 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quality Guided Sketch-to-Photo Image Synthesis
Apr 20, 2020

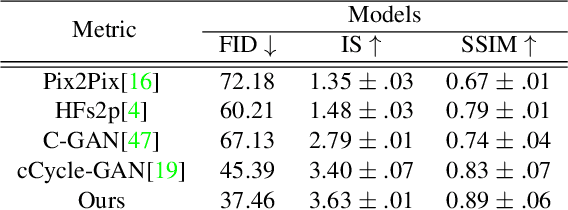
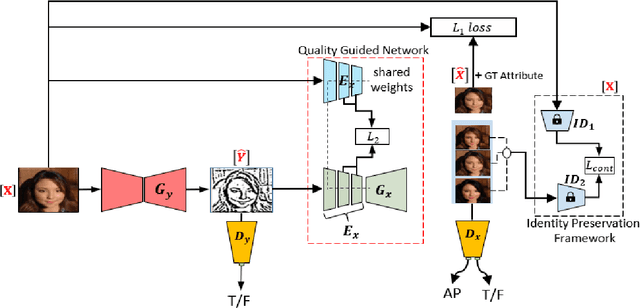
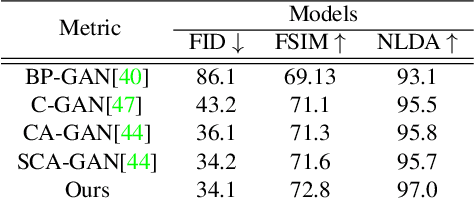
Facial sketches drawn by artists are widely used for visual identification applications and mostly by law enforcement agencies, but the quality of these sketches depend on the ability of the artist to clearly replicate all the key facial features that could aid in capturing the true identity of a subject. Recent works have attempted to synthesize these sketches into plausible visual images to improve visual recognition and identification. However, synthesizing photo-realistic images from sketches proves to be an even more challenging task, especially for sensitive applications such as suspect identification. In this work, we propose a novel approach that adopts a generative adversarial network that synthesizes a single sketch into multiple synthetic images with unique attributes like hair color, sex, etc. We incorporate a hybrid discriminator which performs attribute classification of multiple target attributes, a quality guided encoder that minimizes the perceptual dissimilarity of the latent space embedding of the synthesized and real image at different layers in the network and an identity preserving network that maintains the identity of the synthesised image throughout the training process. Our approach is aimed at improving the visual appeal of the synthesised images while incorporating multiple attribute assignment to the generator without compromising the identity of the synthesised image. We synthesised sketches using XDOG filter for the CelebA, WVU Multi-modal and CelebA-HQ datasets and from an auxiliary generator trained on sketches from CUHK, IIT-D and FERET datasets. Our results are impressive compared to current state of the art.
Hierarchical Semantic Segmentation using Psychometric Learning
Jul 07, 2021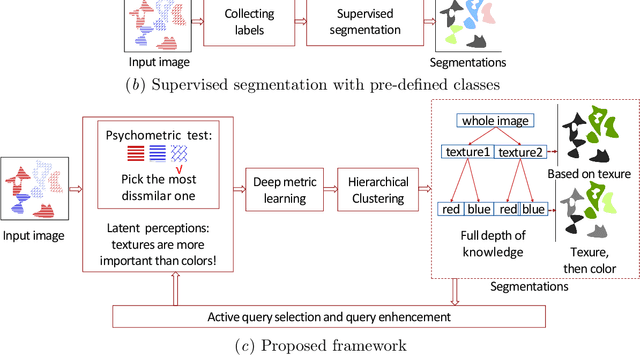


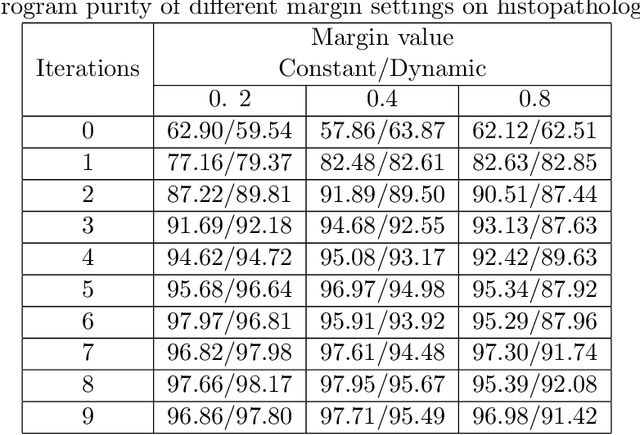
Assigning meaning to parts of image data is the goal of semantic image segmentation. Machine learning methods, specifically supervised learning is commonly used in a variety of tasks formulated as semantic segmentation. One of the major challenges in the supervised learning approaches is expressing and collecting the rich knowledge that experts have with respect to the meaning present in the image data. Towards this, typically a fixed set of labels is specified and experts are tasked with annotating the pixels, patches or segments in the images with the given labels. In general, however, the set of classes does not fully capture the rich semantic information present in the images. For example, in medical imaging such as histology images, the different parts of cells could be grouped and sub-grouped based on the expertise of the pathologist. To achieve such a precise semantic representation of the concepts in the image, we need access to the full depth of knowledge of the annotator. In this work, we develop a novel approach to collect segmentation annotations from experts based on psychometric testing. Our method consists of the psychometric testing procedure, active query selection, query enhancement, and a deep metric learning model to achieve a patch-level image embedding that allows for semantic segmentation of images. We show the merits of our method with evaluation on the synthetically generated image, aerial image and histology image.
The Majority Can Help The Minority: Context-rich Minority Oversampling for Long-tailed Classification
Dec 03, 2021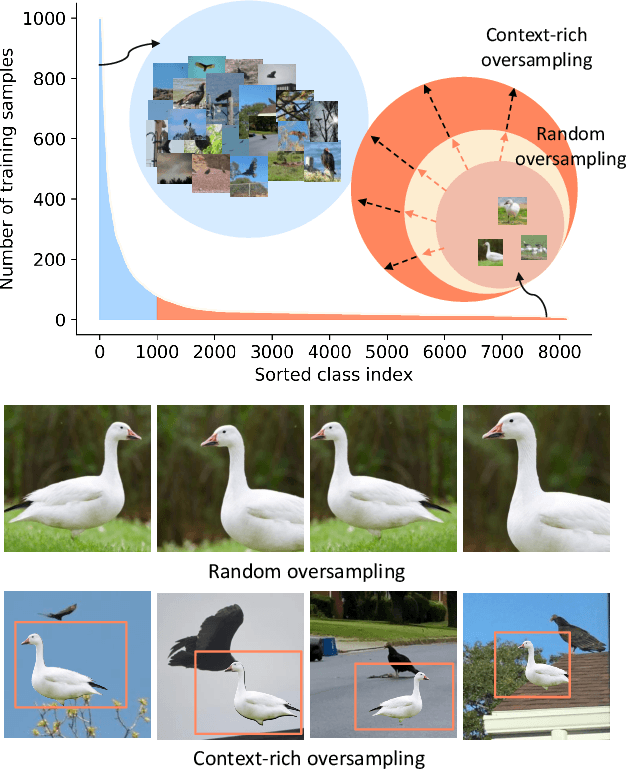
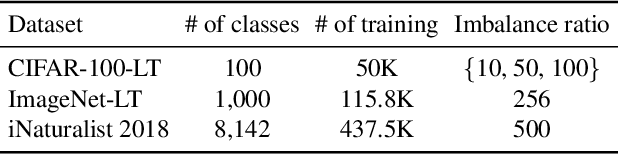
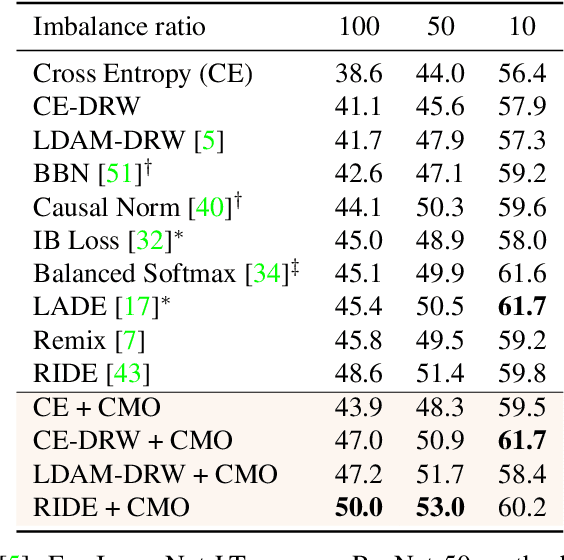

The problem of class imbalanced data lies in that the generalization performance of the classifier is deteriorated due to the lack of data of the minority classes. In this paper, we propose a novel minority over-sampling method to augment diversified minority samples by leveraging the rich context of the majority classes as background images. To diversify the minority samples, our key idea is to paste a foreground patch from a minority class to a background image from a majority class having affluent contexts. Our method is simple and can be easily combined with the existing long-tailed recognition methods. We empirically prove the effectiveness of the proposed oversampling method through extensive experiments and ablation studies. Without any architectural changes or complex algorithms, our method achieves state-of-the-art performance on various long-tailed classification benchmarks. Our code will be publicly available at link.
Groupwise Multimodal Image Registration using Joint Total Variation
May 06, 2020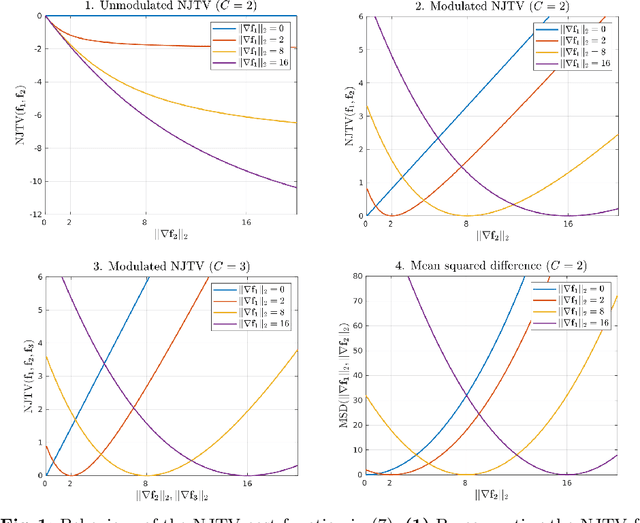

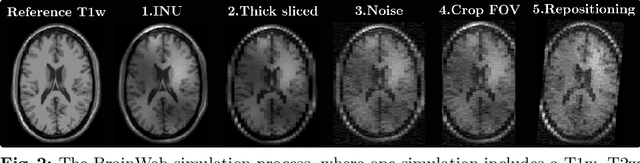
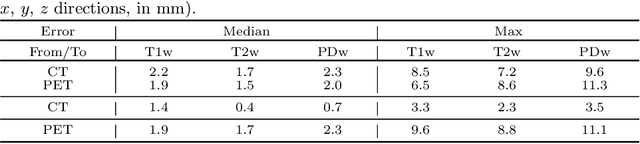
In medical imaging it is common practice to acquire a wide range of modalities (MRI, CT, PET, etc.), to highlight different structures or pathologies. As patient movement between scans or scanning session is unavoidable, registration is often an essential step before any subsequent image analysis. In this paper, we introduce a cost function based on joint total variation for such multimodal image registration. This cost function has the advantage of enabling principled, groupwise alignment of multiple images, whilst being insensitive to strong intensity non-uniformities. We evaluate our algorithm on rigidly aligning both simulated and real 3D brain scans. This validation shows robustness to strong intensity non-uniformities and low registration errors for CT/PET to MRI alignment. Our implementation is publicly available at https://github.com/brudfors/coregistration-njtv.
Projective Skip-Connections for Segmentation Along a Subset of Dimensions in Retinal OCT
Aug 02, 2021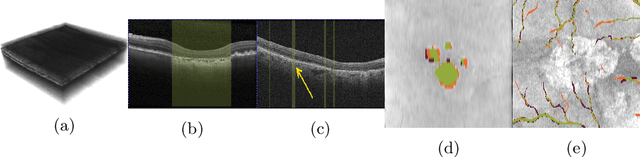
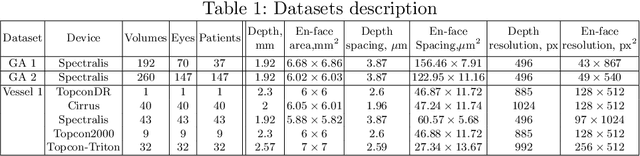
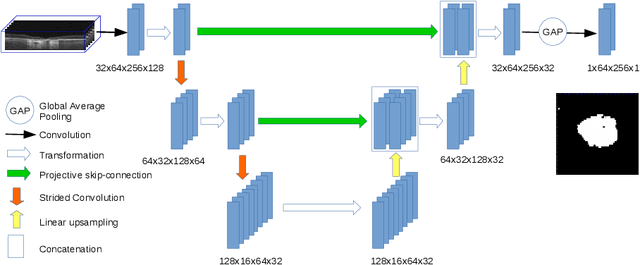
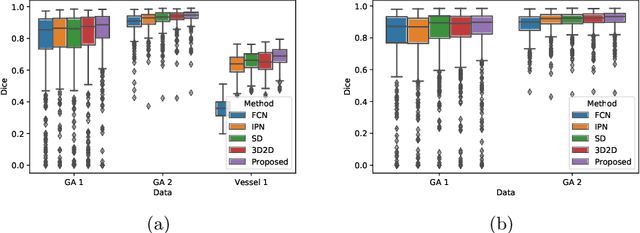
In medical imaging, there are clinically relevant segmentation tasks where the output mask is a projection to a subset of input image dimensions. In this work, we propose a novel convolutional neural network architecture that can effectively learn to produce a lower-dimensional segmentation mask than the input image. The network restores encoded representation only in a subset of input spatial dimensions and keeps the representation unchanged in the others. The newly proposed projective skip-connections allow linking the encoder and decoder in a UNet-like structure. We evaluated the proposed method on two clinically relevant tasks in retinal Optical Coherence Tomography (OCT): geographic atrophy and retinal blood vessel segmentation. The proposed method outperformed the current state-of-the-art approaches on all the OCT datasets used, consisting of 3D volumes and corresponding 2D en-face masks. The proposed architecture fills the methodological gap between image classification and ND image segmentation.
Recyclable Waste Identification Using CNN Image Recognition and Gaussian Clustering
Nov 02, 2020
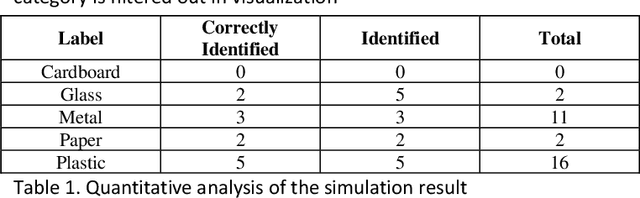

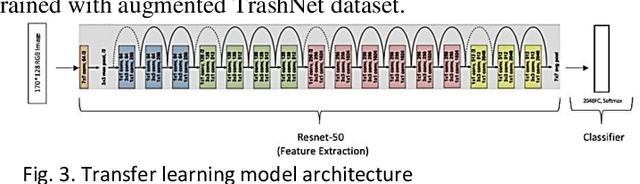
Waste recycling is an important way of saving energy and materials in the production process. In general cases recyclable objects are mixed with unrecyclable objects, which raises a need for identification and classification. This paper proposes a convolutional neural network (CNN) model to complete both tasks. The model uses transfer learning from a pretrained Resnet-50 CNN to complete feature extraction. A subsequent fully connected layer for classification was trained on the augmented TrashNet dataset [1]. In the application, sliding-window is used for image segmentation in the pre-classification stage. In the post-classification stage, the labelled sample points are integrated with Gaussian Clustering to locate the object. The resulting model has achieved an overall detection rate of 48.4% in simulation and final classification accuracy of 92.4%.
Weak Novel Categories without Tears: A Survey on Weak-Shot Learning
Oct 16, 2021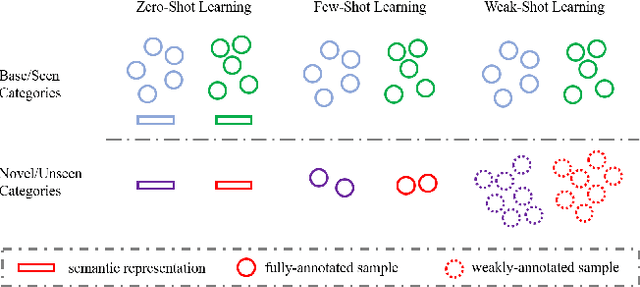
Deep learning is a data-hungry approach, which requires massive training data. However, it is time-consuming and labor-intensive to collect abundant fully-annotated training data for all categories. Assuming the existence of base categories with adequate fully-annotated training samples, different paradigms requiring fewer training samples or weaker annotations for novel categories have attracted growing research interest. Among them, zero-shot (resp., few-shot) learning explores using zero (resp., a few) training samples for novel categories, which lowers the quantity requirement for novel categories. Instead, weak-shot learning lowers the quality requirement for novel categories. Specifically, sufficient training samples are collected for novel categories but they only have weak annotations. In different tasks, weak annotations are presented in different forms (e.g., noisy labels for image classification, image labels for object detection, bounding boxes for segmentation), similar to the definitions in weakly supervised learning. Therefore, weak-shot learning can also be treated as weakly supervised learning with auxiliary fully supervised categories. In this paper, we discuss the existing weak-shot learning methodologies in different tasks and summarize the codes at https://github.com/bcmi/Awesome-Weak-Shot-Learning.
Exploring and Distilling Cross-Modal Information for Image Captioning
Feb 28, 2020
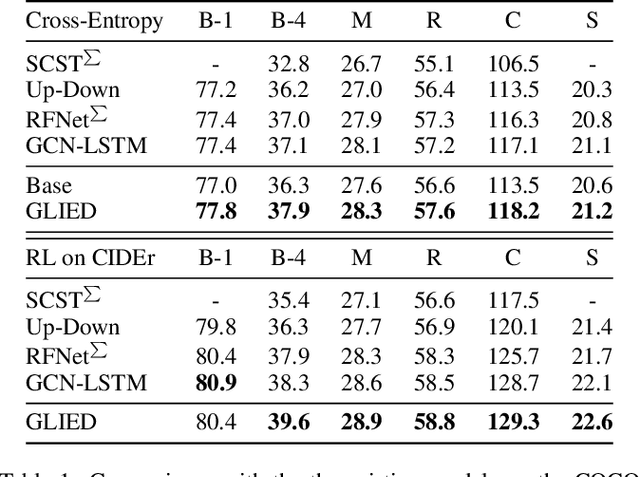
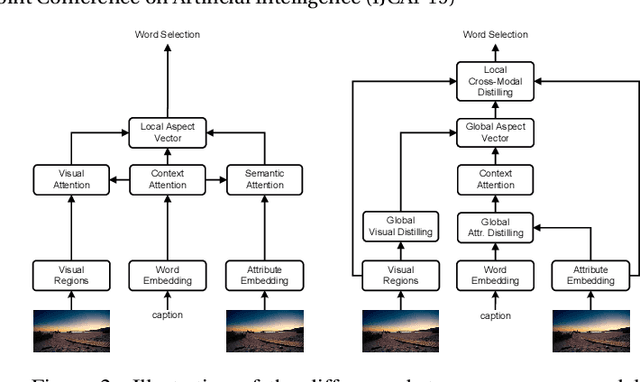
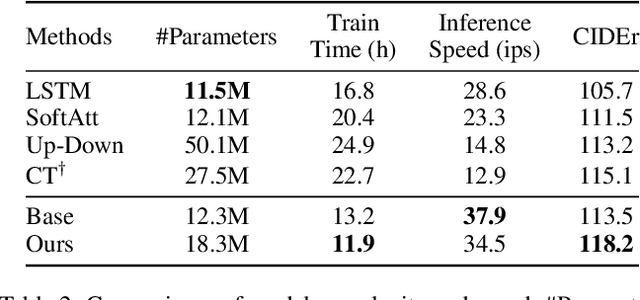
Recently, attention-based encoder-decoder models have been used extensively in image captioning. Yet there is still great difficulty for the current methods to achieve deep image understanding. In this work, we argue that such understanding requires visual attention to correlated image regions and semantic attention to coherent attributes of interest. To perform effective attention, we explore image captioning from a cross-modal perspective and propose the Global-and-Local Information Exploring-and-Distilling approach that explores and distills the source information in vision and language. It globally provides the aspect vector, a spatial and relational representation of images based on caption contexts, through the extraction of salient region groupings and attribute collocations, and locally extracts the fine-grained regions and attributes in reference to the aspect vector for word selection. Our fully-attentive model achieves a CIDEr score of 129.3 in offline COCO evaluation on the COCO testing set with remarkable efficiency in terms of accuracy, speed, and parameter budget.
Beyond Semantic to Instance Segmentation: Weakly-Supervised Instance Segmentation via Semantic Knowledge Transfer and Self-Refinement
Sep 20, 2021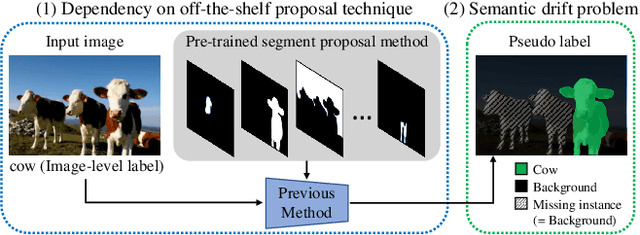
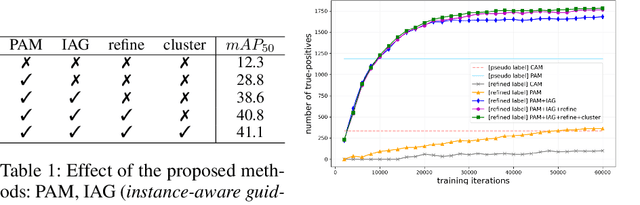
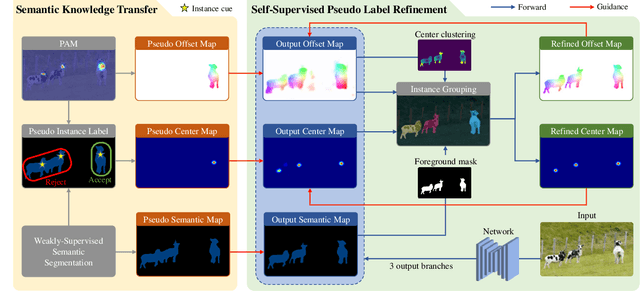
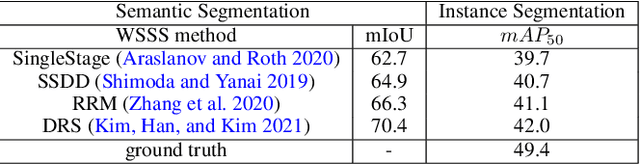
Recent weakly-supervised semantic segmentation (WSSS) has made remarkable progress due to class-wise localization techniques using image-level labels. Meanwhile, weakly-supervised instance segmentation (WSIS) is a more challenging task because instance-wise localization using only image-level labels is quite difficult. Consequently, most WSIS approaches exploit off-the-shelf proposal technique that requires pre-training with high-level labels, deviating a fully image-level supervised setting. Moreover, we focus on semantic drift problem, $i.e.,$ missing instances in pseudo instance labels are categorized as background class, occurring confusion between background and instance in training. To this end, we propose a novel approach that consists of two innovative components. First, we design a semantic knowledge transfer to obtain pseudo instance labels by transferring the knowledge of WSSS to WSIS while eliminating the need for off-the-shelf proposals. Second, we propose a self-refinement method that refines the pseudo instance labels in a self-supervised scheme and employs them to the training in an online manner while resolving the semantic drift problem. The extensive experiments demonstrate the effectiveness of our approach, and we outperform existing works on PASCAL VOC2012 without any off-the-shelf proposal techniques. Furthermore, our approach can be easily applied to the point-supervised setting, boosting the performance with an economical annotation cost. The code will be available soon.
Label-Efficient Semantic Segmentation with Diffusion Models
Dec 06, 2021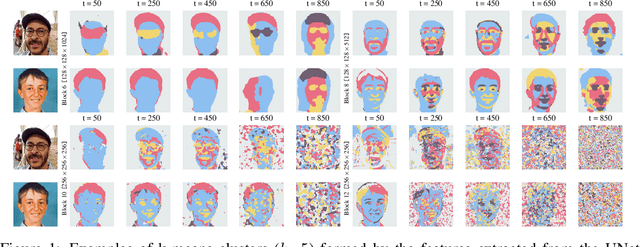
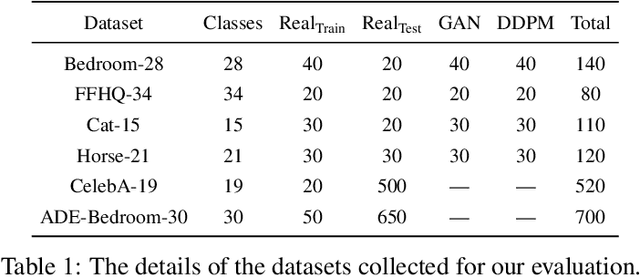
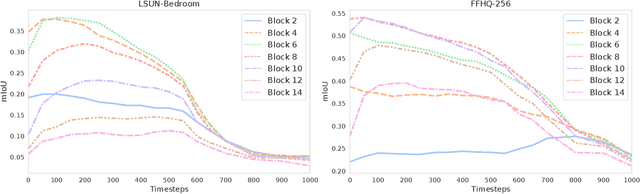
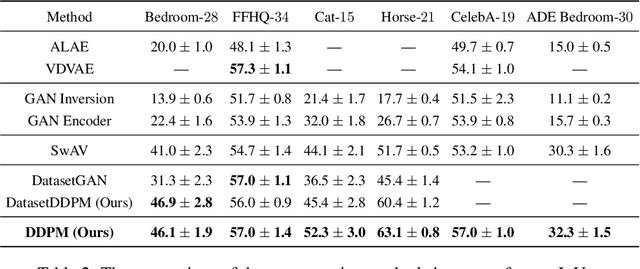
Denoising diffusion probabilistic models have recently received much research attention since they outperform alternative approaches, such as GANs, and currently provide state-of-the-art generative performance. The superior performance of diffusion models has made them an appealing tool in several applications, including inpainting, super-resolution, and semantic editing. In this paper, we demonstrate that diffusion models can also serve as an instrument for semantic segmentation, especially in the setup when labeled data is scarce. In particular, for several pretrained diffusion models, we investigate the intermediate activations from the networks that perform the Markov step of the reverse diffusion process. We show that these activations effectively capture the semantic information from an input image and appear to be excellent pixel-level representations for the segmentation problem. Based on these observations, we describe a simple segmentation method, which can work even if only a few training images are provided. Our approach significantly outperforms the existing alternatives on several datasets for the same amount of human supervision.