 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Auto-Parsing Network for Image Captioning and Visual Question Answering
Aug 24, 2021
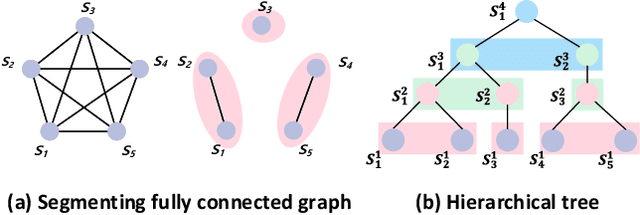

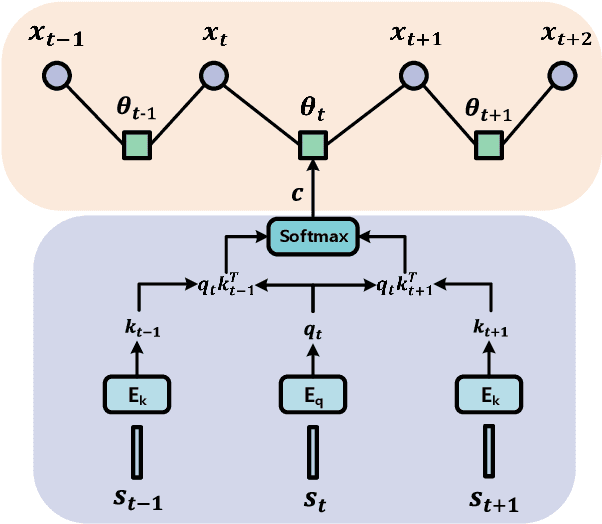
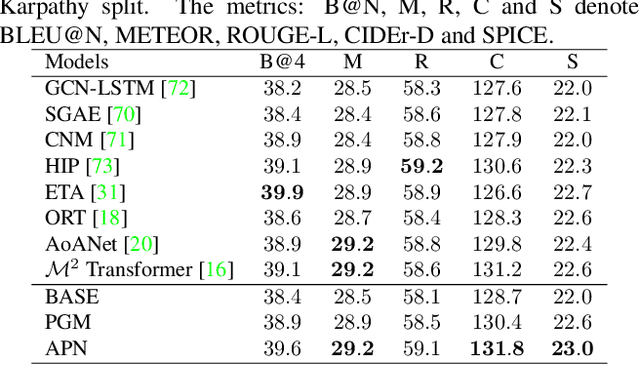
We propose an Auto-Parsing Network (APN) to discover and exploit the input data's hidden tree structures for improving the effectiveness of the Transformer-based vision-language systems. Specifically, we impose a Probabilistic Graphical Model (PGM) parameterized by the attention operations on each self-attention layer to incorporate sparse assumption. We use this PGM to softly segment an input sequence into a few clusters where each cluster can be treated as the parent of the inside entities. By stacking these PGM constrained self-attention layers, the clusters in a lower layer compose into a new sequence, and the PGM in a higher layer will further segment this sequence. Iteratively, a sparse tree can be implicitly parsed, and this tree's hierarchical knowledge is incorporated into the transformed embeddings, which can be used for solving the target vision-language tasks. Specifically, we showcase that our APN can strengthen Transformer based networks in two major vision-language tasks: Captioning and Visual Question Answering. Also, a PGM probability-based parsing algorithm is developed by which we can discover what the hidden structure of input is during the inference.
A Novel Global Spatial Attention Mechanism in Convolutional Neural Network for Medical Image Classification
Jul 31, 2020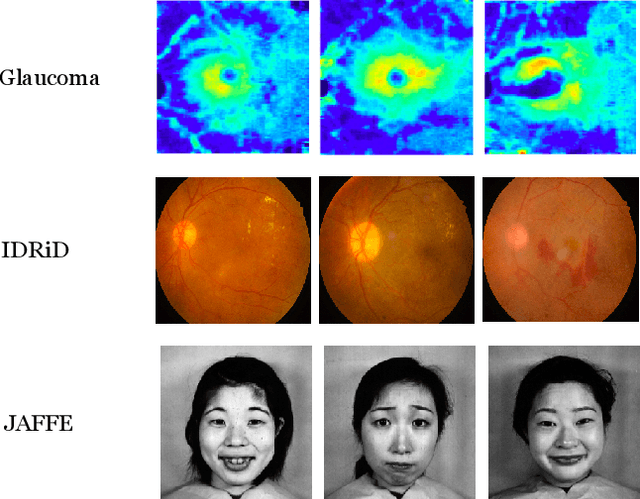

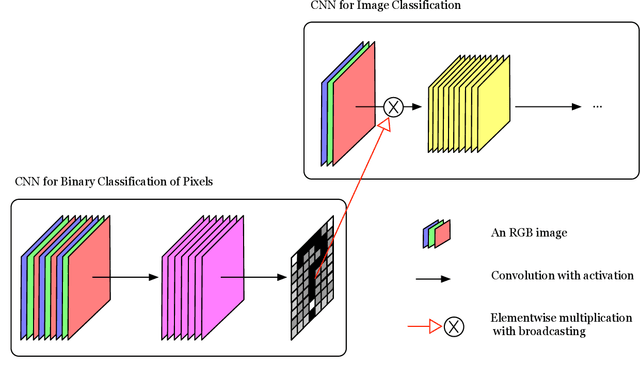
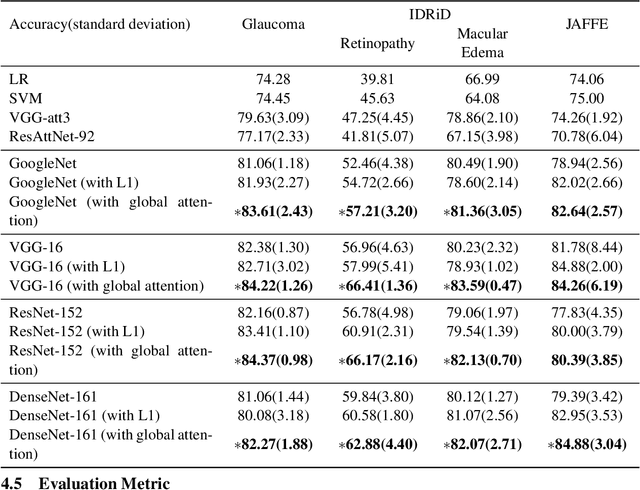
Spatial attention has been introduced to convolutional neural networks (CNNs) for improving both their performance and interpretability in visual tasks including image classification. The essence of the spatial attention is to learn a weight map which represents the relative importance of activations within the same layer or channel. All existing attention mechanisms are local attentions in the sense that weight maps are image-specific. However, in the medical field, there are cases that all the images should share the same weight map because the set of images record the same kind of symptom related to the same object and thereby share the same structural content. In this paper, we thus propose a novel global spatial attention mechanism in CNNs mainly for medical image classification. The global weight map is instantiated by a decision boundary between important pixels and unimportant pixels. And we propose to realize the decision boundary by a binary classifier in which the intensities of all images at a pixel are the features of the pixel. The binary classification is integrated into an image classification CNN and is to be optimized together with the CNN. Experiments on two medical image datasets and one facial expression dataset showed that with the proposed attention, not only the performance of four powerful CNNs which are GoogleNet, VGG, ResNet, and DenseNet can be improved, but also meaningful attended regions can be obtained, which is beneficial for understanding the content of images of a domain.
Aligning Domain-specific Distribution and Classifier for Cross-domain Classification from Multiple Sources
Jan 04, 2022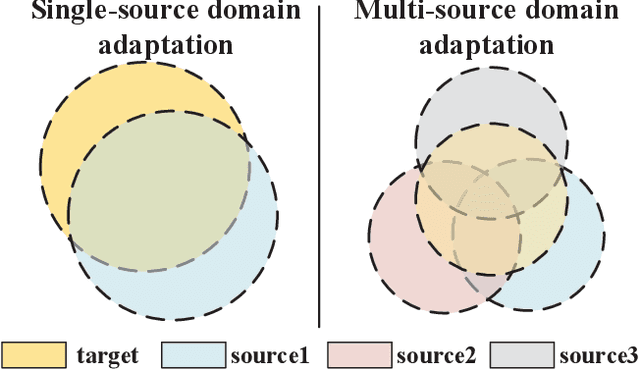
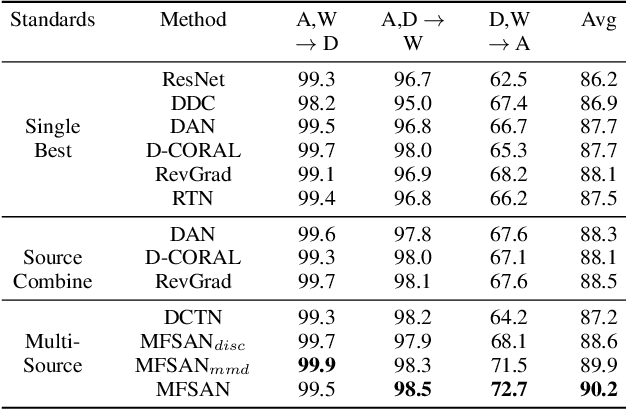
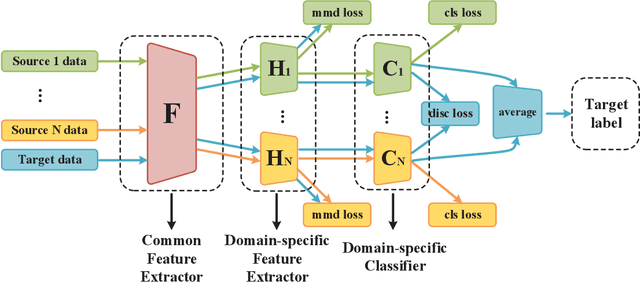
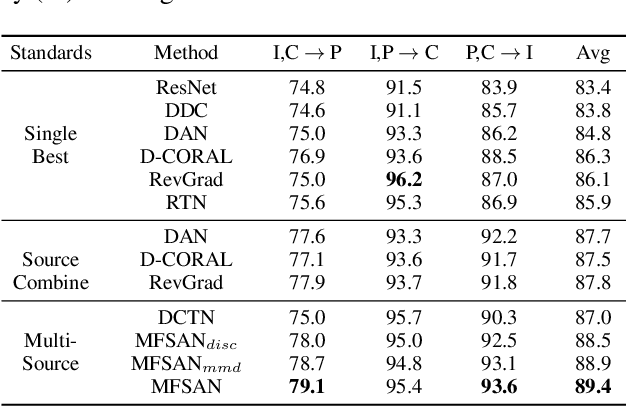
While Unsupervised Domain Adaptation (UDA) algorithms, i.e., there are only labeled data from source domains, have been actively studied in recent years, most algorithms and theoretical results focus on Single-source Unsupervised Domain Adaptation (SUDA). However, in the practical scenario, labeled data can be typically collected from multiple diverse sources, and they might be different not only from the target domain but also from each other. Thus, domain adapters from multiple sources should not be modeled in the same way. Recent deep learning based Multi-source Unsupervised Domain Adaptation (MUDA) algorithms focus on extracting common domain-invariant representations for all domains by aligning distribution of all pairs of source and target domains in a common feature space. However, it is often very hard to extract the same domain-invariant representations for all domains in MUDA. In addition, these methods match distributions without considering domain-specific decision boundaries between classes. To solve these problems, we propose a new framework with two alignment stages for MUDA which not only respectively aligns the distributions of each pair of source and target domains in multiple specific feature spaces, but also aligns the outputs of classifiers by utilizing the domain-specific decision boundaries. Extensive experiments demonstrate that our method can achieve remarkable results on popular benchmark datasets for image classification.
Tradeoffs Between Contrastive and Supervised Learning: An Empirical Study
Dec 10, 2021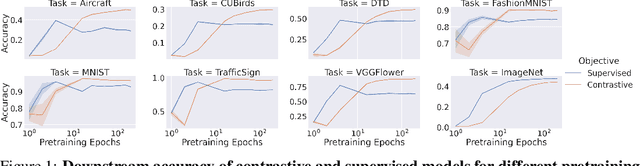
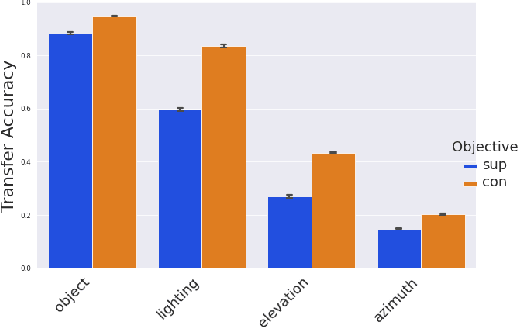
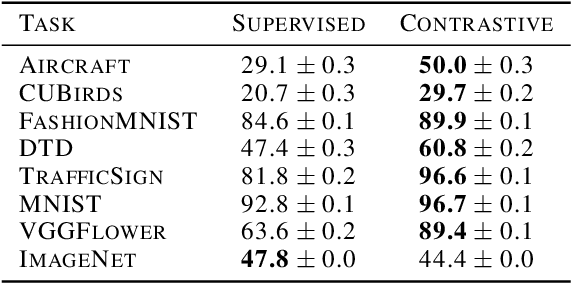
Contrastive learning has made considerable progress in computer vision, outperforming supervised pretraining on a range of downstream datasets. However, is contrastive learning the better choice in all situations? We demonstrate two cases where it is not. First, under sufficiently small pretraining budgets, supervised pretraining on ImageNet consistently outperforms a comparable contrastive model on eight diverse image classification datasets. This suggests that the common practice of comparing pretraining approaches at hundreds or thousands of epochs may not produce actionable insights for those with more limited compute budgets. Second, even with larger pretraining budgets we identify tasks where supervised learning prevails, perhaps because the object-centric bias of supervised pretraining makes the model more resilient to common corruptions and spurious foreground-background correlations. These results underscore the need to characterize tradeoffs of different pretraining objectives across a wider range of contexts and training regimes.
Certifiable Artificial Intelligence Through Data Fusion
Nov 03, 2021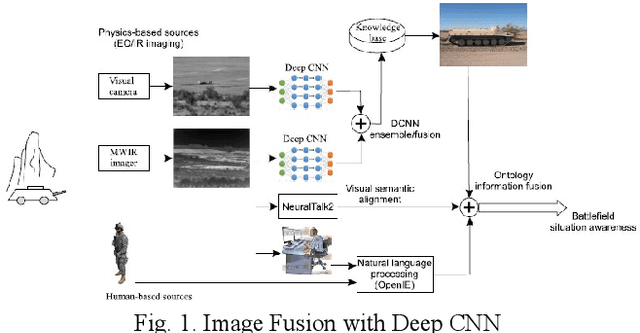
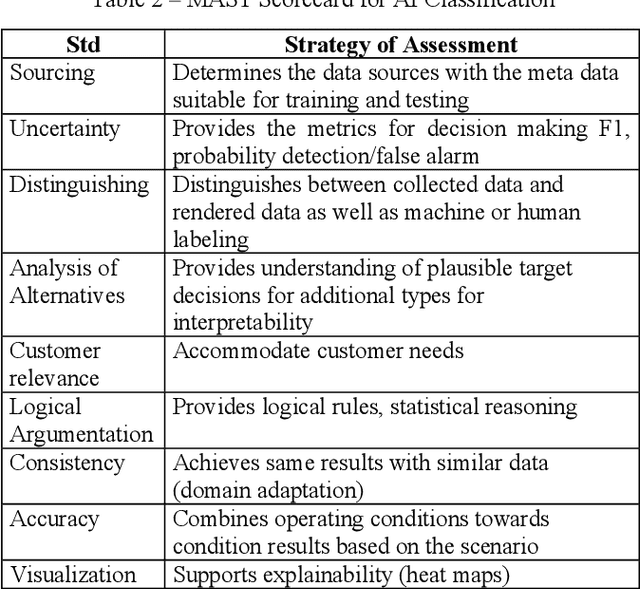
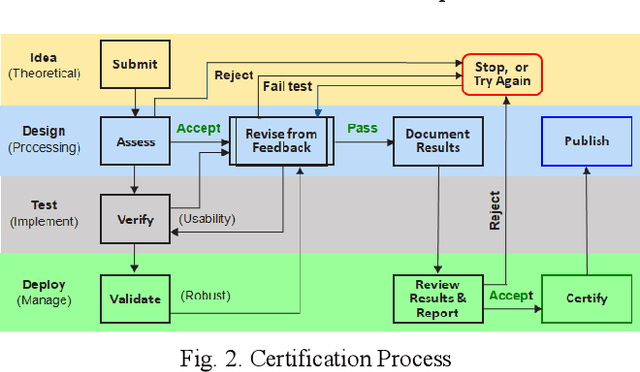
This paper reviews and proposes concerns in adopting, fielding, and maintaining artificial intelligence (AI) systems. While the AI community has made rapid progress, there are challenges in certifying AI systems. Using procedures from design and operational test and evaluation, there are opportunities towards determining performance bounds to manage expectations of intended use. A notional use case is presented with image data fusion to support AI object recognition certifiability considering precision versus distance.
Better Understanding Hierarchical Visual Relationship for Image Caption
Dec 04, 2019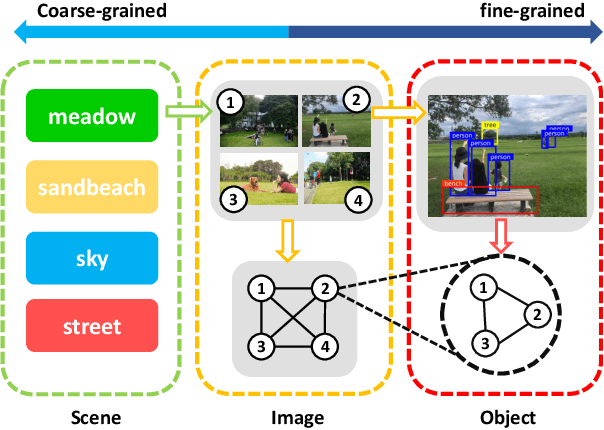
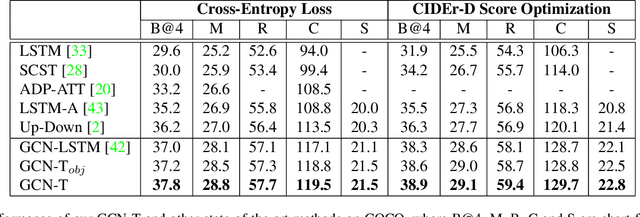

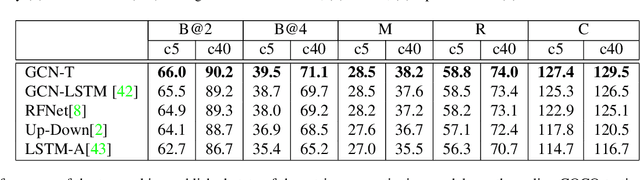
The Convolutional Neural Network (CNN) has been the dominant image feature extractor in computer vision for years. However, it fails to get the relationship between images/objects and their hierarchical interactions which can be helpful for representing and describing an image. In this paper, we propose a new design for image caption under a general encoder-decoder framework. It takes into account the hierarchical interactions between different abstraction levels of visual information in the images and their bounding-boxes. Specifically, we present CNN plus Graph Convolutional Network (GCN) architecture that novelly integrates both semantic and spatial visual relationships into image encoder. The representations of regions in an image and the connections between images are refined by leveraging graph structure through GCN. With the learned multi-level features, our model capitalizes on the Transformer-based decoder for description generation. We conduct experiments on the COCO image captioning dataset. Evaluations show that our proposed model outperforms the previous state-of-the-art models in the task of image caption, leading to a better performance in terms of all evaluation metrics.
Multi-Camera Sensor Fusion for Visual Odometry using Deep Uncertainty Estimation
Dec 23, 2021Visual Odometry (VO) estimation is an important source of information for vehicle state estimation and autonomous driving. Recently, deep learning based approaches have begun to appear in the literature. However, in the context of driving, single sensor based approaches are often prone to failure because of degraded image quality due to environmental factors, camera placement, etc. To address this issue, we propose a deep sensor fusion framework which estimates vehicle motion using both pose and uncertainty estimations from multiple on-board cameras. We extract spatio-temporal feature representations from a set of consecutive images using a hybrid CNN - RNN model. We then utilise a Mixture Density Network (MDN) to estimate the 6-DoF pose as a mixture of distributions and a fusion module to estimate the final pose using MDN outputs from multi-cameras. We evaluate our approach on the publicly available, large scale autonomous vehicle dataset, nuScenes. The results show that the proposed fusion approach surpasses the state-of-the-art, and provides robust estimates and accurate trajectories compared to individual camera-based estimations.
MDN-VO: Estimating Visual Odometry with Confidence
Dec 23, 2021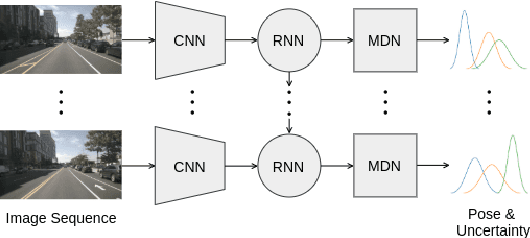
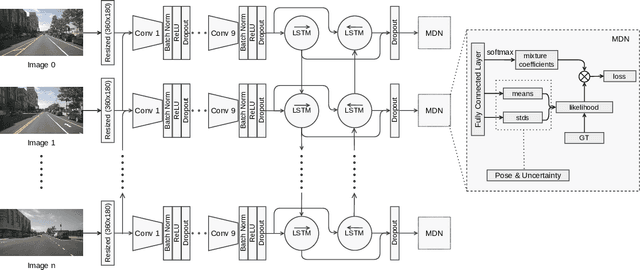
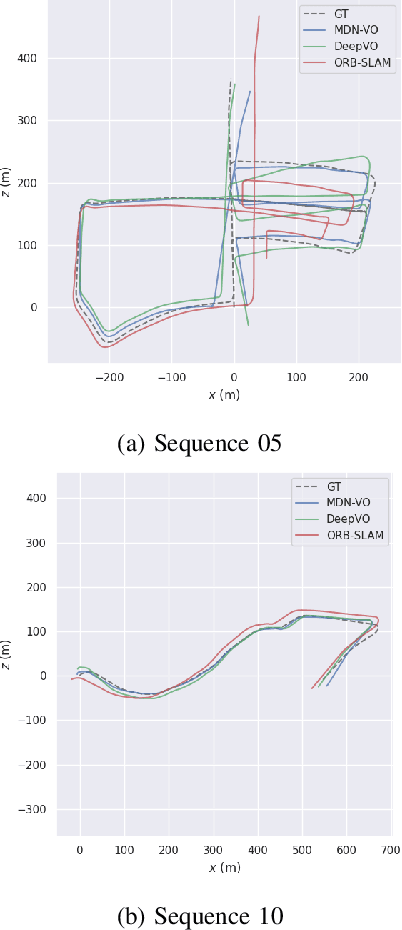
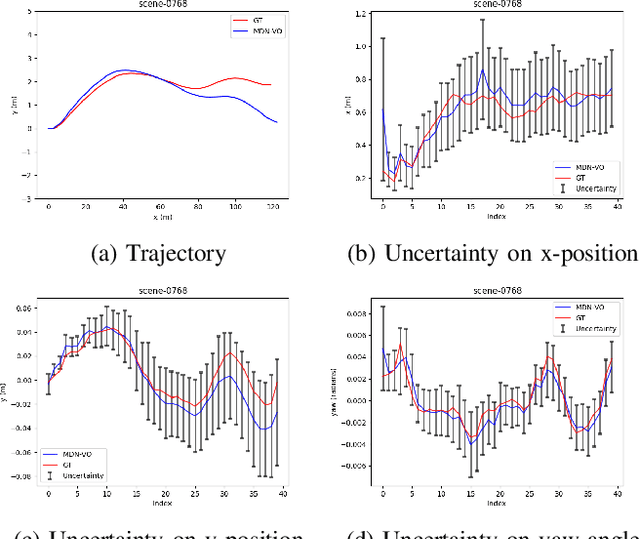
Visual Odometry (VO) is used in many applications including robotics and autonomous systems. However, traditional approaches based on feature matching are computationally expensive and do not directly address failure cases, instead relying on heuristic methods to detect failure. In this work, we propose a deep learning-based VO model to efficiently estimate 6-DoF poses, as well as a confidence model for these estimates. We utilise a CNN - RNN hybrid model to learn feature representations from image sequences. We then employ a Mixture Density Network (MDN) which estimates camera motion as a mixture of Gaussians, based on the extracted spatio-temporal representations. Our model uses pose labels as a source of supervision, but derives uncertainties in an unsupervised manner. We evaluate the proposed model on the KITTI and nuScenes datasets and report extensive quantitative and qualitative results to analyse the performance of both pose and uncertainty estimation. Our experiments show that the proposed model exceeds state-of-the-art performance in addition to detecting failure cases using the predicted pose uncertainty.
Region Normalization for Image Inpainting
Nov 23, 2019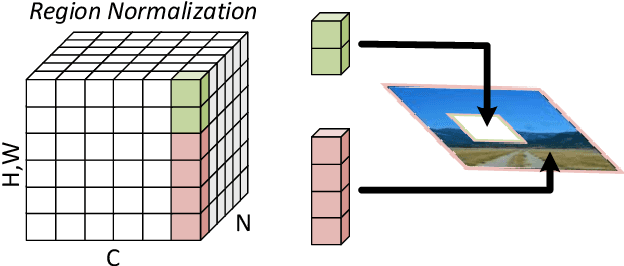
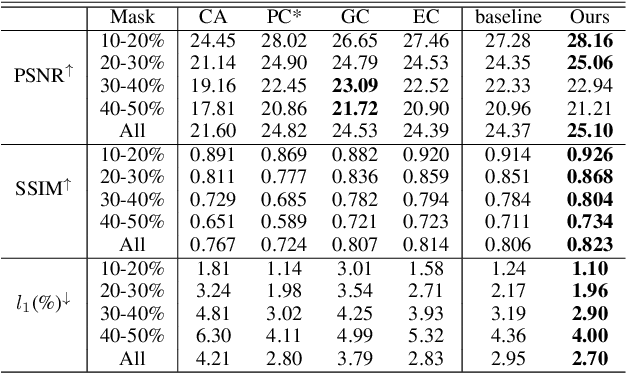
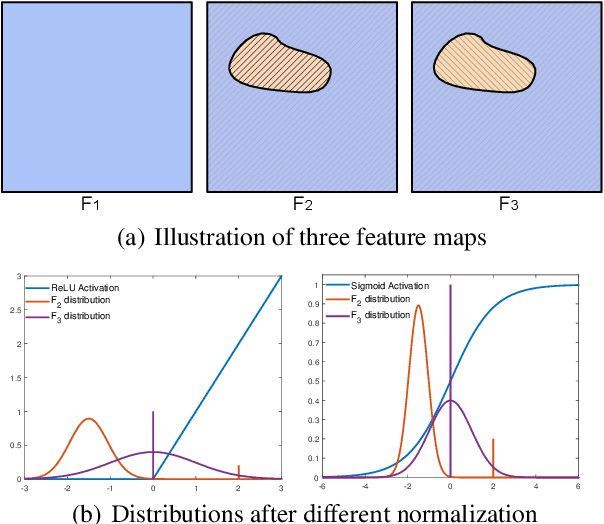
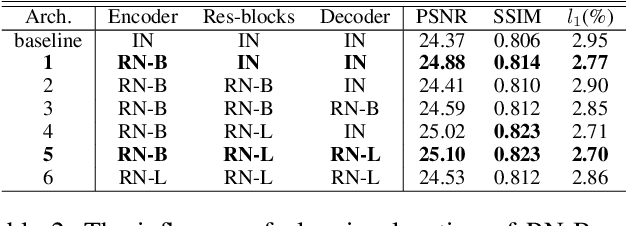
Feature Normalization (FN) is an important technique to help neural network training, which typically normalizes features across spatial dimensions. Most previous image inpainting methods apply FN in their networks without considering the impact of the corrupted regions of the input image on normalization, e.g. mean and variance shifts. In this work, we show that the mean and variance shifts caused by full-spatial FN limit the image inpainting network training and we propose a spatial region-wise normalization named Region Normalization (RN) to overcome the limitation. RN divides spatial pixels into different regions according to the input mask, and computes the mean and variance in each region for normalization. We develop two kinds of RN for our image inpainting network: (1) Basic RN (RN-B), which normalizes pixels from the corrupted and uncorrupted regions separately based on the original inpainting mask to solve the mean and variance shift problem; (2) Learnable RN (RN-L), which automatically detects potentially corrupted and uncorrupted regions for separate normalization, and performs global affine transformation to enhance their fusion. We apply RN-B in the early layers and RN-L in the latter layers of the network respectively. Experiments show that our method outperforms current state-of-the-art methods quantitatively and qualitatively. We further generalize RN to other inpainting networks and achieve consistent performance improvements.
CamLessMonoDepth: Monocular Depth Estimation with Unknown Camera Parameters
Oct 27, 2021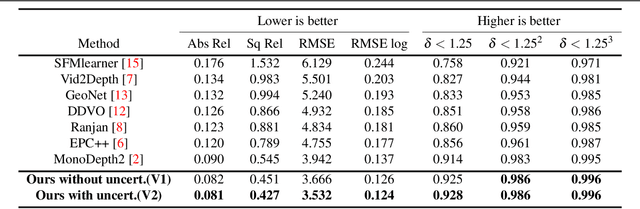
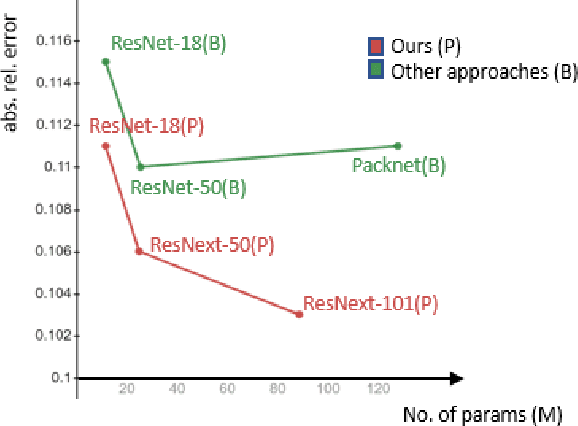
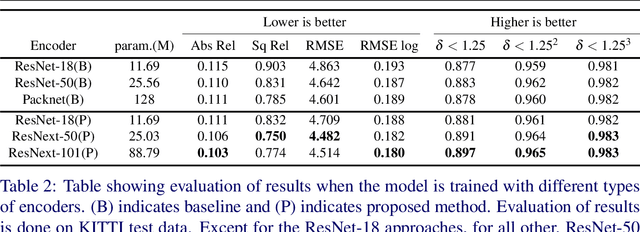
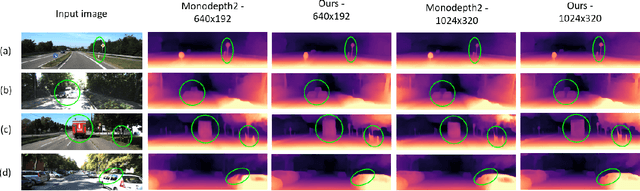
Perceiving 3D information is of paramount importance in many applications of computer vision. Recent advances in monocular depth estimation have shown that gaining such knowledge from a single camera input is possible by training deep neural networks to predict inverse depth and pose, without the necessity of ground truth data. The majority of such approaches, however, require camera parameters to be fed explicitly during training. As a result, image sequences from wild cannot be used during training. While there exist methods which also predict camera intrinsics, their performance is not on par with novel methods taking camera parameters as input. In this work, we propose a method for implicit estimation of pinhole camera intrinsics along with depth and pose, by learning from monocular image sequences alone. In addition, by utilizing efficient sub-pixel convolutions, we show that high fidelity depth estimates can be obtained. We also embed pixel-wise uncertainty estimation into the framework, to emphasize the possible applicability of this work in practical domain. Finally, we demonstrate the possibility of accurate prediction of depth information without prior knowledge of camera intrinsics, while outperforming the existing state-of-the-art approaches on KITTI benchmark.