 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Amplitude-Phase Recombination: Rethinking Robustness of Convolutional Neural Networks in Frequency Domain
Aug 19, 2021
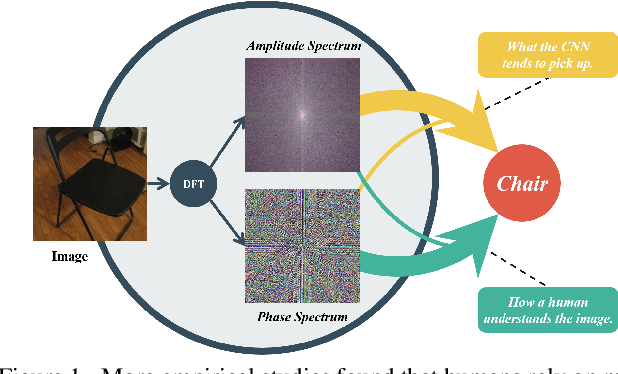
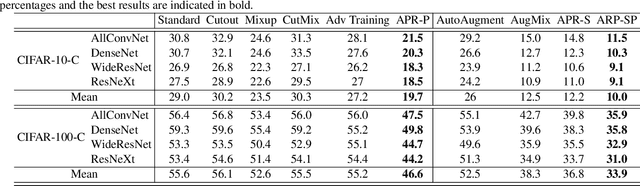

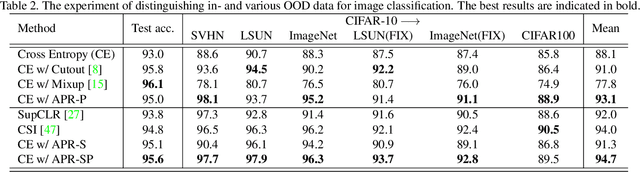
Recently, the generalization behavior of Convolutional Neural Networks (CNN) is gradually transparent through explanation techniques with the frequency components decomposition. However, the importance of the phase spectrum of the image for a robust vision system is still ignored. In this paper, we notice that the CNN tends to converge at the local optimum which is closely related to the high-frequency components of the training images, while the amplitude spectrum is easily disturbed such as noises or common corruptions. In contrast, more empirical studies found that humans rely on more phase components to achieve robust recognition. This observation leads to more explanations of the CNN's generalization behaviors in both robustness to common perturbations and out-of-distribution detection, and motivates a new perspective on data augmentation designed by re-combing the phase spectrum of the current image and the amplitude spectrum of the distracter image. That is, the generated samples force the CNN to pay more attention to the structured information from phase components and keep robust to the variation of the amplitude. Experiments on several image datasets indicate that the proposed method achieves state-of-the-art performances on multiple generalizations and calibration tasks, including adaptability for common corruptions and surface variations, out-of-distribution detection, and adversarial attack.
DDet: Dual-path Dynamic Enhancement Network for Real-World Image Super-Resolution
Feb 25, 2020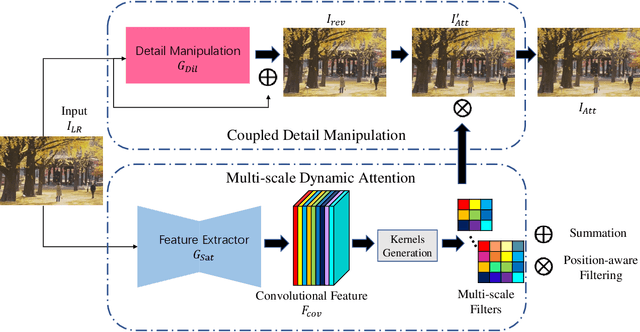
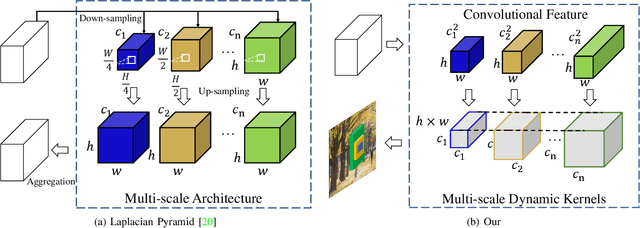

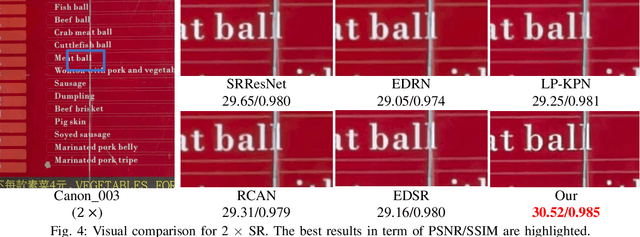
Different from traditional image super-resolution task, real image super-resolution(Real-SR) focus on the relationship between real-world high-resolution(HR) and low-resolution(LR) image. Most of the traditional image SR obtains the LR sample by applying a fixed down-sampling operator. Real-SR obtains the LR and HR image pair by incorporating different quality optical sensors. Generally, Real-SR has more challenges as well as broader application scenarios. Previous image SR methods fail to exhibit similar performance on Real-SR as the image data is not aligned inherently. In this article, we propose a Dual-path Dynamic Enhancement Network(DDet) for Real-SR, which addresses the cross-camera image mapping by realizing a dual-way dynamic sub-pixel weighted aggregation and refinement. Unlike conventional methods which stack up massive convolutional blocks for feature representation, we introduce a content-aware framework to study non-inherently aligned image pair in image SR issue. First, we use a content-adaptive component to exhibit the Multi-scale Dynamic Attention(MDA). Second, we incorporate a long-term skip connection with a Coupled Detail Manipulation(CDM) to perform collaborative compensation and manipulation. The above dual-path model is joint into a unified model and works collaboratively. Extensive experiments on the challenging benchmarks demonstrate the superiority of our model.
Barely-Supervised Learning: Semi-Supervised Learning with very few labeled images
Dec 22, 2021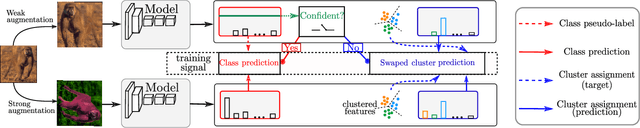
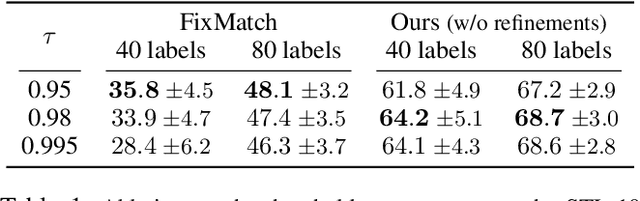
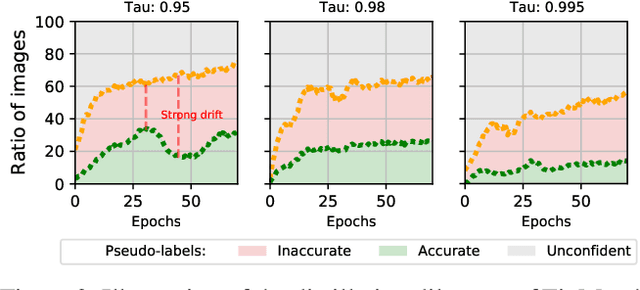

This paper tackles the problem of semi-supervised learning when the set of labeled samples is limited to a small number of images per class, typically less than 10, problem that we refer to as barely-supervised learning. We analyze in depth the behavior of a state-of-the-art semi-supervised method, FixMatch, which relies on a weakly-augmented version of an image to obtain supervision signal for a more strongly-augmented version. We show that it frequently fails in barely-supervised scenarios, due to a lack of training signal when no pseudo-label can be predicted with high confidence. We propose a method to leverage self-supervised methods that provides training signal in the absence of confident pseudo-labels. We then propose two methods to refine the pseudo-label selection process which lead to further improvements. The first one relies on a per-sample history of the model predictions, akin to a voting scheme. The second iteratively updates class-dependent confidence thresholds to better explore classes that are under-represented in the pseudo-labels. Our experiments show that our approach performs significantly better on STL-10 in the barely-supervised regime, e.g. with 4 or 8 labeled images per class.
Efficient Deep Feature Calibration for Cross-Modal Joint Embedding Learning
Aug 08, 2021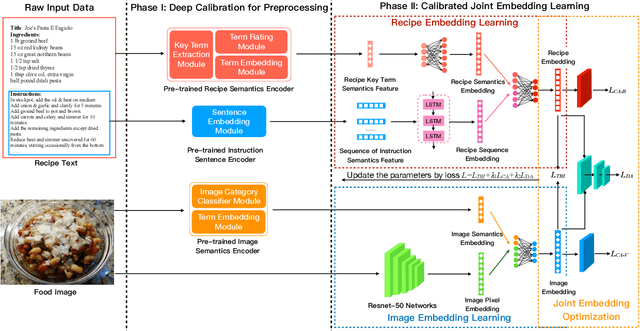
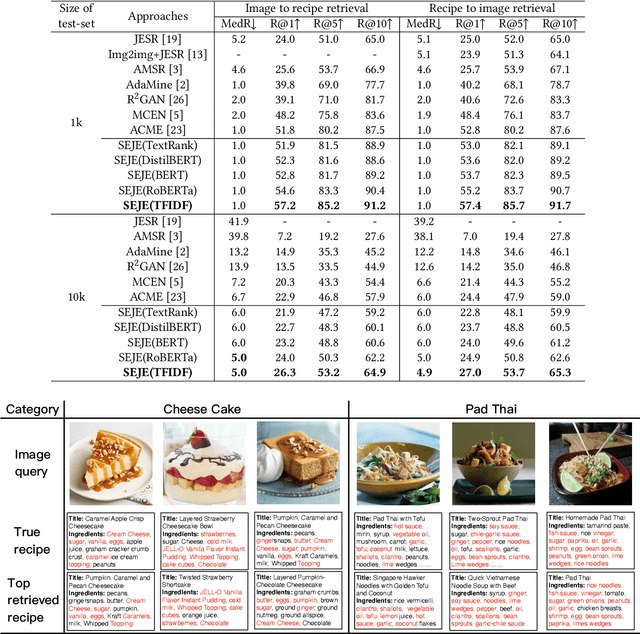

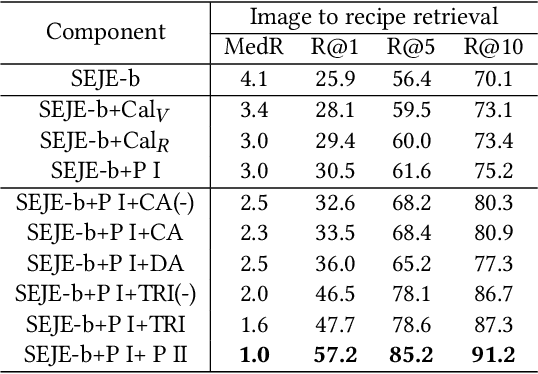
This paper introduces a two-phase deep feature calibration framework for efficient learning of semantics enhanced text-image cross-modal joint embedding, which clearly separates the deep feature calibration in data preprocessing from training the joint embedding model. We use the Recipe1M dataset for the technical description and empirical validation. In preprocessing, we perform deep feature calibration by combining deep feature engineering with semantic context features derived from raw text-image input data. We leverage LSTM to identify key terms, NLP methods to produce ranking scores for key terms before generating the key term feature. We leverage wideResNet50 to extract and encode the image category semantics to help semantic alignment of the learned recipe and image embeddings in the joint latent space. In joint embedding learning, we perform deep feature calibration by optimizing the batch-hard triplet loss function with soft-margin and double negative sampling, also utilizing the category-based alignment loss and discriminator-based alignment loss. Extensive experiments demonstrate that our SEJE approach with the deep feature calibration significantly outperforms the state-of-the-art approaches.
Towards Robust Classification with Image Quality Assessment
Apr 14, 2020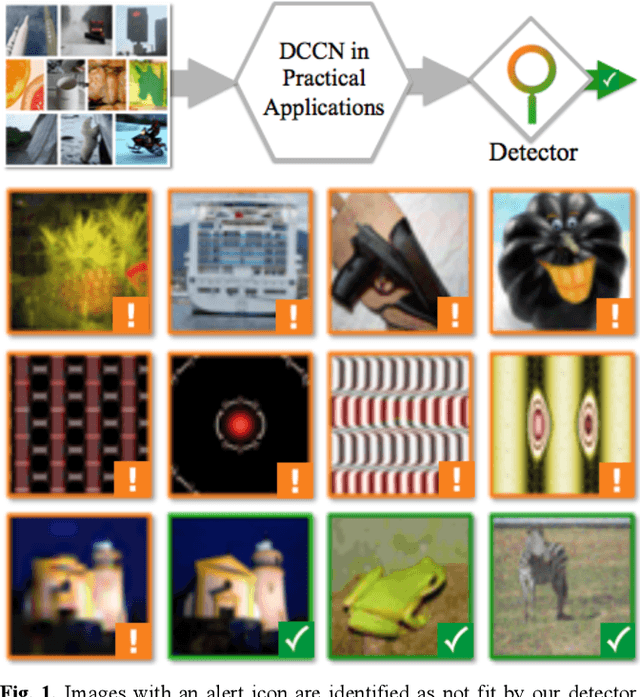
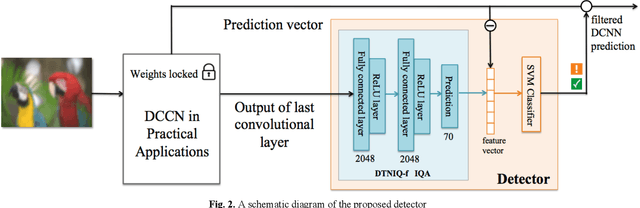
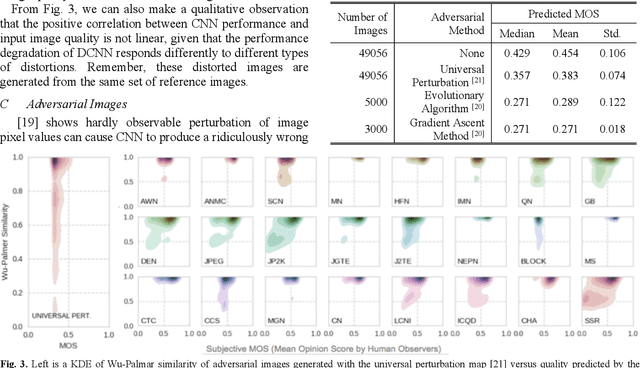
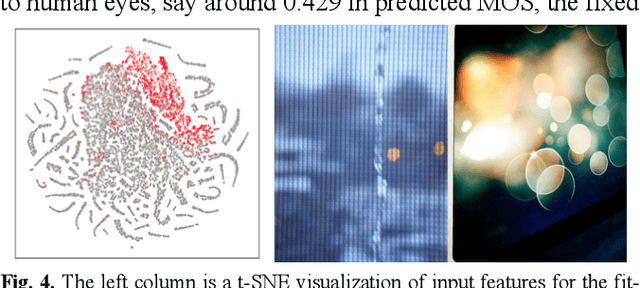
Recent studies have shown that deep convolutional neural networks (DCNN) are vulnerable to adversarial examples and sensitive to perceptual quality as well as the acquisition condition of images. These findings raise a big concern for the adoption of DCNN-based applications for critical tasks. In the literature, various defense strategies have been introduced to increase the robustness of DCNN, including re-training an entire model with benign noise injection, adversarial examples, or adding extra layers. In this paper, we investigate the connection between adversarial manipulation and image quality, subsequently propose a protective mechanism that doesnt require re-training a DCNN. Our method combines image quality assessment with knowledge distillation to detect input images that would trigger a DCCN to produce egregiously wrong results. Using the ResNet model trained on ImageNet as an example, we demonstrate that the detector can effectively identify poor quality and adversarial images.
A General Divergence Modeling Strategy for Salient Object Detection
Nov 23, 2021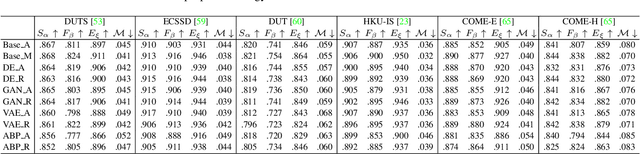
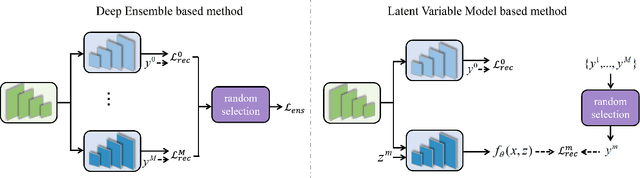
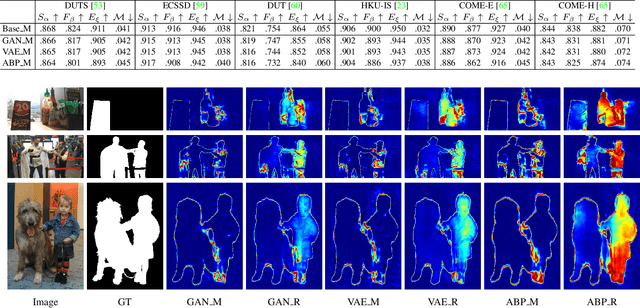
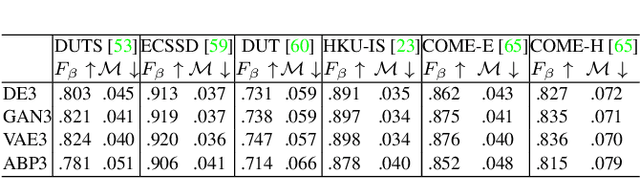
Salient object detection is subjective in nature, which implies that multiple estimations should be related to the same input image. Most existing salient object detection models are deterministic following a point to point estimation learning pipeline, making them incapable to estimate the predictive distribution. Although latent variable model based stochastic prediction network exists to model the prediction variants, the latent space based on the single clean saliency annotation is less reliable in exploring the subjective nature of saliency, leading to less effective saliency "divergence modeling". Given multiple saliency annotations, we introduce a general divergence modeling strategy via random sampling, and apply our strategy to an ensemble based framework and three latent variable model based solutions. Experimental results indicate that our general divergence modeling strategy works superiorly in exploring the subjective nature of saliency.
How Reliable Are Out-of-Distribution Generalization Methods for Medical Image Segmentation?
Sep 03, 2021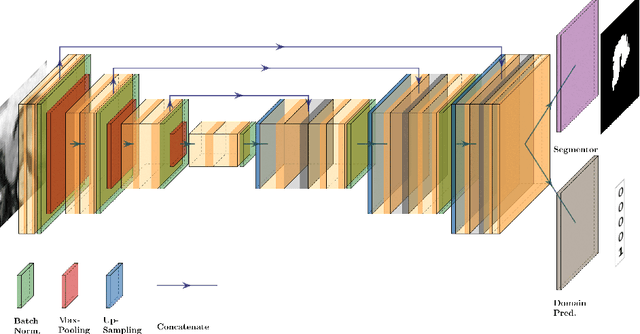

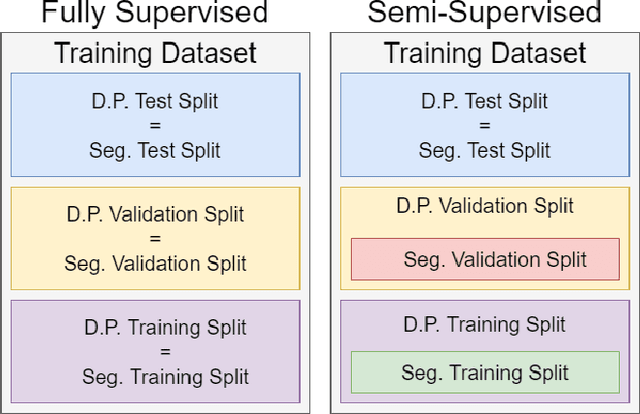

The recent achievements of Deep Learning rely on the test data being similar in distribution to the training data. In an ideal case, Deep Learning models would achieve Out-of-Distribution (OoD) Generalization, i.e. reliably make predictions on out-of-distribution data. Yet in practice, models usually fail to generalize well when facing a shift in distribution. Several methods were thereby designed to improve the robustness of the features learned by a model through Regularization- or Domain-Prediction-based schemes. Segmenting medical images such as MRIs of the hippocampus is essential for the diagnosis and treatment of neuropsychiatric disorders. But these brain images often suffer from distribution shift due to the patient's age and various pathologies affecting the shape of the organ. In this work, we evaluate OoD Generalization solutions for the problem of hippocampus segmentation in MR data using both fully- and semi-supervised training. We find that no method performs reliably in all experiments. Only the V-REx loss stands out as it remains easy to tune, while it outperforms a standard U-Net in most cases.
Learning Invariant Representation for Unsupervised Image Restoration
Mar 28, 2020
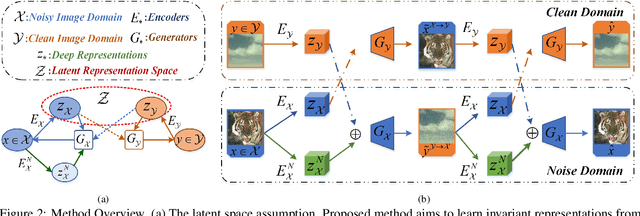

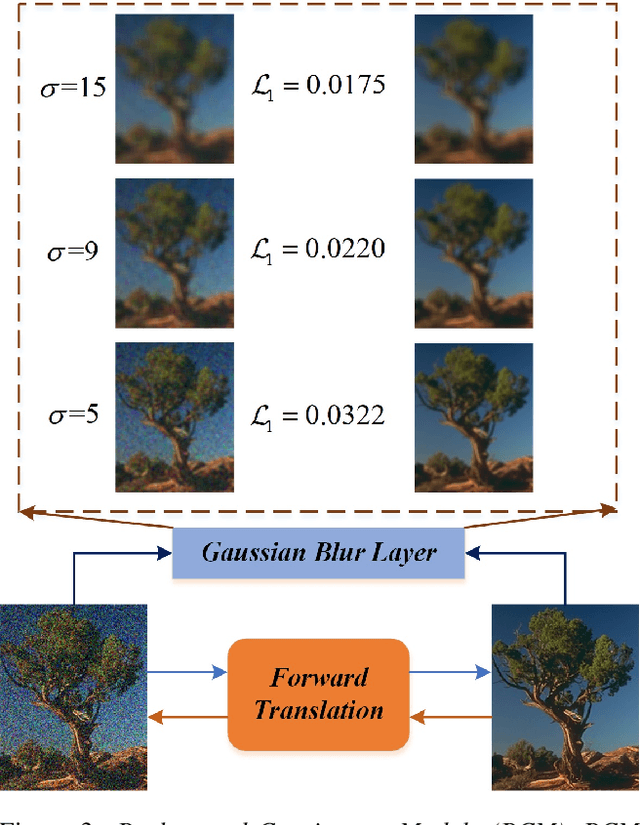
Recently, cross domain transfer has been applied for unsupervised image restoration tasks. However, directly applying existing frameworks would lead to domain-shift problems in translated images due to lack of effective supervision. Instead, we propose an unsupervised learning method that explicitly learns invariant presentation from noisy data and reconstructs clear observations. To do so, we introduce discrete disentangling representation and adversarial domain adaption into general domain transfer framework, aided by extra self-supervised modules including background and semantic consistency constraints, learning robust representation under dual domain constraints, such as feature and image domains. Experiments on synthetic and real noise removal tasks show the proposed method achieves comparable performance with other state-of-the-art supervised and unsupervised methods, while having faster and stable convergence than other domain adaption methods.
Composing Text and Image for Image Retrieval - An Empirical Odyssey
Dec 18, 2018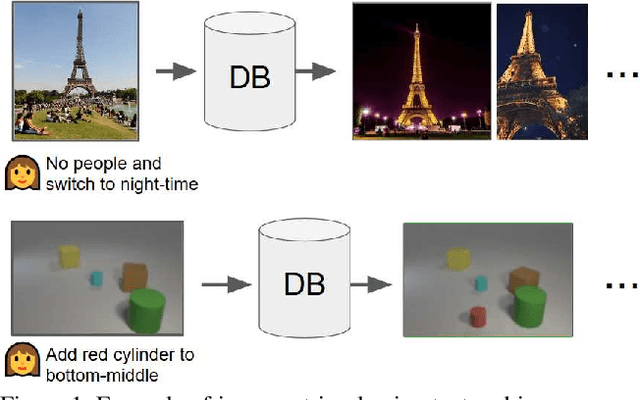
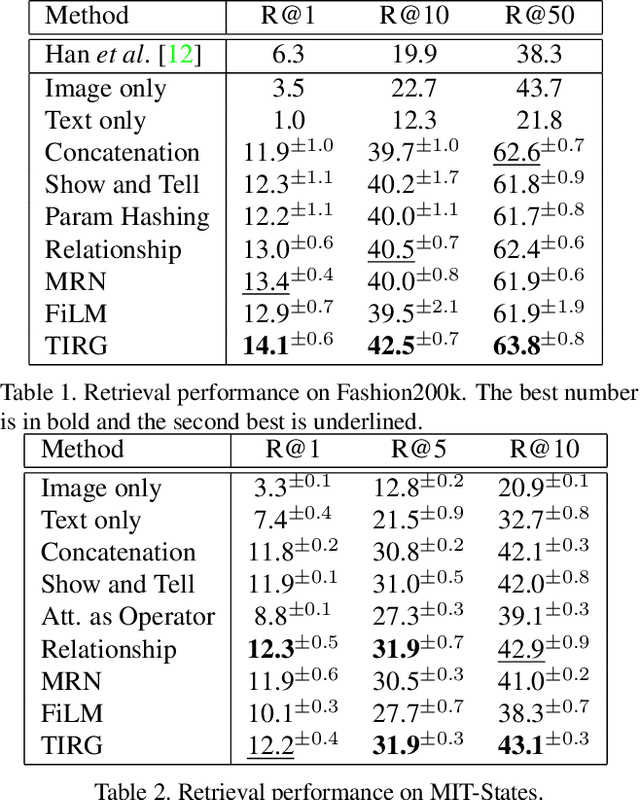
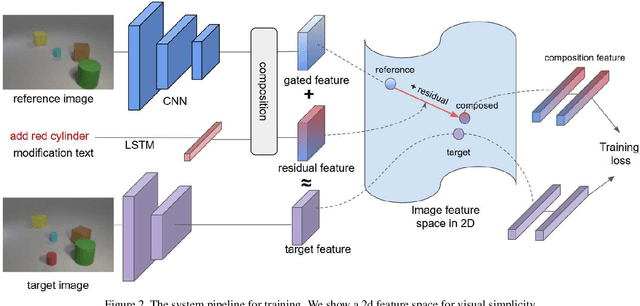

In this paper, we study the task of image retrieval, where the input query is specified in the form of an image plus some text that describes desired modifications to the input image. For example, we may present an image of the Eiffel tower, and ask the system to find images which are visually similar but are modified in small ways, such as being taken at nighttime instead of during the day. To tackle this task, we learn a similarity metric between a target image and a source image plus source text, an embedding and composing function such that target image feature is close to the source image plus text composition feature. We propose a new way to combine image and text using such function that is designed for the retrieval task. We show this outperforms existing approaches on 3 different datasets, namely Fashion-200k, MIT-States and a new synthetic dataset we create based on CLEVR. We also show that our approach can be used to classify input queries, in addition to image retrieval.
IconQA: A New Benchmark for Abstract Diagram Understanding and Visual Language Reasoning
Oct 25, 2021
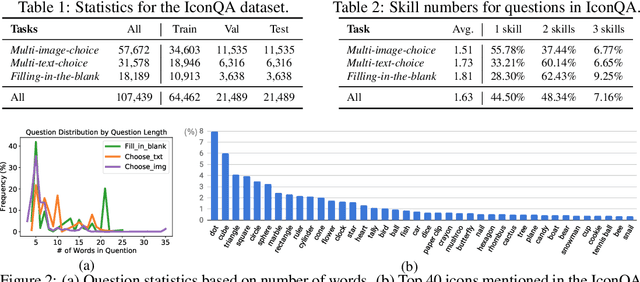

Current visual question answering (VQA) tasks mainly consider answering human-annotated questions for natural images. However, aside from natural images, abstract diagrams with semantic richness are still understudied in visual understanding and reasoning research. In this work, we introduce a new challenge of Icon Question Answering (IconQA) with the goal of answering a question in an icon image context. We release IconQA, a large-scale dataset that consists of 107,439 questions and three sub-tasks: multi-image-choice, multi-text-choice, and filling-in-the-blank. The IconQA dataset is inspired by real-world diagram word problems that highlight the importance of abstract diagram understanding and comprehensive cognitive reasoning. Thus, IconQA requires not only perception skills like object recognition and text understanding, but also diverse cognitive reasoning skills, such as geometric reasoning, commonsense reasoning, and arithmetic reasoning. To facilitate potential IconQA models to learn semantic representations for icon images, we further release an icon dataset Icon645 which contains 645,687 colored icons on 377 classes. We conduct extensive user studies and blind experiments and reproduce a wide range of advanced VQA methods to benchmark the IconQA task. Also, we develop a strong IconQA baseline Patch-TRM that applies a pyramid cross-modal Transformer with input diagram embeddings pre-trained on the icon dataset. IconQA and Icon645 are available at https://iconqa.github.io.