 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image-Guided Navigation of a Robotic Ultrasound Probe for Autonomous Spinal Sonography Using a Shadow-aware Dual-Agent Framework
Nov 10, 2021
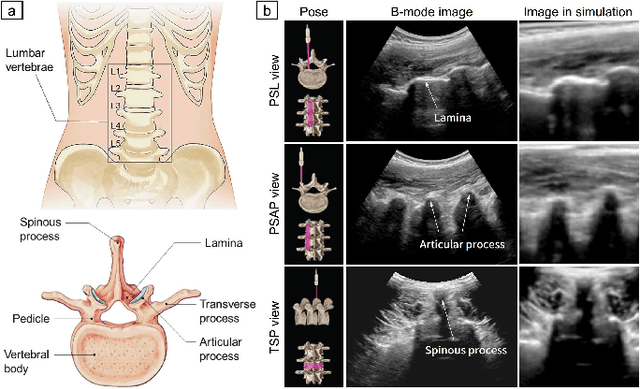
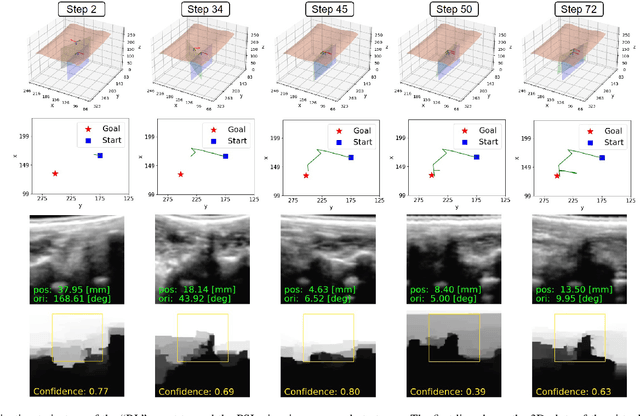
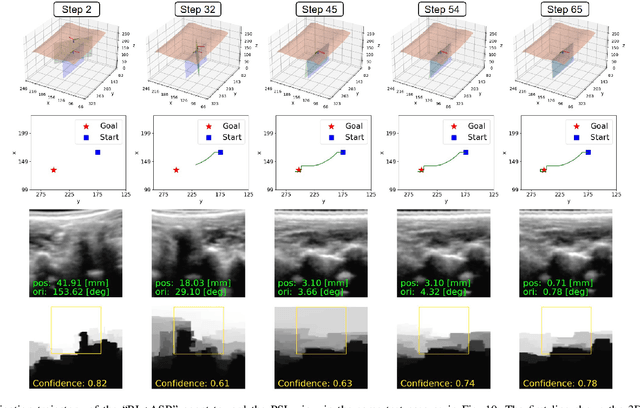
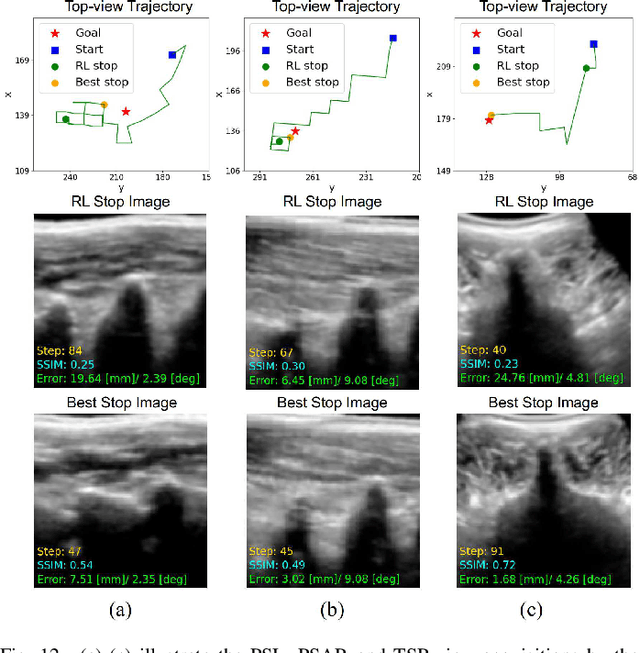
Ultrasound (US) imaging is commonly used to assist in the diagnosis and interventions of spine diseases, while the standardized US acquisitions performed by manually operating the probe require substantial experience and training of sonographers. In this work, we propose a novel dual-agent framework that integrates a reinforcement learning (RL) agent and a deep learning (DL) agent to jointly determine the movement of the US probe based on the real-time US images, in order to mimic the decision-making process of an expert sonographer to achieve autonomous standard view acquisitions in spinal sonography. Moreover, inspired by the nature of US propagation and the characteristics of the spinal anatomy, we introduce a view-specific acoustic shadow reward to utilize the shadow information to implicitly guide the navigation of the probe toward different standard views of the spine. Our method is validated in both quantitative and qualitative experiments in a simulation environment built with US data acquired from 17 volunteers. The average navigation accuracy toward different standard views achieves 5.18mm/5.25deg and 12.87mm/17.49deg in the intra- and inter-subject settings, respectively. The results demonstrate that our method can effectively interpret the US images and navigate the probe to acquire multiple standard views of the spine.
SIR: Self-supervised Image Rectification via Seeing the Same Scene from Multiple Different Lenses
Nov 30, 2020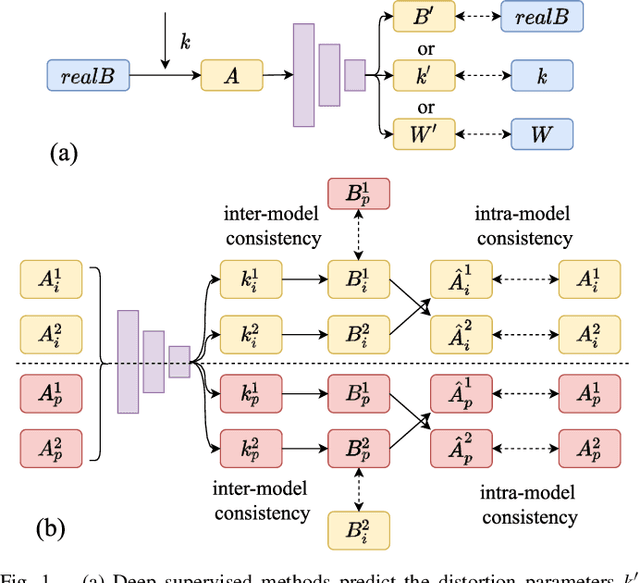
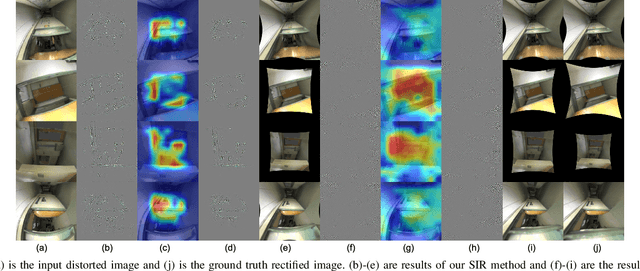
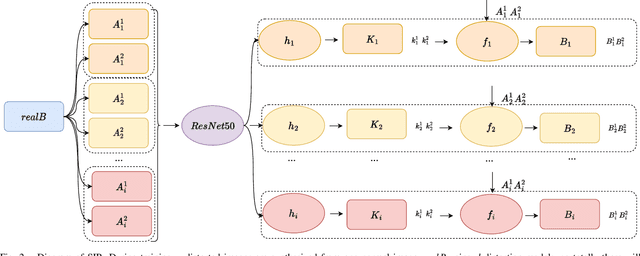
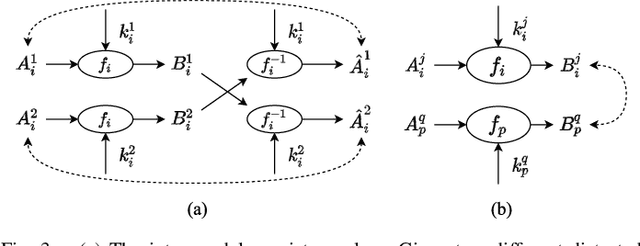
Deep learning has demonstrated its power in image rectification by leveraging the representation capacity of deep neural networks via supervised training based on a large-scale synthetic dataset. However, the model may overfit the synthetic images and generalize not well on real-world fisheye images due to the limited universality of a specific distortion model and the lack of explicitly modeling the distortion and rectification process. In this paper, we propose a novel self-supervised image rectification (SIR) method based on an important insight that the rectified results of distorted images of the same scene from different lens should be the same. Specifically, we devise a new network architecture with a shared encoder and several prediction heads, each of which predicts the distortion parameter of a specific distortion model. We further leverage a differentiable warping module to generate the rectified images and re-distorted images from the distortion parameters and exploit the intra- and inter-model consistency between them during training, thereby leading to a self-supervised learning scheme without the need for ground-truth distortion parameters or normal images. Experiments on synthetic dataset and real-world fisheye images demonstrate that our method achieves comparable or even better performance than the supervised baseline method and representative state-of-the-art methods. Self-supervised learning also improves the universality of distortion models while keeping their self-consistency.
Time accelerated image super-resolution using shallow residual feature representative network
Apr 08, 2020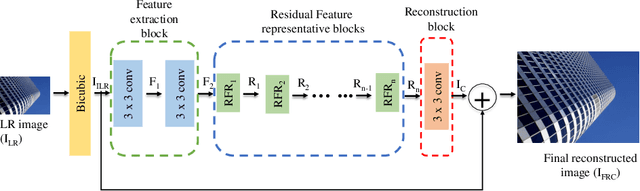
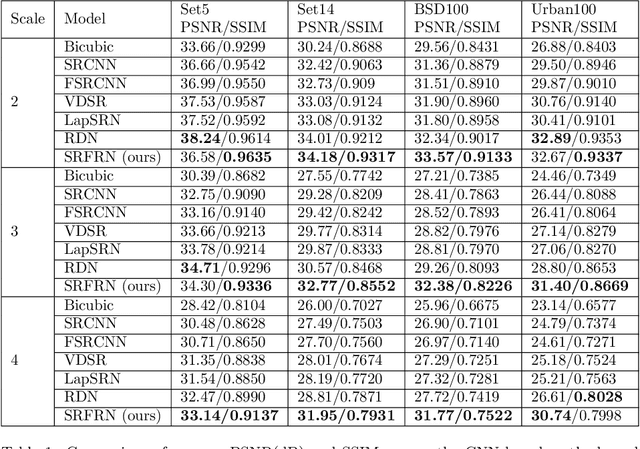

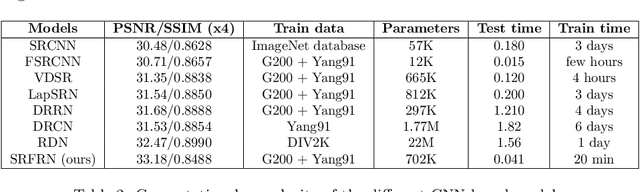
The recent advances in deep learning indicate significant progress in the field of single image super-resolution. With the advent of these techniques, high-resolution image with high peak signal to noise ratio (PSNR) and excellent perceptual quality can be reconstructed. The major challenges associated with existing deep convolutional neural networks are their computational complexity and time; the increasing depth of the networks, often result in high space complexity. To alleviate these issues, we developed an innovative shallow residual feature representative network (SRFRN) that uses a bicubic interpolated low-resolution image as input and residual representative units (RFR) which include serially stacked residual non-linear convolutions. Furthermore, the reconstruction of the high-resolution image is done by combining the output of the RFR units and the residual output from the bicubic interpolated LR image. Finally, multiple experiments have been performed on the benchmark datasets and the proposed model illustrates superior performance for higher scales. Besides, this model also exhibits faster execution time compared to all the existing approaches.
Domain-Specific Image Super-Resolution with Progressive Adversarial Network
Mar 10, 2020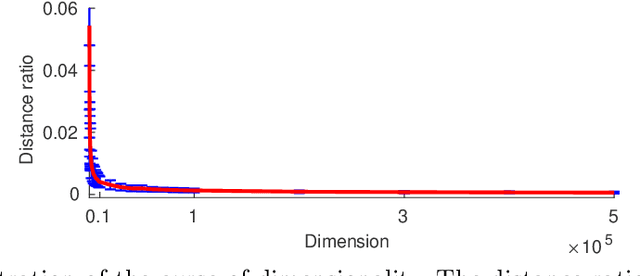
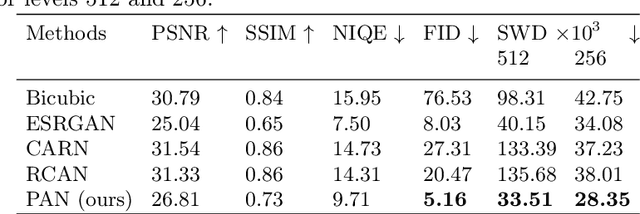
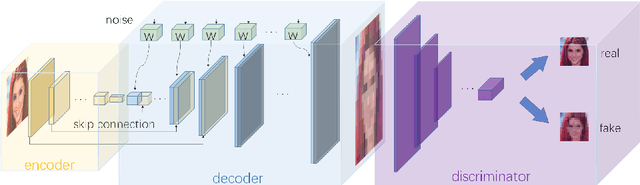
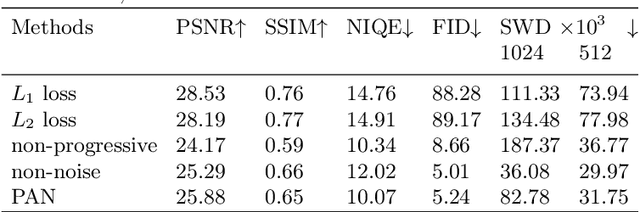
Single Image Super-Resolution (SISR) aims to improve resolution of small-size low-quality image from a single one. With popularity of consumer electronics in our daily life, this topic has become more and more attractive. In this paper, we argue that the curse of dimensionality is the underlying reason of limiting the performance of state-of-the-art algorithms. To address this issue, we propose Progressive Adversarial Network (PAN) that is capable of coping with this difficulty for domainspecific image super-resolution. The key principle of PAN is that we do not apply any distance-based reconstruction errors as the loss to be optimized, thus free from the restriction of the curse of dimensionality. To maintain faithful reconstruction precision, we resort to U-Net and progressive growing of neural architecture. The low-level features in encoder can be transferred into decoder to enhance textural details with U-Net. Progressive growing enhances image resolution gradually, thereby preserving precision of recovered image. Moreover, to obtain high-fidelity outputs, we leverage the framework of the powerful StyleGAN to perform adversarial learning. Without the curse of dimensionality, our model can super-resolve large-size images with remarkable photo-realistic details and few distortion. Extensive experiments demonstrate the superiority of our algorithm over existing state-of-the-arts both quantitatively and qualitatively.
ClonalNet: Classifying Better by Focusing on Confusing Categories
Oct 14, 2021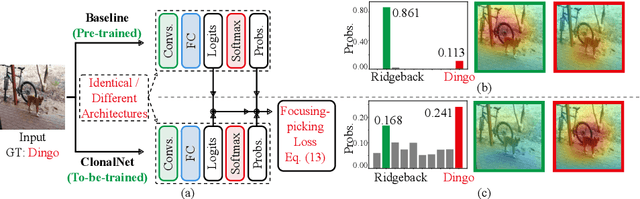
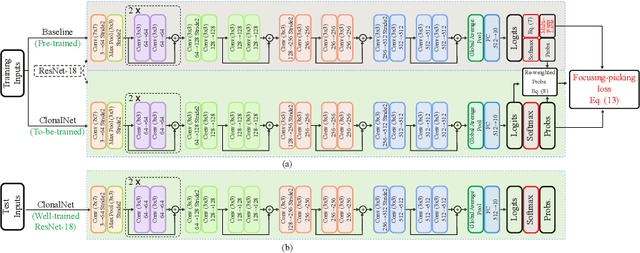

Existing neural classification networks predominately adopt one-hot encoding due to its simplicity in representing categorical data. However, the one-hot representation neglects inter-category correlations, which may result in poor generalization. Herein, we observe that a pre-trained baseline network has paid attention to the target image region even though it incorrectly predicts the image, revealing which categories confuse the baseline. This observation motivates us to consider inter-category correlations. Therefore, we propose a clonal network, named ClonalNet, which learns to discriminate between confusing categories derived from the pre-trained baseline. The ClonalNet architecture can be identical or smaller than the baseline architecture. When identical, ClonalNet is a clonal version of the baseline but does not share weights. When smaller, the training process of ClonalNet resembles that of the standard knowledge distillation. The difference from knowledge distillation is that we design a focusing-picking loss to optimize ClonalNet. This novel loss enforces ClonalNet to concentrate on confusing categories and make more confident predictions on ground-truth labels with the baseline reference. Experiments show that ClonalNet significantly outperforms baseline networks and knowledge distillation.
Text-Based Person Search with Limited Data
Oct 20, 2021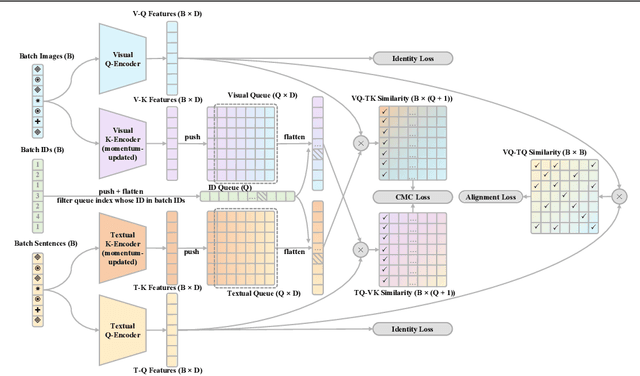
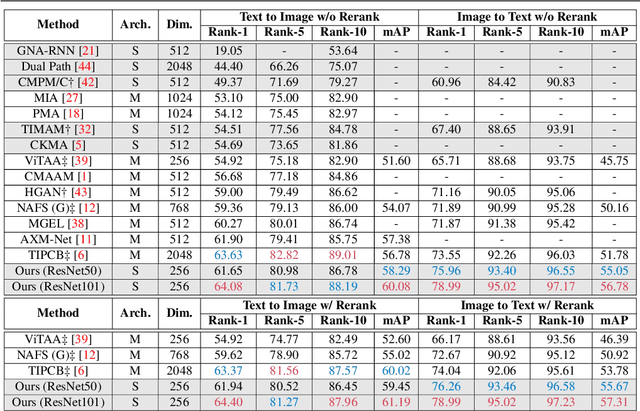
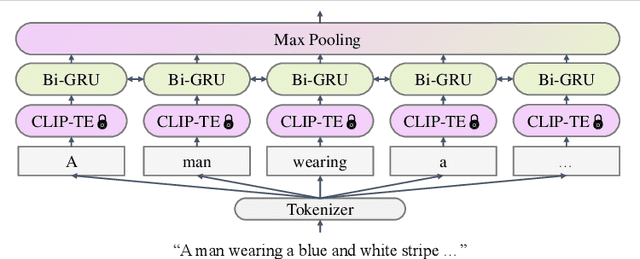
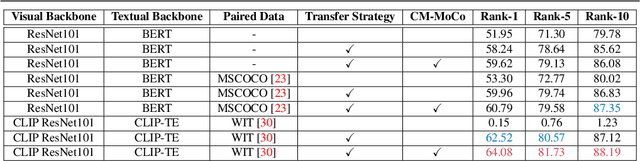
Text-based person search (TBPS) aims at retrieving a target person from an image gallery with a descriptive text query. Solving such a fine-grained cross-modal retrieval task is challenging, which is further hampered by the lack of large-scale datasets. In this paper, we present a framework with two novel components to handle the problems brought by limited data. Firstly, to fully utilize the existing small-scale benchmarking datasets for more discriminative feature learning, we introduce a cross-modal momentum contrastive learning framework to enrich the training data for a given mini-batch. Secondly, we propose to transfer knowledge learned from existing coarse-grained large-scale datasets containing image-text pairs from drastically different problem domains to compensate for the lack of TBPS training data. A transfer learning method is designed so that useful information can be transferred despite the large domain gap. Armed with these components, our method achieves new state of the art on the CUHK-PEDES dataset with significant improvements over the prior art in terms of Rank-1 and mAP. Our code is available at https://github.com/BrandonHanx/TextReID.
Traversing within the Gaussian Typical Set: Differentiable Gaussianization Layers for Inverse Problems Augmented by Normalizing Flows
Dec 07, 2021
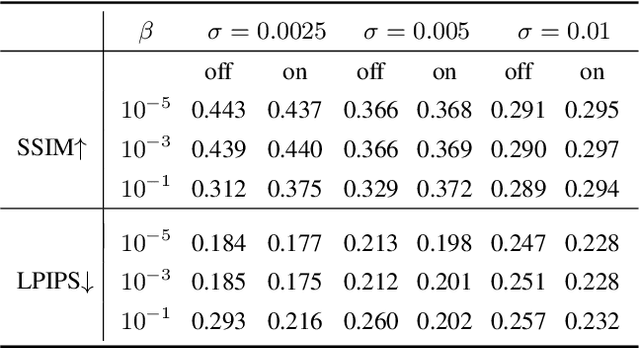
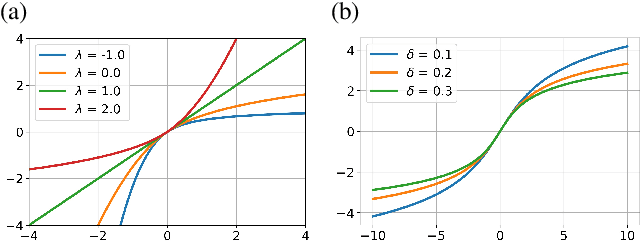
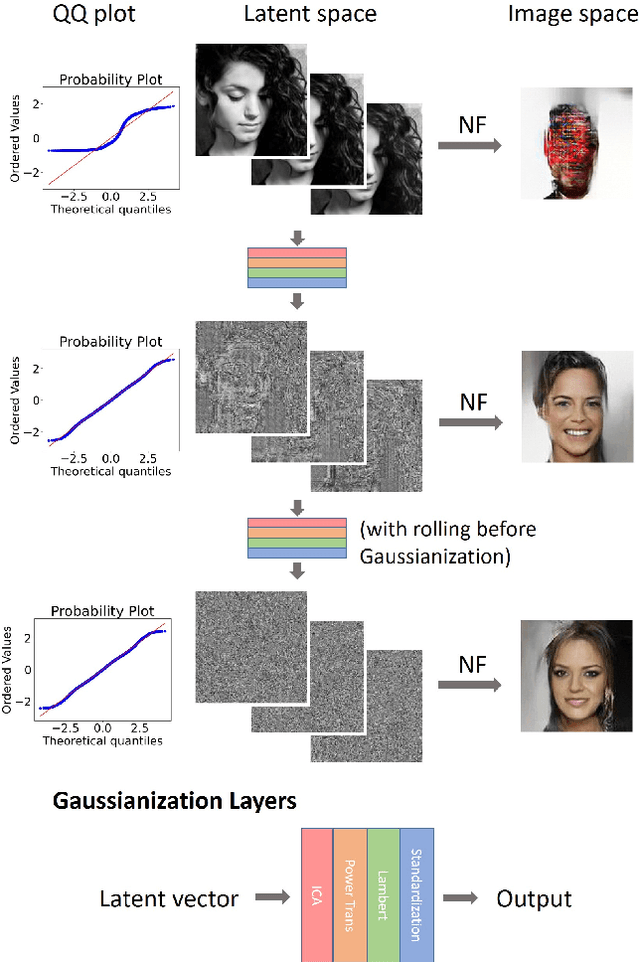
Generative networks such as normalizing flows can serve as a learning-based prior to augment inverse problems to achieve high-quality results. However, the latent space vector may not remain a typical sample from the desired high-dimensional standard Gaussian distribution when traversing the latent space during an inversion. As a result, it can be challenging to attain a high-fidelity solution, particularly in the presence of noise and inaccurate physics-based models. To address this issue, we propose to re-parameterize and Gaussianize the latent vector using novel differentiable data-dependent layers wherein custom operators are defined by solving optimization problems. These proposed layers enforce an inversion to find a feasible solution within a Gaussian typical set of the latent space. We tested and validated our technique on an image deblurring task and eikonal tomography -- a PDE-constrained inverse problem and achieved high-fidelity results.
Convolutional Neural Network-Based Age Estimation Using B-Mode Ultrasound Tongue Image
Jan 27, 2021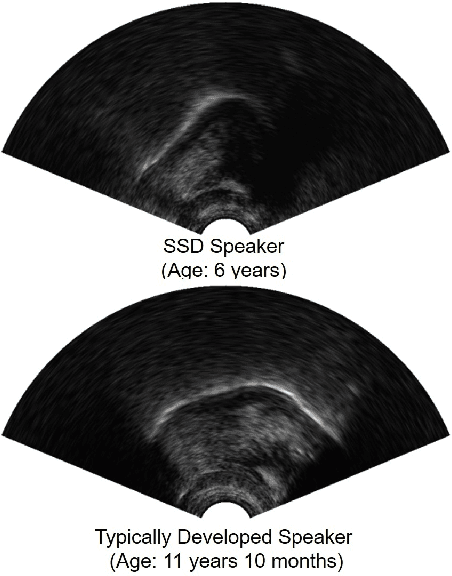
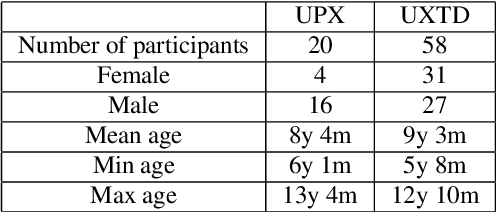
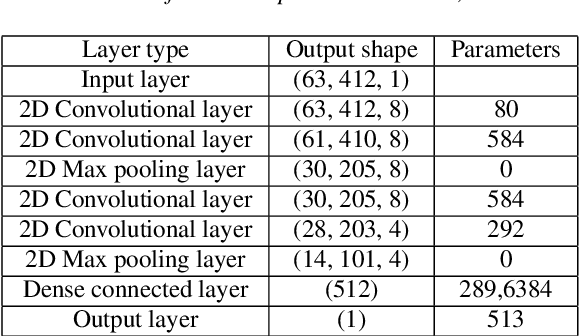
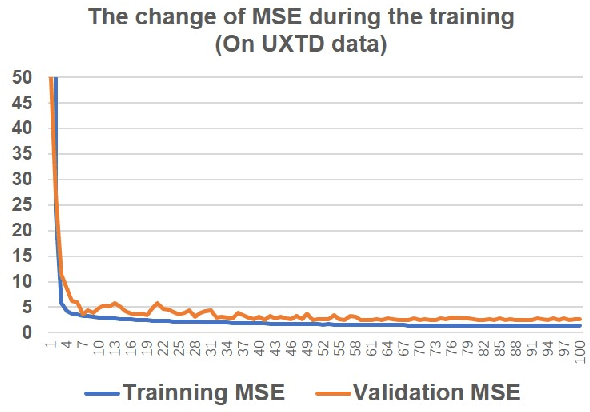
Ultrasound tongue imaging is widely used for speech production research, and it has attracted increasing attention as its potential applications seem to be evident in many different fields, such as the visual biofeedback tool for second language acquisition and silent speech interface. Unlike previous studies, here we explore the feasibility of age estimation using the ultrasound tongue image of the speakers. Motivated by the success of deep learning, this paper leverages deep learning on this task. We train a deep convolutional neural network model on the UltraSuite dataset. The deep model achieves mean absolute error (MAE) of 2.03 for the data from typically developing children, while MAE is 4.87 for the data from the children with speech sound disorders, which suggest that age estimation using ultrasound is more challenging for the children with speech sound disorder. The developed method can be used a tool to evaluate the performance of speech therapy sessions. It is also worthwhile to notice that, although we leverage the ultrasound tongue imaging for our study, the proposed methods may also be extended to other imaging modalities (e.g. MRI) to assist the studies on speech production.
SLCRF: Subspace Learning with Conditional Random Field for Hyperspectral Image Classification
Oct 07, 2020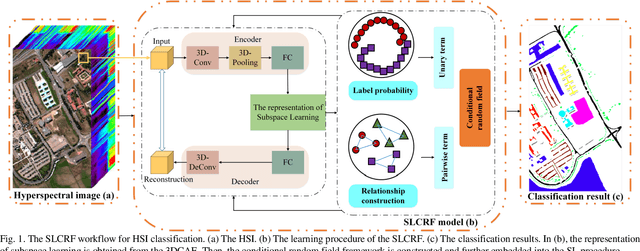

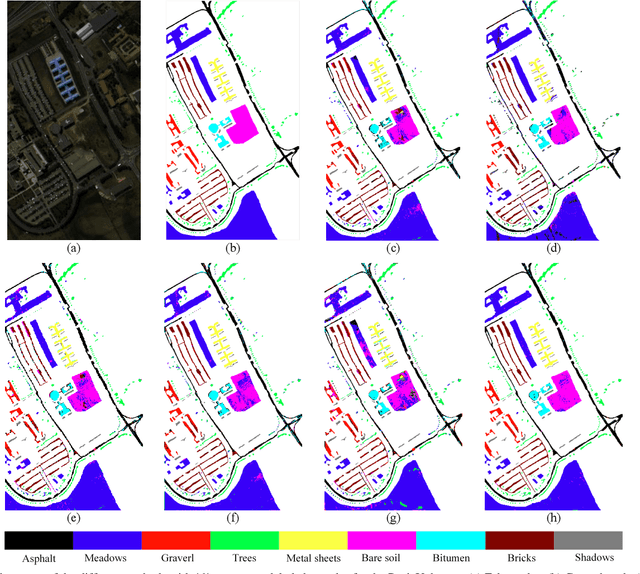
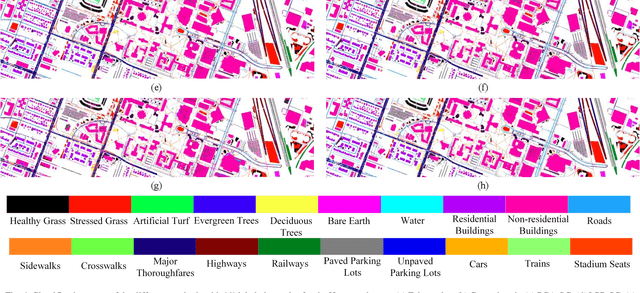
Subspace learning (SL) plays an important role in hyperspectral image (HSI) classification, since it can provide an effective solution to reduce the redundant information in the image pixels of HSIs. Previous works about SL aim to improve the accuracy of HSI recognition. Using a large number of labeled samples, related methods can train the parameters of the proposed solutions to obtain better representations of HSI pixels. However, the data instances may not be sufficient enough to learn a precise model for HSI classification in real applications. Moreover, it is well-known that it takes much time, labor and human expertise to label HSI images. To avoid the aforementioned problems, a novel SL method that includes the probability assumption called subspace learning with conditional random field (SLCRF) is developed. In SLCRF, first, the 3D convolutional autoencoder (3DCAE) is introduced to remove the redundant information in HSI pixels. In addition, the relationships are also constructed using the spectral-spatial information among the adjacent pixels. Then, the conditional random field (CRF) framework can be constructed and further embedded into the HSI SL procedure with the semi-supervised approach. Through the linearized alternating direction method termed LADMAP, the objective function of SLCRF is optimized using a defined iterative algorithm. The proposed method is comprehensively evaluated using the challenging public HSI datasets. We can achieve stateof-the-art performance using these HSI sets.
Novelty-based Generalization Evaluation for Traffic Light Detection
Jan 03, 2022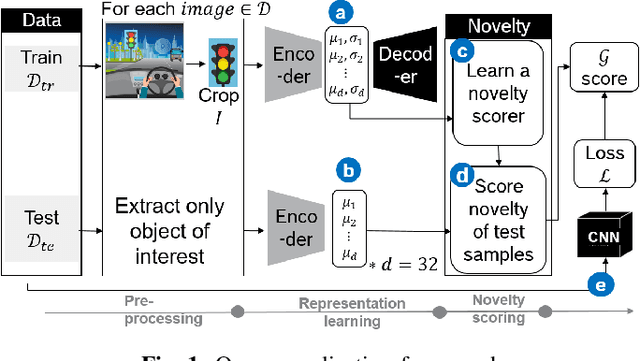
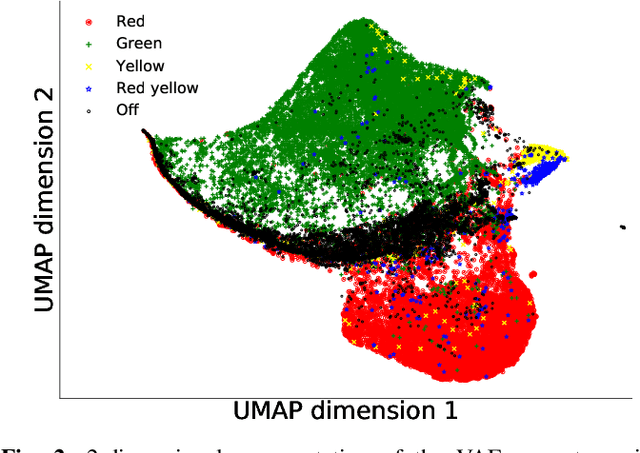
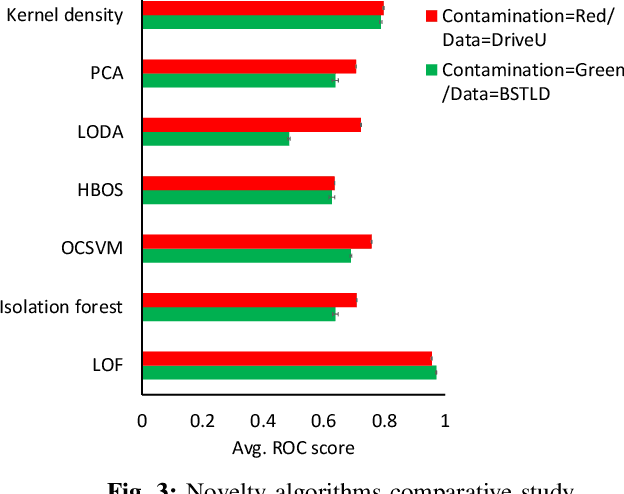
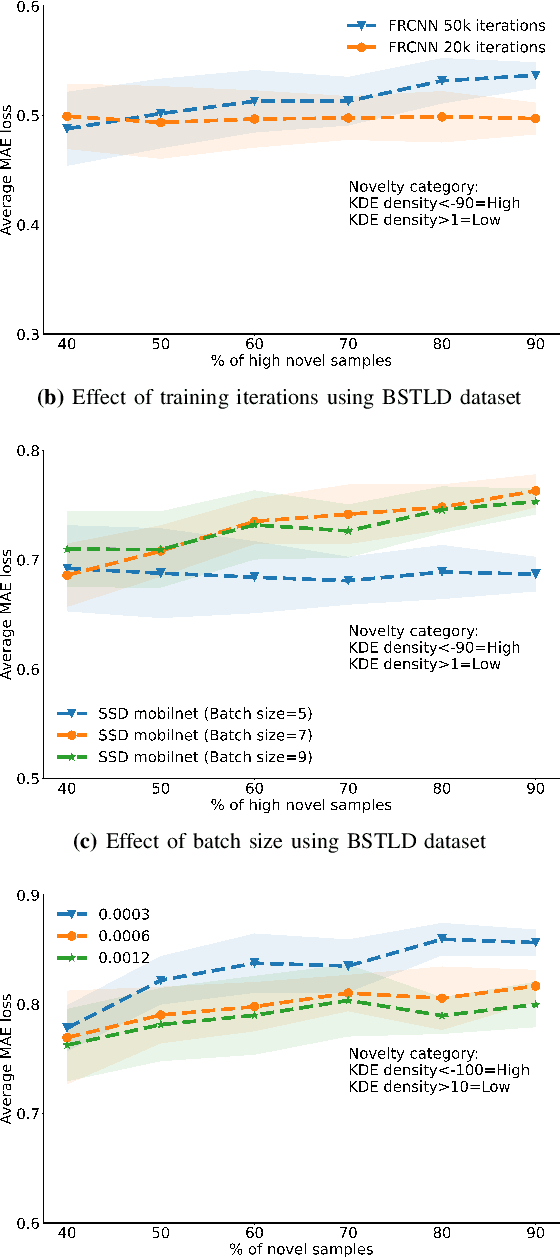
The advent of Convolutional Neural Networks (CNNs) has led to their application in several domains. One noteworthy application is the perception system for autonomous driving that relies on the predictions from CNNs. Practitioners evaluate the generalization ability of such CNNs by calculating various metrics on an independent test dataset. A test dataset is often chosen based on only one precondition, i.e., its elements are not a part of the training data. Such a dataset may contain objects that are both similar and novel w.r.t. the training dataset. Nevertheless, existing works do not reckon the novelty of the test samples and treat them all equally for evaluating generalization. Such novelty-based evaluations are of significance to validate the fitness of a CNN in autonomous driving applications. Hence, we propose a CNN generalization scoring framework that considers novelty of objects in the test dataset. We begin with the representation learning technique to reduce the image data into a low-dimensional space. It is on this space we estimate the novelty of the test samples. Finally, we calculate the generalization score as a combination of the test data prediction performance and novelty. We perform an experimental study of the same for our traffic light detection application. In addition, we systematically visualize the results for an interpretable notion of novelty.