 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Building a Parallel Universe Image Synthesis from Land Cover Maps and Auxiliary Raster Data
Nov 23, 2020
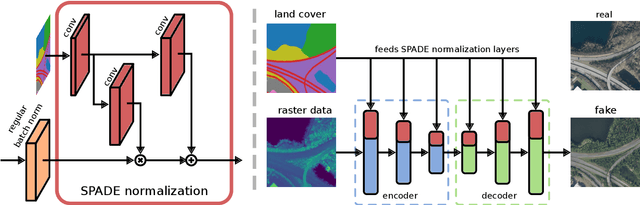


We synthesize both optical RGB and SAR remote sensing images from land cover maps and auxiliary raster data using GANs. In remote sensing many types of data, such as digital elevation models or precipitation maps, are often not reflected in land cover maps but still influence image content or structure. Including such data in the synthesis process increases the quality of the generated images and exerts more control on their characteristics. Our method fuses both inputs by spatially adaptive normalization layers, previously published as SPADE semantic image synthesis. In contrast to SPADE, these normalization layers are applied to a full-blown generator architecture consisting of encoder and decoder, to take full advantage of the information content in the auxiliary raster data. Our method successfully synthesizes medium (10m) and high (1m) resolution images, when trained with the corresponding dataset. We show the advantage of data fusion of land cover maps and auxiliary information using mean intersection over union, pixel accuracy and FID using pre-trained U-Net segmentation models. Handpicked images exemplify how fusing information avoids ambiguities in the synthesized images. By slightly editing the input our method can be used to synthesize realistic changes, i.e., raising the water levels. The source code is available at https://github.com/gbaier/rs_img_synth and we published the newly created high-resolution dataset at https://ieee-dataport.org/open-access/geonrw.
Towards artificially intelligent recycling Improving image processing for waste classification
Aug 09, 2021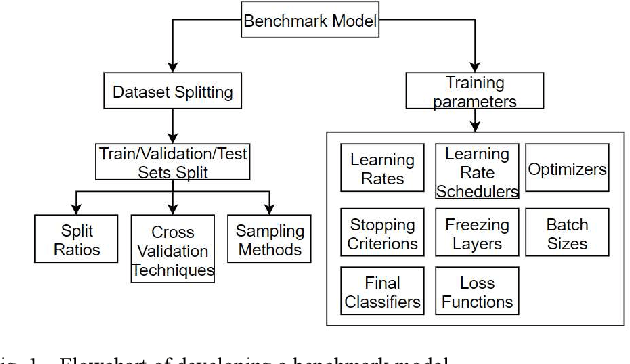
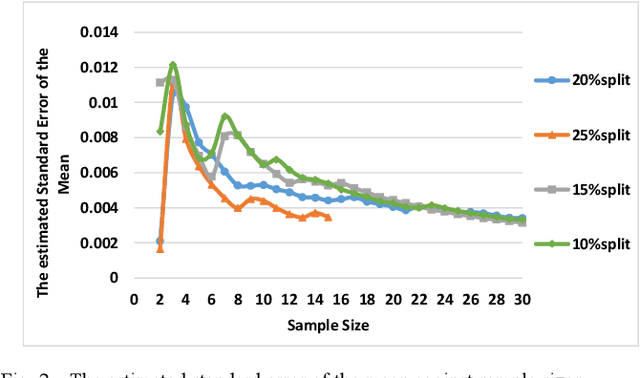
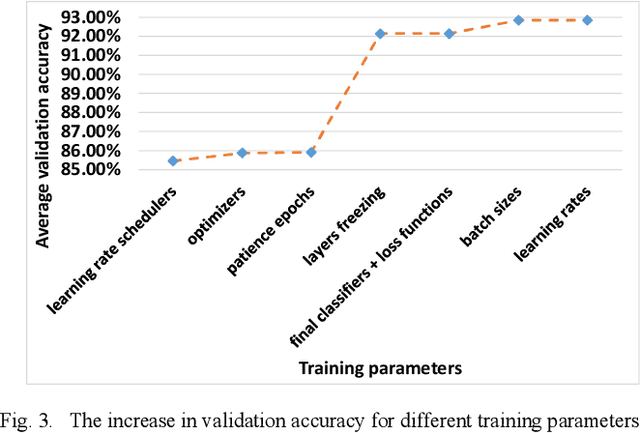
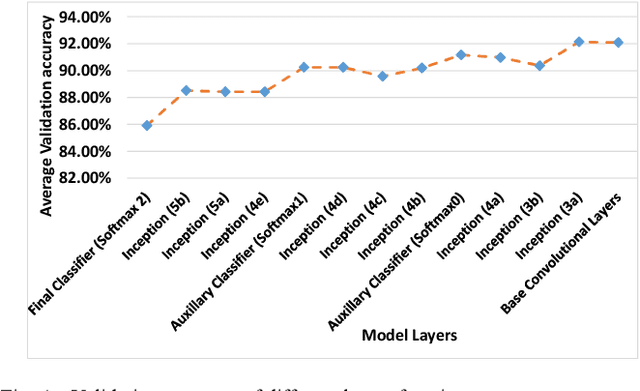
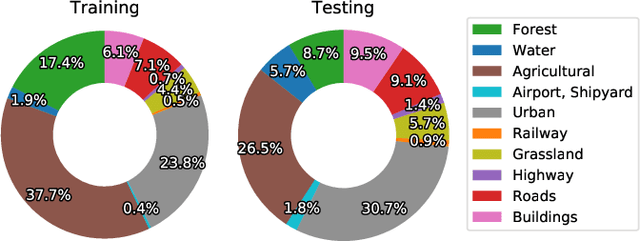
The ever-increasing amount of global refuse is overwhelming the waste and recycling management industries. The need for smart systems for environmental monitoring and the enhancement of recycling processes is thus greater than ever. Amongst these efforts lies IBM's Wastenet project which aims to improve recycling by using artificial intelligence for waste classification. The work reported in this paper builds on this project through the use of transfer learning and data augmentation techniques to ameliorate classification accuracy. Starting with a convolutional neural network (CNN), a systematic approach is followed for selecting appropriate splitting ratios and for tuning multiple training parameters including learning rate schedulers, layers freezing, batch sizes and loss functions, in the context of the given scenario which requires classification of waste into different recycling types. Results are compared and contrasted using 10-fold cross validation and demonstrate that the model developed achieves a 91.21% test accuracy. Subsequently, a range of data augmentation techniques are then incorporated into this work including flipping, rotation, shearing, zooming, and brightness control. Results show that these augmentation techniques further improve the test accuracy of the final model to 95.40%. Unlike other work reported in the field, this paper provides full details regarding the training of the model. Furthermore, the code for this work has been made open-source and we have demonstrated that the model can perform successful real-time classification of recycling waste items using a standard computer webcam.
Deep Transfer Learning for Land Use Land Cover Classification: A Comparative Study
Oct 08, 2021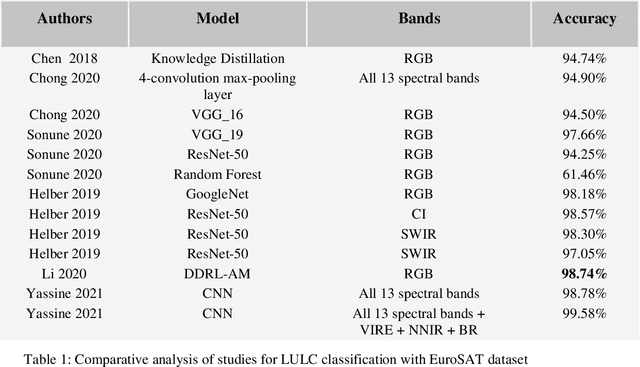
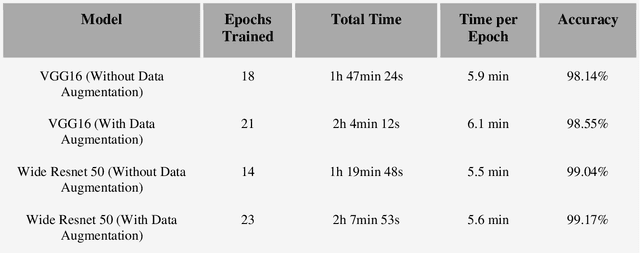
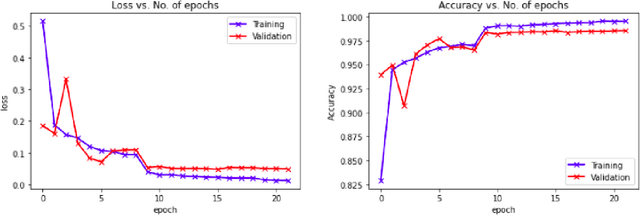
Efficiently implementing remote sensing image classification with high spatial resolution imagery can provide great significant value in land-use land-cover classification (LULC). The developments in remote sensing and deep learning technologies have facilitated the extraction of spatiotemporal information for LULC classification. Moreover, the diverse disciplines of science, including remote sensing, have utilised tremendous improvements in image classification by CNNs with Transfer Learning. In this study, instead of training CNNs from scratch, we make use of transfer learning to fine-tune pre-trained networks a) VGG16 and b) Wide Residual Networks (WRNs), by replacing the final layer with additional layers, for LULC classification with EuroSAT dataset. Further, the performance and computational time were compared and optimized with techniques like early stopping, gradient clipping, adaptive learning rates and data augmentation. With the proposed approaches we were able to address the limited-data problem and achieved very good accuracy. Comprehensive comparisons over the EuroSAT RGB version benchmark have successfully established that our method outperforms the previous best-stated results, with a significant improvement over the accuracy from 98.57% to 99.17%.
DISIR: Deep Image Segmentation with Interactive Refinement
Mar 31, 2020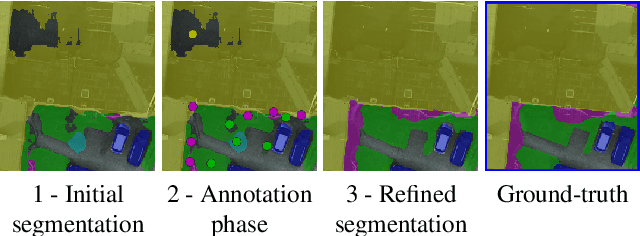
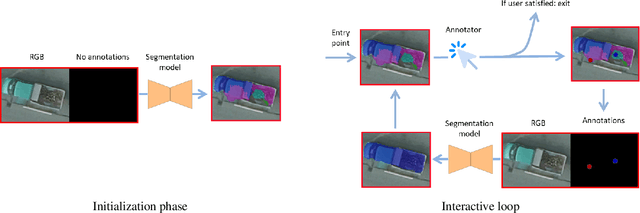

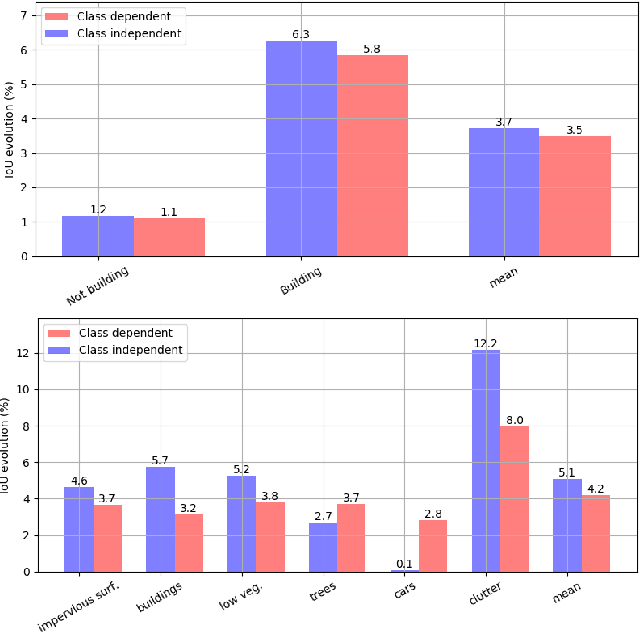
This paper presents an interactive approach for multi-class segmentation of aerial images. Precisely, it is based on a deep neural network which exploits both RGB images and annotations. Starting from an initial output based on the image only, our network then interactively refines this segmentation map using a concatenation of the image and user annotations. Importantly, user annotations modify the inputs of the network - not its weights - enabling a fast and smooth process. Through experiments on two public aerial datasets, we show that user annotations are extremely rewarding: each click corrects roughly 5000 pixels. We analyze the impact of different aspects of our framework such as the representation of the annotations, the volume of training data or the network architecture. Code is available at https://github.com/delair-ai/DISIR.
A singular Riemannian geometry approach to Deep Neural Networks I. Theoretical foundations
Dec 17, 2021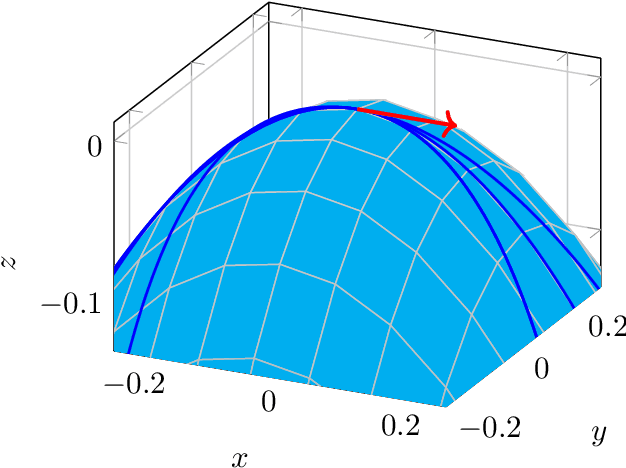
Deep Neural Networks are widely used for solving complex problems in several scientific areas, such as speech recognition, machine translation, image analysis. The strategies employed to investigate their theoretical properties mainly rely on Euclidean geometry, but in the last years new approaches based on Riemannian geometry have been developed. Motivated by some open problems, we study a particular sequence of maps between manifolds, with the last manifold of the sequence equipped with a Riemannian metric. We investigate the structures induced trough pullbacks on the other manifolds of the sequence and on some related quotients. In particular, we show that the pullbacks of the final Riemannian metric to any manifolds of the sequence is a degenerate Riemannian metric inducing a structure of pseudometric space, we show that the Kolmogorov quotient of this pseudometric space yields a smooth manifold, which is the base space of a particular vertical bundle. We investigate the theoretical properties of the maps of such sequence, eventually we focus on the case of maps between manifolds implementing neural networks of practical interest and we present some applications of the geometric framework we introduced in the first part of the paper.
The Majority Can Help The Minority: Context-rich Minority Oversampling for Long-tailed Classification
Dec 01, 2021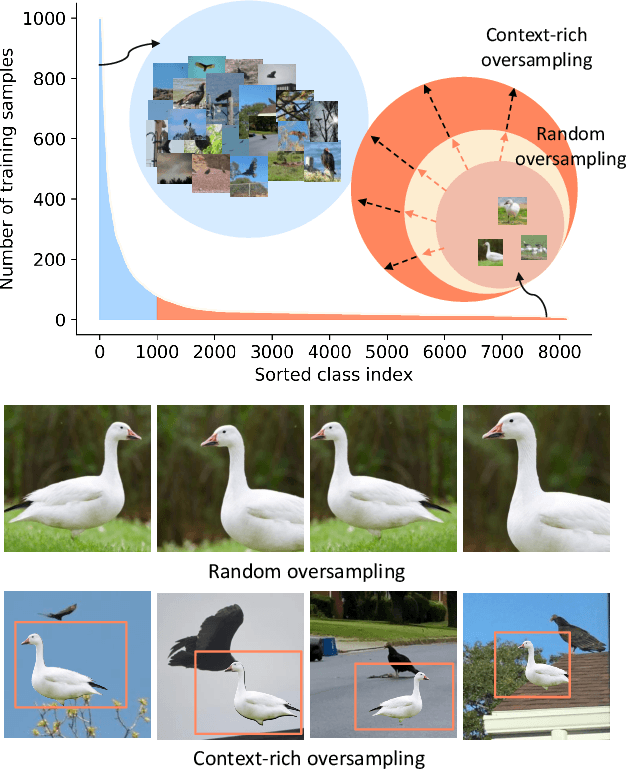
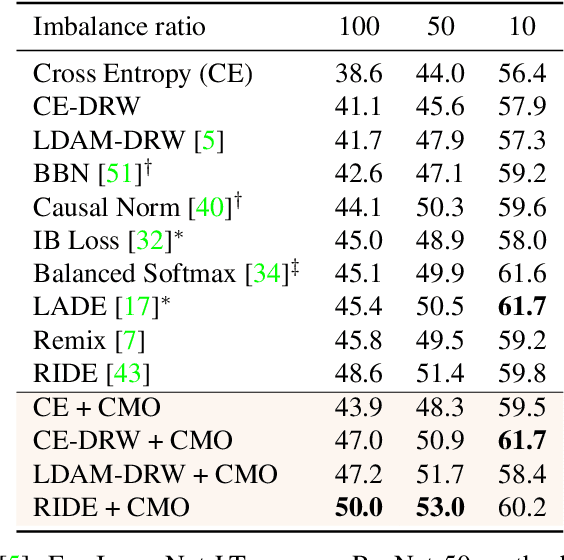

The problem of class imbalanced data lies in that the generalization performance of the classifier is deteriorated due to the lack of data of the minority classes. In this paper, we propose a novel minority over-sampling method to augment diversified minority samples by leveraging the rich context of the majority classes as background images. To diversify the minority samples, our key idea is to paste a foreground patch from a minority class to a background image from a majority class having affluent contexts. Our method is simple and can be easily combined with the existing long-tailed recognition methods. We empirically prove the effectiveness of the proposed oversampling method through extensive experiments and ablation studies. Without any architectural changes or complex algorithms, our method achieves state-of-the-art performance on various long-tailed classification benchmarks. Our code will be publicly available at link.
CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models
Oct 08, 2021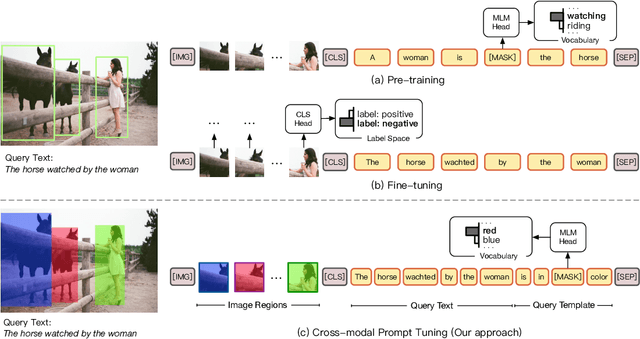
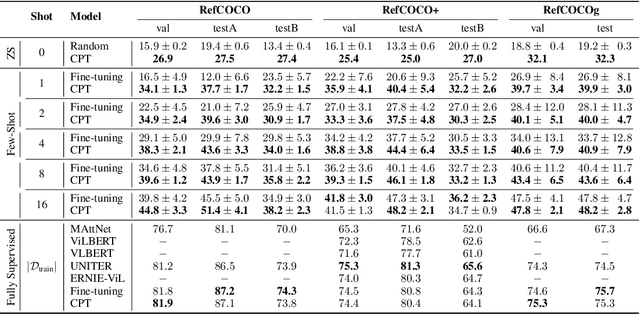
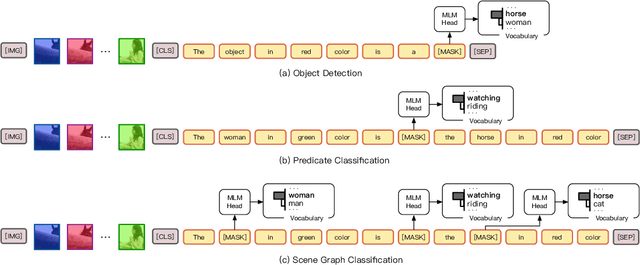
Pre-Trained Vision-Language Models (VL-PTMs) have shown promising capabilities in grounding natural language in image data, facilitating a broad variety of cross-modal tasks. However, we note that there exists a significant gap between the objective forms of model pre-training and fine-tuning, resulting in a need for large amounts of labeled data to stimulate the visual grounding capability of VL-PTMs for downstream tasks. To address the challenge, we present Cross-modal Prompt Tuning (CPT, alternatively, Colorful Prompt Tuning), a novel paradigm for tuning VL-PTMs, which reformulates visual grounding into a fill-in-the-blank problem with color-based co-referential markers in image and text, maximally mitigating the gap. In this way, CPT enables strong few-shot and even zero-shot visual grounding capabilities of VL-PTMs. Comprehensive experimental results show that the prompt-tuned VL-PTMs outperform their fine-tuned counterparts by a large margin (e.g., 17.3% absolute accuracy improvement, and 73.8% relative standard deviation reduction on average with one shot in RefCOCO evaluation). All the data and codes will be available to facilitate future research.
Deeply Cascaded U-Net for Multi-Task Image Processing
May 01, 2020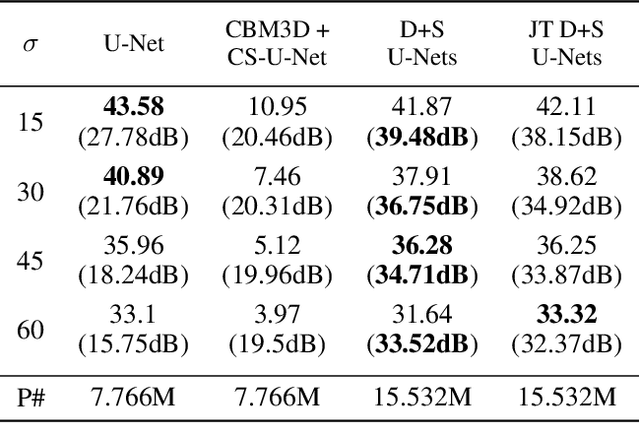
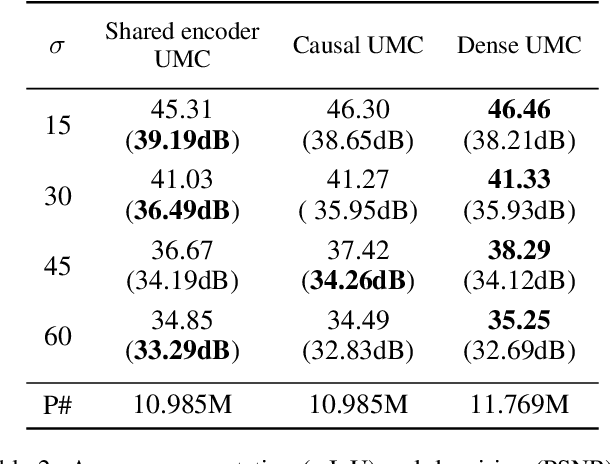
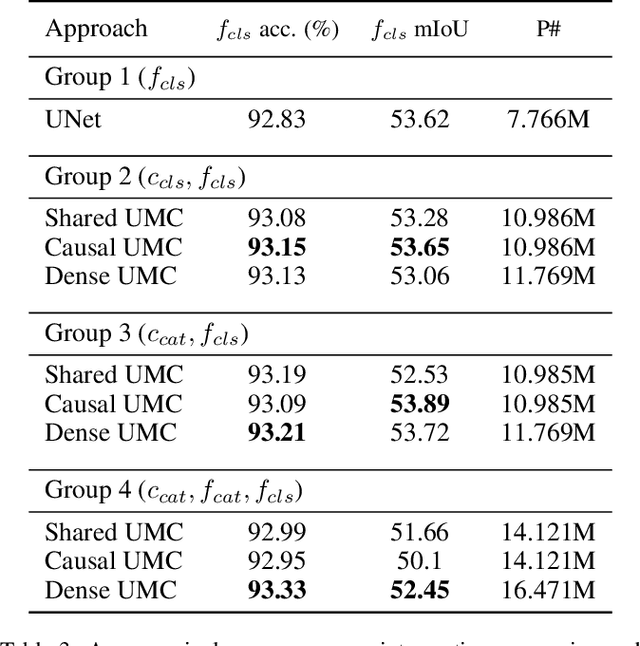
In current practice, many image processing tasks are done sequentially (e.g. denoising, dehazing, followed by semantic segmentation). In this paper, we propose a novel multi-task neural network architecture designed for combining sequential image processing tasks. We extend U-Net by additional decoding pathways for each individual task, and explore deep cascading of outputs and connectivity from one pathway to another. We demonstrate effectiveness of the proposed approach on denoising and semantic segmentation, as well as on progressive coarse-to-fine semantic segmentation, and achieve better performance than multiple individual or jointly-trained networks, with lower number of trainable parameters.
Fully Adaptive Bayesian Algorithm for Data Analysis, FABADA
Jan 13, 2022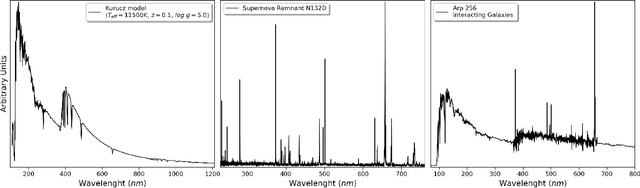

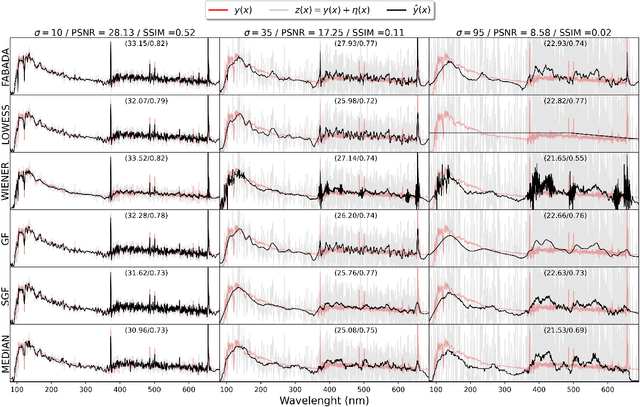
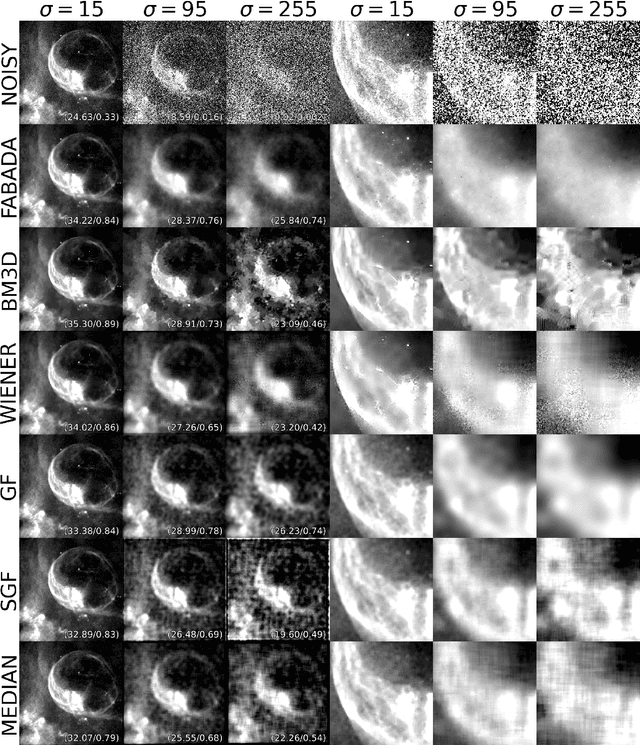
The aim of this paper is to describe a novel non-parametric noise reduction technique from the point of view of Bayesian inference that may automatically improve the signal-to-noise ratio of one- and two-dimensional data, such as e.g. astronomical images and spectra. The algorithm iteratively evaluates possible smoothed versions of the data, the smooth models, obtaining an estimation of the underlying signal that is statistically compatible with the noisy measurements. Iterations stop based on the evidence and the $\chi^2$ statistic of the last smooth model, and we compute the expected value of the signal as a weighted average of the whole set of smooth models. In this paper, we explain the mathematical formalism and numerical implementation of the algorithm, and we evaluate its performance in terms of the peak signal to noise ratio, the structural similarity index, and the time payload, using a battery of real astronomical observations. Our Fully Adaptive Bayesian Algorithm for Data Analysis (FABADA) yields results that, without any parameter tuning, are comparable to standard image processing algorithms whose parameters have been optimized based on the true signal to be recovered, something that is impossible in a real application. State-of-the-art non-parametric methods, such as BM3D, offer slightly better performance at high signal-to-noise ratio, while our algorithm is significantly more accurate for extremely noisy data (higher than $20-40\%$ relative errors, a situation of particular interest in the field of astronomy). In this range, the standard deviation of the residuals obtained by our reconstruction may become more than an order of magnitude lower than that of the original measurements. The source code needed to reproduce all the results presented in this report, including the implementation of the method, is publicly available at https://github.com/PabloMSanAla/fabada
Features based Mammogram Image Classification using Weighted Feature Support Vector Machine
Sep 19, 2020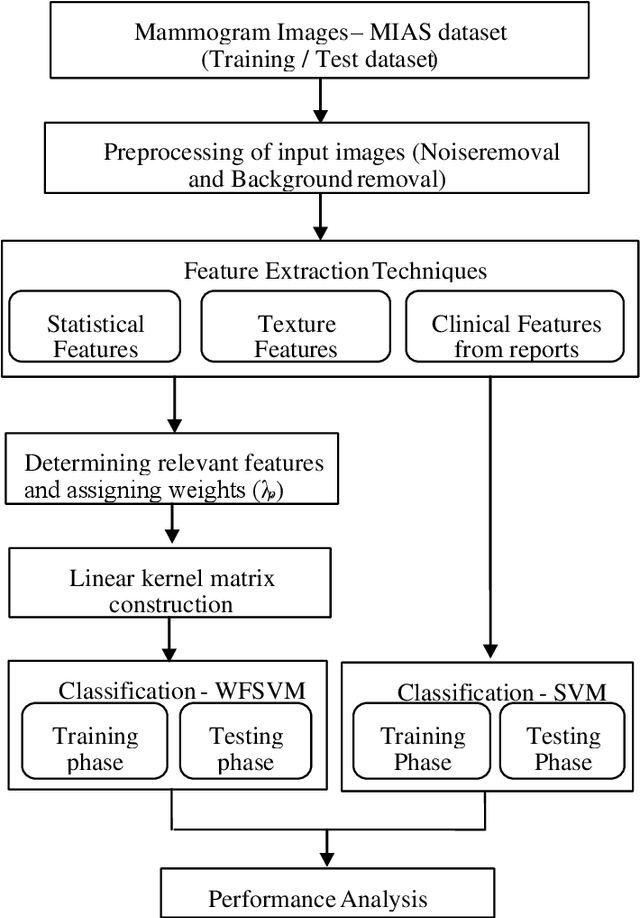

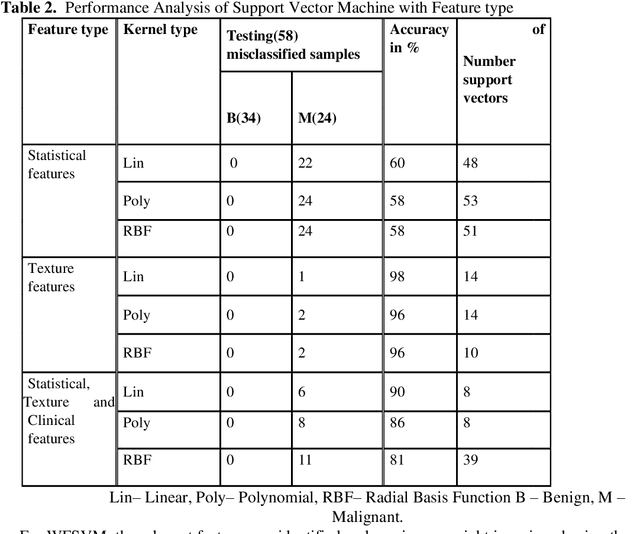
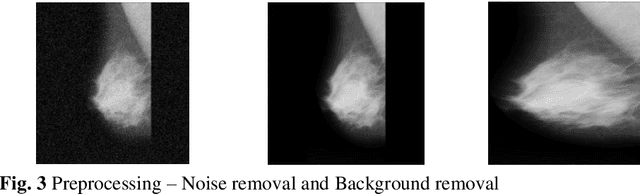
In the existing research of mammogram image classification, either clinical data or image features of a specific type is considered along with the supervised classifiers such as Neural Network (NN) and Support Vector Machine (SVM). This paper considers automated classification of breast tissue type as benign or malignant using Weighted Feature Support Vector Machine (WFSVM) through constructing the precomputed kernel function by assigning more weight to relevant features using the principle of maximizing deviations. Initially, MIAS dataset of mammogram images is divided into training and test set, then the preprocessing techniques such as noise removal and background removal are applied to the input images and the Region of Interest (ROI) is identified. The statistical features and texture features are extracted from the ROI and the clinical features are obtained directly from the dataset. The extracted features of the training dataset are used to construct the weighted features and precomputed linear kernel for training the WFSVM, from which the training model file is created. Using this model file the kernel matrix of test samples is classified as benign or malignant. This analysis shows that the texture features have resulted in better accuracy than the other features with WFSVM and SVM. However, the number of support vectors created in WFSVM is less than the SVM classifier.
* 9 pages, 3 figures, "submitted to International Conference on Computing and Communication Systems"