 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
G-VAE: A Continuously Variable Rate Deep Image Compression Framework
Mar 04, 2020
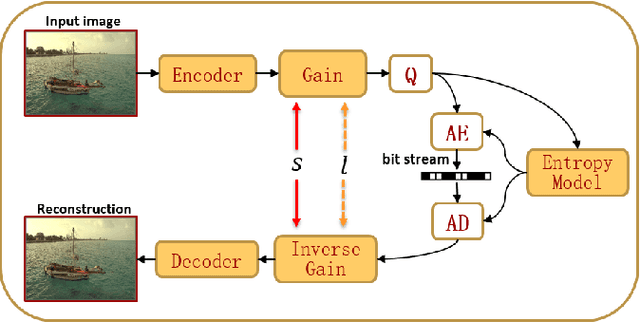

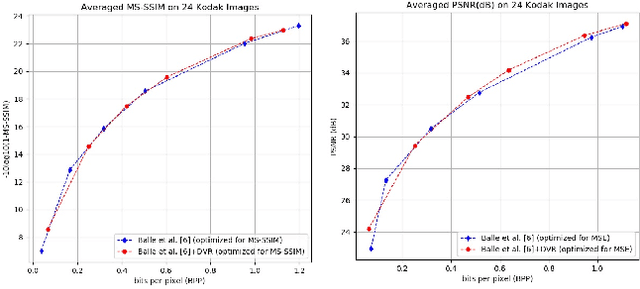
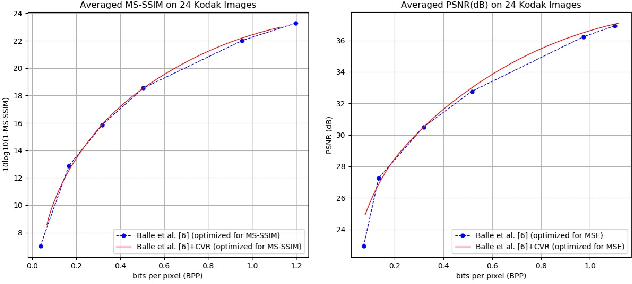
Rate adaption of deep image compression in a single model will become one of the decisive factors competing with the classical image compression codecs. However, until now, there is no perfect solution that neither increases the computation nor affects the compression performance. In this paper, we propose a novel image compression framework G-VAE (Gained Variational Autoencoder), which could achieve continuously variable rate in a single model. Unlike the previous solutions that encode progressively or change the internal unit of the network, G-VAE only adds a pair of gain units at the output of encoder and the input of decoder. It is so concise that G-VAE could be applied to almost all the image compression methods and achieve continuously variable rate with negligible additional parameters and computation. We also propose a new deep image compression framework, which outperforms all the published results on Kodak datasets in PSNR and MS-SSIM metrics. Experimental results show that adding a pair of gain units will not affect the performance of the basic models while endowing them with continuously variable rate.
Local Texture Estimator for Implicit Representation Function
Nov 21, 2021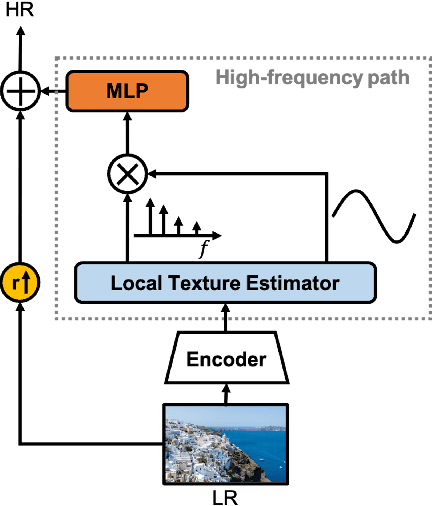
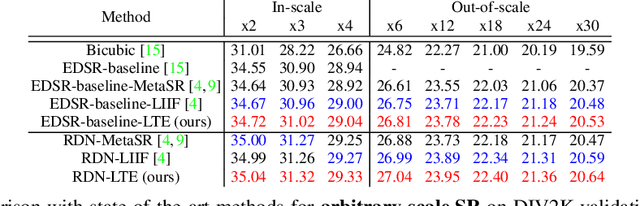
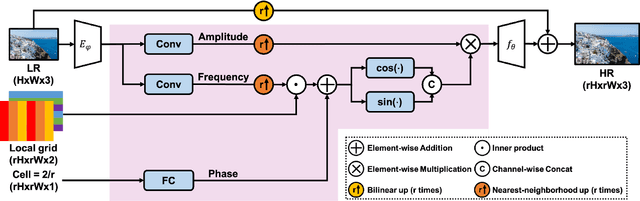

Recent works with an implicit neural function shed light on representing images in arbitrary resolution. However, a standalone multi-layer perceptron (MLP) shows limited performance in learning high-frequency components. In this paper, we propose a Local Texture Estimator (LTE), a dominant-frequency estimator for natural images, enabling an implicit function to capture fine details while reconstructing images in a continuous manner. When jointly trained with a deep super-resolution (SR) architecture, LTE is capable of characterizing image textures in 2D Fourier space. We show that an LTE-based neural function outperforms existing deep SR methods within an arbitrary-scale for all datasets and all scale factors. Furthermore, we demonstrate that our implementation takes the shortest running time compared to previous works. Source code will be open.
Fast Image Caption Generation with Position Alignment
Dec 13, 2019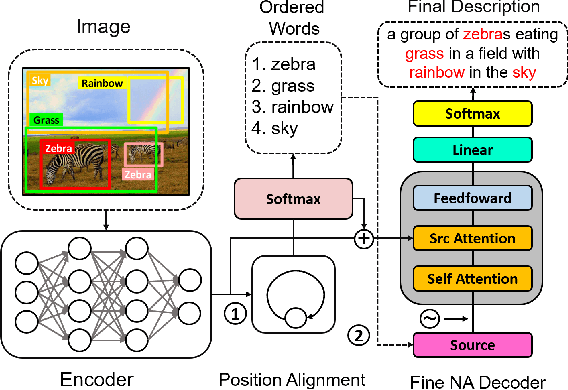
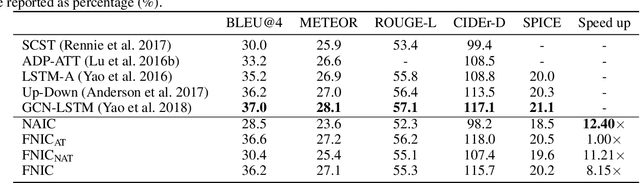

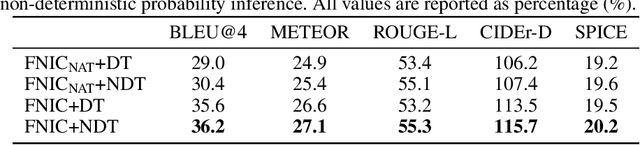
Recent neural network models for image captioning usually employ an encoder-decoder architecture, where the decoder adopts a recursive sequence decoding way. However, such autoregressive decoding may result in sequential error accumulation and slow generation which limit the applications in practice. Non-autoregressive (NA) decoding has been proposed to cover these issues but suffers from language quality problem due to the indirect modeling of the target distribution. Towards that end, we propose an improved NA prediction framework to accelerate image captioning. Our decoding part consists of a position alignment to order the words that describe the content detected in the given image, and a fine non-autoregressive decoder to generate elegant descriptions. Furthermore, we introduce an inference strategy that regards position information as a latent variable to guide the further sentence generation. The Experimental results on public datasets show that our proposed model achieves better performance compared to general NA captioning models, while achieves comparable performance as autoregressive image captioning models with a significant speedup.
Composing Text and Image for Image Retrieval - An Empirical Odyssey
Dec 18, 2018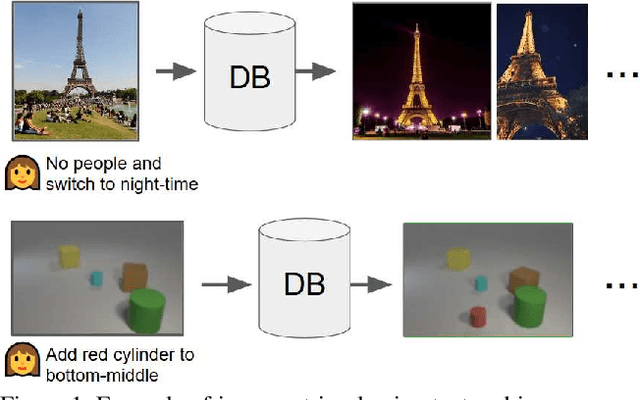
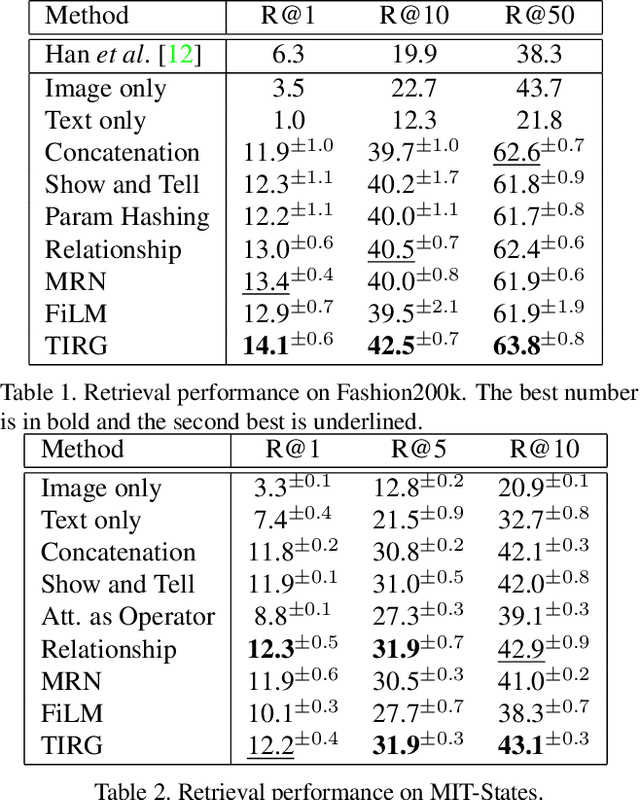
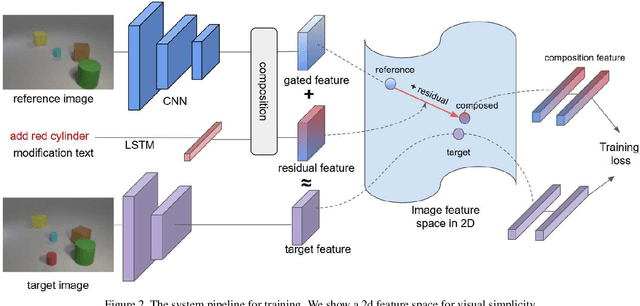

In this paper, we study the task of image retrieval, where the input query is specified in the form of an image plus some text that describes desired modifications to the input image. For example, we may present an image of the Eiffel tower, and ask the system to find images which are visually similar but are modified in small ways, such as being taken at nighttime instead of during the day. To tackle this task, we learn a similarity metric between a target image and a source image plus source text, an embedding and composing function such that target image feature is close to the source image plus text composition feature. We propose a new way to combine image and text using such function that is designed for the retrieval task. We show this outperforms existing approaches on 3 different datasets, namely Fashion-200k, MIT-States and a new synthetic dataset we create based on CLEVR. We also show that our approach can be used to classify input queries, in addition to image retrieval.
Curriculum Meta-Learning for Few-shot Classification
Dec 06, 2021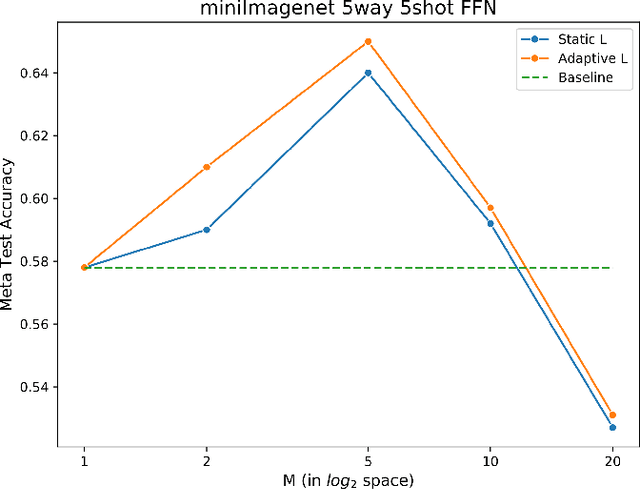
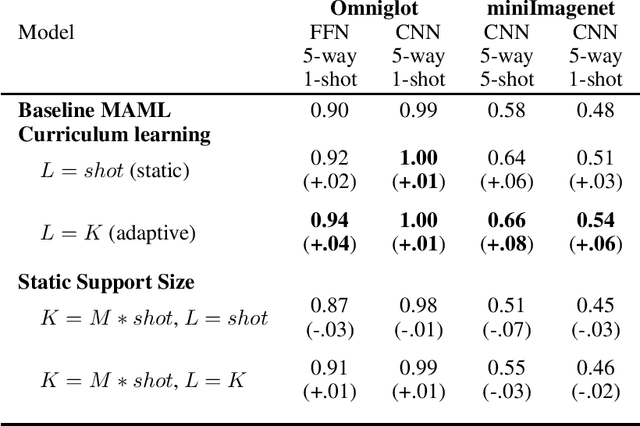
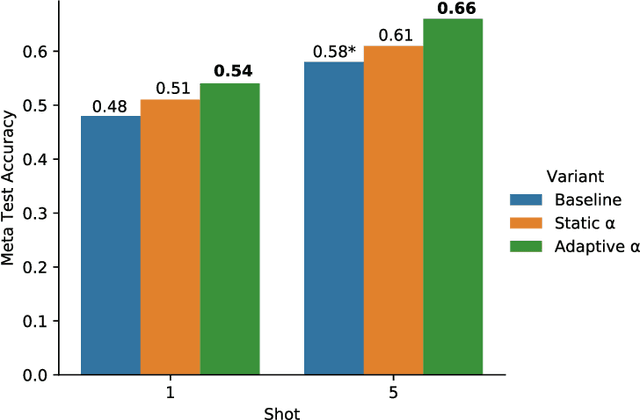
We propose an adaptation of the curriculum training framework, applicable to state-of-the-art meta learning techniques for few-shot classification. Curriculum-based training popularly attempts to mimic human learning by progressively increasing the training complexity to enable incremental concept learning. As the meta-learner's goal is learning how to learn from as few samples as possible, the exact number of those samples (i.e. the size of the support set) arises as a natural proxy of a given task's difficulty. We define a simple yet novel curriculum schedule that begins with a larger support size and progressively reduces it throughout training to eventually match the desired shot-size of the test setup. This proposed method boosts the learning efficiency as well as the generalization capability. Our experiments with the MAML algorithm on two few-shot image classification tasks show significant gains with the curriculum training framework. Ablation studies corroborate the independence of our proposed method from the model architecture as well as the meta-learning hyperparameters
Leveraging Scale-Invariance and Uncertainity with Self-Supervised Domain Adaptation for Semantic Segmentation of Foggy Scenes
Jan 07, 2022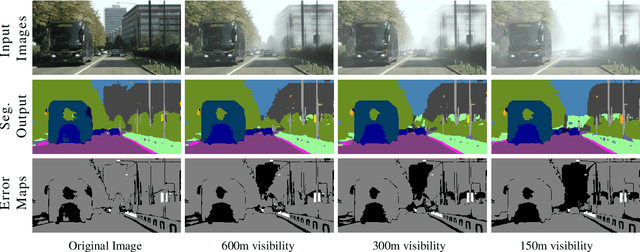

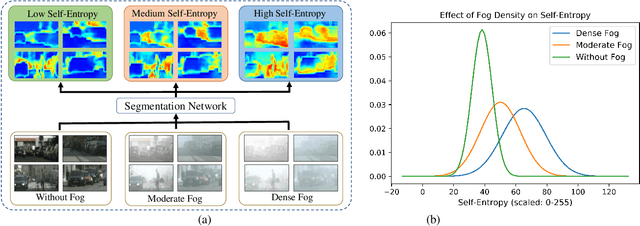
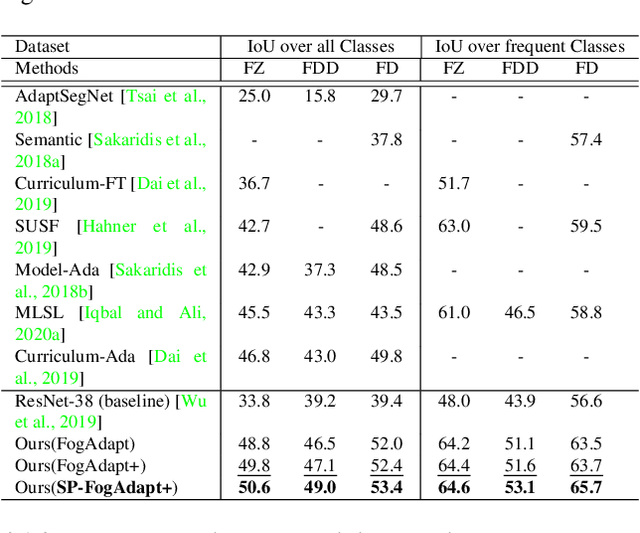
This paper presents FogAdapt, a novel approach for domain adaptation of semantic segmentation for dense foggy scenes. Although significant research has been directed to reduce the domain shift in semantic segmentation, adaptation to scenes with adverse weather conditions remains an open question. Large variations in the visibility of the scene due to weather conditions, such as fog, smog, and haze, exacerbate the domain shift, thus making unsupervised adaptation in such scenarios challenging. We propose a self-entropy and multi-scale information augmented self-supervised domain adaptation method (FogAdapt) to minimize the domain shift in foggy scenes segmentation. Supported by the empirical evidence that an increase in fog density results in high self-entropy for segmentation probabilities, we introduce a self-entropy based loss function to guide the adaptation method. Furthermore, inferences obtained at different image scales are combined and weighted by the uncertainty to generate scale-invariant pseudo-labels for the target domain. These scale-invariant pseudo-labels are robust to visibility and scale variations. We evaluate the proposed model on real clear-weather scenes to real foggy scenes adaptation and synthetic non-foggy images to real foggy scenes adaptation scenarios. Our experiments demonstrate that FogAdapt significantly outperforms the current state-of-the-art in semantic segmentation of foggy images. Specifically, by considering the standard settings compared to state-of-the-art (SOTA) methods, FogAdapt gains 3.8% on Foggy Zurich, 6.0% on Foggy Driving-dense, and 3.6% on Foggy Driving in mIoU when adapted from Cityscapes to Foggy Zurich.
Discriminator Synthesis: On reusing the other half of Generative Adversarial Networks
Nov 12, 2021



Generative Adversarial Networks have long since revolutionized the world of computer vision and, tied to it, the world of art. Arduous efforts have gone into fully utilizing and stabilizing training so that outputs of the Generator network have the highest possible fidelity, but little has gone into using the Discriminator after training is complete. In this work, we propose to use the latter and show a way to use the features it has learned from the training dataset to both alter an image and generate one from scratch. We name this method Discriminator Dreaming, and the full code can be found at https://github.com/PDillis/stylegan3-fun.
Top-Down Deep Clustering with Multi-generator GANs
Dec 24, 2021
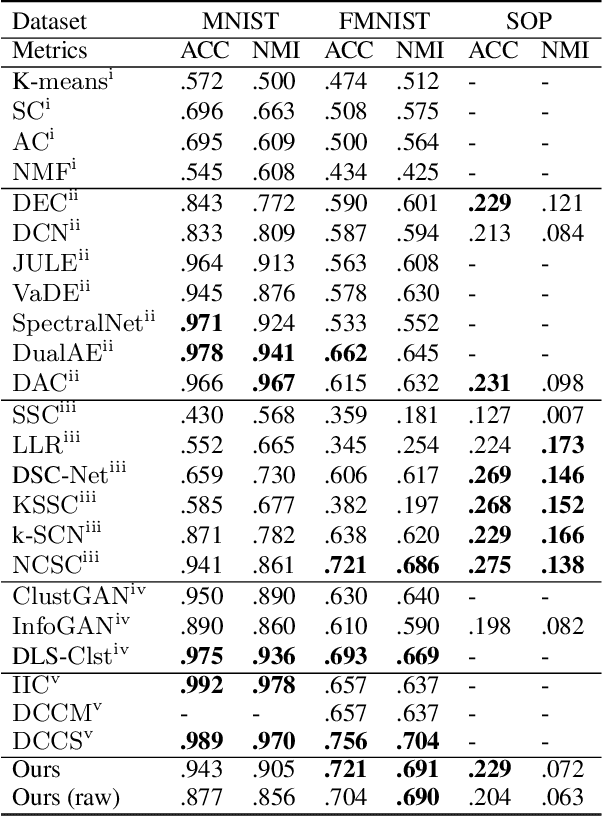
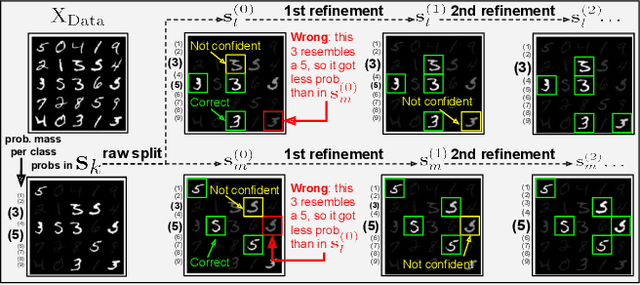

Deep clustering (DC) leverages the representation power of deep architectures to learn embedding spaces that are optimal for cluster analysis. This approach filters out low-level information irrelevant for clustering and has proven remarkably successful for high dimensional data spaces. Some DC methods employ Generative Adversarial Networks (GANs), motivated by the powerful latent representations these models are able to learn implicitly. In this work, we propose HC-MGAN, a new technique based on GANs with multiple generators (MGANs), which have not been explored for clustering. Our method is inspired by the observation that each generator of a MGAN tends to generate data that correlates with a sub-region of the real data distribution. We use this clustered generation to train a classifier for inferring from which generator a given image came from, thus providing a semantically meaningful clustering for the real distribution. Additionally, we design our method so that it is performed in a top-down hierarchical clustering tree, thus proposing the first hierarchical DC method, to the best of our knowledge. We conduct several experiments to evaluate the proposed method against recent DC methods, obtaining competitive results. Last, we perform an exploratory analysis of the hierarchical clustering tree that highlights how accurately it organizes the data in a hierarchy of semantically coherent patterns.
Knowledge Perceived Multi-modal Pretraining in E-commerce
Aug 20, 2021

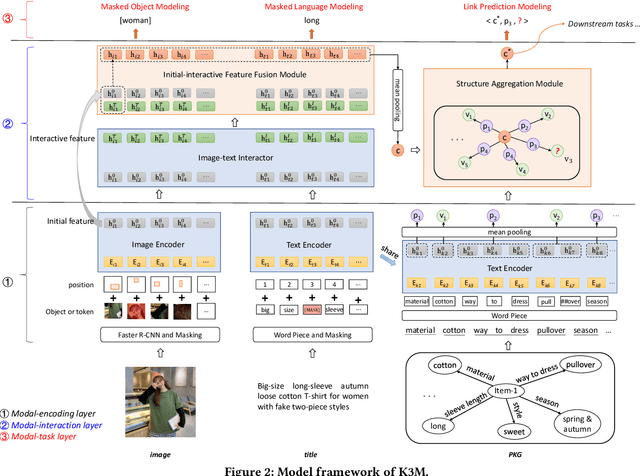
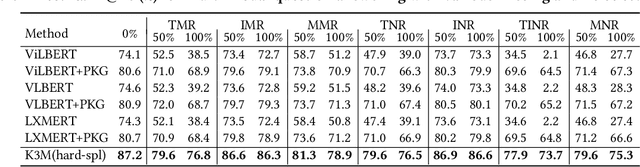
In this paper, we address multi-modal pretraining of product data in the field of E-commerce. Current multi-modal pretraining methods proposed for image and text modalities lack robustness in the face of modality-missing and modality-noise, which are two pervasive problems of multi-modal product data in real E-commerce scenarios. To this end, we propose a novel method, K3M, which introduces knowledge modality in multi-modal pretraining to correct the noise and supplement the missing of image and text modalities. The modal-encoding layer extracts the features of each modality. The modal-interaction layer is capable of effectively modeling the interaction of multiple modalities, where an initial-interactive feature fusion model is designed to maintain the independence of image modality and text modality, and a structure aggregation module is designed to fuse the information of image, text, and knowledge modalities. We pretrain K3M with three pretraining tasks, including masked object modeling (MOM), masked language modeling (MLM), and link prediction modeling (LPM). Experimental results on a real-world E-commerce dataset and a series of product-based downstream tasks demonstrate that K3M achieves significant improvements in performances than the baseline and state-of-the-art methods when modality-noise or modality-missing exists.
RSI-Net: Two-Stream Deep Neural Network Integrating GCN and Atrous CNN for Semantic Segmentation of High-resolution Remote Sensing Images
Sep 19, 2021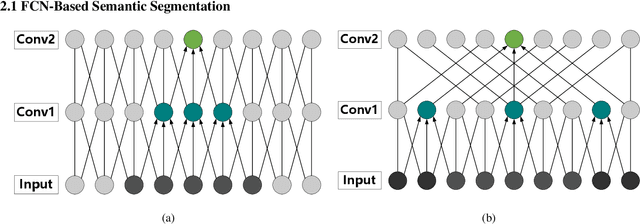
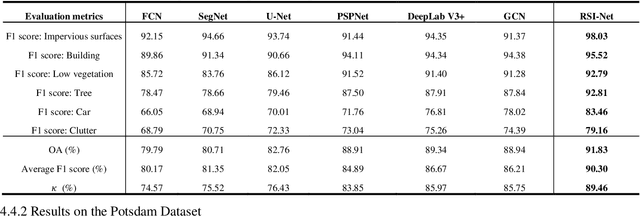
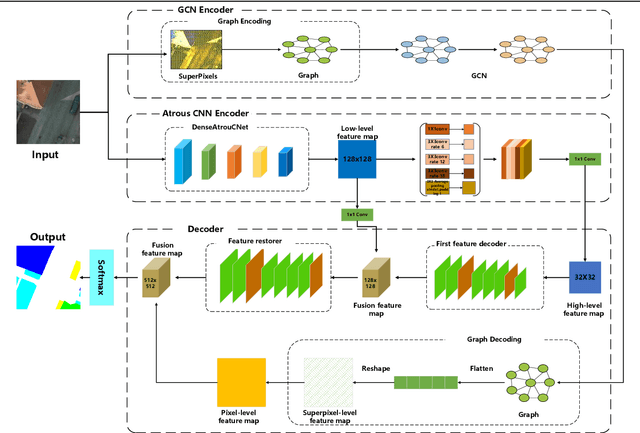
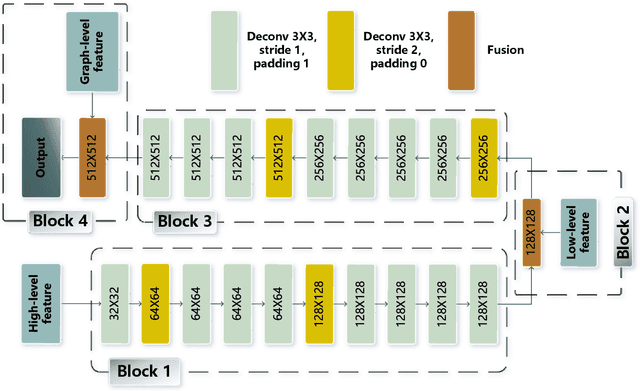
For semantic segmentation of remote sensing images (RSI), trade-off between representation power and location accuracy is quite important. How to get the trade-off effectively is an open question, where current approaches of utilizing attention schemes or very deep models result in complex models with large memory consumption. Compared with the popularly-used convolutional neural network (CNN) with fixed square kernels, graph convolutional network (GCN) can explicitly utilize correlations between adjacent land covers and conduct flexible convolution on arbitrarily irregular image regions. However, the problems of large variations of target scales and blurred boundary cannot be easily solved by GCN, while densely connected atrous convolution network (DenseAtrousCNet) with multi-scale atrous convolution can expand the receptive fields and obtain image global information. Inspired by the advantages of both GCN and Atrous CNN, a two-stream deep neural network for semantic segmentation of RSI (RSI-Net) is proposed in this paper to obtain improved performance through modeling and propagating spatial contextual structure effectively and a novel decoding scheme with image-level and graph-level combination. Extensive experiments are implemented on the Vaihingen, Potsdam and Gaofen RSI datasets, where the comparison results demonstrate the superior performance of RSI-Net in terms of overall accuracy, F1 score and kappa coefficient when compared with six state-of-the-art RSI semantic segmentation methods.