 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HighEr-Resolution Network for Image Demosaicing and Enhancing
Nov 19, 2019


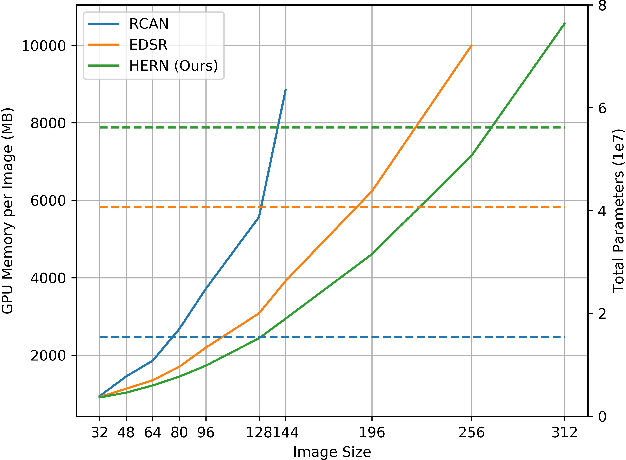
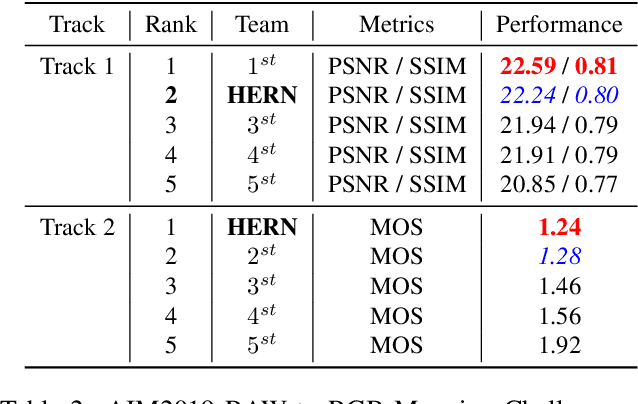
Neural-networks based image restoration methods tend to use low-resolution image patches for training. Although higher-resolution image patches can provide more global information, state-of-the-art methods cannot utilize them due to their huge GPU memory usage, as well as the instable training process. However, plenty of studies have shown that global information is crucial for image restoration tasks like image demosaicing and enhancing. In this work, we propose a HighEr-Resolution Network (HERN) to fully learning global information in high-resolution image patches. To achieve this, the HERN employs two parallel paths to learn image features in two different resolutions, respectively. By combining global-aware features and multi-scale features, our HERN is able to learn global information with feasible GPU memory usage. Besides, we introduce a progressive training method to solve the instability issue and accelerate model convergence. On the task of image demosaicing and enhancing, our HERN achieves state-of-the-art performance on the AIM2019 RAW to RGB mapping challenge. The source code of our implementation is available at https://github.com/MKFMIKU/RAW2RGBNet.
Schema matching using Gaussian mixture models with Wasserstein distance
Nov 28, 2021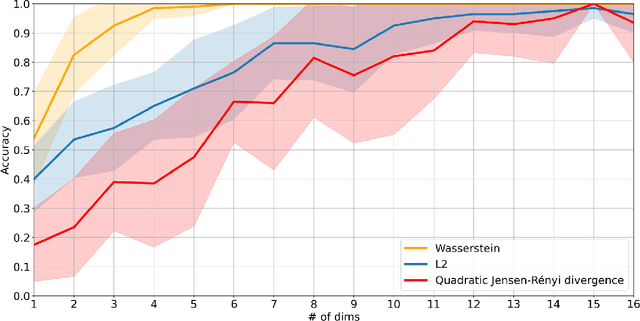
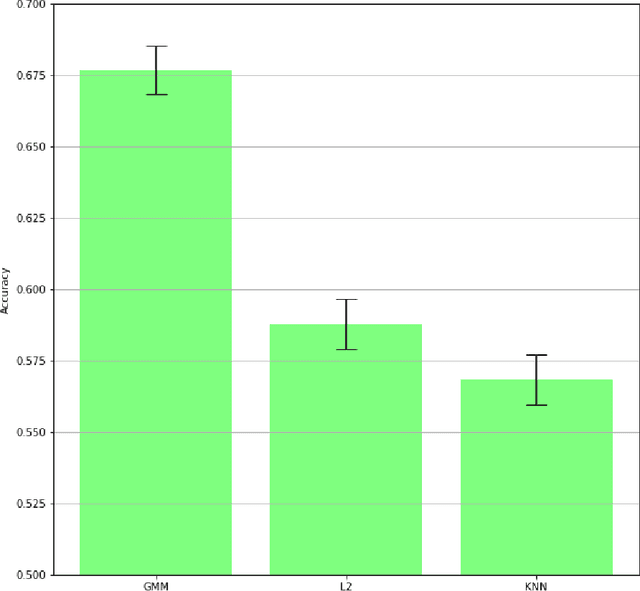
Gaussian mixture models find their place as a powerful tool, mostly in the clustering problem, but with proper preparation also in feature extraction, pattern recognition, image segmentation and in general machine learning. When faced with the problem of schema matching, different mixture models computed on different pieces of data can maintain crucial information about the structure of the dataset. In order to measure or compare results from mixture models, the Wasserstein distance can be very useful, however it is not easy to calculate for mixture distributions. In this paper we derive one of possible approximations for the Wasserstein distance between Gaussian mixture models and reduce it to linear problem. Furthermore, application examples concerning real world data are shown.
Subject-independent Human Pose Image Construction with Commodity Wi-Fi
Dec 22, 2020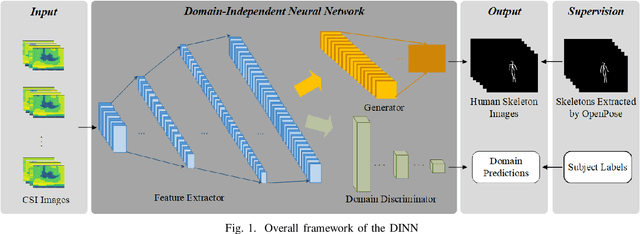

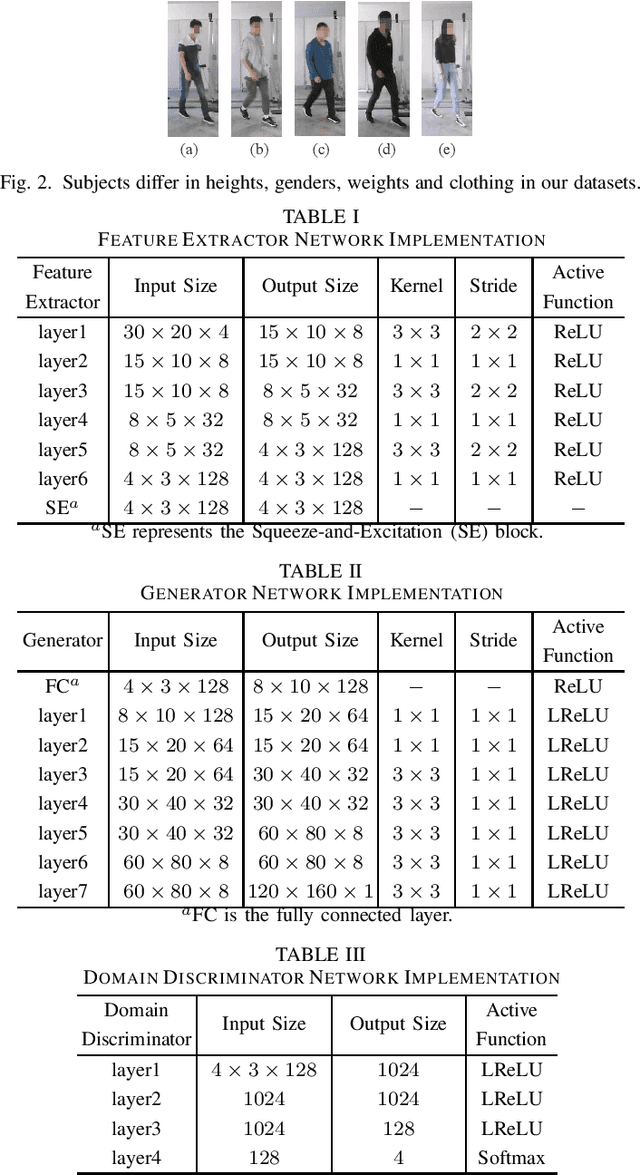
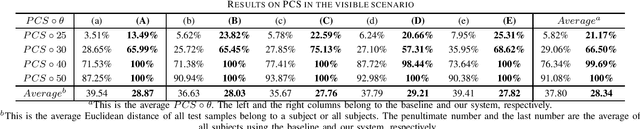
Recently, commodity Wi-Fi devices have been shown to be able to construct human pose images, i.e., human skeletons, as fine-grained as cameras. Existing papers achieve good results when constructing the images of subjects who are in the prior training samples. However, the performance drops when it comes to new subjects, i.e., the subjects who are not in the training samples. This paper focuses on solving the subject-generalization problem in human pose image construction. To this end, we define the subject as the domain. Then we design a Domain-Independent Neural Network (DINN) to extract subject-independent features and convert them into fine-grained human pose images. We also propose a novel training method to train the DINN and it has no re-training overhead comparing with the domain-adversarial approach. We build a prototype system and experimental results demonstrate that our system can construct fine-grained human pose images of new subjects with commodity Wi-Fi in both the visible and through-wall scenarios, which shows the effectiveness and the subject-generalization ability of our model.
Generalized Wasserstein Dice Loss, Test-time Augmentation, and Transformers for the BraTS 2021 challenge
Dec 24, 2021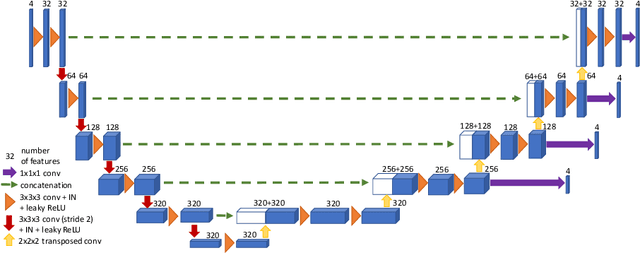
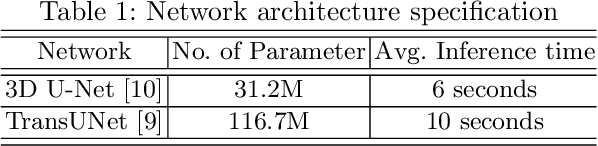
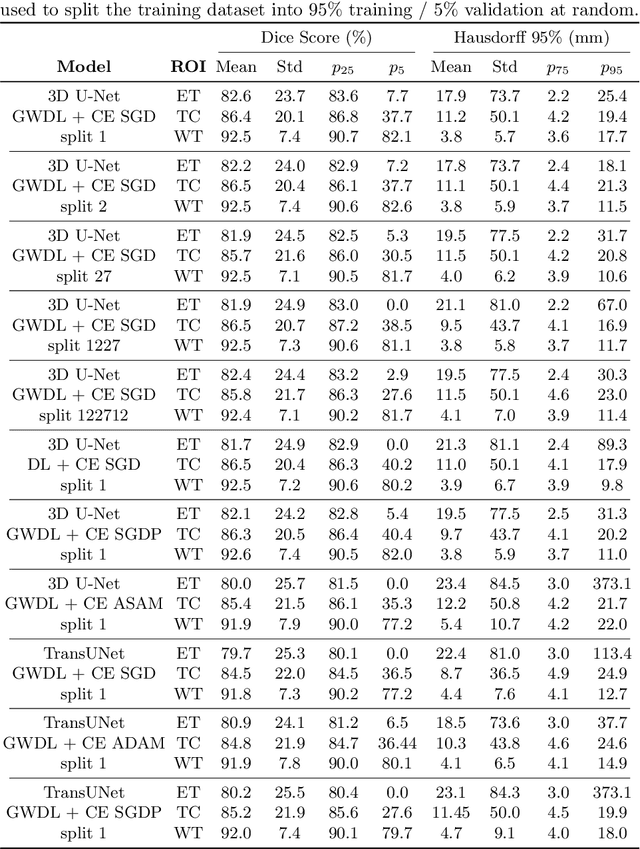
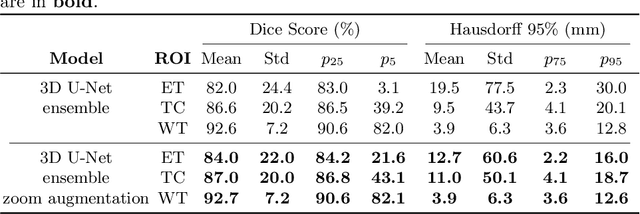
Brain tumor segmentation from multiple Magnetic Resonance Imaging (MRI) modalities is a challenging task in medical image computation. The main challenges lie in the generalizability to a variety of scanners and imaging protocols. In this paper, we explore strategies to increase model robustness without increasing inference time. Towards this aim, we explore finding a robust ensemble from models trained using different losses, optimizers, and train-validation data split. Importantly, we explore the inclusion of a transformer in the bottleneck of the U-Net architecture. While we find transformer in the bottleneck performs slightly worse than the baseline U-Net in average, the generalized Wasserstein Dice loss consistently produces superior results. Further, we adopt an efficient test time augmentation strategy for faster and robust inference. Our final ensemble of seven 3D U-Nets with test-time augmentation produces an average dice score of 89.4% and an average Hausdorff 95% distance of 10.0 mm when evaluated on the BraTS 2021 testing dataset. Our code and trained models are publicly available at https://github.com/LucasFidon/TRABIT_BraTS2021.
Hyperspectral Image Classification with Attention Aided CNNs
Jun 12, 2020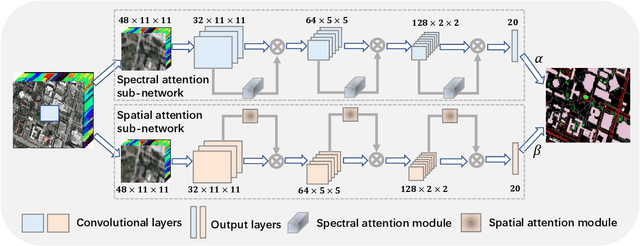
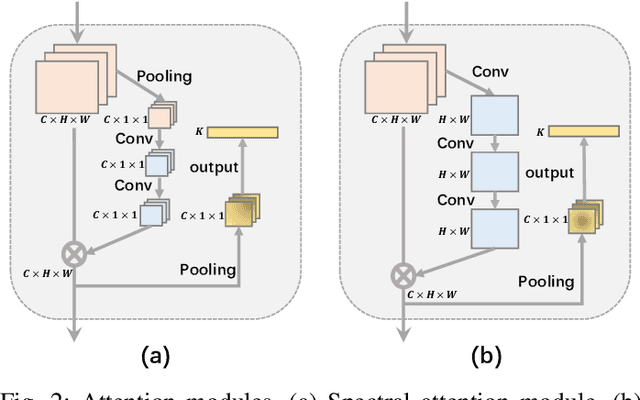

Convolutional neural networks (CNNs) have been widely used for hyperspectral image classification. As a common process, small cubes are firstly cropped from the hyperspectral image and then fed into CNNs to extract spectral and spatial features. It is well known that different spectral bands and spatial positions in the cubes have different discriminative abilities. If fully explored, this prior information will help improve the learning capacity of CNNs. Along this direction, we propose an attention aided CNN model for spectral-spatial classification of hyperspectral images. Specifically, a spectral attention sub-network and a spatial attention sub-network are proposed for spectral and spatial classification, respectively. Both of them are based on the traditional CNN model, and incorporate attention modules to aid networks focus on more discriminative channels or positions. In the final classification phase, the spectral classification result and the spatial classification result are combined together via an adaptively weighted summation method. To evaluate the effectiveness of the proposed model, we conduct experiments on three standard hyperspectral datasets. The experimental results show that the proposed model can achieve superior performance compared to several state-of-the-art CNN-related models.
Reservoir Computing Approach for Gray Images Segmentation
Jul 23, 2021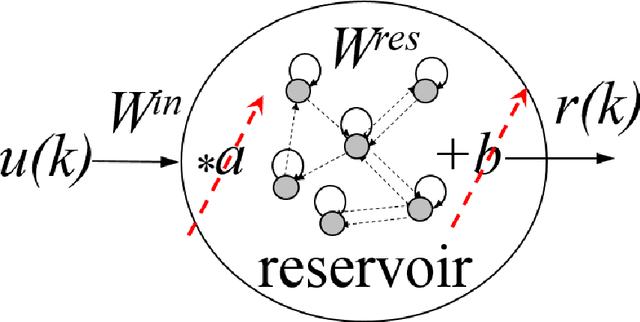
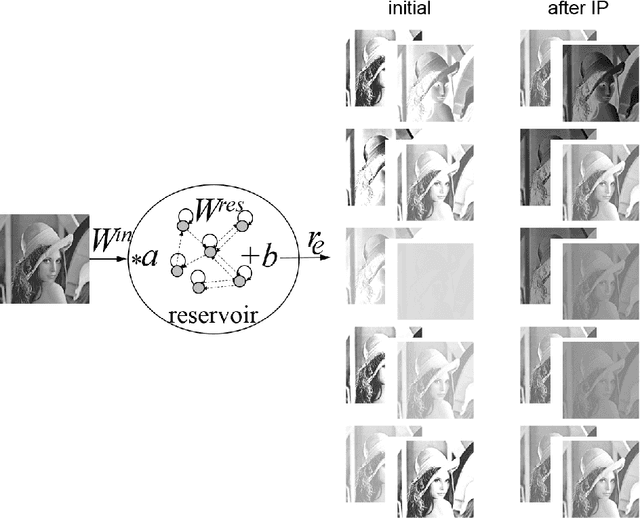
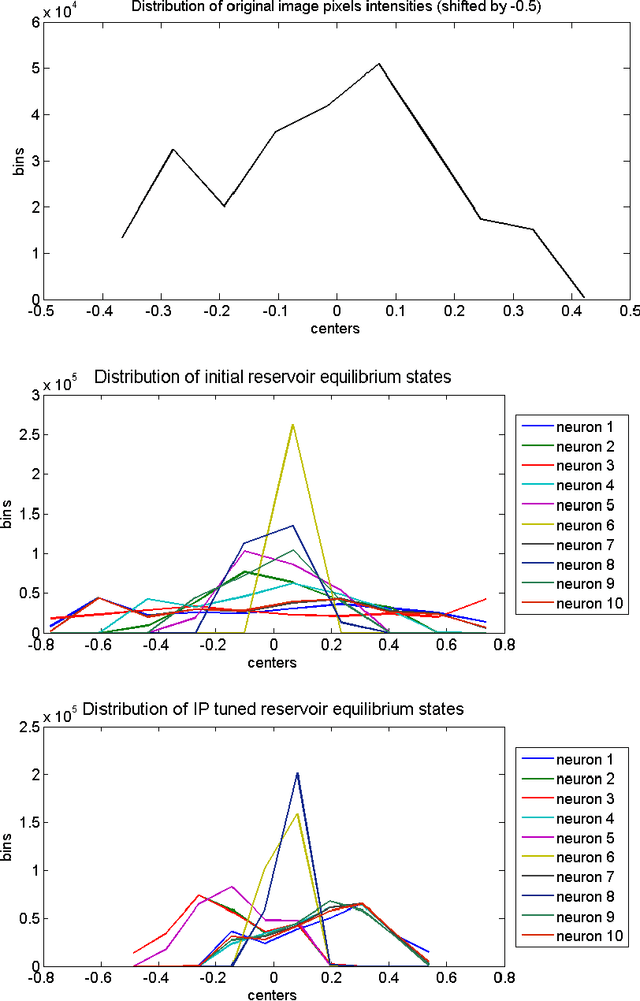

The paper proposes a novel approach for gray scale images segmentation. It is based on multiple features extraction from single feature per image pixel, namely its intensity value, using Echo state network. The newly extracted features -- reservoir equilibrium states -- reveal hidden image characteristics that improve its segmentation via a clustering algorithm. Moreover, it was demonstrated that the intrinsic plasticity tuning of reservoir fits its equilibrium states to the original image intensity distribution thus allowing for its better segmentation. The proposed approach is tested on the benchmark image Lena.
Hyperspectral Image Super-resolution via Deep Spatio-spectral Convolutional Neural Networks
May 29, 2020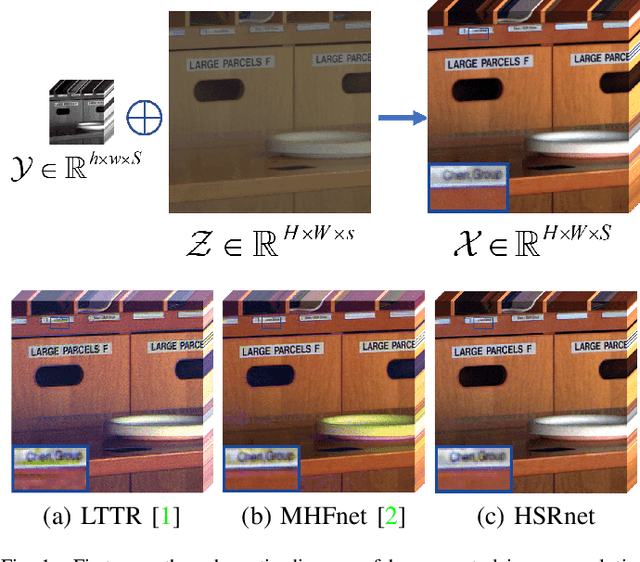

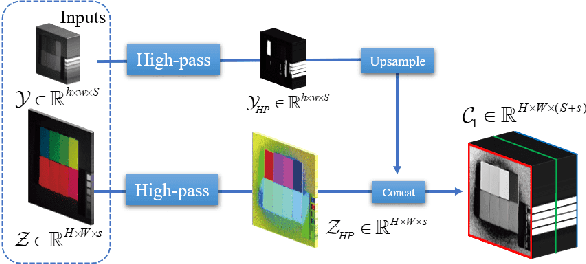
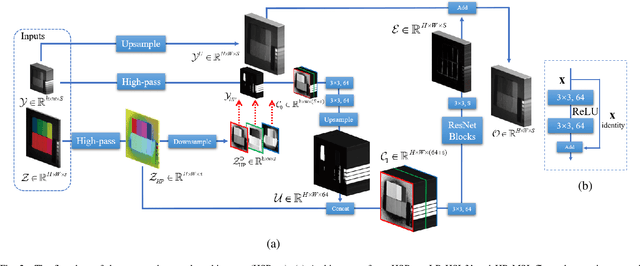
Hyperspectral images are of crucial importance in order to better understand features of different materials. To reach this goal, they leverage on a high number of spectral bands. However, this interesting characteristic is often paid by a reduced spatial resolution compared with traditional multispectral image systems. In order to alleviate this issue, in this work, we propose a simple and efficient architecture for deep convolutional neural networks to fuse a low-resolution hyperspectral image (LR-HSI) and a high-resolution multispectral image (HR-MSI), yielding a high-resolution hyperspectral image (HR-HSI). The network is designed to preserve both spatial and spectral information thanks to an architecture from two folds: one is to utilize the HR-HSI at a different scale to get an output with a satisfied spectral preservation; another one is to apply concepts of multi-resolution analysis to extract high-frequency information, aiming to output high quality spatial details. Finally, a plain mean squared error loss function is used to measure the performance during the training. Extensive experiments demonstrate that the proposed network architecture achieves best performance (both qualitatively and quantitatively) compared with recent state-of-the-art hyperspectral image super-resolution approaches. Moreover, other significant advantages can be pointed out by the use of the proposed approach, such as, a better network generalization ability, a limited computational burden, and a robustness with respect to the number of training samples.
Contrastive Fine-grained Class Clustering via Generative Adversarial Networks
Dec 30, 2021
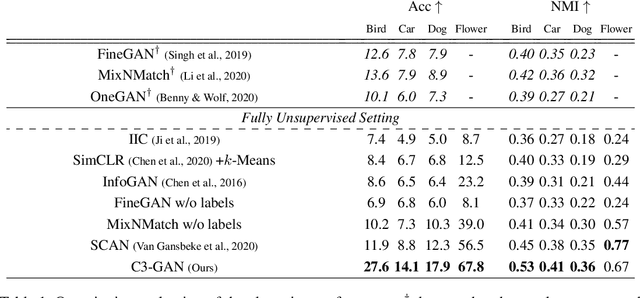
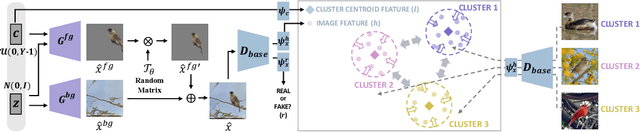

Unsupervised fine-grained class clustering is practical yet challenging task due to the difficulty of feature representations learning of subtle object details. We introduce C3-GAN, a method that leverages the categorical inference power of InfoGAN by applying contrastive learning. We aim to learn feature representations that encourage the data to form distinct cluster boundaries in the embedding space, while also maximizing the mutual information between the latent code and its observation. Our approach is to train the discriminator, which is used for inferring clusters, to optimize the contrastive loss, where the image-latent pairs that maximize the mutual information are considered as positive pairs and the rest as negative pairs. Specifically, we map the input of the generator, which has sampled from the categorical distribution, to the embedding space of the discriminator and let them act as a cluster centroid. In this way, C3-GAN achieved to learn a clustering-friendly embedding space where each cluster is distinctively separable. Experimental results show that C3-GAN achieved state-of-the-art clustering performance on four fine-grained benchmark datasets, while also alleviating the mode collapse phenomenon.
Producing augmentation-invariant embeddings from real-life imagery
Dec 06, 2021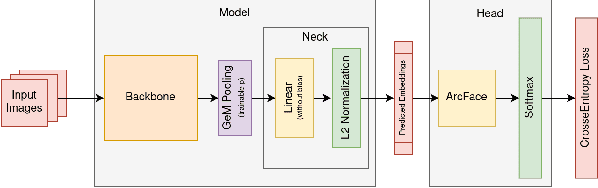
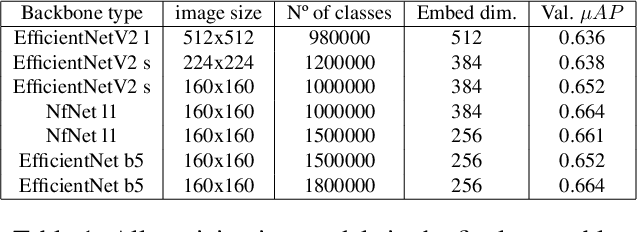


This article presents an efficient way to produce feature-rich, high-dimensionality embedding spaces from real-life images. The features produced are designed to be independent from augmentations used in real-life cases which appear on social media. Our approach uses convolutional neural networks (CNN) to produce an embedding space. An ArcFace head was used to train the model by employing automatically produced augmentations. Additionally, we present a way to make an ensemble out of different embeddings containing the same semantic information, a way to normalize the resulting embedding using an external dataset, and a novel way to perform quick training of these models with a high number of classes in the ArcFace head. Using this approach we achieved the 2nd place in the 2021 Facebook AI Image Similarity Challenge: Descriptor Track.
Boosting segmentation with weak supervision from image-to-image translation
Apr 04, 2019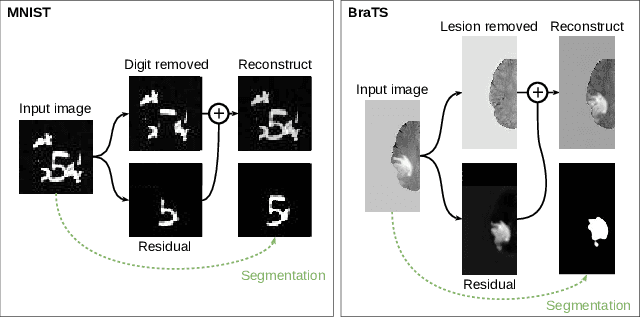

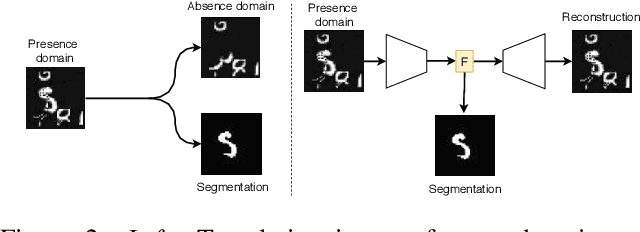
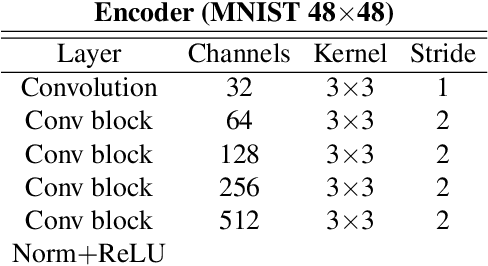
In many cases, especially with medical images, it is prohibitively challenging to produce a sufficiently large training sample of pixel-level annotations to train deep neural networks for semantic image segmentation. On the other hand, some information is often known about the contents of images. We leverage information on whether an image presents the segmentation target or whether it is absent from the image to improve segmentation performance by augmenting the amount of data usable for model training. Specifically, we propose a semi-supervised framework that employs image-to-image translation between weak labels (e.g., presence vs. absence of cancer), in addition to fully supervised segmentation on some examples. We conjecture that this translation objective is well aligned with the segmentation objective as both require the same disentangling of image variations. Building on prior image-to-image translation work, we re-use the encoder and decoders for translating in either direction between two domains, employing a strategy of selectively decoding domain-specific variations. For presence vs. absence domains, the encoder produces variations that are common to both and those unique to the presence domain. Furthermore, we successfully re-use one of the decoders used in translation for segmentation. We validate the proposed method on synthetic tasks of varying difficulty as well as on the real task of brain tumor segmentation in magnetic resonance images, where we show significant improvements over standard semi-supervised training with autoencoding.