 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Normalized and Geometry-Aware Self-Attention Network for Image Captioning
Mar 19, 2020
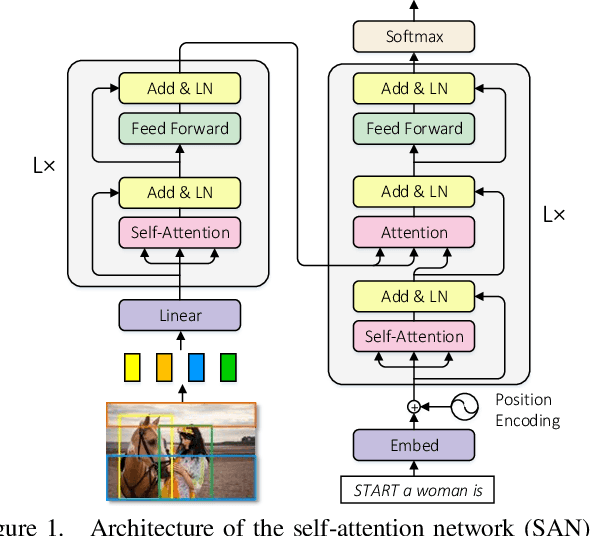
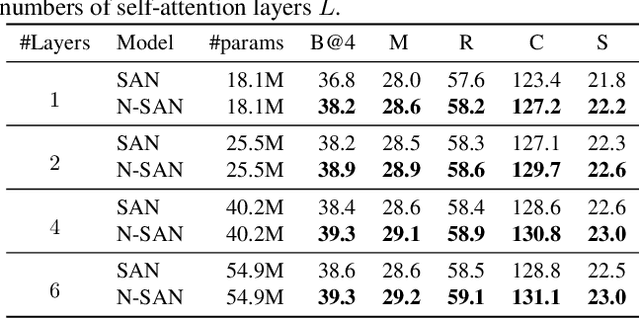
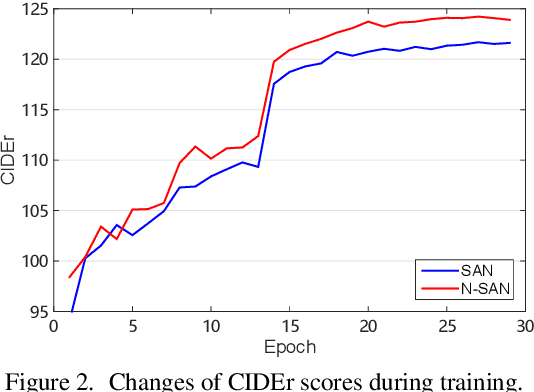
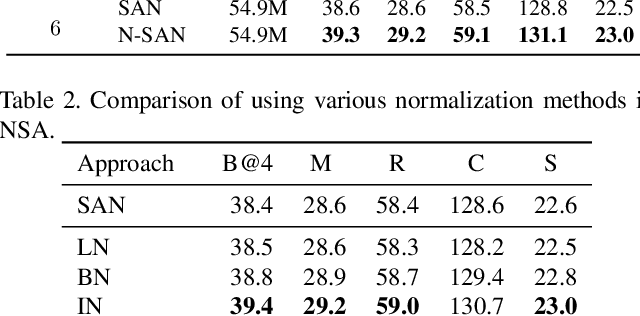
Self-attention (SA) network has shown profound value in image captioning. In this paper, we improve SA from two aspects to promote the performance of image captioning. First, we propose Normalized Self-Attention (NSA), a reparameterization of SA that brings the benefits of normalization inside SA. While normalization is previously only applied outside SA, we introduce a novel normalization method and demonstrate that it is both possible and beneficial to perform it on the hidden activations inside SA. Second, to compensate for the major limit of Transformer that it fails to model the geometry structure of the input objects, we propose a class of Geometry-aware Self-Attention (GSA) that extends SA to explicitly and efficiently consider the relative geometry relations between the objects in the image. To construct our image captioning model, we combine the two modules and apply it to the vanilla self-attention network. We extensively evaluate our proposals on MS-COCO image captioning dataset and superior results are achieved when comparing to state-of-the-art approaches. Further experiments on three challenging tasks, i.e. video captioning, machine translation, and visual question answering, show the generality of our methods.
Deep Low-Shot Learning for Biological Image Classification and Visualization from Limited Training Samples
Oct 20, 2020
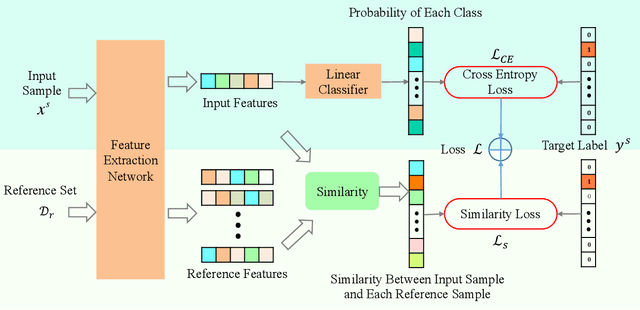
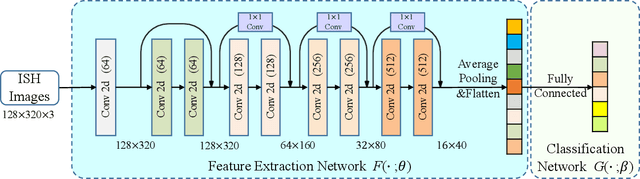
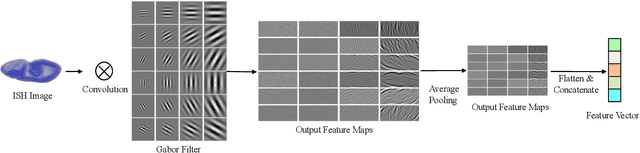
Predictive modeling is useful but very challenging in biological image analysis due to the high cost of obtaining and labeling training data. For example, in the study of gene interaction and regulation in Drosophila embryogenesis, the analysis is most biologically meaningful when in situ hybridization (ISH) gene expression pattern images from the same developmental stage are compared. However, labeling training data with precise stages is very time-consuming even for evelopmental biologists. Thus, a critical challenge is how to build accurate computational models for precise developmental stage classification from limited training samples. In addition, identification and visualization of developmental landmarks are required to enable biologists to interpret prediction results and calibrate models. To address these challenges, we propose a deep two-step low-shot learning framework to accurately classify ISH images using limited training images. Specifically, to enable accurate model training on limited training samples, we formulate the task as a deep low-shot learning problem and develop a novel two-step learning approach, including data-level learning and feature-level learning. We use a deep residual network as our base model and achieve improved performance in the precise stage prediction task of ISH images. Furthermore, the deep model can be interpreted by computing saliency maps, which consist of pixel-wise contributions of an image to its prediction result. In our task, saliency maps are used to assist the identification and visualization of developmental landmarks. Our experimental results show that the proposed model can not only make accurate predictions, but also yield biologically meaningful interpretations. We anticipate our methods to be easily generalizable to other biological image classification tasks with small training datasets.
Multi-Attributed and Structured Text-to-Face Synthesis
Aug 25, 2021
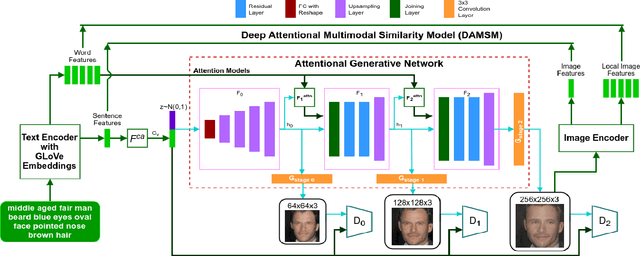
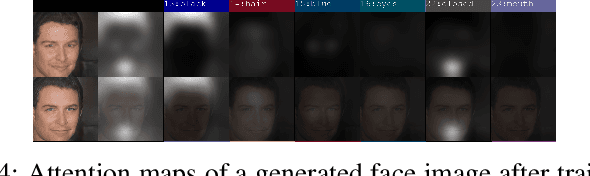
Generative Adversarial Networks (GANs) have revolutionized image synthesis through many applications like face generation, photograph editing, and image super-resolution. Image synthesis using GANs has predominantly been uni-modal, with few approaches that can synthesize images from text or other data modes. Text-to-image synthesis, especially text-to-face synthesis, has promising use cases of robust face-generation from eye witness accounts and augmentation of the reading experience with visual cues. However, only a couple of datasets provide consolidated face data and textual descriptions for text-to-face synthesis. Moreover, these textual annotations are less extensive and descriptive, which reduces the diversity of faces generated from it. This paper empirically proves that increasing the number of facial attributes in each textual description helps GANs generate more diverse and real-looking faces. To prove this, we propose a new methodology that focuses on using structured textual descriptions. We also consolidate a Multi-Attributed and Structured Text-to-face (MAST) dataset consisting of high-quality images with structured textual annotations and make it available to researchers to experiment and build upon. Lastly, we report benchmark Frechet's Inception Distance (FID), Facial Semantic Similarity (FSS), and Facial Semantic Distance (FSD) scores for the MAST dataset.
Image Aesthetics Prediction Using Multiple Patches Preserving the Original Aspect Ratio of Contents
Jul 05, 2020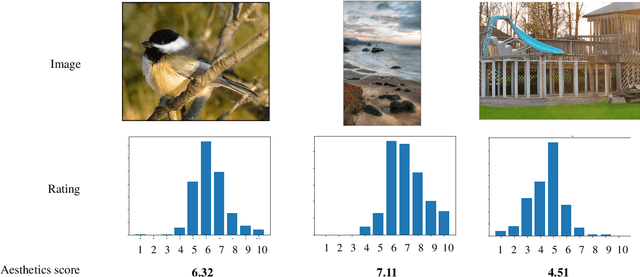
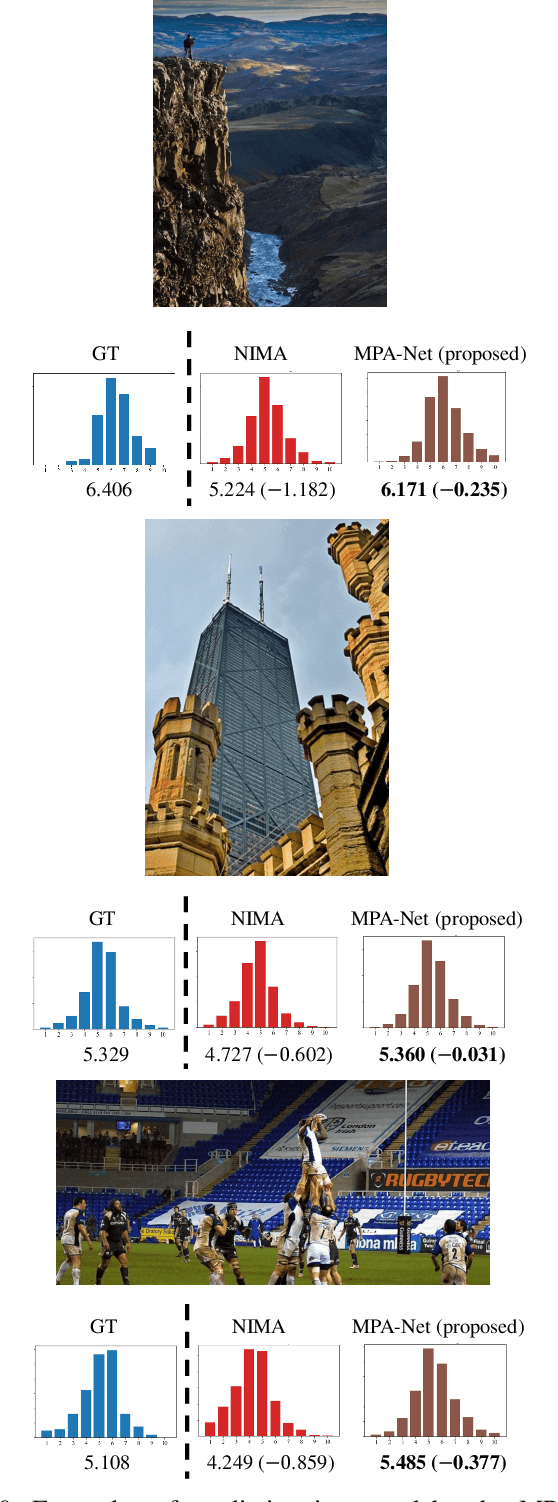
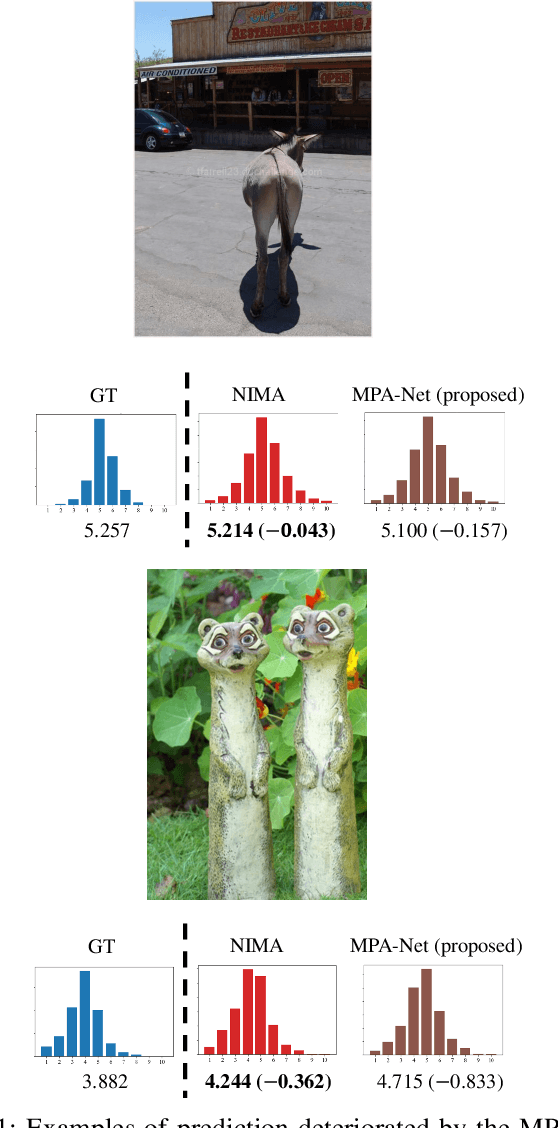
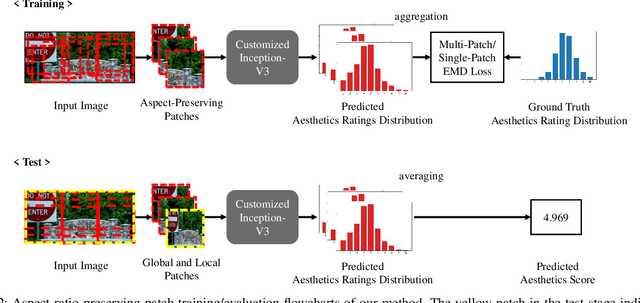
The spread of social networking services has created an increasing demand for selecting, editing, and generating impressive images. This trend increases the importance of evaluating image aesthetics as a complementary function of automatic image processing. We propose a multi-patch method, named MPA-Net (Multi-Patch Aggregation Network), to predict image aesthetics scores by maintaining the original aspect ratios of contents in the images. Through an experiment involving the large-scale AVA dataset, which contains 250,000 images, we show that the effectiveness of the equal-interval multi-patch selection approach for aesthetics score prediction is significant compared to the single-patch prediction and random patch selection approaches. For this dataset, MPA-Net outperforms the neural image assessment algorithm, which was regarded as a baseline method. In particular, MPA-Net yields a 0.073 (11.5%) higher linear correlation coefficient (LCC) of aesthetics scores and a 0.088 (14.4%) higher Spearman's rank correlation coefficient (SRCC). MPA-Net also reduces the mean square error (MSE) by 0.0115 (4.18%) and achieves results for the LCC and SRCC that are comparable to those of the state-of-the-art continuous aesthetics score prediction methods. Most notably, MPA-Net yields a significant lower MSE especially for images with aspect ratios far from 1.0, indicating that MPA-Net is useful for a wide range of image aspect ratios. MPA-Net uses only images and does not require external information during the training nor prediction stages. Therefore, MPA-Net has great potential for applications aside from aesthetics score prediction such as other human subjectivity prediction.
Traversing within the Gaussian Typical Set: Differentiable Gaussianization Layers for Inverse Problems Augmented by Normalizing Flows
Dec 07, 2021
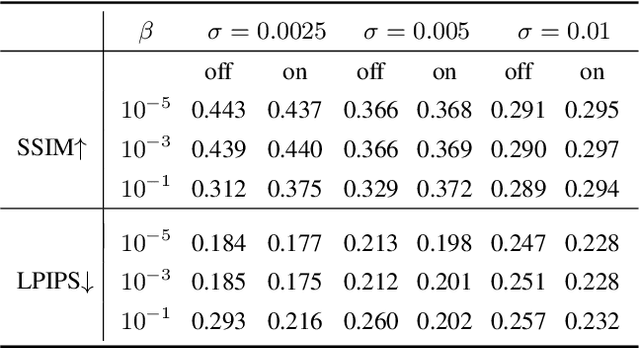
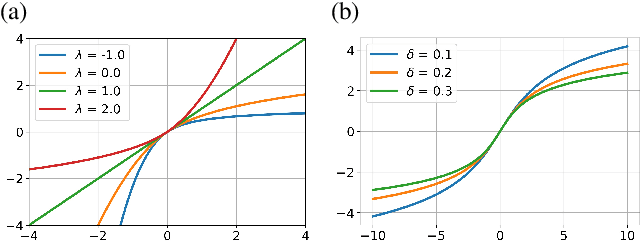
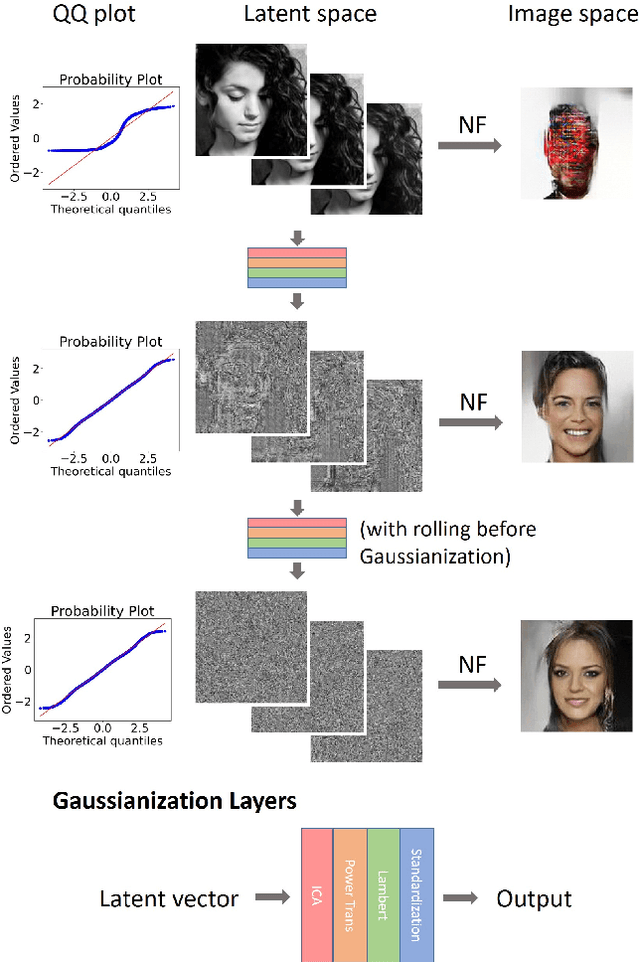
Generative networks such as normalizing flows can serve as a learning-based prior to augment inverse problems to achieve high-quality results. However, the latent space vector may not remain a typical sample from the desired high-dimensional standard Gaussian distribution when traversing the latent space during an inversion. As a result, it can be challenging to attain a high-fidelity solution, particularly in the presence of noise and inaccurate physics-based models. To address this issue, we propose to re-parameterize and Gaussianize the latent vector using novel differentiable data-dependent layers wherein custom operators are defined by solving optimization problems. These proposed layers enforce an inversion to find a feasible solution within a Gaussian typical set of the latent space. We tested and validated our technique on an image deblurring task and eikonal tomography -- a PDE-constrained inverse problem and achieved high-fidelity results.
A tool for user friendly, cloud based, whole slide image segmentation
Jan 18, 2021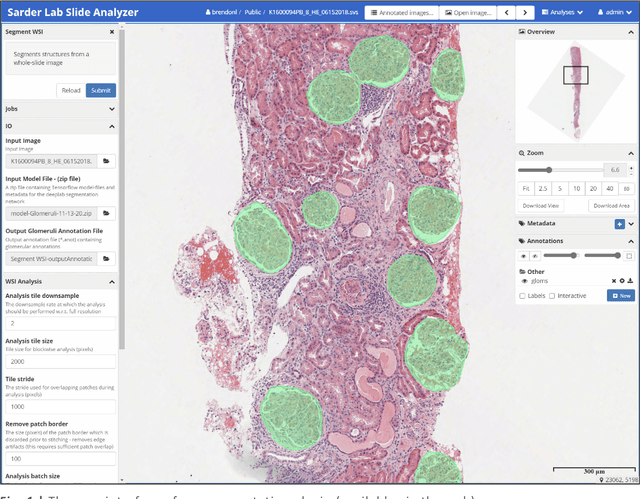
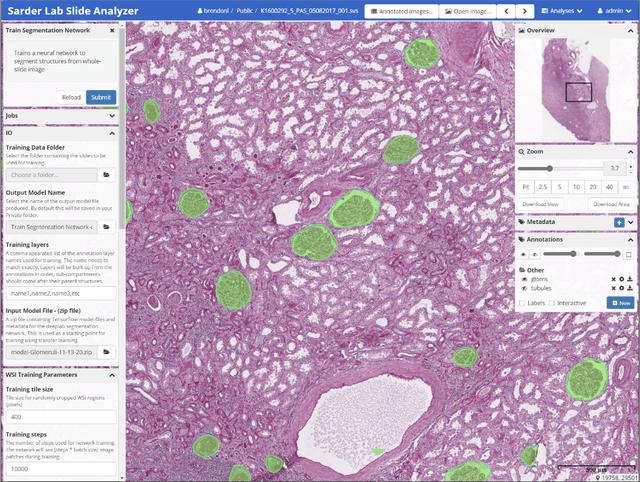
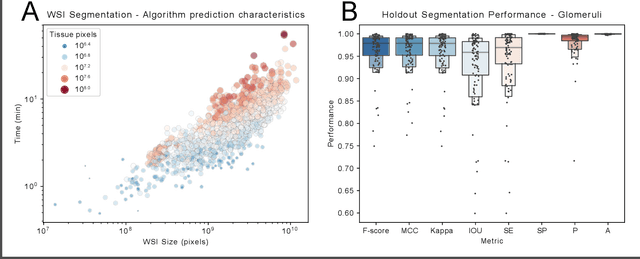
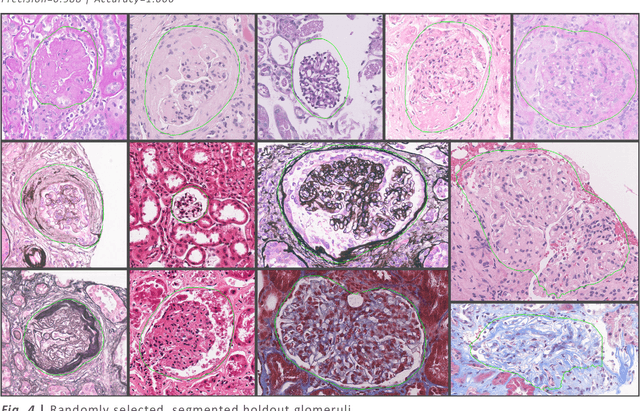
Convolutional neural networks, the state of the art for image segmentation, have been successfully applied to histology images by many computational researchers. However, the translatability of this technology to clinicians and biological researchers is limited due to the complex and undeveloped user interface of the code, as well as the extensive computer setup required. As an extension of our previous work (arXiv:1812.07509), we have developed a tool for segmentation of whole slide images (WSIs) with an easy to use graphical user interface. Our tool runs a state-of-the-art convolutional neural network for segmentation of WSIs in the cloud. Our plugin is built on the open source tool HistomicsTK by Kitware Inc. (Clifton Park, NY), which provides remote data management and viewing abilities for WSI datasets. The ability to access this tool over the internet will facilitate widespread use by computational non-experts. Users can easily upload slides to a server where our plugin is installed and perform human in the loop segmentation analysis remotely. This tool is open source, and has the ability to be adapted to segment of any pathological structure. For a proof of concept, we have trained it to segment glomeruli from renal tissue images, achieving an F-score > 0.97 on holdout tissue slides.
Semi-supervised Hyperspectral Image Classification with Graph Clustering Convolutional Networks
Dec 20, 2020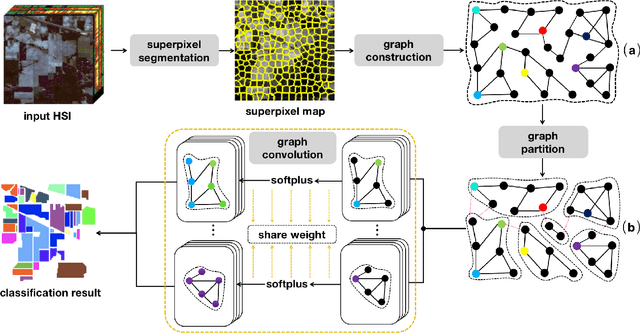
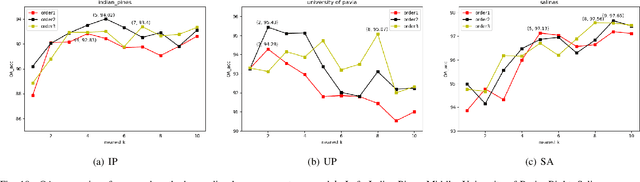
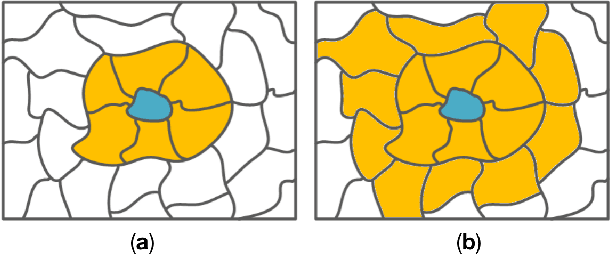

Hyperspectral image classification (HIC) is an important but challenging task, and a problem that limits the algorithmic development in this field is that the ground truths of hyperspectral images (HSIs) are extremely hard to obtain. Recently a handful of HIC methods are developed based on the graph convolution networks (GCNs), which effectively relieves the scarcity of labeled data for deep learning based HIC methods. To further lift the classification performance, in this work we propose a graph convolution network (GCN) based framework for HSI classification that uses two clustering operations to better exploit multi-hop node correlations and also effectively reduce graph size. In particular, we first cluster the pixels with similar spectral features into a superpixel and build the graph based on the superpixels of the input HSI. Then instead of performing convolution over this superpixel graph, we further partition it into several sub-graphs by pruning the edges with weak weights, so as to strengthen the correlations of nodes with high similarity. This second round of clustering also further reduces the graph size, thus reducing the computation burden of graph convolution. Experimental results on three widely used benchmark datasets well prove the effectiveness of our proposed framework.
Virtual Multi-Modality Self-Supervised Foreground Matting for Human-Object Interaction
Oct 07, 2021
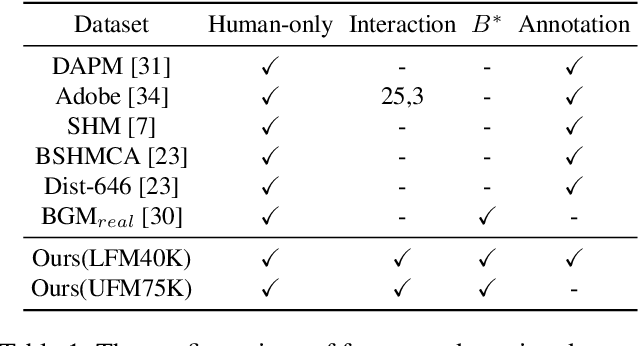
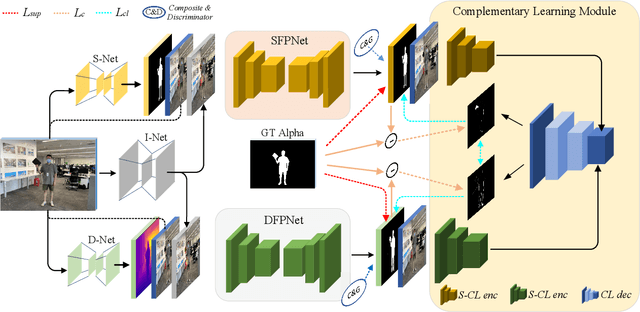
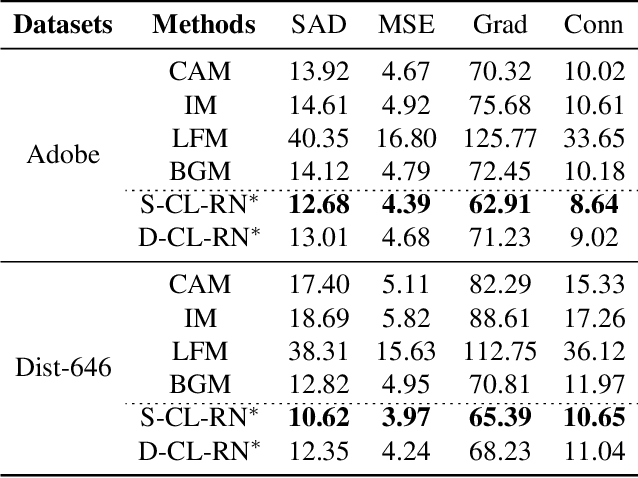
Most existing human matting algorithms tried to separate pure human-only foreground from the background. In this paper, we propose a Virtual Multi-modality Foreground Matting (VMFM) method to learn human-object interactive foreground (human and objects interacted with him or her) from a raw RGB image. The VMFM method requires no additional inputs, e.g. trimap or known background. We reformulate foreground matting as a self-supervised multi-modality problem: factor each input image into estimated depth map, segmentation mask, and interaction heatmap using three auto-encoders. In order to fully utilize the characteristics of each modality, we first train a dual encoder-to-decoder network to estimate the same alpha matte. Then we introduce a self-supervised method: Complementary Learning(CL) to predict deviation probability map and exchange reliable gradients across modalities without label. We conducted extensive experiments to analyze the effectiveness of each modality and the significance of different components in complementary learning. We demonstrate that our model outperforms the state-of-the-art methods.
3D Pose Estimation and Future Motion Prediction from 2D Images
Nov 26, 2021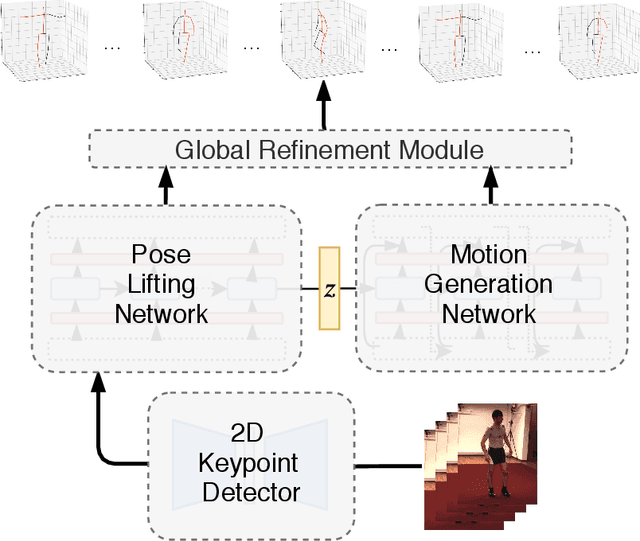
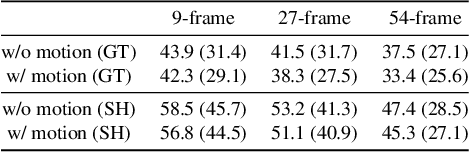
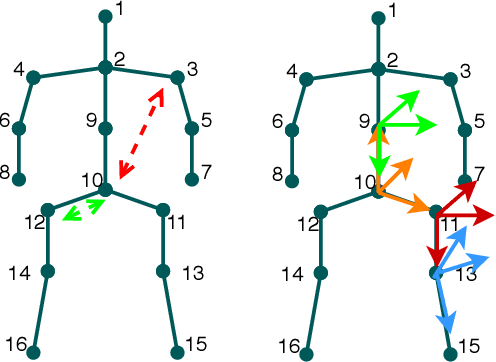

This paper considers to jointly tackle the highly correlated tasks of estimating 3D human body poses and predicting future 3D motions from RGB image sequences. Based on Lie algebra pose representation, a novel self-projection mechanism is proposed that naturally preserves human motion kinematics. This is further facilitated by a sequence-to-sequence multi-task architecture based on an encoder-decoder topology, which enables us to tap into the common ground shared by both tasks. Finally, a global refinement module is proposed to boost the performance of our framework. The effectiveness of our approach, called PoseMoNet, is demonstrated by ablation tests and empirical evaluations on Human3.6M and HumanEva-I benchmark, where competitive performance is obtained comparing to the state-of-the-arts.
Video Instance Segmentation by Instance Flow Assembly
Oct 20, 2021
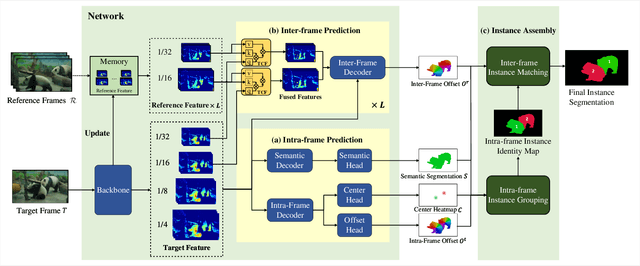
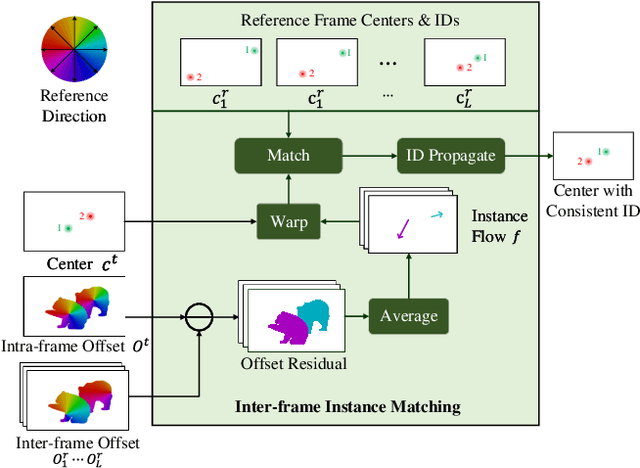

Instance segmentation is a challenging task aiming at classifying and segmenting all object instances of specific classes. While two-stage box-based methods achieve top performances in the image domain, they cannot easily extend their superiority into the video domain. This is because they usually deal with features or images cropped from the detected bounding boxes without alignment, failing to capture pixel-level temporal consistency. We embrace the observation that bottom-up methods dealing with box-free features could offer accurate spacial correlations across frames, which can be fully utilized for object and pixel level tracking. We first propose our bottom-up framework equipped with a temporal context fusion module to better encode inter-frame correlations. Intra-frame cues for semantic segmentation and object localization are simultaneously extracted and reconstructed by corresponding decoders after a shared backbone. For efficient and robust tracking among instances, we introduce an instance-level correspondence across adjacent frames, which is represented by a center-to-center flow, termed as instance flow, to assemble messy dense temporal correspondences. Experiments demonstrate that the proposed method outperforms the state-of-the-art online methods (taking image-level input) on the challenging Youtube-VIS dataset.