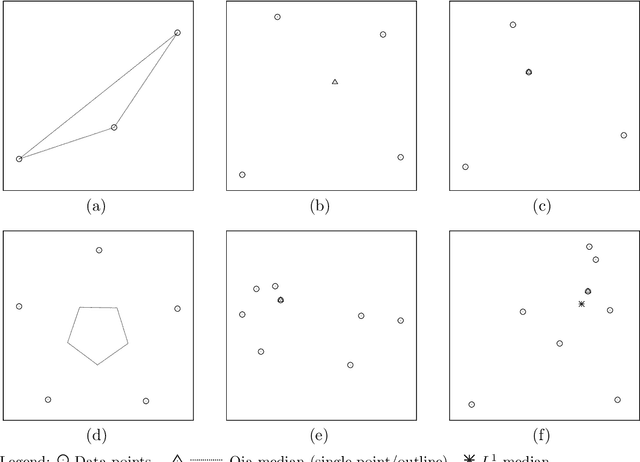
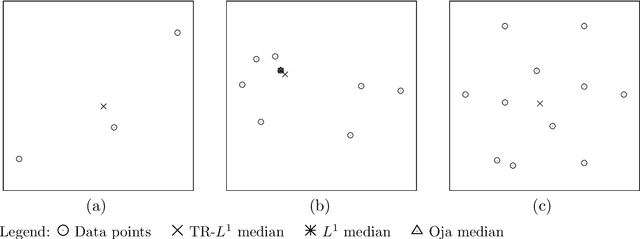
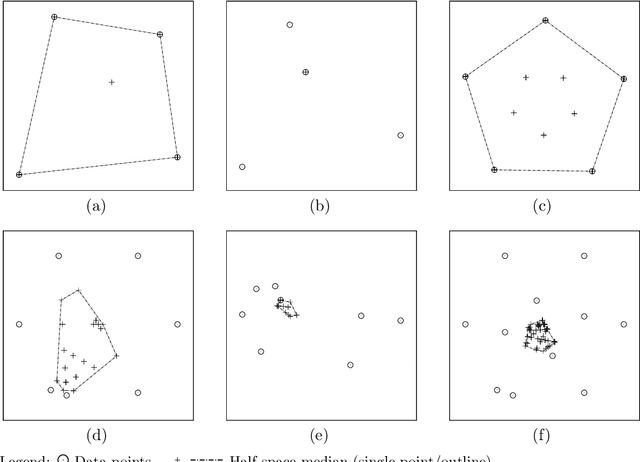
Having been studied since long by statisticians, multivariate median concepts found their way into the image processing literature in the course of the last decades, being used to construct robust and efficient denoising filters for multivariate images such as colour images but also matrix-valued images. Based on the similarities between image and geometric data as results of the sampling of continuous physical quantities, it can be expected that the understanding of multivariate median filters for images provides a starting point for the development of shape processing techniques. This paper presents an overview of multivariate median concepts relevant for image and shape processing. It focusses on their mathematical principles and discusses important properties especially in the context of image processing.
Revisiting Non Local Sparse Models for Image Restoration
Jan 28, 2020


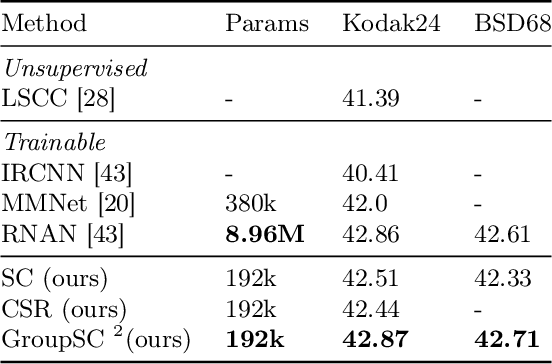
We propose a differentiable algorithm for image restoration inspired by the success of sparse models and self-similarity priors for natural images. Our approach builds upon the concept of joint sparsity between groups of similar image patches, and we show how this simple idea can be implemented in a differentiable architecture, allowing end-to-end training. The algorithm has the advantage of being interpretable, performing sparse decompositions of image patches, while being more parameter efficient than recent deep learning methods. We evaluate our algorithm on grayscale and color denoising, where we achieve competitive results, and on demoisaicking, where we outperform the most recent state-of-the-art deep learning model with 47 times less parameters and a much shallower architecture.
Adaptive Offline Quintuplet Loss for Image-Text Matching
Mar 14, 2020
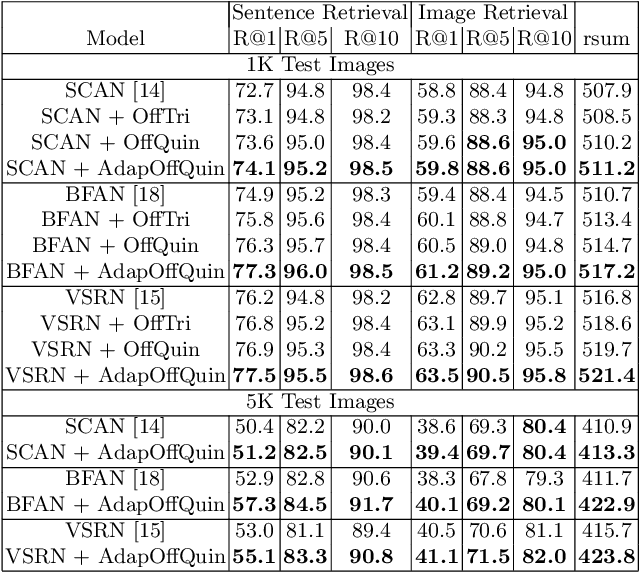
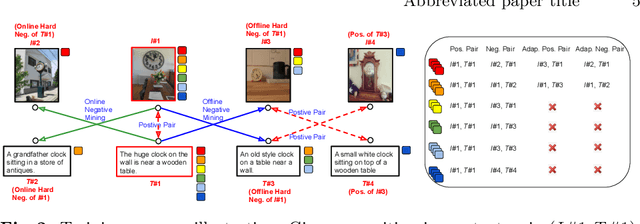
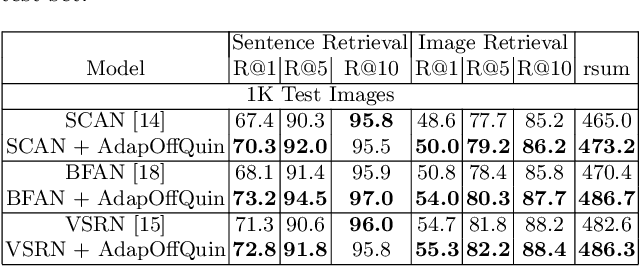
Existing image-text matching approaches typically leverage triplet loss with online hard negatives to train the model. For each image or text anchor in a training mini-batch, the model is trained to distinguish between a positive and the most confusing negative of the anchor mined from the mini-batch (i.e. online hard negative). This strategy improves the model's capacity to discover fine-grained correspondences and non-correspondences between image and text inputs. However, the above training approach has the following drawbacks: (1) the negative selection strategy still provides limited chances for the model to learn from very hard-to-distinguish cases. (2) The trained model has weak generalization capability from the training set to the testing set. (3) The penalty lacks hierarchy and adaptiveness for hard negatives with different ``hardness'' degrees. In this paper, we propose solutions by sampling negatives offline from the whole training set. It provides ``harder'' offline negatives than online hard negatives for the model to distinguish. Based on the offline hard negatives, a quintuplet loss is proposed to improve the model's generalization capability to distinguish positives and negatives. In addition, a novel loss function that combines the knowledge of positives, offline hard negatives and online hard negatives is created. It leverages offline hard negatives as intermediary to adaptively penalize them based on their distance relations to the anchor. We evaluate the proposed training approach on three state-of-the-art image-text models on the MS-COCO and Flickr30K datasets. Significant performance improvements are observed for all the models, demonstrating the effectiveness and generality of the proposed approach.
Contact-Rich Manipulation of a Flexible Object based on Deep Predictive Learning using Vision and Tactility
Dec 13, 2021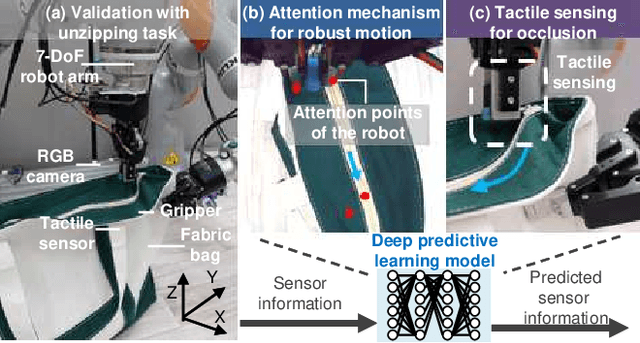
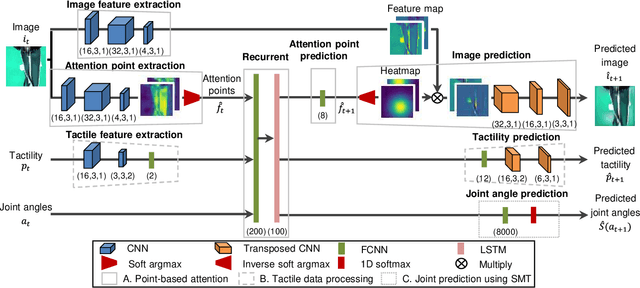

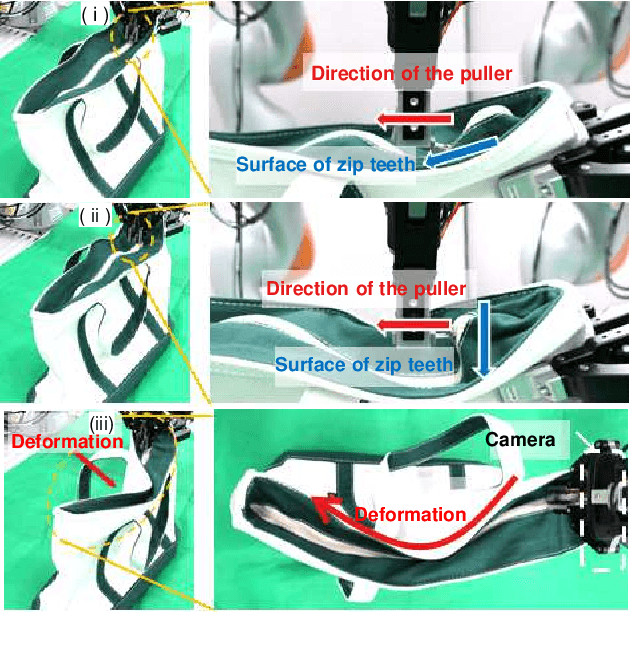
We achieved contact-rich flexible object manipulation, which was difficult to control with vision alone. In the unzipping task we chose as a validation task, the gripper grasps the puller, which hides the bag state such as the direction and amount of deformation behind it, making it difficult to obtain information to perform the task by vision alone. Additionally, the flexible fabric bag state constantly changes during operation, so the robot needs to dynamically respond to the change. However, the appropriate robot behavior for all bag states is difficult to prepare in advance. To solve this problem, we developed a model that can perform contact-rich flexible object manipulation by real-time prediction of vision with tactility. We introduced a point-based attention mechanism for extracting image features, softmax transformation for predicting motions, and convolutional neural network for extracting tactile features. The results of experiments using a real robot arm revealed that our method can realize motions responding to the deformation of the bag while reducing the load on the zipper. Furthermore, using tactility improved the success rate from 56.7% to 93.3% compared with vision alone, demonstrating the effectiveness and high performance of our method.
Pretraining Image Encoders without Reconstruction via Feature Prediction Loss
Mar 16, 2020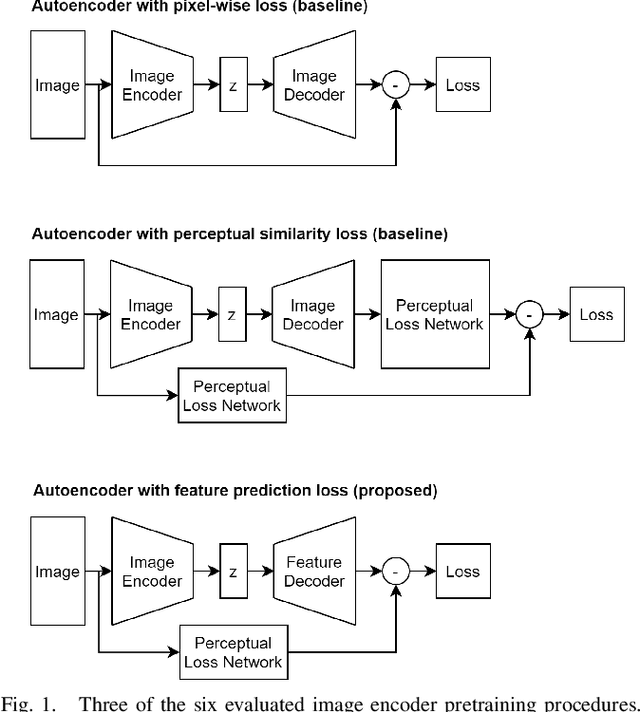
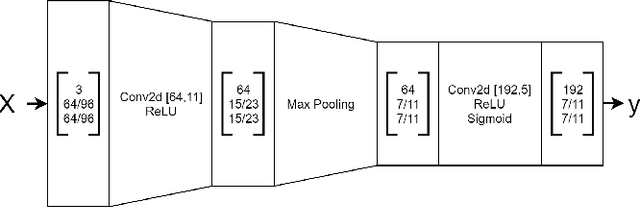

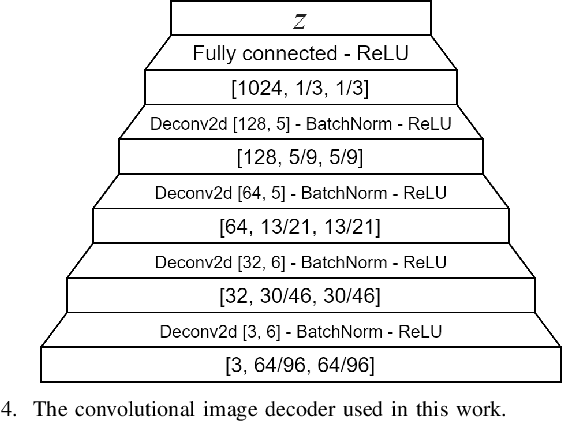
This work investigates three different loss functions for autoencoder-based pretraining of image encoders: The commonly used reconstruction loss, the more recently introduced perceptual similarity loss, and a feature prediction loss proposed here; the latter turning out to be the most efficient choice. Former work shows that predictions based on embeddings generated by image autoencoders can be improved by training with perceptual loss. So far the autoencoders trained with perceptual loss networks implemented an explicit comparison of the original and reconstructed images using the loss network. However, given such a loss network we show that there is no need for the timeconsuming task of decoding the entire image. Instead, we propose to decode the features of the loss network, hence the name "feature prediction loss". To evaluate this method we compare six different procedures for training image encoders based on pixel-wise, perceptual similarity, and feature prediction loss. The embedding-based prediction results show that encoders trained with feature prediction loss is as good or better than those trained with the other two losses. Additionally, the encoder is significantly faster to train using feature prediction loss in comparison to the other losses. The method implementation used in this work is available online: https://github.com/guspih/Perceptual-Autoencoders
Spectral Complexity-scaled Generalization Bound of Complex-valued Neural Networks
Dec 07, 2021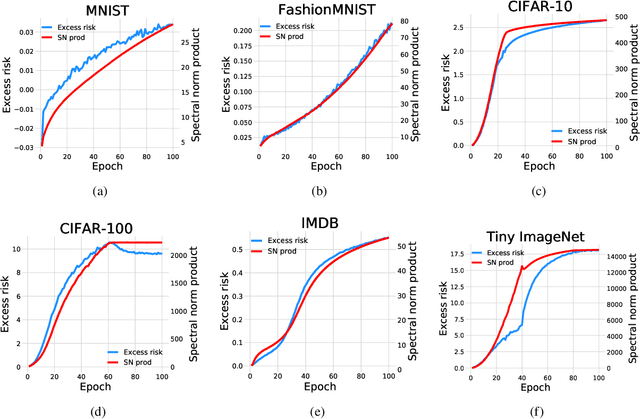
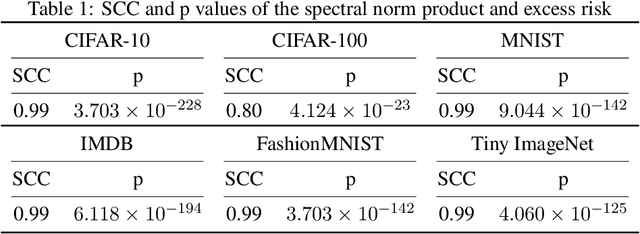
Complex-valued neural networks (CVNNs) have been widely applied to various fields, especially signal processing and image recognition. However, few works focus on the generalization of CVNNs, albeit it is vital to ensure the performance of CVNNs on unseen data. This paper is the first work that proves a generalization bound for the complex-valued neural network. The bound scales with the spectral complexity, the dominant factor of which is the spectral norm product of weight matrices. Further, our work provides a generalization bound for CVNNs when training data is sequential, which is also affected by the spectral complexity. Theoretically, these bounds are derived via Maurey Sparsification Lemma and Dudley Entropy Integral. Empirically, we conduct experiments by training complex-valued convolutional neural networks on different datasets: MNIST, FashionMNIST, CIFAR-10, CIFAR-100, Tiny ImageNet, and IMDB. Spearman's rank-order correlation coefficients and the corresponding p values on these datasets give strong proof that the spectral complexity of the network, measured by the weight matrices spectral norm product, has a statistically significant correlation with the generalization ability.
Learning Hierarchical Graph Neural Networks for Image Clustering
Jul 03, 2021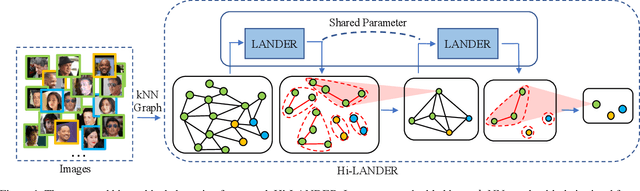
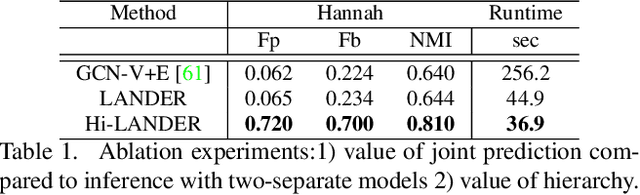
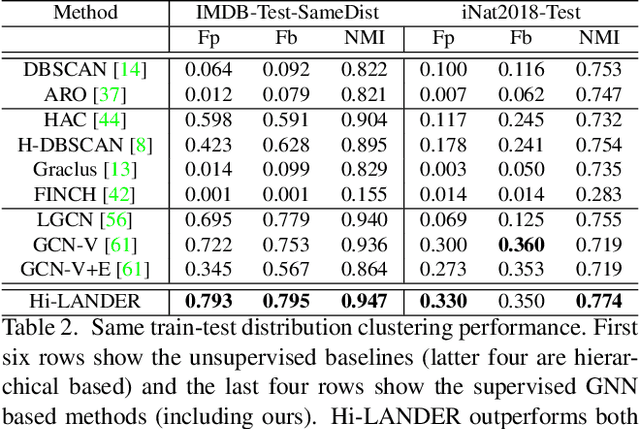
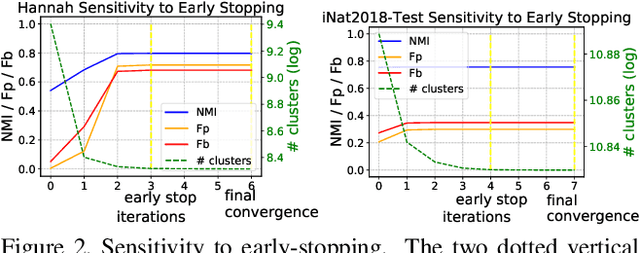
We propose a hierarchical graph neural network (GNN) model that learns how to cluster a set of images into an unknown number of identities using a training set of images annotated with labels belonging to a disjoint set of identities. Our hierarchical GNN uses a novel approach to merge connected components predicted at each level of the hierarchy to form a new graph at the next level. Unlike fully unsupervised hierarchical clustering, the choice of grouping and complexity criteria stems naturally from supervision in the training set. The resulting method, Hi-LANDER, achieves an average of 54% improvement in F-score and 8% increase in Normalized Mutual Information (NMI) relative to current GNN-based clustering algorithms. Additionally, state-of-the-art GNN-based methods rely on separate models to predict linkage probabilities and node densities as intermediate steps of the clustering process. In contrast, our unified framework achieves a seven-fold decrease in computational cost. We release our training and inference code at https://github.com/dmlc/dgl/tree/master/examples/pytorch/hilander.
Deep Level Set for Box-supervised Instance Segmentation in Aerial Images
Dec 07, 2021
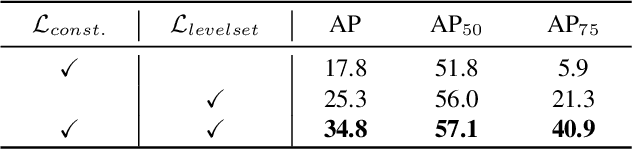
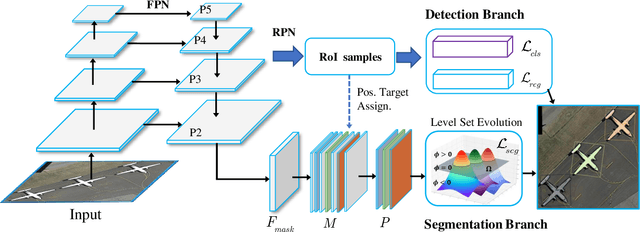
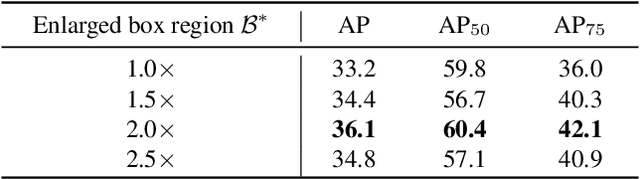
Box-supervised instance segmentation has recently attracted lots of research efforts while little attention is received in aerial image domain. In contrast to the general object collections, aerial objects have large intra-class variances and inter-class similarity with complex background. Moreover, there are many tiny objects in the high-resolution satellite images. This makes the recent pairwise affinity modeling method inevitably to involve the noisy supervision with the inferior results. To tackle these problems, we propose a novel aerial instance segmentation approach, which drives the network to learn a series of level set functions for the aerial objects with only box annotations in an end-to-end fashion. Instead of learning the pairwise affinity, the level set method with the carefully designed energy functions treats the object segmentation as curve evolution, which is able to accurately recover the object's boundaries and prevent the interference from the indistinguishable background and similar objects. The experimental results demonstrate that the proposed approach outperforms the state-of-the-art box-supervised instance segmentation methods. The source code is available at https://github.com/LiWentomng/boxlevelset.