 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Update in Unit Gradient
Oct 01, 2021
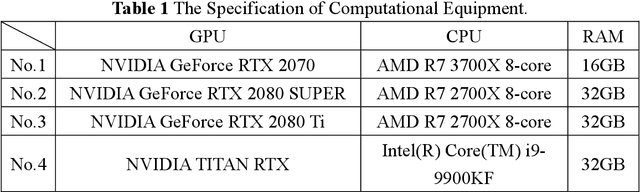
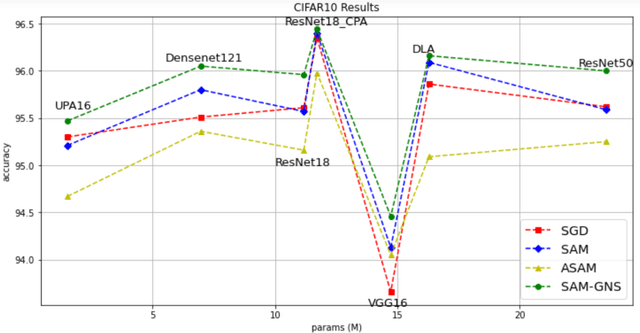
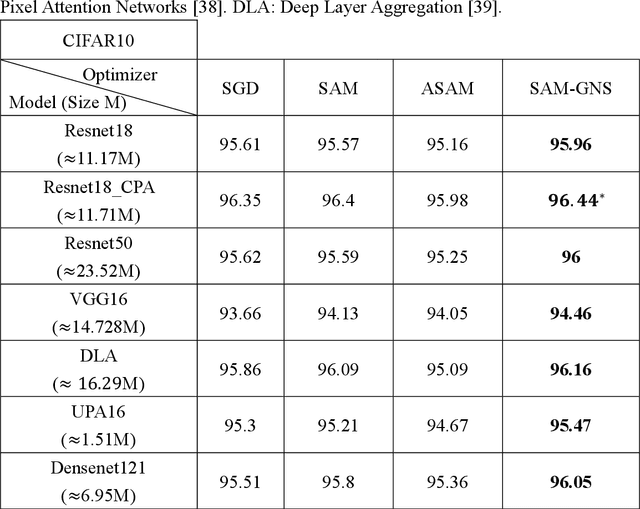
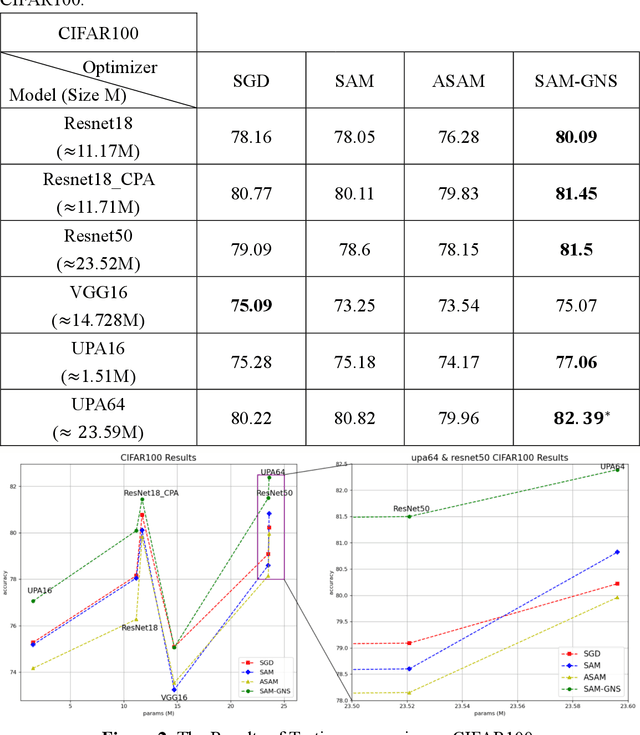
In Machine Learning, optimization mostly has been done by using a gradient descent method to find the minimum value of the loss. However, especially in deep learning, finding a global minimum from a nonconvex loss function across a high dimensional space is an extraordinarily difficult task. Recently, a generalization learning algorithm, Sharpness-Aware Minimization (SAM), has made a great success in image classification task. Despite the great performance in creating convex space, proper direction leading by SAM is still remained unclear. We, thereby, propose a creating a Unit Vector space in SAM, which not only consisted of the mathematical instinct in linear algebra but also kept the advantages of adaptive gradient algorithm. Moreover, applying SAM in unit gradient brings models competitive performances in image classification datasets, such as CIFAR - {10, 100}. The experiment showed that it performed even better and more robust than SAM.
Multi-Expert Adversarial Attack Detection in Person Re-identification Using Context Inconsistency
Aug 23, 2021
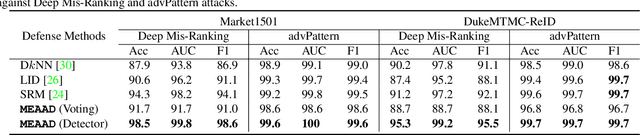
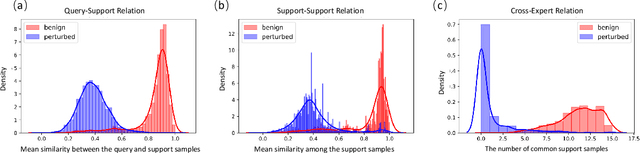

The success of deep neural networks (DNNs) haspromoted the widespread applications of person re-identification (ReID). However, ReID systems inherit thevulnerability of DNNs to malicious attacks of visually in-conspicuous adversarial perturbations. Detection of adver-sarial attacks is, therefore, a fundamental requirement forrobust ReID systems. In this work, we propose a Multi-Expert Adversarial Attack Detection (MEAAD) approach toachieve this goal by checking context inconsistency, whichis suitable for any DNN-based ReID systems. Specifically,three kinds of context inconsistencies caused by adversar-ial attacks are employed to learn a detector for distinguish-ing the perturbed examples, i.e., a) the embedding distancesbetween a perturbed query person image and its top-K re-trievals are generally larger than those between a benignquery image and its top-K retrievals, b) the embedding dis-tances among the top-K retrievals of a perturbed query im-age are larger than those of a benign query image, c) thetop-K retrievals of a benign query image obtained with mul-tiple expert ReID models tend to be consistent, which isnot preserved when attacks are present. Extensive exper-iments on the Market1501 and DukeMTMC-ReID datasetsshow that, as the first adversarial attack detection approachfor ReID,MEAADeffectively detects various adversarial at-tacks and achieves high ROC-AUC (over 97.5%).
Composition-Aware Image Aesthetics Assessment
Jul 25, 2019



Automatic image aesthetics assessment is important for a wide variety of applications such as on-line photo suggestion, photo album management and image retrieval. Previous methods have focused on mapping the holistic image content to a high or low aesthetics rating. However, the composition information of an image characterizes the harmony of its visual elements according to the principles of art, and provides richer information for learning aesthetics. In this work, we propose to model the image composition information as the mutual dependency of its local regions, and design a novel architecture to leverage such information to boost the performance of aesthetics assessment. To achieve this, we densely partition an image into local regions and compute aesthetics-preserving features over the regions to characterize the aesthetics properties of image content. With the feature representation of local regions, we build a region composition graph in which each node denotes one region and any two nodes are connected by an edge weighted by the similarity of the region features. We perform reasoning on this graph via graph convolution, in which the activation of each node is determined by its highly correlated neighbors. Our method naturally uncovers the mutual dependency of local regions in the network training procedure, and achieves the state-of-the-art performance on the benchmark visual aesthetics datasets.
Human Performance Capture from Monocular Video in the Wild
Nov 30, 2021
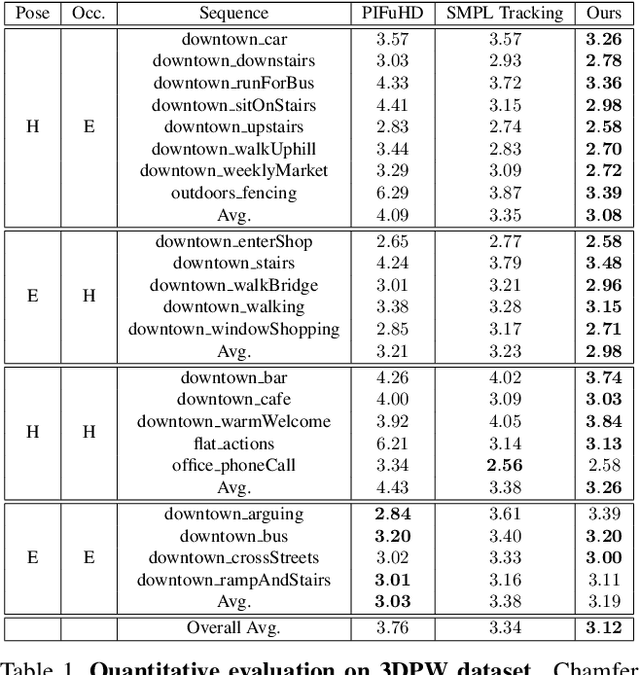
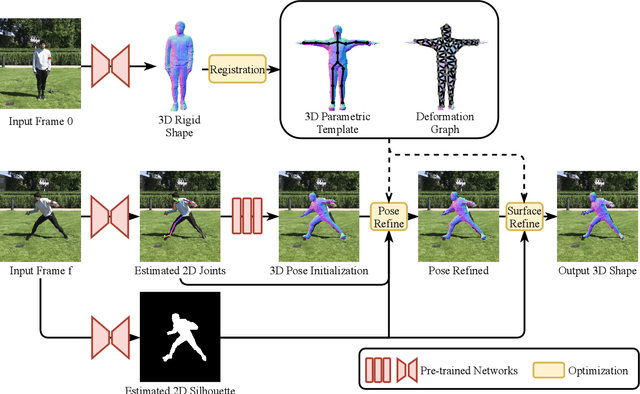
Capturing the dynamically deforming 3D shape of clothed human is essential for numerous applications, including VR/AR, autonomous driving, and human-computer interaction. Existing methods either require a highly specialized capturing setup, such as expensive multi-view imaging systems, or they lack robustness to challenging body poses. In this work, we propose a method capable of capturing the dynamic 3D human shape from a monocular video featuring challenging body poses, without any additional input. We first build a 3D template human model of the subject based on a learned regression model. We then track this template model's deformation under challenging body articulations based on 2D image observations. Our method outperforms state-of-the-art methods on an in-the-wild human video dataset 3DPW. Moreover, we demonstrate its efficacy in robustness and generalizability on videos from iPER datasets.
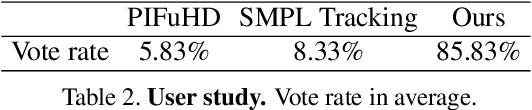
Weakly Supervised High-Fidelity Clothing Model Generation
Dec 14, 2021
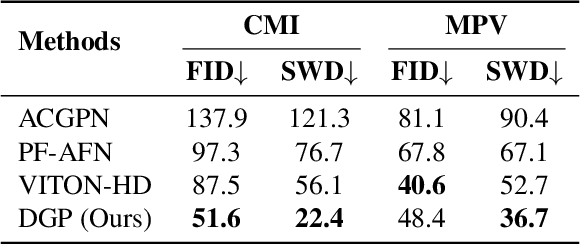
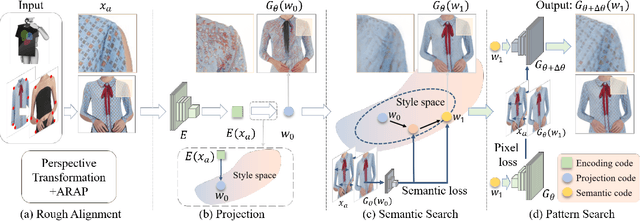

The development of online economics arouses the demand of generating images of models on product clothes, to display new clothes and promote sales. However, the expensive proprietary model images challenge the existing image virtual try-on methods in this scenario, as most of them need to be trained on considerable amounts of model images accompanied with paired clothes images. In this paper, we propose a cheap yet scalable weakly-supervised method called Deep Generative Projection (DGP) to address this specific scenario. Lying in the heart of the proposed method is to imitate the process of human predicting the wearing effect, which is an unsupervised imagination based on life experience rather than computation rules learned from supervisions. Here a pretrained StyleGAN is used to capture the practical experience of wearing. Experiments show that projecting the rough alignment of clothing and body onto the StyleGAN space can yield photo-realistic wearing results. Experiments on real scene proprietary model images demonstrate the superiority of DGP over several state-of-the-art supervised methods when generating clothing model images.
FPGA: Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification
Nov 11, 2020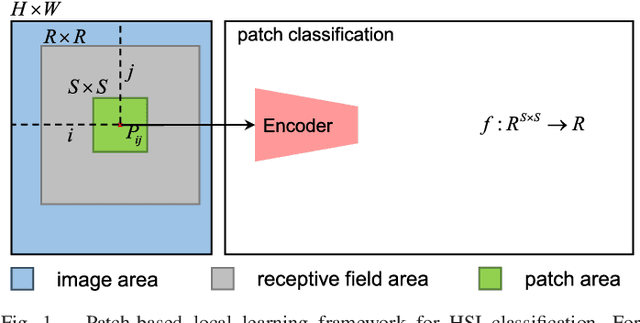

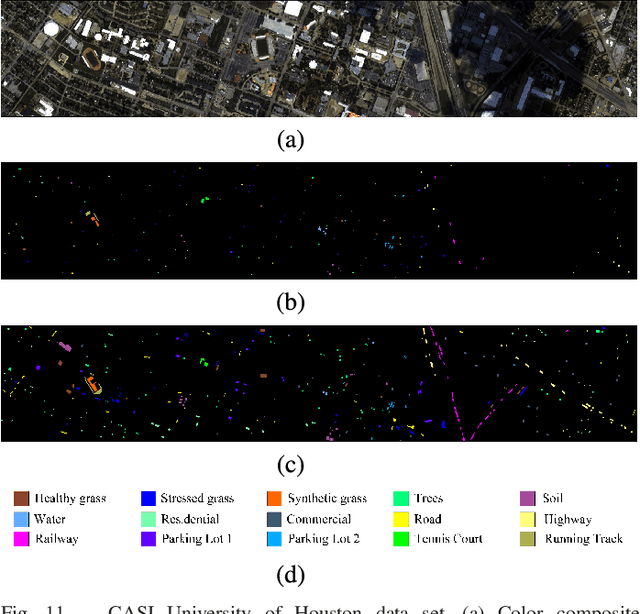
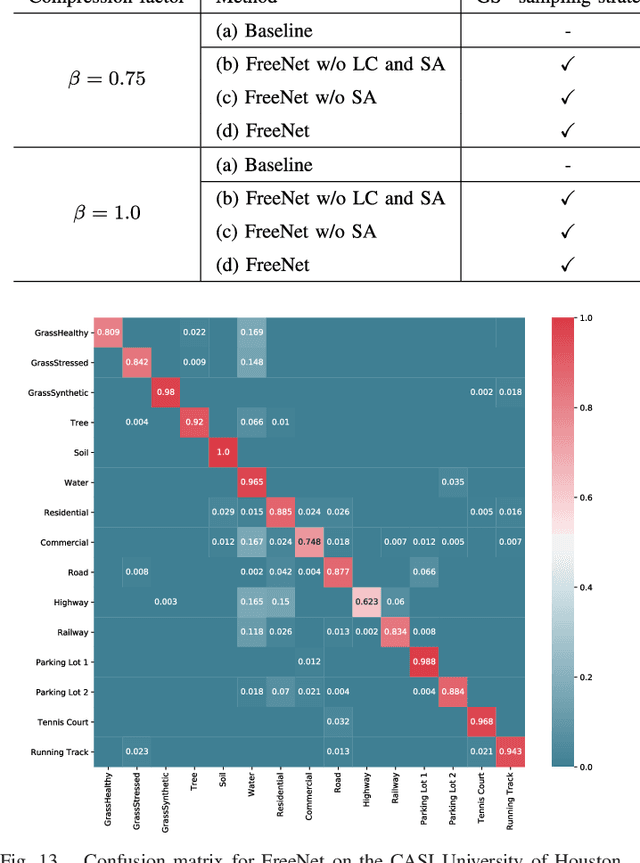
Deep learning techniques have provided significant improvements in hyperspectral image (HSI) classification. The current deep learning based HSI classifiers follow a patch-based learning framework by dividing the image into overlapping patches. As such, these methods are local learning methods, which have a high computational cost. In this paper, a fast patch-free global learning (FPGA) framework is proposed for HSI classification. In FPGA, an encoder-decoder based FCN is utilized to consider the global spatial information by processing the whole image, which results in fast inference. However, it is difficult to directly utilize the encoder-decoder based FCN for HSI classification as it always fails to converge due to the insufficiently diverse gradients caused by the limited training samples. To solve the divergence problem and maintain the abilities of FCN of fast inference and global spatial information mining, a global stochastic stratified sampling strategy is first proposed by transforming all the training samples into a stochastic sequence of stratified samples. This strategy can obtain diverse gradients to guarantee the convergence of the FCN in the FPGA framework. For a better design of FCN architecture, FreeNet, which is a fully end-to-end network for HSI classification, is proposed to maximize the exploitation of the global spatial information and boost the performance via a spectral attention based encoder and a lightweight decoder. A lateral connection module is also designed to connect the encoder and decoder, fusing the spatial details in the encoder and the semantic features in the decoder. The experimental results obtained using three public benchmark datasets suggest that the FPGA framework is superior to the patch-based framework in both speed and accuracy for HSI classification. Code has been made available at: https://github.com/Z-Zheng/FreeNet.
Towards Unsupervised Open World Semantic Segmentation
Jan 04, 2022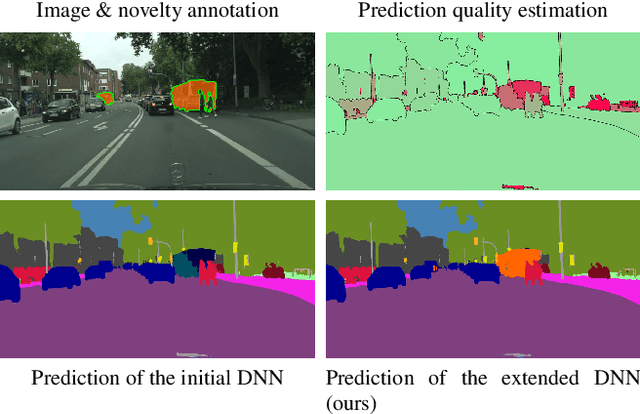
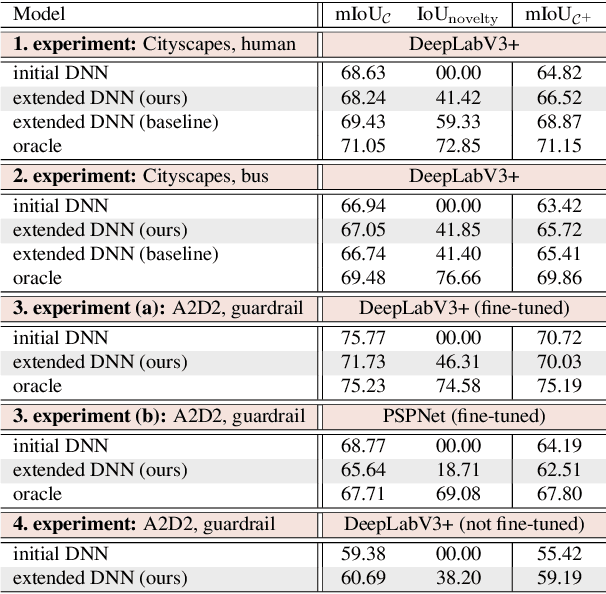
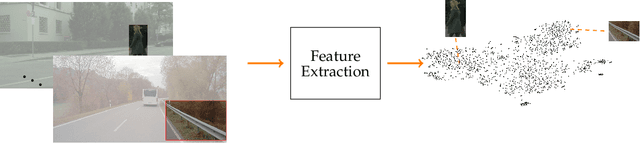
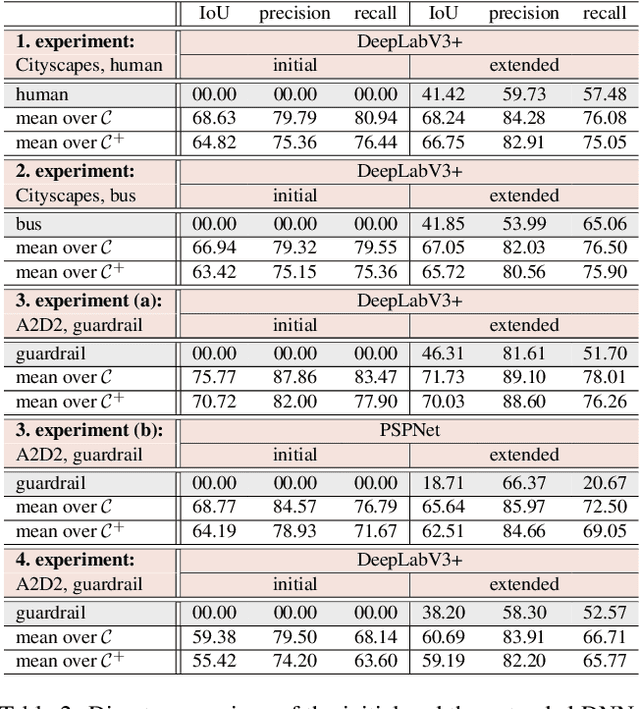
For the semantic segmentation of images, state-of-the-art deep neural networks (DNNs) achieve high segmentation accuracy if that task is restricted to a closed set of classes. However, as of now DNNs have limited ability to operate in an open world, where they are tasked to identify pixels belonging to unknown objects and eventually to learn novel classes, incrementally. Humans have the capability to say: I don't know what that is, but I've already seen something like that. Therefore, it is desirable to perform such an incremental learning task in an unsupervised fashion. We introduce a method where unknown objects are clustered based on visual similarity. Those clusters are utilized to define new classes and serve as training data for unsupervised incremental learning. More precisely, the connected components of a predicted semantic segmentation are assessed by a segmentation quality estimate. connected components with a low estimated prediction quality are candidates for a subsequent clustering. Additionally, the component-wise quality assessment allows for obtaining predicted segmentation masks for the image regions potentially containing unknown objects. The respective pixels of such masks are pseudo-labeled and afterwards used for re-training the DNN, i.e., without the use of ground truth generated by humans. In our experiments we demonstrate that, without access to ground truth and even with few data, a DNN's class space can be extended by a novel class, achieving considerable segmentation accuracy.
Efficient Image Gallery Representations at Scale Through Multi-Task Learning
May 25, 2020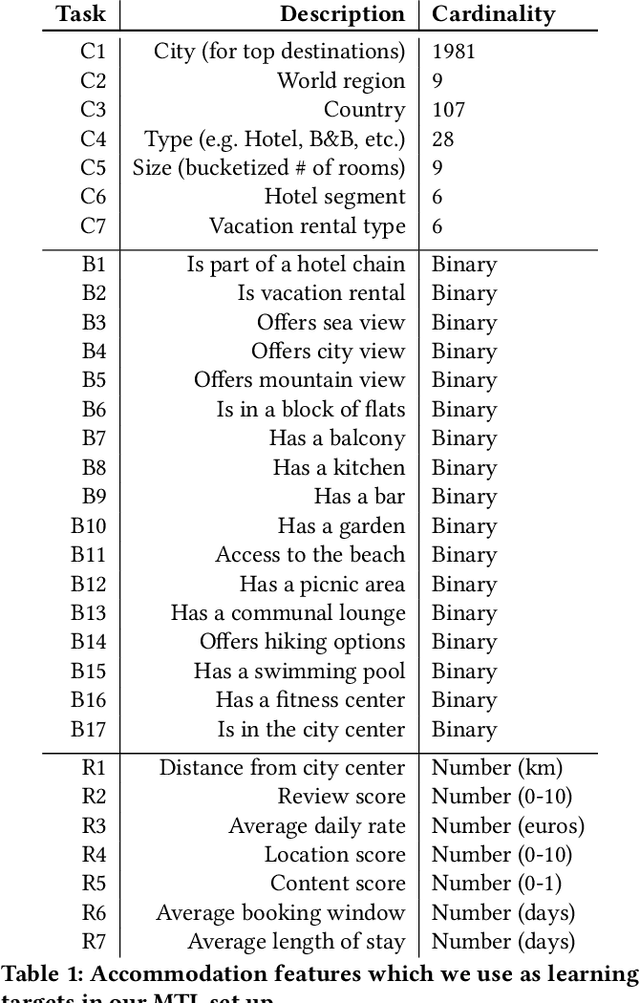

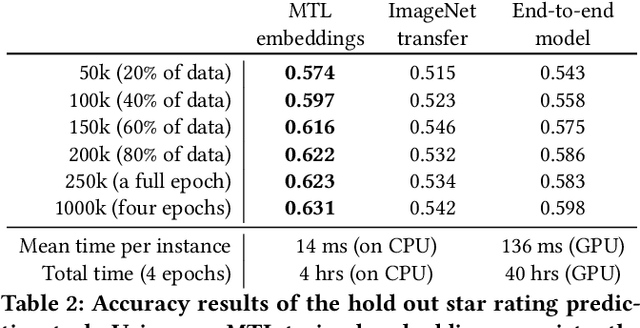
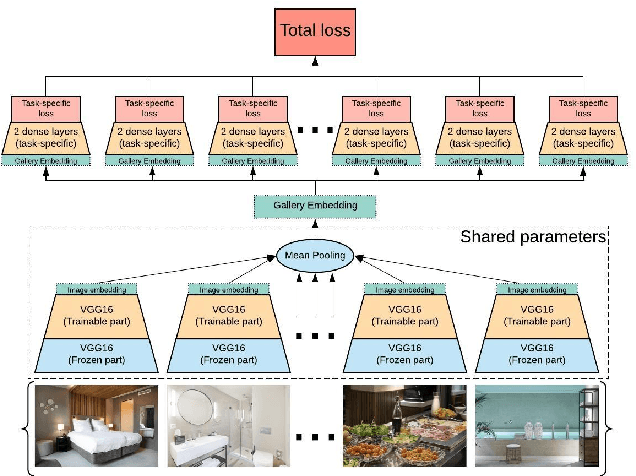
Image galleries provide a rich source of diverse information about a product which can be leveraged across many recommendation and retrieval applications. We study the problem of building a universal image gallery encoder through multi-task learning (MTL) approach and demonstrate that it is indeed a practical way to achieve generalizability of learned representations to new downstream tasks. Additionally, we analyze the relative predictive performance of MTL-trained solutions against optimal and substantially more expensive solutions, and find signals that MTL can be a useful mechanism to address sparsity in low-resource binary tasks.
Learning Generalizable Vision-Tactile Robotic Grasping Strategy for Deformable Objects via Transformer
Dec 20, 2021

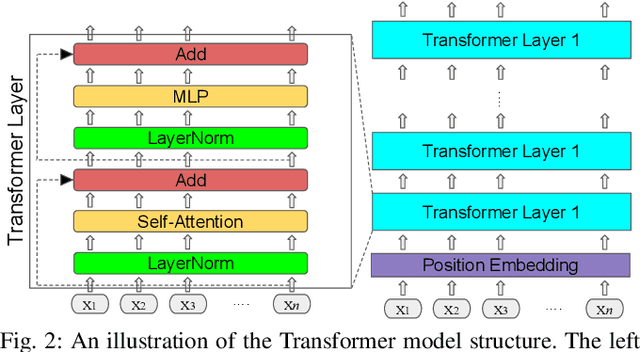
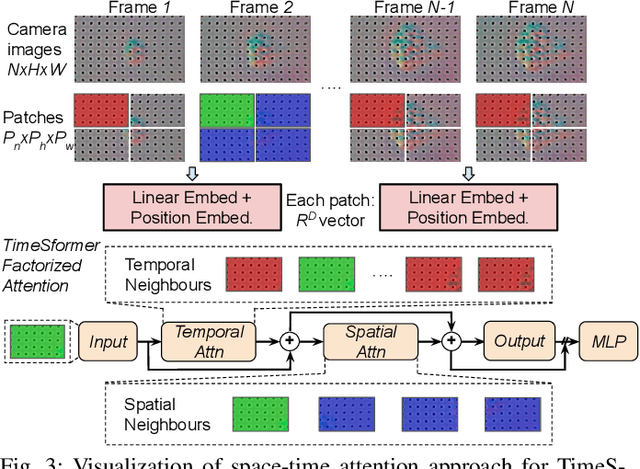
Reliable robotic grasping, especially with deformable objects such as fruits, remains a challenging task due to underactuated contact interactions with a gripper, unknown object dynamics and geometries. In this study, we propose a Transformer-based robotic grasping framework for rigid grippers that leverage tactile and visual information for safe object grasping. Specifically, the Transformer models learn physical feature embeddings with sensor feedback through performing two pre-defined explorative actions (pinching and sliding) and predict a grasping outcome through a multilayer perceptron (MLP) with a given grasping strength. Using these predictions, the gripper predicts a safe grasping strength via inference. Compared with convolutional recurrent networks (CNN), the Transformer models can capture the long-term dependencies across the image sequences and process spatial-temporal features simultaneously. We first benchmark the Transformer models on a public dataset for slip detection. Following that, we show that the Transformer models outperform a CNN+LSTM model in terms of grasping accuracy and computational efficiency. We also collect our fruit grasping dataset and conduct online grasping experiments using the proposed framework for both seen and unseen fruits. Our codes and dataset are public on GitHub.
Adaptive Denoising via GainTuning
Jul 27, 2021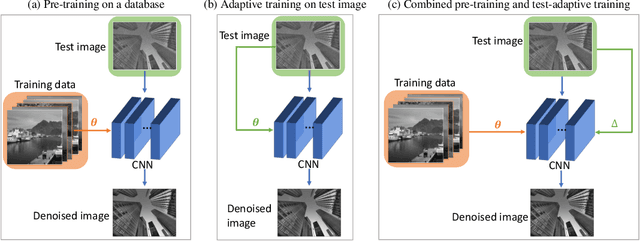
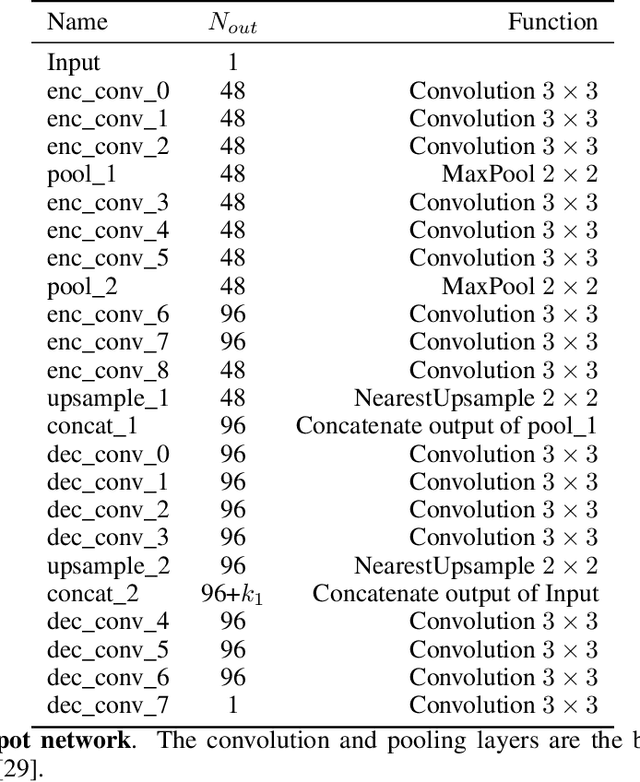
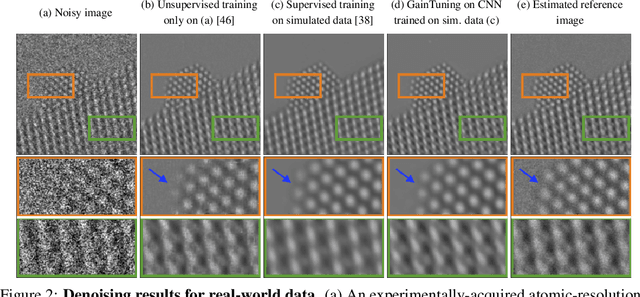

Deep convolutional neural networks (CNNs) for image denoising are usually trained on large datasets. These models achieve the current state of the art, but they have difficulties generalizing when applied to data that deviate from the training distribution. Recent work has shown that it is possible to train denoisers on a single noisy image. These models adapt to the features of the test image, but their performance is limited by the small amount of information used to train them. Here we propose "GainTuning", in which CNN models pre-trained on large datasets are adaptively and selectively adjusted for individual test images. To avoid overfitting, GainTuning optimizes a single multiplicative scaling parameter (the "Gain") of each channel in the convolutional layers of the CNN. We show that GainTuning improves state-of-the-art CNNs on standard image-denoising benchmarks, boosting their denoising performance on nearly every image in a held-out test set. These adaptive improvements are even more substantial for test images differing systematically from the training data, either in noise level or image type. We illustrate the potential of adaptive denoising in a scientific application, in which a CNN is trained on synthetic data, and tested on real transmission-electron-microscope images. In contrast to the existing methodology, GainTuning is able to faithfully reconstruct the structure of catalytic nanoparticles from these data at extremely low signal-to-noise ratios.