 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DoubleU-Net: A Deep Convolutional Neural Network for Medical Image Segmentation
Jun 08, 2020
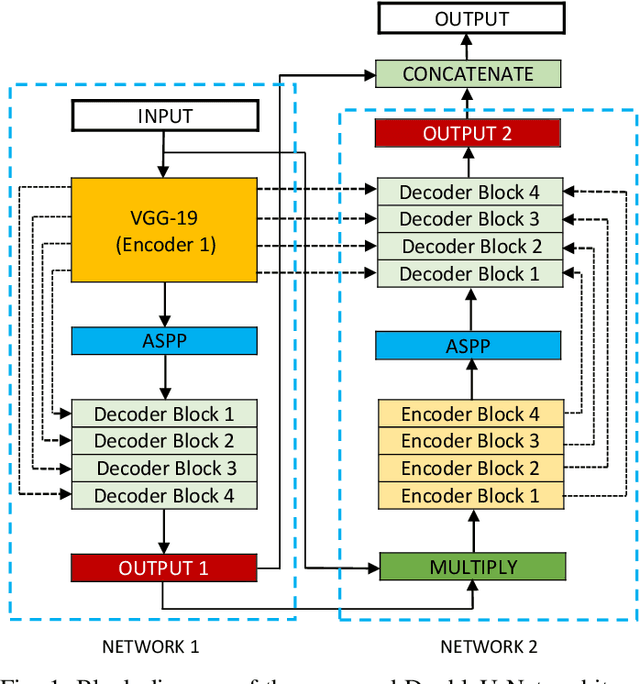
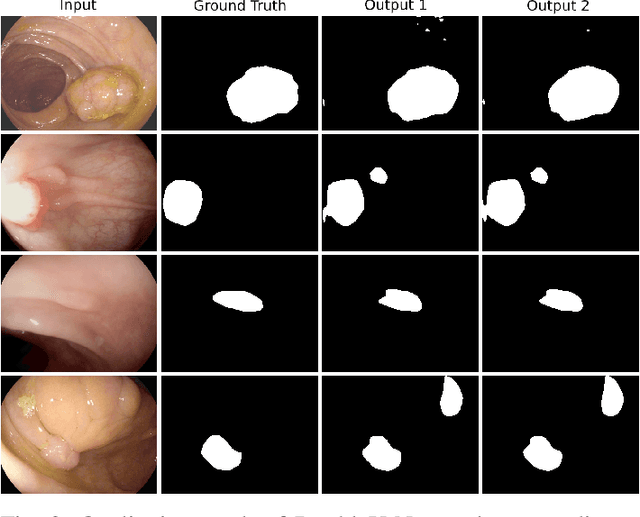
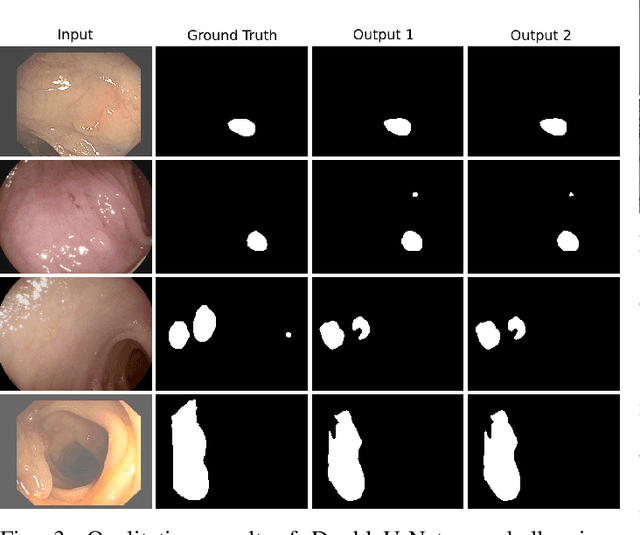
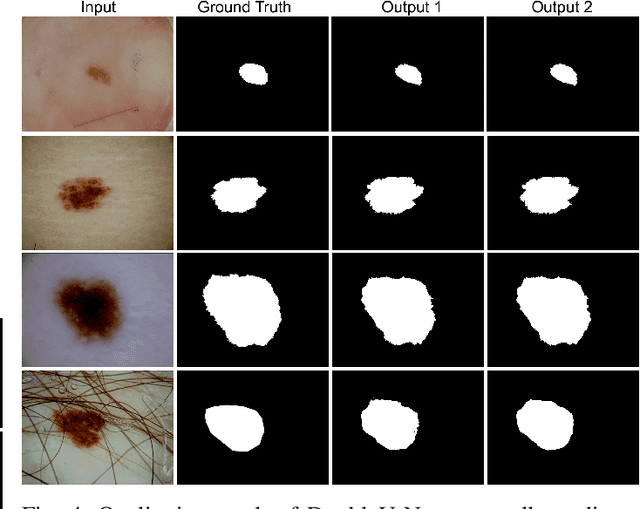
Semantic image segmentation is the process of labeling each pixel of an image with its corresponding class. An encoder-decoder based approach, like U-Net and its variants, is a popular strategy for solving medical image segmentation tasks. To improve the performance of U-Net on various segmentation tasks, we propose a novel architecture called DoubleU-Net, which is a combination of two U-Net architectures stacked on top of each other. The first U-Net uses a pre-trained VGG-19 as the encoder, which has already learned features from ImageNet and can be transferred to another task easily. To capture more semantic information efficiently, we added another U-Net at the bottom. We also adopt Atrous Spatial Pyramid Pooling (ASPP) to capture contextual information within the network. We have evaluated DoubleU-Net using four medical segmentation datasets, covering various imaging modalities such as colonoscopy, dermoscopy, and microscopy. Experiments on the MICCAI 2015 segmentation challenge, the CVC-ClinicDB, the 2018 Data Science Bowl challenge, and the Lesion boundary segmentation datasets demonstrate that the DoubleU-Net outperforms U-Net and the baseline models. Moreover, DoubleU-Net produces more accurate segmentation masks, especially in the case of the CVC-ClinicDB and MICCAI 2015 segmentation challenge datasets, which have challenging images such as smaller and flat polyps. These results show the improvement over the existing U-Net model. The encouraging results, produced on various medical image segmentation datasets, show that DoubleU-Net can be used as a strong baseline for both medical image segmentation and cross-dataset evaluation testing to measure the generalizability of Deep Learning (DL) models.
MRI Reconstruction Using Deep Energy-Based Model
Sep 09, 2021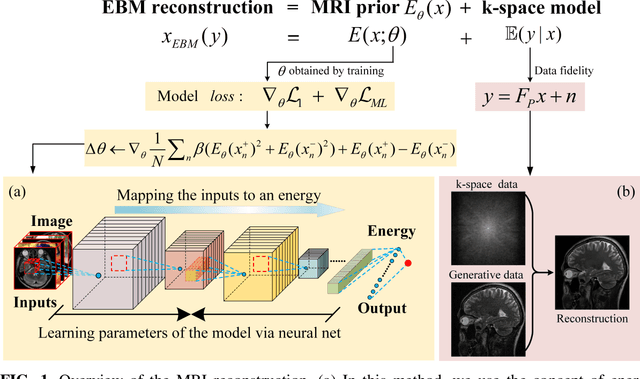
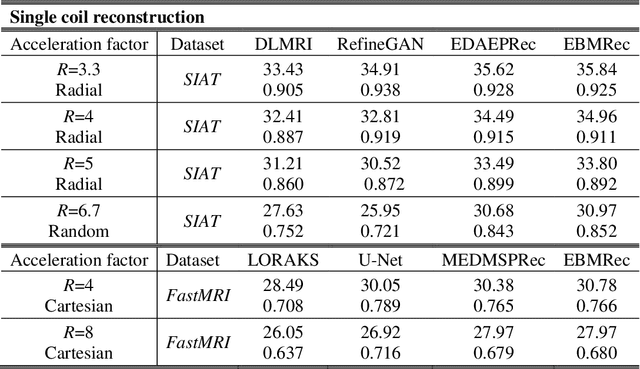
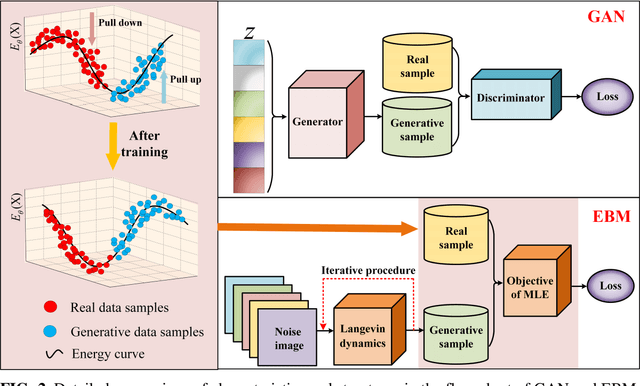
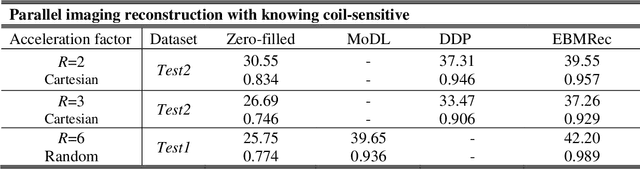
Purpose: Although recent deep energy-based generative models (EBMs) have shown encouraging results in many image generation tasks, how to take advantage of the self-adversarial cogitation in deep EBMs to boost the performance of Magnetic Resonance Imaging (MRI) reconstruction is still desired. Methods: With the successful application of deep learning in a wide range of MRI reconstruction, a line of emerging research involves formulating an optimization-based reconstruction method in the space of a generative model. Leveraging this, a novel regularization strategy is introduced in this article which takes advantage of self-adversarial cogitation of the deep energy-based model. More precisely, we advocate for alternative learning a more powerful energy-based model with maximum likelihood estimation to obtain the deep energy-based information, represented as image prior. Simultaneously, implicit inference with Langevin dynamics is a unique property of re-construction. In contrast to other generative models for reconstruction, the proposed method utilizes deep energy-based information as the image prior in reconstruction to improve the quality of image. Results: Experiment results that imply the proposed technique can obtain remarkable performance in terms of high reconstruction accuracy that is competitive with state-of-the-art methods, and does not suffer from mode collapse. Conclusion: Algorithmically, an iterative approach was presented to strengthen EBM training with the gradient of energy network. The robustness and the reproducibility of the algorithm were also experimentally validated. More importantly, the proposed reconstruction framework can be generalized for most MRI reconstruction scenarios.
Semi-Local Convolutions for LiDAR Scan Processing
Nov 30, 2021
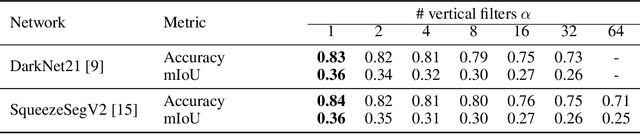

A number of applications, such as mobile robots or automated vehicles, use LiDAR sensors to obtain detailed information about their three-dimensional surroundings. Many methods use image-like projections to efficiently process these LiDAR measurements and use deep convolutional neural networks to predict semantic classes for each point in the scan. The spatial stationary assumption enables the usage of convolutions. However, LiDAR scans exhibit large differences in appearance over the vertical axis. Therefore, we propose semi local convolution (SLC), a convolution layer with reduced amount of weight-sharing along the vertical dimension. We are first to investigate the usage of such a layer independent of any other model changes. Our experiments did not show any improvement over traditional convolution layers in terms of segmentation IoU or accuracy.
* arXiv admin note: text overlap with arXiv:2004.11803
Generalized Category Discovery
Jan 07, 2022
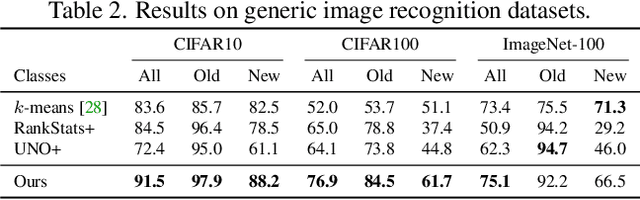

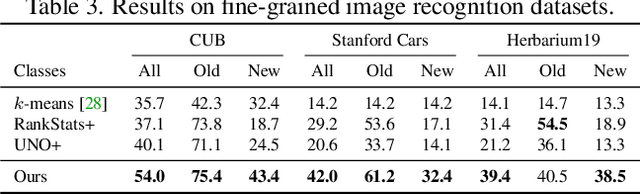
In this paper, we consider a highly general image recognition setting wherein, given a labelled and unlabelled set of images, the task is to categorize all images in the unlabelled set. Here, the unlabelled images may come from labelled classes or from novel ones. Existing recognition methods are not able to deal with this setting, because they make several restrictive assumptions, such as the unlabelled instances only coming from known - or unknown - classes and the number of unknown classes being known a-priori. We address the more unconstrained setting, naming it 'Generalized Category Discovery', and challenge all these assumptions. We first establish strong baselines by taking state-of-the-art algorithms from novel category discovery and adapting them for this task. Next, we propose the use of vision transformers with contrastive representation learning for this open world setting. We then introduce a simple yet effective semi-supervised $k$-means method to cluster the unlabelled data into seen and unseen classes automatically, substantially outperforming the baselines. Finally, we also propose a new approach to estimate the number of classes in the unlabelled data. We thoroughly evaluate our approach on public datasets for generic object classification including CIFAR10, CIFAR100 and ImageNet-100, and for fine-grained visual recognition including CUB, Stanford Cars and Herbarium19, benchmarking on this new setting to foster future research.
Towards holistic scene understanding: Semantic segmentation and beyond
Jan 16, 2022This dissertation addresses visual scene understanding and enhances segmentation performance and generalization, training efficiency of networks, and holistic understanding. First, we investigate semantic segmentation in the context of street scenes and train semantic segmentation networks on combinations of various datasets. In Chapter 2 we design a framework of hierarchical classifiers over a single convolutional backbone, and train it end-to-end on a combination of pixel-labeled datasets, improving generalizability and the number of recognizable semantic concepts. Chapter 3 focuses on enriching semantic segmentation with weak supervision and proposes a weakly-supervised algorithm for training with bounding box-level and image-level supervision instead of only with per-pixel supervision. The memory and computational load challenges that arise from simultaneous training on multiple datasets are addressed in Chapter 4. We propose two methodologies for selecting informative and diverse samples from datasets with weak supervision to reduce our networks' ecological footprint without sacrificing performance. Motivated by memory and computation efficiency requirements, in Chapter 5, we rethink simultaneous training on heterogeneous datasets and propose a universal semantic segmentation framework. This framework achieves consistent increases in performance metrics and semantic knowledgeability by exploiting various scene understanding datasets. Chapter 6 introduces the novel task of part-aware panoptic segmentation, which extends our reasoning towards holistic scene understanding. This task combines scene and parts-level semantics with instance-level object detection. In conclusion, our contributions span over convolutional network architectures, weakly-supervised learning, part and panoptic segmentation, paving the way towards a holistic, rich, and sustainable visual scene understanding.
An Incremental Learning Approach to Automatically Recognize Pulmonary Diseases from the Multi-vendor Chest Radiographs
Jan 07, 2022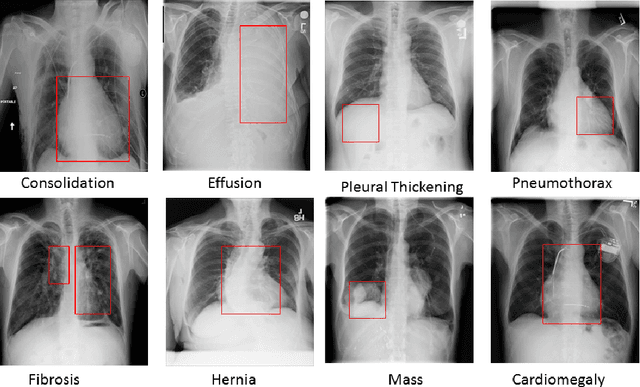
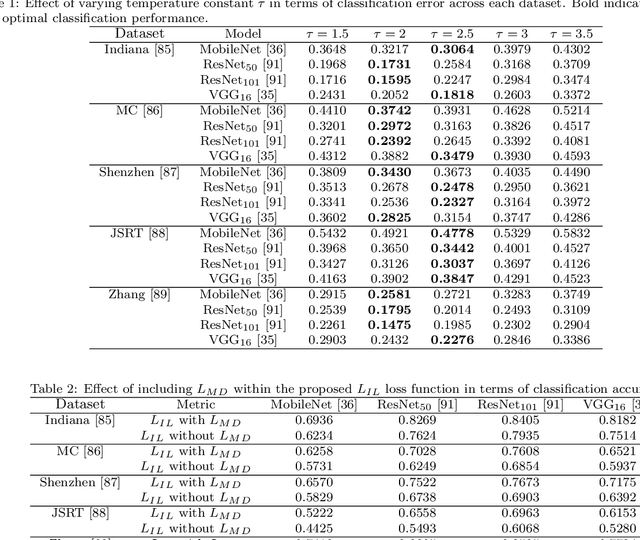
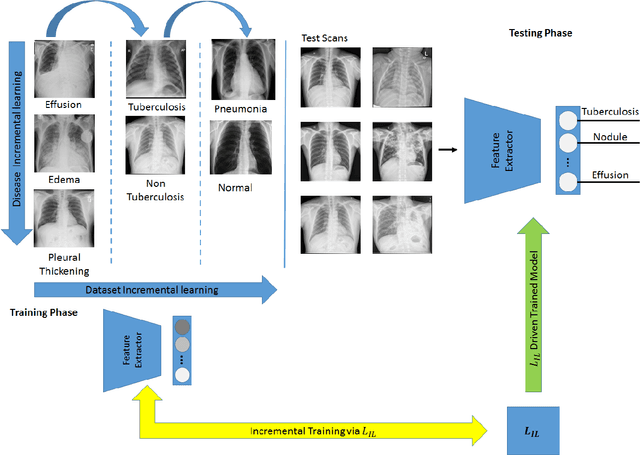
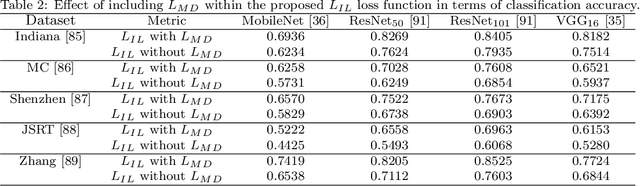
Pulmonary diseases can cause severe respiratory problems, leading to sudden death if not treated timely. Many researchers have utilized deep learning systems to diagnose pulmonary disorders using chest X-rays (CXRs). However, such systems require exhaustive training efforts on large-scale data to effectively diagnose chest abnormalities. Furthermore, procuring such large-scale data is often infeasible and impractical, especially for rare diseases. With the recent advances in incremental learning, researchers have periodically tuned deep neural networks to learn different classification tasks with few training examples. Although, such systems can resist catastrophic forgetting, they treat the knowledge representations independently of each other, and this limits their classification performance. Also, to the best of our knowledge, there is no incremental learning-driven image diagnostic framework that is specifically designed to screen pulmonary disorders from the CXRs. To address this, we present a novel framework that can learn to screen different chest abnormalities incrementally. In addition to this, the proposed framework is penalized through an incremental learning loss function that infers Bayesian theory to recognize structural and semantic inter-dependencies between incrementally learned knowledge representations to diagnose the pulmonary diseases effectively, regardless of the scanner specifications. We tested the proposed framework on five public CXR datasets containing different chest abnormalities, where it outperformed various state-of-the-art system through various metrics.
* Computers in Biology and Medicine
GAN Based Boundary Aware Classifier for Detecting Out-of-distribution Samples
Dec 22, 2021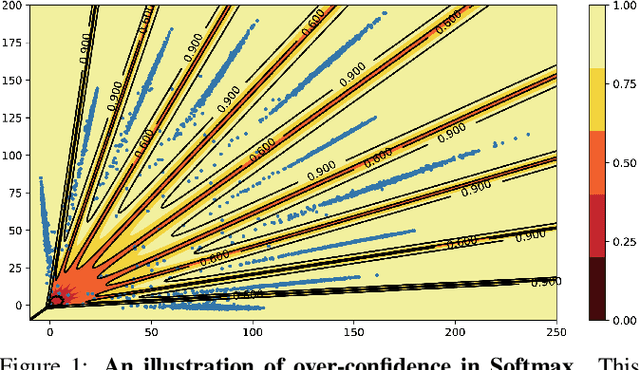
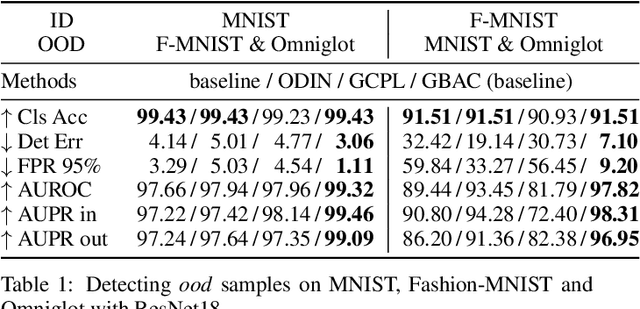
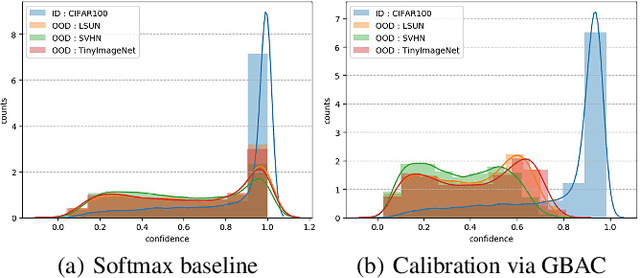
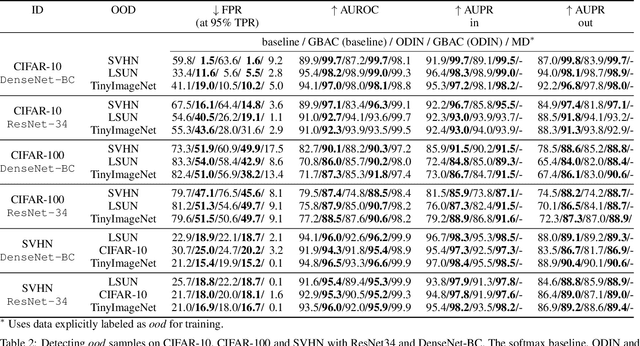
This paper focuses on the problem of detecting out-of-distribution (ood) samples with neural nets. In image recognition tasks, the trained classifier often gives high confidence score for input images which are remote from the in-distribution (id) data, and this has greatly limited its application in real world. For alleviating this problem, we propose a GAN based boundary aware classifier (GBAC) for generating a closed hyperspace which only contains most id data. Our method is based on the fact that the traditional neural net seperates the feature space as several unclosed regions which are not suitable for ood detection. With GBAC as an auxiliary module, the ood data distributed outside the closed hyperspace will be assigned with much lower score, allowing more effective ood detection while maintaining the classification performance. Moreover, we present a fast sampling method for generating hard ood representations which lie on the boundary of pre-mentioned closed hyperspace. Experiments taken on several datasets and neural net architectures promise the effectiveness of GBAC.
AlphaNet: An Attention Guided Deep Network for Automatic Image Matting
Mar 07, 2020
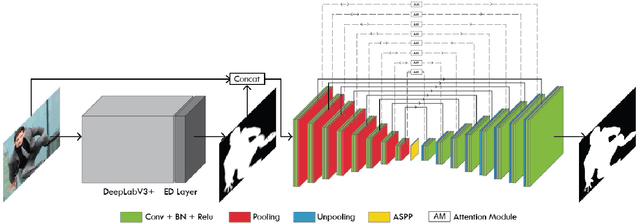
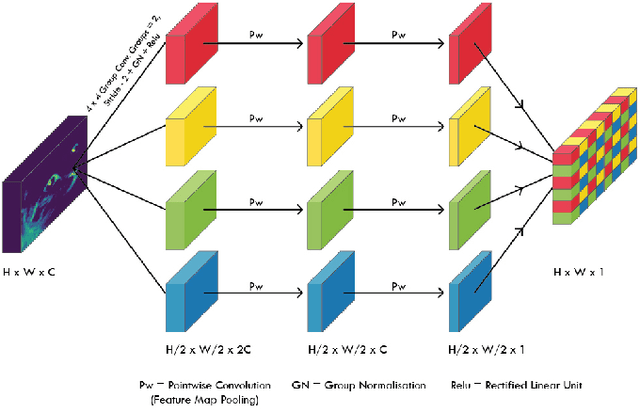
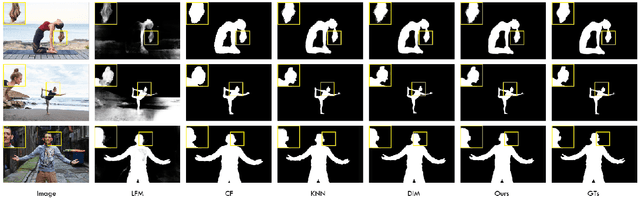
In this paper, we propose an end to end solution for image matting i.e high-precision extraction of foreground objects from natural images. Image matting and background detection can be achieved easily through chroma keying in a studio setting when the background is either pure green or blue. Nonetheless, image matting in natural scenes with complex and uneven depth backgrounds remains a tedious task that requires human intervention. To achieve complete automatic foreground extraction in natural scenes, we propose a method that assimilates semantic segmentation and deep image matting processes into a single network to generate detailed semantic mattes for image composition task. The contribution of our proposed method is two-fold, firstly it can be interpreted as a fully automated semantic image matting method and secondly as a refinement of existing semantic segmentation models. We propose a novel model architecture as a combination of segmentation and matting that unifies the function of upsampling and downsampling operators with the notion of attention. As shown in our work, attention guided downsampling and upsampling can extract high-quality boundary details, unlike other normal downsampling and upsampling techniques. For achieving the same, we utilized an attention guided encoder-decoder framework which does unsupervised learning for generating an attention map adaptively from the data to serve and direct the upsampling and downsampling operators. We also construct a fashion e-commerce focused dataset with high-quality alpha mattes to facilitate the training and evaluation for image matting.
Uncertainty-Aware Blind Image Quality Assessment in the Laboratory and Wild
May 29, 2020
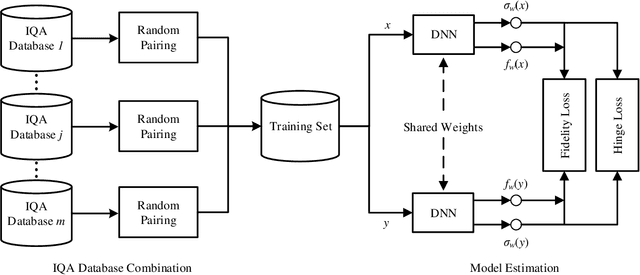
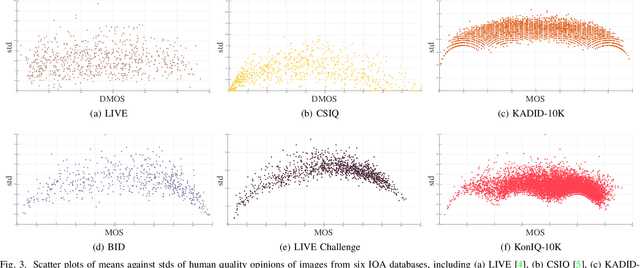

Performance of blind image quality assessment (BIQA) models has been significantly boosted by end-to-end optimization of feature engineering and quality regression. Nevertheless, due to the distributional shifts between images simulated in the laboratory and captured in the wild, models trained on databases with synthetic distortions remain particularly weak at handling realistic distortions (and vice versa). To confront the cross-distortion-scenario challenge, we develop a unified BIQA model and an effective approach of training it for both synthetic and realistic distortions. We first sample pairs of images from the same IQA databases and compute a probability that one image of each pair is of higher quality as the supervisory signal. We then employ the fidelity loss to optimize a deep neural network for BIQA over a large number of such image pairs. We also explicitly enforce a hinge constraint to regularize uncertainty estimation during optimization. Extensive experiments on six IQA databases show the promise of the learned method in blindly assessing image quality in the laboratory and wild. In addition, we demonstrate the universality of the proposed training strategy by using it to improve existing BIQA models.
Event-based Action Recognition Using Timestamp Image Encoding Network
Sep 28, 2020

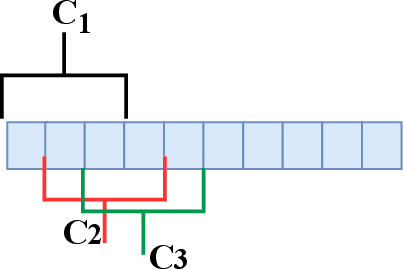
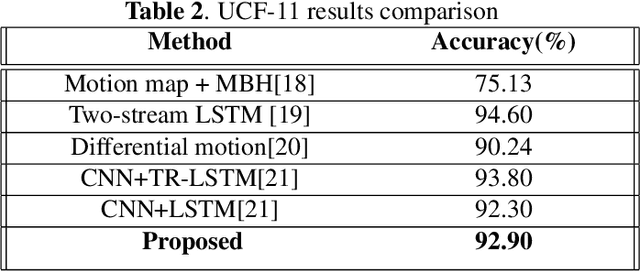
Event camera is an asynchronous, high frequency vision sensor with low power consumption, which is suitable for human action recognition task. It is vital to encode the spatial-temporal information of event data properly and use standard computer vision tool to learn from the data. In this work, we propose a timestamp image encoding 2D network, which takes the encoded spatial-temporal images of the event data as input and output the action label. Experiment results show that our method can achieve the same level of performance as those RGB-based benchmarks on real world action recognition, and also achieve the SOTA result on gesture recognition.