 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Progressively Volumetrized Deep Generative Models for Data-Efficient Contextual Learning of MR Image Recovery
Dec 03, 2020
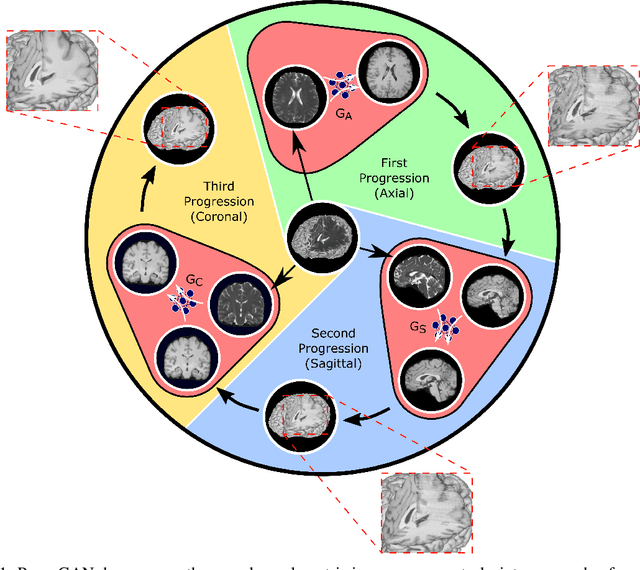
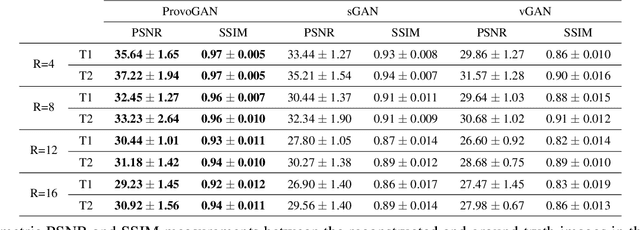

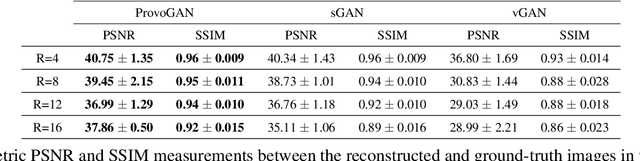
Magnetic resonance imaging (MRI) offers the flexibility to image a given anatomic volume under a multitude of tissue contrasts. Yet, scan time considerations put stringent limits on the quality and diversity of MRI data. The gold-standard approach to alleviate this limitation is to recover high-quality images from data undersampled across various dimensions such as the Fourier domain or contrast sets. A central divide among recovery methods is whether the anatomy is processed per volume or per cross-section. Volumetric models offer enhanced capture of global contextual information, but they can suffer from suboptimal learning due to elevated model complexity. Cross-sectional models with lower complexity offer improved learning behavior, yet they ignore contextual information across the longitudinal dimension of the volume. Here, we introduce a novel data-efficient progressively volumetrized generative model (ProvoGAN) that decomposes complex volumetric image recovery tasks into a series of simpler cross-sectional tasks across individual rectilinear dimensions. ProvoGAN effectively captures global context and recovers fine-structural details across all dimensions, while maintaining low model complexity and data-efficiency advantages of cross-sectional models. Comprehensive demonstrations on mainstream MRI reconstruction and synthesis tasks show that ProvoGAN yields superior performance to state-of-the-art volumetric and cross-sectional models.
MTGLS: Multi-Task Gaze Estimation with Limited Supervision
Oct 23, 2021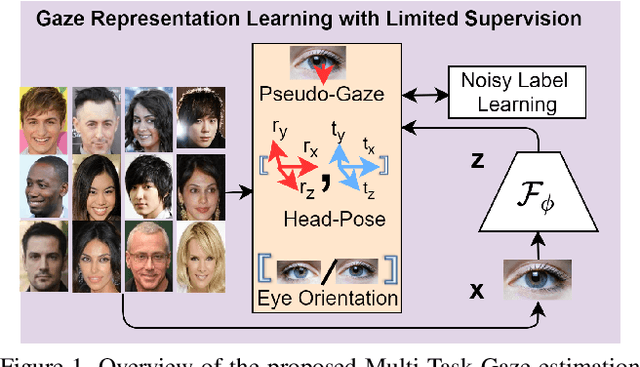
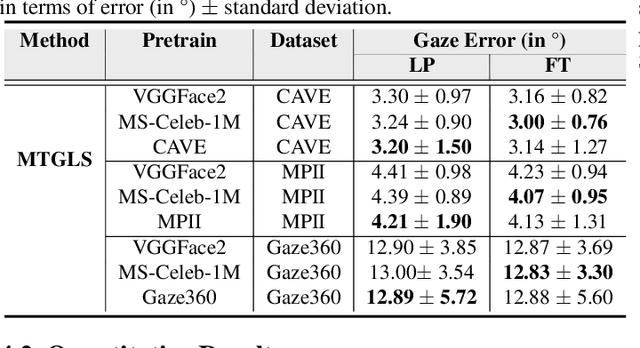
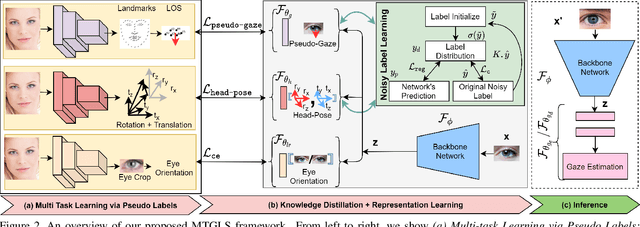
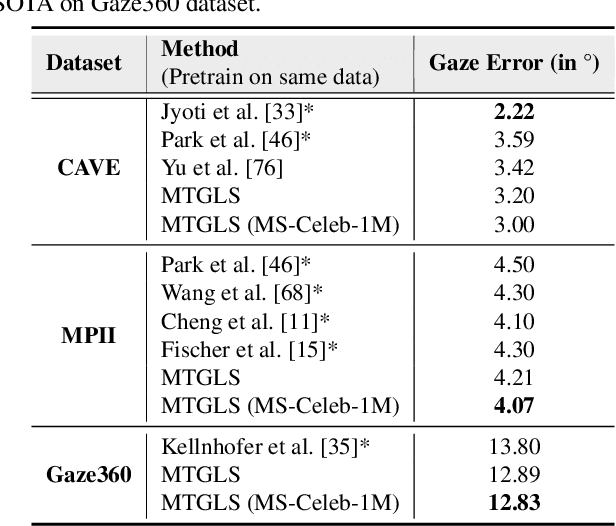
Robust gaze estimation is a challenging task, even for deep CNNs, due to the non-availability of large-scale labeled data. Moreover, gaze annotation is a time-consuming process and requires specialized hardware setups. We propose MTGLS: a Multi-Task Gaze estimation framework with Limited Supervision, which leverages abundantly available non-annotated facial image data. MTGLS distills knowledge from off-the-shelf facial image analysis models, and learns strong feature representations of human eyes, guided by three complementary auxiliary signals: (a) the line of sight of the pupil (i.e. pseudo-gaze) defined by the localized facial landmarks, (b) the head-pose given by Euler angles, and (c) the orientation of the eye patch (left/right eye). To overcome inherent noise in the supervisory signals, MTGLS further incorporates a noise distribution modelling approach. Our experimental results show that MTGLS learns highly generalized representations which consistently perform well on a range of datasets. Our proposed framework outperforms the unsupervised state-of-the-art on CAVE (by 6.43%) and even supervised state-of-the-art methods on Gaze360 (by 6.59%) datasets.
Continuous Human Action Detection Based on Wearable Inertial Data
Dec 11, 2021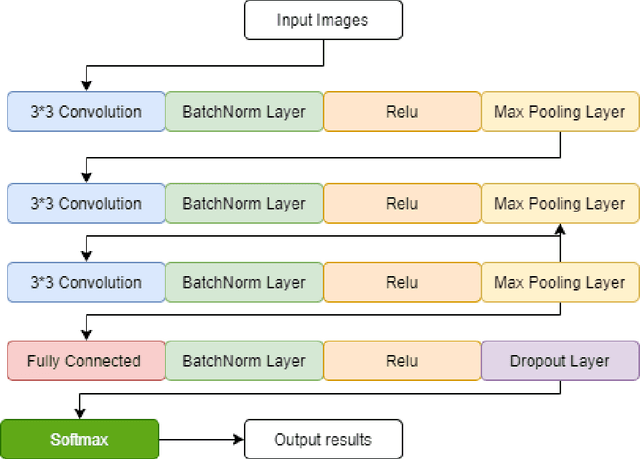

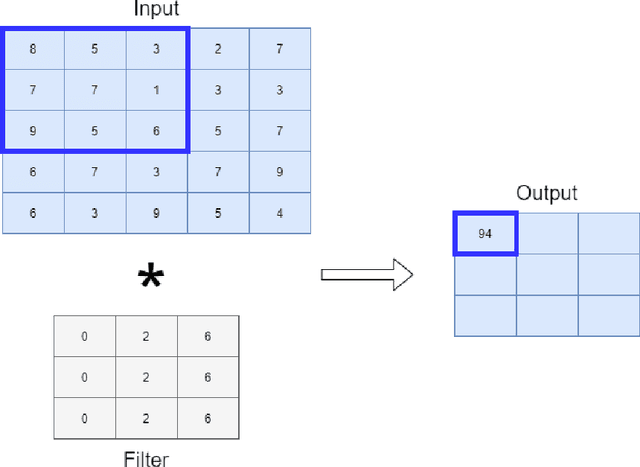
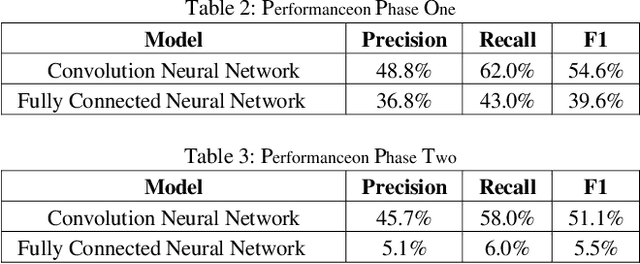
Human action detection is a hot topic, which is widely used in video surveillance, human machine interface, healthcare monitoring, gaming, dancing training and musical instrument teaching. As inertial sensors are low cost, portable, and having no operating space, it is suitable to detect human action. In real-world applications, actions that are of interest appear among actions of non interest without pauses in between. Recognizing and detecting actions of interests from continuous action streams is more challenging and useful for real applications. Based on inertial sensor and C-MHAD smart TV gesture recognition dataset, this paper utilized different inertial sensor feature formats, then compared the performance with different deep neural network structures according to these feature formats. Experiment results show the best performance was achieved by image based inertial feature with convolution neural network, which got 51.1% F1 score.
Towards Group Robustness in the presence of Partial Group Labels
Jan 10, 2022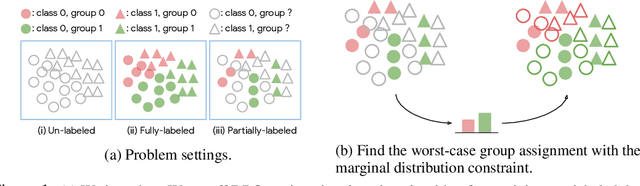

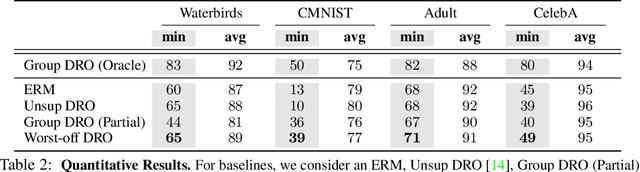
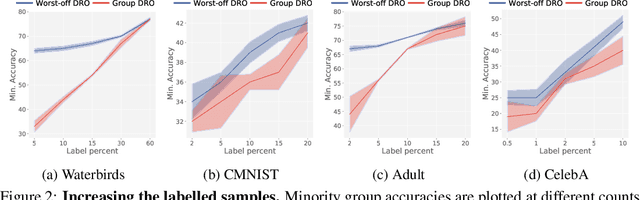
Learning invariant representations is an important requirement when training machine learning models that are driven by spurious correlations in the datasets. These spurious correlations, between input samples and the target labels, wrongly direct the neural network predictions resulting in poor performance on certain groups, especially the minority groups. Robust training against these spurious correlations requires the knowledge of group membership for every sample. Such a requirement is impractical in situations where the data labeling efforts for minority or rare groups are significantly laborious or where the individuals comprising the dataset choose to conceal sensitive information. On the other hand, the presence of such data collection efforts results in datasets that contain partially labeled group information. Recent works have tackled the fully unsupervised scenario where no labels for groups are available. Thus, we aim to fill the missing gap in the literature by tackling a more realistic setting that can leverage partially available sensitive or group information during training. First, we construct a constraint set and derive a high probability bound for the group assignment to belong to the set. Second, we propose an algorithm that optimizes for the worst-off group assignments from the constraint set. Through experiments on image and tabular datasets, we show improvements in the minority group's performance while preserving overall aggregate accuracy across groups.
Weakly Supervised Change Detection Using Guided Anisotropic Difusion
Dec 31, 2021
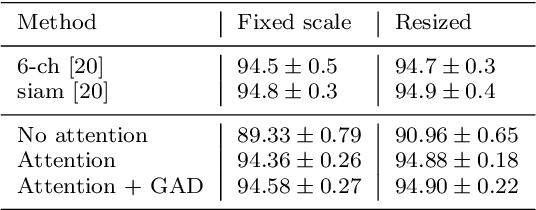

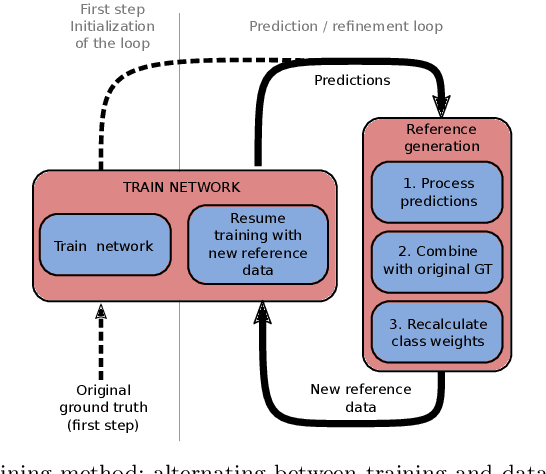
Large scale datasets created from crowdsourced labels or openly available data have become crucial to provide training data for large scale learning algorithms. While these datasets are easier to acquire, the data are frequently noisy and unreliable, which is motivating research on weakly supervised learning techniques. In this paper we propose original ideas that help us to leverage such datasets in the context of change detection. First, we propose the guided anisotropic diffusion (GAD) algorithm, which improves semantic segmentation results using the input images as guides to perform edge preserving filtering. We then show its potential in two weakly-supervised learning strategies tailored for change detection. The first strategy is an iterative learning method that combines model optimisation and data cleansing using GAD to extract the useful information from a large scale change detection dataset generated from open vector data. The second one incorporates GAD within a novel spatial attention layer that increases the accuracy of weakly supervised networks trained to perform pixel-level predictions from image-level labels. Improvements with respect to state-of-the-art are demonstrated on 4 different public datasets.
3D Segmentation with Fully Trainable Gabor Kernels and Pearson's Correlation Coefficient
Jan 10, 2022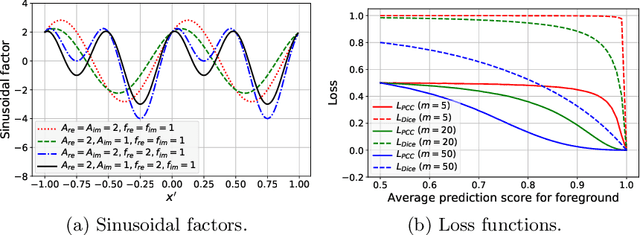
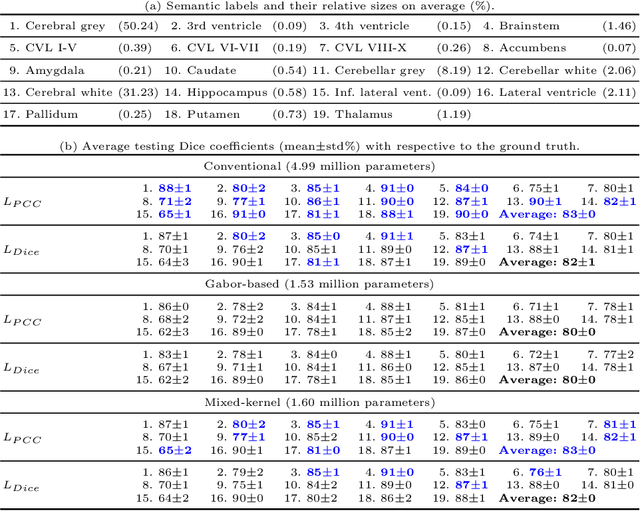
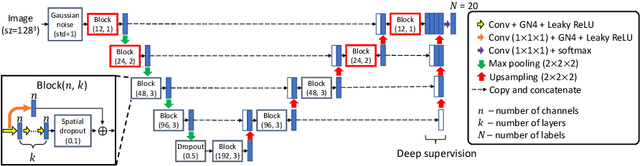
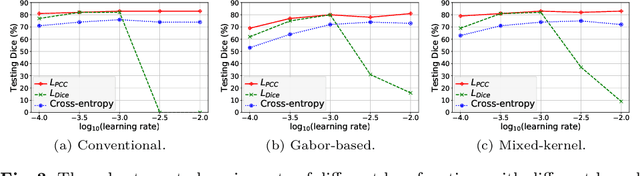
The convolutional layer and loss function are two fundamental components in deep learning. Because of the success of conventional deep learning kernels, the less versatile Gabor kernels become less popular despite the fact that they can provide abundant features at different frequencies, orientations, and scales with much fewer parameters. For existing loss functions for multi-class image segmentation, there is usually a tradeoff among accuracy, robustness to hyperparameters, and manual weight selections for combining different losses. Therefore, to gain the benefits of using Gabor kernels while keeping the advantage of automatic feature generation in deep learning, we propose a fully trainable Gabor-based convolutional layer where all Gabor parameters are trainable through backpropagation. Furthermore, we propose a loss function based on the Pearson's correlation coefficient, which is accurate, robust to learning rates, and does not require manual weight selections. Experiments on 43 3D brain magnetic resonance images with 19 anatomical structures show that, using the proposed loss function with a proper combination of conventional and Gabor-based kernels, we can train a network with only 1.6 million parameters to achieve an average Dice coefficient of 83%. This size is 44 times smaller than the V-Net which has 71 million parameters. This paper demonstrates the potentials of using learnable parametric kernels in deep learning for 3D segmentation.
Competing Mutual Information Constraints with Stochastic Competition-based Activations for Learning Diversified Representations
Jan 10, 2022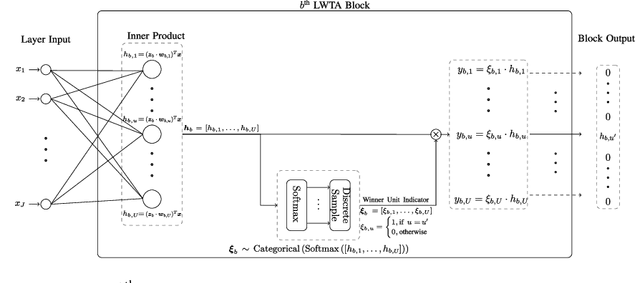
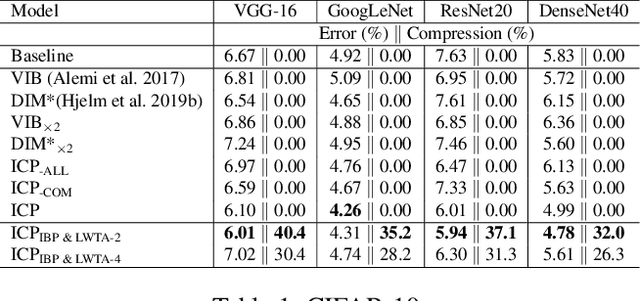
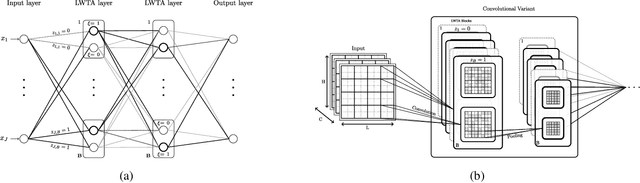
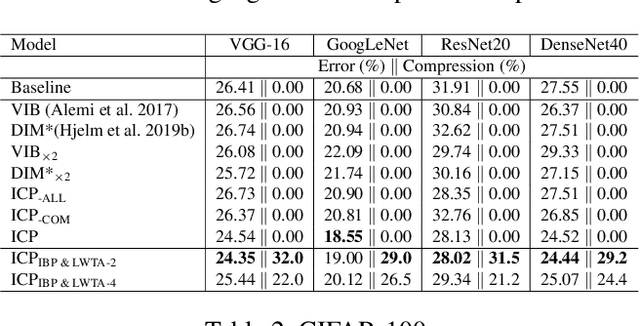
This work aims to address the long-established problem of learning diversified representations. To this end, we combine information-theoretic arguments with stochastic competition-based activations, namely Stochastic Local Winner-Takes-All (LWTA) units. In this context, we ditch the conventional deep architectures commonly used in Representation Learning, that rely on non-linear activations; instead, we replace them with sets of locally and stochastically competing linear units. In this setting, each network layer yields sparse outputs, determined by the outcome of the competition between units that are organized into blocks of competitors. We adopt stochastic arguments for the competition mechanism, which perform posterior sampling to determine the winner of each block. We further endow the considered networks with the ability to infer the sub-part of the network that is essential for modeling the data at hand; we impose appropriate stick-breaking priors to this end. To further enrich the information of the emerging representations, we resort to information-theoretic principles, namely the Information Competing Process (ICP). Then, all the components are tied together under the stochastic Variational Bayes framework for inference. We perform a thorough experimental investigation for our approach using benchmark datasets on image classification. As we experimentally show, the resulting networks yield significant discriminative representation learning abilities. In addition, the introduced paradigm allows for a principled investigation mechanism of the emerging intermediate network representations.
CNN-based Single Image Crowd Counting: Network Design, Loss Function and Supervisory Signal
Dec 31, 2020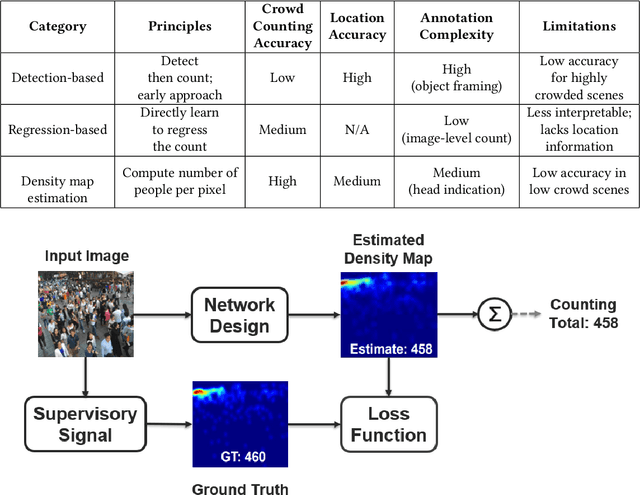

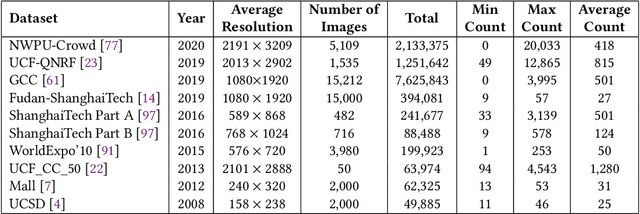
Single image crowd counting is a challenging computer vision problem with wide applications in public safety, city planning, traffic management, etc. This survey is to provide a comprehensive summary of recent advanced crowd counting techniques based on Convolutional Neural Network (CNN) via density map estimation. Our goals are to provide an up-to-date review of recent approaches, and educate new researchers in this field the design principles and trade-offs. After presenting publicly available datasets and evaluation metrics, we review the recent advances with detailed comparisons on three major design modules for crowd counting: deep neural network designs, loss functions, and supervisory signals. We conclude the survey with some future directions.
COVID-19 Face Mask Recognition with Advanced Face Cut Algorithm for Human Safety Measures
Oct 08, 2021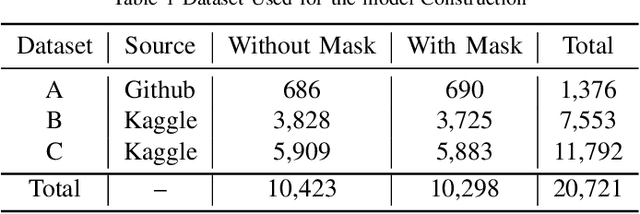

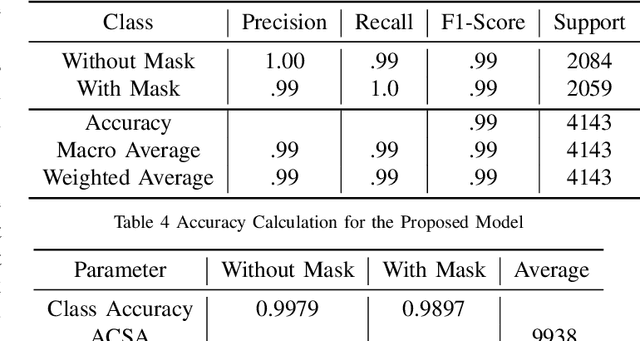
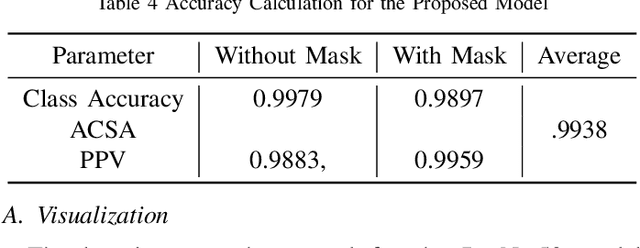
In the last year, the outbreak of COVID-19 has deployed computer vision and machine learning algorithms in various fields to enhance human life interactions. COVID-19 is a highly contaminated disease that affects mainly the respiratory organs of the human body. We must wear a mask in this situation as the virus can be contaminated through the air and a non-masked person can be affected. Our proposal deploys a computer vision and deep learning framework to recognize face masks from images or videos. We have implemented a Boundary dependent face cut recognition algorithm that can cut the face from the image using 27 landmarks and then the preprocessed image can further be sent to the deep learning ResNet50 model. The experimental result shows a significant advancement of 3.4 percent compared to the YOLOV3 mask recognition architecture in just 10 epochs.
Explicitly Modeled Attention Maps for Image Classification
Jun 14, 2020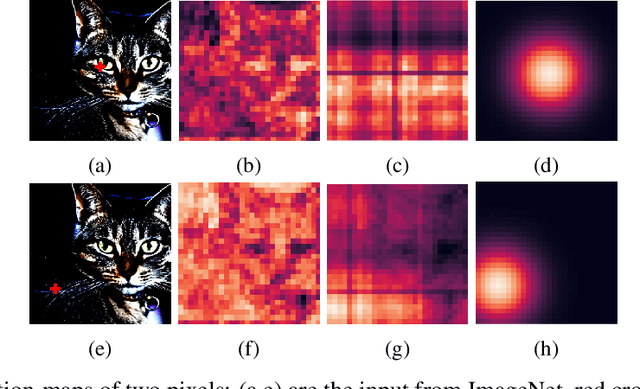

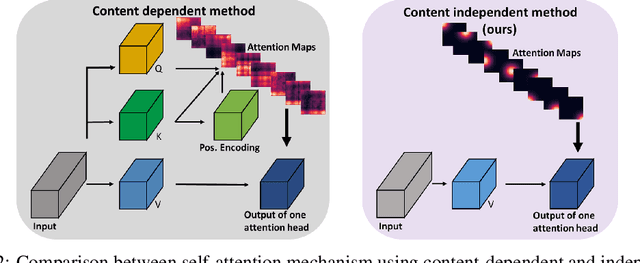
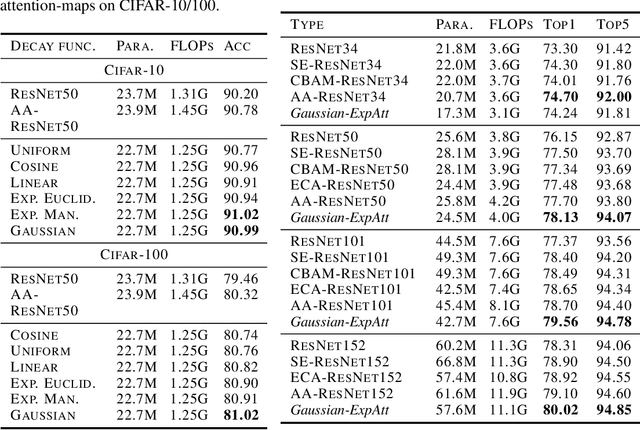
Self-attention networks have shown remarkable progress in computer vision tasks such as image classification. The main benefit of the self-attention mechanism is the ability to capture long-range feature interactions in attention-maps. However, the computation of attention-maps requires a learnable key, query, and positional encoding, whose usage is often not intuitive and computationally expensive. To mitigate this problem, we propose a novel self-attention module with explicitly modeled attention-maps using only a single learnable parameter for low computational overhead. The design of explicitly modeled attention-maps using geometric prior is based on the observation that the spatial context for a given pixel within an image is mostly dominated by its neighbors, while more distant pixels have a minor contribution. Concretely, the attention-maps are parametrized via simple functions (e.g., Gaussian kernel) with a learnable radius, which is modeled independently of the input content. Our evaluation shows that our method achieves an accuracy improvement of up to 2.2% over the ResNet-baselines in ImageNet ILSVRC and outperforms other self-attention methods such as AA-ResNet152 (Bello et al., 2019) in accuracy by 0.9% with 6.4% fewer parameters and 6.7% fewer GFLOPs.