 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Snapshot Ptychography on Array cameras
Nov 05, 2021




We use convolutional neural networks to recover images optically down-sampled by $6.7\times$ using coherent aperture synthesis over a 16 camera array. Where conventional ptychography relies on scanning and oversampling, here we apply decompressive neural estimation to recover full resolution image from a single snapshot, although as shown in simulation multiple snapshots can be used to improve SNR. In place training on experimental measurements eliminates the need to directly calibrate the measurement system. We also present simulations of diverse array camera sampling strategies to explore how snapshot compressive systems might be optimized.
Fusion of CNNs and statistical indicators to improve image classification
Dec 20, 2020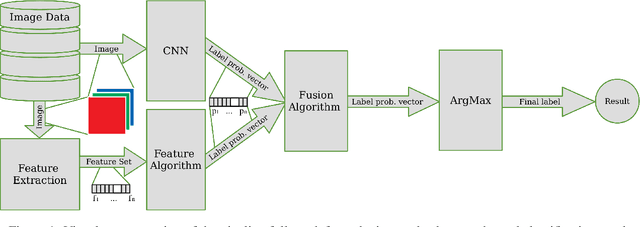

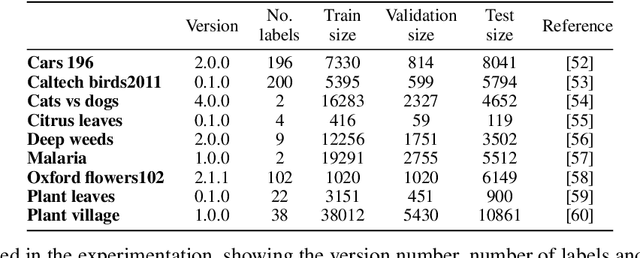
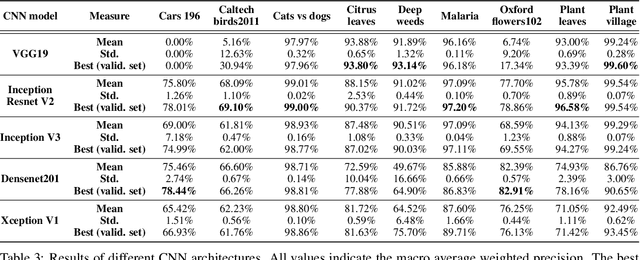
Convolutional Networks have dominated the field of computer vision for the last ten years, exhibiting extremely powerful feature extraction capabilities and outstanding classification performance. The main strategy to prolong this trend relies on further upscaling networks in size. However, costs increase rapidly while performance improvements may be marginal. We hypothesise that adding heterogeneous sources of information may be more cost-effective to a CNN than building a bigger network. In this paper, an ensemble method is proposed for accurate image classification, fusing automatically detected features through Convolutional Neural Network architectures with a set of manually defined statistical indicators. Through a combination of the predictions of a CNN and a secondary classifier trained on statistical features, better classification performance can be cheaply achieved. We test multiple learning algorithms and CNN architectures on a diverse number of datasets to validate our proposal, making public all our code and data via GitHub. According to our results, the inclusion of additional indicators and an ensemble classification approach helps to increase the performance in 8 of 9 datasets, with a remarkable increase of more than 10% precision in two of them.
A tool for user friendly, cloud based, whole slide image segmentation
Jan 18, 2021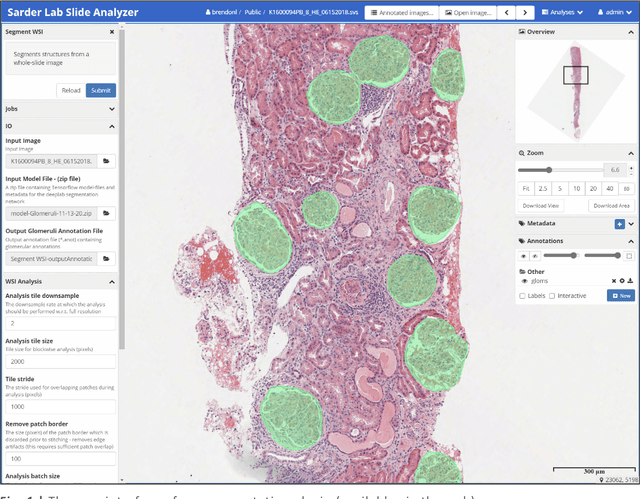
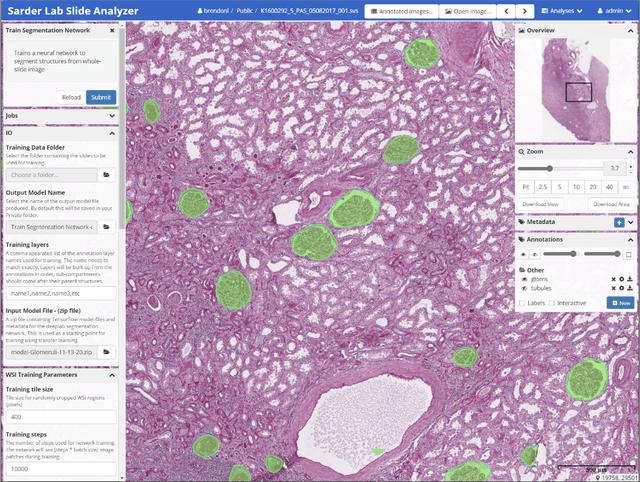
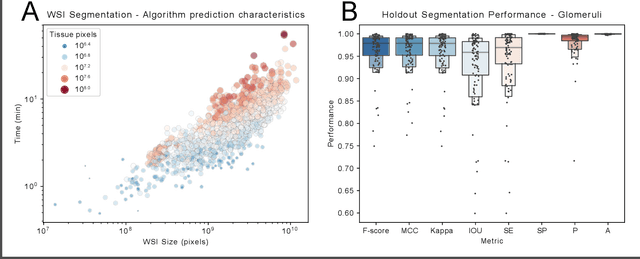
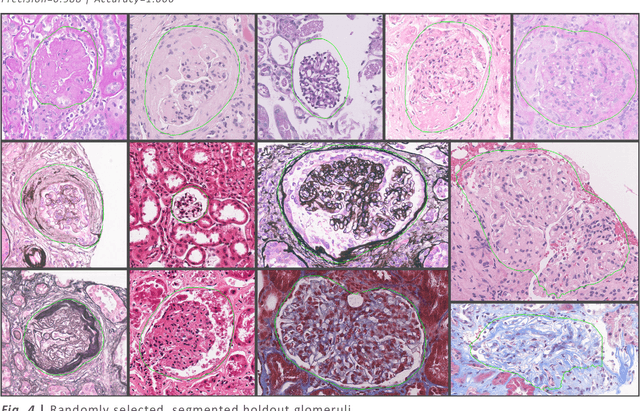
Convolutional neural networks, the state of the art for image segmentation, have been successfully applied to histology images by many computational researchers. However, the translatability of this technology to clinicians and biological researchers is limited due to the complex and undeveloped user interface of the code, as well as the extensive computer setup required. As an extension of our previous work (arXiv:1812.07509), we have developed a tool for segmentation of whole slide images (WSIs) with an easy to use graphical user interface. Our tool runs a state-of-the-art convolutional neural network for segmentation of WSIs in the cloud. Our plugin is built on the open source tool HistomicsTK by Kitware Inc. (Clifton Park, NY), which provides remote data management and viewing abilities for WSI datasets. The ability to access this tool over the internet will facilitate widespread use by computational non-experts. Users can easily upload slides to a server where our plugin is installed and perform human in the loop segmentation analysis remotely. This tool is open source, and has the ability to be adapted to segment of any pathological structure. For a proof of concept, we have trained it to segment glomeruli from renal tissue images, achieving an F-score > 0.97 on holdout tissue slides.
From Noise to Feature: Exploiting Intensity Distribution as a Novel Soft Biometric Trait for Finger Vein Recognition
Dec 15, 2021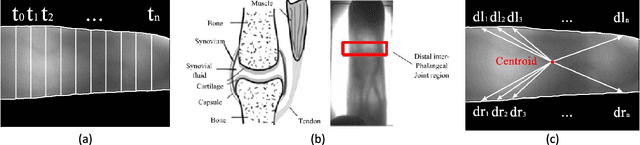
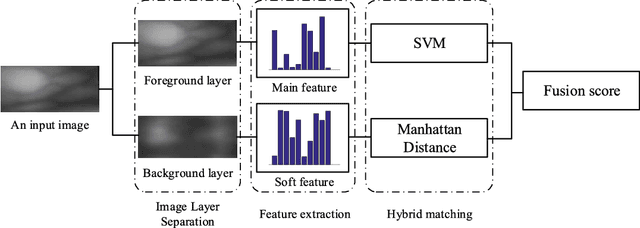
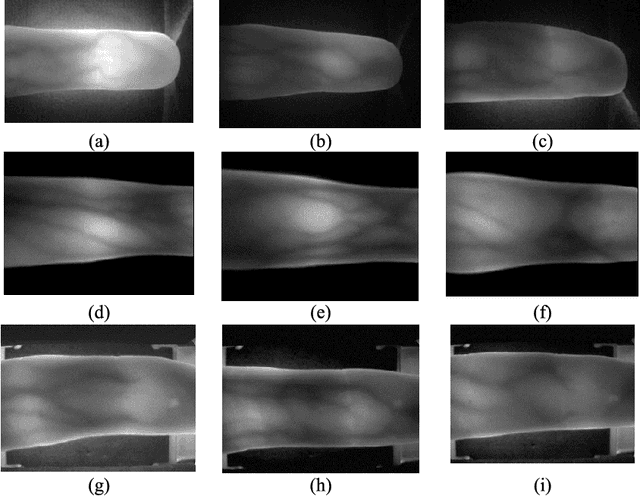

Most finger vein feature extraction algorithms achieve satisfactory performance due to their texture representation abilities, despite simultaneously ignoring the intensity distribution that is formed by the finger tissue, and in some cases, processing it as background noise. In this paper, we exploit this kind of noise as a novel soft biometric trait for achieving better finger vein recognition performance. First, a detailed analysis of the finger vein imaging principle and the characteristics of the image are presented to show that the intensity distribution that is formed by the finger tissue in the background can be extracted as a soft biometric trait for recognition. Then, two finger vein background layer extraction algorithms and three soft biometric trait extraction algorithms are proposed for intensity distribution feature extraction. Finally, a hybrid matching strategy is proposed to solve the issue of dimension difference between the primary and soft biometric traits on the score level. A series of rigorous contrast experiments on three open-access databases demonstrates that our proposed method is feasible and effective for finger vein recognition.
* 11 pages
SLCRF: Subspace Learning with Conditional Random Field for Hyperspectral Image Classification
Oct 07, 2020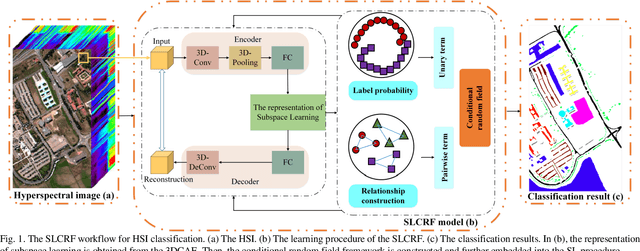

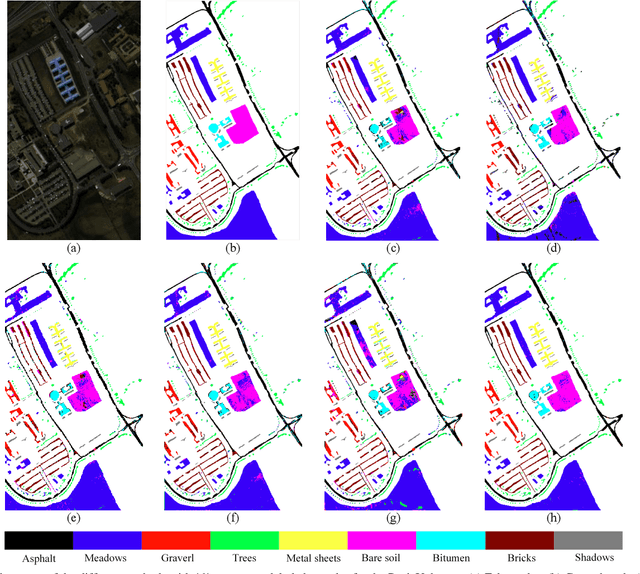
Subspace learning (SL) plays an important role in hyperspectral image (HSI) classification, since it can provide an effective solution to reduce the redundant information in the image pixels of HSIs. Previous works about SL aim to improve the accuracy of HSI recognition. Using a large number of labeled samples, related methods can train the parameters of the proposed solutions to obtain better representations of HSI pixels. However, the data instances may not be sufficient enough to learn a precise model for HSI classification in real applications. Moreover, it is well-known that it takes much time, labor and human expertise to label HSI images. To avoid the aforementioned problems, a novel SL method that includes the probability assumption called subspace learning with conditional random field (SLCRF) is developed. In SLCRF, first, the 3D convolutional autoencoder (3DCAE) is introduced to remove the redundant information in HSI pixels. In addition, the relationships are also constructed using the spectral-spatial information among the adjacent pixels. Then, the conditional random field (CRF) framework can be constructed and further embedded into the HSI SL procedure with the semi-supervised approach. Through the linearized alternating direction method termed LADMAP, the objective function of SLCRF is optimized using a defined iterative algorithm. The proposed method is comprehensively evaluated using the challenging public HSI datasets. We can achieve stateof-the-art performance using these HSI sets.
SPTS: Single-Point Text Spotting
Dec 15, 2021
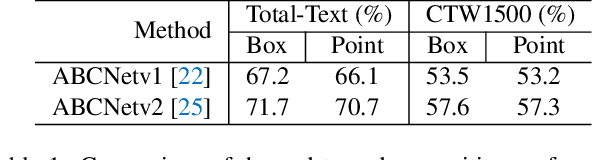

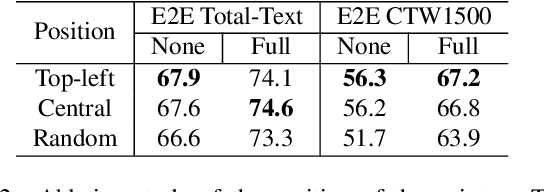
Almost all scene text spotting (detection and recognition) methods rely on costly box annotation (e.g., text-line box, word-level box, and character-level box). For the first time, we demonstrate that training scene text spotting models can be achieved with an extremely low-cost annotation of a single-point for each instance. We propose an end-to-end scene text spotting method that tackles scene text spotting as a sequence prediction task, like language modeling. Given an image as input, we formulate the desired detection and recognition results as a sequence of discrete tokens and use an auto-regressive transformer to predict the sequence. We achieve promising results on several horizontal, multi-oriented, and arbitrarily shaped scene text benchmarks. Most significantly, we show that the performance is not very sensitive to the positions of the point annotation, meaning that it can be much easier to be annotated and automatically generated than the bounding box that requires precise positions. We believe that such a pioneer attempt indicates a significant opportunity for scene text spotting applications of a much larger scale than previously possible.
InstaGAN: Instance-aware Image-to-Image Translation
Jan 02, 2019
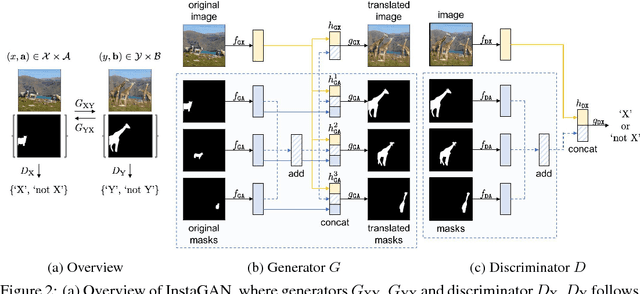
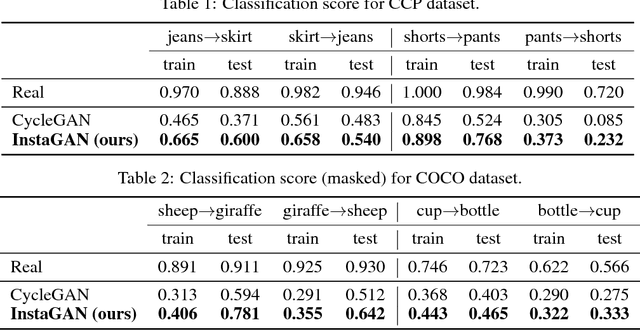
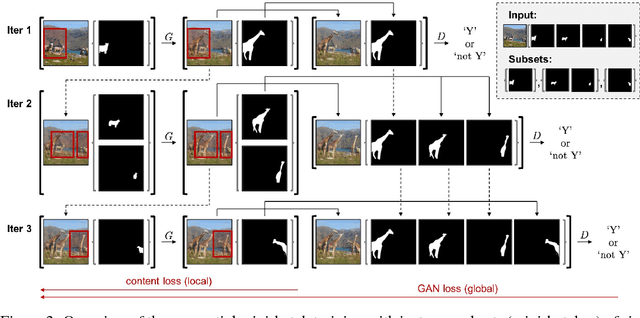
Unsupervised image-to-image translation has gained considerable attention due to the recent impressive progress based on generative adversarial networks (GANs). However, previous methods often fail in challenging cases, in particular, when an image has multiple target instances and a translation task involves significant changes in shape, e.g., translating pants to skirts in fashion images. To tackle the issues, we propose a novel method, coined instance-aware GAN (InstaGAN), that incorporates the instance information (e.g., object segmentation masks) and improves multi-instance transfiguration. The proposed method translates both an image and the corresponding set of instance attributes while maintaining the permutation invariance property of the instances. To this end, we introduce a context preserving loss that encourages the network to learn the identity function outside of target instances. We also propose a sequential mini-batch inference/training technique that handles multiple instances with a limited GPU memory and enhances the network to generalize better for multiple instances. Our comparative evaluation demonstrates the effectiveness of the proposed method on different image datasets, in particular, in the aforementioned challenging cases. Code and results are available in https://github.com/sangwoomo/instagan
Application of Video-to-Video Translation Networks to Computational Fluid Dynamics
Sep 12, 2021
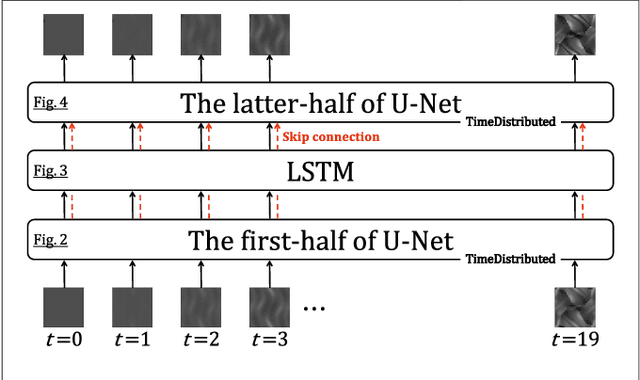
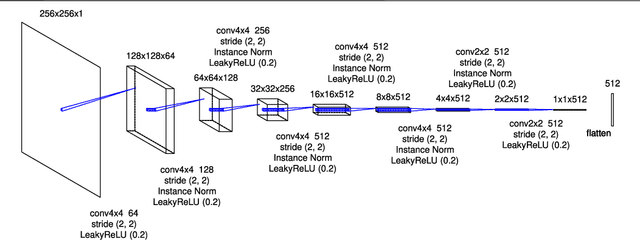

In recent years, the evolution of artificial intelligence, especially deep learning, has been remarkable, and its application to various fields has been growing rapidly. In this paper, I report the results of the application of generative adversarial networks (GANs), specifically video-to-video translation networks, to computational fluid dynamics (CFD) simulations. The purpose of this research is to reduce the computational cost of CFD simulations with GANs. The architecture of GANs in this research is a combination of the image-to-image translation networks (the so-called "pix2pix") and Long Short-Term Memory (LSTM). It is shown that the results of high-cost and high-accuracy simulations (with high-resolution computational grids) can be estimated from those of low-cost and low-accuracy simulations (with low-resolution grids). In particular, the time evolution of density distributions in the cases of a high-resolution grid is reproduced from that in the cases of a low-resolution grid through GANs, and the density inhomogeneity estimated from the image generated by GANs recovers the ground truth with good accuracy. Qualitative and quantitative comparisons of the results of the proposed method with those of several super-resolution algorithms are also presented.
GeneAnnotator: A Semi-automatic Annotation Tool for Visual Scene Graph
Sep 06, 2021
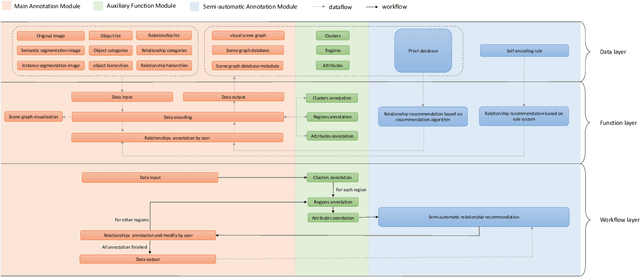
In this manuscript, we introduce a semi-automatic scene graph annotation tool for images, the GeneAnnotator. This software allows human annotators to describe the existing relationships between participators in the visual scene in the form of directed graphs, hence enabling the learning and reasoning on visual relationships, e.g., image captioning, VQA and scene graph generation, etc. The annotations for certain image datasets could either be merged in a single VG150 data-format file to support most existing models for scene graph learning or transformed into a separated annotation file for each single image to build customized datasets. Moreover, GeneAnnotator provides a rule-based relationship recommending algorithm to reduce the heavy annotation workload. With GeneAnnotator, we propose Traffic Genome, a comprehensive scene graph dataset with 1000 diverse traffic images, which in return validates the effectiveness of the proposed software for scene graph annotation. The project source code, with usage examples and sample data is available at https://github.com/Milomilo0320/A-Semi-automatic-Annotation-Software-for-Scene-Graph, under the Apache open-source license.
Robust Depth Completion with Uncertainty-Driven Loss Functions
Dec 15, 2021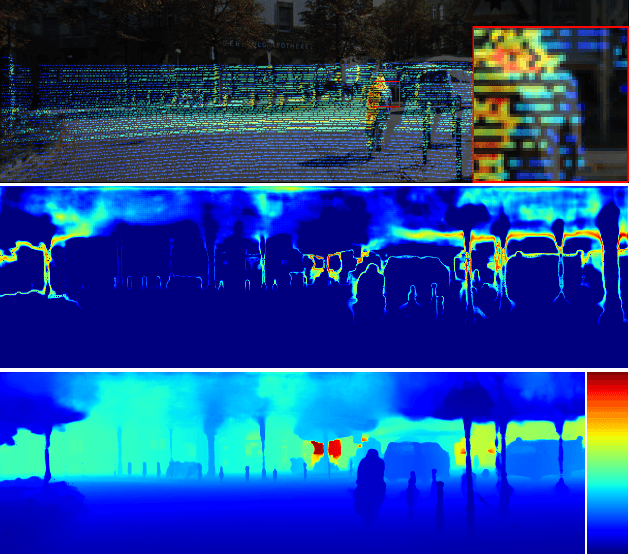
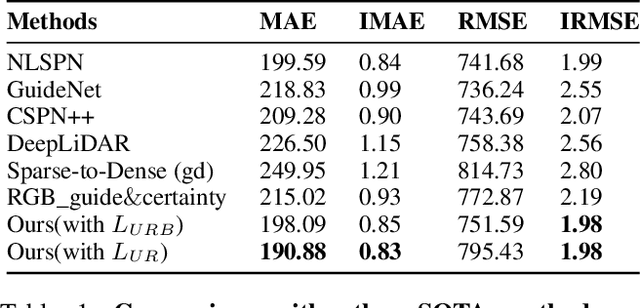
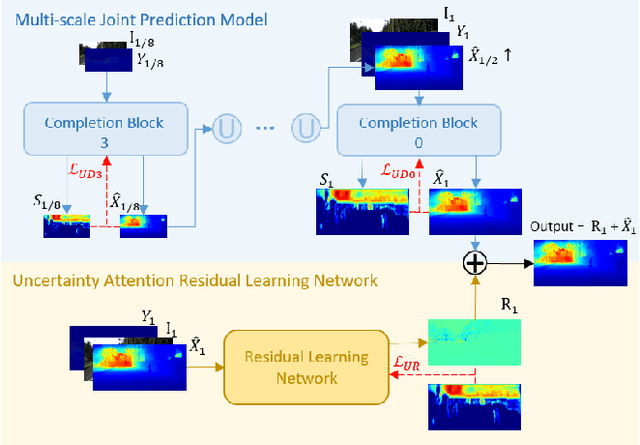
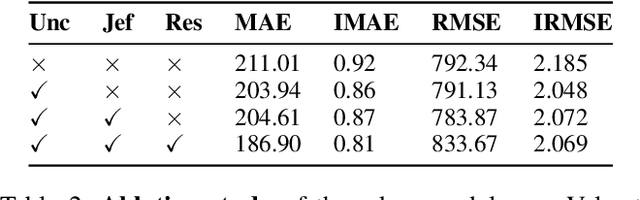
Recovering a dense depth image from sparse LiDAR scans is a challenging task. Despite the popularity of color-guided methods for sparse-to-dense depth completion, they treated pixels equally during optimization, ignoring the uneven distribution characteristics in the sparse depth map and the accumulated outliers in the synthesized ground truth. In this work, we introduce uncertainty-driven loss functions to improve the robustness of depth completion and handle the uncertainty in depth completion. Specifically, we propose an explicit uncertainty formulation for robust depth completion with Jeffrey's prior. A parametric uncertain-driven loss is introduced and translated to new loss functions that are robust to noisy or missing data. Meanwhile, we propose a multiscale joint prediction model that can simultaneously predict depth and uncertainty maps. The estimated uncertainty map is also used to perform adaptive prediction on the pixels with high uncertainty, leading to a residual map for refining the completion results. Our method has been tested on KITTI Depth Completion Benchmark and achieved the state-of-the-art robustness performance in terms of MAE, IMAE, and IRMSE metrics.