 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploiting context dependence for image compression with upsampling
Apr 06, 2020
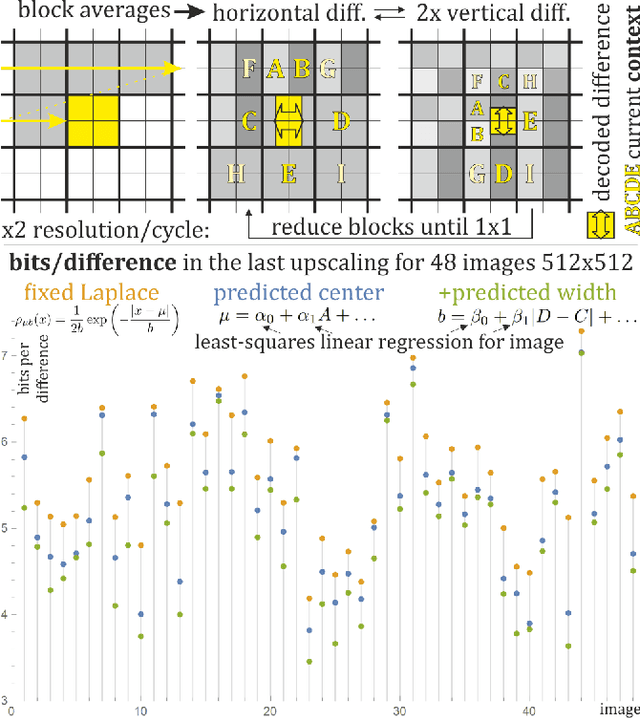

Image compression with upsampling encodes information to succeedingly increase image resolution, for example by encoding differences in FUIF and JPEG XL. It is useful for progressive decoding, also often can improve compression ratio. However, the currently used solutions rather do not exploit context dependence for encoding of such upscaling information. This article discusses simple inexpensive general techniques for this purpose, which allowed to save on average 0.645 bits/difference (between 0.138 and 1.489) for the last upscaling for 48 standard $512\times 512$ grayscale images - compared to assumption of fixed Laplace distribution. Using least squares linear regression of context to predict center of Laplace distribution gave on average 0.393 bits/difference savings. The remaining savings were obtained by additionally predicting width of this Laplace distribution, also using just the least squares linear regression. The presented simple inexpensive general methodology can be also used for different types of data like DCT coefficients in lossy image compression.
End-to-End Differentiable Learning to HDR Image Synthesis for Multi-exposure Images
Jun 29, 2020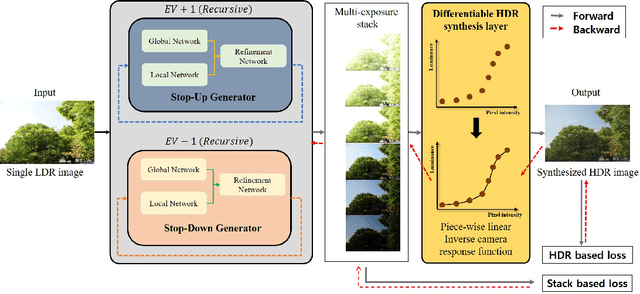
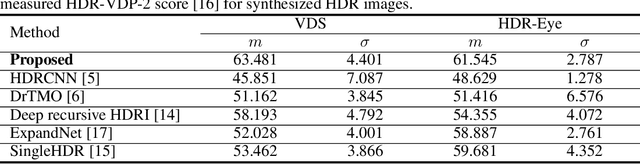
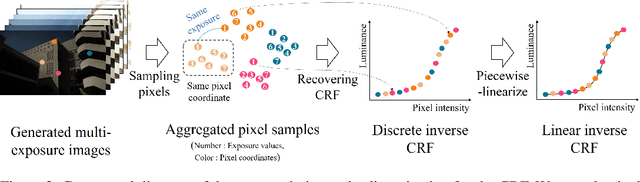
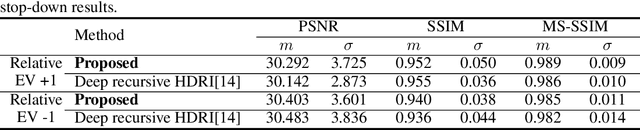
Recent deep learning-based methods have reconstructed a high dynamic range (HDR) image from a single low dynamic range (LDR) image by focusing on the exposure transfer task to reconstruct the multi-exposure stack. However, these methods often fail to fuse the multi-exposure stack into a perceptually pleasant HDR image as the local inversion artifacts are formed in the HDR imaging (HDRI) process. The artifacts arise from the impossibility of learning the whole HDRI process due to its non-differentiable structure of the camera response recovery. Therefore, we tackle the major challenge in stack reconstruction-based methods by proposing a novel framework with the fully differentiable HDRI process. Our framework enables a neural network to train the HDR image generation based on the end-to-end structure. Hence, a deep neural network can train the precise correlations between multi-exposure images in the HDRI process using our differentiable HDR synthesis layer. In addition, our network uses the image decomposition and the recursive process to facilitate the exposure transfer task and to adaptively respond to recursion frequency. The experimental results show that the proposed network outperforms the state-of-the-art quatitative and qualitative results in terms of both the exposure transfer tasks and the whole HDRI process.
Multi-Label Classification on Remote-Sensing Images
Jan 06, 2022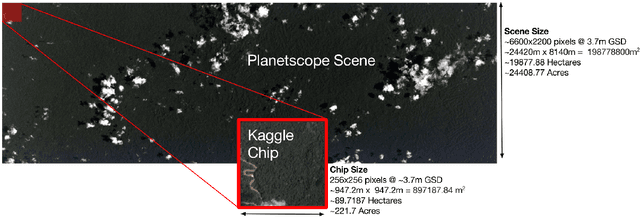

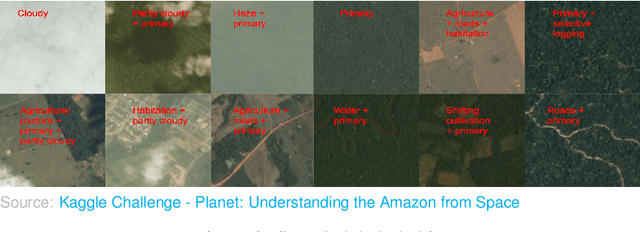
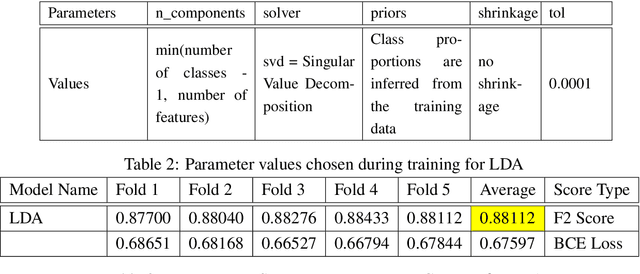
Acquiring information on large areas on the earth's surface through satellite cameras allows us to see much more than we can see while standing on the ground. This assists us in detecting and monitoring the physical characteristics of an area like land-use patterns, atmospheric conditions, forest cover, and many unlisted aspects. The obtained images not only keep track of continuous natural phenomena but are also crucial in tackling the global challenge of severe deforestation. Among which Amazon basin accounts for the largest share every year. Proper data analysis would help limit detrimental effects on the ecosystem and biodiversity with a sustainable healthy atmosphere. This report aims to label the satellite image chips of the Amazon rainforest with atmospheric and various classes of land cover or land use through different machine learning and superior deep learning models. Evaluation is done based on the F2 metric, while for loss function, we have both sigmoid cross-entropy as well as softmax cross-entropy. Images are fed indirectly to the machine learning classifiers after only features are extracted using pre-trained ImageNet architectures. Whereas for deep learning models, ensembles of fine-tuned ImageNet pre-trained models are used via transfer learning. Our best score was achieved so far with the F2 metric is 0.927.
Partially-supervised novel object captioning leveraging context from paired data
Sep 10, 2021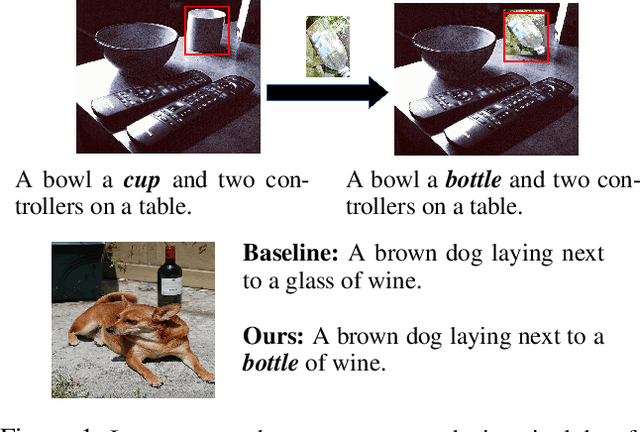
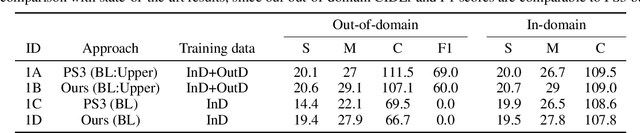
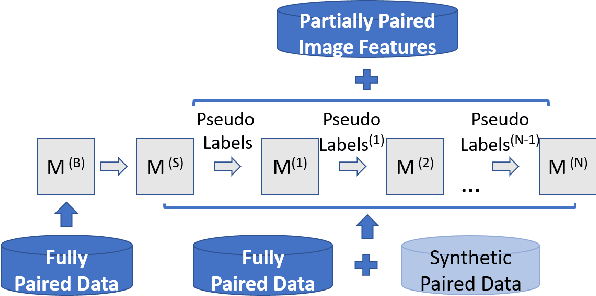
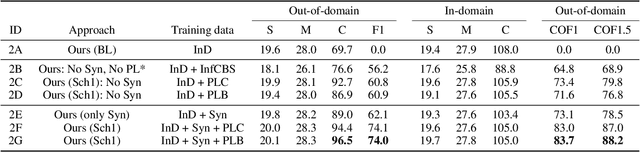
In this paper, we propose an approach to improve image captioning solutions for images with novel objects that do not have caption labels in the training dataset. Our approach is agnostic to model architecture, and primarily focuses on training technique that uses existing fully paired image-caption data and the images with only the novel object detection labels (partially paired data). We create synthetic paired captioning data for these novel objects by leveraging context from existing image-caption pairs. We further re-use these partially paired images with novel objects to create pseudo-label captions that are used to fine-tune the captioning model. Using a popular captioning model (Up-Down) as baseline, our approach achieves state-of-the-art results on held-out MS COCO out-of-domain test split, and improves F1 metric and CIDEr for novel object images by 75.8 and 26.6 points respectively, compared to baseline model that does not use partially paired images during training.
Experimental realization of the active convolved illumination imaging technique for enhanced signal-to-noise ratio
Dec 31, 2021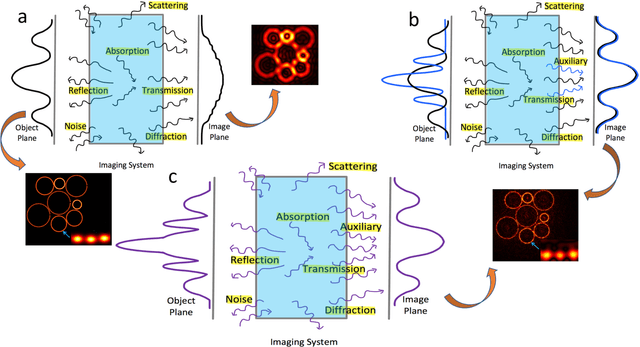
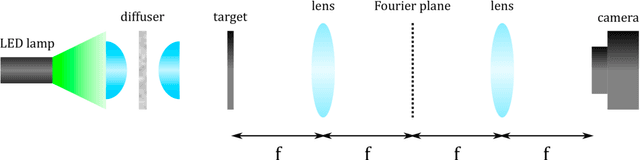
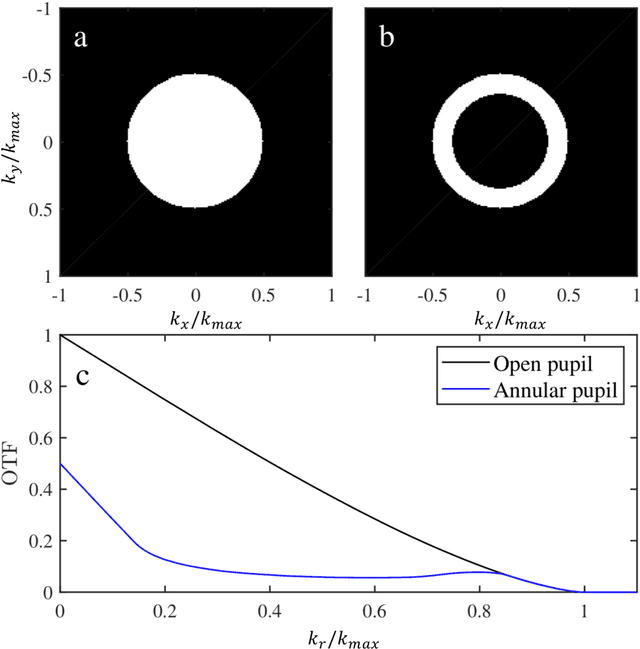
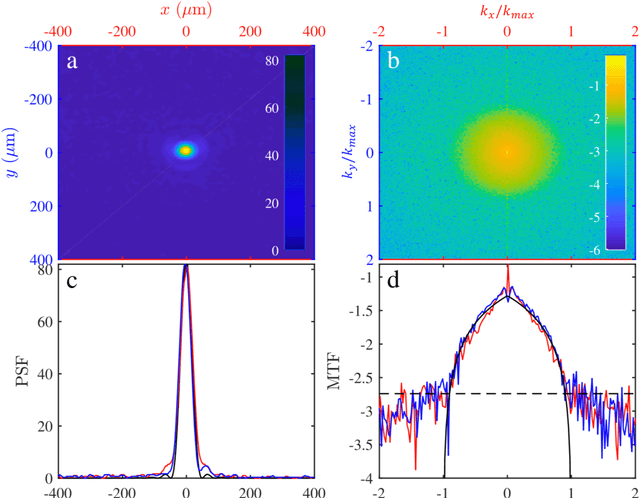
Imaging is indispensable for nearly every field of science, engineering, technology, and medicine. However, measurement noise and stochastic distortions pose fundamental limits to accessible spatiotemporal information despite impressive tools such as SIM, PALM/STORM, and STED microscopy. How to combat this challenge ideally has been an open question for decades. Inspired by a "virtual gain" technique to compensate losses in metamaterials, "active convolved illumination" has been recently proposed to significantly improve the signal-to-noise ratio, hence data acquisition. In this technique, the light pattern of the object is superimposed with a correlated auxiliary pattern, the function of which is to reverse the adverse effect of noise and random distortion based on their spectral characteristics. Despite enormous implications in statistics, an experimental realization of this novel technique has been lacking to date. Here, we present the first experimental demonstration. We find that the active convolved illumination does not only boost the resolution limit and image contrast, but also the resistance to pixel saturation. The results confirm the previous theories and opens up new horizons in a wide range of disciplines from atmospheric sciences, seismology, biology, statistical learning, and information processing to quantum noise beyond the fundamental boundaries.
$AIR^2$ for Interaction Prediction
Nov 16, 2021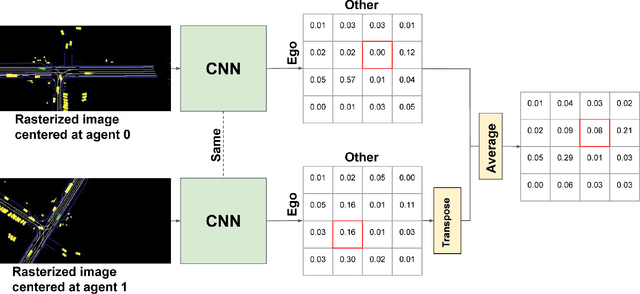

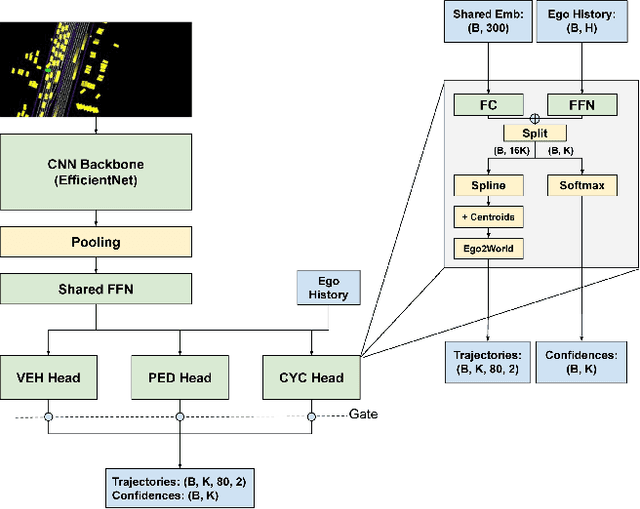
The 2021 Waymo Interaction Prediction Challenge introduced a problem of predicting the future trajectories and confidences of two interacting agents jointly. We developed a solution that takes an anchored marginal motion prediction model with rasterization and augments it to model agent interaction. We do this by predicting the joint confidences using a rasterized image that highlights the ego agent and the interacting agent. Our solution operates on the cartesian product space of the anchors; hence the $"^2"$ in $AIR^2$. Our model achieved the highest mAP (the primary metric) on the leaderboard.
Progressively Volumetrized Deep Generative Models for Data-Efficient Contextual Learning of MR Image Recovery
Dec 03, 2020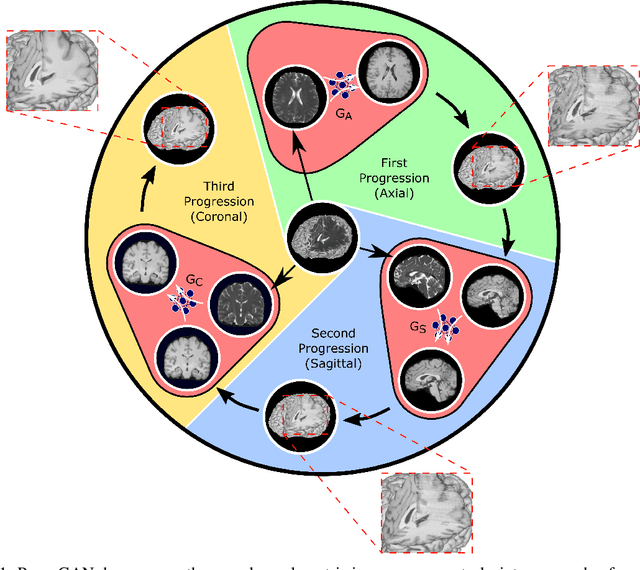
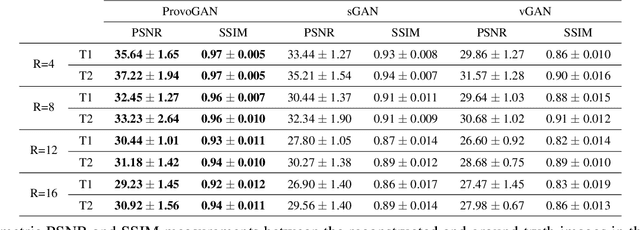

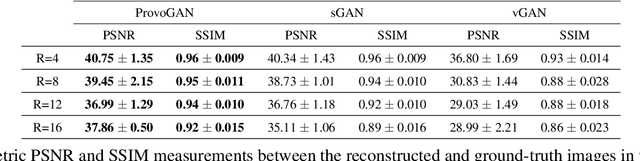
Magnetic resonance imaging (MRI) offers the flexibility to image a given anatomic volume under a multitude of tissue contrasts. Yet, scan time considerations put stringent limits on the quality and diversity of MRI data. The gold-standard approach to alleviate this limitation is to recover high-quality images from data undersampled across various dimensions such as the Fourier domain or contrast sets. A central divide among recovery methods is whether the anatomy is processed per volume or per cross-section. Volumetric models offer enhanced capture of global contextual information, but they can suffer from suboptimal learning due to elevated model complexity. Cross-sectional models with lower complexity offer improved learning behavior, yet they ignore contextual information across the longitudinal dimension of the volume. Here, we introduce a novel data-efficient progressively volumetrized generative model (ProvoGAN) that decomposes complex volumetric image recovery tasks into a series of simpler cross-sectional tasks across individual rectilinear dimensions. ProvoGAN effectively captures global context and recovers fine-structural details across all dimensions, while maintaining low model complexity and data-efficiency advantages of cross-sectional models. Comprehensive demonstrations on mainstream MRI reconstruction and synthesis tasks show that ProvoGAN yields superior performance to state-of-the-art volumetric and cross-sectional models.
ForgeryNet -- Face Forgery Analysis Challenge 2021: Methods and Results
Dec 15, 2021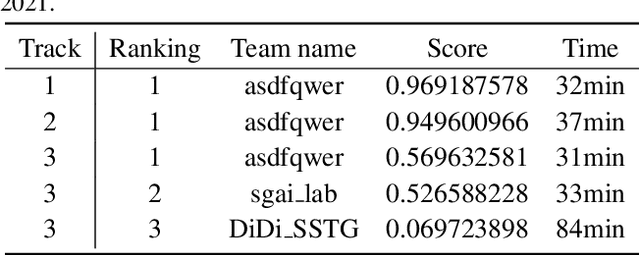
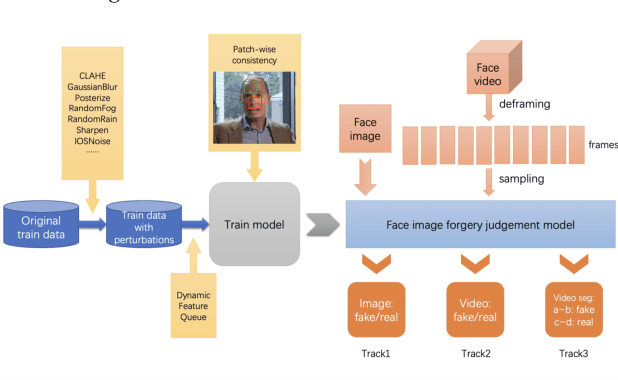
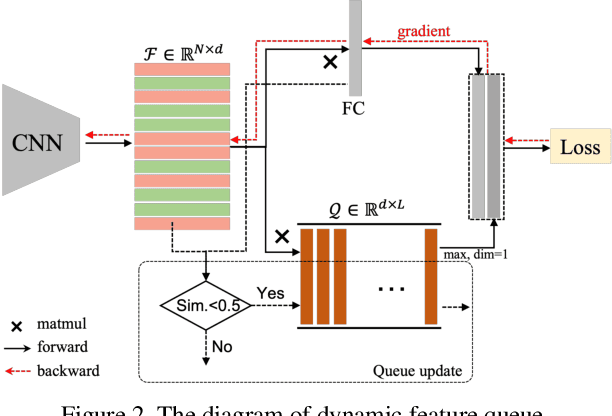
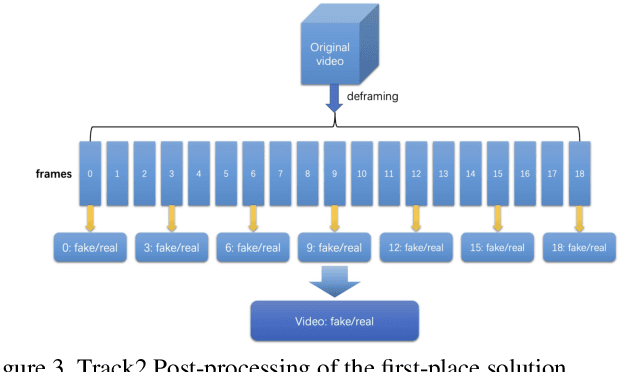
The rapid progress of photorealistic synthesis techniques has reached a critical point where the boundary between real and manipulated images starts to blur. Recently, a mega-scale deep face forgery dataset, ForgeryNet which comprised of 2.9 million images and 221,247 videos has been released. It is by far the largest publicly available in terms of data-scale, manipulations (7 image-level approaches, 8 video-level approaches), perturbations (36 independent and more mixed perturbations), and annotations (6.3 million classification labels, 2.9 million manipulated area annotations, and 221,247 temporal forgery segment labels). This paper reports methods and results in the ForgeryNet - Face Forgery Analysis Challenge 2021, which employs the ForgeryNet benchmark. The model evaluation is conducted offline on the private test set. A total of 186 participants registered for the competition, and 11 teams made valid submissions. We will analyze the top-ranked solutions and present some discussion on future work directions.
PDBL: Improving Histopathological Tissue Classification with Plug-and-Play Pyramidal Deep-Broad Learning
Nov 04, 2021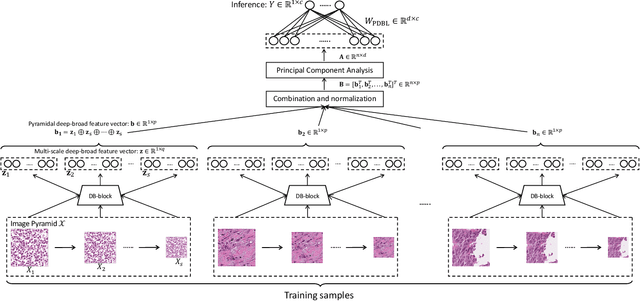
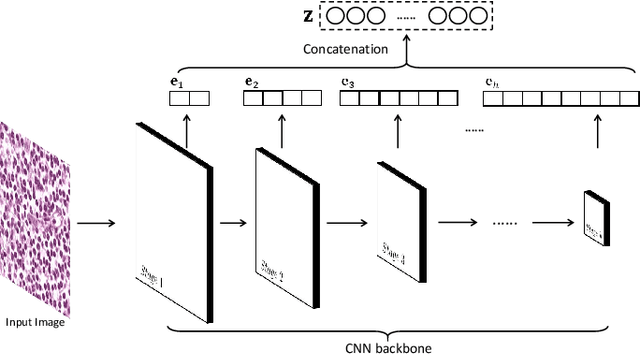

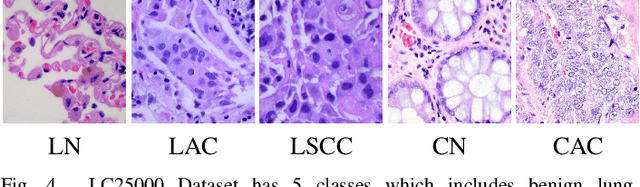
Histopathological tissue classification is a fundamental task in pathomics cancer research. Precisely differentiating different tissue types is a benefit for the downstream researches, like cancer diagnosis, prognosis and etc. Existing works mostly leverage the popular classification backbones in computer vision to achieve histopathological tissue classification. In this paper, we proposed a super lightweight plug-and-play module, named Pyramidal Deep-Broad Learning (PDBL), for any well-trained classification backbone to further improve the classification performance without a re-training burden. We mimic how pathologists observe pathology slides in different magnifications and construct an image pyramid for the input image in order to obtain the pyramidal contextual information. For each level in the pyramid, we extract the multi-scale deep-broad features by our proposed Deep-Broad block (DB-block). We equipped PDBL in three popular classification backbones, ShuffLeNetV2, EfficientNetb0, and ResNet50 to evaluate the effectiveness and efficiency of our proposed module on two datasets (Kather Multiclass Dataset and the LC25000 Dataset). Experimental results demonstrate the proposed PDBL can steadily improve the tissue-level classification performance for any CNN backbones, especially for the lightweight models when given a small among of training samples (less than 10%), which greatly saves the computational time and annotation efforts.
A Quantitative Comparison of Epistemic Uncertainty Maps Applied to Multi-Class Segmentation
Sep 22, 2021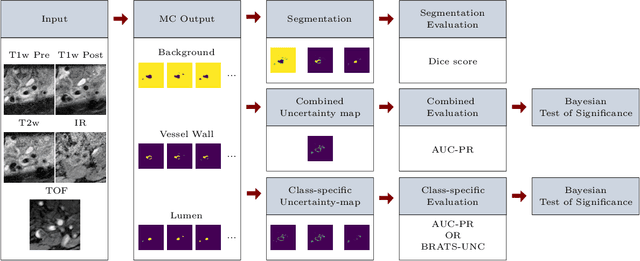

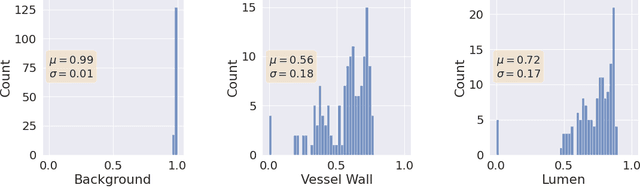
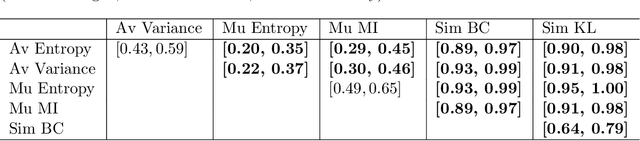
Uncertainty assessment has gained rapid interest in medical image analysis. A popular technique to compute epistemic uncertainty is the Monte-Carlo (MC) dropout technique. From a network with MC dropout and a single input, multiple outputs can be sampled. Various methods can be used to obtain epistemic uncertainty maps from those multiple outputs. In the case of multi-class segmentation, the number of methods is even larger as epistemic uncertainty can be computed voxelwise per class or voxelwise per image. This paper highlights a systematic approach to define and quantitatively compare those methods in two different contexts: class-specific epistemic uncertainty maps (one value per image, voxel and class) and combined epistemic uncertainty maps (one value per image and voxel). We applied this quantitative analysis to a multi-class segmentation of the carotid artery lumen and vessel wall, on a multi-center, multi-scanner, multi-sequence dataset of (MR) images. We validated our analysis over 144 sets of hyperparameters of a model. Our main analysis considers the relationship between the order of the voxels sorted according to their epistemic uncertainty values and the misclassification of the prediction. Under this consideration, the comparison of combined uncertainty maps reveals that the multi-class entropy and the multi-class mutual information statistically out-perform the other combined uncertainty maps under study. In a class-specific scenario, the one-versus-all entropy statistically out-performs the class-wise entropy, the class-wise variance and the one versus all mutual information. The class-wise entropy statistically out-performs the other class-specific uncertainty maps in terms of calibration. We made a python package available to reproduce our analysis on different data and tasks.