 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dangerous Cloaking: Natural Trigger based Backdoor Attacks on Object Detectors in the Physical World
Jan 21, 2022

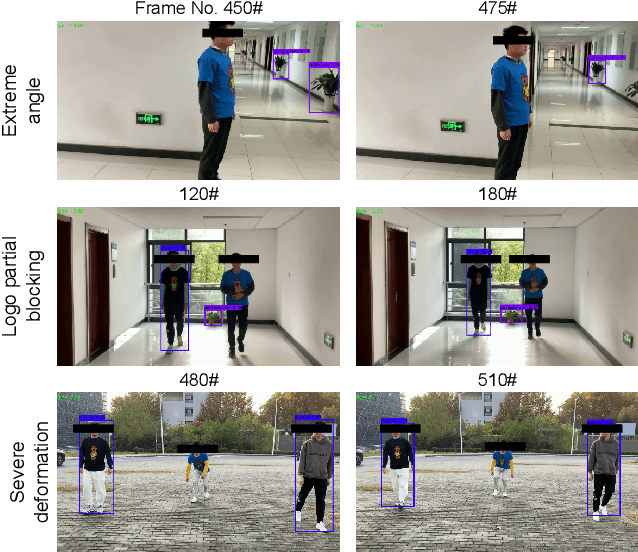
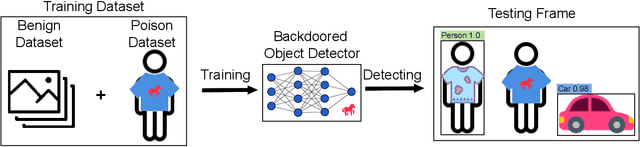

Deep learning models have been shown to be vulnerable to recent backdoor attacks. A backdoored model behaves normally for inputs containing no attacker-secretly-chosen trigger and maliciously for inputs with the trigger. To date, backdoor attacks and countermeasures mainly focus on image classification tasks. And most of them are implemented in the digital world with digital triggers. Besides the classification tasks, object detection systems are also considered as one of the basic foundations of computer vision tasks. However, there is no investigation and understanding of the backdoor vulnerability of the object detector, even in the digital world with digital triggers. For the first time, this work demonstrates that existing object detectors are inherently susceptible to physical backdoor attacks. We use a natural T-shirt bought from a market as a trigger to enable the cloaking effect--the person bounding-box disappears in front of the object detector. We show that such a backdoor can be implanted from two exploitable attack scenarios into the object detector, which is outsourced or fine-tuned through a pretrained model. We have extensively evaluated three popular object detection algorithms: anchor-based Yolo-V3, Yolo-V4, and anchor-free CenterNet. Building upon 19 videos shot in real-world scenes, we confirm that the backdoor attack is robust against various factors: movement, distance, angle, non-rigid deformation, and lighting. Specifically, the attack success rate (ASR) in most videos is 100% or close to it, while the clean data accuracy of the backdoored model is the same as its clean counterpart. The latter implies that it is infeasible to detect the backdoor behavior merely through a validation set. The averaged ASR still remains sufficiently high to be 78% in the transfer learning attack scenarios evaluated on CenterNet. See the demo video on https://youtu.be/Q3HOF4OobbY.
Variable Augmented Network for Invertible Modality Synthesis-Fusion
Sep 02, 2021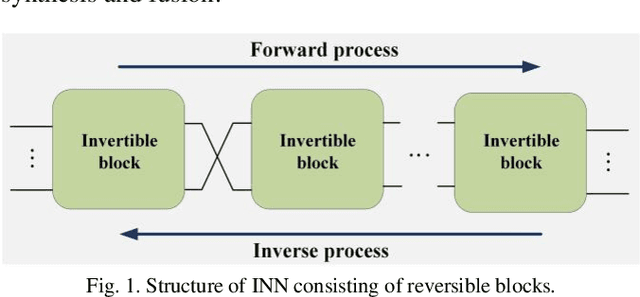
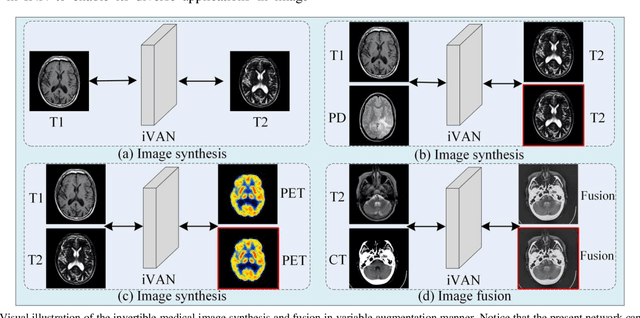
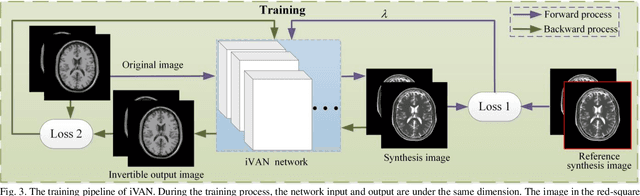
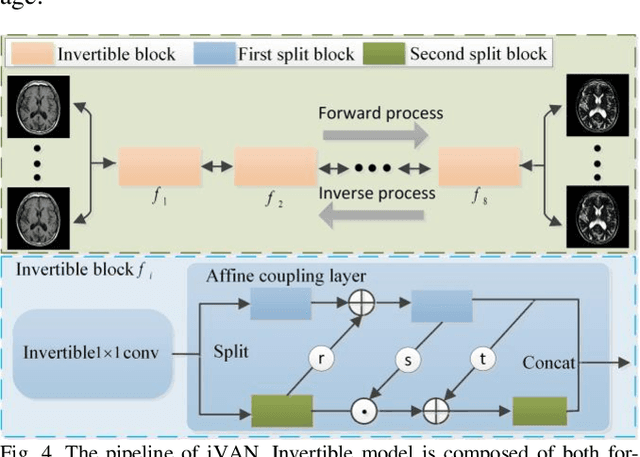
As an effective way to integrate the information contained in multiple medical images under different modalities, medical image synthesis and fusion have emerged in various clinical applications such as disease diagnosis and treatment planning. In this paper, an invertible and variable augmented network (iVAN) is proposed for medical image synthesis and fusion. In iVAN, the channel number of the network input and output is the same through variable augmentation technology, and data relevance is enhanced, which is conducive to the generation of characterization information. Meanwhile, the invertible network is used to achieve the bidirectional inference processes. Due to the invertible and variable augmentation schemes, iVAN can not only be applied to the mappings of multi-input to one-output and multi-input to multi-output, but also be applied to one-input to multi-output. Experimental results demonstrated that the proposed method can obtain competitive or superior performance in comparison to representative medical image synthesis and fusion methods.
SLCRF: Subspace Learning with Conditional Random Field for Hyperspectral Image Classification
Oct 07, 2020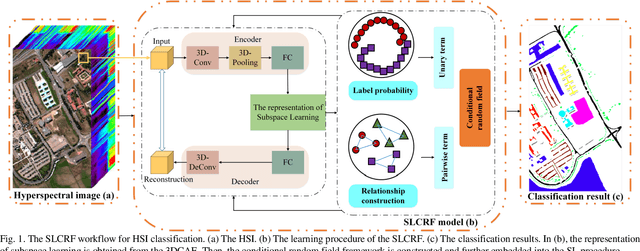

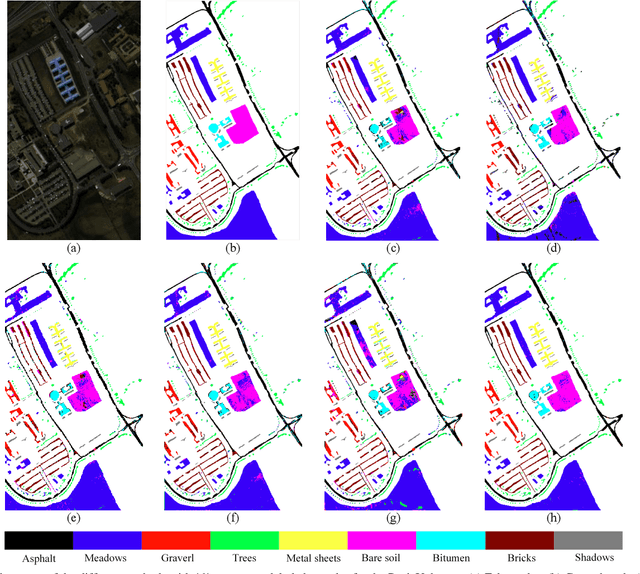
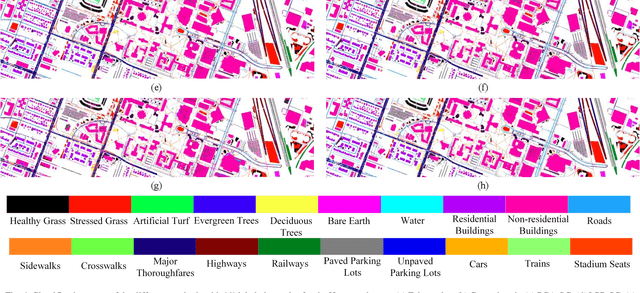
Subspace learning (SL) plays an important role in hyperspectral image (HSI) classification, since it can provide an effective solution to reduce the redundant information in the image pixels of HSIs. Previous works about SL aim to improve the accuracy of HSI recognition. Using a large number of labeled samples, related methods can train the parameters of the proposed solutions to obtain better representations of HSI pixels. However, the data instances may not be sufficient enough to learn a precise model for HSI classification in real applications. Moreover, it is well-known that it takes much time, labor and human expertise to label HSI images. To avoid the aforementioned problems, a novel SL method that includes the probability assumption called subspace learning with conditional random field (SLCRF) is developed. In SLCRF, first, the 3D convolutional autoencoder (3DCAE) is introduced to remove the redundant information in HSI pixels. In addition, the relationships are also constructed using the spectral-spatial information among the adjacent pixels. Then, the conditional random field (CRF) framework can be constructed and further embedded into the HSI SL procedure with the semi-supervised approach. Through the linearized alternating direction method termed LADMAP, the objective function of SLCRF is optimized using a defined iterative algorithm. The proposed method is comprehensively evaluated using the challenging public HSI datasets. We can achieve stateof-the-art performance using these HSI sets.
Tensor Networks for Medical Image Classification
Apr 21, 2020



With the increasing adoption of machine learning tools like neural networks across several domains, interesting connections and comparisons to concepts from other domains are coming to light. In this work, we focus on the class of Tensor Networks, which has been a work horse for physicists in the last two decades to analyse quantum many-body systems. Building on the recent interest in tensor networks for machine learning, we extend the Matrix Product State tensor networks (which can be interpreted as linear classifiers operating in exponentially high dimensional spaces) to be useful in medical image analysis tasks. We focus on classification problems as a first step where we motivate the use of tensor networks and propose adaptions for 2D images using classical image domain concepts such as local orderlessness of images. With the proposed locally orderless tensor network model (LoTeNet), we show that tensor networks are capable of attaining performance that is comparable to state-of-the-art deep learning methods. We evaluate the model on two publicly available medical imaging datasets and show performance improvements with fewer model hyperparameters and lesser computational resources compared to relevant baseline methods.
HRINet: Alternative Supervision Network for High-resolution CT image Interpolation
Feb 11, 2020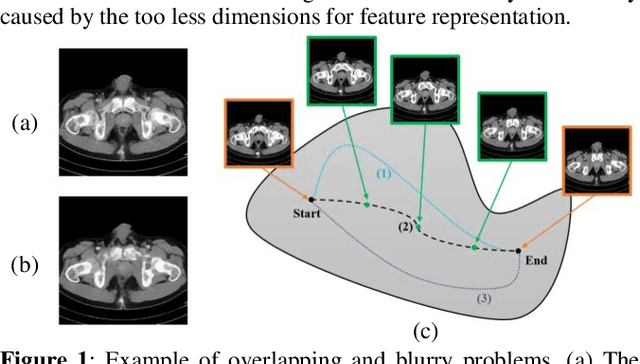

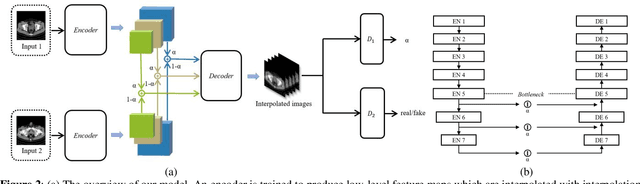
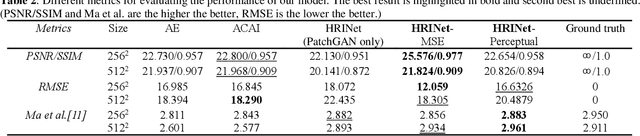
Image interpolation in medical area is of high importance as most 3D biomedical volume images are sampled where the distance between consecutive slices significantly greater than the in-plane pixel size due to radiation dose or scanning time. Image interpolation creates a number of new slices between known slices in order to obtain an isotropic volume image. The results can be used for the higher quality of 3D reconstruction and visualization of human body structures. Semantic interpolation on the manifold has been proved to be very useful for smoothing image interpolation. Nevertheless, all previous methods focused on low-resolution image interpolation, and most of them work poorly on high-resolution image. We propose a novel network, High Resolution Interpolation Network (HRINet), aiming at producing high-resolution CT image interpolations. We combine the idea of ACAI and GANs, and propose a novel idea of alternative supervision method by applying supervised and unsupervised training alternatively to raise the accuracy of human organ structures in CT while keeping high quality. We compare an MSE based and a perceptual based loss optimizing methods for high quality interpolation, and show the tradeoff between the structural correctness and sharpness. Our experiments show the great improvement on 256 2 and 5122 images quantitatively and qualitatively.
Convolutional Neural Network-Based Age Estimation Using B-Mode Ultrasound Tongue Image
Jan 27, 2021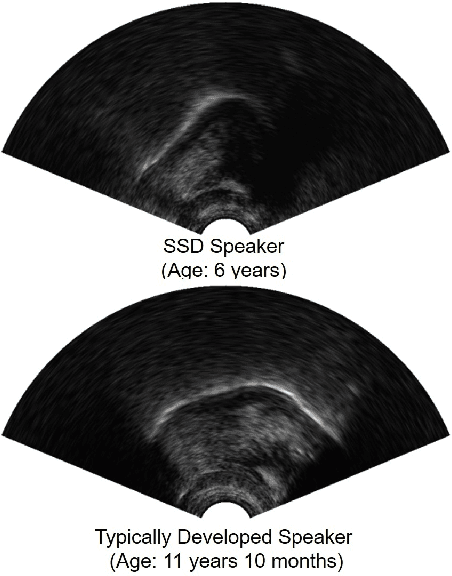
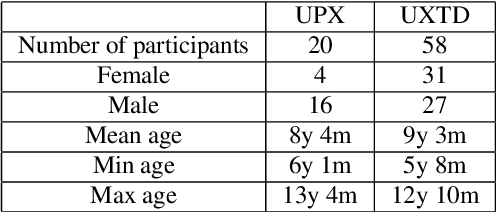
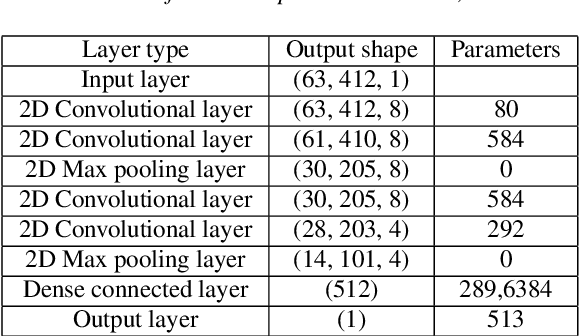
Ultrasound tongue imaging is widely used for speech production research, and it has attracted increasing attention as its potential applications seem to be evident in many different fields, such as the visual biofeedback tool for second language acquisition and silent speech interface. Unlike previous studies, here we explore the feasibility of age estimation using the ultrasound tongue image of the speakers. Motivated by the success of deep learning, this paper leverages deep learning on this task. We train a deep convolutional neural network model on the UltraSuite dataset. The deep model achieves mean absolute error (MAE) of 2.03 for the data from typically developing children, while MAE is 4.87 for the data from the children with speech sound disorders, which suggest that age estimation using ultrasound is more challenging for the children with speech sound disorder. The developed method can be used a tool to evaluate the performance of speech therapy sessions. It is also worthwhile to notice that, although we leverage the ultrasound tongue imaging for our study, the proposed methods may also be extended to other imaging modalities (e.g. MRI) to assist the studies on speech production.
ZstGAN: An Adversarial Approach for Unsupervised Zero-Shot Image-to-Image Translation
Jun 01, 2019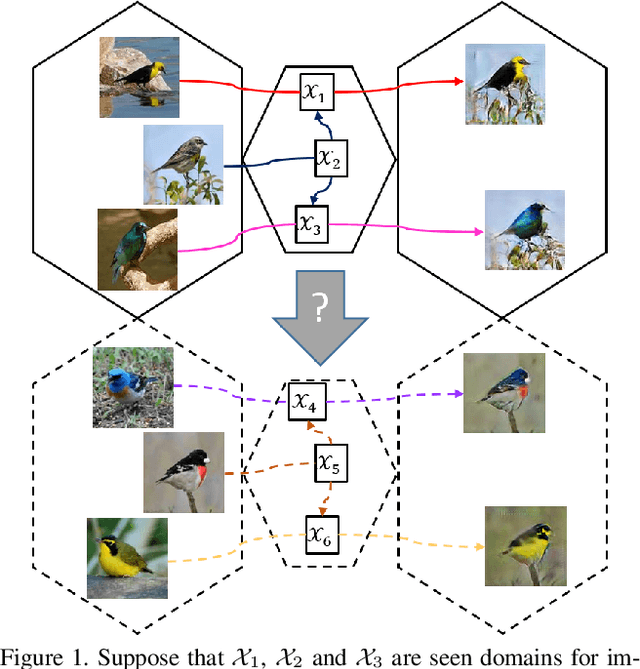
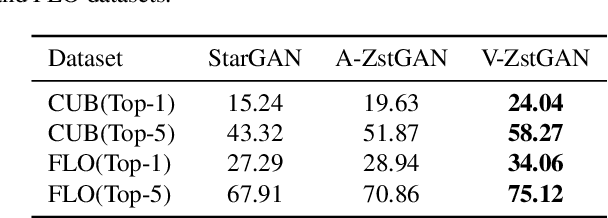
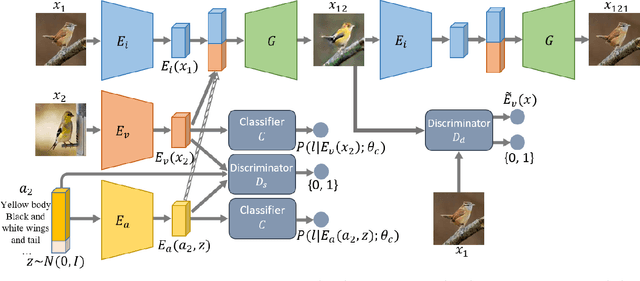
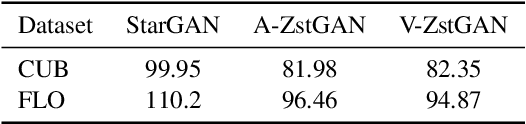
Image-to-image translation models have shown remarkable ability on transferring images among different domains. Most of existing work follows the setting that the source domain and target domain keep the same at training and inference phases, which cannot be generalized to the scenarios for translating an image from an unseen domain to an another unseen domain. In this work, we propose the Unsupervised Zero-Shot Image-to-image Translation (UZSIT) problem, which aims to learn a model that can transfer translation knowledge from seen domains to unseen domains. Accordingly, we propose a framework called ZstGAN: By introducing an adversarial training scheme, ZstGAN learns to model each domain with domain-specific feature distribution that is semantically consistent on vision and attribute modalities. Then the domain-invariant features are disentangled with an shared encoder for image generation. We carry out extensive experiments on CUB and FLO datasets, and the results demonstrate the effectiveness of proposed method on UZSIT task. Moreover, ZstGAN shows significant accuracy improvements over state-of-the-art zero-shot learning methods on CUB and FLO.
CA-Net: Comprehensive Attention Convolutional Neural Networks for Explainable Medical Image Segmentation
Sep 23, 2020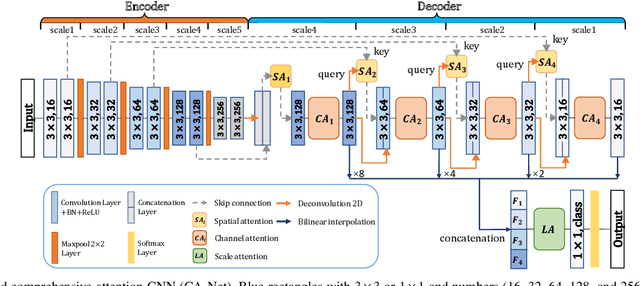
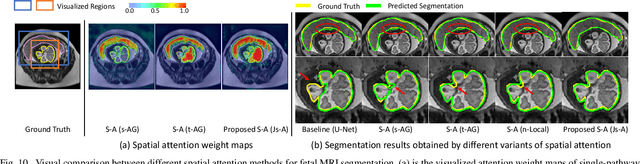
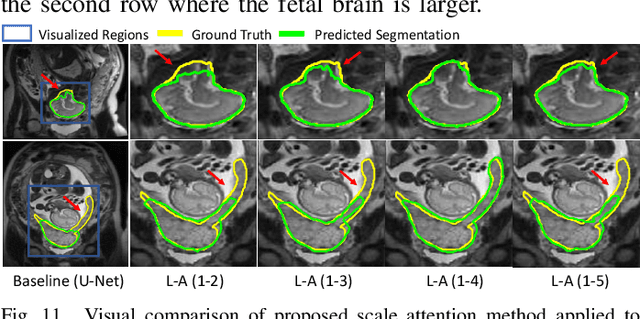
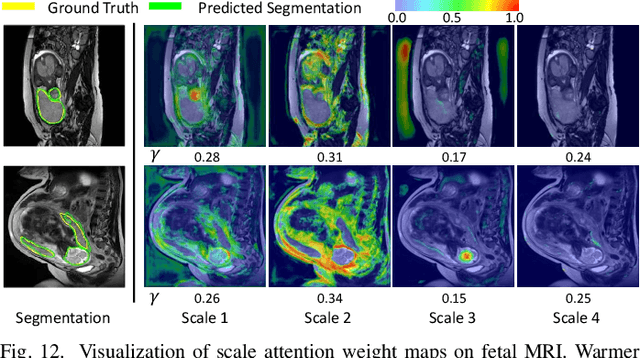
Accurate medical image segmentation is essential for diagnosis and treatment planning of diseases. Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance for automatic medical image segmentation. However, they are still challenged by complicated conditions where the segmentation target has large variations of position, shape and scale, and existing CNNs have a poor explainability that limits their application to clinical decisions. In this work, we make extensive use of multiple attentions in a CNN architecture and propose a comprehensive attention-based CNN (CA-Net) for more accurate and explainable medical image segmentation that is aware of the most important spatial positions, channels and scales at the same time. In particular, we first propose a joint spatial attention module to make the network focus more on the foreground region. Then, a novel channel attention module is proposed to adaptively recalibrate channel-wise feature responses and highlight the most relevant feature channels. Also, we propose a scale attention module implicitly emphasizing the most salient feature maps among multiple scales so that the CNN is adaptive to the size of an object. Extensive experiments on skin lesion segmentation from ISIC 2018 and multi-class segmentation of fetal MRI found that our proposed CA-Net significantly improved the average segmentation Dice score from 87.77% to 92.08% for skin lesion, 84.79% to 87.08% for the placenta and 93.20% to 95.88% for the fetal brain respectively compared with U-Net. It reduced the model size to around 15 times smaller with close or even better accuracy compared with state-of-the-art DeepLabv3+. In addition, it has a much higher explainability than existing networks by visualizing the attention weight maps. Our code is available at https://github.com/HiLab-git/CA-Net
Efficient Image Gallery Representations at Scale Through Multi-Task Learning
May 25, 2020

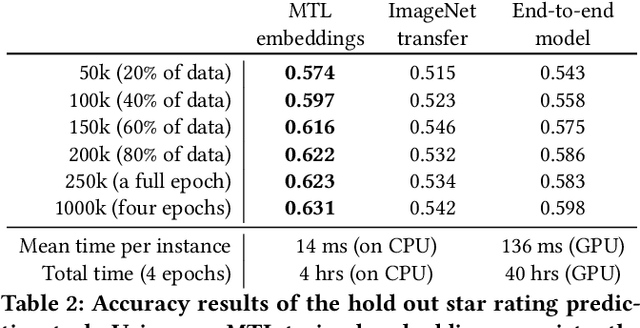
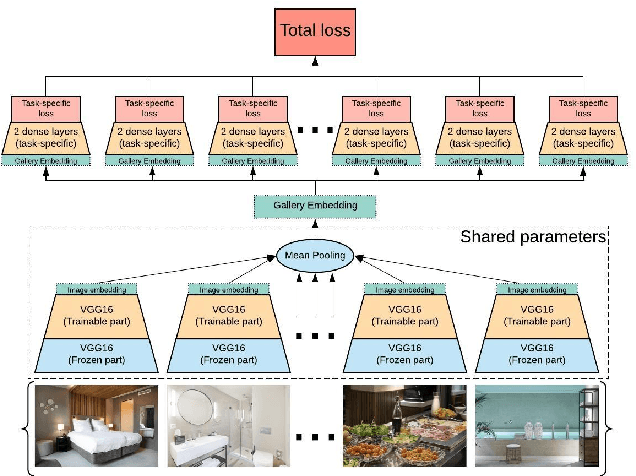
Image galleries provide a rich source of diverse information about a product which can be leveraged across many recommendation and retrieval applications. We study the problem of building a universal image gallery encoder through multi-task learning (MTL) approach and demonstrate that it is indeed a practical way to achieve generalizability of learned representations to new downstream tasks. Additionally, we analyze the relative predictive performance of MTL-trained solutions against optimal and substantially more expensive solutions, and find signals that MTL can be a useful mechanism to address sparsity in low-resource binary tasks.
Facial Information Analysis Technology for Gender and Age Estimation
Nov 17, 2021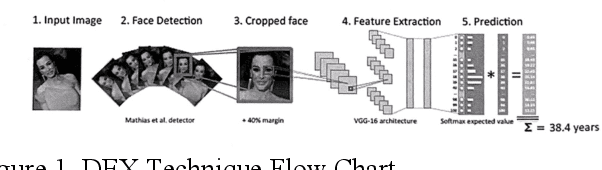
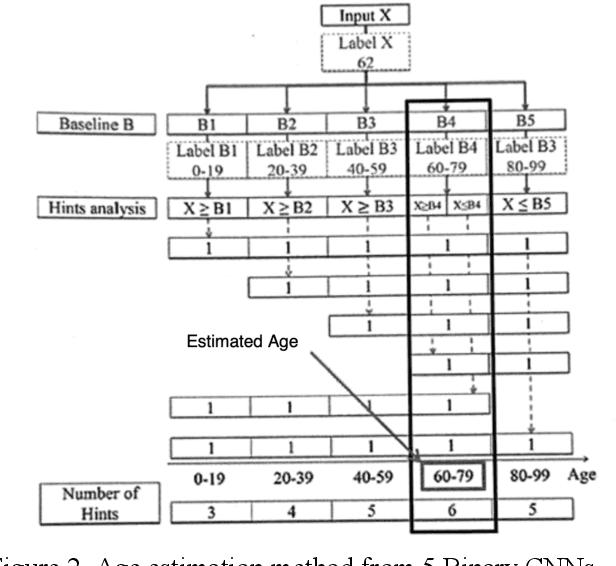
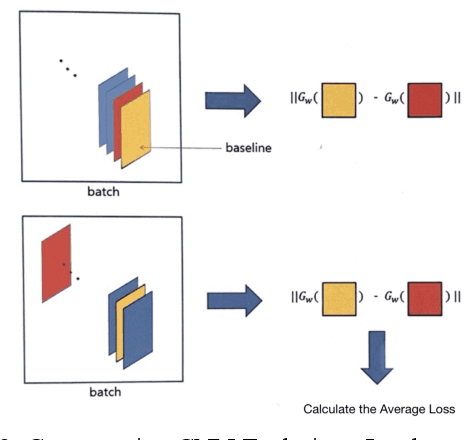
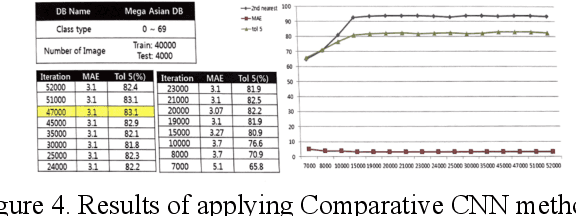
This is a study on facial information analysis technology for estimating gender and age, and poses are estimated using a transformation relationship matrix between the camera coordinate system and the world coordinate system for estimating the pose of a face image. Gender classification was relatively simple compared to age estimation, and age estimation was made possible using deep learning-based facial recognition technology. A comparative CNN was proposed to calculate the experimental results using the purchased database and the public database, and deep learning-based gender classification and age estimation performed at a significant level and was more robust to environmental changes compared to the existing machine learning techniques.