 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RelationRS: Relationship Representation Network for Object Detection in Aerial Images
Oct 13, 2021
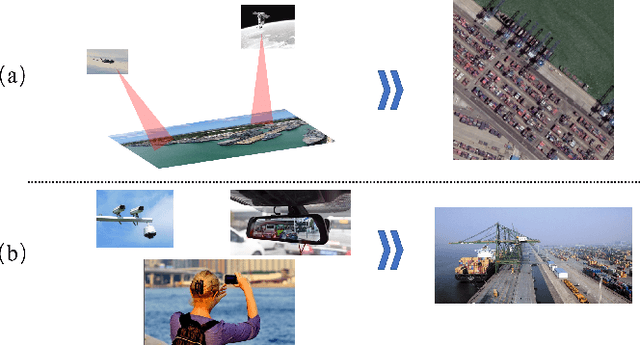
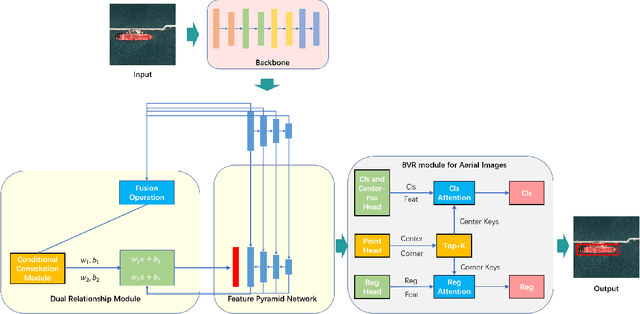


Object detection is a basic and important task in the field of aerial image processing and has gained much attention in computer vision. However, previous aerial image object detection approaches have insufficient use of scene semantic information between different regions of large-scale aerial images. In addition, complex background and scale changes make it difficult to improve detection accuracy. To address these issues, we propose a relationship representation network for object detection in aerial images (RelationRS): 1) Firstly, multi-scale features are fused and enhanced by a dual relationship module (DRM) with conditional convolution. The dual relationship module learns the potential relationship between features of different scales and learns the relationship between different scenes from different patches in a same iteration. In addition, the dual relationship module dynamically generates parameters to guide the fusion of multi-scale features. 2) Secondly, The bridging visual representations module (BVR) is introduced into the field of aerial images to improve the object detection effect in images with complex backgrounds. Experiments with a publicly available object detection dataset for aerial images demonstrate that the proposed RelationRS achieves a state-of-the-art detection performance.
Medical Visual Question Answering: A Survey
Nov 19, 2021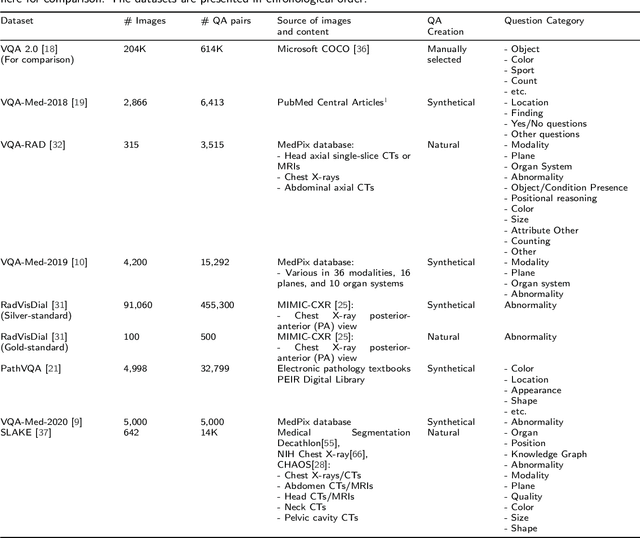
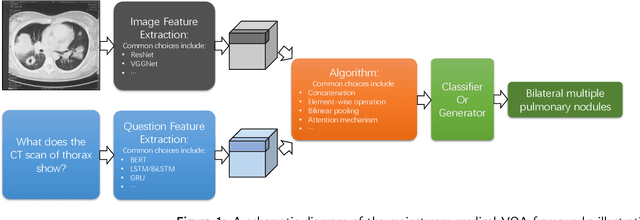
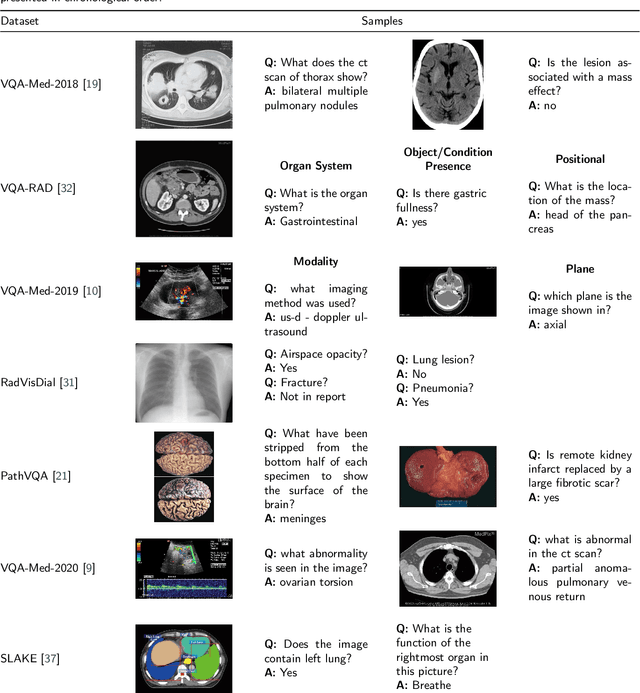
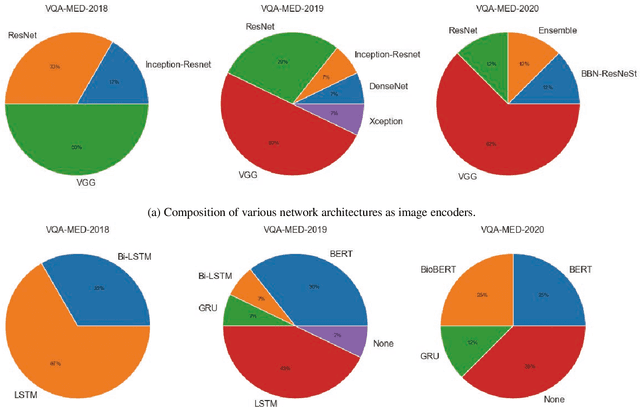
Medical Visual Question Answering (VQA) is a combination of medical artificial intelligence and popular VQA challenges. Given a medical image and a clinically relevant question in natural language, the medical VQA system is expected to predict a plausible and convincing answer. Although the general-domain VQA has been extensively studied, the medical VQA still needs specific investigation and exploration due to its task features. In the first part of this survey, we cover and discuss the publicly available medical VQA datasets up to date about the data source, data quantity, and task feature. In the second part, we review the approaches used in medical VQA tasks. In the last part, we analyze some medical-specific challenges for the field and discuss future research directions.
Who's Waldo? Linking People Across Text and Images
Aug 17, 2021

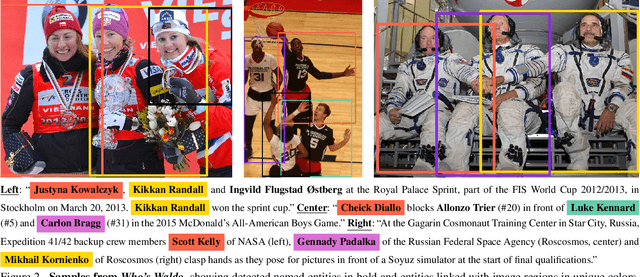
We present a task and benchmark dataset for person-centric visual grounding, the problem of linking between people named in a caption and people pictured in an image. In contrast to prior work in visual grounding, which is predominantly object-based, our new task masks out the names of people in captions in order to encourage methods trained on such image-caption pairs to focus on contextual cues (such as rich interactions between multiple people), rather than learning associations between names and appearances. To facilitate this task, we introduce a new dataset, Who's Waldo, mined automatically from image-caption data on Wikimedia Commons. We propose a Transformer-based method that outperforms several strong baselines on this task, and are releasing our data to the research community to spur work on contextual models that consider both vision and language.
Learning Dual Semantic Relations with Graph Attention for Image-Text Matching
Oct 22, 2020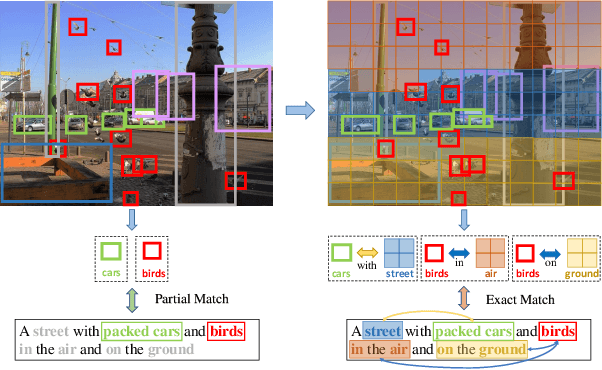
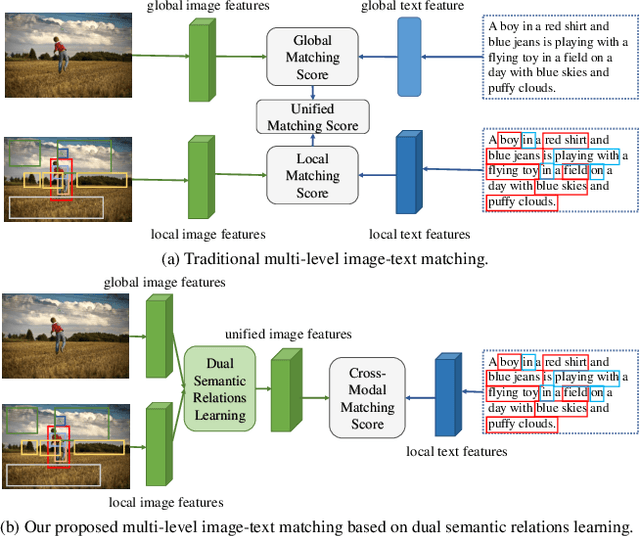
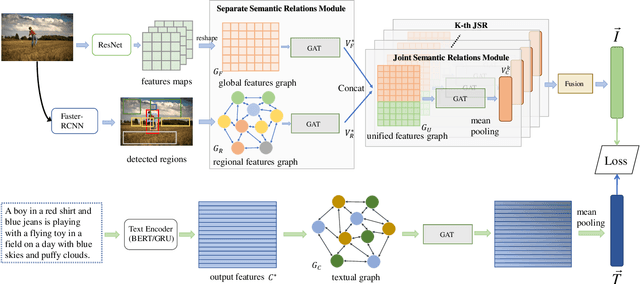
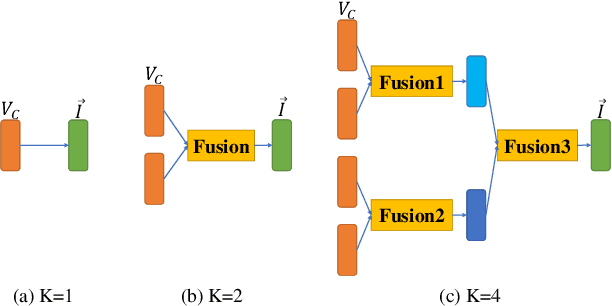
Image-Text Matching is one major task in cross-modal information processing. The main challenge is to learn the unified visual and textual representations. Previous methods that perform well on this task primarily focus on not only the alignment between region features in images and the corresponding words in sentences, but also the alignment between relations of regions and relational words. However, the lack of joint learning of regional features and global features will cause the regional features to lose contact with the global context, leading to the mismatch with those non-object words which have global meanings in some sentences. In this work, in order to alleviate this issue, it is necessary to enhance the relations between regions and the relations between regional and global concepts to obtain a more accurate visual representation so as to be better correlated to the corresponding text. Thus, a novel multi-level semantic relations enhancement approach named Dual Semantic Relations Attention Network(DSRAN) is proposed which mainly consists of two modules, separate semantic relations module and the joint semantic relations module. DSRAN performs graph attention in both modules respectively for region-level relations enhancement and regional-global relations enhancement at the same time. With these two modules, different hierarchies of semantic relations are learned simultaneously, thus promoting the image-text matching process by providing more information for the final visual representation. Quantitative experimental results have been performed on MS-COCO and Flickr30K and our method outperforms previous approaches by a large margin due to the effectiveness of the dual semantic relations learning scheme. Codes are available at https://github.com/kywen1119/DSRAN.
Can Deep Neural Networks be Converted to Ultra Low-Latency Spiking Neural Networks?
Dec 22, 2021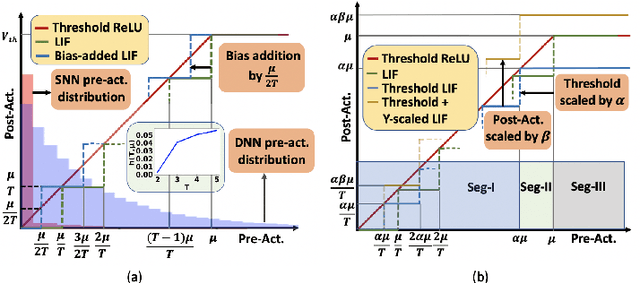
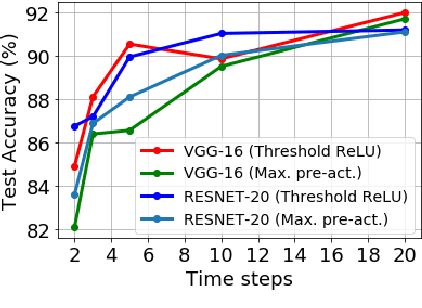

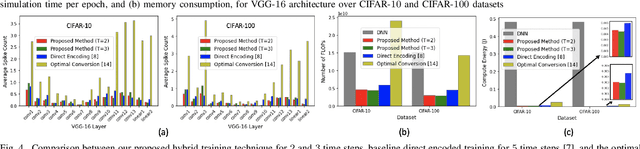
Spiking neural networks (SNNs), that operate via binary spikes distributed over time, have emerged as a promising energy efficient ML paradigm for resource-constrained devices. However, the current state-of-the-art (SOTA) SNNs require multiple time steps for acceptable inference accuracy, increasing spiking activity and, consequently, energy consumption. SOTA training strategies for SNNs involve conversion from a non-spiking deep neural network (DNN). In this paper, we determine that SOTA conversion strategies cannot yield ultra low latency because they incorrectly assume that the DNN and SNN pre-activation values are uniformly distributed. We propose a new training algorithm that accurately captures these distributions, minimizing the error between the DNN and converted SNN. The resulting SNNs have ultra low latency and high activation sparsity, yielding significant improvements in compute efficiency. In particular, we evaluate our framework on image recognition tasks from CIFAR-10 and CIFAR-100 datasets on several VGG and ResNet architectures. We obtain top-1 accuracy of 64.19% with only 2 time steps on the CIFAR-100 dataset with ~159.2x lower compute energy compared to an iso-architecture standard DNN. Compared to other SOTA SNN models, our models perform inference 2.5-8x faster (i.e., with fewer time steps).
A CLIP-Enhanced Method for Video-Language Understanding
Oct 14, 2021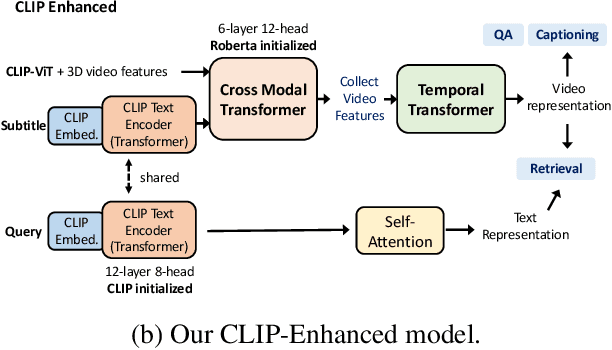
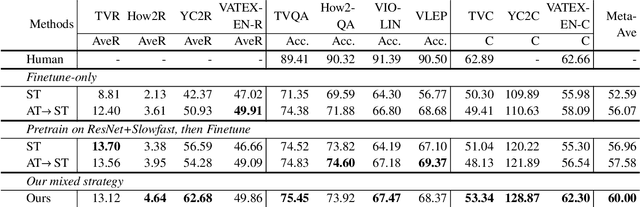
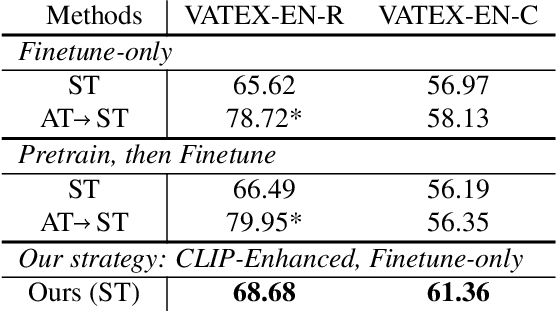
This technical report summarizes our method for the Video-And-Language Understanding Evaluation (VALUE) challenge (https://value-benchmark.github.io/challenge\_2021.html). We propose a CLIP-Enhanced method to incorporate the image-text pretrained knowledge into downstream video-text tasks. Combined with several other improved designs, our method outperforms the state-of-the-art by $2.4\%$ ($57.58$ to $60.00$) Meta-Ave score on VALUE benchmark.
An Annotated Video Dataset for Computing Video Memorability
Dec 04, 2021
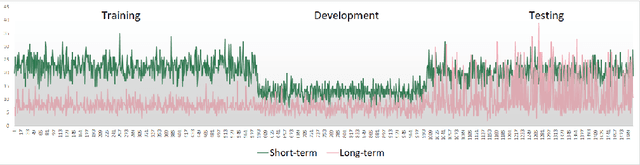
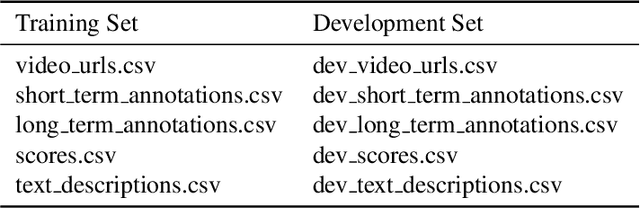
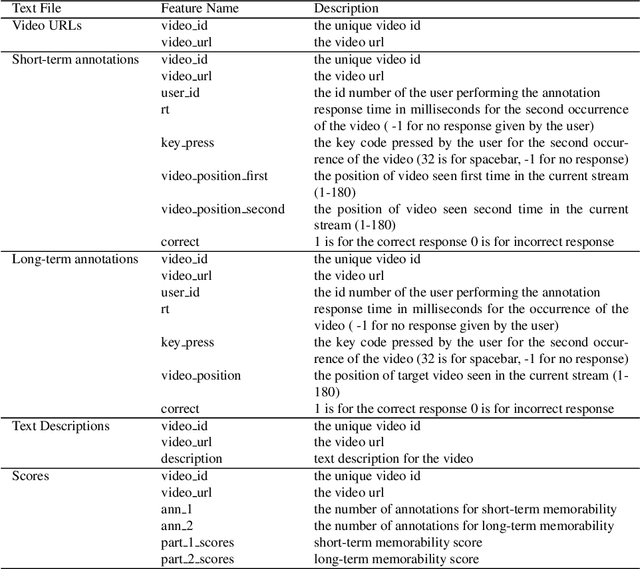
Using a collection of publicly available links to short form video clips of an average of 6 seconds duration each, 1,275 users manually annotated each video multiple times to indicate both long-term and short-term memorability of the videos. The annotations were gathered as part of an online memory game and measured a participant's ability to recall having seen the video previously when shown a collection of videos. The recognition tasks were performed on videos seen within the previous few minutes for short-term memorability and within the previous 24 to 72 hours for long-term memorability. Data includes the reaction times for each recognition of each video. Associated with each video are text descriptions (captions) as well as a collection of image-level features applied to 3 frames extracted from each video (start, middle and end). Video-level features are also provided. The dataset was used in the Video Memorability task as part of the MediaEval benchmark in 2020.
* 11 pages
Semantic Object Accuracy for Generative Text-to-Image Synthesis
Oct 29, 2019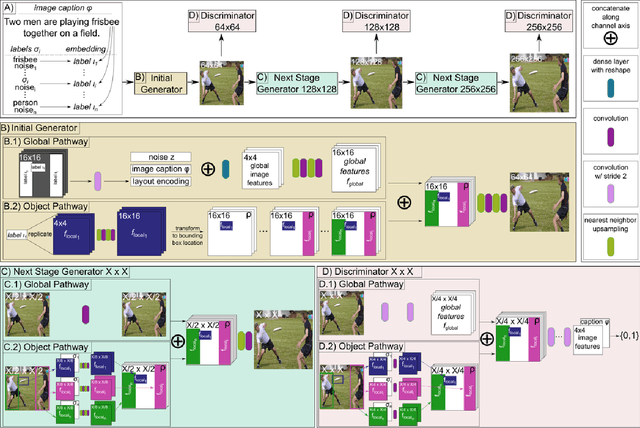
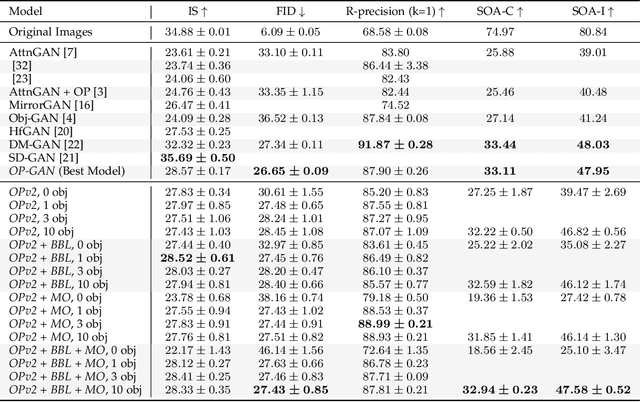

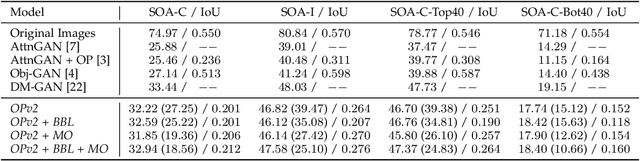
Generative adversarial networks conditioned on simple textual image descriptions are capable of generating realistic-looking images. However, current methods still struggle to generate images based on complex image captions from a heterogeneous domain. Furthermore, quantitatively evaluating these text-to-image synthesis models is still challenging, as most evaluation metrics only judge image quality but not the conformity between the image and its caption. To address the aforementioned challenges we introduce both a new model that explicitly models individual objects within an image and a new evaluation metric called Semantic Object Accuracy (SOA) that specifically evaluates images given an image caption. Our model adds an object pathway to both the generator and the discriminator to explicitly learn features of individual objects. The SOA uses a pre-trained object detector to evaluate if a generated image contains objects that are specifically mentioned in the image caption, e.g. whether an image generated from "a car driving down the street" contains a car. Our evaluation shows that models which explicitly model individual objects outperform models which only model global image characteristics. However, the SOA also shows that despite this increased performance current models still struggle to generate images that contain realistic objects of multiple different domains.
Unpaired Image Translation via Adaptive Convolution-based Normalization
Nov 29, 2019

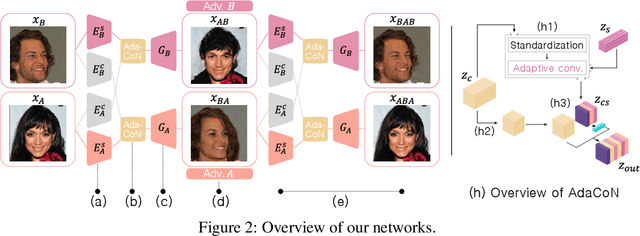
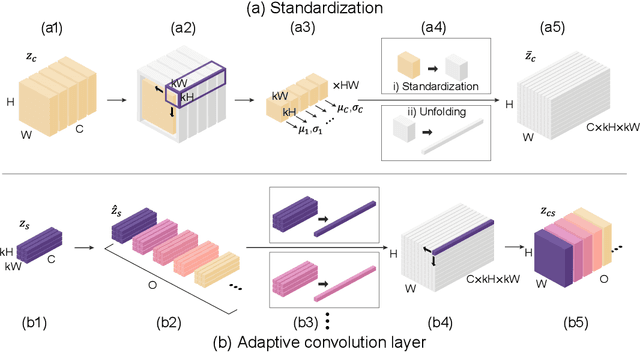
Disentangling content and style information of an image has played an important role in recent success in image translation. In this setting, how to inject given style into an input image containing its own content is an important issue, but existing methods followed relatively simple approaches, leaving room for improvement especially when incorporating significant style changes. In response, we propose an advanced normalization technique based on adaptive convolution (AdaCoN), in order to properly impose style information into the content of an input image. In detail, after locally standardizing the content representation in a channel-wise manner, AdaCoN performs adaptive convolution where the convolution filter weights are dynamically estimated using the encoded style representation. The flexibility of AdaCoN can handle complicated image translation tasks involving significant style changes. Our qualitative and quantitative experiments demonstrate the superiority of our proposed method against various existing approaches that inject the style into the content.
GridDehazeNet+: An Enhanced Multi-Scale Network with Intra-Task Knowledge Transfer for Single Image Dehazing
Mar 25, 2021


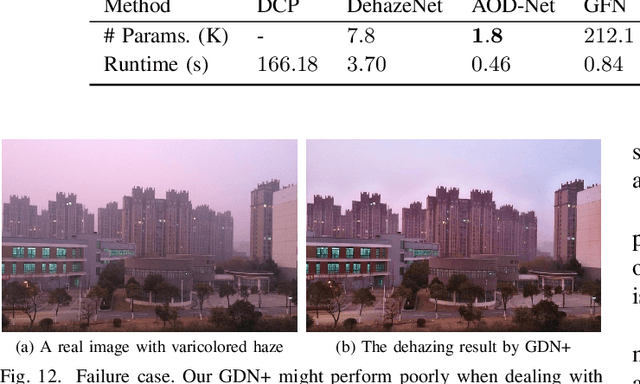
We propose an enhanced multi-scale network, dubbed GridDehazeNet+, for single image dehazing. It consists of three modules: pre-processing, backbone, and post-processing. The trainable pre-processing module can generate learned inputs with better diversity and more pertinent features as compared to those derived inputs produced by hand-selected pre-processing methods. The backbone module implements multi-scale estimation with two major enhancements: 1) a novel grid structure that effectively alleviates the bottleneck issue via dense connections across different scales; 2) a spatial-channel attention block that can facilitate adaptive fusion by consolidating dehazing-relevant features. The post-processing module helps to reduce the artifacts in the final output. To alleviate domain shift between network training and testing, we convert synthetic data to so-called translated data with the distribution shaped to match that of real data. Moreover, to further improve the dehazing performance in real-world scenarios, we propose a novel intra-task knowledge transfer mechanism that leverages the distilled knowledge from synthetic data to assist the learning process on translated data. Experimental results indicate that the proposed GridDehazeNet+ outperforms the state-of-the-art methods on several dehazing benchmarks. The proposed dehazing method does not rely on the atmosphere scattering model, and we provide a possible explanation as to why it is not necessarily beneficial to take advantage of the dimension reduction offered by this model, even if only the dehazing results on synthetic images are concerned.