 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantic-Based Few-Shot Learning by Interactive Psychometric Testing
Dec 16, 2021
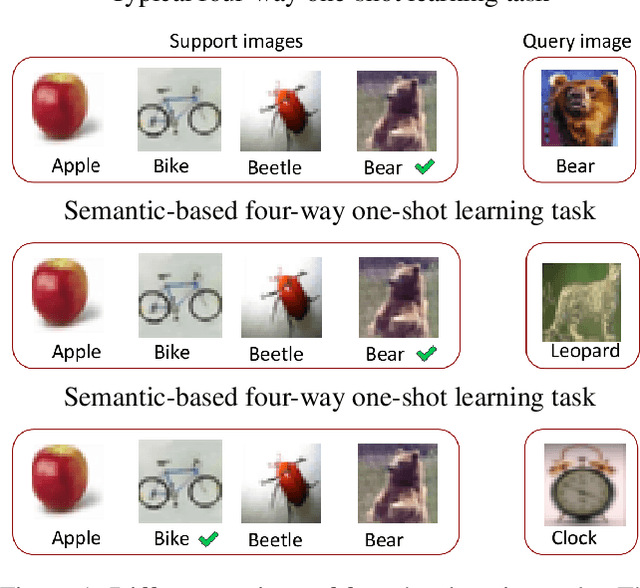

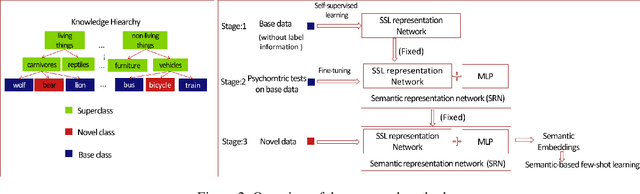

Few-shot classification tasks aim to classify images in query sets based on only a few labeled examples in support sets. Most studies usually assume that each image in a task has a single and unique class association. Under these assumptions, these algorithms may not be able to identify the proper class assignment when there is no exact matching between support and query classes. For example, given a few images of lions, bikes, and apples to classify a tiger. However, in a more general setting, we could consider the higher-level concept of large carnivores to match the tiger to the lion for semantic classification. Existing studies rarely considered this situation due to the incompatibility of label-based supervision with complex conception relationships. In this work, we advanced the few-shot learning towards this more challenging scenario, the semantic-based few-shot learning, and proposed a method to address the paradigm by capturing the inner semantic relationships using interactive psychometric learning. We evaluate our method on the CIFAR-100 dataset. The results show the merits of our proposed method.
Pyramid Fusion Transformer for Semantic Segmentation
Jan 11, 2022
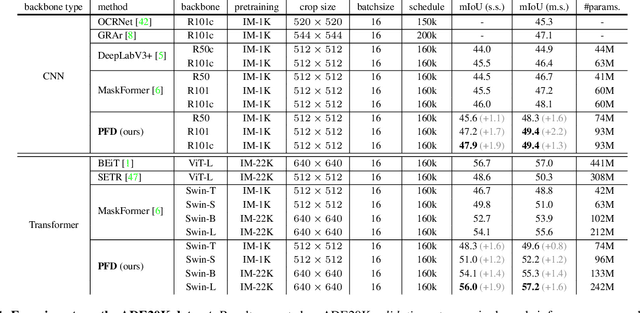
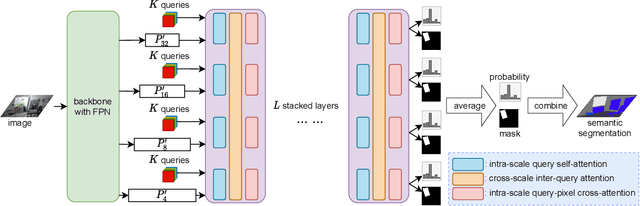
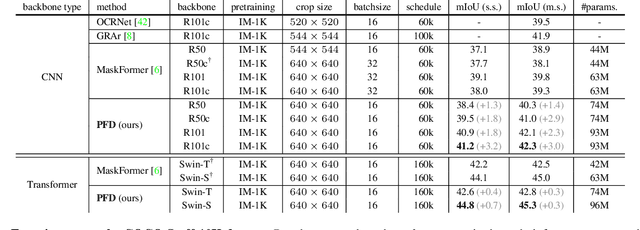
The recently proposed MaskFormer \cite{maskformer} gives a refreshed perspective on the task of semantic segmentation: it shifts from the popular pixel-level classification paradigm to a mask-level classification method. In essence, it generates paired probabilities and masks corresponding to category segments and combines them during inference for the segmentation maps. The segmentation quality thus relies on how well the queries can capture the semantic information for categories and their spatial locations within the images. In our study, we find that per-mask classification decoder on top of a single-scale feature is not effective enough to extract reliable probability or mask. To mine for rich semantic information across the feature pyramid, we propose a transformer-based Pyramid Fusion Transformer (PFT) for per-mask approach semantic segmentation on top of multi-scale features. To efficiently utilize image features of different resolutions without incurring too much computational overheads, PFT uses a multi-scale transformer decoder with cross-scale inter-query attention to exchange complimentary information. Extensive experimental evaluations and ablations demonstrate the efficacy of our framework. In particular, we achieve a 3.2 mIoU improvement on COCO-Stuff 10K dataset with ResNet-101c compared to MaskFormer. Besides, on ADE20K validation set, our result with Swin-B backbone matches that of MaskFormer's with a much larger Swin-L backbone in both single-scale and multi-scale inference, achieving 54.1 mIoU and 55.3 mIoU respectively. Using a Swin-L backbone, we achieve 56.0 mIoU single-scale result on the ADE20K validation set and 57.2 multi-scale result, obtaining state-of-the-art performance on the dataset.
Groupwise Multimodal Image Registration using Joint Total Variation
May 06, 2020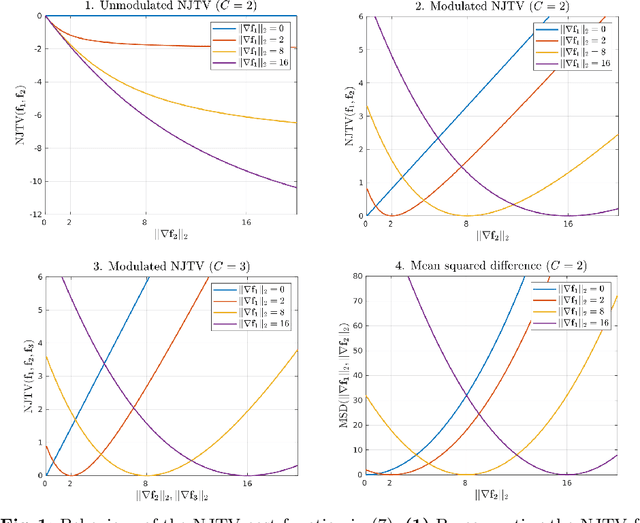

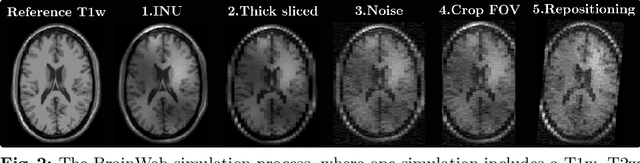
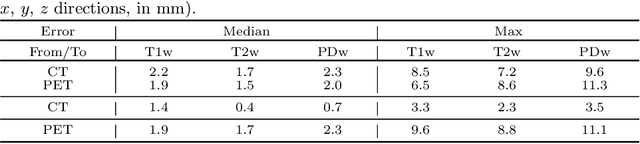
In medical imaging it is common practice to acquire a wide range of modalities (MRI, CT, PET, etc.), to highlight different structures or pathologies. As patient movement between scans or scanning session is unavoidable, registration is often an essential step before any subsequent image analysis. In this paper, we introduce a cost function based on joint total variation for such multimodal image registration. This cost function has the advantage of enabling principled, groupwise alignment of multiple images, whilst being insensitive to strong intensity non-uniformities. We evaluate our algorithm on rigidly aligning both simulated and real 3D brain scans. This validation shows robustness to strong intensity non-uniformities and low registration errors for CT/PET to MRI alignment. Our implementation is publicly available at https://github.com/brudfors/coregistration-njtv.
Overview of the HECKTOR Challenge at MICCAI 2021: Automatic Head and Neck Tumor Segmentation and Outcome Prediction in PET/CT Images
Jan 11, 2022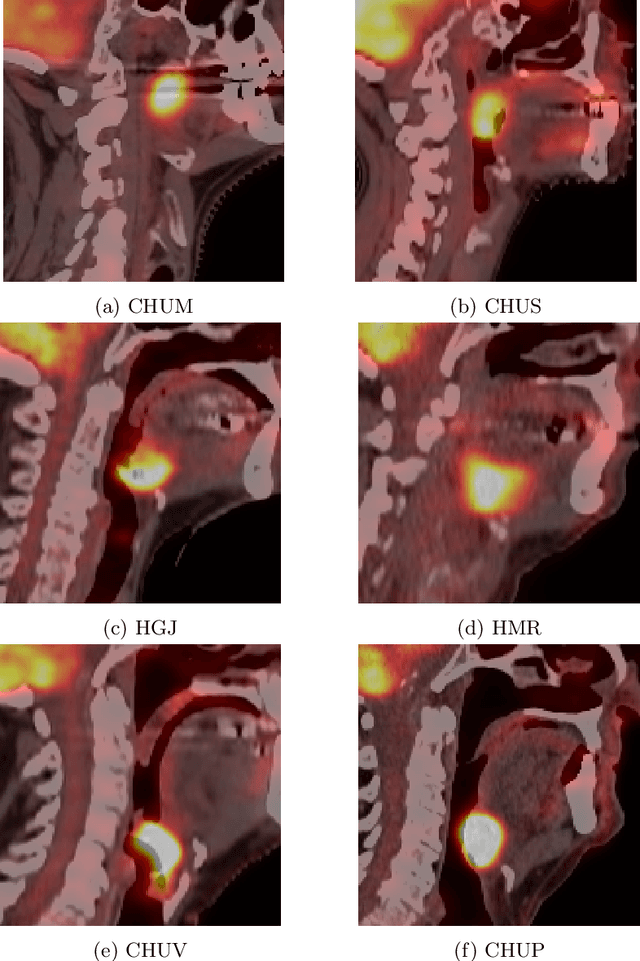
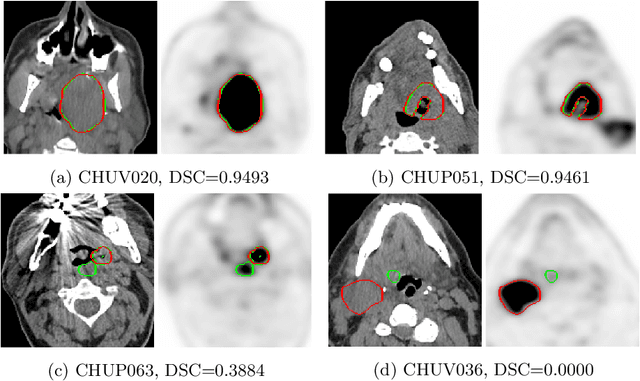
This paper presents an overview of the second edition of the HEad and neCK TumOR (HECKTOR) challenge, organized as a satellite event of the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) 2021. The challenge is composed of three tasks related to the automatic analysis of PET/CT images for patients with Head and Neck cancer (H&N), focusing on the oropharynx region. Task 1 is the automatic segmentation of H&N primary Gross Tumor Volume (GTVt) in FDG-PET/CT images. Task 2 is the automatic prediction of Progression Free Survival (PFS) from the same FDG-PET/CT. Finally, Task 3 is the same as Task 2 with ground truth GTVt annotations provided to the participants. The data were collected from six centers for a total of 325 images, split into 224 training and 101 testing cases. The interest in the challenge was highlighted by the important participation with 103 registered teams and 448 result submissions. The best methods obtained a Dice Similarity Coefficient (DSC) of 0.7591 in the first task, and a Concordance index (C-index) of 0.7196 and 0.6978 in Tasks 2 and 3, respectively. In all tasks, simplicity of the approach was found to be key to ensure generalization performance. The comparison of the PFS prediction performance in Tasks 2 and 3 suggests that providing the GTVt contour was not crucial to achieve best results, which indicates that fully automatic methods can be used. This potentially obviates the need for GTVt contouring, opening avenues for reproducible and large scale radiomics studies including thousands potential subjects.
Coarse-to-Fine Reasoning for Visual Question Answering
Oct 06, 2021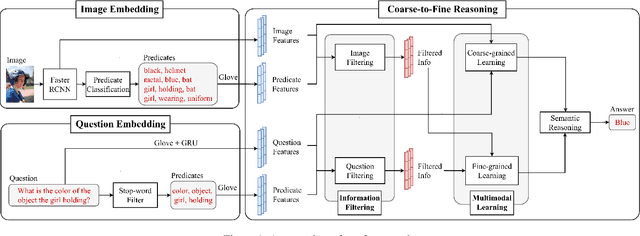
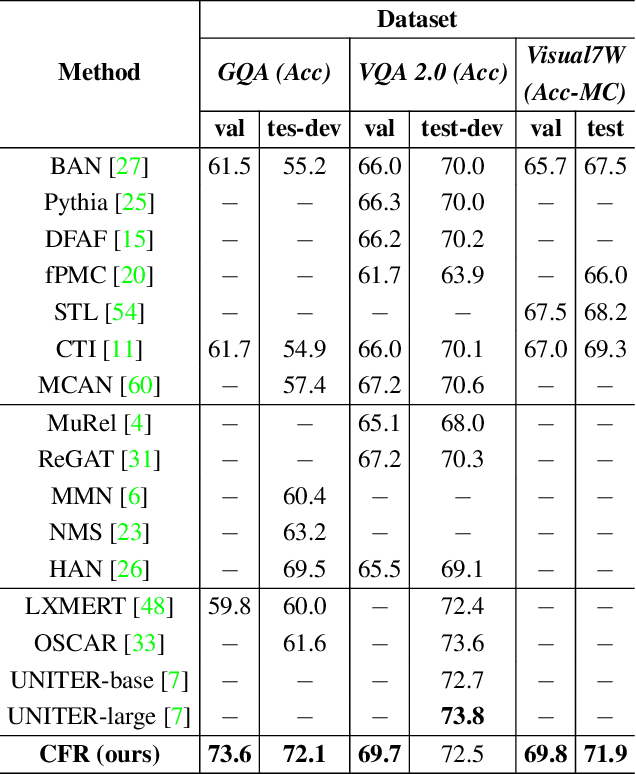
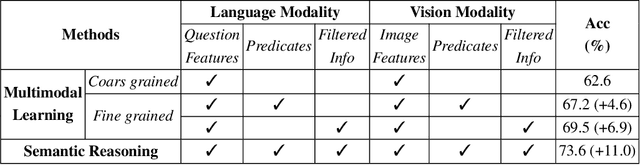
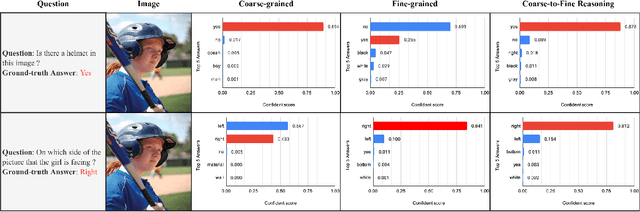
Bridging the semantic gap between image and question is an important step to improve the accuracy of the Visual Question Answering (VQA) task. However, most of the existing VQA methods focus on attention mechanisms or visual relations for reasoning the answer, while the features at different semantic levels are not fully utilized. In this paper, we present a new reasoning framework to fill the gap between visual features and semantic clues in the VQA task. Our method first extracts the features and predicates from the image and question. We then propose a new reasoning framework to effectively jointly learn these features and predicates in a coarse-to-fine manner. The intensively experimental results on three large-scale VQA datasets show that our proposed approach achieves superior accuracy comparing with other state-of-the-art methods. Furthermore, our reasoning framework also provides an explainable way to understand the decision of the deep neural network when predicting the answer.
High Fidelity Visualization of What Your Self-Supervised Representation Knows About
Dec 16, 2021


Discovering what is learned by neural networks remains a challenge. In self-supervised learning, classification is the most common task used to evaluate how good a representation is. However, relying only on such downstream task can limit our understanding of how much information is retained in the representation of a given input. In this work, we showcase the use of a conditional diffusion based generative model (RCDM) to visualize representations learned with self-supervised models. We further demonstrate how this model's generation quality is on par with state-of-the-art generative models while being faithful to the representation used as conditioning. By using this new tool to analyze self-supervised models, we can show visually that i) SSL (backbone) representation are not really invariant to many data augmentation they were trained on. ii) SSL projector embedding appear too invariant for tasks like classifications. iii) SSL representations are more robust to small adversarial perturbation of their inputs iv) there is an inherent structure learned with SSL model that can be used for image manipulation.
Deep learning and hand-crafted features for virus image classification
Nov 11, 2020
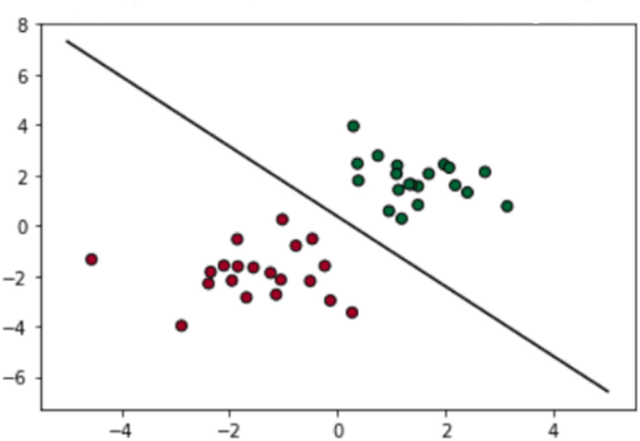
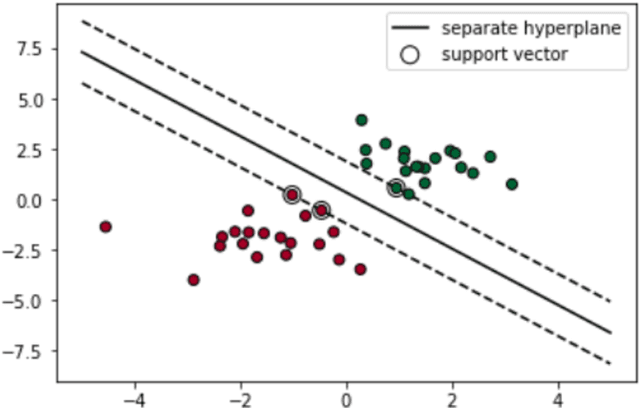
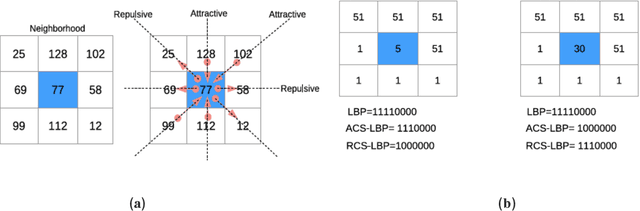
In this work, we present an ensemble of descriptors for the classification of transmission electron microscopy images of viruses. We propose to combine handcrafted and deep learning approaches for virus image classification. The set of handcrafted is mainly based on Local Binary Pattern variants, for each descriptor a different Support Vector Machine is trained, then the set of classifiers is combined by sum rule. The deep learning approach is a densenet201 pretrained on ImageNet and then tuned in the virus dataset, the net is used as features extractor for feeding another Support Vector Machine, in particular the last average pooling layer is used as feature extractor. Finally, classifiers trained on handcrafted features and classifier trained on deep learning features are combined by sum rule. The proposed fusion strongly boosts the performance obtained by each stand-alone approach, obtaining state of the art performance.
GeneAnnotator: A Semi-automatic Annotation Tool for Visual Scene Graph
Sep 06, 2021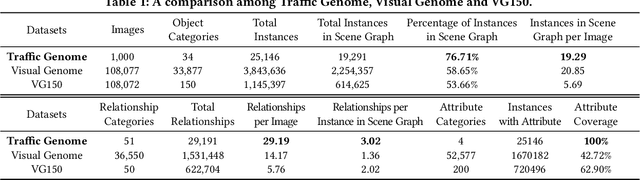
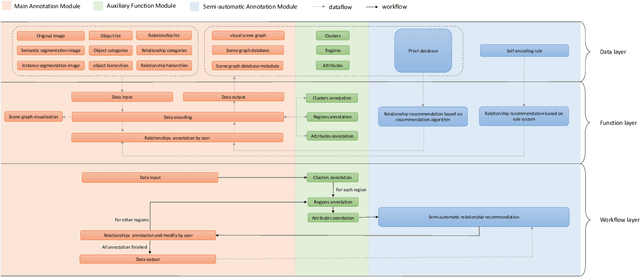
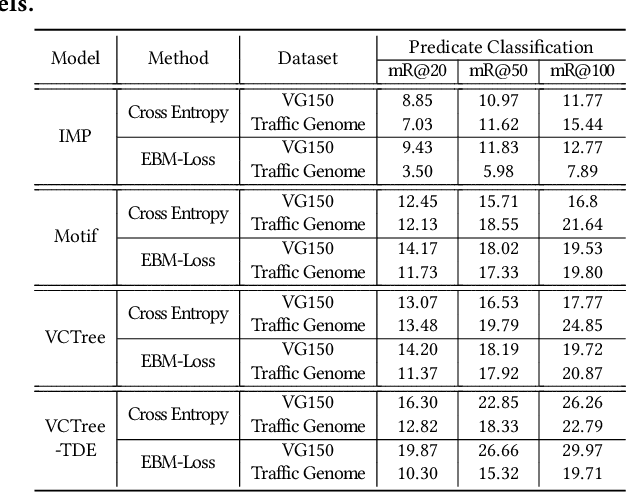
In this manuscript, we introduce a semi-automatic scene graph annotation tool for images, the GeneAnnotator. This software allows human annotators to describe the existing relationships between participators in the visual scene in the form of directed graphs, hence enabling the learning and reasoning on visual relationships, e.g., image captioning, VQA and scene graph generation, etc. The annotations for certain image datasets could either be merged in a single VG150 data-format file to support most existing models for scene graph learning or transformed into a separated annotation file for each single image to build customized datasets. Moreover, GeneAnnotator provides a rule-based relationship recommending algorithm to reduce the heavy annotation workload. With GeneAnnotator, we propose Traffic Genome, a comprehensive scene graph dataset with 1000 diverse traffic images, which in return validates the effectiveness of the proposed software for scene graph annotation. The project source code, with usage examples and sample data is available at https://github.com/Milomilo0320/A-Semi-automatic-Annotation-Software-for-Scene-Graph, under the Apache open-source license.
Talking Head Generation with Audio and Speech Related Facial Action Units
Oct 19, 2021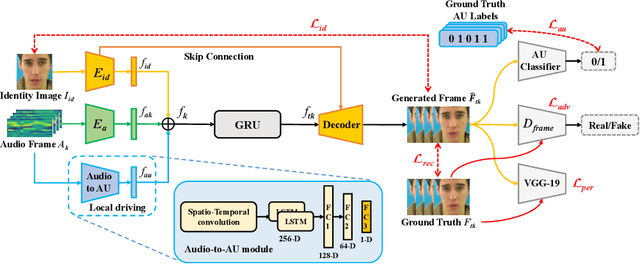
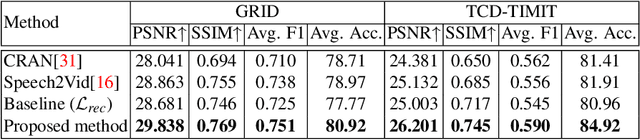


The task of talking head generation is to synthesize a lip synchronized talking head video by inputting an arbitrary face image and audio clips. Most existing methods ignore the local driving information of the mouth muscles. In this paper, we propose a novel recurrent generative network that uses both audio and speech-related facial action units (AUs) as the driving information. AU information related to the mouth can guide the movement of the mouth more accurately. Since speech is highly correlated with speech-related AUs, we propose an Audio-to-AU module in our system to predict the speech-related AU information from speech. In addition, we use AU classifier to ensure that the generated images contain correct AU information. Frame discriminator is also constructed for adversarial training to improve the realism of the generated face. We verify the effectiveness of our model on the GRID dataset and TCD-TIMIT dataset. We also conduct an ablation study to verify the contribution of each component in our model. Quantitative and qualitative experiments demonstrate that our method outperforms existing methods in both image quality and lip-sync accuracy.
Fine-grained Multi-Modal Self-Supervised Learning
Dec 22, 2021
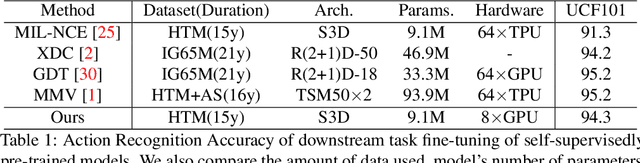
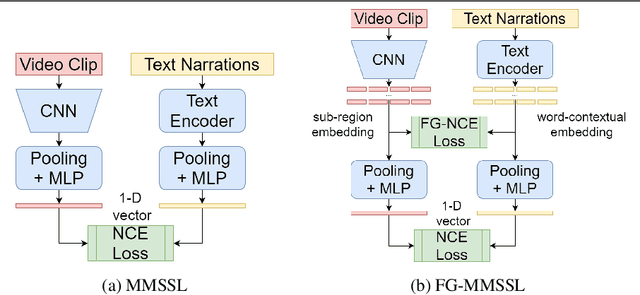

Multi-Modal Self-Supervised Learning from videos has been shown to improve model's performance on various downstream tasks. However, such Self-Supervised pre-training requires large batch sizes and a large amount of computation resources due to the noise present in the uncurated data. This is partly due to the fact that the prevalent training scheme is trained on coarse-grained setting, in which vectors representing the whole video clips or natural language sentences are used for computing similarity. Such scheme makes training noisy as part of the video clips can be totally not correlated with the other-modality input such as text description. In this paper, we propose a fine-grained multi-modal self-supervised training scheme that computes the similarity between embeddings at finer-scale (such as individual feature map embeddings and embeddings of phrases), and uses attention mechanisms to reduce noisy pairs' weighting in the loss function. We show that with the proposed pre-training scheme, we can train smaller models, with smaller batch-size and much less computational resources to achieve downstream tasks performances comparable to State-Of-The-Art, for tasks including action recognition and text-image retrievals.