 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TextCaps: a Dataset for Image Captioning with Reading Comprehension
Mar 24, 2020

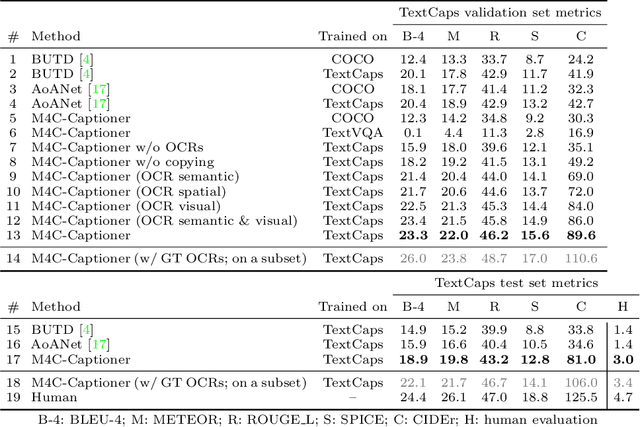

Image descriptions can help visually impaired people to quickly understand the image content. While we made significant progress in automatically describing images and optical character recognition, current approaches are unable to include written text in their descriptions, although text is omnipresent in human environments and frequently critical to understand our surroundings. To study how to comprehend text in the context of an image we collect a novel dataset, TextCaps, with 145k captions for 28k images. Our dataset challenges a model to recognize text, relate it to its visual context, and decide what part of the text to copy or paraphrase, requiring spatial, semantic, and visual reasoning between multiple text tokens and visual entities, such as objects. We study baselines and adapt existing approaches to this new task, which we refer to as image captioning with reading comprehension. Our analysis with automatic and human studies shows that our new TextCaps dataset provides many new technical challenges over previous datasets.
Multi-Subspace Neural Network for Image Recognition
Jun 17, 2020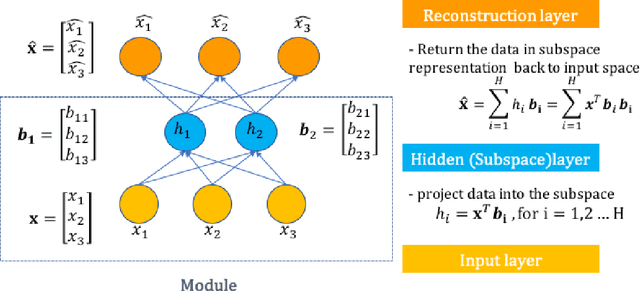
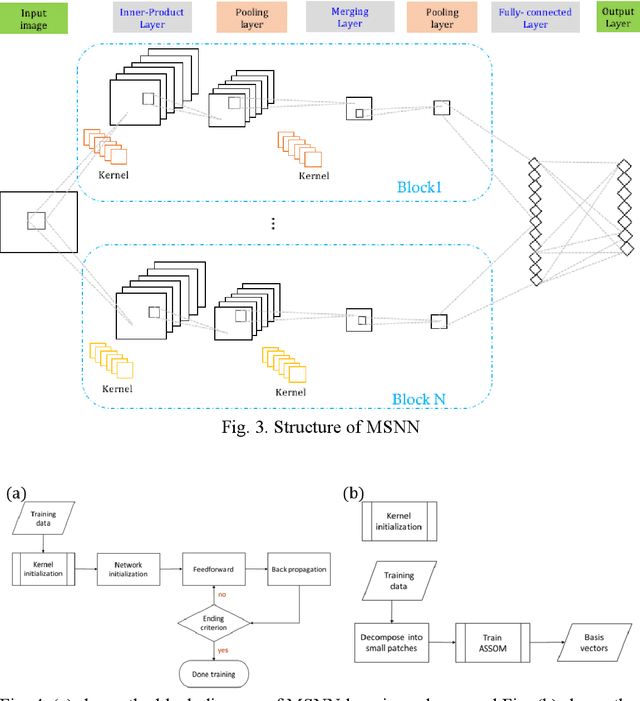
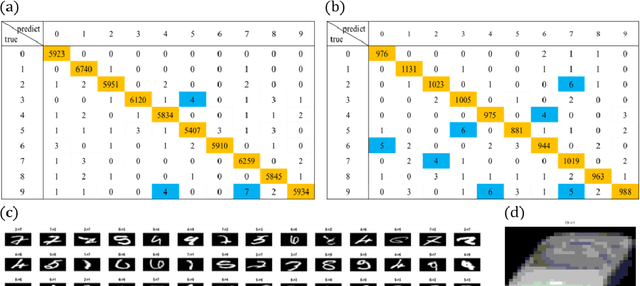
In image classification task, feature extraction is always a big issue. Intra-class variability increases the difficulty in designing the extractors. Furthermore, hand-crafted feature extractor cannot simply adapt new situation. Recently, deep learning has drawn lots of attention on automatically learning features from data. In this study, we proposed multi-subspace neural network (MSNN) which integrates key components of the convolutional neural network (CNN), receptive field, with subspace concept. Associating subspace with the deep network is a novel designing, providing various viewpoints of data. Basis vectors, trained by adaptive subspace self-organization map (ASSOM) span the subspace, serve as a transfer function to access axial components and define the receptive field to extract basic patterns of data without distorting the topology in the visual task. Moreover, the multiple-subspace strategy is implemented as parallel blocks to adapt real-world data and contribute various interpretations of data hoping to be more robust dealing with intra-class variability issues. To this end, handwritten digit and object image datasets (i.e., MNIST and COIL-20) for classification are employed to validate the proposed MSNN architecture. Experimental results show MSNN is competitive to other state-of-the-art approaches.
FIDNet: LiDAR Point Cloud Semantic Segmentation with Fully Interpolation Decoding
Sep 08, 2021

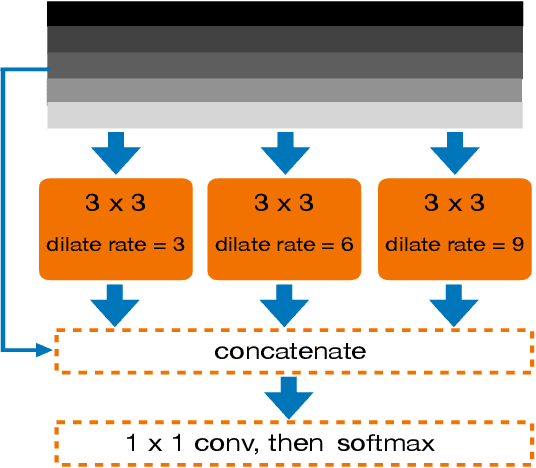

Projecting the point cloud on the 2D spherical range image transforms the LiDAR semantic segmentation to a 2D segmentation task on the range image. However, the LiDAR range image is still naturally different from the regular 2D RGB image; for example, each position on the range image encodes the unique geometry information. In this paper, we propose a new projection-based LiDAR semantic segmentation pipeline that consists of a novel network structure and an efficient post-processing step. In our network structure, we design a FID (fully interpolation decoding) module that directly upsamples the multi-resolution feature maps using bilinear interpolation. Inspired by the 3D distance interpolation used in PointNet++, we argue this FID module is a 2D version distance interpolation on $(\theta, \phi)$ space. As a parameter-free decoding module, the FID largely reduces the model complexity by maintaining good performance. Besides the network structure, we empirically find that our model predictions have clear boundaries between different semantic classes. This makes us rethink whether the widely used K-nearest-neighbor post-processing is still necessary for our pipeline. Then, we realize the many-to-one mapping causes the blurring effect that some points are mapped into the same pixel and share the same label. Therefore, we propose to process those occluded points by assigning the nearest predicted label to them. This NLA (nearest label assignment) post-processing step shows a better performance than KNN with faster inference speed in the ablation study. On the SemanticKITTI dataset, our pipeline achieves the best performance among all projection-based methods with $64 \times 2048$ resolution and all point-wise solutions. With a ResNet-34 as the backbone, both the training and testing of our model can be finished on a single RTX 2080 Ti with 11G memory. The code is released.
An Unsupervised Way to Understand Artifact Generating Internal Units in Generative Neural Networks
Dec 16, 2021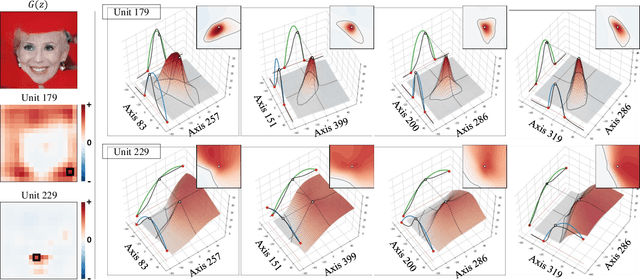
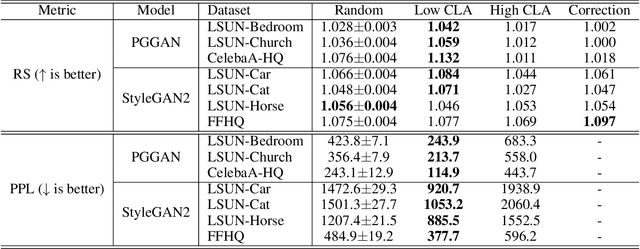
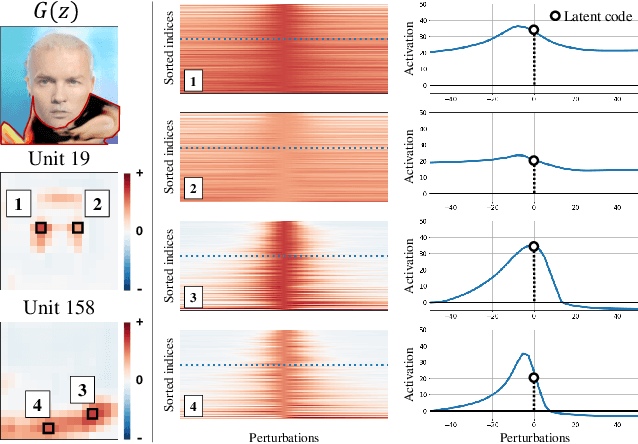
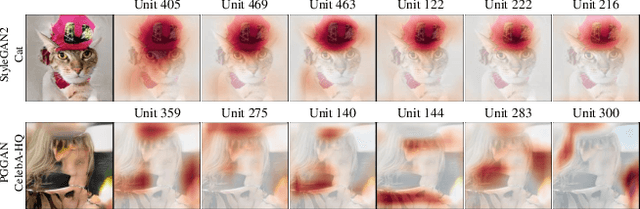
Despite significant improvements on the image generation performance of Generative Adversarial Networks (GANs), generations with low visual fidelity still have been observed. As widely used metrics for GANs focus more on the overall performance of the model, evaluation on the quality of individual generations or detection of defective generations is challenging. While recent studies try to detect featuremap units that cause artifacts and evaluate individual samples, these approaches require additional resources such as external networks or a number of training data to approximate the real data manifold. In this work, we propose the concept of local activation, and devise a metric on the local activation to detect artifact generations without additional supervision. We empirically verify that our approach can detect and correct artifact generations from GANs with various datasets. Finally, we discuss a geometrical analysis to partially reveal the relation between the proposed concept and low visual fidelity.
Statistical Analysis of Signal-Dependent Noise: Application in Blind Localization of Image Splicing Forgery
Nov 02, 2020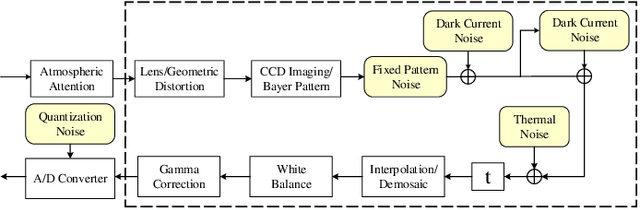
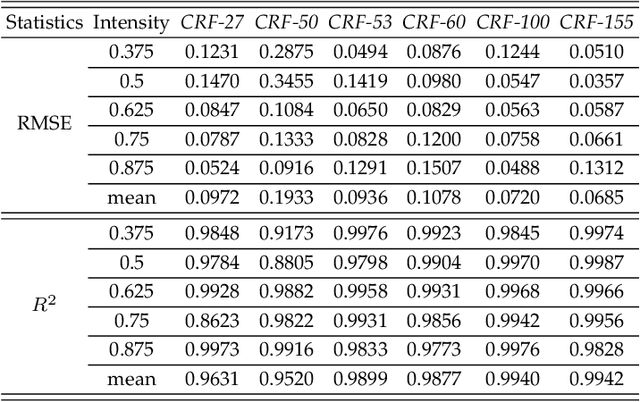
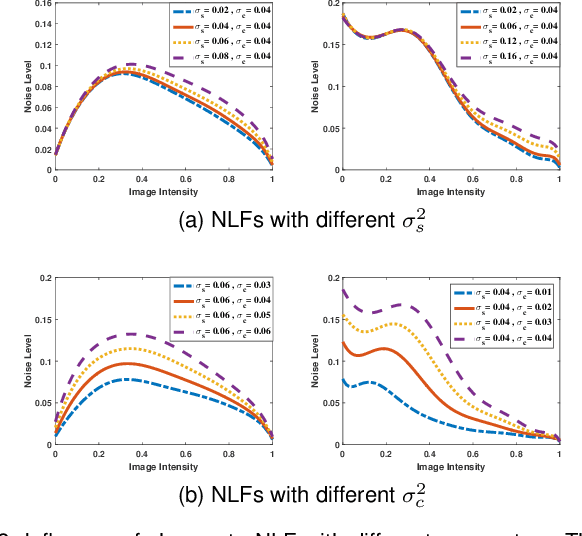
Visual noise is often regarded as a disturbance in image quality, whereas it can also provide a crucial clue for image-based forensic tasks. Conventionally, noise is assumed to comprise an additive Gaussian model to be estimated and then used to reveal anomalies. However, for real sensor noise, it should be modeled as signal-dependent noise (SDN). In this work, we apply SDN to splicing forgery localization tasks. Through statistical analysis of the SDN model, we assume that noise can be modeled as a Gaussian approximation for a certain brightness and propose a likelihood model for a noise level function. By building a maximum a posterior Markov random field (MAP-MRF) framework, we exploit the likelihood of noise to reveal the alien region of spliced objects, with a probability combination refinement strategy. To ensure a completely blind detection, an iterative alternating method is adopted to estimate the MRF parameters. Experimental results demonstrate that our method is effective and provides a comparative localization performance.
Unsupervised Deep-Learning Based Deformable Image Registration: A Bayesian Framework
Aug 10, 2020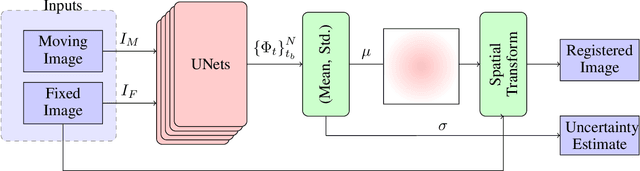

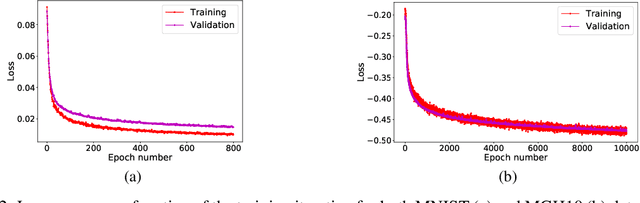
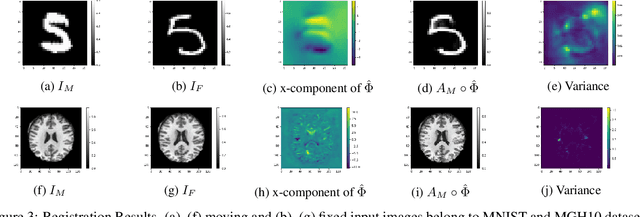
Unsupervised deep-learning (DL) models were recently proposed for deformable image registration tasks. In such models, a neural-network is trained to predict the best deformation field by minimizing some dissimilarity function between the moving and the target images. After training on a dataset without reference deformation fields available, such a model can be used to rapidly predict the deformation field between newly seen moving and target images. Currently, the training process effectively provides a point-estimate of the network weights rather than characterizing their entire posterior distribution. This may result in a potential over-fitting which may yield sub-optimal results at inference phase, especially for small-size datasets, frequently present in the medical imaging domain. We introduce a fully Bayesian framework for unsupervised DL-based deformable image registration. Our method provides a principled way to characterize the true posterior distribution, thus, avoiding potential over-fitting. We used stochastic gradient Langevin dynamics (SGLD) to conduct the posterior sampling, which is both theoretically well-founded and computationally efficient. We demonstrated the added-value of our Basyesian unsupervised DL-based registration framework on the MNIST and brain MRI (MGH10) datasets in comparison to the VoxelMorph unsupervised DL-based image registration framework. Our experiments show that our approach provided better estimates of the deformation field by means of improved mean-squared-error ($0.0063$ vs. $0.0065$) and Dice coefficient ($0.73$ vs. $0.71$) for the MNIST and the MGH10 datasets respectively. Further, our approach provides an estimate of the uncertainty in the deformation-field by characterizing the true posterior distribution.
SwAMP: Swapped Assignment of Multi-Modal Pairs for Cross-Modal Retrieval
Nov 10, 2021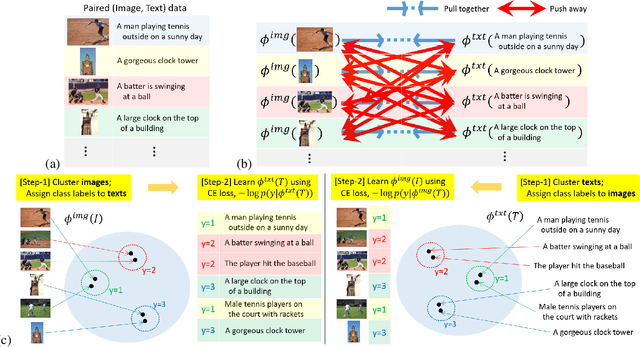
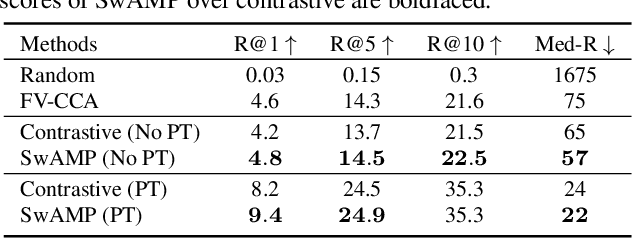
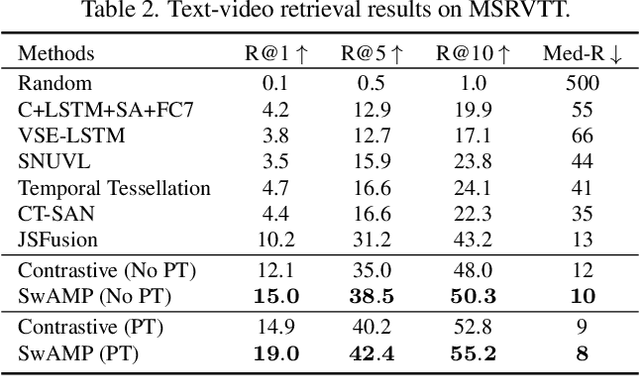
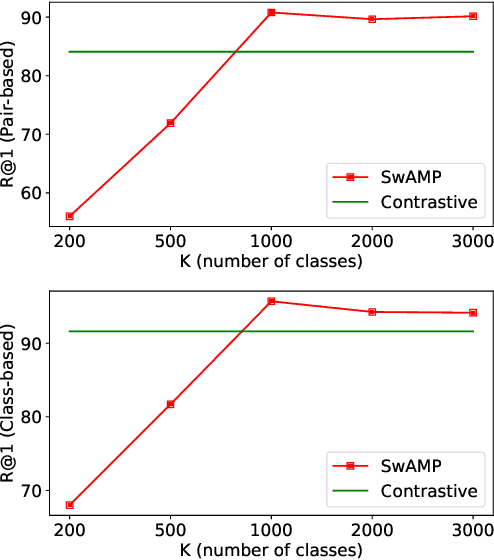
We tackle the cross-modal retrieval problem, where the training is only supervised by the relevant multi-modal pairs in the data. The contrastive learning is the most popular approach for this task. However, its sampling complexity for learning is quadratic in the number of training data points. Moreover, it makes potentially wrong assumption that the instances in different pairs are automatically irrelevant. To address these issues, we propose a novel loss function that is based on self-labeling of the unknown classes. Specifically, we aim to predict class labels of the data instances in each modality, and assign those labels to the corresponding instances in the other modality (i.e., swapping the pseudo labels). With these swapped labels, we learn the data embedding for each modality using the supervised cross-entropy loss, hence leading to linear sampling complexity. We also maintain the queues for storing the embeddings of the latest batches, for which clustering assignment and embedding learning are done at the same time in an online fashion. This removes computational overhead of injecting intermittent epochs of entire training data sweep for offline clustering. We tested our approach on several real-world cross-modal retrieval problems, including text-based video retrieval, sketch-based image retrieval, and image-text retrieval, and for all these tasks our method achieves significant performance improvement over the contrastive learning.
Train and Deploy an Image Classifier for Disaster Response
May 12, 2020
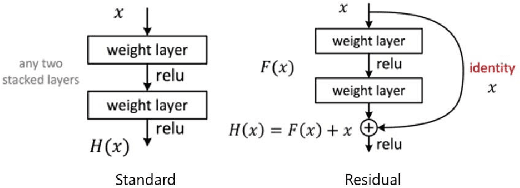
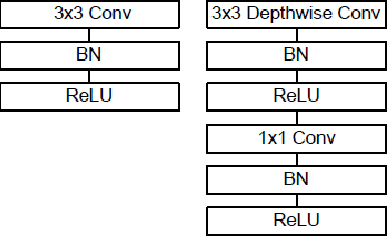
With Deep Learning Image Classification becoming more powerful each year, it is apparent that its introduction to disaster response will increase the efficiency that responders can work with. Using several Neural Network Models, including AlexNet, ResNet, MobileNet, DenseNets, and 4-Layer CNN, we have classified flood disaster images from a large image data set with up to 79% accuracy. Our models and tutorials for working with the data set have created a foundation for others to classify other types of disasters contained in the images.
A Contrastive Learning Approach to Auroral Identification and Classification
Sep 29, 2021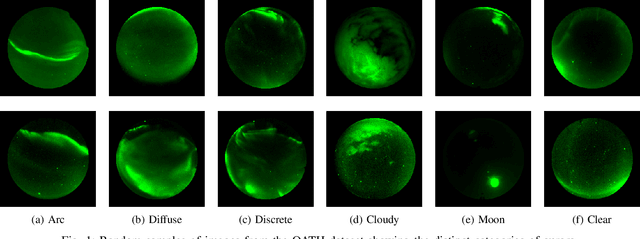
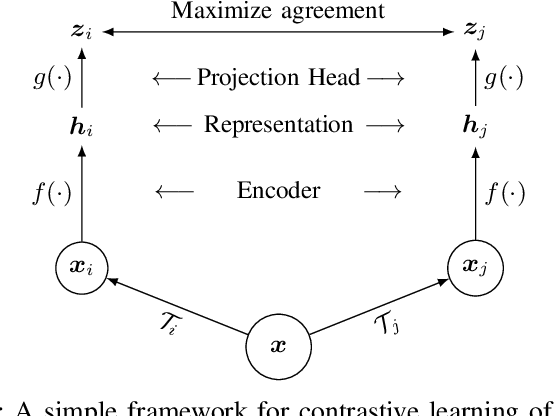
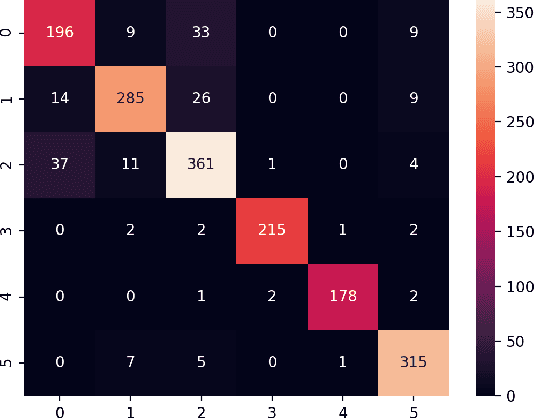
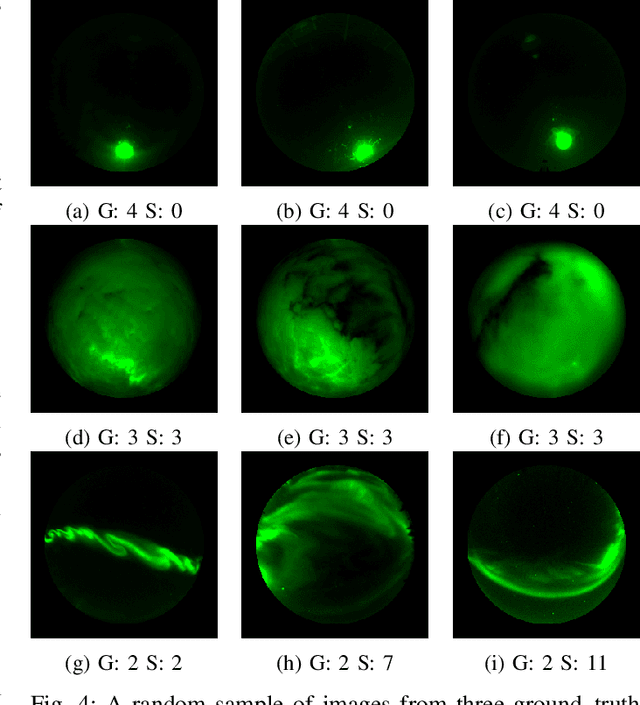
Unsupervised learning algorithms are beginning to achieve accuracies comparable to their supervised counterparts on benchmark computer vision tasks, but their utility for practical applications has not yet been demonstrated. In this work, we present a novel application of unsupervised learning to the task of auroral image classification. Specifically, we modify and adapt the Simple framework for Contrastive Learning of Representations (SimCLR) algorithm to learn representations of auroral images in a recently released auroral image dataset constructed using image data from Time History of Events and Macroscale Interactions during Substorms (THEMIS) all-sky imagers. We demonstrate that (a) simple linear classifiers fit to the learned representations of the images achieve state-of-the-art classification performance, improving the classification accuracy by almost 10 percentage points over the current benchmark; and (b) the learned representations naturally cluster into more clusters than exist manually assigned categories, suggesting that existing categorizations are overly coarse and may obscure important connections between auroral types, near-earth solar wind conditions, and geomagnetic disturbances at the earth's surface. Moreover, our model is much lighter than the previous benchmark on this dataset, requiring in the area of fewer than 25\% of the number of parameters. Our approach exceeds an established threshold for operational purposes, demonstrating readiness for deployment and utilization.
Anisotropic Mesh Adaptation for Image Segmentation Based on Mumford-Shah Functional
Jul 17, 2020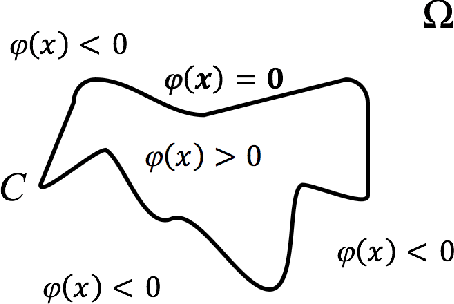
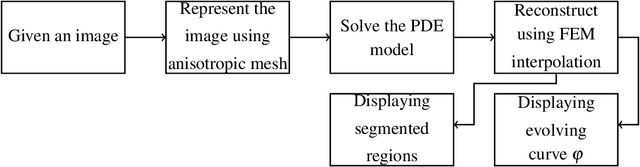
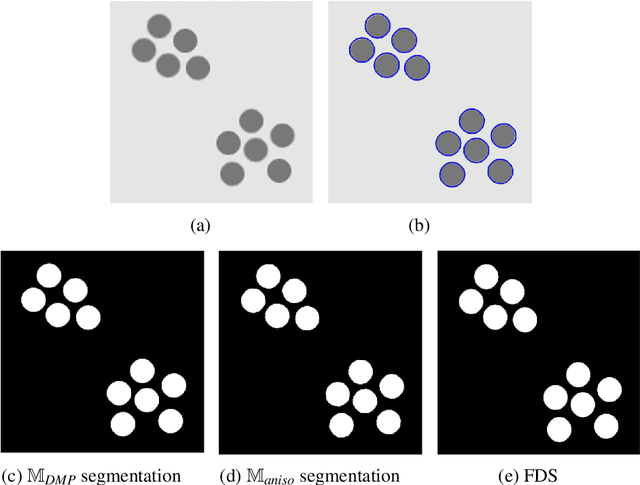

As the resolution of digital images increase significantly, the processing of images becomes more challenging in terms of accuracy and efficiency. In this paper, we consider image segmentation by solving a partial differentiation equation (PDE) model based on the Mumford-Shah functional. We develop a new algorithm by combining anisotropic mesh adaptation for image representation and finite element method for solving the PDE model. Comparing to traditional algorithms solved by finite difference method, our algorithm provides faster and better results without the need to resizing the images to lower quality. We also extend the algorithm to segment images with multiple regions.