 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Simple Single-Scale Vision Transformer for Object Localization and Instance Segmentation
Dec 17, 2021
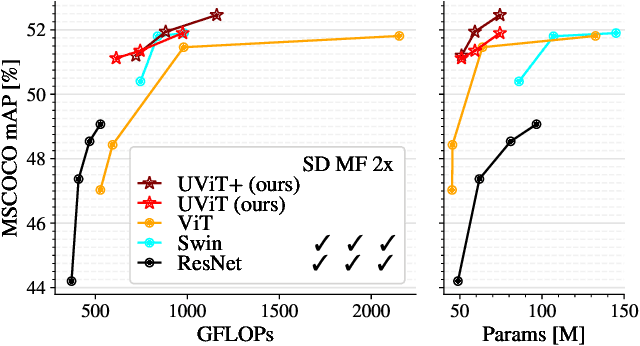

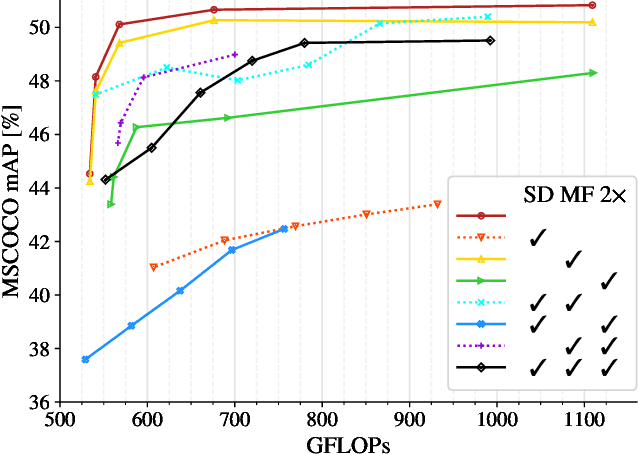

This work presents a simple vision transformer design as a strong baseline for object localization and instance segmentation tasks. Transformers recently demonstrate competitive performance in image classification tasks. To adopt ViT to object detection and dense prediction tasks, many works inherit the multistage design from convolutional networks and highly customized ViT architectures. Behind this design, the goal is to pursue a better trade-off between computational cost and effective aggregation of multiscale global contexts. However, existing works adopt the multistage architectural design as a black-box solution without a clear understanding of its true benefits. In this paper, we comprehensively study three architecture design choices on ViT -- spatial reduction, doubled channels, and multiscale features -- and demonstrate that a vanilla ViT architecture can fulfill this goal without handcrafting multiscale features, maintaining the original ViT design philosophy. We further complete a scaling rule to optimize our model's trade-off on accuracy and computation cost / model size. By leveraging a constant feature resolution and hidden size throughout the encoder blocks, we propose a simple and compact ViT architecture called Universal Vision Transformer (UViT) that achieves strong performance on COCO object detection and instance segmentation tasks.
KFWC: A Knowledge-Driven Deep Learning Model for Fine-grained Classification of Wet-AMD
Dec 23, 2021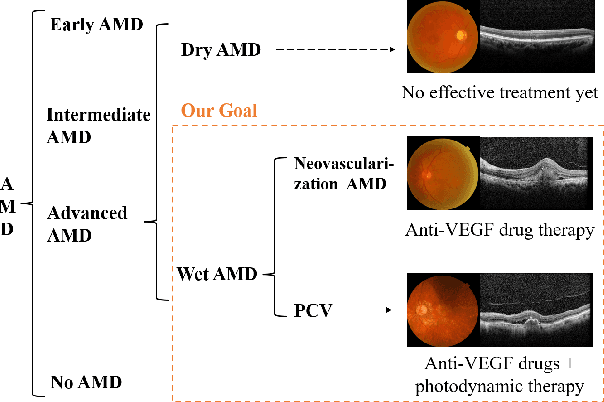
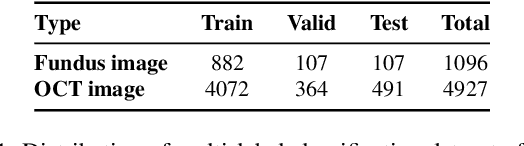
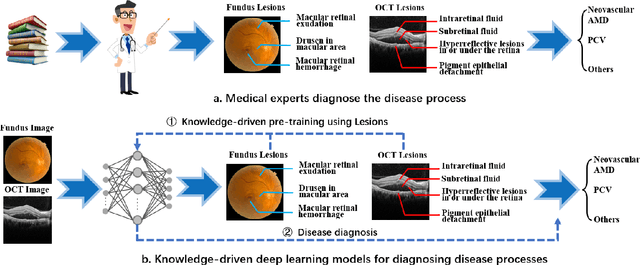
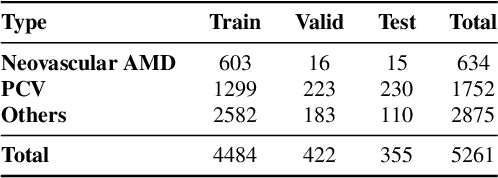
Automated diagnosis using deep neural networks can help ophthalmologists detect the blinding eye disease wet Age-related Macular Degeneration (AMD). Wet-AMD has two similar subtypes, Neovascular AMD and Polypoidal Choroidal Vessels (PCV). However, due to the difficulty in data collection and the similarity between images, most studies have only achieved the coarse-grained classification of wet-AMD rather than a finer-grained one of wet-AMD subtypes. To solve this issue, in this paper we propose a Knowledge-driven Fine-grained Wet-AMD Classification Model (KFWC), to classify fine-grained diseases with insufficient data. With the introduction of a priori knowledge of 10 lesion signs of input images into the KFWC, we aim to accelerate the KFWC by means of multi-label classification pre-training, to locate the decisive image features in the fine-grained disease classification task and therefore achieve better classification. Simultaneously, the KFWC can also provide good interpretability and effectively alleviate the pressure of data collection and annotation in the field of fine-grained disease classification for wet-AMD. The experiments demonstrate the effectiveness of the KFWC which reaches 99.71% in AU-ROC scores, and its considerable improvements over the data-driven w/o Knowledge and ophthalmologists, with the rates of 6.69% over the strongest baseline and 4.14% over ophthalmologists.
Deep Transfer Learning for Land Use Land Cover Classification: A Comparative Study
Oct 08, 2021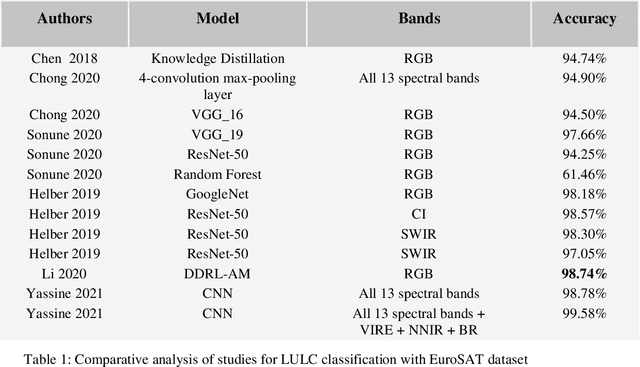
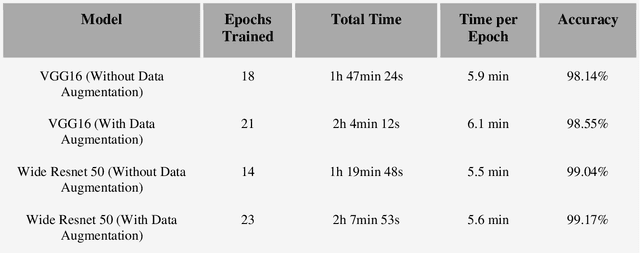
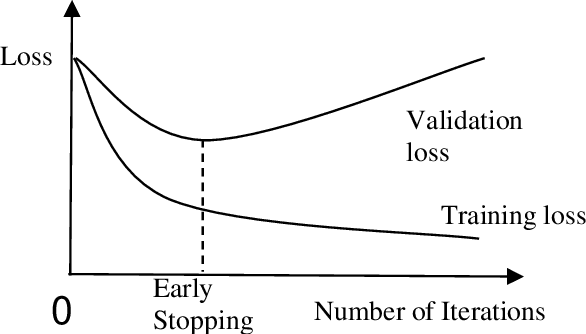
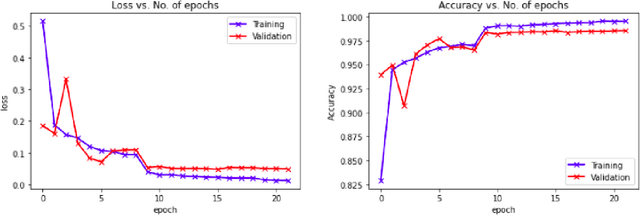
Efficiently implementing remote sensing image classification with high spatial resolution imagery can provide great significant value in land-use land-cover classification (LULC). The developments in remote sensing and deep learning technologies have facilitated the extraction of spatiotemporal information for LULC classification. Moreover, the diverse disciplines of science, including remote sensing, have utilised tremendous improvements in image classification by CNNs with Transfer Learning. In this study, instead of training CNNs from scratch, we make use of transfer learning to fine-tune pre-trained networks a) VGG16 and b) Wide Residual Networks (WRNs), by replacing the final layer with additional layers, for LULC classification with EuroSAT dataset. Further, the performance and computational time were compared and optimized with techniques like early stopping, gradient clipping, adaptive learning rates and data augmentation. With the proposed approaches we were able to address the limited-data problem and achieved very good accuracy. Comprehensive comparisons over the EuroSAT RGB version benchmark have successfully established that our method outperforms the previous best-stated results, with a significant improvement over the accuracy from 98.57% to 99.17%.
DDet: Dual-path Dynamic Enhancement Network for Real-World Image Super-Resolution
Feb 25, 2020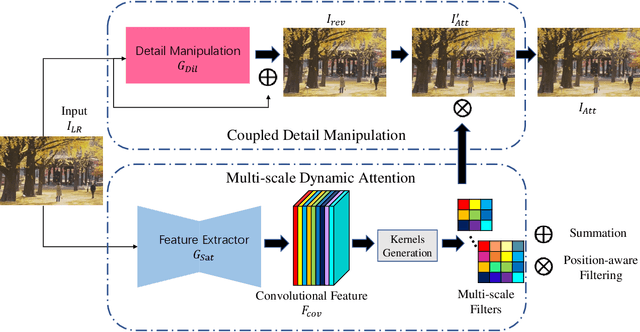
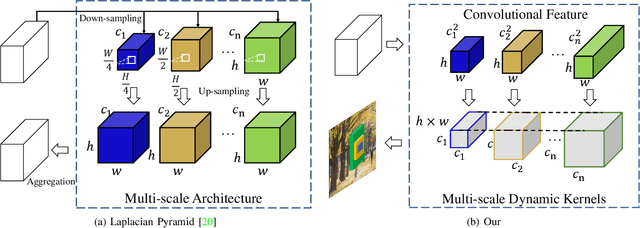

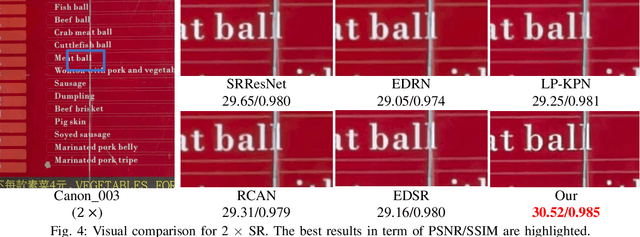
Different from traditional image super-resolution task, real image super-resolution(Real-SR) focus on the relationship between real-world high-resolution(HR) and low-resolution(LR) image. Most of the traditional image SR obtains the LR sample by applying a fixed down-sampling operator. Real-SR obtains the LR and HR image pair by incorporating different quality optical sensors. Generally, Real-SR has more challenges as well as broader application scenarios. Previous image SR methods fail to exhibit similar performance on Real-SR as the image data is not aligned inherently. In this article, we propose a Dual-path Dynamic Enhancement Network(DDet) for Real-SR, which addresses the cross-camera image mapping by realizing a dual-way dynamic sub-pixel weighted aggregation and refinement. Unlike conventional methods which stack up massive convolutional blocks for feature representation, we introduce a content-aware framework to study non-inherently aligned image pair in image SR issue. First, we use a content-adaptive component to exhibit the Multi-scale Dynamic Attention(MDA). Second, we incorporate a long-term skip connection with a Coupled Detail Manipulation(CDM) to perform collaborative compensation and manipulation. The above dual-path model is joint into a unified model and works collaboratively. Extensive experiments on the challenging benchmarks demonstrate the superiority of our model.
Active Ensemble Deep Learning for Polarimetric Synthetic Aperture Radar Image Classification
Jun 29, 2020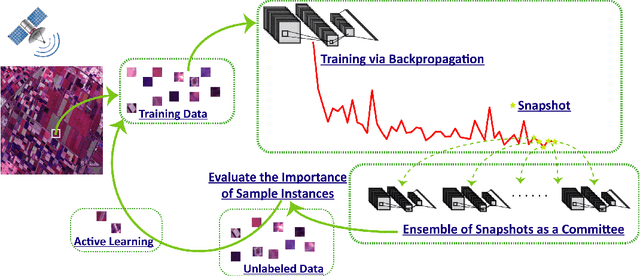
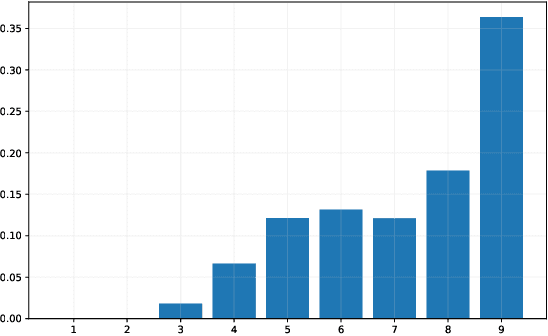
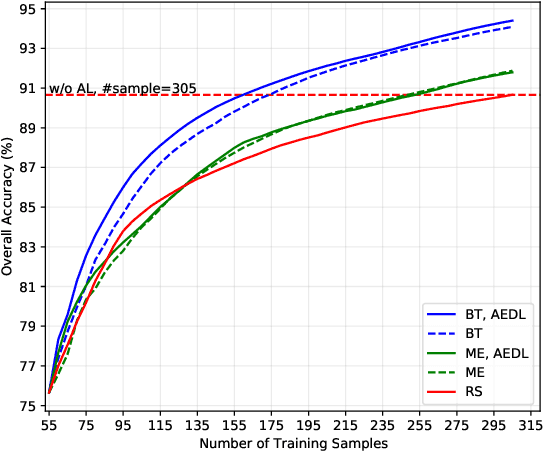
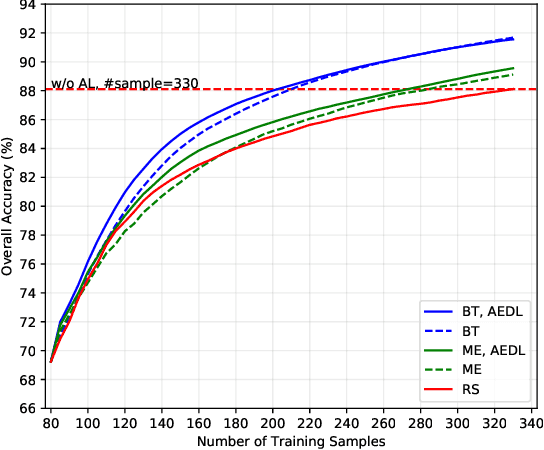
Although deep learning has achieved great success in image classification tasks, its performance is subject to the quantity and quality of training samples. For classification of polarimetric synthetic aperture radar (PolSAR) images, it is nearly impossible to annotate the images from visual interpretation. Therefore, it is urgent for remote sensing scientists to develop new techniques for PolSAR image classification under the condition of very few training samples. In this letter, we take the advantage of active learning and propose active ensemble deep learning (AEDL) for PolSAR image classification. We first show that only 35\% of the predicted labels of a deep learning model's snapshots near its convergence were exactly the same. The disagreement between snapshots is non-negligible. From the perspective of multiview learning, the snapshots together serve as a good committee to evaluate the importance of unlabeled instances. Using the snapshots committee to give out the informativeness of unlabeled data, the proposed AEDL achieved better performance on two real PolSAR images compared with standard active learning strategies. It achieved the same classification accuracy with only 86% and 55% of the training samples compared with breaking ties active learning and random selection for the Flevoland dataset.
Incremental Learning for Animal Pose Estimation using RBF k-DPP
Oct 26, 2021



Pose estimation is the task of locating keypoints for an object of interest in an image. Animal Pose estimation is more challenging than estimating human pose due to high inter and intra class variability in animals. Existing works solve this problem for a fixed set of predefined animal categories. Models trained on such sets usually do not work well with new animal categories. Retraining the model on new categories makes the model overfit and leads to catastrophic forgetting. Thus, in this work, we propose a novel problem of "Incremental Learning for Animal Pose Estimation". Our method uses an exemplar memory, sampled using Determinantal Point Processes (DPP) to continually adapt to new animal categories without forgetting the old ones. We further propose a new variant of k-DPP that uses RBF kernel (termed as "RBF k-DPP") which gives more gain in performance over traditional k-DPP. Due to memory constraints, the limited number of exemplars along with new class data can lead to class imbalance. We mitigate it by performing image warping as an augmentation technique. This helps in crafting diverse poses, which reduces overfitting and yields further improvement in performance. The efficacy of our proposed approach is demonstrated via extensive experiments and ablations where we obtain significant improvements over state-of-the-art baseline methods.
Cubical Ripser: Software for computing persistent homology of image and volume data
Jun 12, 2020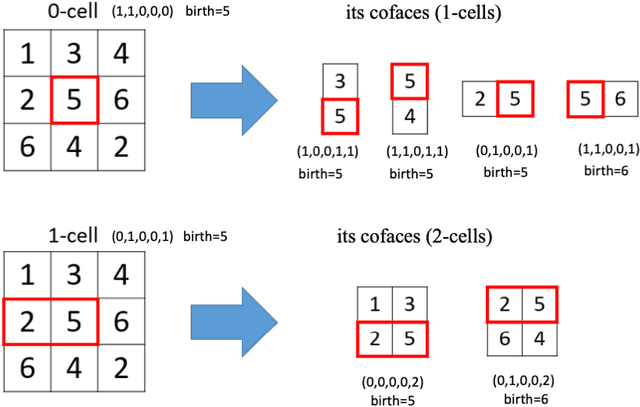



We introduce Cubical Ripser for computing persistent homology of image and volume data (more precisely, weighted cubical complexes). To our best knowledge, Cubical Ripser is currently the fastest and the most memory-efficient program for computing persistent homology of weighted cubical complexes. We demonstrate our software with an example of image analysis in which persistent homology and convolutional neural networks are successfully combined. Our open-source implementation is available online.
CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models
Oct 08, 2021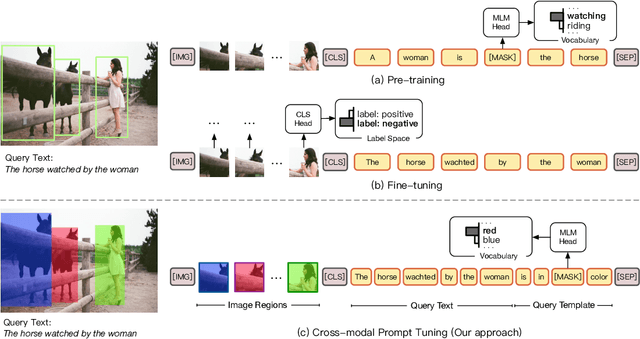
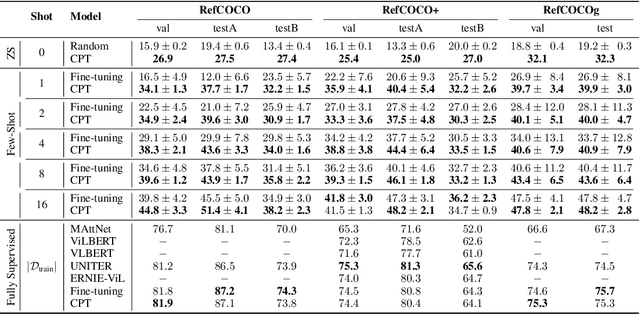
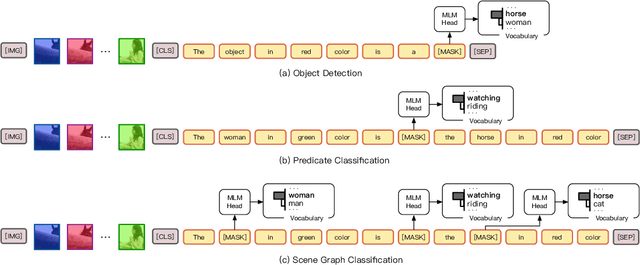
Pre-Trained Vision-Language Models (VL-PTMs) have shown promising capabilities in grounding natural language in image data, facilitating a broad variety of cross-modal tasks. However, we note that there exists a significant gap between the objective forms of model pre-training and fine-tuning, resulting in a need for large amounts of labeled data to stimulate the visual grounding capability of VL-PTMs for downstream tasks. To address the challenge, we present Cross-modal Prompt Tuning (CPT, alternatively, Colorful Prompt Tuning), a novel paradigm for tuning VL-PTMs, which reformulates visual grounding into a fill-in-the-blank problem with color-based co-referential markers in image and text, maximally mitigating the gap. In this way, CPT enables strong few-shot and even zero-shot visual grounding capabilities of VL-PTMs. Comprehensive experimental results show that the prompt-tuned VL-PTMs outperform their fine-tuned counterparts by a large margin (e.g., 17.3% absolute accuracy improvement, and 73.8% relative standard deviation reduction on average with one shot in RefCOCO evaluation). All the data and codes will be available to facilitate future research.
Composing Text and Image for Image Retrieval - An Empirical Odyssey
Dec 18, 2018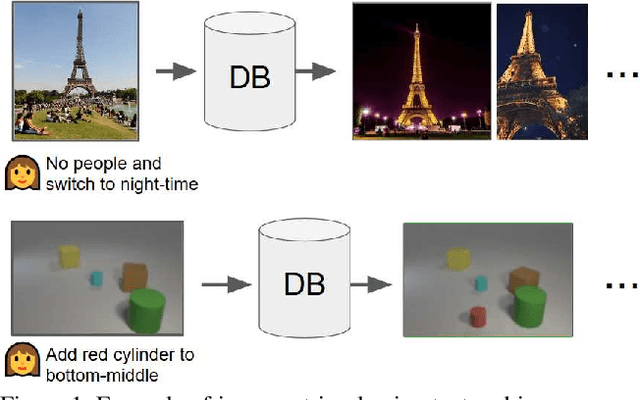
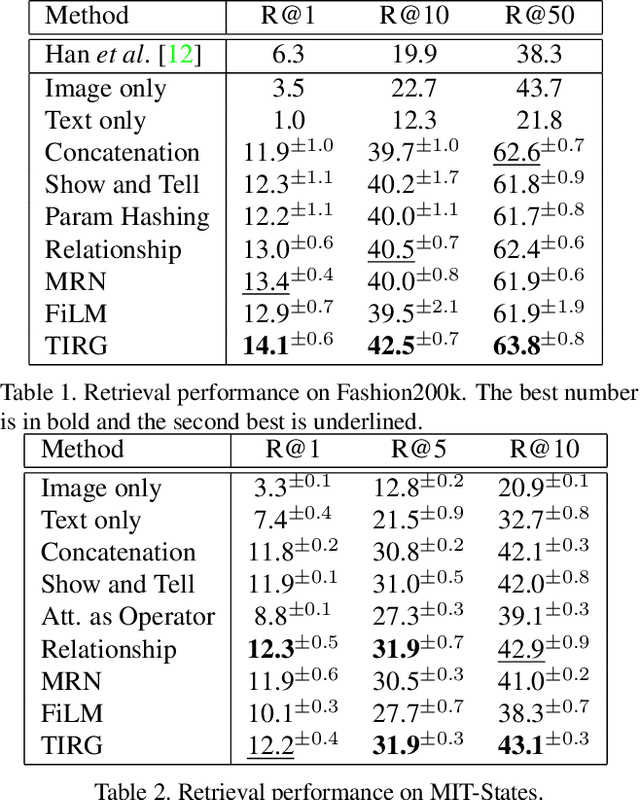
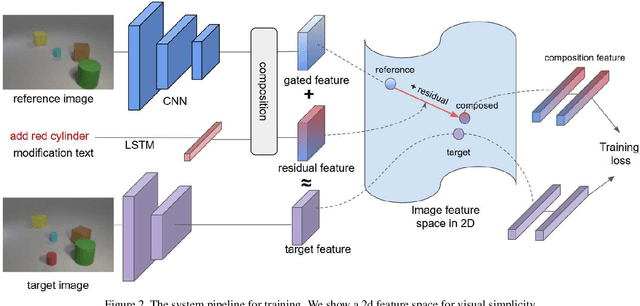

In this paper, we study the task of image retrieval, where the input query is specified in the form of an image plus some text that describes desired modifications to the input image. For example, we may present an image of the Eiffel tower, and ask the system to find images which are visually similar but are modified in small ways, such as being taken at nighttime instead of during the day. To tackle this task, we learn a similarity metric between a target image and a source image plus source text, an embedding and composing function such that target image feature is close to the source image plus text composition feature. We propose a new way to combine image and text using such function that is designed for the retrieval task. We show this outperforms existing approaches on 3 different datasets, namely Fashion-200k, MIT-States and a new synthetic dataset we create based on CLEVR. We also show that our approach can be used to classify input queries, in addition to image retrieval.
Towards Deep Learning-based 6D Bin Pose Estimation in 3D Scans
Dec 17, 2021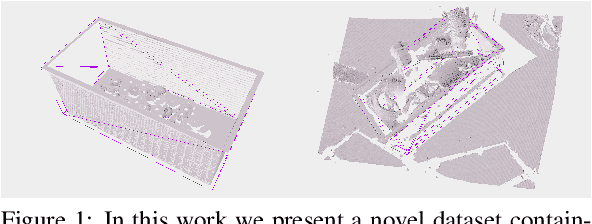
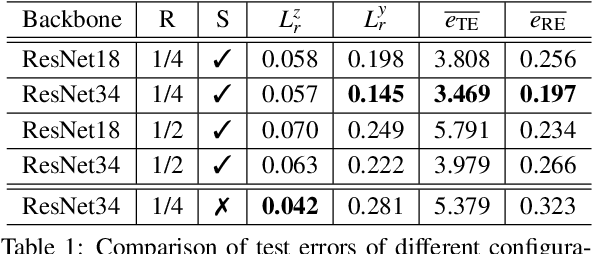
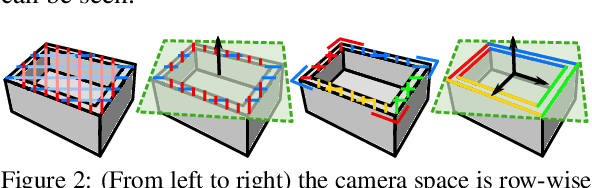
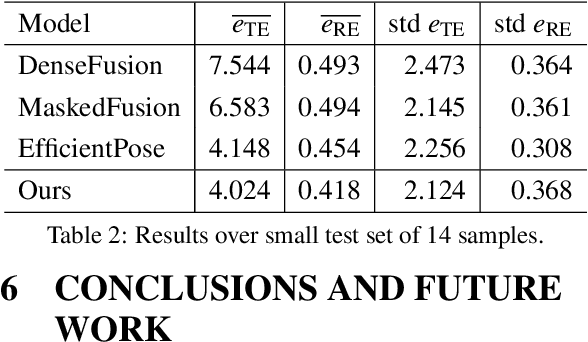
An automated robotic system needs to be as robust as possible and fail-safe in general while having relatively high precision and repeatability. Although deep learning-based methods are becoming research standard on how to approach 3D scan and image processing tasks, the industry standard for processing this data is still analytically-based. Our paper claims that analytical methods are less robust and harder for testing, updating, and maintaining. This paper focuses on a specific task of 6D pose estimation of a bin in 3D scans. Therefore, we present a high-quality dataset composed of synthetic data and real scans captured by a structured-light scanner with precise annotations. Additionally, we propose two different methods for 6D bin pose estimation, an analytical method as the industrial standard and a baseline data-driven method. Both approaches are cross-evaluated, and our experiments show that augmenting the training on real scans with synthetic data improves our proposed data-driven neural model. This position paper is preliminary, as proposed methods are trained and evaluated on a relatively small initial dataset which we plan to extend in the future.