 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
3D-OOCS: Learning Prostate Segmentation with Inductive Bias
Oct 29, 2021
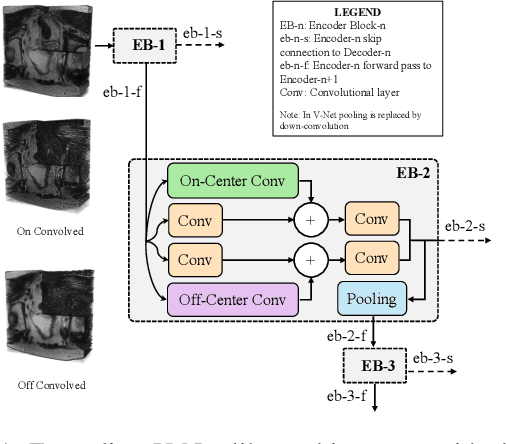
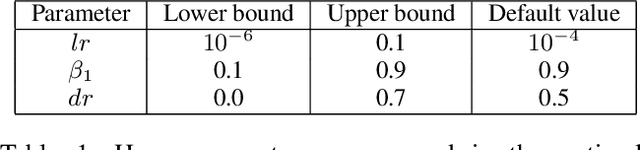
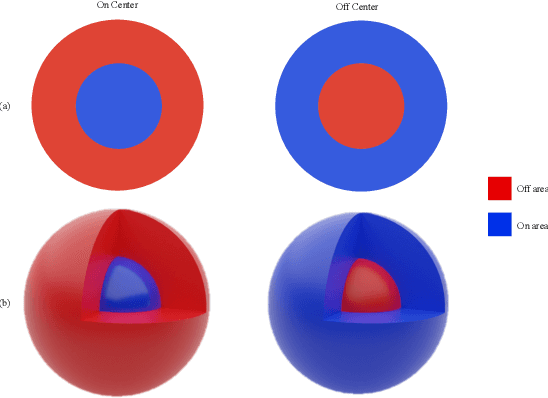
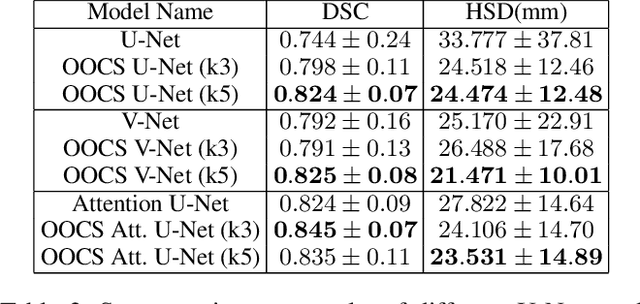
Despite the great success of convolutional neural networks (CNN) in 3D medical image segmentation tasks, the methods currently in use are still not robust enough to the different protocols utilized by different scanners, and to the variety of image properties or artefacts they produce. To this end, we introduce OOCS-enhanced networks, a novel architecture inspired by the innate nature of visual processing in the vertebrates. With different 3D U-Net variants as the base, we add two 3D residual components to the second encoder blocks: on and off center-surround (OOCS). They generalise the ganglion pathways in the retina to a 3D setting. The use of 2D-OOCS in any standard CNN network complements the feedforward framework with sharp edge-detection inductive biases. The use of 3D-OOCS also helps 3D U-Nets to scrutinise and delineate anatomical structures present in 3D images with increased accuracy.We compared the state-of-the-art 3D U-Nets with their 3D-OOCS extensions and showed the superior accuracy and robustness of the latter in automatic prostate segmentation from 3D Magnetic Resonance Images (MRIs). For a fair comparison, we trained and tested all the investigated 3D U-Nets with the same pipeline, including automatic hyperparameter optimisation and data augmentation.
Bounding Boxes Are All We Need: Street View Image Classification via Context Encoding of Detected Buildings
Oct 03, 2020
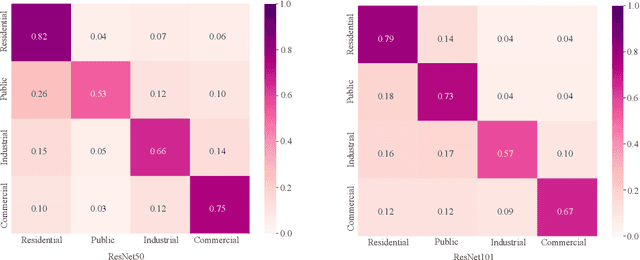
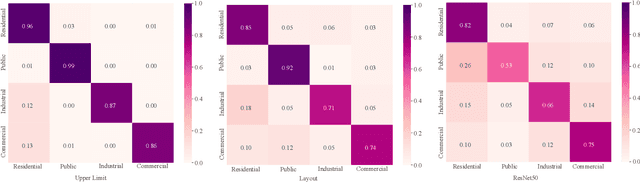

Street view images have been increasingly used in tasks like urban land use classification and urban functional zone portraying. Street view image classification is difficult because the class labels such as commercial area, are concepts with higher abstract level compared to general visual tasks. Therefore, classification models using only visual features often fail to achieve satisfactory performance. We believe that the efficient representation of significant objects and their context relations in street view images are the keys to solve this problem. In this paper, a novel approach based on a detector-encoder-classifier framework is proposed. Different from common image-level end-to-end models, our approach does not use visual features of the whole image directly. The proposed framework obtains the bounding boxes of buildings in street view images from a detector. Their contextual information such as building classes and positions are then encoded into metadata and finally classified by a recurrent neural network (RNN). To verify our approach, we made a dataset of 19,070 street view images and 38,857 buildings based on the BIC_GSV dataset through a combination of automatic label acquisition and expert annotation. The dataset can be used not only for street view image classification aiming at urban land use analysis, but also for multi-class building detection. Experiments show that the proposed approach achieves a 12.65% performance improvement on macro-precision and 12% on macro-recall over the models based on end-to-end convolutional neural network (CNN). Our code and dataset are available at https://github.com/kyle-one/Context-Encoding-of-Detected-Buildings/
OPA: Object Placement Assessment Dataset
Jul 05, 2021Image composition aims to generate realistic composite image by inserting an object from one image into another background image, where the placement (e.g., location, size, occlusion) of inserted object may be unreasonable, which would significantly degrade the quality of the composite image. Although some works attempted to learn object placement to create realistic composite images, they did not focus on assessing the plausibility of object placement. In this paper, we focus on object placement assessment task, which verifies whether a composite image is plausible in terms of the object placement. To accomplish this task, we construct the first Object Placement Assessment (OPA) dataset consisting of composite images and their rationality labels. Dataset is available at https://github.com/bcmi/Object-Placement-Assessment-Dataset-OPA.
Whole Brain Segmentation with Full Volume Neural Network
Oct 29, 2021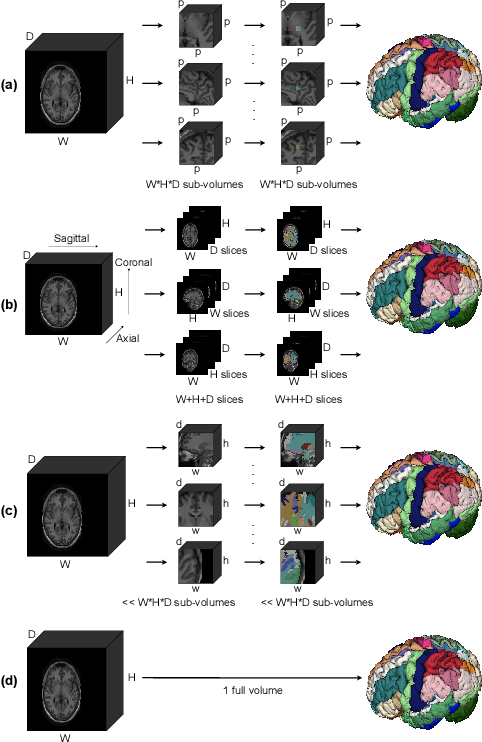
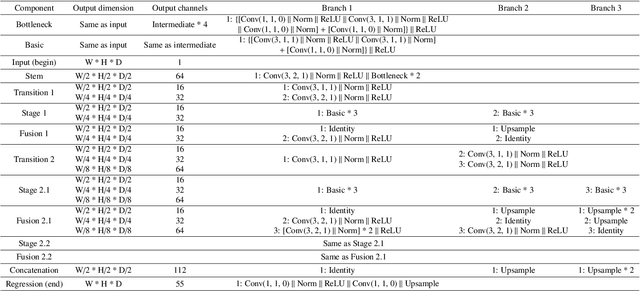
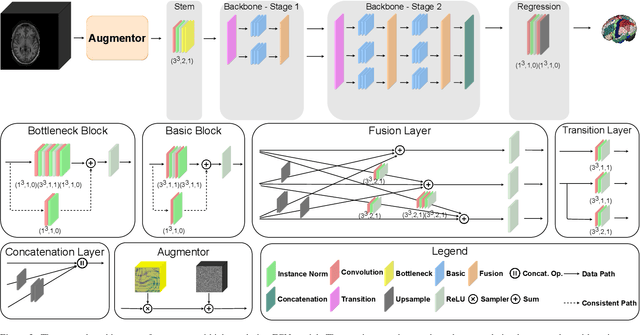
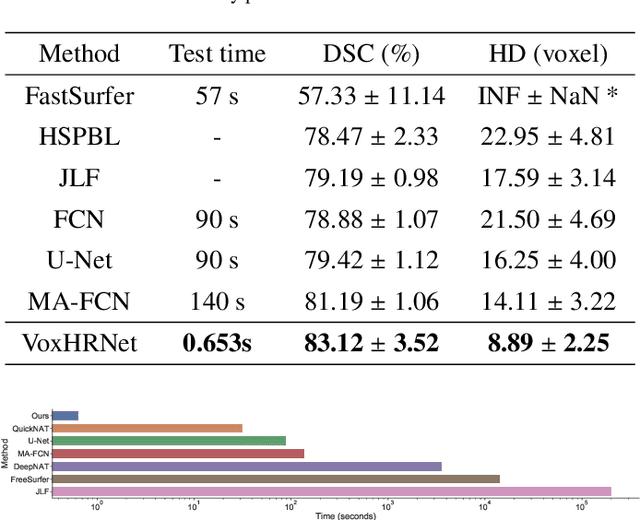
Whole brain segmentation is an important neuroimaging task that segments the whole brain volume into anatomically labeled regions-of-interest. Convolutional neural networks have demonstrated good performance in this task. Existing solutions, usually segment the brain image by classifying the voxels, or labeling the slices or the sub-volumes separately. Their representation learning is based on parts of the whole volume whereas their labeling result is produced by aggregation of partial segmentation. Learning and inference with incomplete information could lead to sub-optimal final segmentation result. To address these issues, we propose to adopt a full volume framework, which feeds the full volume brain image into the segmentation network and directly outputs the segmentation result for the whole brain volume. The framework makes use of complete information in each volume and can be implemented easily. An effective instance in this framework is given subsequently. We adopt the $3$D high-resolution network (HRNet) for learning spatially fine-grained representations and the mixed precision training scheme for memory-efficient training. Extensive experiment results on a publicly available $3$D MRI brain dataset show that our proposed model advances the state-of-the-art methods in terms of segmentation performance. Source code is publicly available at https://github.com/microsoft/VoxHRNet.
* Accepted to CMIG
VisualEchoes: Spatial Image Representation Learning through Echolocation
May 04, 2020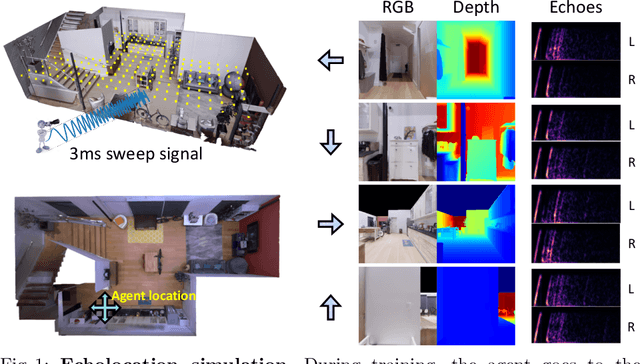

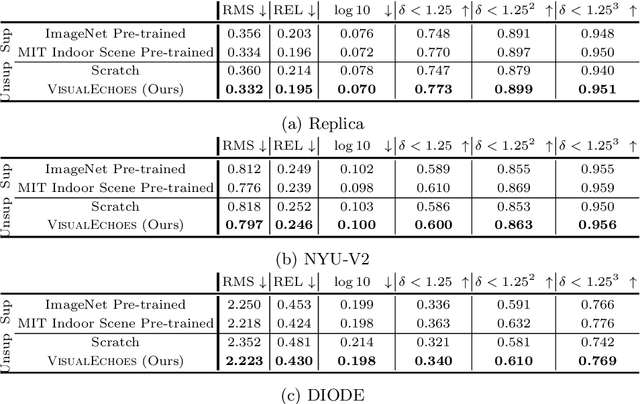
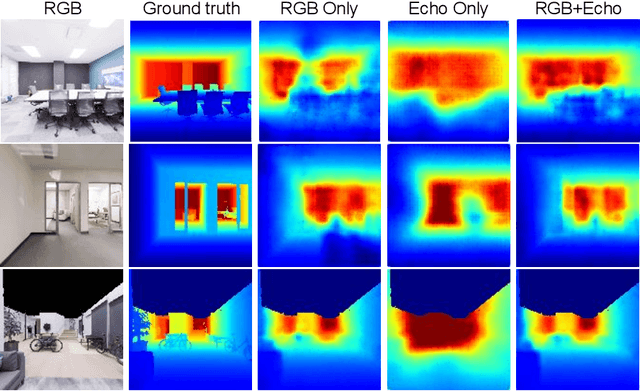
Several animal species (e.g., bats, dolphins, and whales) and even visually impaired humans have the remarkable ability to perform echolocation: a biological sonar used to perceive spatial layout and locate objects in the world. We explore the spatial cues contained in echoes and how they can benefit vision tasks that require spatial reasoning. First we capture echo responses in photo-realistic 3D indoor scene environments. Then we propose a novel interaction-based representation learning framework that learns useful visual features via echolocation. We show that the learned image features are useful for multiple downstream vision tasks requiring spatial reasoning---monocular depth estimation, surface normal estimation, and visual navigation. Our work opens a new path for representation learning for embodied agents, where supervision comes from interacting with the physical world. Our experiments demonstrate that our image features learned from echoes are comparable or even outperform heavily supervised pre-training methods for multiple fundamental spatial tasks.
Sparse regularization with a non-convex penalty for SAR imaging and autofocusing
Aug 22, 2021

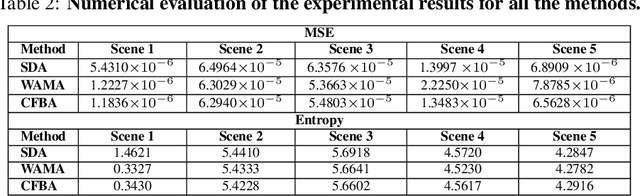

In this paper, SAR image reconstruction with joint phase error estimation (autofocusing) is formulated as an inverse problem. An optimization model utilising a sparsity-enforcing Cauchy regularizer is proposed, and an alternating minimization framework is used to solve it, in which the desired image and the phase errors are optimized alternatively. For the image reconstruction sub-problem (f-sub-problem), two methods are presented capable of handling the problem's complex nature, and we thus present two variants of our SAR image autofocusing algorithm. Firstly, we design a complex version of the forward-backward splitting algorithm (CFBA) to solve the f-sub-problem iteratively. For the second variant, the Wirtinger alternating minimization autofocusing (WAMA) method is presented, in which techniques of Wirtinger calculus are utilized to minimize the complex-valued cost function in the f-sub-problem in a direct fashion. For both methods, the phase error estimation sub-problem is solved by simply expanding and observing its cost function. Moreover, the convergence of both algorithms is discussed in detail. By conducting experiments on both simulated scenes and real SAR images, the proposed method is demonstrated to give impressive autofocusing results compared to other state of the art methods.
Distilling Image Classifiers in Object Detectors
Jun 09, 2021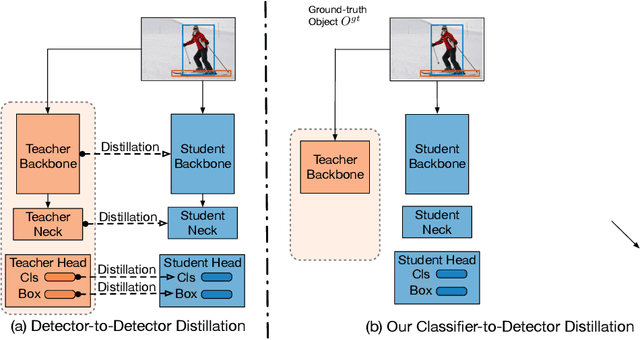
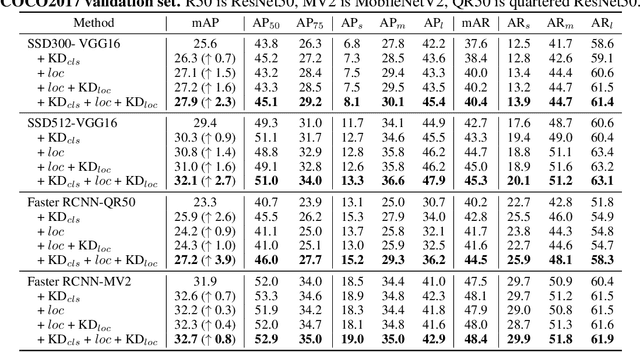
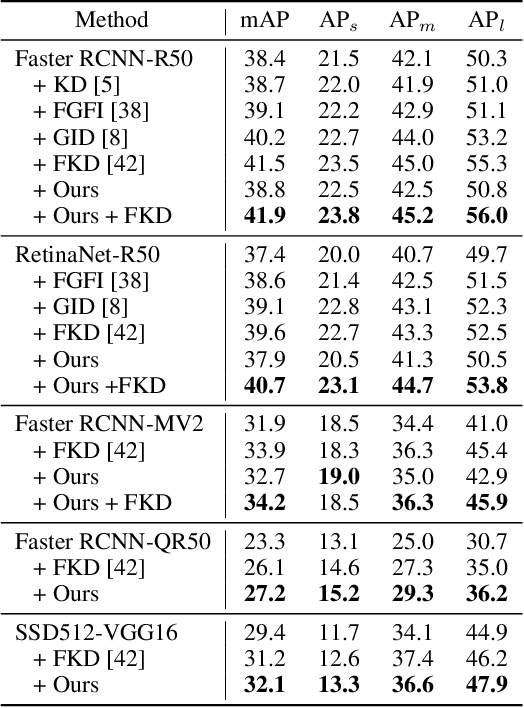

Knowledge distillation constitutes a simple yet effective way to improve the performance of a compact student network by exploiting the knowledge of a more powerful teacher. Nevertheless, the knowledge distillation literature remains limited to the scenario where the student and the teacher tackle the same task. Here, we investigate the problem of transferring knowledge not only across architectures but also across tasks. To this end, we study the case of object detection and, instead of following the standard detector-to-detector distillation approach, introduce a classifier-to-detector knowledge transfer framework. In particular, we propose strategies to exploit the classification teacher to improve both the detector's recognition accuracy and localization performance. Our experiments on several detectors with different backbones demonstrate the effectiveness of our approach, allowing us to outperform the state-of-the-art detector-to-detector distillation methods.
UNITER: Learning UNiversal Image-TExt Representations
Sep 25, 2019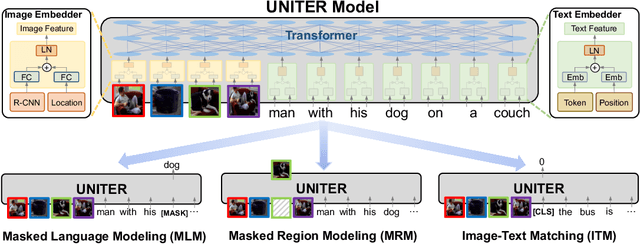

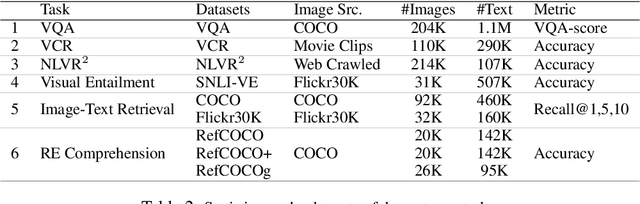
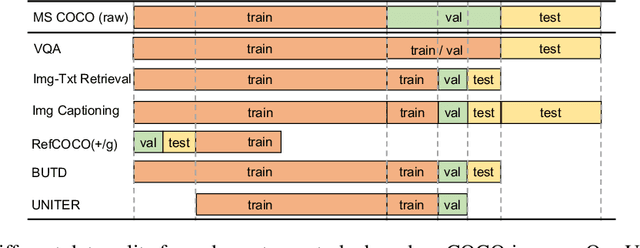
Joint image-text embedding is the bedrock for most Vision-and-Language (V+L) tasks, where multimodality inputs are jointly processed for visual and textual understanding. In this paper, we introduce UNITER, a UNiversal Image-TExt Representation, learned through large-scale pre-training over four image-text datasets (COCO, Visual Genome, Conceptual Captions, and SBU Captions), which can power heterogeneous downstream V+L tasks with joint multimodal embeddings. We design three pre-training tasks: Masked Language Modeling (MLM), Image-Text Matching (ITM), and Masked Region Modeling (MRM, with three variants). Different from concurrent work on multimodal pre-training that apply joint random masking to both modalities, we use conditioned masking on pre-training tasks (i.e., masked language/region modeling is conditioned on full observation of image/text). Comprehensive analysis shows that conditioned masking yields better performance than unconditioned masking. We also conduct a thorough ablation study to find an optimal setting for the combination of pre-training tasks. Extensive experiments show that UNITER achieves new state of the art across six V+L tasks (over nine datasets), including Visual Question Answering, Image-Text Retrieval, Referring Expression Comprehension, Visual Commonsense Reasoning, Visual Entailment, and NLVR2.
FNR: A Similarity and Transformer-Based Approachto Detect Multi-Modal FakeNews in Social Media
Dec 02, 2021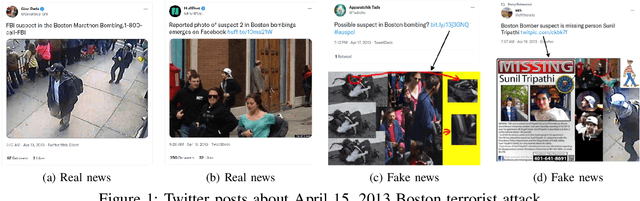
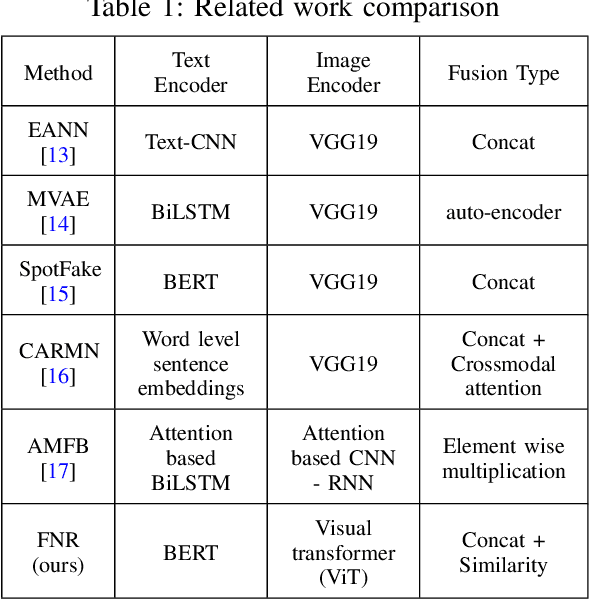
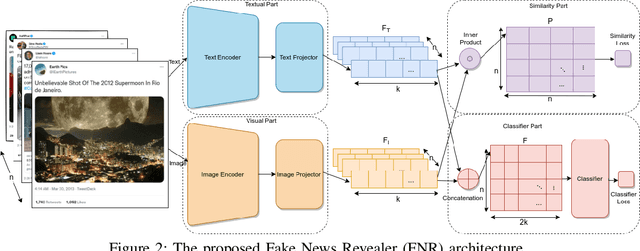
The availability and interactive nature of social media have made them the primary source of news around the globe. The popularity of social media tempts criminals to pursue their immoral intentions by producing and disseminating fake news using seductive text and misleading images. Therefore, verifying social media news and spotting fakes is crucial. This work aims to analyze multi-modal features from texts and images in social media for detecting fake news. We propose a Fake News Revealer (FNR) method that utilizes transform learning to extract contextual and semantic features and contrastive loss to determine the similarity between image and text. We applied FNR on two real social media datasets. The results show the proposed method achieves higher accuracies in detecting fake news compared to the previous works.
Context-aware Padding for Semantic Segmentation
Sep 16, 2021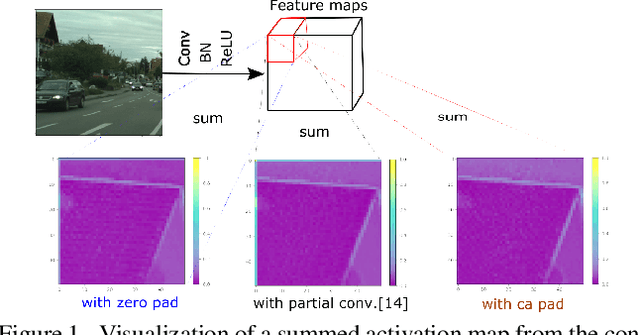

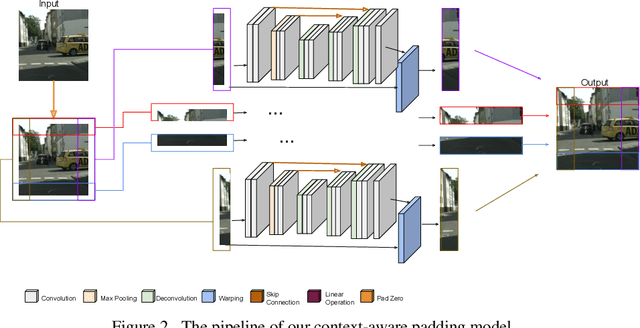

Zero padding is widely used in convolutional neural networks to prevent the size of feature maps diminishing too fast. However, it has been claimed to disturb the statistics at the border. As an alternative, we propose a context-aware (CA) padding approach to extend the image. We reformulate the padding problem as an image extrapolation problem and illustrate the effects on the semantic segmentation task. Using context-aware padding, the ResNet-based segmentation model achieves higher mean Intersection-Over-Union than the traditional zero padding on the Cityscapes and the dataset of DeepGlobe satellite imaging challenge. Furthermore, our padding does not bring noticeable overhead during training and testing.