 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Runway Extraction and Improved Mapping from Space Imagery
Dec 30, 2021

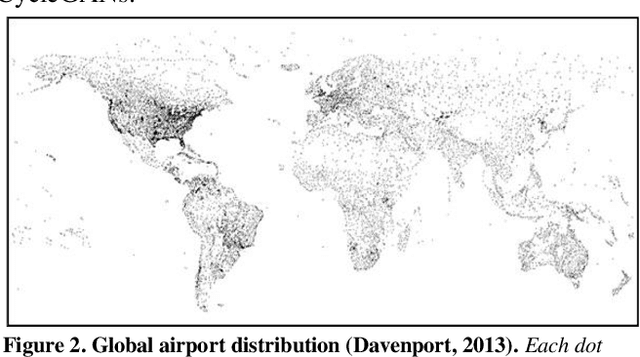
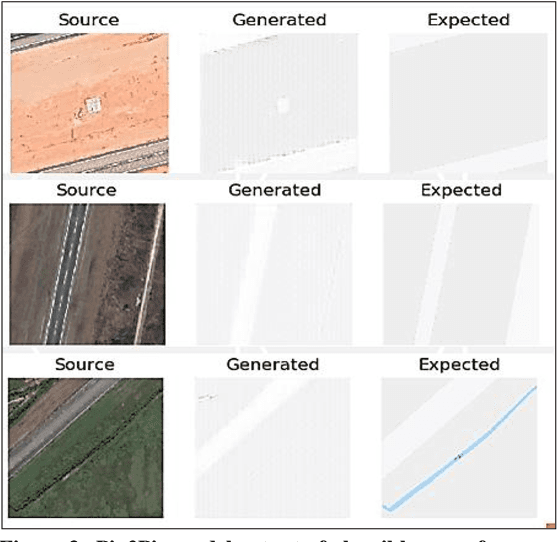

Change detection methods applied to monitoring key infrastructure like airport runways represent an important capability for disaster relief and urban planning. The present work identifies two generative adversarial networks (GAN) architectures that translate reversibly between plausible runway maps and satellite imagery. We illustrate the training capability using paired images (satellite-map) from the same point of view and using the Pix2Pix architecture or conditional GANs. In the absence of available pairs, we likewise show that CycleGAN architectures with four network heads (discriminator-generator pairs) can also provide effective style transfer from raw image pixels to outline or feature maps. To emphasize the runway and tarmac boundaries, we experimentally show that the traditional grey-tan map palette is not a required training input but can be augmented by higher contrast mapping palettes (red-black) for sharper runway boundaries. We preview a potentially novel use case (called "sketch2satellite") where a human roughly draws the current runway boundaries and automates the machine output of plausible satellite images. Finally, we identify examples of faulty runway maps where the published satellite and mapped runways disagree but an automated update renders the correct map using GANs.
SIDOD: A Synthetic Image Dataset for 3D Object Pose Recognition with Distractors
Aug 12, 2020


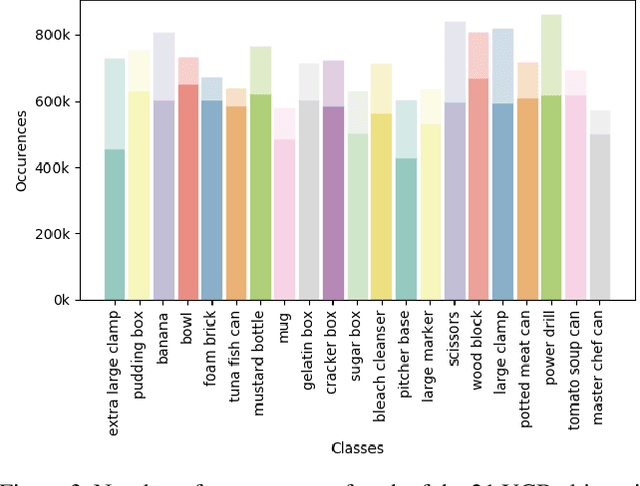
We present a new, publicly-available image dataset generated by the NVIDIA Deep Learning Data Synthesizer intended for use in object detection, pose estimation, and tracking applications. This dataset contains 144k stereo image pairs that synthetically combine 18 camera viewpoints of three photorealistic virtual environments with up to 10 objects (chosen randomly from the 21 object models of the YCB dataset [1]) and flying distractors. Object and camera pose, scene lighting, and quantity of objects and distractors were randomized. Each provided view includes RGB, depth, segmentation, and surface normal images, all pixel level. We describe our approach for domain randomization and provide insight into the decisions that produced the dataset.
Distractor-Aware Neuron Intrinsic Learning for Generic 2D Medical Image Classifications
Jul 20, 2020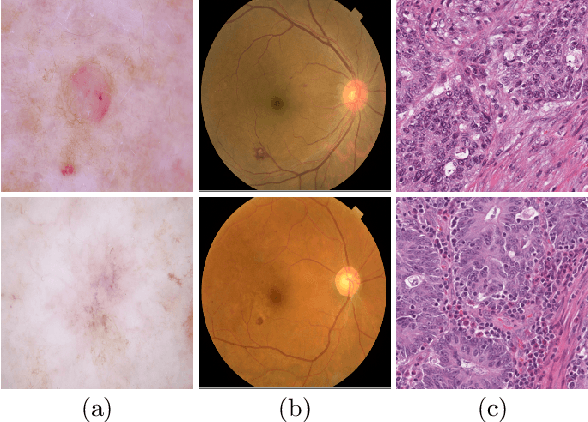
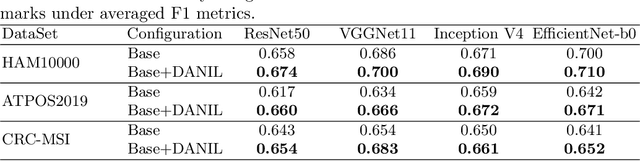
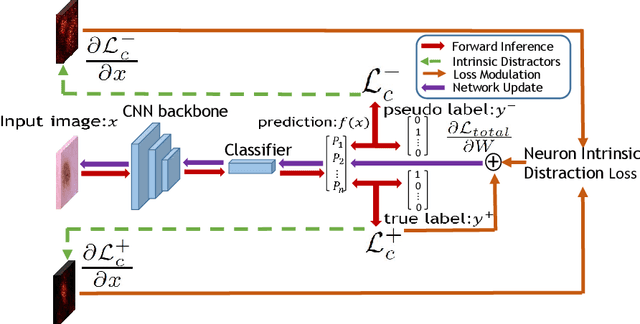
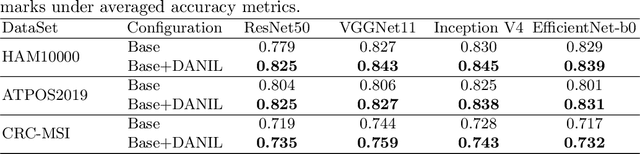
Medical image analysis benefits Computer Aided Diagnosis (CADx). A fundamental analyzing approach is the classification of medical images, which serves for skin lesion diagnosis, diabetic retinopathy grading, and cancer classification on histological images. When learning these discriminative classifiers, we observe that the convolutional neural networks (CNNs) are vulnerable to distractor interference. This is due to the similar sample appearances from different categories (i.e., small inter-class distance). Existing attempts select distractors from input images by empirically estimating their potential effects to the classifier. The essences of how these distractors affect CNN classification are not known. In this paper, we explore distractors from the CNN feature space via proposing a neuron intrinsic learning method. We formulate a novel distractor-aware loss that encourages large distance between the original image and its distractor in the feature space. The novel loss is combined with the original classification loss to update network parameters by back-propagation. Neuron intrinsic learning first explores distractors crucial to the deep classifier and then uses them to robustify CNN inherently. Extensive experiments on medical image benchmark datasets indicate that the proposed method performs favorably against the state-of-the-art approaches.
Boosting segmentation with weak supervision from image-to-image translation
Apr 04, 2019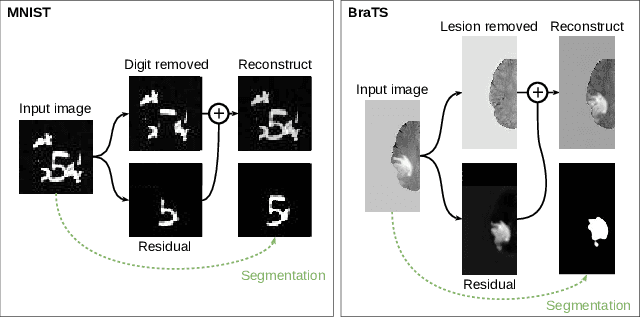

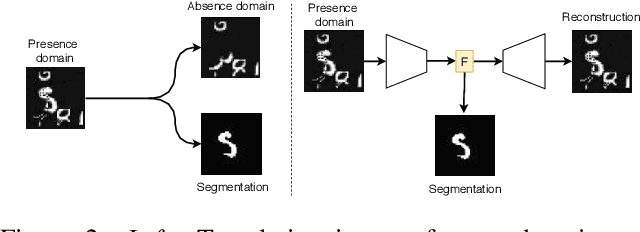
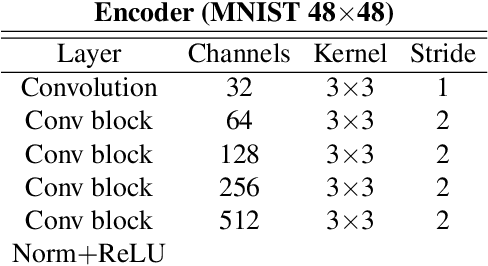
In many cases, especially with medical images, it is prohibitively challenging to produce a sufficiently large training sample of pixel-level annotations to train deep neural networks for semantic image segmentation. On the other hand, some information is often known about the contents of images. We leverage information on whether an image presents the segmentation target or whether it is absent from the image to improve segmentation performance by augmenting the amount of data usable for model training. Specifically, we propose a semi-supervised framework that employs image-to-image translation between weak labels (e.g., presence vs. absence of cancer), in addition to fully supervised segmentation on some examples. We conjecture that this translation objective is well aligned with the segmentation objective as both require the same disentangling of image variations. Building on prior image-to-image translation work, we re-use the encoder and decoders for translating in either direction between two domains, employing a strategy of selectively decoding domain-specific variations. For presence vs. absence domains, the encoder produces variations that are common to both and those unique to the presence domain. Furthermore, we successfully re-use one of the decoders used in translation for segmentation. We validate the proposed method on synthetic tasks of varying difficulty as well as on the real task of brain tumor segmentation in magnetic resonance images, where we show significant improvements over standard semi-supervised training with autoencoding.
Hotel Recognition via Latent Image Embedding
Jun 15, 2021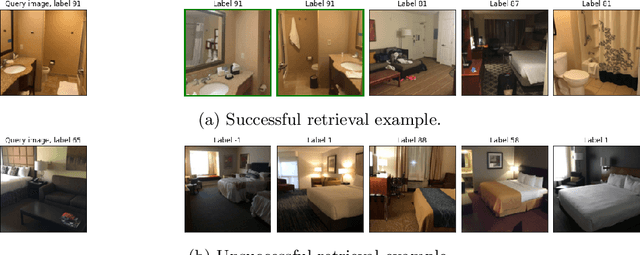
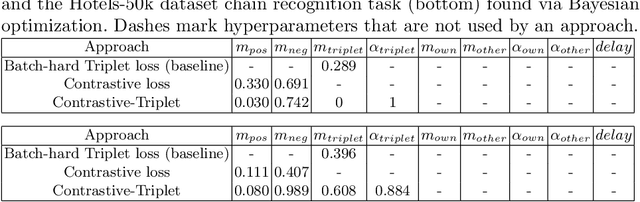
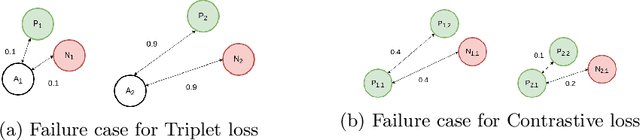
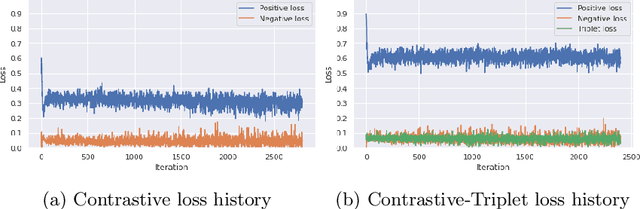
We approach the problem of hotel recognition with deep metric learning. We overview the existing approaches and propose a modification to Contrastive loss called Contrastive-Triplet loss. We construct a robust pipeline for benchmarking metric learning models and perform experiments on Hotels-50K and CUB200 datasets. Contrastive-Triplet loss is shown to achieve better retrieval on Hotels-50k. We open-source our code.
Contrastive Counterfactual Visual Explanations With Overdetermination
Jun 28, 2021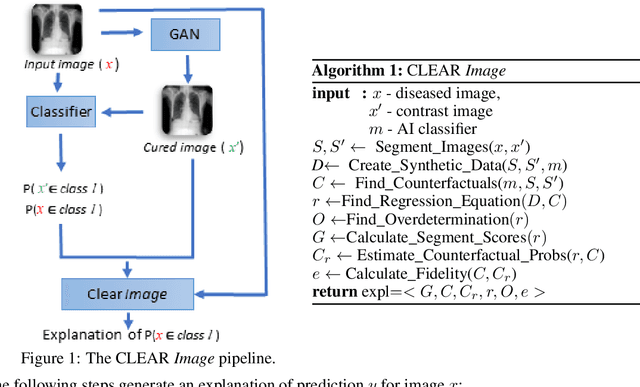
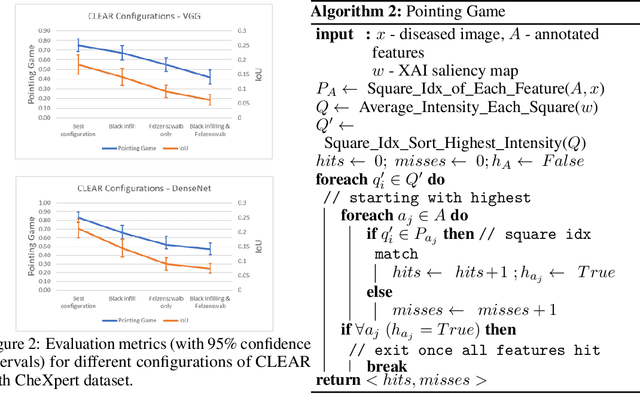

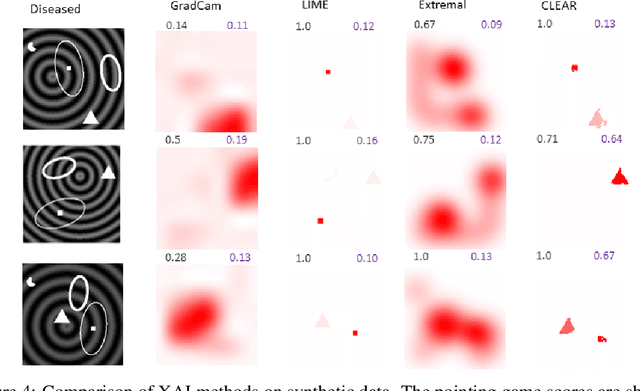
A novel explainable AI method called CLEAR Image is introduced in this paper. CLEAR Image is based on the view that a satisfactory explanation should be contrastive, counterfactual and measurable. CLEAR Image explains an image's classification probability by contrasting the image with a corresponding image generated automatically via adversarial learning. This enables both salient segmentation and perturbations that faithfully determine each segment's importance. CLEAR Image was successfully applied to a medical imaging case study where it outperformed methods such as Grad-CAM and LIME by an average of 27% using a novel pointing game metric. CLEAR Image excels in identifying cases of "causal overdetermination" where there are multiple patches in an image, any one of which is sufficient by itself to cause the classification probability to be close to one.
A State-of-the-art Survey of Artificial Neural Networks for Whole-slide Image Analysis:from Popular Convolutional Neural Networks to Potential Visual Transformers
May 04, 2021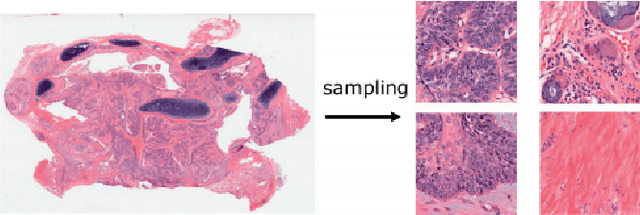
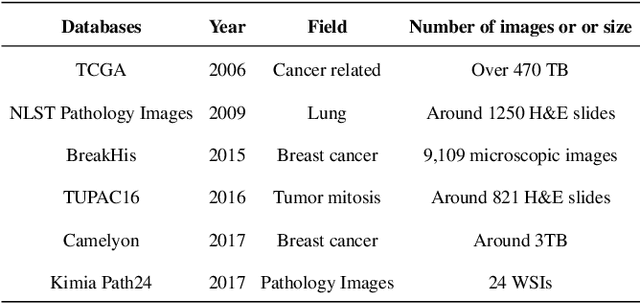
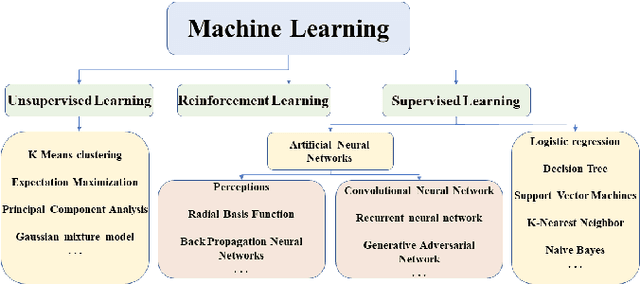

In recent years, with the advancement of computer-aided diagnosis (CAD) technology and whole slide image (WSI), histopathological WSI has gradually played a crucial aspect in the diagnosis and analysis of diseases. To increase the objectivity and accuracy of pathologists' work, artificial neural network (ANN) methods have been generally needed in the segmentation, classification, and detection of histopathological WSI. In this paper, WSI analysis methods based on ANN are reviewed. Firstly, the development status of WSI and ANN methods is introduced. Secondly, we summarize the common ANN methods. Next, we discuss publicly available WSI datasets and evaluation metrics. These ANN architectures for WSI processing are divided into classical neural networks and deep neural networks (DNNs) and then analyzed. Finally, the application prospect of the analytical method in this field is discussed. The important potential method is Visual Transformers.
DreamerPro: Reconstruction-Free Model-Based Reinforcement Learning with Prototypical Representations
Oct 27, 2021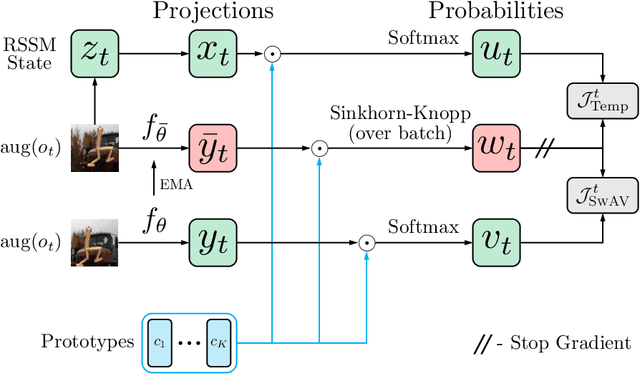
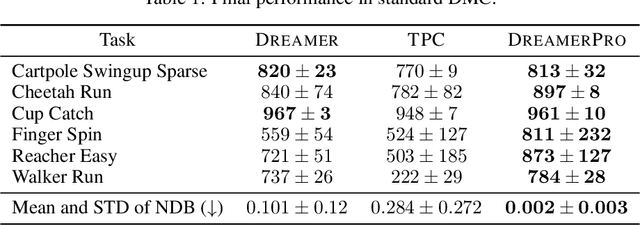
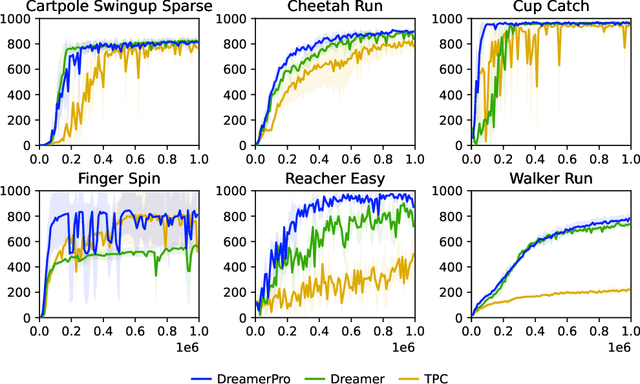

Top-performing Model-Based Reinforcement Learning (MBRL) agents, such as Dreamer, learn the world model by reconstructing the image observations. Hence, they often fail to discard task-irrelevant details and struggle to handle visual distractions. To address this issue, previous work has proposed to contrastively learn the world model, but the performance tends to be inferior in the absence of distractions. In this paper, we seek to enhance robustness to distractions for MBRL agents. Specifically, we consider incorporating prototypical representations, which have yielded more accurate and robust results than contrastive approaches in computer vision. However, it remains elusive how prototypical representations can benefit temporal dynamics learning in MBRL, since they treat each image independently without capturing temporal structures. To this end, we propose to learn the prototypes from the recurrent states of the world model, thereby distilling temporal structures from past observations and actions into the prototypes. The resulting model, DreamerPro, successfully combines Dreamer with prototypes, making large performance gains on the DeepMind Control suite both in the standard setting and when there are complex background distractions. Code available at https://github.com/fdeng18/dreamer-pro .
Modeling dynamic target deformation in camera calibration
Oct 14, 2021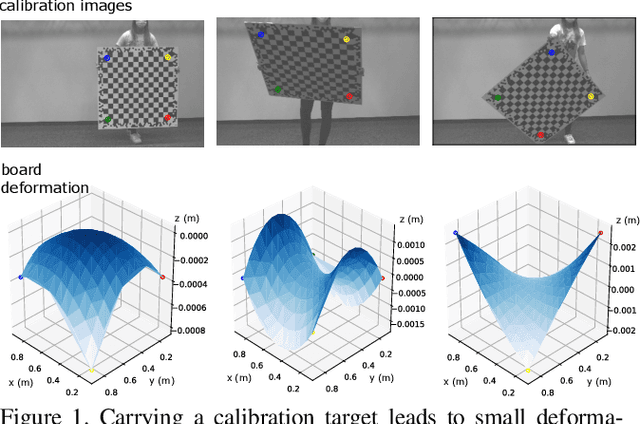
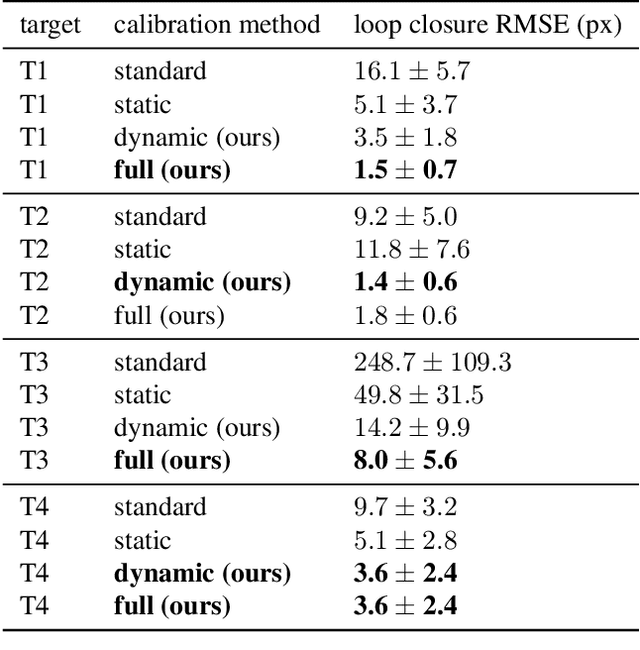
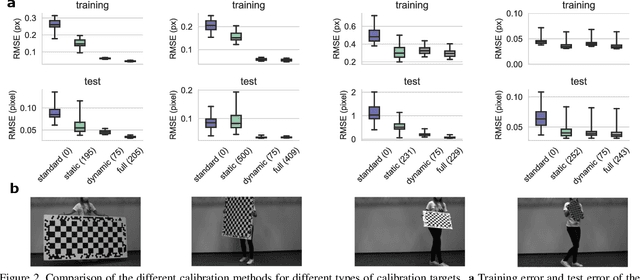
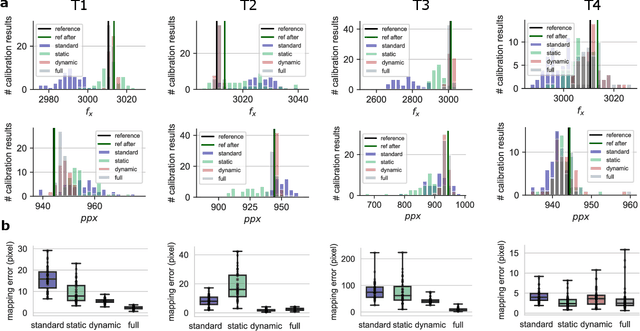
Most approaches to camera calibration rely on calibration targets of well-known geometry. During data acquisition, calibration target and camera system are typically moved w.r.t. each other, to allow image coverage and perspective versatility. We show that moving the target can lead to small temporary deformations of the target, which can introduce significant errors into the calibration result. While static inaccuracies of calibration targets have been addressed in previous works, to our knowledge, none of the existing approaches can capture time-varying, dynamic deformations. To achieve high-accuracy calibrations despite moving the target, we propose a way to explicitly model dynamic target deformations in camera calibration. This is achieved by using a low-dimensional deformation model with only few parameters per image, which can be optimized jointly with target poses and intrinsics. We demonstrate the effectiveness of modeling dynamic deformations using different calibration targets and show its significance in a structure-from-motion application.
A Novel Global Spatial Attention Mechanism in Convolutional Neural Network for Medical Image Classification
Jul 31, 2020

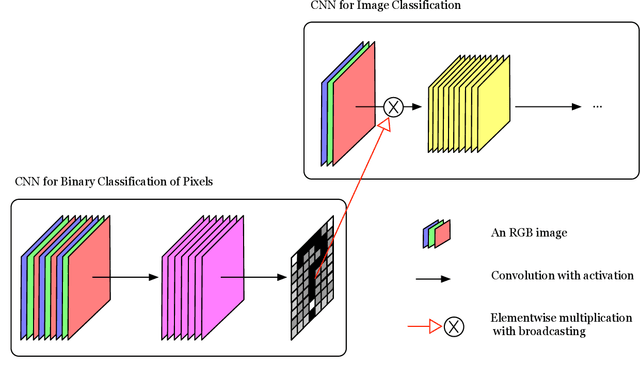
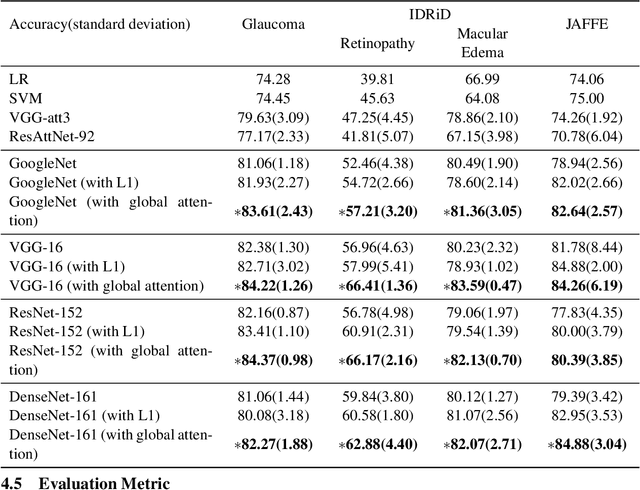
Spatial attention has been introduced to convolutional neural networks (CNNs) for improving both their performance and interpretability in visual tasks including image classification. The essence of the spatial attention is to learn a weight map which represents the relative importance of activations within the same layer or channel. All existing attention mechanisms are local attentions in the sense that weight maps are image-specific. However, in the medical field, there are cases that all the images should share the same weight map because the set of images record the same kind of symptom related to the same object and thereby share the same structural content. In this paper, we thus propose a novel global spatial attention mechanism in CNNs mainly for medical image classification. The global weight map is instantiated by a decision boundary between important pixels and unimportant pixels. And we propose to realize the decision boundary by a binary classifier in which the intensities of all images at a pixel are the features of the pixel. The binary classification is integrated into an image classification CNN and is to be optimized together with the CNN. Experiments on two medical image datasets and one facial expression dataset showed that with the proposed attention, not only the performance of four powerful CNNs which are GoogleNet, VGG, ResNet, and DenseNet can be improved, but also meaningful attended regions can be obtained, which is beneficial for understanding the content of images of a domain.