 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CLIP2StyleGAN: Unsupervised Extraction of StyleGAN Edit Directions
Dec 09, 2021

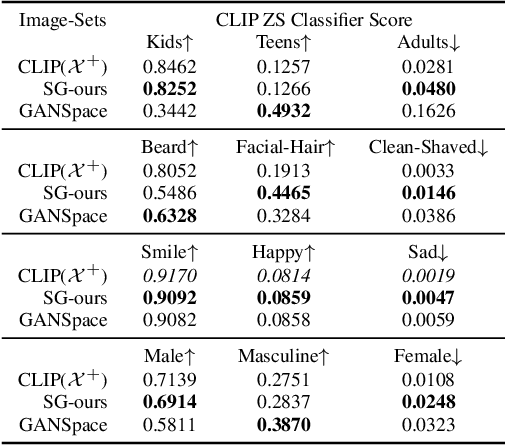
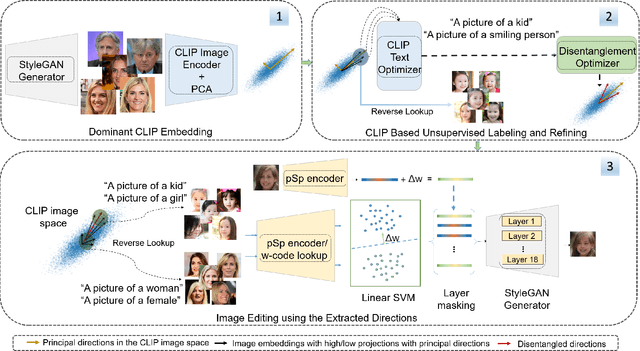

The success of StyleGAN has enabled unprecedented semantic editing capabilities, on both synthesized and real images. However, such editing operations are either trained with semantic supervision or described using human guidance. In another development, the CLIP architecture has been trained with internet-scale image and text pairings and has been shown to be useful in several zero-shot learning settings. In this work, we investigate how to effectively link the pretrained latent spaces of StyleGAN and CLIP, which in turn allows us to automatically extract semantically labeled edit directions from StyleGAN, finding and naming meaningful edit operations without any additional human guidance. Technically, we propose two novel building blocks; one for finding interesting CLIP directions and one for labeling arbitrary directions in CLIP latent space. The setup does not assume any pre-determined labels and hence we do not require any additional supervised text/attributes to build the editing framework. We evaluate the effectiveness of the proposed method and demonstrate that extraction of disentangled labeled StyleGAN edit directions is indeed possible, and reveals interesting and non-trivial edit directions.
Learning Multiple Dense Prediction Tasks from Partially Annotated Data
Nov 29, 2021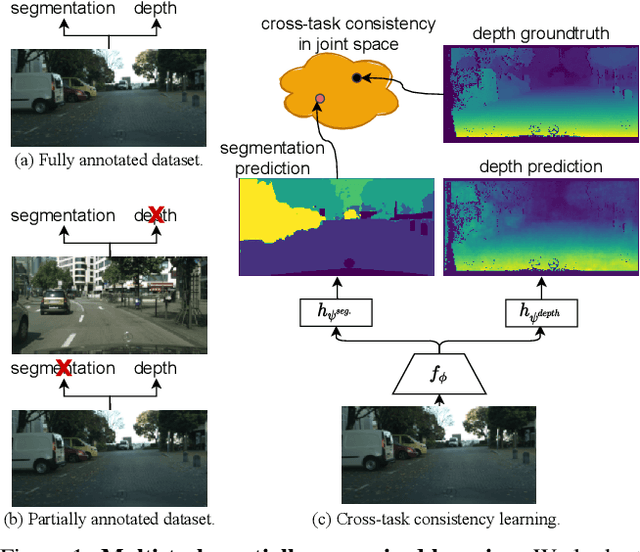
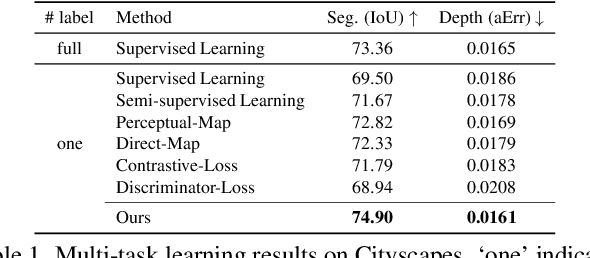
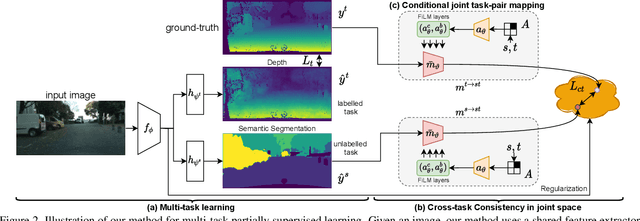
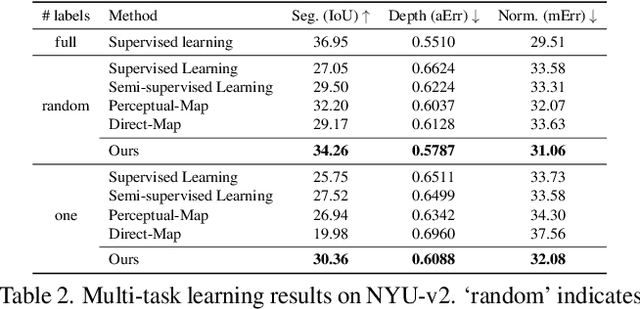
Despite the recent advances in multi-task learning of dense prediction problems, most methods rely on expensive labelled datasets. In this paper, we present a label efficient approach and look at jointly learning of multiple dense prediction tasks on partially annotated data, which we call multi-task partially-supervised learning. We propose a multi-task training procedure that successfully leverages task relations to supervise its multi-task learning when data is partially annotated. In particular, we learn to map each task pair to a joint pairwise task-space which enables sharing information between them in a computationally efficient way through another network conditioned on task pairs, and avoids learning trivial cross-task relations by retaining high-level information about the input image. We rigorously demonstrate that our proposed method effectively exploits the images with unlabelled tasks and outperforms existing semi-supervised learning approaches and related methods on three standard benchmarks.
A Shared Representation for Photorealistic Driving Simulators
Dec 09, 2021
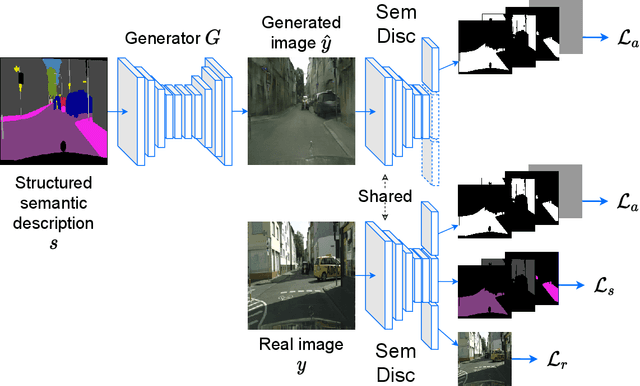


A powerful simulator highly decreases the need for real-world tests when training and evaluating autonomous vehicles. Data-driven simulators flourished with the recent advancement of conditional Generative Adversarial Networks (cGANs), providing high-fidelity images. The main challenge is synthesizing photorealistic images while following given constraints. In this work, we propose to improve the quality of generated images by rethinking the discriminator architecture. The focus is on the class of problems where images are generated given semantic inputs, such as scene segmentation maps or human body poses. We build on successful cGAN models to propose a new semantically-aware discriminator that better guides the generator. We aim to learn a shared latent representation that encodes enough information to jointly do semantic segmentation, content reconstruction, along with a coarse-to-fine grained adversarial reasoning. The achieved improvements are generic and simple enough to be applied to any architecture of conditional image synthesis. We demonstrate the strength of our method on the scene, building, and human synthesis tasks across three different datasets. The code is available at https://github.com/vita-epfl/SemDisc.
Lung image segmentation by generative adversarial networks
Jul 30, 2019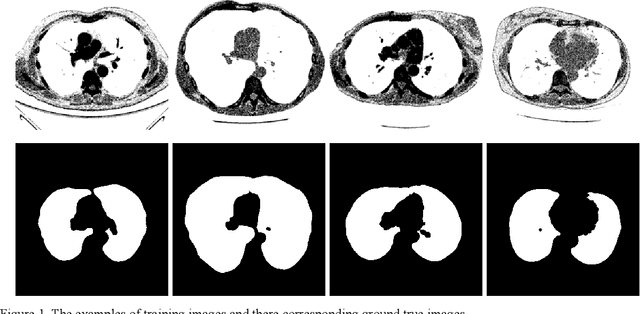
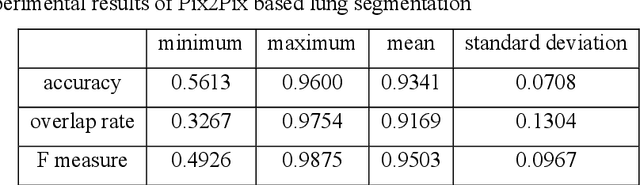
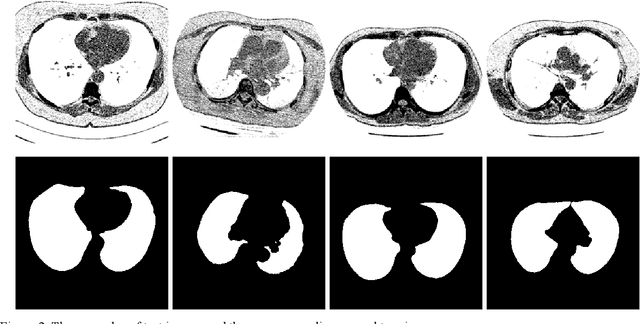

Lung image segmentation plays an important role in computer-aid pulmonary diseases diagnosis and treatment. This paper proposed a lung image segmentation method by generative adversarial networks. We employed a variety of generative adversarial networks and use its capability of image translation to perform image segmentation. The generative adversarial networks was employed to translate the original lung image to the segmented image. The generative adversarial networks based segmentation method was test on real lung image data set. Experimental results shows that the proposed method is effective and outperform state-of-the art method.
A Bayesian Treatment of Real-to-Sim for Deformable Object Manipulation
Dec 09, 2021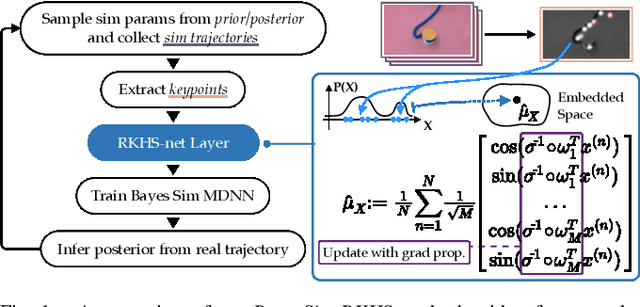


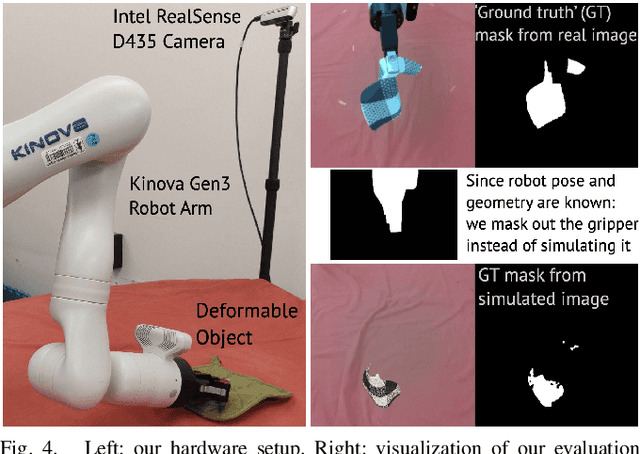
Deformable object manipulation remains a challenging task in robotics research. Conventional techniques for parameter inference and state estimation typically rely on a precise definition of the state space and its dynamics. While this is appropriate for rigid objects and robot states, it is challenging to define the state space of a deformable object and how it evolves in time. In this work, we pose the problem of inferring physical parameters of deformable objects as a probabilistic inference task defined with a simulator. We propose a novel methodology for extracting state information from image sequences via a technique to represent the state of a deformable object as a distribution embedding. This allows to incorporate noisy state observations directly into modern Bayesian simulation-based inference tools in a principled manner. Our experiments confirm that we can estimate posterior distributions of physical properties, such as elasticity, friction and scale of highly deformable objects, such as cloth and ropes. Overall, our method addresses the real-to-sim problem probabilistically and helps to better represent the evolution of the state of deformable objects.
How useful is Active Learning for Image-based Plant Phenotyping?
Jul 01, 2020

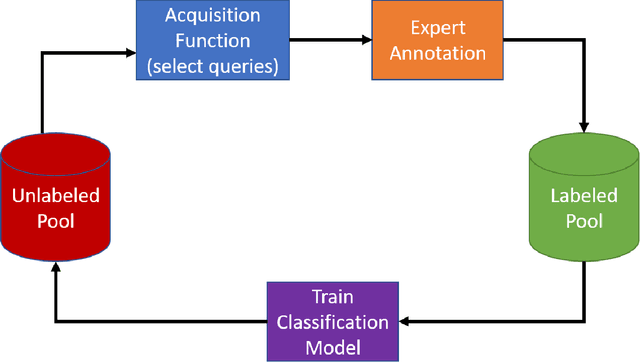
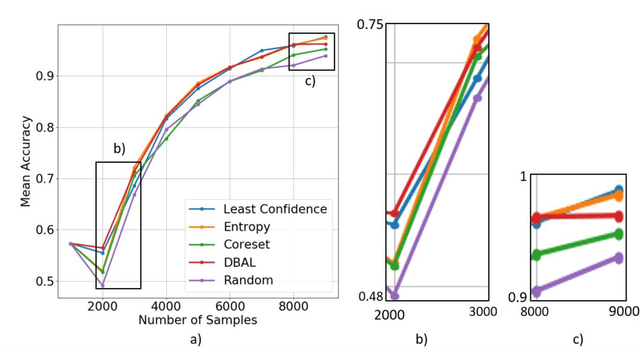
Deep learning models have been successfully deployed for a diverse array of image-based plant phenotyping applications including disease detection and classification. However, successful deployment of supervised deep learning models requires large amount of labeled data, which is a significant challenge in plant science (and most biological) domains due to the inherent complexity. Specifically, data annotation is costly, laborious, time consuming and needs domain expertise for phenotyping tasks, especially for diseases. To overcome this challenge, active learning algorithms have been proposed that reduce the amount of labeling needed by deep learning models to achieve good predictive performance. Active learning methods adaptively select samples to annotate using an acquisition function to achieve maximum (classification) performance under a fixed labeling budget. We report the performance of four different active learning methods, (1) Deep Bayesian Active Learning (DBAL), (2) Entropy, (3) Least Confidence, and (4) Coreset, with conventional random sampling-based annotation for two different image-based classification datasets. The first image dataset consists of soybean [Glycine max L. (Merr.)] leaves belonging to eight different soybean stresses and a healthy class, and the second consists of nine different weed species from the field. For a fixed labeling budget, we observed that the classification performance of deep learning models with active learning-based acquisition strategies is better than random sampling-based acquisition for both datasets. The integration of active learning strategies for data annotation can help mitigate labelling challenges in the plant sciences applications particularly where deep domain knowledge is required.
Quantitative analysis of visual representation of sign elements in COVID-19 context
Dec 15, 2021

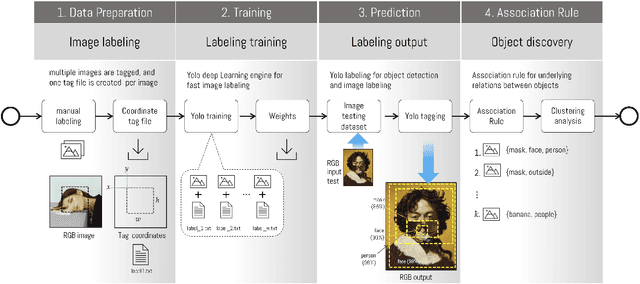
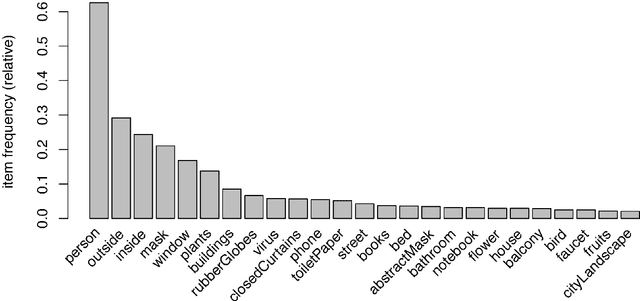
Representation is the way in which human beings re-present the reality of what is happening, both externally and internally. Thus, visual representation as a means of communication uses elements to build a narrative, just as spoken and written language do. We propose using computer analysis to perform a quantitative analysis of the elements used in the visual creations that have been produced in reference to the epidemic, using the images compiled in The Covid Art Museum's Instagram account to analyze the different elements used to represent subjective experiences with regard to a global event. This process has been carried out with techniques based on machine learning to detect objects in the images so that the algorithm can be capable of learning and detecting the objects contained in each study image. This research reveals that the elements that are repeated in images to create narratives and the relations of association that are established in the sample, concluding that, despite the subjectivity that all creation entails, there are certain parameters of shared and reduced decisions when it comes to selecting objects to be included in visual representations
Uncertainty Sets for Image Classifiers using Conformal Prediction
Sep 29, 2020
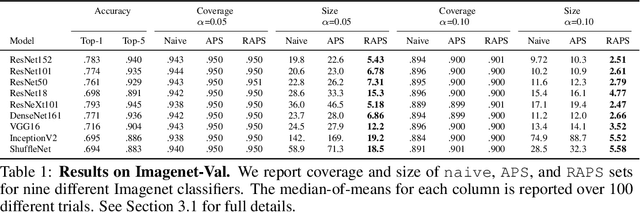
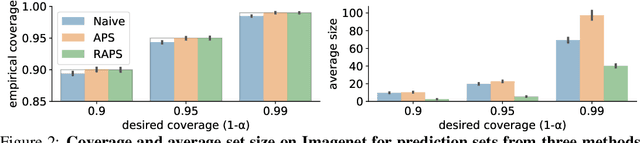
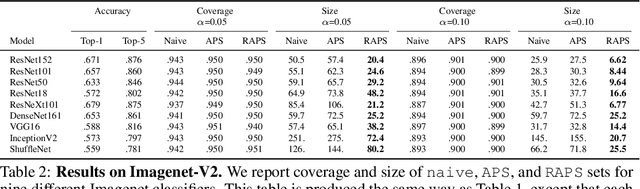
Convolutional image classifiers can achieve high predictive accuracy, but quantifying their uncertainty remains an unresolved challenge, hindering their deployment in consequential settings. Existing uncertainty quantification techniques, such as Platt scaling, attempt to calibrate the network's probability estimates, but they do not have formal guarantees. We present an algorithm that modifies any classifier to output a predictive set containing the true label with a user-specified probability, such as 90%. The algorithm is simple and fast like Platt scaling, but provides a formal finite-sample coverage guarantee for every model and dataset. Furthermore, our method generates much smaller predictive sets than alternative methods, since we introduce a regularizer to stabilize the small scores of unlikely classes after Platt scaling. In experiments on both Imagenet and Imagenet-V2 with a ResNet-152 and other classifiers, our scheme outperforms existing approaches, achieving exact coverage with sets that are often factors of 5 to 10 smaller.
A Complex Constrained Total Variation Image Denoising Algorithm with Application to Phase Retrieval
Sep 12, 2021
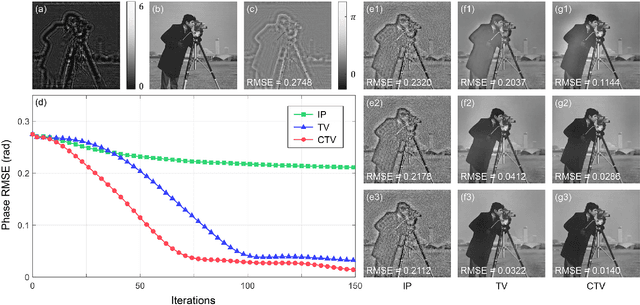
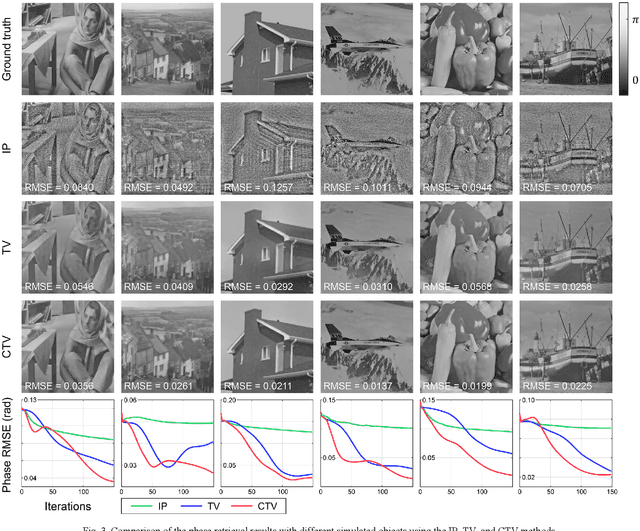
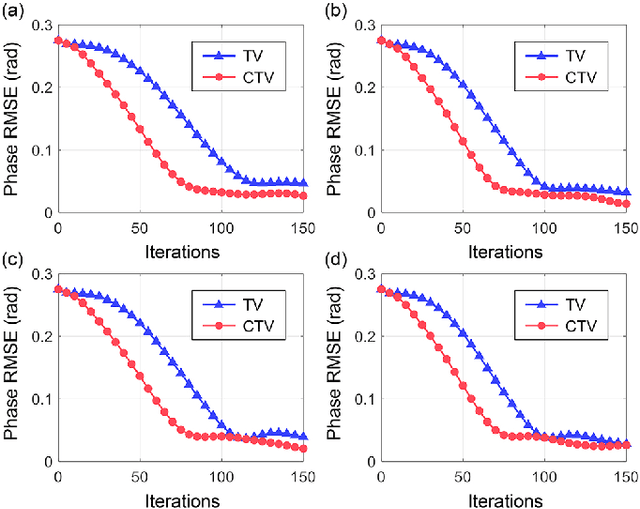
This paper considers the constrained total variation (TV) denoising problem for complex-valued images. We extend the definition of TV seminorms for real-valued images to dealing with complex-valued ones. In particular, we introduce two types of complex TV in both isotropic and anisotropic forms. To solve the constrained denoising problem, we adopt a dual approach and derive an accelerated gradient projection algorithm. We further generalize the proposed denoising algorithm as a key building block of the proximal gradient scheme to solve a vast class of complex constrained optimization problems with TV regularizers. As an example, we apply the proposed algorithmic framework to phase retrieval. We combine the complex TV regularizer with the conventional projection-based method within the constraint complex TV model. Initial results from both simulated and optical experiments demonstrate the validity of the constrained TV model in extracting sparsity priors within complex-valued images, while also utilizing physically tractable constraints that help speed up convergence.
Learning Spatial Pyramid Attentive Pooling in Image Synthesis and Image-to-Image Translation
Jan 18, 2019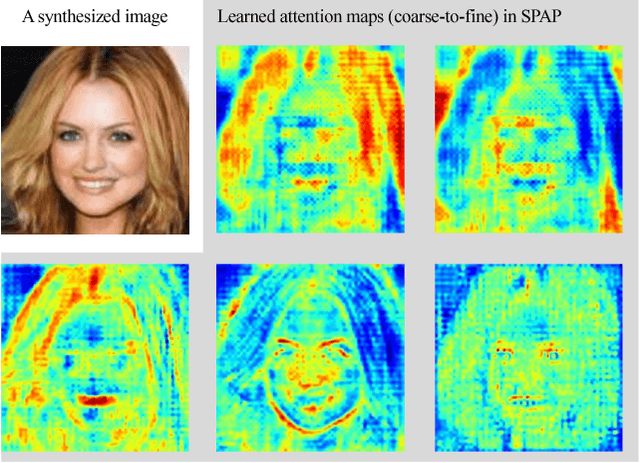
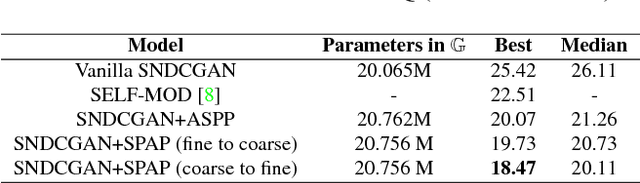
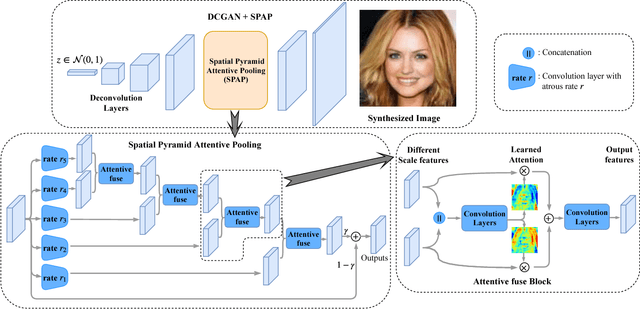
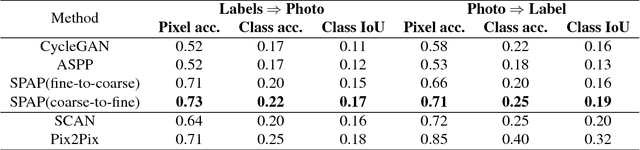
Image synthesis and image-to-image translation are two important generative learning tasks. Remarkable progress has been made by learning Generative Adversarial Networks (GANs)~\cite{goodfellow2014generative} and cycle-consistent GANs (CycleGANs)~\cite{zhu2017unpaired} respectively. This paper presents a method of learning Spatial Pyramid Attentive Pooling (SPAP) which is a novel architectural unit and can be easily integrated into both generators and discriminators in GANs and CycleGANs. The proposed SPAP integrates Atrous spatial pyramid~\cite{chen2018deeplab}, a proposed cascade attention mechanism and residual connections~\cite{he2016deep}. It leverages the advantages of the three components to facilitate effective end-to-end generative learning: (i) the capability of fusing multi-scale information by ASPP; (ii) the capability of capturing relative importance between both spatial locations (especially multi-scale context) or feature channels by attention; (iii) the capability of preserving information and enhancing optimization feasibility by residual connections. Coarse-to-fine and fine-to-coarse SPAP are studied and intriguing attention maps are observed in both tasks. In experiments, the proposed SPAP is tested in GANs on the Celeba-HQ-128 dataset~\cite{karras2017progressive}, and tested in CycleGANs on the Image-to-Image translation datasets including the Cityscape dataset~\cite{cordts2016cityscapes}, Facade and Aerial Maps dataset~\cite{zhu2017unpaired}, both obtaining better performance.